数据结构(C):从初识堆到堆排序的实现


目录
🌞0.前言
🚈 1.堆的概念
🚈 2.堆的实现
🚝2.1堆向下调整算法
🚝2.2堆的创建(堆向下调整算法)
✈️2.2.1 向下调整建堆时间复杂度
🚝2.3堆向上调整算法
🚝2.4堆的创建(堆向上调整算法)
✈️2.4.1向上调整算法建堆的时间复杂度
🚝2.5堆的插入
🚝2.6堆的删除
🚝2.7建堆的代码实现
✈️2.7.1向下调整实现堆的建立
✈️2.7.2向上调整实现堆的建立
🚈 3.完整的堆的代码的实现
🚝3.1堆的创建
🚝3.2堆的销毁
🚝3.3堆的插入
🚝3.4堆的删除(头删)
🚝3.5取堆顶元素的数据
🚝3.6 堆的数据个数
🚝3.7堆的判空
🚈 4.堆的应用堆排序
✍5.结束语
🌞0.前言
言C之言,聊C之识,以C会友,共向远方。各位博友的各位你们好啊,这里是持续分享数据结构知识的小赵同学,今天要分享的数据结构知识是堆,在这一章,小赵将会向大家展开聊聊堆的相关知识。✊
🚈 1.堆的概念
堆就是以 二叉树的顺序存储方式来存储元素,同时又要满足 父亲结点存储数据都要大于等于儿子结点存储数据(也可以是父亲结点数据都要小于等于儿子结点数据)的一种数据结构。堆只有两种即大堆和小堆,大堆就是父亲结点数据大于等于儿子结点数据,小堆则反之。
同时这里要注意的是堆一定是完全二叉树,不然就不是堆。那完全二叉树是什么呢?这个地方不懂的博友可以看我们的这一篇博客:数据结构(C)树的概念和二叉树初见http://t.csdnimg.cn/JnWfb
如果看完了还是不明白可以私信小赵询问哦。
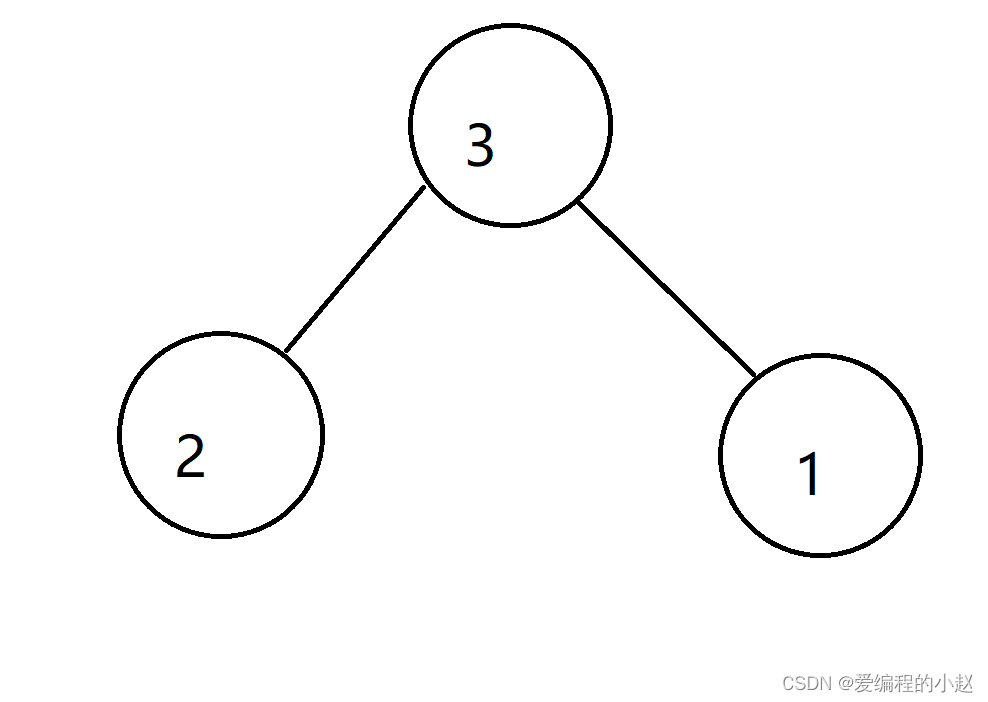
好了下面让我们看看上面说的两种堆在图上是怎么呈现的呢?
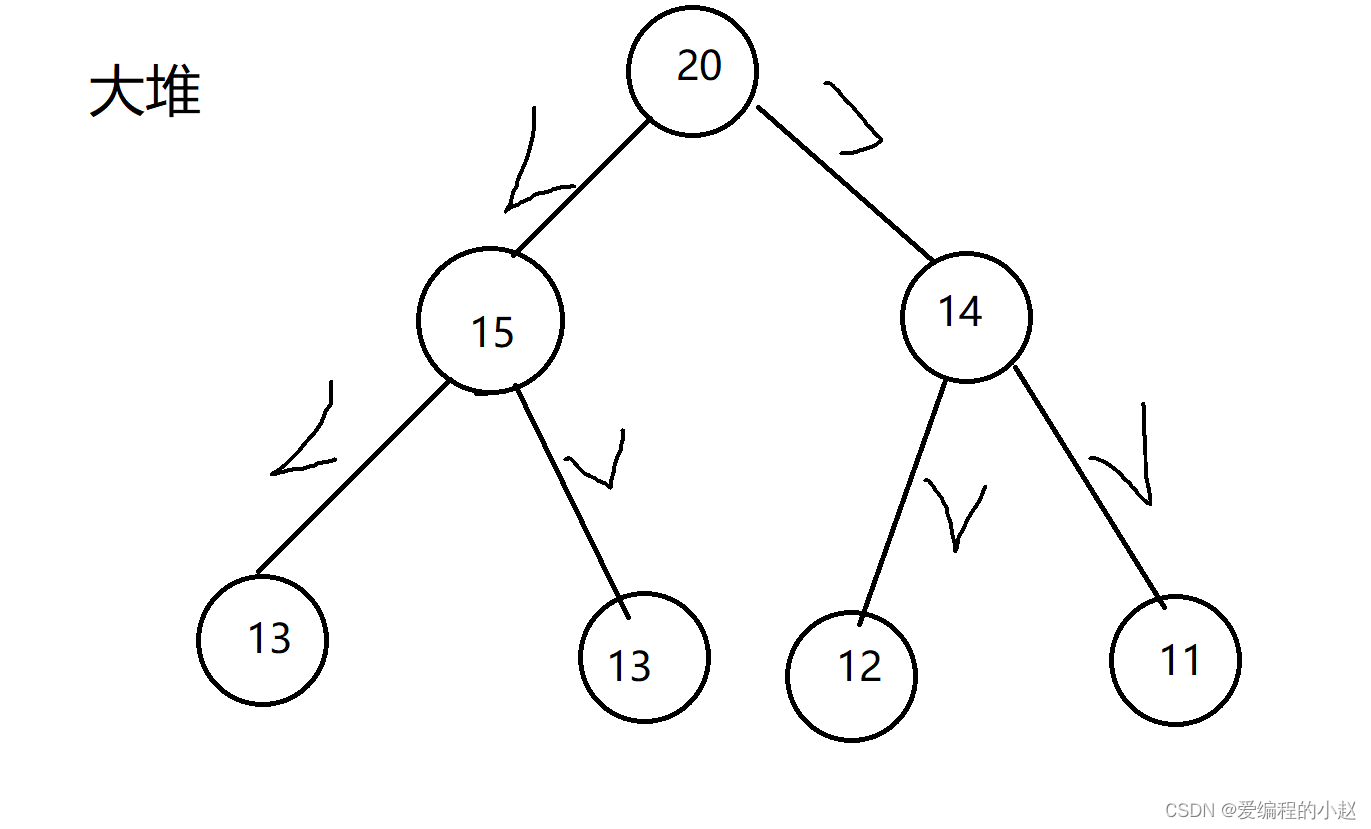
我们发现我们的任意一个父节点都比他的两个子节点大(或等于)这个时候这就是一个大堆。
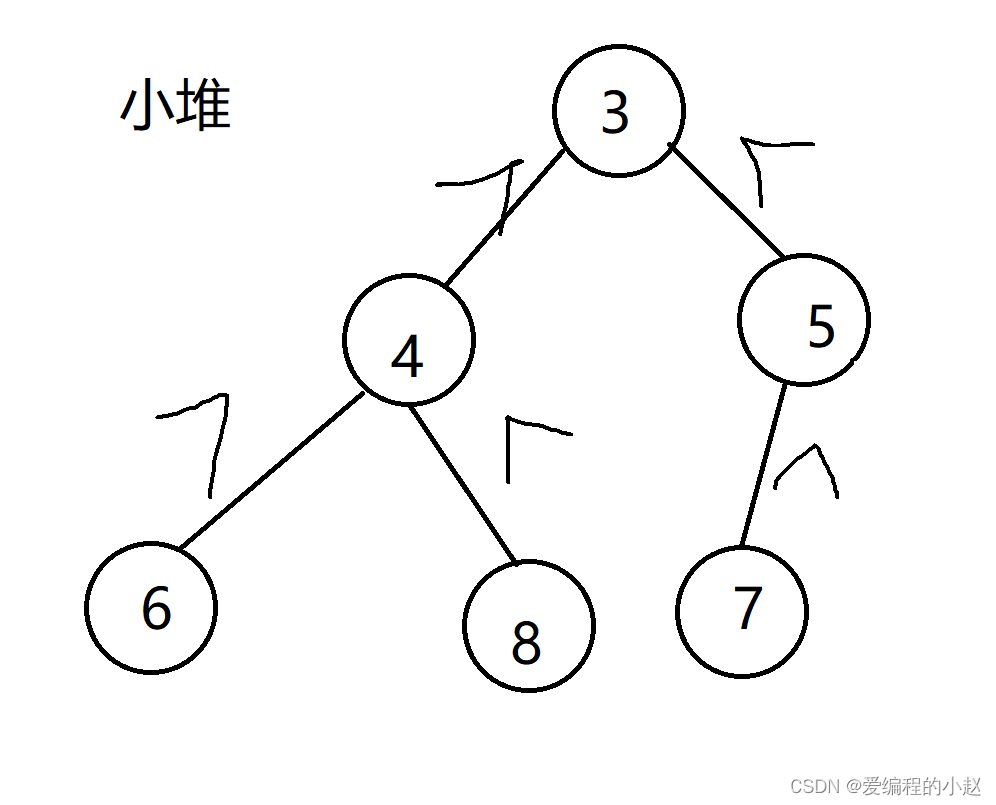
我们发现我们的任意一个父节点都比他的两个子节点小(或等于)这个时候这就是一个小堆。
虽然堆是完全二叉树,但其的存储方式却与二叉树不同,我们一般存储堆的方式是数组。而我们上面所画的叫逻辑结构,那怎么由数组的存储方式,转化为我们的逻辑结构呢?
我们在介绍二叉树的时候其实也曾简单的说过二叉树是有顺序的,是从上到下,从左向右的,按这个顺序我们就可以给我们的二叉树标序号。
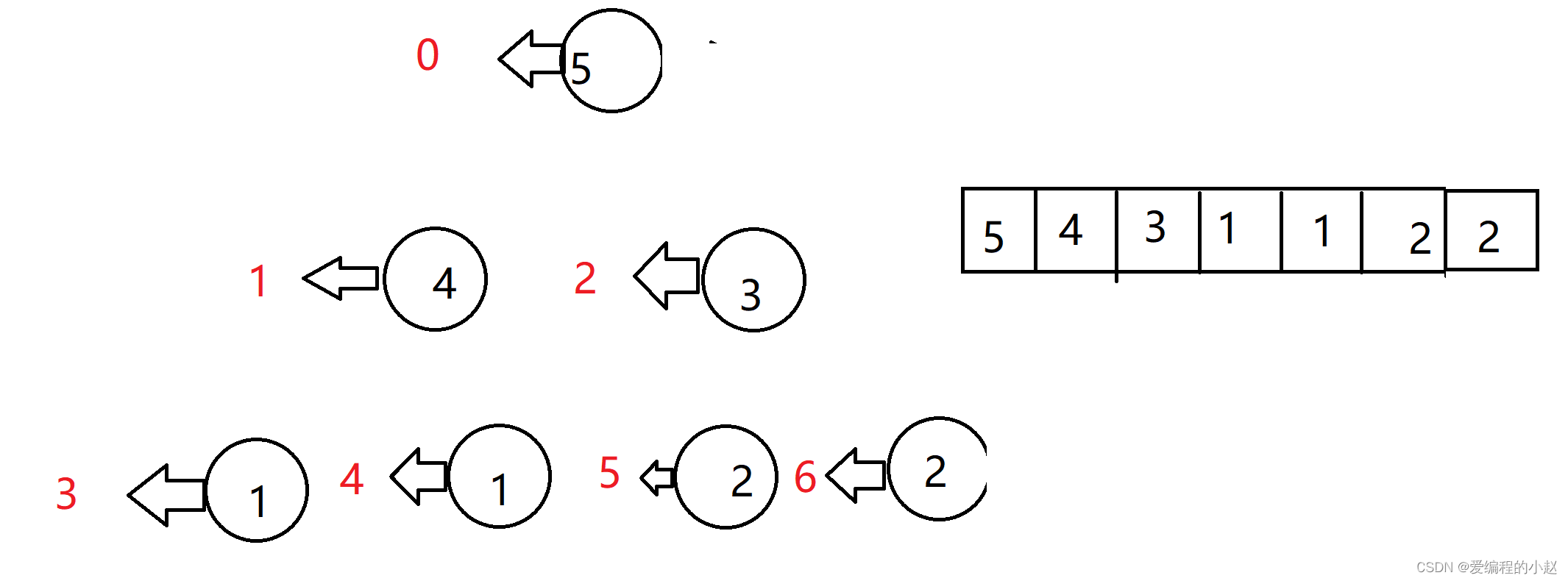
那么就可以我们的逻辑结构转化成我们的数组结构了,既然我们已经会将逻辑结构转化为数组结构了,那么将数组结构转化为逻辑结构也就没有这么难了,大家可以自己试试,如果实在实现不了也可以找小赵咨询哦。
🚈 2.堆的实现
🚝2.1堆向下调整算法
什么是向下调整算法呢?其实正如其名就是从上到下调整堆的意思。要想更深入了解这个东西就先来看这张图。
看这张图这是一个很明显的小堆对吧,那我这个时候要你改成一个大堆怎么办,这个时候的操作其实是2,3进行比较,然后拿出大的和1换这个就成大堆了。
可如果这个时候我给你的是个这样的堆你又该怎么办(要改成小堆)
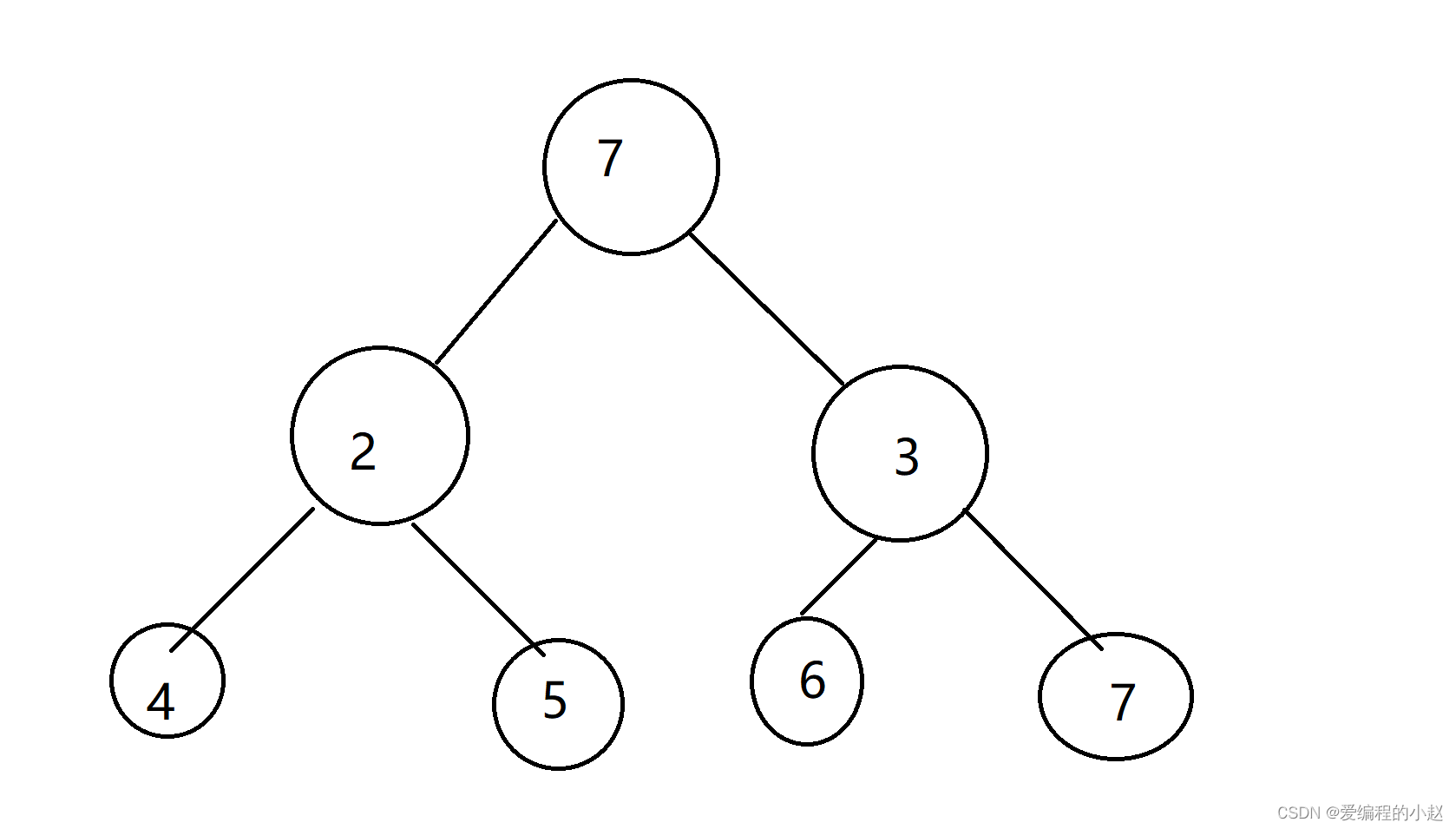
其实这个时候也是可以操作的,因为下面是有序的堆,我们只需要按照前面的顺序一步步来就可以完成了。只不过这个时候改成了选择两个子中的小的哪一个,因为我们要做得是小堆(这个时候之所以说他下面是有序的堆是因为盖住最上面的一个,下面的两个堆都是小堆,我们要改成的也是小堆。)
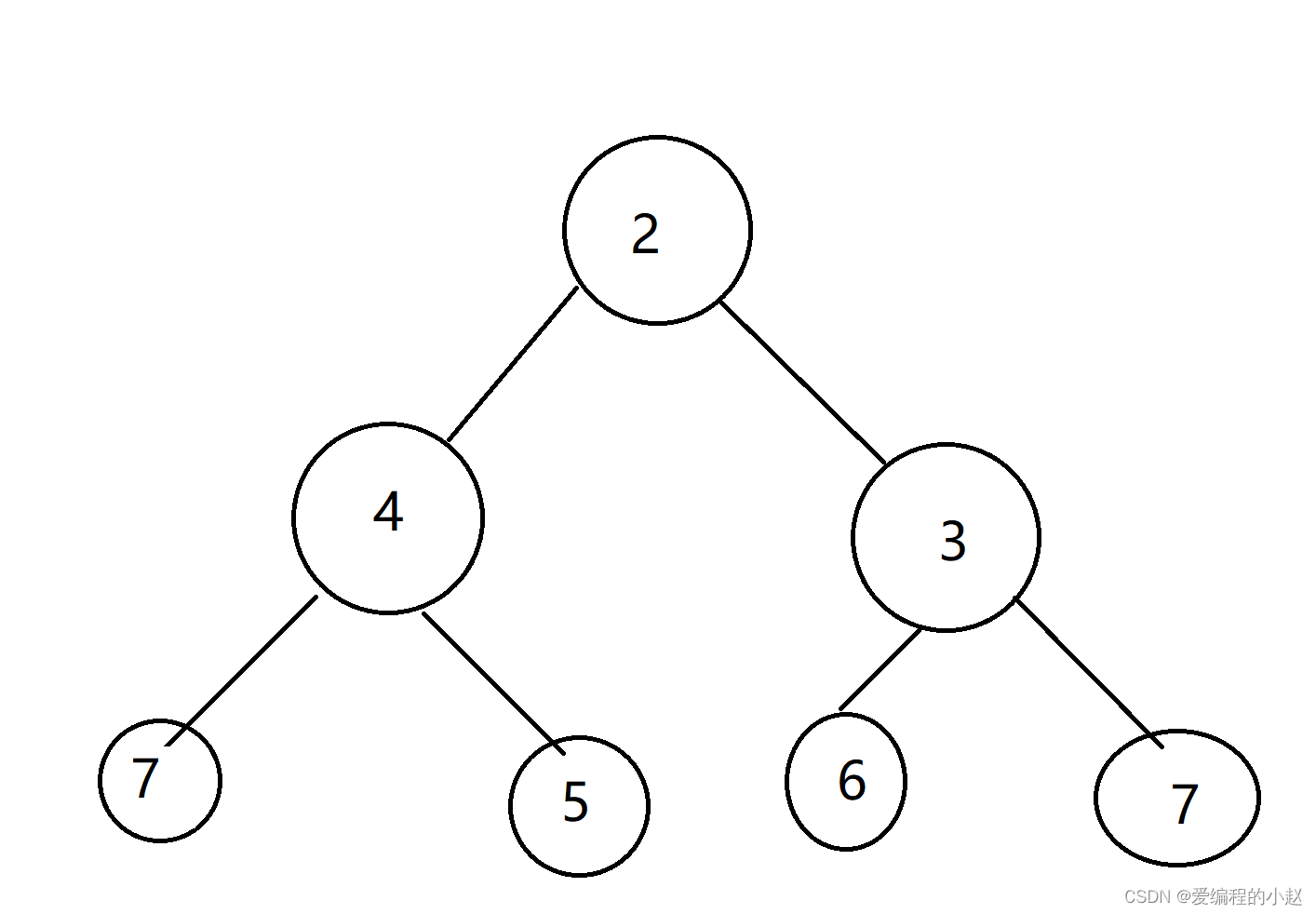
那如果是无序的呢? (改成小堆)

这个时候我们发现我们再想把这个改成小堆的难度就很大了。
🚝2.2堆的创建(堆向下调整算法)
那通过上面的实验我们发现,想通过一个位置来做上面的操作,并把整个堆都变成小(大)堆,必须下面就是一个小(大)堆。所以我们的向下调整其实也是从最下面的开始的,而且我们刚刚做的步骤其实就是向下调整。
那么再面对上面那个无序的堆我们也就有方法了。
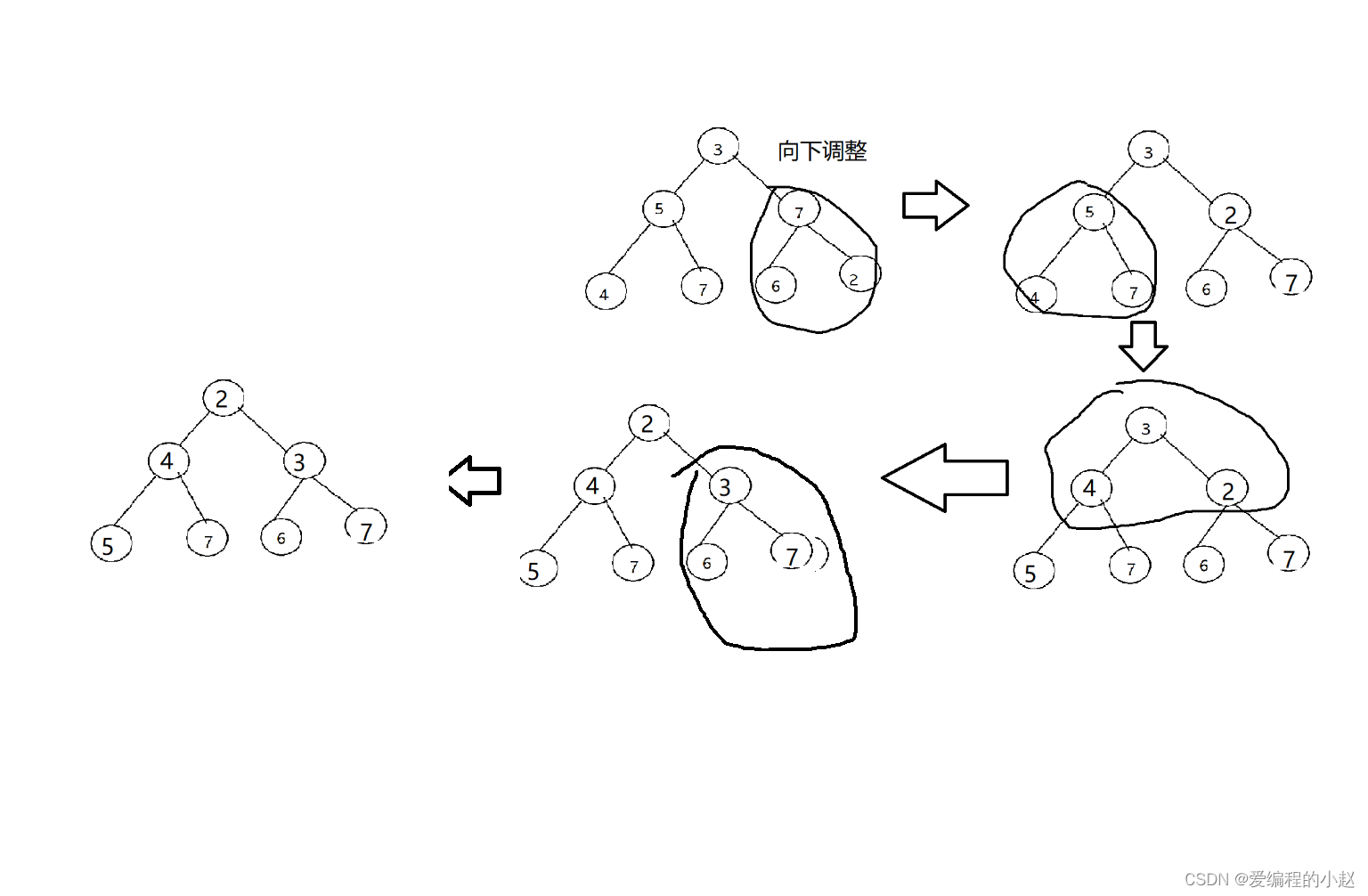
这个时候我们就可以做到将无序的堆转化成有序的堆了。 那么这个时候我们面对任何一个无序的数组,都可以通过这样的方式将他转化成堆.(至少在逻辑图上可以实现,代码实现下面说)
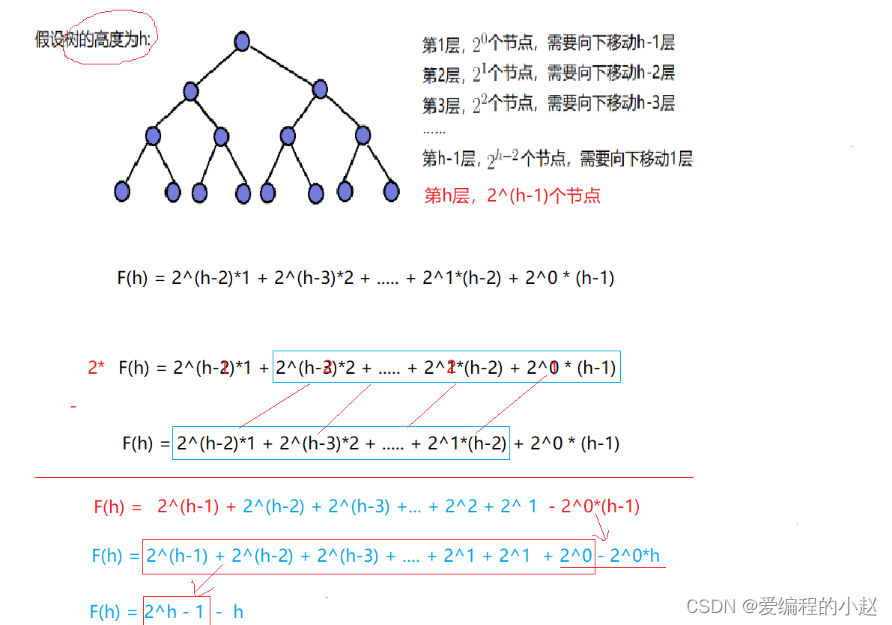
✈️2.2.1 向下调整建堆时间复杂度
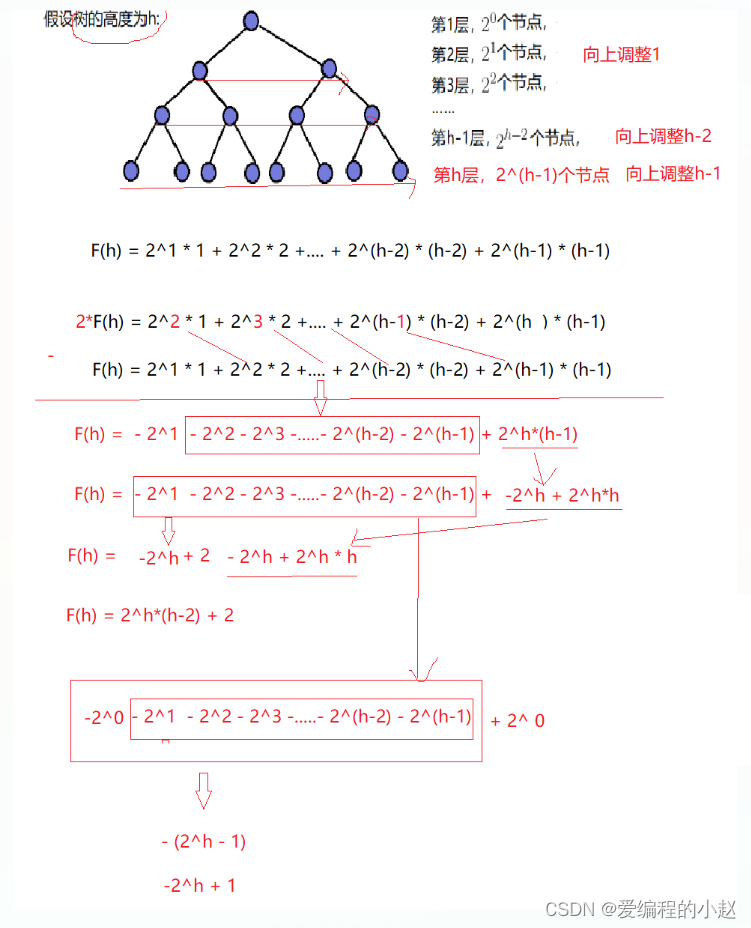
每层节点个数 × 最坏情况向下调整次数:
T(N) = 2^(h-2) × 1 + 2^(h-3) × 2 + … … + 2^1 × (h-2)+2^0*(h-1)
错位相减法
等号左右两边乘个 2 得到一个新公式,再用新公式减去旧的公式,具体见下图
🚝2.3堆向上调整算法
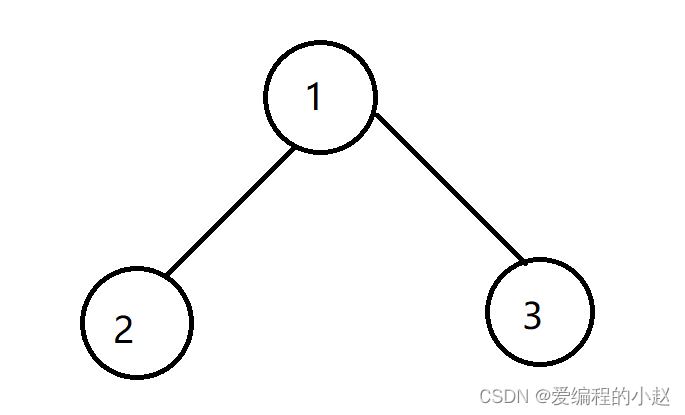
聊了向下调整算法,那么其实也有向上调整算法。
如这里我们如何把这个堆改成大堆
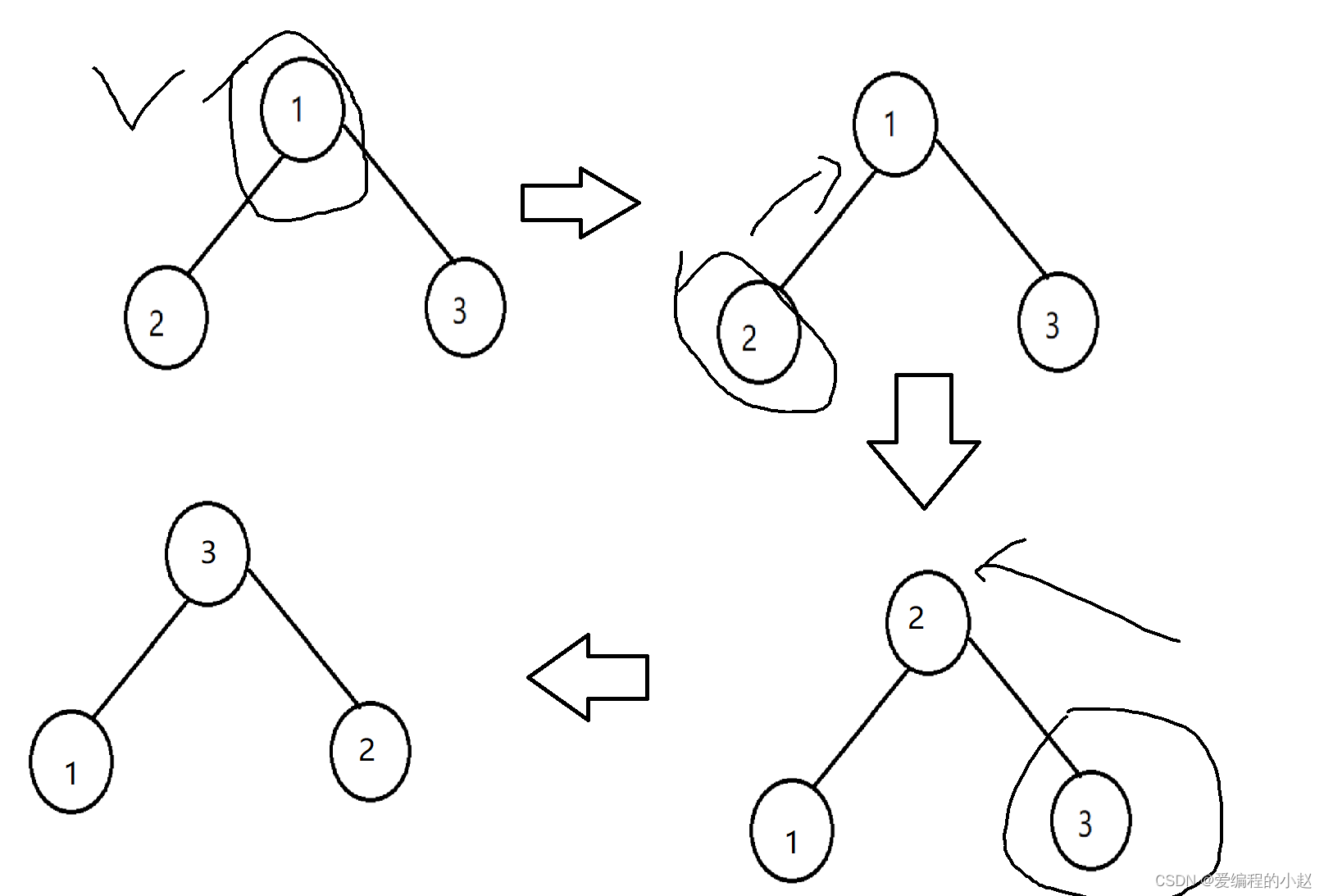
向上调整一般是怎么玩的呢,一般我们的向上调整法就是从下面往上调整,向这里要想调整到我们想要的样子就要三步
🚝2.4堆的创建(堆向上调整算法)
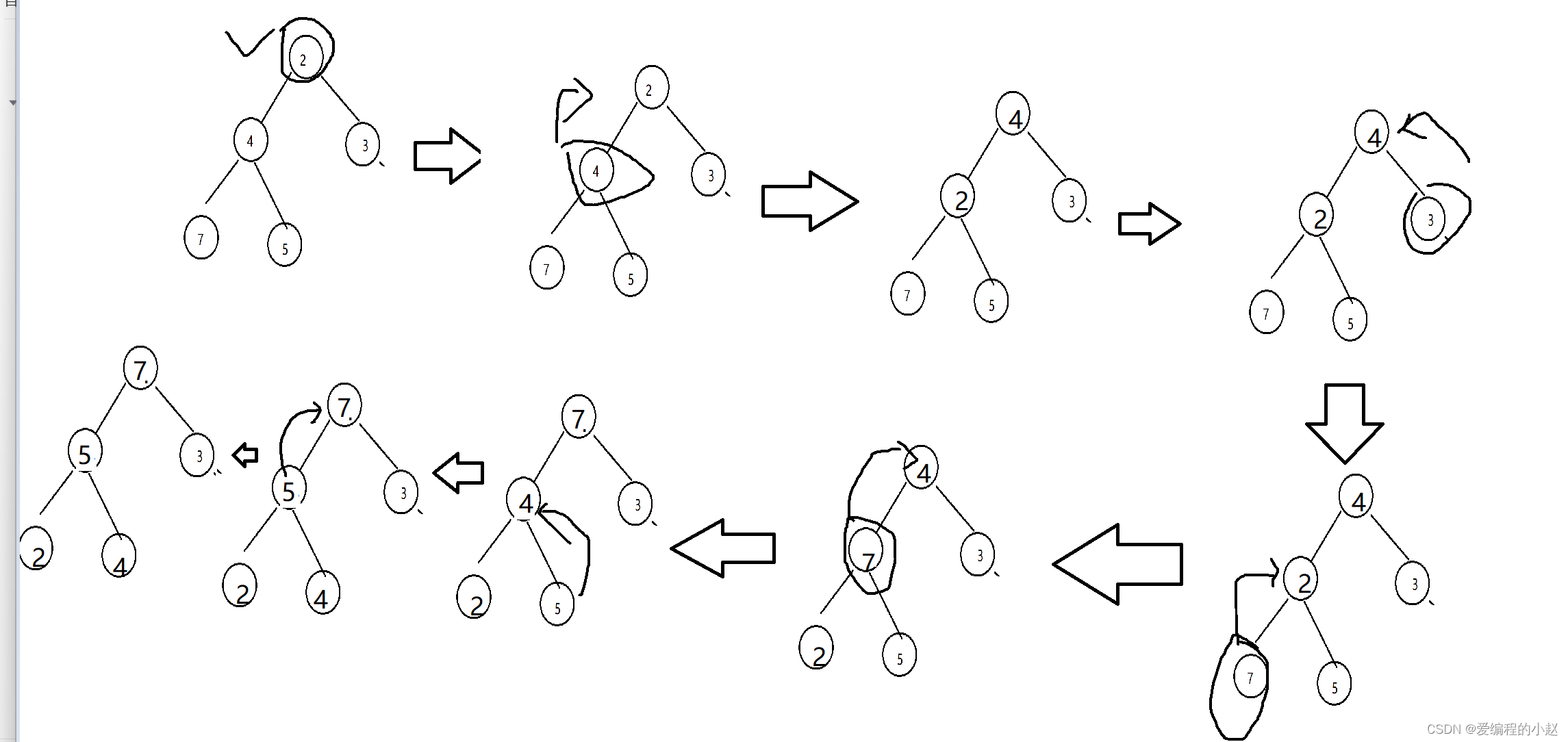
这里呢也和上面一样,向上调整的地方的上面必须是已经调整好的,所以我们一般用向上调整法去建堆的时候往往要从第一个开始建堆到最下面。
✈️2.4.1向上调整算法建堆的时间复杂度
T(N) = 2^1× 1 + 2^2× 2 + 2^3 ×3+ … … + 2^(h-3)× (h-3) + 2^(h-2) × (h-2)+ 2^(h-1) × (h-1)
综上:向下调整建堆要更优秀,效率更高
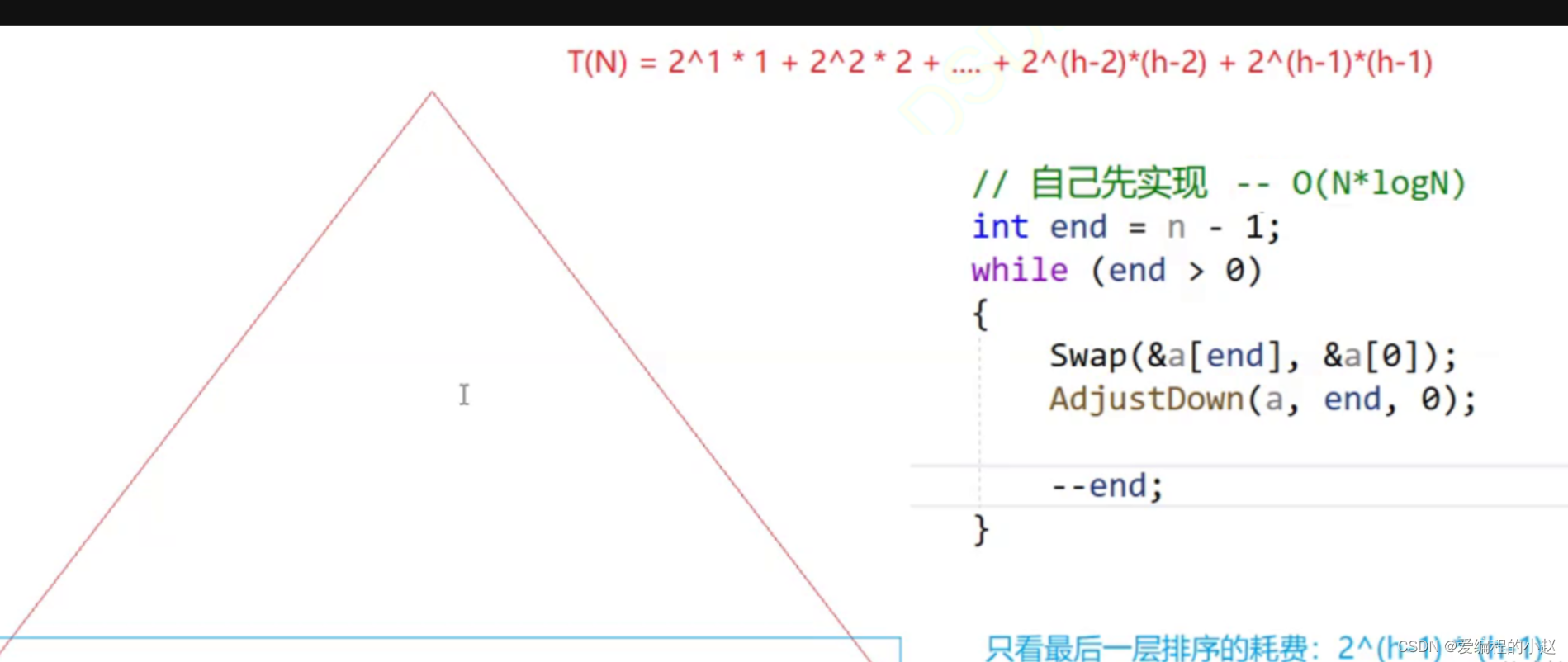
但总的来建堆的时间复杂度是O(N*logN)
🚝2.5堆的插入
像我们一般堆是用数组存储的,我们一般插入也是从数组后面插入,所以也就是在最后一个位置插入,而这个时候上面的堆都是有顺序的,我们可以用我们的向上调整算法来解决堆的插入。
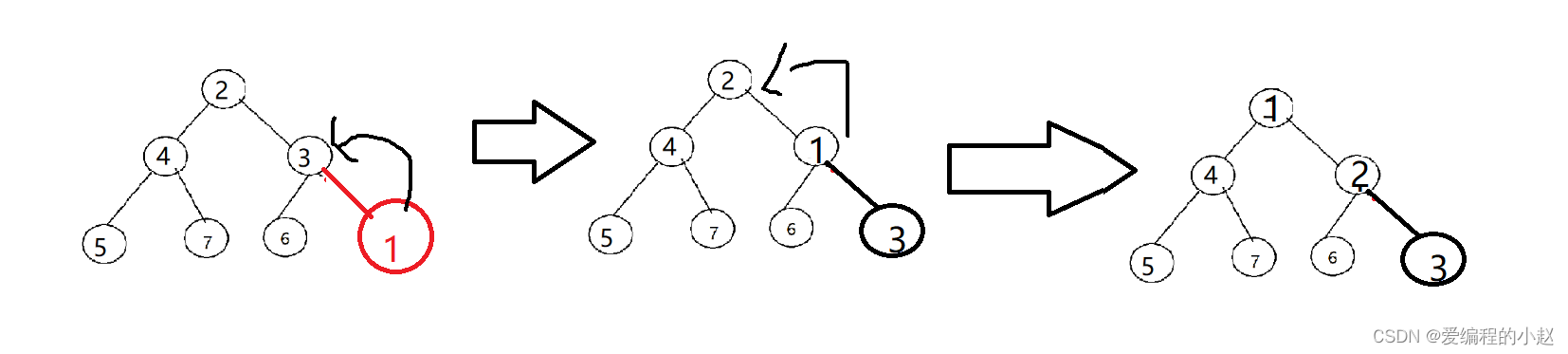
🚝2.6堆的删除
堆的删除,我们一般针对的是头元素的删除,这个时候我们采取的策略是将头元素和尾元素交换,然后让头元素,向下调整(因为下面的堆都已经是有顺序的)
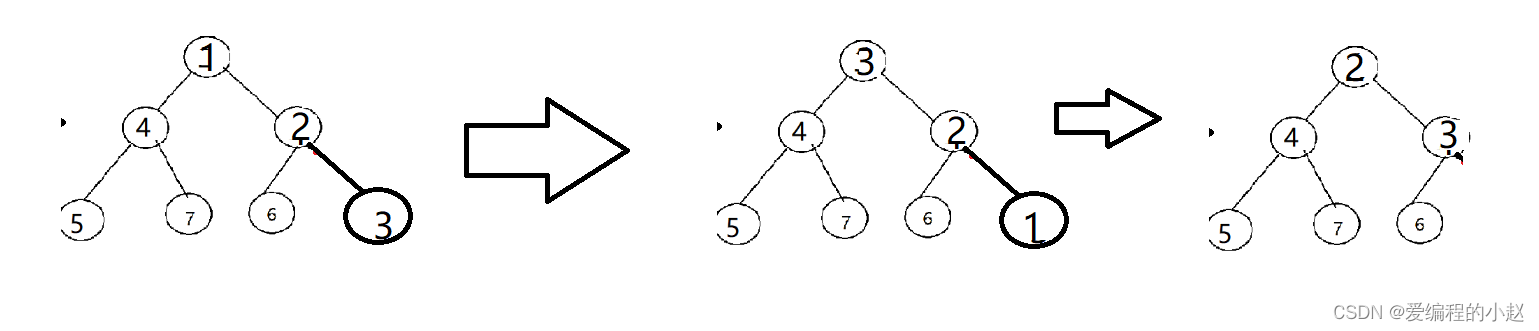
这样就可以完成头删了
🚝2.7建堆的代码实现
代码的实现我们的表示表示方式和前面的双亲节点是对应的(parent),然后子节点就是(child)
✈️2.7.1向下调整实现堆的建立
//小堆的建立
void Swap(int* a, int* b)//交换
{int tmp = *a;*a = *b;*b = tmp;
}
//小堆
void ADjustDown(int *a,int parent,int n)
{int child = parent * 2 + 1;//子节点和双亲节点的关系while (child < n){if (child + 1 < n && a[child + 1] < a[child])//选出两个孩子中较小的一个{child++;}if (a[child] < a[parent])//若子节点比双亲节点小{Swap(&a[child], &a[parent]);//交换接着向下进行parent = child;child = parent * 2 + 1;}else{break;}}
}
void Heap(int *a,int n)
{int i = (n - 1 - 1) / 2;//找到最后一个双亲节点while (i >= 0){ADjustDown(a, i, n);i--;}
}
int main()
{int a[10] = { 3,5,9,8,6,1,5,2,6,323 };Heap(a, 10);
}这里的主要方式就是我们前面的图所演示的,就是从最后一个双亲节点向下调整,然后调整过程中要小心不要让字节出了数组的范围,同时要记住子节点和双亲节点的关系。 这样可以方便我们的代码的实现。
✈️2.7.2向上调整实现堆的建立
//建立小堆
void Swap(int* a, int* b)//交换
{int tmp = *a;*a = *b;*b = tmp;
}
void ADjustUp(int*a,int child,int n)
{int parent = (child - 1) / 2;//双亲节点和子节点关系while (parent >= 0){if (a[child] < a[parent])//如果子节点比双亲节点小,那么交换,并且向上移动{Swap(&a[child], &a[parent]);child = parent;parent = (child - 1 - 1) / 2;}else{break;}}
}
void Heap(int* a, int n)
{int i = 0;while (i < n)//从最上面开始建堆{ADjustUp(a, i, n);i++;}
}
int main()
{int a[10] = { 3,5,9,87,6,12,7,11,13,1 };Heap(a, 10);
}这里也基本上就是我们上面逻辑的实现,向上建堆,就要保证上面都是已经建好的堆,那么就得从首元素开始依次向下,建堆。
🚈 3.完整的堆的代码的实现
要想实现完整的堆的实现就要实现以下几个函数
typedef int HPDataType;
typedef struct Heap
{HPDataType* _a;int _size;int _capacity;
}Heap;
// 堆的构建
void HeapCreate(Heap* hp, HPDataType* a, int n);
// 堆的销毁
void HeapDestory(Heap* hp);
// 堆的插入
void HeapPush(Heap* hp, HPDataType x);
// 堆的删除
void HeapPop(Heap* hp);
// 取堆顶的数据
HPDataType HeapTop(Heap* hp);
// 堆的数据个数
int HeapSize(Heap* hp);
// 堆的判空
int HeapEmpty(Heap* hp);这样我们的堆就可以像之前的链表顺序表等一样使用了。
🚝3.1堆的创建
和上面的代码逻辑基本一样。
这里我们主要采用的是向下排序建堆,因为向下排序的时间复杂度低。
void HeapCreate(Heap* hp, HPDataType* a, int n)
{hp->_a = (HPDataType*)malloc(sizeof(HPDataType) * n);if (hp->_a == NULL){perror("malloc failed");}memcpy(hp->_a, a, n);hp->_capacity = n;hp->_size = n;int i = (n - 1 - 1) / 2;while (i >= 0){ADjustDown(a, i, n);i--;}
}🚝3.2堆的销毁
void HeapDestory(Heap* hp)
{free(hp->_a);hp->_a = NULL;hp->_capacity = 0;hp->_size = 0;
}🚝3.3堆的插入
void HeapPush(Heap* hp, HPDataType x)
{if (hp->_size == hp->_capacity){int newcapacity = (hp->_size == 0 ? 4 : hp->_capacity * 2);//如果没有内存就给4,有就是原来内存的双倍HPDataType* tmp = (HPDataType*)realloc(hp->_a, sizeof(HPDataType) * newcapacity);if (tmp == NULL){perror("realloc failed");exit(-1);//退出程序,返回-1;}hp->_a = tmp;hp->_capacity = newcapacity;}hp->_a[hp->_size] = x;hp->_size++;ADjustUp(hp->_a, hp->_size - 1, hp->_size);//上面都是建好的堆,只需要向上调整即可
}🚝3.4堆的删除(头删)
void HeapPop(Heap* hp)
{if (!HeapEmpty(hp)){Swap(&(hp->_a[0]), &(hp->_a[hp->_size - 1]));//首尾交换ADjustDown(hp->_a, 0, hp->_size);//向下调整hp->_size--;//删除尾}else{return;}
}🚝3.5取堆顶元素的数据
HPDataType HeapTop(Heap* hp)
{if (!HeapEmpty(hp))//不是空集,返回首元素(即堆顶元素){return hp->_a[0];}else{return NULL;}
}🚝3.6 堆的数据个数
int HeapSize(Heap* hp)
{return hp->_size;
}🚝3.7堆的判空
int HeapEmpty(Heap* hp)
{return hp->_size == 0;//如果等式成立返回非零数,不成立返回零
}🚈 4.堆的应用堆排序
下面我们进入堆排序的学习,堆排序是我们的排序中比较优的一个排序,他具体是如何实现的呢?其实我们在前面的知识中已经发现了,就是如果我们建的是小堆,那小堆的堆顶元素一定是整个堆里面最小的,大堆的堆顶元素一定是最大的,那么如果我们想排一个顺序的方法就出来了,先把数组弄成一个大堆,再把第一个元素和最后一个元素交换,然后这个时候我们就排好了最大的一个,接着我们不管最后一个元素,对前面的n-1个元素再次建成大堆(其实只要进行向下调整就可以了因为下面的已经是大堆了),再重复上述操作。
那么我们就可以试着用代码实现了。
//建大堆
void ADjustDown(int* a, int parent, int n)
{int child = parent * 2 + 1;//子节点和双亲节点的关系while (child < n){if (child + 1 < n && a[child + 1] > a[child])//选出两个孩子中较大的一个{child++;}if (a[child] > a[parent])//若子节点比双亲节点大{Swap(&a[child], &a[parent]);//交换接着向下进行parent = child;child = parent * 2 + 1;}else{break;}}
}
void Heapsort(int* a, int n)
{int i = (n - 1 - 1) / 2;while (i >= 0){ADjustDown(a, i, n);i--;}//建堆while (n > 0){n--;Swap(&a[0], &a[n]);//交换首尾元素位置ADjustDown(a, 0, n);//下面都是建好的,只要向下调整就可以}
}
int main()
{int a[10] = { 3,5,9,87,6,12,7,11,13,1 };Heapsort(a,10);
}
✍5.结束语
好了小赵今天的分享就到这里了,如果大家有什么不明白的地方可以在小赵的下方留言哦,同时如果小赵的博客中有什么地方不对也希望得到大家的指点,谢谢各位家人们的支持。你们的支持是小赵创作的动力,加油。

如果觉得文章对你有帮助的话,还请点赞,关注,收藏支持小赵,如有不足还请指点,方便小赵及时改正,感谢大家支持!!!

相关文章:
数据结构(C):从初识堆到堆排序的实现
目录 🌞0.前言 🚈 1.堆的概念 🚈 2.堆的实现 🚝2.1堆向下调整算法 🚝2.2堆的创建(堆向下调整算法) ✈️2.2.1 向下调整建堆时间复杂度 🚝2.3堆向上调整算法 🚝2.…...
ChatGLM3-6B部署
ZhipuAI/chatglm3-6b 模型文件地址 chatglm3-6B-32k-int4 量化的模型地址 ChatGLM3 代码仓库 ChatGLM3 技术文档 cpolar http xxx 端口 /anaconda3/envs/chatglm2/lib/python3.8/site-packages/gradio$ networking.py 硬件环境 最低要求: 为…...

代码随想录35期Day54-JavaScript
Day54题目 ### LeetCode739每日温度 核心思想:今天主要是学会单调栈的使用.找到比元素更大的下一个元素,如果比栈顶元素小就入栈,否则就出栈顶元素,当前元素就是比栈顶元素大的"下一个更大的元素". /*** param {number[]} temperatures* return {number[]}*/ var …...

把自己的服务器添加到presearch节点
Presearch is a scam. Before, judging by the price of the token you should have been able to get between $150-$200 after 12-13 months of regular searches. "If you use this service for the next 11 years you will have earned $30!" Presearch大约需要…...

Open3D(C++) OTSU点云二值化
目录 一、算法原理二、代码实现三、结果展示1、原始点云2、二值化本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫与GPT。 一、算法原理 最大类间方差法(Between-class scatter method)是一种用于分割的方法,它通过计算图…...

浔川python社获得全网博主原力月度排名泸州地区第二名!
今日,浔川python社在查看全网博主原力月度排名泸州地区时,一看就震惊啦! 全网博主原力月度排名泸州地区排名榜单 全网博主原力月度排名泸州地区第二名为:浔川python社。 感谢粉丝们的支持!浔川python社还会继续努力&a…...
)
第二站:Java——集合框架的深邃海洋(续)
### Java——集合框架的深邃海洋(续) 在我们的Java集合框架探索之旅中,我们已经涉足了基本操作、高级特性,现在让我们深入探讨一些特定场景下的应用和进阶技巧,比如集合的分区操作、分组、并行流的性能考量࿰…...

linux系统下,mysql增加用户
首先,在linux进入mysql mysql -u root -p 然后查看当前用户: select user,host from user; 增加用户语句: CREATE USER 用户名host范围 IDENTIFIED BY 密码;...
)
Java数据结构与算法(最长回文子串中心扩散法)
前言 回文子串是练习数据结构和算法比较好的使用场景,可以同时练习到双指针、动态规划等一些列算法。 实现原理 中心扩散算法实现。这里定义最长回文子串长度的大小为maxLen,起点位置为0. 奇数个数为中心点和偶数个数为中心点分别计算回文长度大小。…...

基于Python网络招聘数据可视化分析系统的设计与实现
基于Python网络招聘数据可视化分析系统的设计与实现 Design and Implementation of Python-based Network Recruitment Data Visualization Analysis System 完整下载链接:基于Python网络招聘数据可视化分析系统的设计与实现 文章目录 基于Python网络招聘数据可视化分析系统的…...

【Linux】Linux工具——gcc/g++
1.使用vim更改信用名单——sudo 我们这里来补充sudo的相关知识——添加信任白名单用户 使用sudo就必须将使用sudo的那个账号添加到信用名单里,而且啊,只有超级管理员才可以添加 信用名单在/etc/sudoers里 我们发现它的权限只是可读啊,所以…...
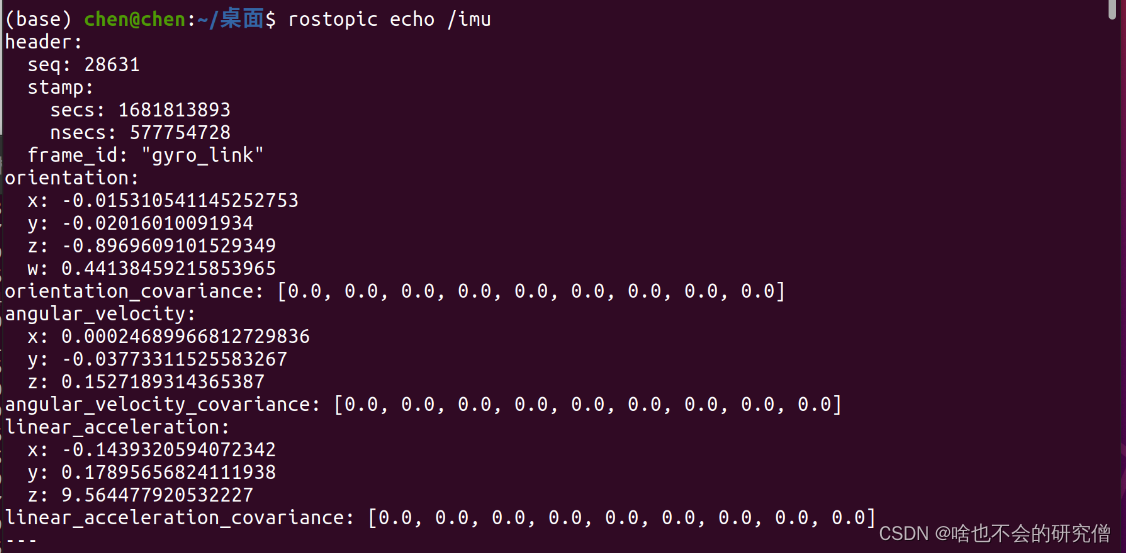
【惯性传感器imu】—— WHEELTEC的惯导模块的imu的驱动安装配置和运行
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、IMU驱动安装1. 安装依赖2. 源码的下载3. 编译源码(1) 配置固定串口设备(2) 修改luanch文件(3) 编译 二、启动IMU1. 运行imu2. 查看imu数据 总结 前言 WHEE…...

Linux提权一
#信息收集 当前主机的操作系统 hostnamectl cat /etc/*-release lsb_release -a cat /etc/lsb-release # Debain cat /etc/redhat-release # Redhat cat /etc/centos-release # Centos cat /etc/os-release # Ubuntu cat /etc/issue 当前主机的内核版本 hostnamectl uname -a …...

Vue.js中如何实现以列表首列为表头
前言 一般情况table列表的展示,列头都在第一横行,此方法用于列头在第一列的情况。 效果图 核心代码 <template><div><table class"data-table"><tr v-for"(column, columnIndex) in columns" :key"col…...

如果孙宇晨和贾跃亭能够握手,或许将会上演新的戏码
就在贾跃亭宣布将进行个人IP的商业化不久,便迎来了回应,并且这一次给予贾跃亭回应的,同样是一个颇具争议性的人物——孙宇晨。 根据孙宇晨最新发布的视频显示,他愿意投资贾跃亭「做一个新的个人IP化的公司」,并且将会…...
渲染100为什么是高性价比网渲平台?渲染100邀请码1a12
市面上主流的网渲平台有很多,如渲染100、瑞云、炫云、渲云等,这些平台各有特色和优势,也都声称自己性价比高,以渲染100为例,我们来介绍下它的优势有哪些。 1、渲染100对新用户很友好,注册填邀请码1a12有3…...
Jenkins流水线pipeline--基于上一章的工作流程
1流水线部署 1.流水线文本名Jenkinsfile,将流水线放入gitlab远程仓库代码里面 2pipeline脚本 Jenkinsfile文件内容 pipeline {agent anyenvironment {key"value"}stages {stage("拉取git仓库代码") {steps {deleteDir()checkout scmGit(branches: [[nam…...

比较Rust和Haskel
在比较Rust和Haskell时,我们可以从多个维度来分析它们各自的优势。以下是Rust相对于Haskell的优势,以及Haskell相对于Rust的优势: Rust比Haskell强的方面: 内存安全与并发性: Rust通过独特的所有权系统和借用检查器在…...

RedisTemplate的Long类型使用increment自增报错
问题描述 代码如下 Resourceprivate RedisTemplate<String,String > redisTemplate;redisTemplate.opsForValue().set("testKey", 0L); redisTemplate.opsForValue().increment("testKey");工作里用Long类型存储评论数,在使用increment自…...

【代码随想录训练营】【Day 36】【贪心-3】| Leetcode 1005, 134, 135
【代码随想录训练营】【Day 36】【贪心-3】| Leetcode 1005, 134, 135 需强化知识点 题目 1005. K 次取反后最大化的数组和 贪心:翻转绝对值最小的数思路:将数组按绝对值降序排序后,从左向右遍历数组,如果遇到小于0的数并且还…...

AI驱动全栈开发:Cursor集成模板与高效协作实践
1. 项目概述:当AI代码助手遇上全栈开发最近在GitHub上看到一个挺有意思的项目,叫“Cursor-FullStack-AI-App”。光看名字,你大概能猜到它和Cursor这个AI编程工具,以及全栈应用开发有关。作为一个在前后端都摸爬滚打过多年的开发者…...

LLVM开发实战指南:从入门到精通编译器与程序分析
1. 项目概述:为什么你需要一份LLVM指南?如果你是一名C开发者,或者对编译器、程序分析、代码优化这些底层技术感兴趣,那么“LLVM”这个名字对你来说一定不陌生。它早已不是象牙塔里的学术玩具,而是驱动着从iOS、macOS到…...

多智能体强化学习环境PettingZoo:从核心概念到工程实践
1. 项目概述:从零理解PettingZoo如果你正在寻找一个能让你快速上手、高效构建多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)实验环境的工具,那么Farama Foundation旗下的PettingZoo项目,绝对是你绕不开…...
)
多语种出海必备,ElevenLabs菲律宾文语音质量实测对比:Wavenet vs. Instant Voice vs. Custom Model(附MOS评分表)
更多请点击: https://intelliparadigm.com 第一章:多语种出海语音技术演进与菲律宾语本地化挑战 随着全球数字服务加速出海,语音交互系统正从单语种向多语种、低资源语言深度拓展。菲律宾语(Filipino/Tagalog)作为东…...
架构与实现)
基于RAG与向量数据库的智能信息管理系统(IIMS)架构与实现
1. 项目概述:当AI成为你的“第二大脑”最近在折腾一个挺有意思的项目,叫“IIMS-By-AI”。乍一看这个标题,可能有点摸不着头脑,但拆解一下就能明白它的野心:IntelligentInformationManagementSystem, By AI。…...
滤波器,收敛稳如老狗)
别再一个点一个点更新了!用Python手把手实现分块LMS(BLMS)滤波器,收敛稳如老狗
用Python实现分块LMS滤波器:告别收敛震荡的工程实践指南 在实时信号处理领域,自适应滤波器的稳定性往往比理论性能更重要。想象一下这样的场景:你正在开发一套会议系统降噪算法,每次麦克风捕捉到新的声音样本,滤波器系…...

子高斯随机变量与深度学习异常检测原理
1. 子高斯随机变量基础解析子高斯随机变量是概率论中一类具有特殊尾部性质的分布。简单来说,一个随机变量X如果满足存在常数σ>0,使得对于所有λ∈R都有E[exp(λX)] ≤ exp(λσ/2),那么我们就称X是σ-子高斯的。这类分布的关键特征是它们…...

湿版摄影风格失效的5个致命误区,第4个连Midjourney官方文档都未披露——基于217组AB测试的权威归因报告
更多请点击: https://intelliparadigm.com 第一章:湿版摄影风格失效的5个致命误区,第4个连Midjourney官方文档都未披露——基于217组AB测试的权威归因报告 为何“wet plate collodion”提示词突然失灵? 在 Midjourney v6.1 及 N…...

开源项目仪表盘开发指南:基于React、Next.js与GitHub API的实践
1. 项目概述:一个为开源项目量身定制的现代化仪表盘 最近在折腾一个开源项目,想把它的状态、数据和一些关键指标更直观地展示出来,于是找到了 tugcantopaloglu/openclaw-dashboard 这个仓库。简单来说,这是一个专门为开源项目设…...

基于CircuitPython与MagTag的电子墨水屏俳句显示器项目实践
1. 项目概述与核心价值如果你对嵌入式开发感兴趣,但又觉得传统的C/C开发环境配置繁琐、学习曲线陡峭,那么CircuitPython绝对是一个值得尝试的入口。它本质上是一个运行在微控制器上的Python 3解释器,由Adafruit主导开发,目标就是让…...