[学习笔记](b站视频)PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】(ing)
视频来源:PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
前面P1-P5属于环境安装,略过。
5-6.Pytorch加载数据初认识
数据文件: hymenoptera_data
# read_data.py文件from torch.utils.data import Dataset
from PIL import Image
import osclass MyData(Dataset):def __init__(self, root_dir, label_dir):self.root_dir = root_dirself.label_dir = label_dirself.path = os.path.join(self.root_dir, self.label_dir)self.img_path = os.listdir(self.path)def __getitem__(self, idx):img_name = self.img_path[idx]img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)img = Image.open(img_item_path)label = self.label_dirreturn img, labeldef __len__(self):return len(self.img_path)root_dir = "dataset/train"
ants_label_dir = "ants"
bees_label_dir = "bees"
ants_dataset = MyData(root_dir, ants_label_dir)
bees_dataset = MyData(root_dir, bees_label_dir)train_dataset = ants_dataset + bees_dataset
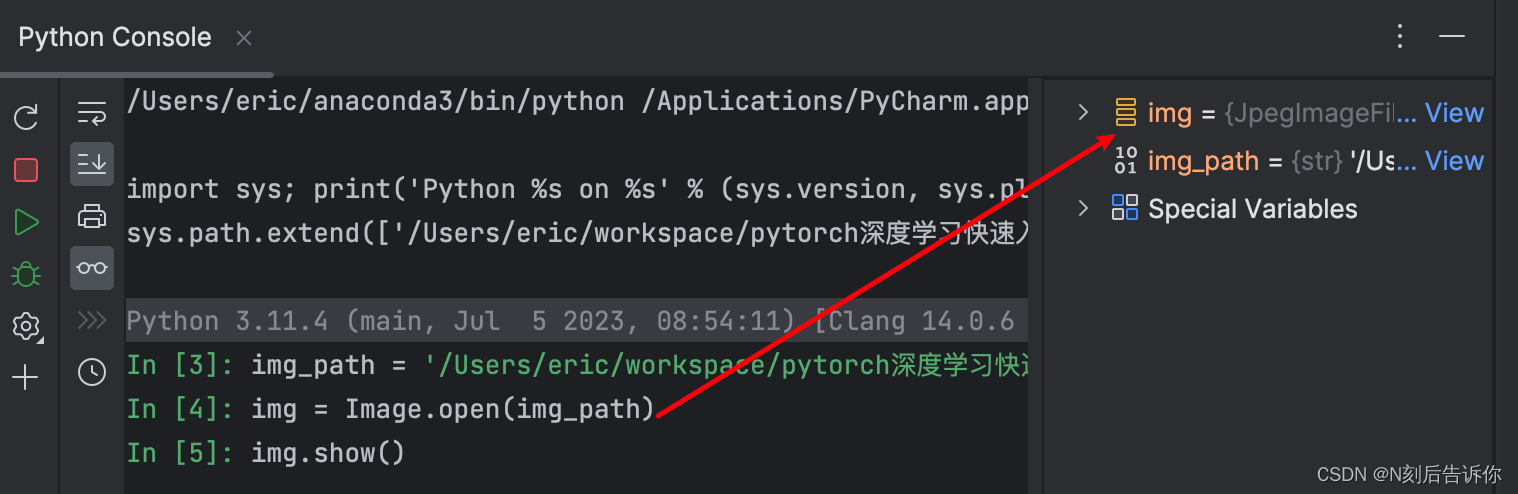
1.在jupytrer notebook中,可以使用
help(xxx)或者xxx??来获取帮助文档。
2.__init__方法主要用于声明一些变量用于后续类内的方法。
3.python console可以显示变量的值,所以建议使用它来进行调试。
x.使用os.path.join()来拼接路径的好处是:适配windows和linux。
7-8.TensorBoard的使用
add_scalar
# tb.pyfrom torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter("logs")for i in range(100):writer.add_scalar("y=x", i, i)writer.close()
不要以
test+其他字符作为.py文件的文件名(test.py是可以的),这会导致报empty suite(没有测试用例)。
详细参考:笔记19:在运行一个简单的carla例程时,报错 Empty Suite
SummaryWriter(log_dir, comment, ...)实例化时,log_dir是可选参数,表示事件文件存放地址。comment也是可选参数,会扩充事件文件的存放地址后缀。
add_scalar(tag, scalar_value, global_steap)调用时,tag是标题(标识符),scaler_value是y轴数值,gloabl_step是x轴数值。
# shell
tensorboard --logdir=logs --port=6007
一般上述命令打开6006端口,但如果一台服务器上有好几个人打开tensorboard,会麻烦。所以
--port=6007可以指定端口。
如果两次写入的scalar写入的tag是相同的,那么两次scalar会在一个图上。
add_image
# P8_Tensorboard.py
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as npwriter = SummaryWriter("logs")
image_path = 'dataset/train/ants/0013035.jpg'
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)writer.add_image('test', img_array, 1, dataformats='HWC')writer.close()
add_image(tag, img_tensor, global_steap)调用时,img_tensor需要是torch.Tensor, numpy.ndarray或string等。
add_image默认匹配的图片的大小是(3, H, W),如果大小是(H, W, 3),需要添加参数dataformats='HWC'
9-13.Transforms的使用
# P9_Transformsfrom PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformsimg_path = 'dataset/train/ants/0013035.jpg'
img = Image.open(img_path) # 得到PIL类型图片
# 这里也可以通过cv2.imread()读取图片,转化为nd.arraywriter = SummaryWriter('logs')tensor_trans = transforms.ToTensor()
tensor_img = tensor_trans(img) # ToTensor支持PIL、nd.array图片类型作为输入writer.add_image('Tensor_img', tensor_img)writer.close()
对于一个模块文件,如transforms.py,可以借助pycharm的Structure快速了解其中定义的class类。
pip install opencv-python之后才能import cv2
Image.open()返回的是PIL类型的图片。cv2.imread()返回的是nd.array类型的图片。

常见的Transforms
类里面的__call__方法的作用是:使得实例化对象可以像函数一样被调用。
ToTensor
作用:将PIL,nd.array转化为Tensor类型。
这个对象的输入可以是PIL图像,也可以是np.ndarray。
Normalize
作用:对tensor格式的图像做标准化。需要多通道的均值和多通道的标准差。
这个对象的输入必须是tensor图像。
Resize
作用:变更大小。如果size的值是形如(h, w)的序列,则输出的大小就是(h, w)。如果size的值是一个标量,则较小的边长变成该标量,另一个边长成比例缩放。
这个对象的输入可以是PIL图像,也可以是np.array
(这意味着cv2.imread得到的ndarray也可以作为输入)。(之前的版本只能是PIL图像)
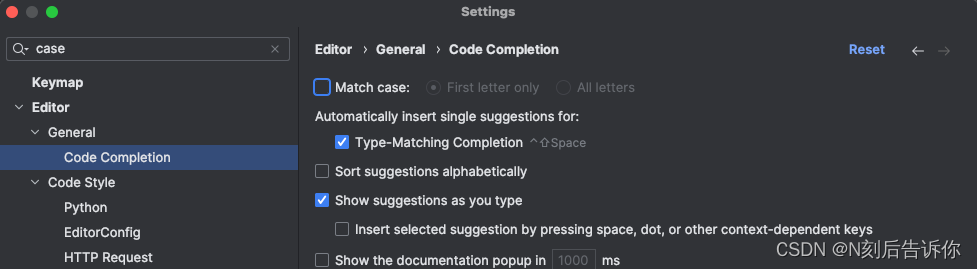
设置大小写不敏感的代码补缺:通过搜索settings->Editor->General->Code Completion,取消对Match Case的勾选
Compose
作用:组合各种transforms.xx
RandomCrop
作用:随机裁剪
代码实现
# P9_Transforms.pyfrom PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformsimg_path = 'dataset/train/ants/0013035.jpg'
img = Image.open(img_path)writer = SummaryWriter('logs')# ToTensor
trans_totensor = transforms.ToTensor()
tensor_img = trans_totensor(img) # ToTensor支持PIL图片类型作为输入
writer.add_image('Tensor_img', tensor_img)# Normalize
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(tensor_img) # 标准化
writer.add_image('Normalize', img_norm)# Resize
trans_resize = transforms.Resize((512, 512))
# img PIL -> resize -> img_resize PIL
img_resize = trans_resize(img)
# img_resize PIL -> resize -> img_resize tensor
img_resize = trans_totensor(img_resize)
writer.add_image('Resize', img_resize, 0)# Compose - resize - 2
trans_resize_2 = transforms.Resize(512)
# PIL -> PIL -> tensor
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image('Resize', img_resize_2, 1)# RandomCrop
trans_random = transforms.RandomCrop(50)
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):img_crop = trans_compose_2(img)writer.add_image('RandomCrop', img_crop, i)writer.close()
总结:
主要关注输入和输出。
多看官方文档
关注方法需要的参数
14.torchvision中的数据集使用
本节介绍如何将torchvision的数据集和transforms结合起来。
# P10_dataset_transformsimport torchvision
from torch.utils.tensorboard import SummaryWriter
from torchvision import transformsdataset_transform = transforms.Compose([transforms.ToTensor()])train_set = torchvision.datasets.CIFAR10(root="./dataset", train=True, transform=dataset_transform, download=True
)
test_set = torchvision.datasets.CIFAR10(root="./dataset", train=False, transform=dataset_transform, download=True
)writer = SummaryWriter("p10")
for i in range(10):img, target = test_set[i]writer.add_image("test_set", img, i)writer.close()
15.DataLoader的使用
参考资料:torch.utils.data.DataLoader
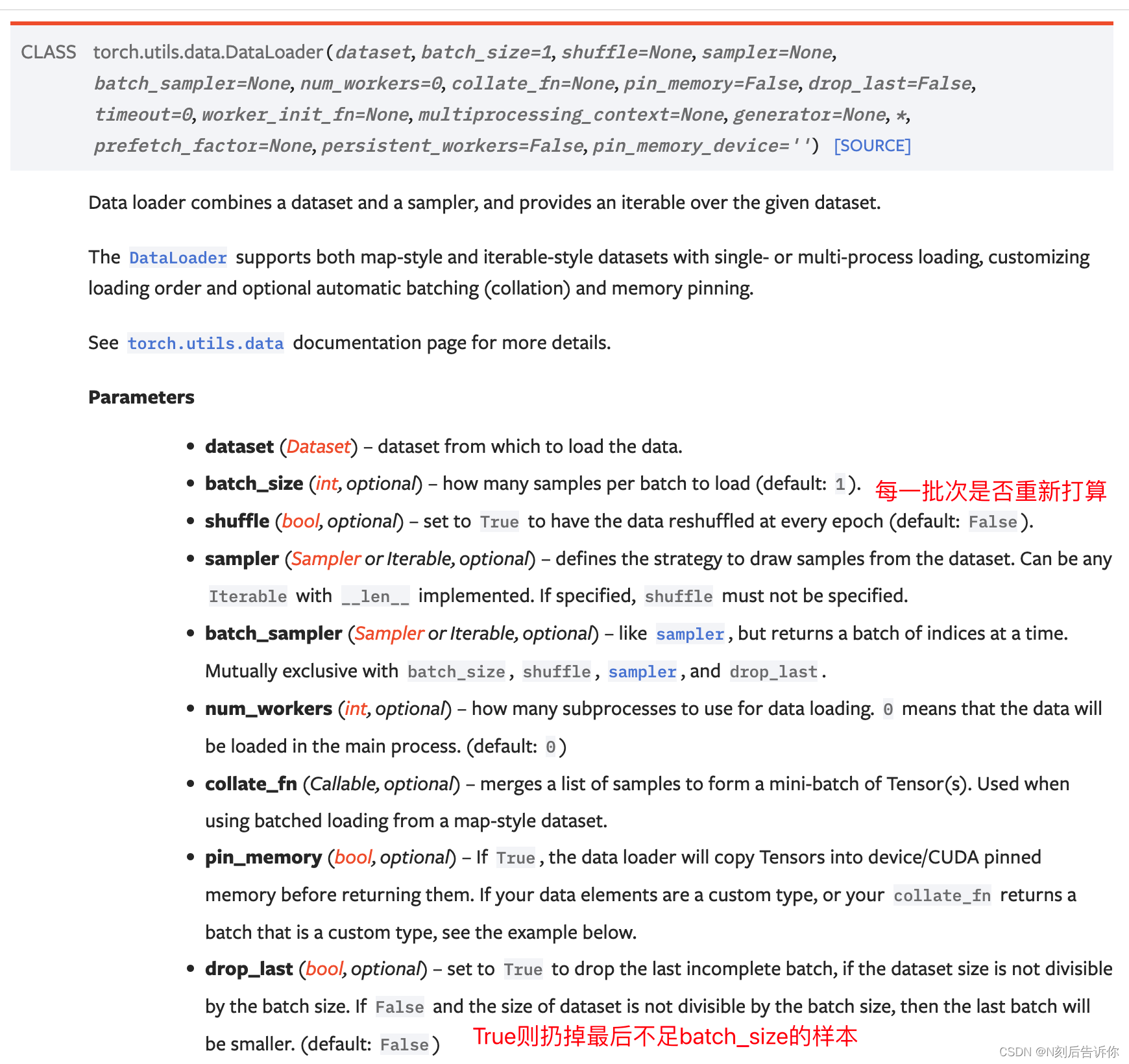
# dataloaderimport torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWritertest_data = torchvision.datasets.CIFAR10('./dataset', train=False, transform=torchvision.transforms.ToTensor())test_loader = DataLoader(test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)# 测试数据集中第一张图片及target
img, target = test_data[0]
# print(img.shape) # (3, 32, 32)
# print(target) # 3writer = SummaryWriter("dataloader")
step = 0
for data in test_loader:imgs, targets = data# print(imgs.shape) # (4, 3, 32, 32)# print(targets) # [2, 7, 2, 2]writer.add_images('test_data', imgs, step) # 多张图片用add_imagesstep += 1writer.close()
16.神经网络的基本骨架-nn.Module的使用

按照上面的模版,定义模型名,继承Module类,重写forward函数。下面写一个例子。(这一节比较简单)
import torch
from torch import nnclass Tudui(nn.Module):def __init__(self, *args, **kwargs) -> None:super().__init__(*args, **kwargs)def forward(self, input):output = input + 1return outputtudui = Tudui()
x = torch.tensor(1.0)
output = tudui(x)
print(output)
17.卷积
第17个视频主要通过torch.nn.functional.conv2d来介绍stride和padding。这里略过。
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoaderdataset = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor(), download=True
)dataloader = DataLoader(dataset, batch_size=64)class Tudui(nn.Module):def __init__(self):super().__init__()self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)def forward(self, x):x = self.conv1(x)return xtudui = Tudui()
for data in dataloader:imgs, targets = dataoutput = tudui(imgs)print(imgs.shape)print(output.shape)
相关文章:
[学习笔记](b站视频)PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】(ing)
视频来源:PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】 前面P1-P5属于环境安装,略过。 5-6.Pytorch加载数据初认识 数据文件: hymenoptera_data # read_data.py文件from torch.utils.data import Dataset …...

Flutter开发效率提升1000%,Flutter Quick教程之定义构造参数和State成员变量
一个Flutter页面,可以定义页面构造参数和State成员变量。所谓页面构造参数,就是当前页面构造函数里面的参数。 比如下面代码,a就是构造参数,a1就是State成员变量。 class Testpage extends StatefulWidget {String a;const Test…...

R语言数据分析-xgboost模型预测
XGBoost模型预测的主要大致思路: 1. 数据准备 首先,需要准备数据。这包括数据的读取、预处理和分割。数据应该包括特征和目标变量。 步骤: 读取数据:从CSV文件或其他数据源读取数据。数据清理:处理缺失值、异常值等…...

使用redis的setnx实现分布式锁
在Redis中,SETNX 是 “Set If Not Exists”(如果不存在,则设置)的缩写。这是一个原子操作,用于设置一个键的值,前提是这个键不存在。如果键已经存在,.则不会执行任何操作。 封装方法trylock,用…...

LangChain进行文本摘要 总结
利用LangChain进行文本摘要的详细总结 LangChain是一个强大的工具,可以帮助您使用大型语言模型(LLM)来总结多个文档的内容。以下是一个详细指南,介绍如何使用LangChain进行文本摘要,包括使用文档加载器、三种常见的摘…...
政安晨【零基础玩转各类开源AI项目】:解析开源项目的论文:Physical Non-inertial Poser (PNP)
政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: 零基础玩转各类开源AI项目 希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正! 本文解析的原始论文为:https://arxiv.org/…...
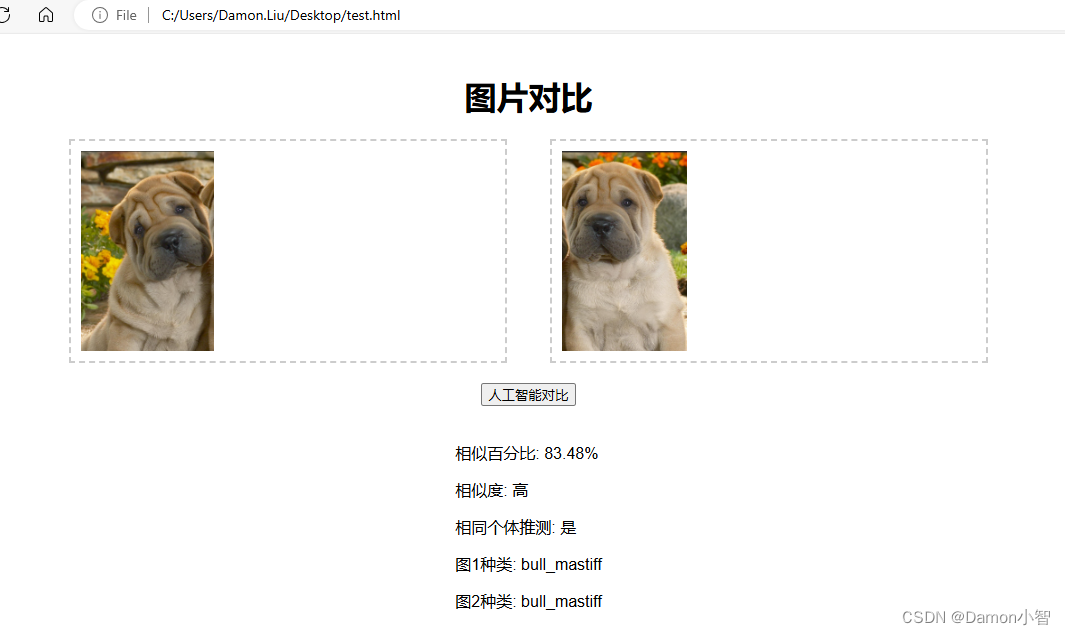
【机器学习】基于OpenCV和TensorFlow的MobileNetV2模型的物种识别与个体相似度分析
在计算机视觉领域,物种识别和图像相似度比较是两个重要的研究方向。本文通过结合深度学习和图像处理技术,基于OpenCV和TensorFlow的MobileNetV2的预训练模型模,实现物种识别和个体相似度分析。本文详细介绍该实验过程并提供相关代码。 一、名…...
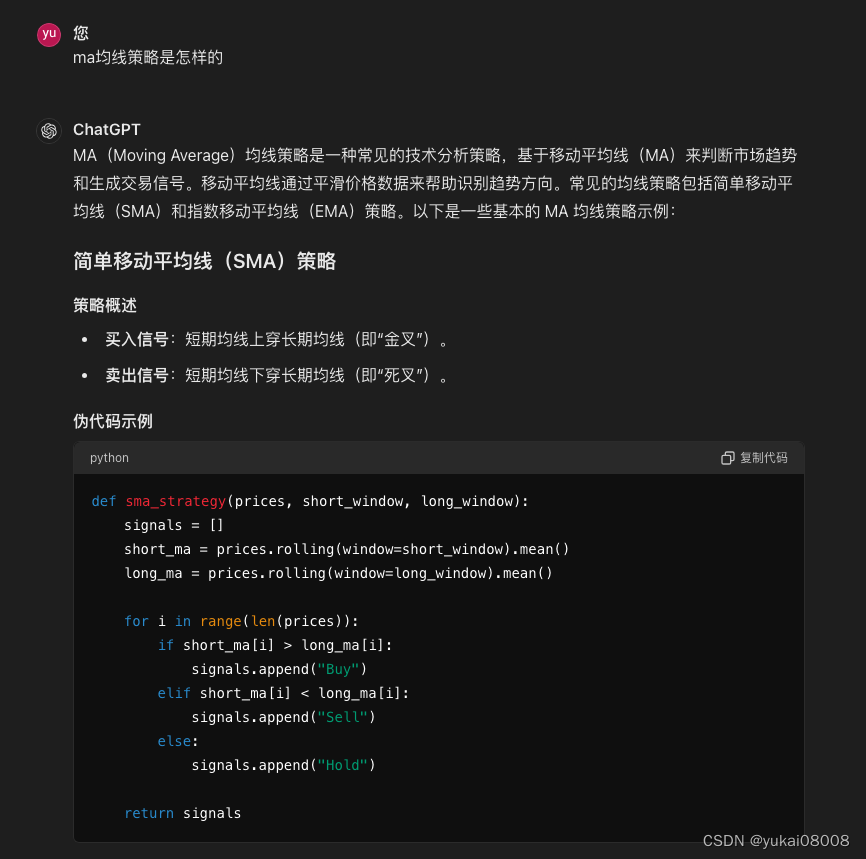
建模杂谈系列244 TimeTraveller
说明 所有的基于时间处理和运行的程序将以同样的节奏同步和执行 TT(TimeTraveller)是一个新的设计,它最初会服务与量化过程的大量任务管理:分散开发、协同运行。但是很显然,TT的功能将远不止于此,它将服务大量的,基于时…...
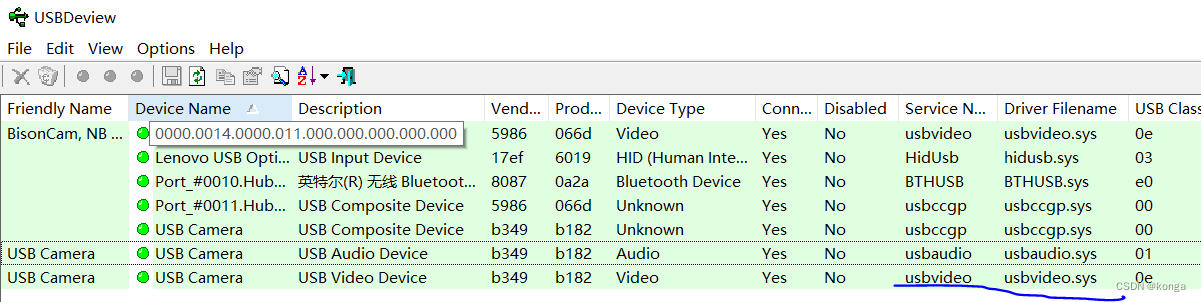
基于MingGW64 GCC编译Windows平台上的 libuvc
安装cmake 打开cmake官网 https://cmake.org/download/,下载安装包: 安装时选择将cmake加到系统环境变量里。安装完成后在新的CMD命令窗口执行cmake --version可看到输出: D:\>cmake --version cmake version 3.29.3 CMake suite mainta…...

【Linux】网络高级IO
欢迎来到Cefler的博客😁 🕌博客主页:折纸花满衣 🏠个人专栏:Linux 目录 👉🏻五种IO模型👉🏻消息通信的同步异步与进程线程的同步异步有什么不同?👉…...
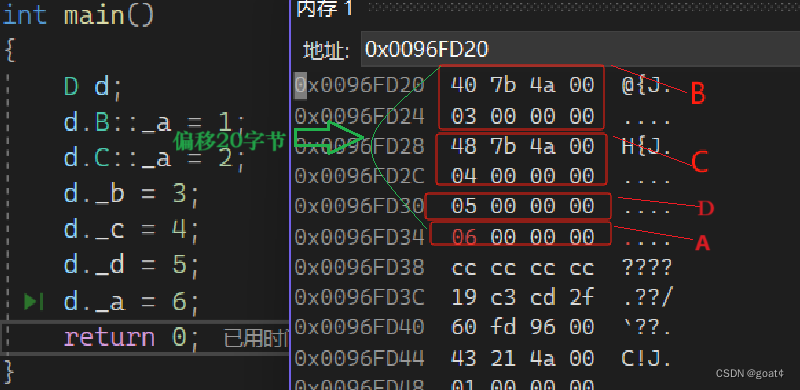
【C++ ——— 继承】
文章目录 继承的概念即定义继承概念继承定义定义格式继承关系和访问限定符继承基类成员访问方式的变化 基类对象和派生类对象的赋值转换继承中的作用域派生类中的默认成员函数继承与友元继承与静态成员菱形继承虚继承解决数据冗余和二义性的原理继承的总结继承常见笔试面试题 继…...
kafka-守护启动
文章目录 1、kafka守护启动1.1、先启动zookeeper1.1.1、查看 zookeeper-server-start.sh 的地址1.1.2、查看 zookeeper.properties 的地址 1.2、查看 jps -l1.3、再启动kafka1.3.1、查看 kafka-server-start.sh 地址1.3.2、查看 server.properties 地址 1.4、再次查看 jps -l 1…...

TypeScript 中的命名空间和模块化
1. 命名空间(Namespace) 命名空间提供了一种逻辑上的代码分组机制,用于避免命名冲突和将相关代码组织在一起。它使用 namespace 关键字来定义命名空间,并通过点运算符来访问其中的成员。例如: // 定义命名空间 names…...

9 html综合案例-注册界面
9 综合案例-注册界面 一个只有html骨架的注册页面 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>…...
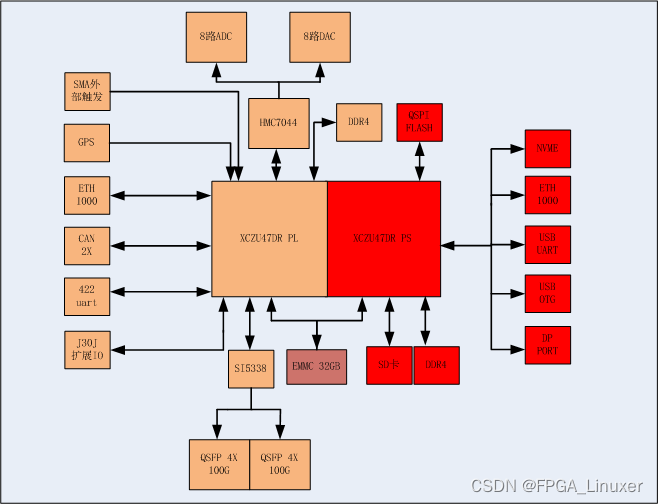
Xilinx RFSOC 47DR 8收8发 信号处理板卡
系统资源如图所示: FPGA采用XCZU47DR 1156芯片,PS端搭载一组64Bit DDR4,容量为4GB,最高支持速率:2400MT/s; PS端挂载两片QSPI X4 FLASH; PS支持一路NVME存储; PS端挂载SD接口,用于存储程序&…...

ros2 launch 用法以及一些基础功能函数的示例
文章目录 launch启动一个节点的launch示例launch文件中添加节点的namespacelaunch文件中的话题名称映射launch文件中向节点内传入命令行参数launch文件中向节点内传入rosparam使用方法多节点启动命令行参数配置资源重映射ROS参数设置加载参数文件在launch文件中使用条件变量act…...

如何使用Python获取图片中的文字信息
如下有三中方法: 方法1. 使用Tesseract OCR(pytesseract) 安装依赖 首先,确保你已经安装了Tesseract OCR引擎(例如,通过你的操作系统的包管理器)。然后,你可以通过pip安装pytesse…...

C++知识点
1. 构造函数:当没有写任何构造函数(含拷贝构造),系统会生成默认的无参构造,并且访问属性是共有。 默认拷贝构造:当没有写任何的拷贝构造,系统会生成默认的拷贝构造->是一个浅拷贝 写了拷贝构造函数,这…...

反转字符串中的单词-力扣
此题将问题分为三步进行解决: 第一步,删除字符串中多余的空格,removeSpaces函数中删除所有的空格,并手动在每个单词后添加一个空格,最后重构字符串s第二步,将整个字符串反转第三步,对反转后的字…...

Kotlin 重写与重载
文章目录 重写(Override)重载(Overload) 重写(Override) 重写通常是指子类覆盖父类的属性或方法,通常会标记为override: open class Base {open val name "Base"open f…...

linuxcnc开发环境搭建
linux cnc ,数控机床开源控制软件,实时系统。下载linuxcnc.iso镜像,在虚拟机里安装。安装成功运行起来。安装了amd64版本的qtcreator运行提示少libxcb:sudo apt update sudo apt install libxcb-cursor0打开窗口成功新建 一个工程…...

Unity接入Google Play Games完整避坑指南
1. 这不是“接个SDK”那么简单:为什么Unity项目接入Google Play Games常卡在第三步就崩了你肯定见过那种教程——标题写着“三分钟接入Google Play Games”,点进去第一行就是“下载插件、拖进Assets、调用PlayGamesPlatform.Activate()”,然后…...
)
2026 软考中级《多媒体应用设计师》备考全攻略(附全套资料)
大家好,最近很多朋友问我软考多媒体应用设计师的备考方法和资料整理问题,今天就把我自己整理的备考资料和实用经验一次性分享给大家,帮你少走弯路,高效备考~ 📚 我的备考资料整理(4 大模块全覆…...

2026企业网盘选型对比:坚果云领衔,5款主流产品优劣与场景建议
随着企业数字化办公不断加深,企业网盘已从“文件存储工具”演变为“组织级协作平台”。到2026年,各厂商在同步机制、协作效率、权限体系与安全合规方面差距进一步拉大。本文对5款主流企业网盘做横向对比,帮助管理者按业务场景选到更合适的方案…...

ROCm rocr-libhsakmt分析系列3: aperture概念
前文 acquire_vm 讲了gpu vm的概念,gpu vm就是一个GPU虚拟地址空间。那么偌大的一个空间,我们该如何使用它呢?仍然可以类比进程的虚拟地址空间,例如,进程的虚拟地址空间按功能划分成了多个段:代码段、全局变量段、栈区、堆区、文件mmap区等,每个段占用互不相交的虚拟地址…...

为什么 AI 多智能体系统最终都会遇到“混乱边界”?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...

5个实战技巧:如何将YOLOv8人脸检测模型高效部署到生产环境
5个实战技巧:如何将YOLOv8人脸检测模型高效部署到生产环境 【免费下载链接】yolov8-face yolov8 face detection with landmark 项目地址: https://gitcode.com/gh_mirrors/yo/yolov8-face YOLOv8人脸检测模型在密集人群、动态表情和复杂场景下展现出卓越的识…...

如何快速掌握TegraRcmGUI:Windows上最简单的Switch注入工具终极指南
如何快速掌握TegraRcmGUI:Windows上最简单的Switch注入工具终极指南 【免费下载链接】TegraRcmGUI C GUI for TegraRcmSmash (Fuse Gele exploit for Nintendo Switch) 项目地址: https://gitcode.com/gh_mirrors/te/TegraRcmGUI 想要在Nintendo Switch上体验…...

2026AI论文写作工具实测排行榜!这几款才是真神器
综合评分 TOP4 为千笔AI(99/100)、毕业之家 (96/100)、DeepSeek Scholar(89/100)、豆包学术版 (88/100)。千笔AI是全流程全能王,毕业之家专注学术合规,DeepSeek 是理工科免费神器,豆包擅长多模态与文献分析。一、测评标准说明(202…...
)
仅限本周开放|Lovable高阶工程化实践内部培训课件(含模块化架构图、依赖注入容器源码注释版)
更多请点击: https://codechina.net 第一章:Lovable应用开发完整教程 Lovable 是一个面向现代 Web 应用的轻量级响应式框架,专为构建高交互性、可访问性强且易于维护的单页应用(SPA)而设计。它采用声明式组件模型与响…...