把自己的服务器添加到presearch节点
Presearch is a scam. Before, judging by the price of the token you should have been able to get between $150-$200 after 12-13 months of regular searches.
"If you use this service for the next 11 years you will have earned $30!"
Presearch大约需要400多MB内存。1核1G内存的VPS还是不要跑presearch-node
is a decentralized search engine that rewards users with cryptocurrency for running search nodes. Here's a step-by-step guide to adding your computer as a Presearch node:
### 1. **Create a Presearch Account**
- Visit the [Presearch website](https://www.presearch.io).
- Sign up for an account if you don't already have one.
### 2. **Set Up a VPS or Dedicated Server**
- Presearch nodes typically run on Linux-based servers. You can use a Virtual Private Server (VPS) or a dedicated server.
- Some popular VPS providers include DigitalOcean, AWS, Google Cloud, and Vultr.
- Choose a VPS plan that suits your needs (minimum requirements are usually 1 CPU, 1 GB RAM, and 10 GB disk space).
### 3. **Install Docker**
- Presearch nodes run within a Docker container. Install Docker on your server:
```bash
sudo apt update
sudo apt install apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt update
sudo apt install docker-ce
```
### 4. **Pull the Presearch Node Docker Image**
- Use the following command to pull the latest Presearch node Docker image:
```bash
sudo docker pull presearch/node
```
/usr/bin/docker-current: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?.
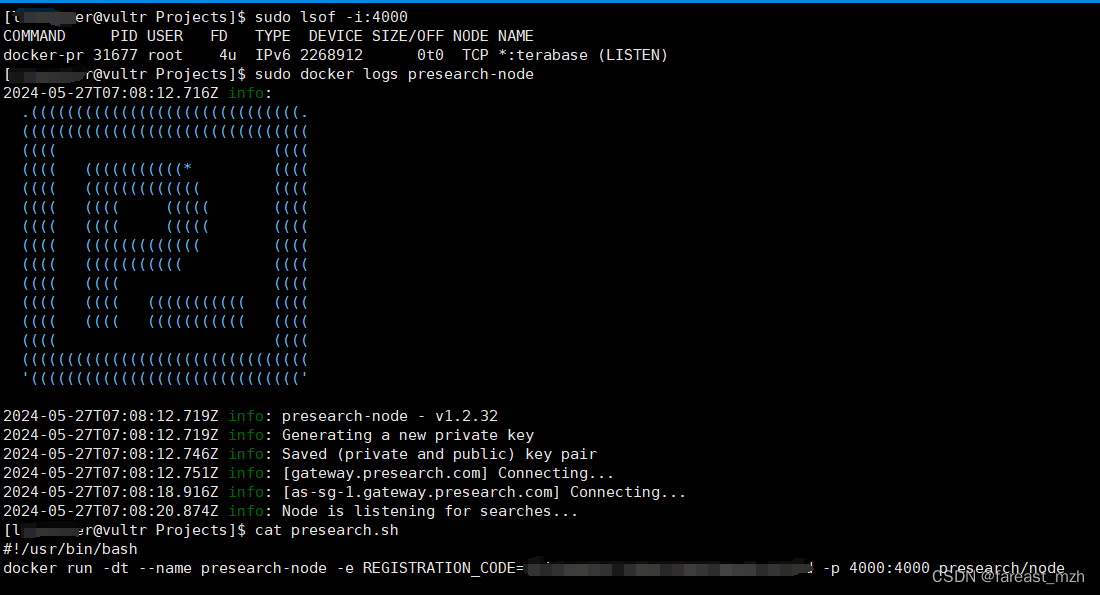
sudo service docker start### 5. **Run the Presearch Node**
- Start the Presearch node container with your registration code. Replace `YOUR-REGISTRATION-CODE` with the code you get from your Presearch account:
```bash
sudo docker run -dt --name presearch-node -e REGISTRATION_CODE=YOUR-REGISTRATION-CODE -p 4000:4000 presearch/node
```
Linux/Mac/PREberry/Windows Powershell
#!/usr/bin/bashYOUR_REGISTRATION_CODE_HERE=自己的注册码
HOSTPORT=4000
CONTAINERPORT=4000docker stop presearch-node
docker rm presearch-node
docker stop presearch-auto-updater
docker rm presearch-auto-updater
docker run -d --name presearch-auto-updater --restart=unless-stopped -v /var/run/docker.sock:/var/run/docker.sock presearch/auto-updater --cleanup --interval 900 presearch-auto-updater presearch-node
docker pull presearch/node
# docker run -dt --name presearch-node --restart=unless-stopped -v presearch-node-storage:/app/node -e REGISTRATION_CODE=$YOUR_REGISTRATION_CODE_HERE presearch/node
docker run -dt --name presearch-node --restart=unless-stopped -p 0.0.0.0:$HOSTPORT:$CONTAINERPORT -v presearch-node-storage:/app/node -e REGISTRATION_CODE=$YOUR_REGISTRATION_CODE_HERE presearch/node
docker logs -f presearch-node
Windows cmd
docker stop presearch-node & docker rm presearch-node & docker stop presearch-auto-updater & docker rm presearch-auto-updater & docker run -d --name presearch-auto-updater --restart=unless-stopped -v /var/run/docker.sock:/var/run/docker.sock presearch/auto-updater --cleanup --interval 900 presearch-auto-updater presearch-node & docker pull presearch/node & docker run -dt --name presearch-node --restart=unless-stopped -v presearch-node-storage:/app/node -e REGISTRATION_CODE=$YOUR_REGISTRATION_CODE_HERE presearch/node & docker logs -f presearch-node### 6. **Verify Node Status**
- After a few minutes, check the status of your node on your Presearch dashboard to ensure it’s running properly.
- You can access your node’s web interface by navigating to `http://YOUR-SERVER-IP:4000` in your web browser.
### 7. **Maintain and Monitor Your Node**
- Regularly check the node's status and logs:
```bash
sudo docker logs presearch-node
```
- Ensure your server is running smoothly and has enough resources.
### Additional Tips
- **Security**: Secure your VPS with a strong password and consider setting up a firewall.
- **Backups**: Regularly back up your node’s data.
- **Updates**: Keep Docker and your node software up to date to benefit from the latest features and security fixes.
Following these steps will help you successfully add your computer as a Presearch node and start earning rewards.
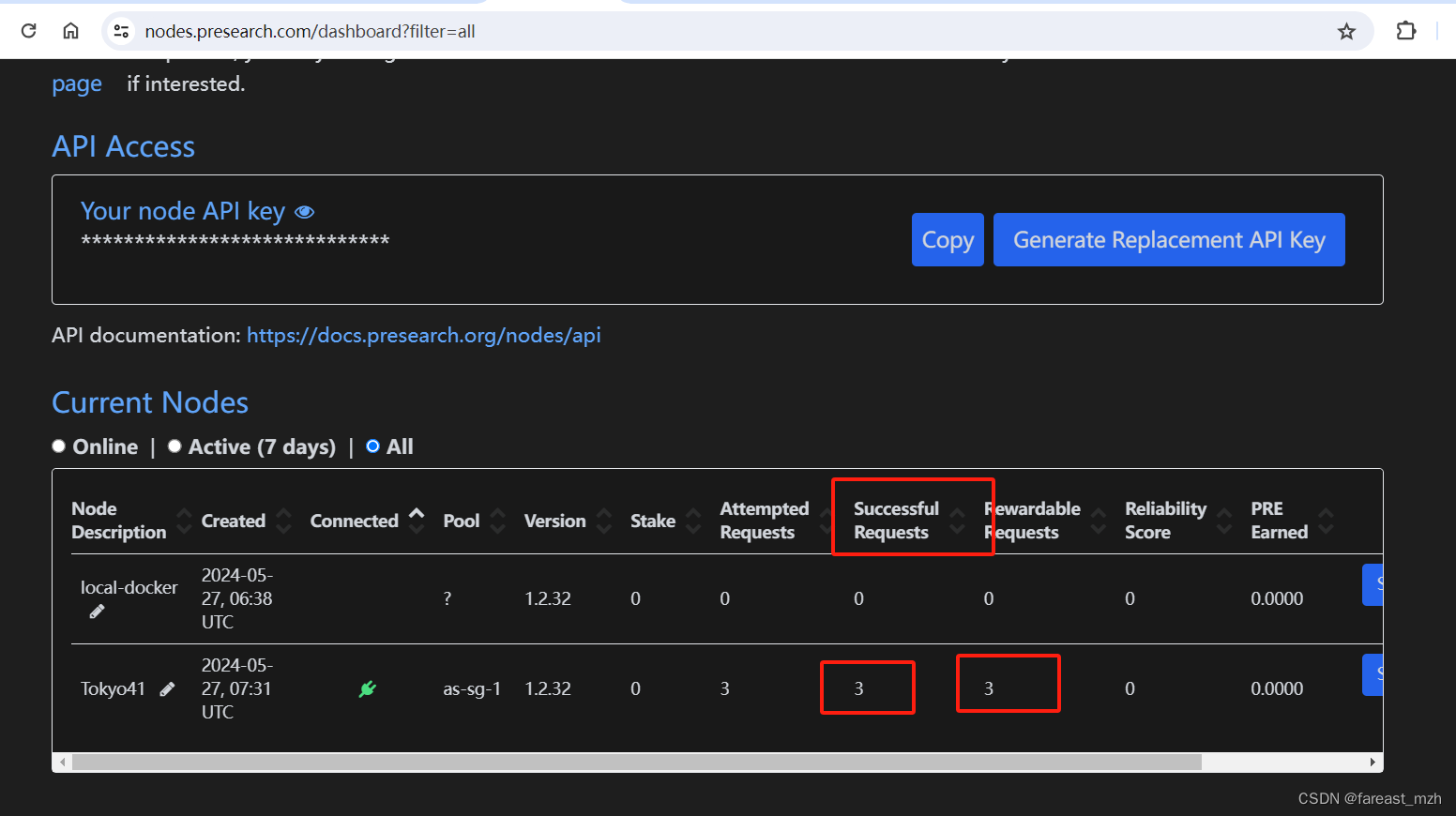
node stats
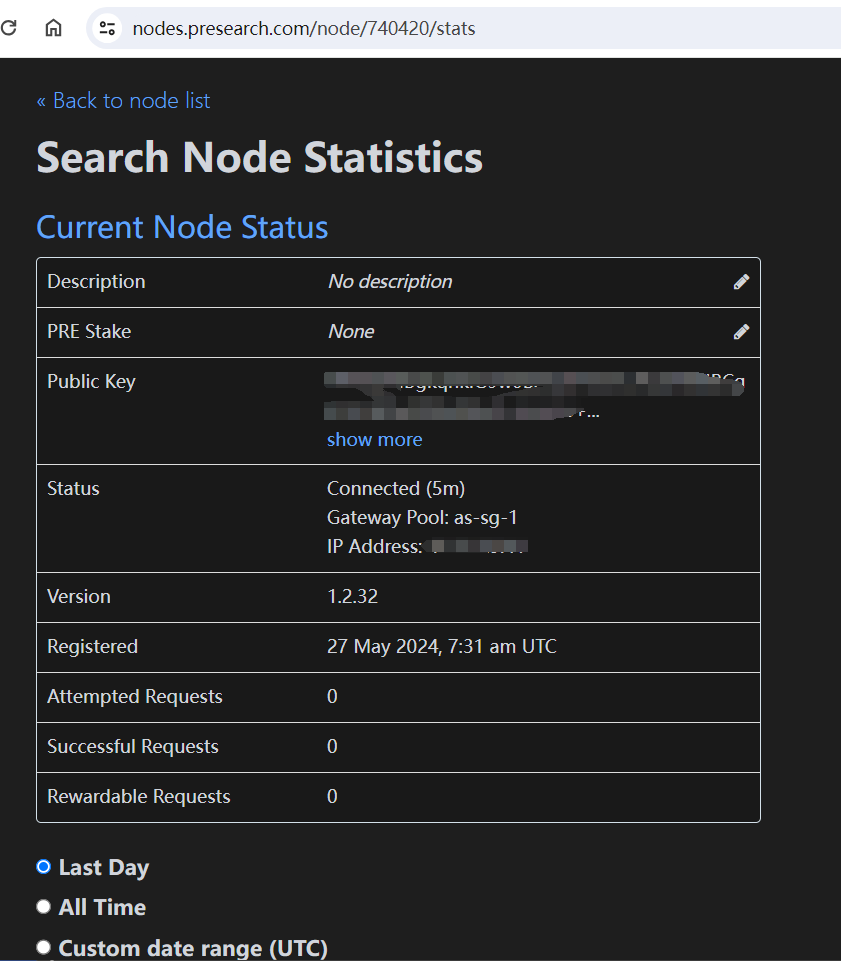
presearch dashboard
node status api
If you prefer not to use Docker due to its resource consumption, you can still run a Presearch node directly on your server. Here’s how you can set it up without Docker:
### 1. **Create a Presearch Account**
- Visit the [Presearch website](https://www.presearch.io).
- Sign up for an account if you don't already have one.
### 2. **Set Up a VPS or Dedicated Server**
- Presearch nodes typically run on Linux-based servers. You can use a Virtual Private Server (VPS) or a dedicated server.
- Some popular VPS providers include DigitalOcean, AWS, Google Cloud, and Vultr.
- Choose a VPS plan that suits your needs (minimum requirements are usually 1 CPU, 1 GB RAM, and 10 GB disk space).
### 3. **Install Required Dependencies**
- Install necessary dependencies for running the Presearch node:
```bash
sudo apt update
sudo apt install -y curl git nodejs npm
```
### 4. **Clone the Presearch Node Repository**
- Clone the Presearch node repository from GitHub:
HTTPS_PROXY
127.0.0.1:1080
```bash
# git clone https://github.com/PresearchOfficial/presearch-node.git
git clone https://github.com/PresearchOfficial/presearch-packages

cd presearch-packages
```
### 5. **Install Node.js Dependencies**
- Install the Node.js dependencies required for the Presearch node:
```bash
npm install
```
### 6. **Configure Your Node**
- Create a `.env` file to store your registration code:
```bash
echo "REGISTRATION_CODE=YOUR-REGISTRATION-CODE" > .env
```
- Replace `YOUR-REGISTRATION-CODE` with the code you get from your Presearch account.
### 7. **Run the Presearch Node**
- Start the Presearch node:
```bash
cd server
npm start
```
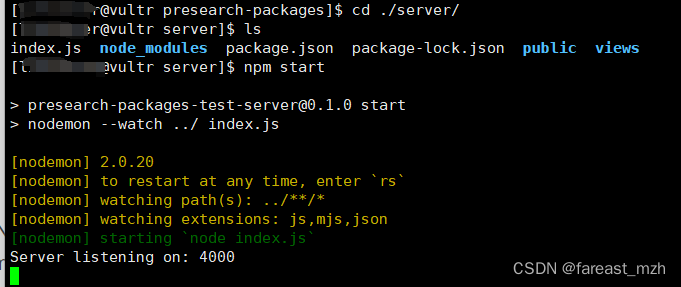
这个代码不对,还是参考上面的docker
$ cat ./firewall.sh
#!/usr/bin/env bashif [ "$#" -ne 1 ]; thenecho "Usage: $0 PORT"exit 22 # Invalid Arguments
fiPORT=$1
default_zone=$(firewall-cmd --get-default-zone)
firewall-cmd --permanent --zone=${default_zone} --add-port=${PORT}/tcp
firewall-cmd --permanent --zone=${default_zone} --add-port=${PORT}/udp
firewall-cmd --reloadfirewall-cmd --state
firewall-cmd --list-all --zone=${default_zone}sudo ./firewall.sh 4000
### 8. **Verify Node Status**
- After a few minutes, check the status of your node on your Presearch dashboard to ensure it’s running properly.
### 9. **Set Up as a Service (Optional)**
- To ensure your node starts automatically and runs in the background, you can set it up as a systemd service:
```bash
sudo nano /etc/systemd/system/presearch-node.service
```
- Add the following content to the file:
```ini
[Unit]
Description=Presearch Node
After=network.target
[Service]
User=root
WorkingDirectory=/path/to/presearch-node
ExecStart=/usr/bin/npm start
Restart=always
[Install]
WantedBy=multi-user.target
```
- Replace `/path/to/presearch-node` with the actual path to the cloned repository.
- Enable and start the service:
```bash
sudo systemctl enable presearch-node
sudo systemctl start presearch-node
```
### 10. **Maintain and Monitor Your Node**
- Regularly check the status and logs of your node:
```bash
sudo systemctl status presearch-node
sudo journalctl -u presearch-node -f
```
- Ensure your server is running smoothly and has enough resources.
Following these steps will help you run a Presearch node without using Docker, which should be lighter on system resources.
Run a Node
Do you support decentralization and an open internet that isn’t dominated by a handful of Big Tech companies?
Now you can be part of the solution by operating a Presearch Node and helping to power the Presearch decentralized search engine.
Presearch Nodes are used to process user search requests, and node operators earn Presearch PRE tokens for joining and supporting the network.
It’s easy to get started!
- Install Docker on your computer or virtual server, or use a turn-key solution like ThreeFold.io, that already has Docker installed
- Register your node and get a registration code at https://nodes.presearch.com/dashboard
- Run the node start commands
Server requirements
Presearch nodes with fast internet and low latency connection to the Presearch Gateway are currently prioritized. You do not need much disk space, much memory, or much CPU current to run a node, and running a more powerful server does not currently increase node rewards. We recommend running many lightweight nodes to optimize your reward earnings relative to your server costs.
Node operator rewards
Rewards are paid to all node operators who stake at least 4,000 PRE to their node.
Each of your staked nodes will qualify for the base reward paid to incentivize participation in the network.
Those who stake more than 4,000 PRE to their node are eligible to earn additional rewards.
For complete information on how staking works, please visit https://nodes.presearch.com/rewards
Risks & Cautions
Running a Presearch node is likely not a concern for most node operators, but there are some things we think you should be aware of:
- If you are running a node locally (and not on an outside server), queries routed through your node to external sources (other search engines, databases & APIs) could be associated with your IP address. If you are trying to minimize your personal footprint with Google and other big tech companies for instance, using Presearch as a searcher is what you want, but running a node is probably not.
- This is particularly true if you are in a repressive country, such as Iran, North Korea or China, where the powers that be can use any excuse to attack you.
- The IP address of your node is used to identify your node within the system and will be logged. Again, if you are trying to minimize your personal external footprint, you would be best to either run a node on an outside server you are comfortable exposing, or do not run a node at all.
- Depending on the country in which you are located, node rewards may need to be declared as income for tax purposes. That is up to you to track and report, and we will not be submitting or providing any documentation aside from the logs of your rewards.
- This software is currently not open source and you are relying on our assurances that nothing malicious is happening underneath the hood. We promise that this is true, but the ability to verify it for yourself would currently be limited to packet sniffers and any other means that you have available to you. It is our intention to open source this software in the future, but we’re not there yet.
- This is beta software, and it is possible that there are bugs that we are not yet aware of. We push updates frequently to resolve anything we discover, but as we cannot control which versions of the node software are run on your machine, we can’t ensure that you will always have the latest version.
- Overall, it’s best to assume that any risk on your part is yours alone, and while we will do our best to ensure that only good things come from running a node, there are no guarantees that this will be the case, only best efforts.
Thanks for your interest in running a node and for your support!

相关文章:
把自己的服务器添加到presearch节点
Presearch is a scam. Before, judging by the price of the token you should have been able to get between $150-$200 after 12-13 months of regular searches. "If you use this service for the next 11 years you will have earned $30!" Presearch大约需要…...

Open3D(C++) OTSU点云二值化
目录 一、算法原理二、代码实现三、结果展示1、原始点云2、二值化本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫与GPT。 一、算法原理 最大类间方差法(Between-class scatter method)是一种用于分割的方法,它通过计算图…...

浔川python社获得全网博主原力月度排名泸州地区第二名!
今日,浔川python社在查看全网博主原力月度排名泸州地区时,一看就震惊啦! 全网博主原力月度排名泸州地区排名榜单 全网博主原力月度排名泸州地区第二名为:浔川python社。 感谢粉丝们的支持!浔川python社还会继续努力&a…...
)
第二站:Java——集合框架的深邃海洋(续)
### Java——集合框架的深邃海洋(续) 在我们的Java集合框架探索之旅中,我们已经涉足了基本操作、高级特性,现在让我们深入探讨一些特定场景下的应用和进阶技巧,比如集合的分区操作、分组、并行流的性能考量࿰…...

linux系统下,mysql增加用户
首先,在linux进入mysql mysql -u root -p 然后查看当前用户: select user,host from user; 增加用户语句: CREATE USER 用户名host范围 IDENTIFIED BY 密码;...
)
Java数据结构与算法(最长回文子串中心扩散法)
前言 回文子串是练习数据结构和算法比较好的使用场景,可以同时练习到双指针、动态规划等一些列算法。 实现原理 中心扩散算法实现。这里定义最长回文子串长度的大小为maxLen,起点位置为0. 奇数个数为中心点和偶数个数为中心点分别计算回文长度大小。…...

基于Python网络招聘数据可视化分析系统的设计与实现
基于Python网络招聘数据可视化分析系统的设计与实现 Design and Implementation of Python-based Network Recruitment Data Visualization Analysis System 完整下载链接:基于Python网络招聘数据可视化分析系统的设计与实现 文章目录 基于Python网络招聘数据可视化分析系统的…...

【Linux】Linux工具——gcc/g++
1.使用vim更改信用名单——sudo 我们这里来补充sudo的相关知识——添加信任白名单用户 使用sudo就必须将使用sudo的那个账号添加到信用名单里,而且啊,只有超级管理员才可以添加 信用名单在/etc/sudoers里 我们发现它的权限只是可读啊,所以…...
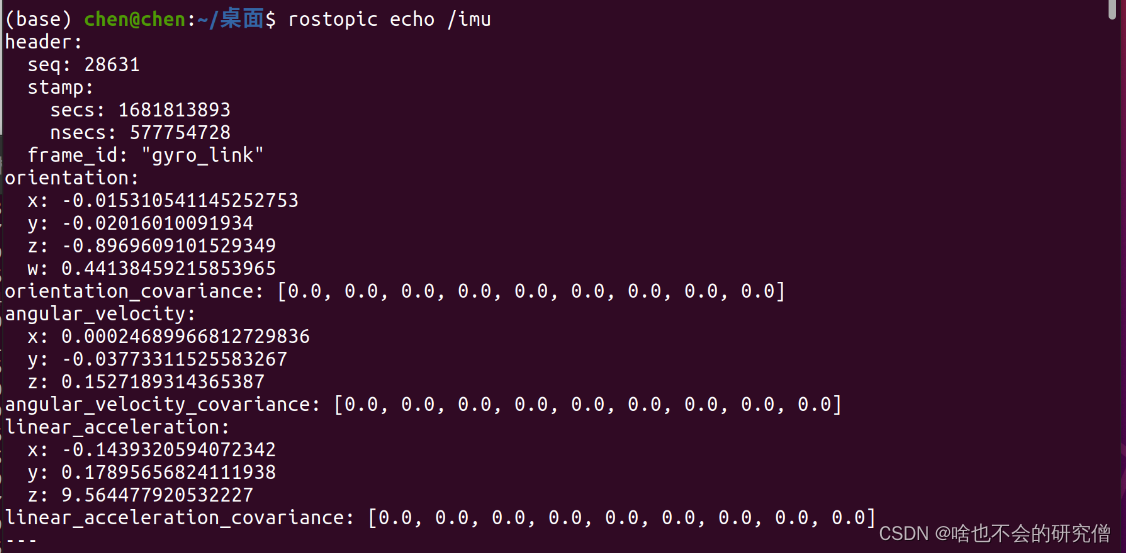
【惯性传感器imu】—— WHEELTEC的惯导模块的imu的驱动安装配置和运行
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、IMU驱动安装1. 安装依赖2. 源码的下载3. 编译源码(1) 配置固定串口设备(2) 修改luanch文件(3) 编译 二、启动IMU1. 运行imu2. 查看imu数据 总结 前言 WHEE…...

Linux提权一
#信息收集 当前主机的操作系统 hostnamectl cat /etc/*-release lsb_release -a cat /etc/lsb-release # Debain cat /etc/redhat-release # Redhat cat /etc/centos-release # Centos cat /etc/os-release # Ubuntu cat /etc/issue 当前主机的内核版本 hostnamectl uname -a …...

Vue.js中如何实现以列表首列为表头
前言 一般情况table列表的展示,列头都在第一横行,此方法用于列头在第一列的情况。 效果图 核心代码 <template><div><table class"data-table"><tr v-for"(column, columnIndex) in columns" :key"col…...

如果孙宇晨和贾跃亭能够握手,或许将会上演新的戏码
就在贾跃亭宣布将进行个人IP的商业化不久,便迎来了回应,并且这一次给予贾跃亭回应的,同样是一个颇具争议性的人物——孙宇晨。 根据孙宇晨最新发布的视频显示,他愿意投资贾跃亭「做一个新的个人IP化的公司」,并且将会…...
渲染100为什么是高性价比网渲平台?渲染100邀请码1a12
市面上主流的网渲平台有很多,如渲染100、瑞云、炫云、渲云等,这些平台各有特色和优势,也都声称自己性价比高,以渲染100为例,我们来介绍下它的优势有哪些。 1、渲染100对新用户很友好,注册填邀请码1a12有3…...
Jenkins流水线pipeline--基于上一章的工作流程
1流水线部署 1.流水线文本名Jenkinsfile,将流水线放入gitlab远程仓库代码里面 2pipeline脚本 Jenkinsfile文件内容 pipeline {agent anyenvironment {key"value"}stages {stage("拉取git仓库代码") {steps {deleteDir()checkout scmGit(branches: [[nam…...

比较Rust和Haskel
在比较Rust和Haskell时,我们可以从多个维度来分析它们各自的优势。以下是Rust相对于Haskell的优势,以及Haskell相对于Rust的优势: Rust比Haskell强的方面: 内存安全与并发性: Rust通过独特的所有权系统和借用检查器在…...

RedisTemplate的Long类型使用increment自增报错
问题描述 代码如下 Resourceprivate RedisTemplate<String,String > redisTemplate;redisTemplate.opsForValue().set("testKey", 0L); redisTemplate.opsForValue().increment("testKey");工作里用Long类型存储评论数,在使用increment自…...

【代码随想录训练营】【Day 36】【贪心-3】| Leetcode 1005, 134, 135
【代码随想录训练营】【Day 36】【贪心-3】| Leetcode 1005, 134, 135 需强化知识点 题目 1005. K 次取反后最大化的数组和 贪心:翻转绝对值最小的数思路:将数组按绝对值降序排序后,从左向右遍历数组,如果遇到小于0的数并且还…...

2.7HDR与LDR
一、基本概念 1.基本概念 动态范围(Dynamic Range) 最高亮度 / 最低亮度 HDR High Dynamic RangeLDR Low Dynamic Range HDR与LDR和Tonemapping的对应关系: 我们常用的各种显示器屏幕,由于不同的厂家不同的工艺导致它们的…...
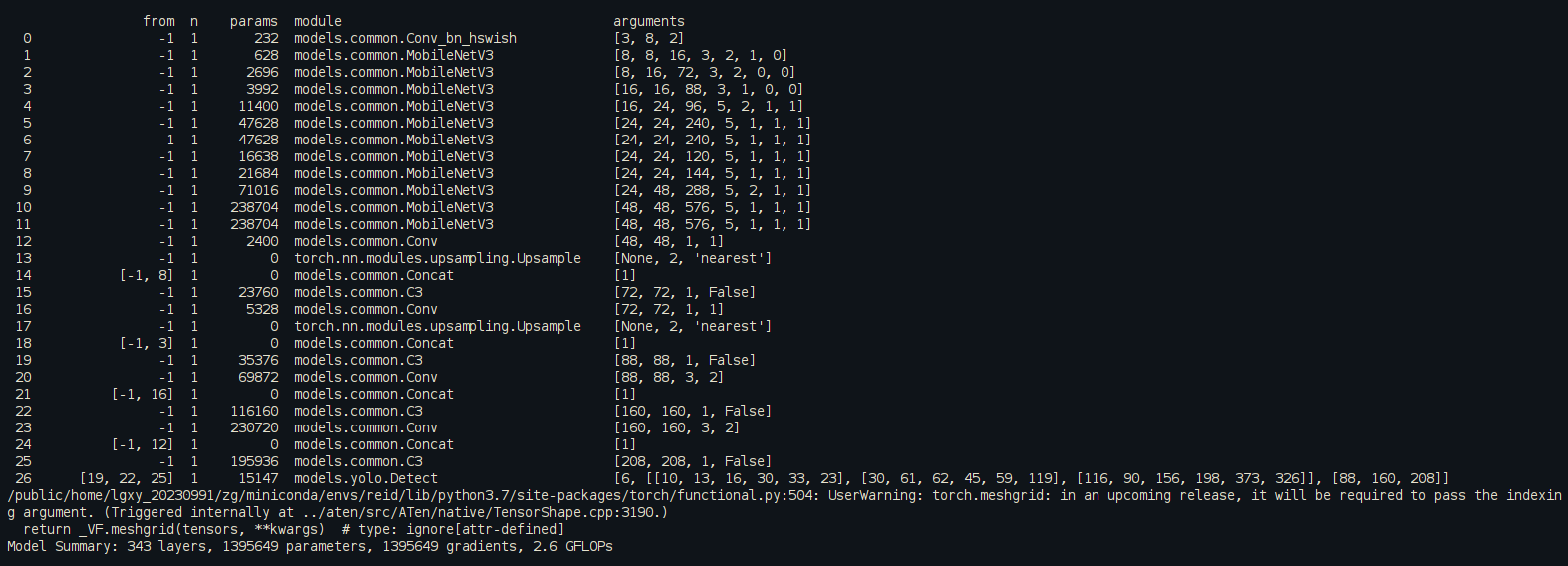
YOLOv5改进(五)-- 轻量化模型MobileNetv3
文章目录 1、MobileNetV3论文2、代码实现2.1、MobileNetV3-small2.2、MobileNetV3-large 3、运行效果4、目标检测系列文章 1、MobileNetV3论文 Searching for MobileNetV3论文 MobileNetV3代码 MobileNetV3 是 Google 提出的一种轻量级神经网络结构,旨在在移动设备上…...
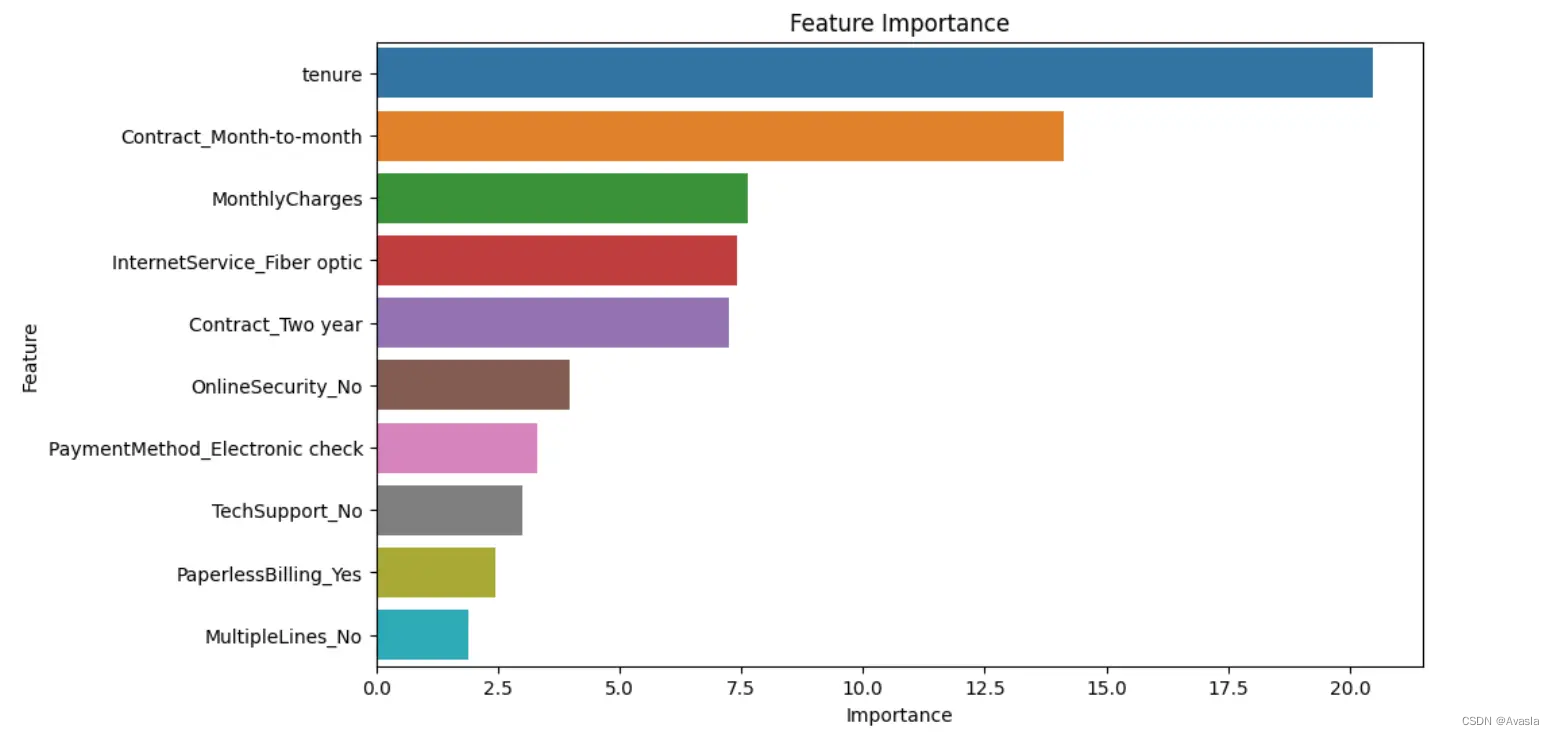
用户流失分析:如何使用Python训练一个用户流失预测模型?
引言 在当今商业环境中,客户流失分析是至关重要的一环。随着市场竞争的加剧,企业需要更加注重保持现有客户,并深入了解他们的离开原因。本文探讨了用户流失分析的核心概念以及如何构建客户流失预测模型的案例。通过分析用户行为数据和交易模式…...

别再只盯着wx.login了!SpringBoot后端实战:用getPhoneNumber接口搞定小程序用户手机号绑定
微信小程序用户手机号绑定:SpringBoot后端深度实践指南 在当今移动互联网生态中,微信小程序已成为连接用户与服务的重要桥梁。对于需要强实名认证或直接触达用户的业务场景(如电商交易、金融服务、政务办理等),仅依赖w…...

Blitz.js全栈开发框架:零API理念与Next.js深度集成实战
1. 项目概述:一个颠覆性的全栈开发框架如果你和我一样,在过去的几年里,一直在React生态圈里打转,从Create React App到Next.js,再到尝试自己搭建一套包含身份验证、数据层、API路由的完整应用,那你一定对那…...

Ash印相渲染失败率骤升47%?紧急预警:V6.2更新后Gamma 2.2→2.4迁移引发的印相断层危机
更多请点击: https://intelliparadigm.com 第一章:Ash印相渲染失败率骤升47%的全局现象与危机定性 近期,全球多个采用 Ash 印相引擎(v3.8.2)的影像处理平台集中报告渲染任务异常终止、输出空白或超时中断。监控数据显…...

从零解析开源API网关fiGate:架构设计与生产实践
1. 项目概述:从零解析一个开源API网关最近在梳理团队内部微服务治理方案时,我又重新审视了市面上各类API网关的实现。除了大家耳熟能详的Kong、APISIX、Tyk这些“明星产品”,其实在GitHub的海洋里,还藏着不少设计精巧、思路独特的…...

AI绘图技能解析:用自然语言驱动Excalidraw自动生成图表
1. 项目概述:一个为Excalidraw注入AI灵魂的绘图技能如果你经常用Excalidraw画流程图、架构图或者白板草图,那你一定体会过那种“想法很丰满,画笔很骨感”的尴尬。脑子里明明有一个清晰的系统架构,但落到画布上,光是调整…...

独立开发者如何利用 Taotoken 以更低成本试验多种 AI 模型能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用 Taotoken 以更低成本试验多种 AI 模型能力 对于独立开发者或小型工作室而言,在产品开发的早期阶段…...

MacOS光标增强工具:命令行驱动,实现自动化与个性化配置
1. 项目概述:当光标成为生产力工具如果你是一名长期在macOS上工作的开发者、设计师或者文字工作者,你肯定对系统自带的光标功能又爱又恨。爱的是它简洁流畅,恨的是它在某些高强度、多任务场景下显得力不从心。比如,当你需要在多个…...

Golioth Firmware SDK:物联网设备连接与管理的开源解决方案
1. 项目概述:Golioth Firmware SDK 是什么?如果你正在开发物联网设备,尤其是那些需要稳定连接到云端、进行远程管理、固件更新和数据同步的设备,那么你一定对“设备管理”和“连接复杂性”这两个词深有体会。自己从头搭建一套稳定…...

Cortex-A78C架构解析:AMU与ETM寄存器实战指南
1. Cortex-A78C核心架构与寄存器概览Cortex-A78C是Armv8-A架构的高性能实现,面向移动计算和边缘AI场景优化。作为A78系列的安全增强版本,它在保留原有3发射乱序执行流水线的基础上,新增了Pointer Authentication等安全扩展,同时强…...

【2026最新】鸿蒙NEXT数据持久化实战:培训班管理系统数据存储全攻略
鸿蒙开发中数据总是丢失?本地存储和网络请求搞不定?本文用15分钟带你彻底搞懂Preferences、RDB、HTTP三大数据持久化方案,附完整培训班管理系统实战代码和踩坑记录,让你的鸿蒙App数据存储从此安全可靠!一、学员信息本地…...