Spark SQL数据源 - Parquet文件
当使用Spark SQL处理Parquet文件时,你可以使用spark.read.parquet()方法从文件系统中加载Parquet数据到一个DataFrame中。Parquet是一种列式存储格式,非常适合用于大数据集,因为它提供了高效的压缩和编码方案。
以下是一个简单的例子,展示了如何使用Spark SQL读取Parquet文件:
首先,假设你有一个Parquet文件people.parquet,它可能由其他Spark作业生成。
你可以使用以下Scala代码来读取这个文件并查询其中的数据:
import org.apache.spark.sql.SparkSessionobject ParquetDatasetExample {def main(args: Array[String]): Unit = {// 创建一个SparkSession对象val spark = SparkSession.builder().appName("ParquetDatasetExample").master("local[*]") // 在本地运行,使用所有可用的核心.getOrCreate()// 读取Parquet文件val peopleDF = spark.read.parquet("path/to/your/people.parquet") // 替换为你的文件路径// 显示DataFrame的内容peopleDF.show()// 打印DataFrame的schemapeopleDF.printSchema()// 注册为临时视图以便可以使用SQL查询peopleDF.createOrReplaceTempView("people")// 使用SQL查询所有年龄大于20岁的人val sqlDF = spark.sql("SELECT * FROM people WHERE age > 20")sqlDF.show()// 停止SparkSessionspark.stop()}
}
请注意,你需要将"path/to/your/people.parquet"替换为你的people.parquet文件的实际路径。如果文件在本地文件系统中,只需提供文件的绝对路径或相对路径即可。如果文件在HDFS或其他分布式文件系统中,你需要提供对应的URI。
此外,.master("local[*]")配置用于在本地模式下运行Spark,并使用所有可用的CPU核心。如果你在一个集群环境中运行Spark,你需要将这部分配置更改为适合你的集群环境的设置。
Parquet文件通常包含嵌套的结构和复杂的数据类型,因此当你使用printSchema()方法时,你可以看到DataFrame的完整模式,包括所有的列和它们的数据类型。
最后,你可以使用sbt或Maven等工具来构建和运行这个项目,或者如果你已经设置好了Spark环境,你可以使用spark-submit命令来提交你的应用程序。例如:
spark-submit --class ParquetDatasetExample --master local[*] your-jar-with-dependencies.jar
请确保将your-jar-with-dependencies.jar替换为你的包含所有依赖的JAR包的路径。
为了提供一个完整的、可运行的Scala代码示例,用于读取Parquet文件并使用Spark SQL查询数据,你可以参考以下代码:
首先,你需要确保你的环境中有一个名为people.parquet的Parquet文件,该文件包含一些数据。
然后,你可以使用以下Scala代码来读取并处理这个Parquet文件:
import org.apache.spark.sql.SparkSessionobject ParquetDatasetExample {def main(args: Array[String]): Unit = {// 创建一个SparkSession对象val spark = SparkSession.builder().appName("ParquetDatasetExample").master("local[*]") // 在本地运行,使用所有可用的核心.getOrCreate()// 读取Parquet文件val peopleDF = spark.read.parquet("path/to/your/people.parquet") // 替换为你的文件路径// 显示DataFrame的内容peopleDF.show()// 打印DataFrame的schemapeopleDF.printSchema()// 注册为临时视图以便可以使用SQL查询peopleDF.createOrReplaceTempView("people")// 使用SQL查询所有年龄大于20岁的人val sqlDF = spark.sql("SELECT * FROM people WHERE age > 20")sqlDF.show()// 停止SparkSessionspark.stop()}
}
注意:
- 将
"path/to/your/people.parquet"替换为你的Parquet文件的实际路径。 - 如果你在集群上运行这段代码,请将
.master("local[*]")替换为适合你的集群环境的设置,比如"spark://your-master-url:7077"。 - 确保你的项目中包含了所有必要的依赖,特别是与Spark相关的依赖。如果你使用sbt,你的
build.sbt文件应该包含类似下面的依赖:
name := "ParquetDatasetExample"
version := "1.0"
scalaVersion := "2.12.10" // 根据你的Scala版本进行调整
libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.1.1" // 根据你的Spark版本进行调整
- 编译并打包你的Scala项目为一个JAR文件。
- 使用
spark-submit命令提交你的JAR文件到Spark集群(如果你在集群上运行的话):
spark-submit --class ParquetDatasetExample --master spark://your-master-url:7077 your-jar-with-dependencies.jar
请确保将your-master-url替换为你的Spark集群的主节点URL,并将your-jar-with-dependencies.jar替换为你的JAR文件的实际路径。如果你在本地运行,可以使用local[*]作为master URL。
相关文章:

Spark SQL数据源 - Parquet文件
当使用Spark SQL处理Parquet文件时,你可以使用spark.read.parquet()方法从文件系统中加载Parquet数据到一个DataFrame中。Parquet是一种列式存储格式,非常适合用于大数据集,因为它提供了高效的压缩和编码方案。 以下是一个简单的例子&#x…...
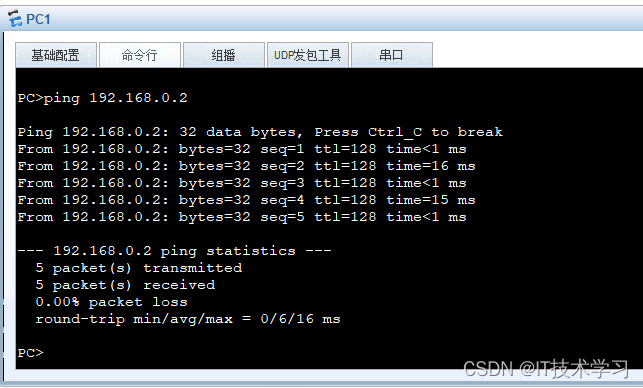
eNsp——两台电脑通过一根网线直连通信
一、拓扑结构 二、电脑配置 ip和子网掩码,配置两台电脑处于同一网段 三、测试 四、应用 传文件等操作,可以在一台电脑上配置FTP服务器...
杂牌记录仪TS视频流恢复方法
大多数的记录仪都采用了MP4/MOV文件方案,极少数的可能在用AVI文件,极极少数的在用TS文件方案。很多人可能不太解TS文件,这是一种古老的视频文件结构,下边这个案例我们来看下TS视频文件的恢复方法。 故障存储:8G存储卡/fat32文件系…...

十_信号7-信号集
int sigemptyset(sigset_t *set); 清空信号集 int sigfillset(sigset_t *set); 填充满 信号集 int sigaddset(sigset_t *set, int signum); 向信号集中添加信号 int sigdelset(sigset_t *set, int signum); 从型号集中删除信号 int sigismember(const sigset_t *set, int s…...

GPT-4o
微软最新发布的CopilotPC采用了OpenAI最新的GPT-4o技术,新增了多项强大功能。以下是主要的新增功能: 更强大的AI处理能力:CopilotPC采用了专门用于AI处理的特殊芯片,使得电脑能够处理更多的人工智能任务,而无需调用云…...

32位与64位程序下函数调用的异同——计科学习中缺失的内容
前言 今天,通过一个有趣的案例,从反编译的角度看一下C语言中函数参数是如何传递的。 创建main.c文件,将下面实验代码拷贝到main.c文件中。 # main.c #include <stdio.h>int test(int a, int b, int c, int d, int e, int f, int g, …...

Python爬虫实战(实战篇)—16获取【百度热搜】数据—写入Ecel(附完整代码)
文章目录 专栏导读背景结果预览1、爬取页面分析2、通过返回数据发现适合利用lxmlxpath3、继续分析【小说榜、电影榜、电视剧榜、汽车榜、游戏榜】4、完整代码总结 专栏导读 🔥🔥本文已收录于《Python基础篇爬虫》 🉑🉑本专栏专门…...
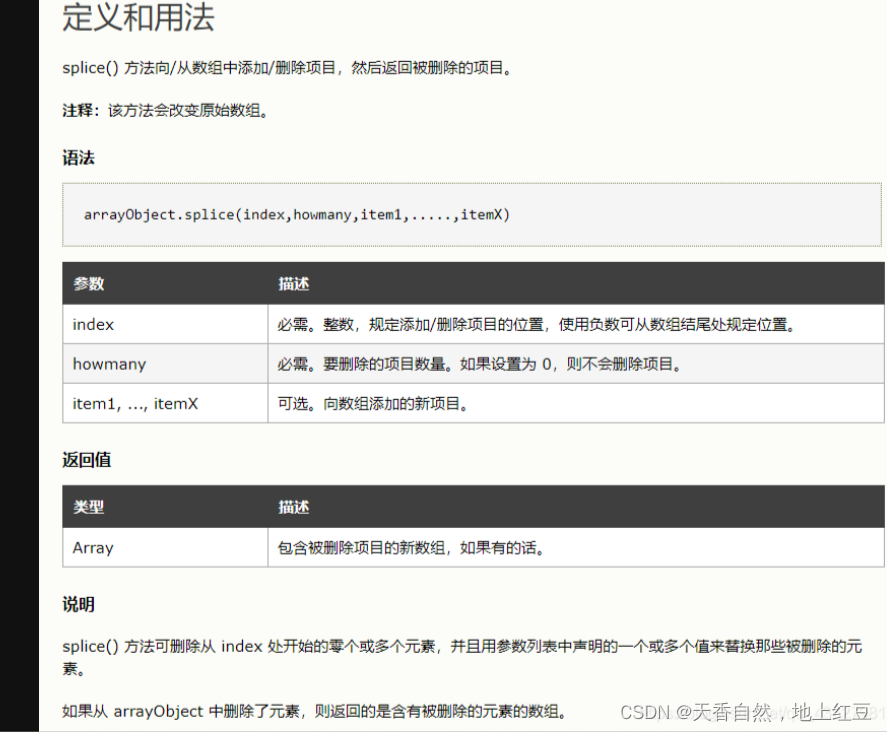
js切割数组的两种方法slice(),splice()
slice() 返回一个索引和另一个索引之间的数据(不改变原数组),slice(start,end)有两个参数(start必需,end选填),都是索引,返回值不包括end 用法和截取字符串一样 splice() 用来添加或者删除数组的数据,只返回被删除的数据,类型为数组(改变原数组) var heroes["李白&q…...

【计算机毕设】基于SpringBoot的医院管理系统设计与实现 - 源码免费(私信领取)
免费领取源码 | 项目完整可运行 | v:chengn7890 诚招源码校园代理! 1. 研究目的 本项目旨在设计并实现一个基于SpringBoot的医院管理系统,以提高医院管理效率,优化医疗服务流程,提升患者就诊体验…...

导线防碰撞警示灯:高压线路安全保障
导线防碰撞警示灯:高压线路安全保障 在广袤的大地上,高压线路如同血脉般纵横交错,然而,在这看似平静的电力输送背后,却隐藏着不容忽视的安全隐患。特别是在那些输电线路跨越道路、施工等区域的路段,线下超…...

【LeetCode 77. 组合】
1. 题目 2. 分析 本题有个难点在于如何保存深搜得到的结果?总结了一下,深搜处理的代码,关于返回值有三大类。 第一类:层层传递,将最深层的结果传上来;这类题有:【反转链表】 第二类࿱…...

element-ui组件table去除下方滚动条,实现鼠标左右拖拽移动表格
时隔多日,再次遇到值得记录的问题。 需求 项目前端使用vue框架,页面使用element-ui进行页面快速搭建。默认的table组件当表格过长时,下方会出现横向的滚动条,便于用户对表格进行左右滑动。考虑到页面美观问题,滚动条…...

【C++】list的使用(上)
🔥个人主页: Forcible Bug Maker 🔥专栏: STL || C 目录 前言🌈关于list🔥默认成员函数构造函数(constructor)析构函数(destructor)赋值运算符重载 …...

【代码随想录训练营】【Day 37】【贪心-4】| Leetcode 840, 406, 452
【代码随想录训练营】【Day 37】【贪心-4】| Leetcode 840, 406, 452 需强化知识点 python list sort的高阶用法,两个key,另一种逆序写法python list insert的用法 题目 860. 柠檬水找零 思路:注意 20 块找零,可以找3张5块升…...

concat是什么?前端开发者必须掌握的数组拼接利器
concat是什么?前端开发者必须掌握的数组拼接利器 在前端开发中,concat是一个极其重要的概念,它能够帮助我们实现数组之间的无缝拼接。那么,concat到底是什么?为什么它在前端开发中如此重要?接下来…...
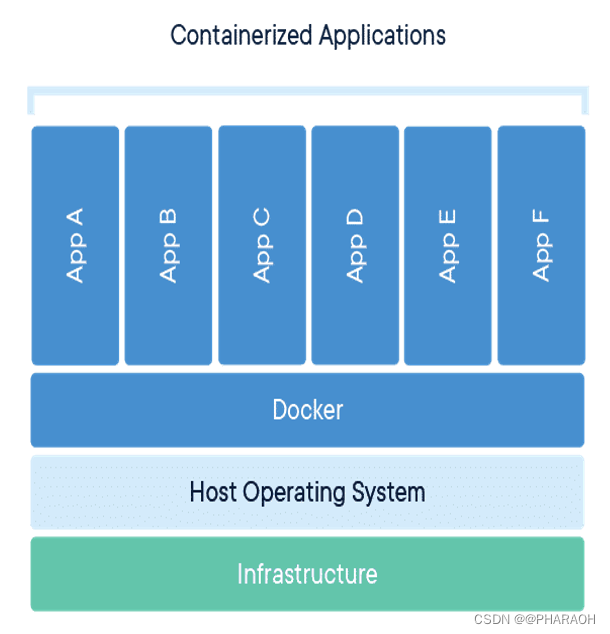
WHAT - 容器化系列(一)
这里写目录标题 一、什么是容器与虚拟机1.1 什么是容器1.2 容器的特点1.3 容器和虚拟机的区别虚拟机(VM):基于硬件的资源隔离技术容器:基于操作系统的资源隔离技术对比总结应用场景 二、容器的实现原理1. Namespace(命…...

QT7_视频知识点笔记_67_项目练习(页面以及对话框的切换,自定义数据类型,DB数据库类的自定义及使用)
视频项目:7----汽车销售管理系统(登录,品牌车管理,新车入库,销售统计图表)-----项目视频没有,代码也不全,更改项目练习:学生信息管理系统。 学生信息管理系统࿱…...
windows10系统64位安装delphiXE11.2完整教程
windows10系统64位安装delphiXE11.2完整教程 https://altd.embarcadero.com/download/radstudio/11.0/radstudio_11_106491a.iso XE11.1 https://altd.embarcadero.com/download/radstudio/11.0/RADStudio_11_2_10937a.iso XE11.2 关键使用文件在以下内容:windows10…...

09.责任链模式
09. 责任链模式 什么是责任链设计模式? 责任链设计模式(Chain of Responsibility Pattern)是一种行为设计模式,它允许将请求沿着处理者对象组成的链进行传递,直到有一个处理者对象能够处理该请求为止。这种模式的目的…...

Amazon云计算AWS(一)
目录 一、基础存储架构Dynamo(一)Dynamo概况(二)Dynamo架构的主要技术 二、弹性计算云EC2(一)EC2的基本架构(二)EC2的关键技术(三)EC2的安全及容错机制 提供的…...

3分钟掌握加密压缩包密码破解:ArchivePasswordTestTool终极实战指南
3分钟掌握加密压缩包密码破解:ArchivePasswordTestTool终极实战指南 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经…...

移动端部署福音?YOLOv5结合EfficientNetV2主干网络的轻量化改造与性能实测
YOLOv5与EfficientNetV2融合:移动端目标检测的轻量化实践 在移动端和边缘计算设备上部署目标检测模型始终面临计算资源有限、功耗敏感等挑战。本文将深入探讨如何通过将YOLOv5与EfficientNetV2主干网络结合,构建一个真正适合嵌入式设备的轻量化目标检测…...

观察Taotoken在不同网络环境下API调用的延迟表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在不同网络环境下API调用的延迟表现 在将大模型API集成到实际应用时,网络环境是影响开发者体验的关键因素…...

AI-Shoujo HF Patch完全指南:从技术架构到高级应用
AI-Shoujo HF Patch完全指南:从技术架构到高级应用 【免费下载链接】AI-HF_Patch Automatically translate, uncensor and update AI-Shoujo! 项目地址: https://gitcode.com/gh_mirrors/ai/AI-HF_Patch AI-Shoujo HF Patch是一款专为AI-Shoujo游戏设计的模块…...

Android Studio中文界面全面配置指南:专业汉化解决方案
Android Studio中文界面全面配置指南:专业汉化解决方案 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack Android Studi…...

需求用例-成功保证
成功保证(success guarantee)说明了用例成功结束后项目相关人员的哪些利益得到了满足,用例可以通过执行主场景获得成功,也可以通过执行可选路径获得成功。成功保证通常是作为最小保证的补充内容:最小保证被满足以后, 第6章 前置条件、触发事件…...

基于知识图谱InsightGraph — 让数据开口说话。
从Palantir的ontology思路出发,我们踩了一遍知识图谱的坑让数据从"分散的资产",变成"会分析、会归因的业务伙伴"💼你一定遇到过这些问题这份数据和其他系统能不能关联?问了三个人有三个答案运营问"为什么…...

Unity ShaderGraph工程化实践:从可视化到生产级渲染
1. 为什么我劝新手别急着写第一行Shader代码——从Unity ShaderGraph的“可视化错觉”说起 刚接触Unity渲染管线的新手,十有八九会经历这样一个阶段:在B站搜“Unity Shader教程”,点开前三个视频,前两分钟听着“顶点着色器负责位置…...

谷歌SEO全面解析|新手入门 + 排名提升核心要点
如今,无论是企业官网、外贸独立站,还是个人博客,越来越多人开始重视“谷歌 SEO”。 原因很简单: 谁能在 Google 搜索结果中获得排名,谁就能持续获得免费的精准流量。 很多新手第一次接触 SEO 时,会觉得它…...

Google三星AI眼镜来了,开发者该关注什么
AI 眼镜又回来了,但这次不只是换个硬件外壳AI 眼镜这个话题,最近又被推到了台前。Google 在 I/O 2026 展示了基于 Android XR 的智能眼镜方向,并把三星、Gentle Monster、Warby Parker 等合作方一起摆上台面。按照目前公布的信息,…...