【强化学习】DPO(Direct Preference Optimization)算法学习笔记
【强化学习】DPO(Direct Preference Optimization)算法学习笔记
- RLHF与DPO的关系
- KL散度
- Bradley-Terry模型
- DPO算法流程
- 参考文献
RLHF与DPO的关系
- DPO(Direct Preference Optimization)和RLHF(Reinforcement Learning from Human Feedback)都是用于训练和优化人工智能模型的方法,特别是在大型语言模型的训练中
- DPO和RLHF都旨在通过人类的反馈来优化模型的表现,它们都试图让模型学习到更符合人类偏好的行为或输出
- RLHF通常涉及三个阶段:全监督微调(Supervised Fine-Tuning)、奖励模型(Reward Model)的训练,以及强化学习(Reinforcement Learning)的微调
- DPO是一种直接优化模型偏好的方法,不需要显式地定义奖励函数,而是通过比较不同模型输出的结果,选择更符合人类偏好的结果作为训练目标,主要是通过直接最小化或最大化目标函数来实现优化,利用偏好直接指导优化过程,而不依赖于强化学习框架

KL散度
- KL散度(Kullback-Leibler divergence),也被称为相对熵,是衡量两个概率分布P和Q差异的一种方法
- 公式: K L ( P ∣ ∣ Q ) = ∑ x P ( x ) log ( P ( x ) Q ( x ) ) \mathrm{KL}(P||Q)=\sum_xP(x)\log\left(\frac{P(x)}{Q(x)}\right) KL(P∣∣Q)=∑xP(x)log(Q(x)P(x))
- KL散度是不对称的, K L ( P ∣ ∣ Q ) ! = K L ( Q ∣ ∣ P ) KL(P||Q)!=KL(Q||P) KL(P∣∣Q)!=KL(Q∣∣P)

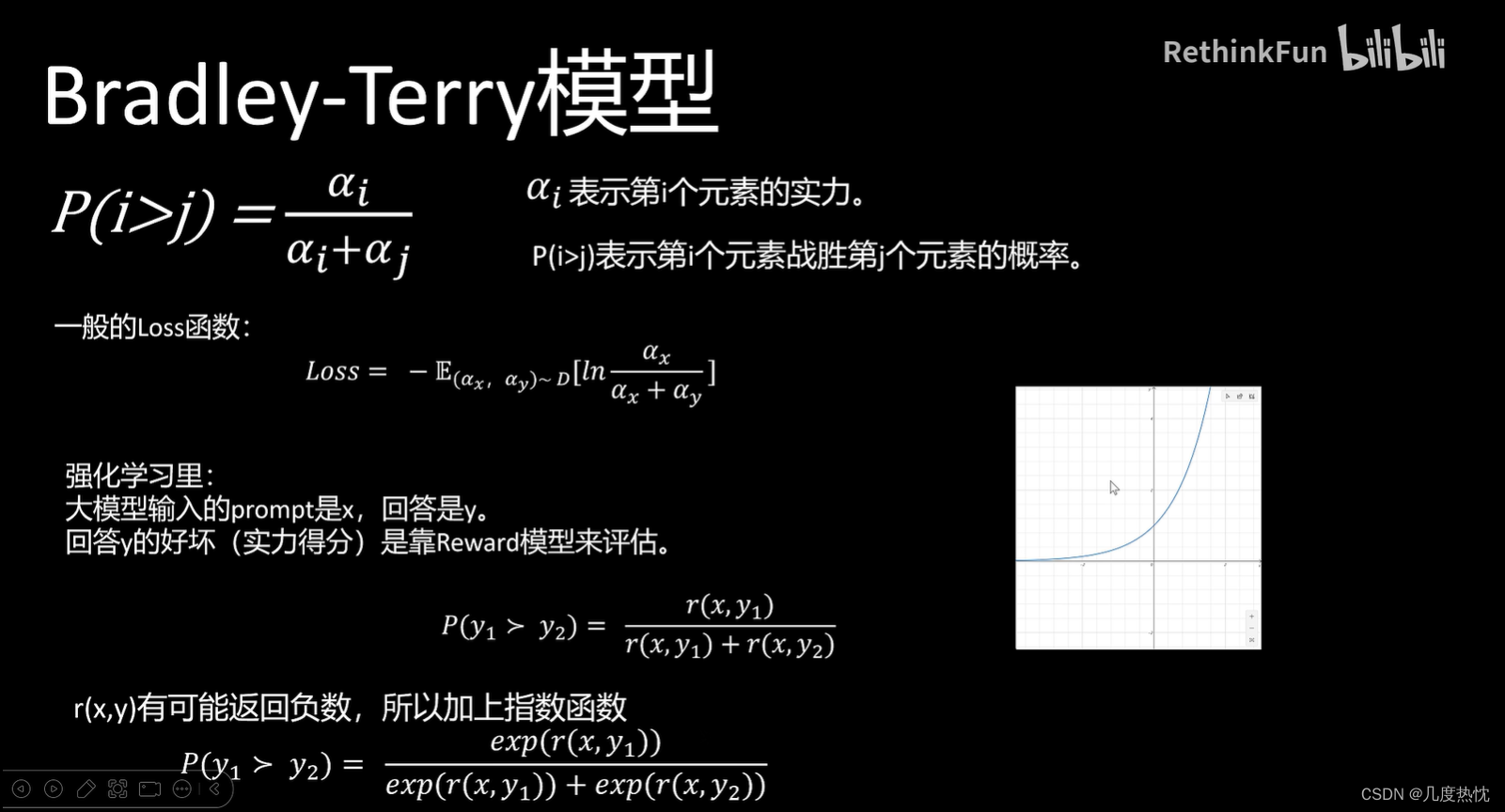
Bradley-Terry模型
-
Bradley-Terry模型是一种用于比较成对对象并确定相对偏好或能力的方法。这种模型特别适用于对成对比较数据进行分析,从而对一组对象进行排序
-
P ( i > j ) = α i α i + α j P(i{>}j)=\frac{\alpha_i}{\alpha_i{+}\alpha_j} P(i>j)=αi+αjαi
-
α i \alpha_i αi表示第 i i i个元素的能力参数,且大于0。 P ( i > j ) P(i>j) P(i>j)表示第 i i i个元素战胜第 j j j个元素的概率
-
Bradley-Terry模型的参数通常通过最大似然估计(MLE)来确定
-
sigmoid函数: σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
-
loss函数的化简
L o s s = − E ( x , y w , y l ) ∼ D [ ln e x p ( r ( x , y w ) ) e x p ( r ( x , y w ) ) + e x p ( r ( x , y l ) ) ] = − E ( x , y w , y l ) ∼ D [ ln 1 1 + e x p ( r ( x , y l ) − r ( x , y w ) ) ] = − E ( x , y w , y l ) ∼ D [ ln σ ( r ( x , y w ) − r ( x , y l ) ) ] \begin{aligned}Loss &=-\mathbb{E}_{(x,y_{w},y_{l})\sim D}[\ln\frac{exp(r(x,y_{w}))}{exp(r(x,y_{w}))+exp(r(x,y_{l}))}] \\ &= -\mathbb{E}_{(x,y_{w},y_{l})\sim D}[\ln\frac{1}{1 + exp(r(x,y_{l})- r(x,y_{w}))}] \\ &= -\mathbb{E}_{(x,y_{w},y_{l})\sim D}[\ln \sigma(r(x,y_{w})-r(x,y_{l}))] \end{aligned} Loss=−E(x,yw,yl)∼D[lnexp(r(x,yw))+exp(r(x,yl))exp(r(x,yw))]=−E(x,yw,yl)∼D[ln1+exp(r(x,yl)−r(x,yw))1]=−E(x,yw,yl)∼D[lnσ(r(x,yw)−r(x,yl))] -
loss函数的目标是优化LLM输出的 y w y_w yw,经过reward计算的得分尽可能的大于 y w y_w yw经过reward计算的得分

DPO算法流程
- DPO通过比较不同输出的偏好,构建一个目标函数,该函数直接反映人类的偏好,通常使用排序损失函数(例如Pairwise Ranking Loss),该函数用来衡量模型在用户偏好上的表现
- DPO优化过程:使用梯度下降等优化算法,直接最小化或最大化目标函数。通过不断调整模型参数,使得模型生成的输出更加符合用户的偏好

- 基准模型一般指经过SFT有监督微调后的模型
- DPO的目标是尽可能得到多的奖励,同时使得新训练的 模型尽可能与基准模型分布一致
DPO训练目标的化简
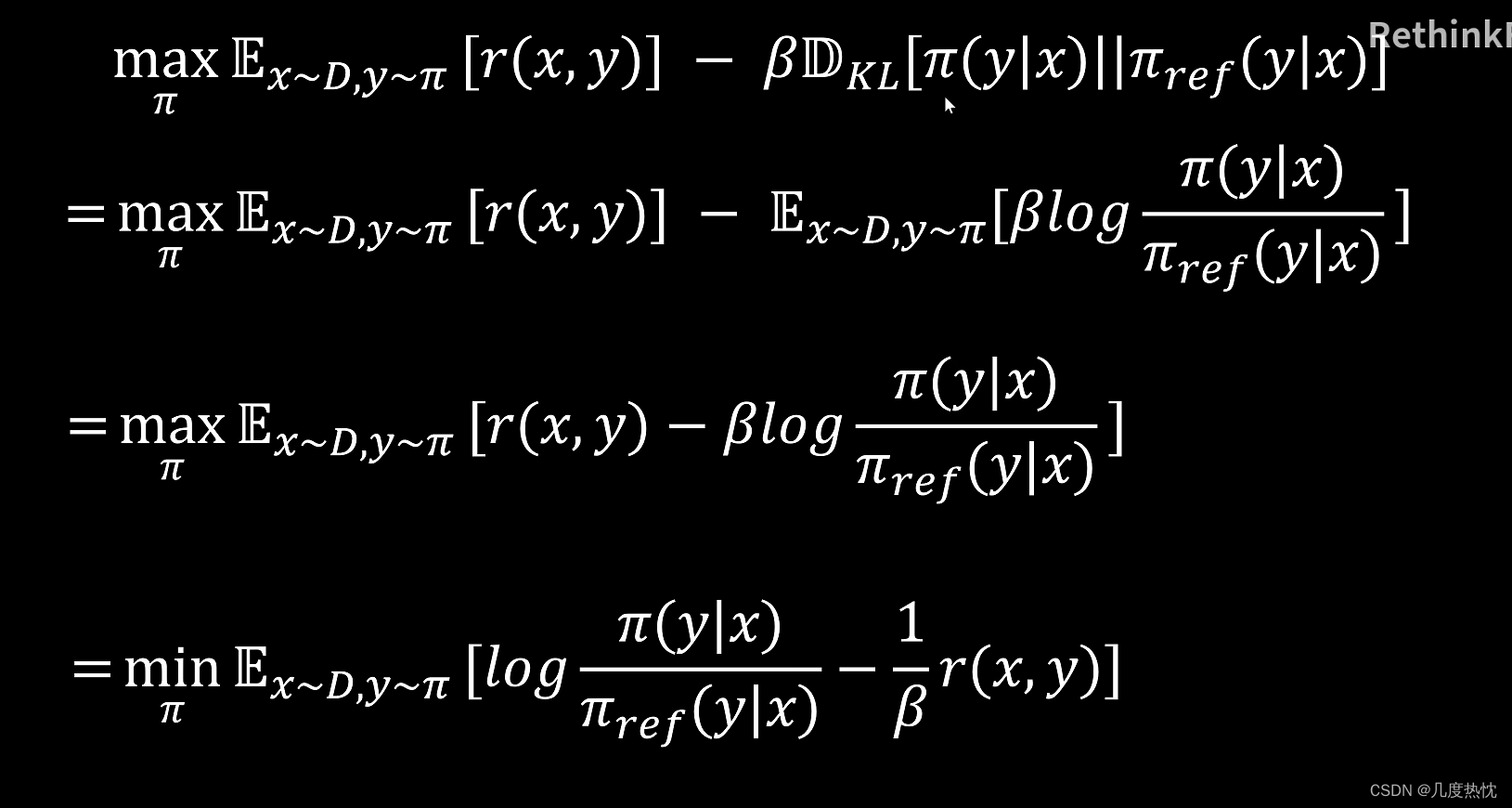
上图中第一步利用的是KL散度的定义,之所以式子中没有KL散度中的 P ( π ( y ∣ x ) ) P(\pi(y|x)) P(π(y∣x)),是因为KL散度可以理解成是一个概率比值的log的期望,在这里这个概率以期望的形式放到式子左边的期望中了
- 求最大值 通过在式中加上负号转化为求最小值,并同时除以 β \beta β
- DPO原论文中的推导过程

- 继续推导

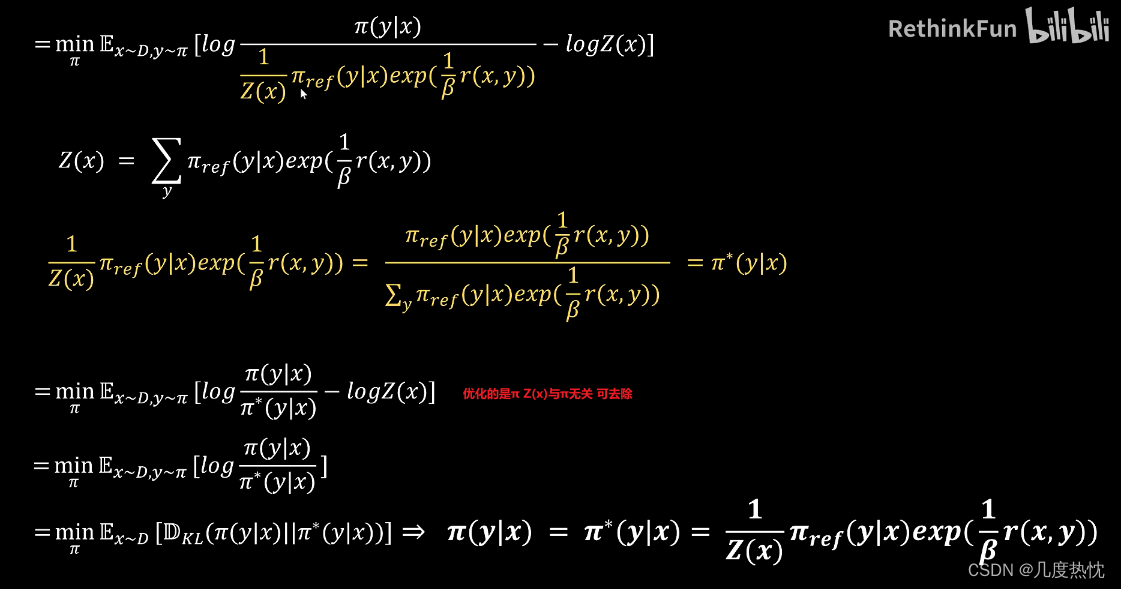
- 求解reward函数的表达式,将reward函数的表达式代入loss函数中
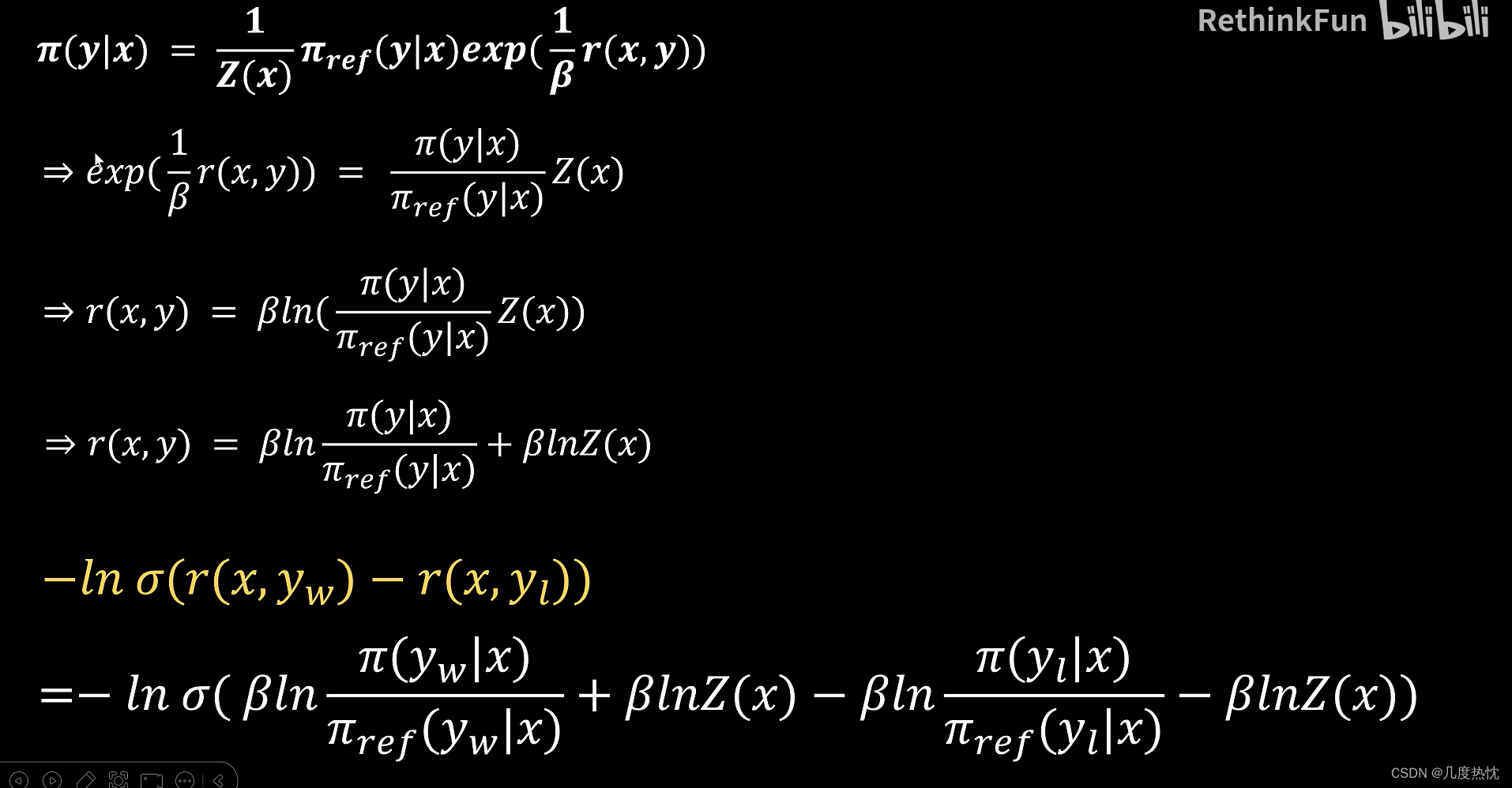
- DPO loss损失函数的表达形式
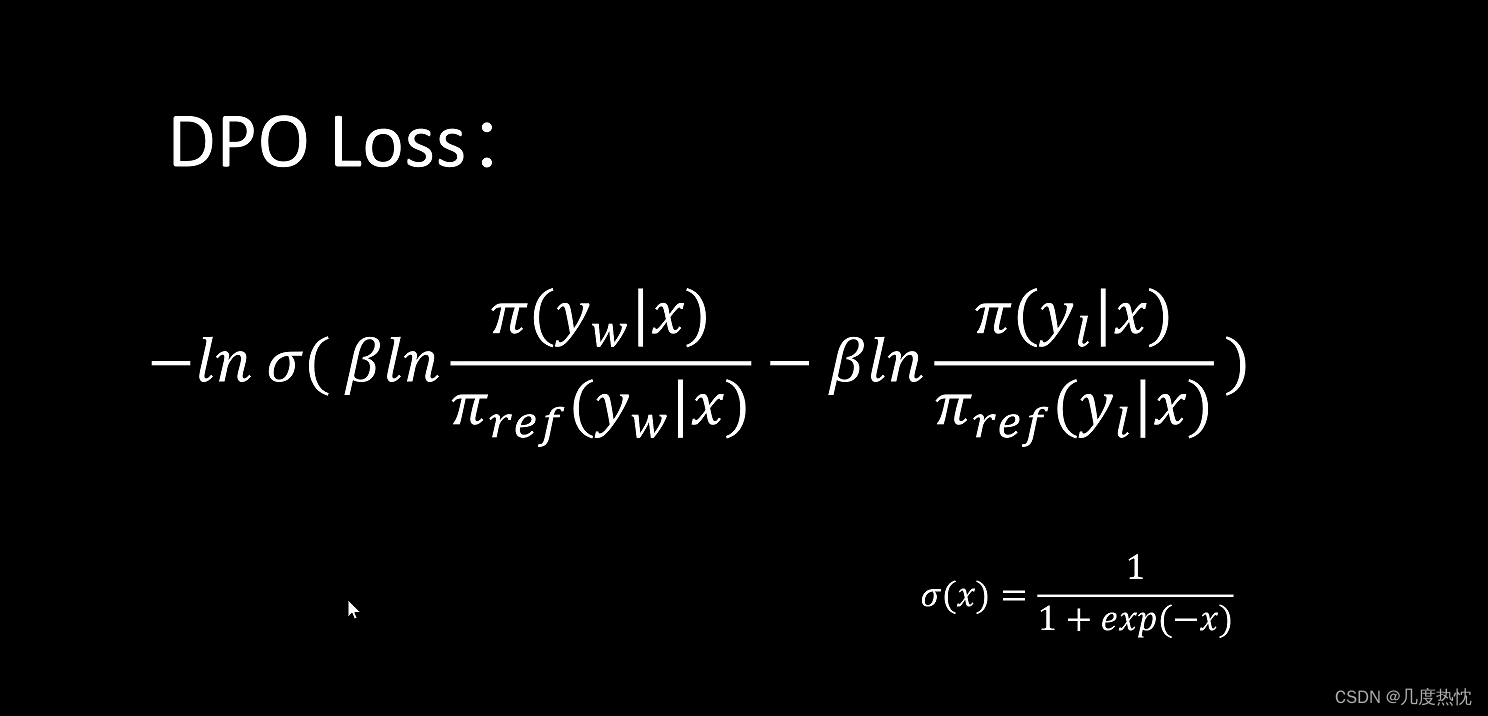
- logZ(x)项被抵消,于是可以转而用最大似然估计MLE直接在这个概率模型上直接优化LM,去得到希望的最优的π*
个人理解的一知半解 有时间还是得去看看原论文
参考文献
- DPO (Direct Preference Optimization) 算法讲解
- Direct Preference Optimization(DPO)学习笔记
- DPO原论文 Direct Preference Optimization: Your Language Model is Secretly a Reward Model
相关文章:
【强化学习】DPO(Direct Preference Optimization)算法学习笔记
【强化学习】DPO(Direct Preference Optimization)算法学习笔记 RLHF与DPO的关系KL散度Bradley-Terry模型DPO算法流程参考文献 RLHF与DPO的关系 DPO(Direct Preference Optimization)和RLHF(Reinforcement Learning f…...

vue3 todolist 简单例子
vue3 简单的TodList 地址: https://gitee.com/cheng_yong_xu/vue3-composition-api-todo-app-my 效果 step-1 初始化项项目 我们不采用vue cli 搭建项目 直接将上图文件夹,复制到vscode编辑器,清空App.vue的内容 安装包 # 安装包 npm…...

Linux项目编程必备武器!
本文目录 一、更换源服务器二、下载man开发手册(一般都自带,没有的话使用下面方法下载) 一、更换源服务器 我们使用apt-get等下载命令下载的软件都是从源服务器上获取的,有些软件包在某个服务器上存在,而另一个服务器不存在。所以我们可以添加…...

AndroidStudio编译很慢问题解决
如果gradle同步、编译下载很慢,可以换一下仓库阿里云镜像 repositories {maven { url https://maven.aliyun.com/repository/google } maven { url https://maven.aliyun.com/repository/jcenter } maven { url https://maven.aliyun.com/repository/public } goog…...
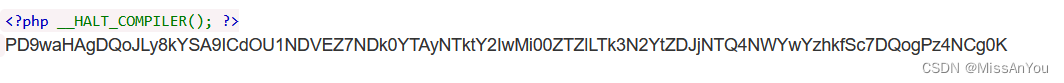
PHAR反序列化
PHAR PHAR(PHP Archive)文件是一种归档文件格式,phar文件本质上是一种压缩文件,会以序列化的形式存储用户自定义的meta-data。当受影响的文件操作函数调用phar文件时,会自动反序列化meta-data内的内容,这里就是我们反序…...

Rust安装
目录 一、安装1.1 在Windows上安装1.2 在Linux下安装 二、包管理工具三、Hello World3.1 安装IDE3.2 输出Hello World 一、安装 1.1 在Windows上安装 点击页面 安装 Rust - Rust 程序设计语言 (rust-lang.org),选择"下载RUSTUP-INIT.EXE(64位)&qu…...

513.找树左下角的值
给定一个二叉树,在树的最后一行找到最左边的值。 示例 1: 示例 2: 思路: 深度最大的叶子结点一定是最后一行。 优先左边搜索,记录深度最大的叶子节点,此时就是树的最后一行最左边的值 代码: class Solution:def fi…...

docker基础,docker安装mysql,docker安装Nginx,docker安装mq,docker基础命令
核心功能操作镜像 Docker安装mysql docker run -d --name mysql -p 3306:3306 -e TZAsia/Shanghai -e MYSQL_ROOT_PASSWORDlcl15604007179 mysql docker的基本操作 docker rm 容器名称即可 docker ps 查看当前运行的容器 docker rm 干掉当前容器 docker logs 查看容器命令日…...

MyBatis二、搭建 MyBatis
MyBatis二、搭建 MyBatis 开发环境MySQL 不同版本的注意事项驱动程序(Driver)JDBC URL连接参数MyBatis配置文件版本兼容性常见问题与解决方案示例(MySQL 8.x与MyBatis连接) 创建 Maven 工程打包方式:Jar引入依赖创建数…...

昵称生成器
package mainimport ("math/rand" )// 随机昵称 形容词 var nicheng_tou []string{"迷你的", "鲜艳的", "飞快的", "真实的", "清新的", "幸福的", "可耐的", "快乐的", "冷…...

mysql仿照find_in_set写了一个replace_in_set函数,英文逗号拼接字符串指定替换
开发中使用mysql5.7版本数据库,对于英文逗号拼接的字符串,想要替换其中指定的字符串,找不到数据库函数支持,自己写了一个,实测好用! /*类似find_in_set,按英文逗号拆分字段,找出指定的旧字符串,替换成新字…...
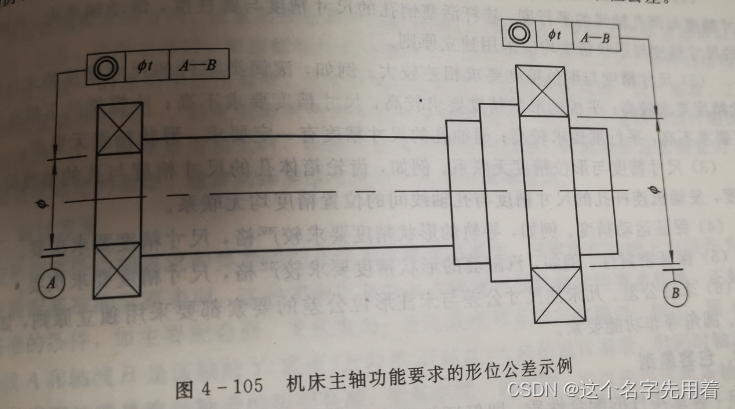
机械设计手册第一册:公差
形位公差的标注: 形位公差框格中,不仅要表达形位公差的特征项目、基准代号和其他符号,还要正确给出公差带的大小、形状等内容。 1.形位公差框格: 形位公差框格由两个框格或多个格框组成,框格中的主要内容从左到右按…...

如何把图片保存成16位png格式?
在进行图像处理的过程中,见过8位和24位的图片,然而还没见过16位的,其实也有,比如对于灰度图,就是相当于利用65535个灰度级进行灰度存储。而8位就是256个位置存储。相当于就是0-255. 今天尝试了巨久,用pyth…...

vue 关闭页面前释放资源
mounted() {window.addEventListener(beforeunload, e > this.handleBeforeUnload(e)) }beforeDestroy() {//监听-关闭页面的时候释放资源window.removeEventListener(beforeunload, e > this.handleBeforeUnload(e))},methods: {handleBeforeUnload(event){event.preven…...

堡垒机,日志审计系统,行为管理,漏洞扫描的作用
堡垒机 日志审计 行为管理 漏洞扫描 堡垒机和防火墙的区别主要体现在以下几个方面: 功能不同:堡垒机主要用于管理和控制服务器访问权限,提供安全的登录通道和权限控制,还可以记录并监控用户对服务器的所有操作,为后…...

JVM学习-自定义类加载器
为什么要自定义类加载器 隔离加载类 在某些框架内进行中间件与应用的模块隔离,把类加载到不同的环境,如Tomcat这类Web应用服务器,内部自定义了好几种类加载器,用于隔离同一个Web应用服务器上的不同应用程序 修改类加载的方式 …...

NDIS Filter开发-OID 请求
NDIS 定义对象标识符 (OID) 值来标识适配器参数,其中包括操作参数,例如设备特征、可配置的设置和统计信息。 Filter驱动程序可以查询或设置基础驱动程序的操作参数,或过滤/覆盖顶层驱动程序的 OID 请求。 NDIS 还为 NDIS 6.1 及更高版本的Fi…...

软考 系统架构设计师之考试感悟2
接前一篇文章:软考 系统架构设计师之考试感悟 今天是2024年5月25号,是个人第二次参加软考系统架构师考试的正日子。和上次一样,考了一天,身心俱疲。天是阴的,心是沉的,感觉比上一次更加沉重。仍然有诸多感悟…...

[学习笔记](b站视频)PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】(ing)
视频来源:PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】 前面P1-P5属于环境安装,略过。 5-6.Pytorch加载数据初认识 数据文件: hymenoptera_data # read_data.py文件from torch.utils.data import Dataset …...

Flutter开发效率提升1000%,Flutter Quick教程之定义构造参数和State成员变量
一个Flutter页面,可以定义页面构造参数和State成员变量。所谓页面构造参数,就是当前页面构造函数里面的参数。 比如下面代码,a就是构造参数,a1就是State成员变量。 class Testpage extends StatefulWidget {String a;const Test…...

Unity接入Google Play Games完整避坑指南
1. 这不是“接个SDK”那么简单:为什么Unity项目接入Google Play Games常卡在第三步就崩了你肯定见过那种教程——标题写着“三分钟接入Google Play Games”,点进去第一行就是“下载插件、拖进Assets、调用PlayGamesPlatform.Activate()”,然后…...

突破内存瓶颈:HBM、CXL与GPU新部署策略
训练生成式AI模型本身已是一项成本高昂、能耗巨大的工作。随着超大规模数据中心和前沿研究机构竞相扩展边缘推理与智能体AI能力,GPU的部署正变得愈加复杂,尤其是在内存层面。在数据中心中,对先进内存配置的需求日益迫切。不断增多的AI处理器正…...

免费在线去水印软件怎样选择?2026 优缺点对比及推荐指南
随着内容创作和素材收集的日常化,去水印的需求越来越普遍。一张素材上的水印、一段视频中的平台标志,都可能影响二次创作或个人使用的体验。市面上的去水印方案从专业软件到在线工具五花八门,选择合适的工具需要了解各自的特点和适用场景。本…...

计算机视觉与深度学习融合的群养猪行为识别与分类算法【附算法】
✨ 长期致力于计算机视觉、深度学习、攻击识别、多物体玩耍识别、饮水和玩耍饮水器分类、进食识别、行为量化研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1&…...

Notepad2-mod终极指南:掌握这款高效开源文本编辑器的深度开发与扩展
Notepad2-mod终极指南:掌握这款高效开源文本编辑器的深度开发与扩展 【免费下载链接】notepad2-mod LOOKING FOR DEVELOPERS - Notepad2-mod, a Notepad2 fork, a fast and light-weight Notepad-like text editor with syntax highlighting 项目地址: https://gi…...

Cocos学习笔记:帧动画制作与动画编辑器使用
一、帧动画基础原理核心逻辑:帧动画本质是逐帧替换精灵(Sprite)的显示图片,通过控制图片切换频率,让静态序列图呈现连续动态效果。视觉原理:人眼存在视觉残留特性,短时间内连续播放 24 帧以上图…...
)
别再被‘pip不是内部命令’搞懵了!Python新手必看的pip安装与修复保姆级教程(附ensurepip用法)
Python包管理革命:从pip失效到ensurepip的深度实践指南 为什么你的pip命令突然"罢工"了? 刚接触Python的新手们常常会遇到一个令人抓狂的问题——昨天还能正常使用的pip命令,今天突然提示"不是内部或外部命令"。这就像突…...
打包成安卓/鸿蒙APP)
保姆级教程:将训练好的YOLOv5s模型(PyTorch 1.7)打包成安卓/鸿蒙APP
从YOLOv5模型到移动端应用:全流程实战指南 1. 环境准备与模型导出 在开始将YOLOv5模型部署到移动端之前,确保你的开发环境已经准备就绪。对于PyTorch 1.7用户,需要特别注意版本兼容性问题。以下是推荐的环境配置: 操作系统&#x…...

别再死记硬背真值表了!用C++和Verilog代码实战,5分钟搞懂所有逻辑门
用代码实战解锁逻辑门:从C到Verilog的沉浸式学习 第一次接触数字逻辑时,那些密密麻麻的真值表总让人望而生畏。与其机械记忆,不如打开代码编辑器,让程序运行结果告诉你逻辑门的秘密。本文将带你用两种语言(C和Verilog&…...

ETS2LA自动驾驶插件:为《欧洲卡车模拟2》带来智能车道保持与模块化AI驾驶体验
ETS2LA自动驾驶插件:为《欧洲卡车模拟2》带来智能车道保持与模块化AI驾驶体验 【免费下载链接】Euro-Truck-Simulator-2-Lane-Assist Plugin based interface program for ETS2/ATS. 项目地址: https://gitcode.com/gh_mirrors/eur/Euro-Truck-Simulator-2-Lane-A…...