MySQL之创建高性能的索引(四)
创建高性能的索引
空间数据索引(R-Tree)
MyISAM表支持空间索引,可以用作地理数据存储。和B-Tree索引不同,这类索引无须前缀查询。空间索引会从所有维度来索引数据。查询时,可以有效地使用任意维度来组合查询。必须使用MySQL的GIS相关函数如MBRCONTAINS()等来维护数据。MySQL的GIS支持并不完善,所以大部分人都不会使用这个特性。开源关系数据库系统中对GIS的解决方案做得比较好的是PostgreSQL的PostGIS.
全文索引
全文索引是一种特殊类型的索引,它查找的是文本中的关键词,而不是直接比较索引中的值。全文搜索和其他几类索引的匹配方式完全不一样。它有许多需要注意的细节,如停用词、词干和复数、布尔搜索等。全文索引更类似于搜索引擎作得事情,而不是简单的WHERE条件匹配。
在相同的列上同时创建全文索引和基于值得B-Tree索引不会有冲突,全文索引适用于MATCH AGAINST操作,而不是普通得WHERE条件操作
索引的优点
索引可以让服务器快速地定位到表的指定位置。但是这并不是索引的唯一作用,到目前为止可以看到,根据创建索引的数据结构不同,索引也有一些其他的附加作用。最常见的B-Tree索引,按照顺序存储数据,所有MySQL可以用来做ORDER BY 和GROUP BY操作。因为数据是有序的,所以B-Tree也就会将相关的列值存储在一起。最后,因为索引中存储了实际的列值,所以某些查询只使用索引就能够完成全部查询。据此特性,总结下来索引有如下三个优点:
- 1.索引大大减少了服务器需要扫描的数据量
- 2.索引可以帮助服务器避免排序和临时表
- 3.索引可以将随机IO变为顺序IO
索引这个主题完全值得单独写一本书,如果想深入理解这部分内容,强烈建议阅读由Tapio Lahdenmaki和Mike Leach编写的Relational Database Index Design and the Optimizers(Wiley出版社)一书,该书详细介绍了如何计算索引的成本和作用、如何评估查询速度、如何分析索引维护的代价和其带来的好处等.Lahdenmaki和Leach在书中介绍了如何评价一个索引是否适合某个查询的"三星系统"(three-star system):索引将相关的记录放到一起则获得一星;如果索引中的数据顺序和查找的排列顺序一致则获得二星;如果索引中的列包含了查询中需要的全部列则获得三星
索引是最好的解决方案吗?
索引并不总是最好的工具。总的来说,只有当索引帮助存储引擎快速查找到记录带来的好处大于其带来的额外工作时,索引才是有效地。对于非常小的表,大部分情况下简单的全表扫描更高效。对于中到大型的表,索引就非常有效。但对于大型的表,建立和使用索引的代价将随之增长。这种情况下,则需要一种技术可以直接区分出查询需要的一组数据,而不是一条记录一条记录地匹配。例如可以使用分区技术。如果表的数量特别多,可以建立一个元数据信息表,用来查询需要用到的某些特性。例如执行那些需要聚合多个应用分布在多个表的数据的查询,则需要记录"哪个用户的信息存储在哪个表中"的元数据,这样在查询时就可以直接忽略那些不包含指定用户信息的表。对于大型系统,这是一个常用的技巧,事实上,Infobright就是使用类似的实现。对于TB级别的数据,定位单条记录的意义不大,所以经常会使用块级别元数据技术来替代索引
高性能的索引策略
正确地创建和使用索引是实现高性能查询的基础。前面已经介绍了各种类型的索引及其对应的优缺点。现在一起来看看如何真正地发挥这些索引的优势。
高效地选择和使用索引有很多种方式,其中有些是针对特殊案例的优化方法,有些则是针对特定行为的优化。使用哪个索引,以及如何评估选择不同索引的性能影响的技巧,则需要持续不断地学习。
独立的列
我们通常会看到一些查询不当地使用索引,或者使得MySQL无法使用已有的索引。如果查询中的列不是独立的,则MySQL就不会使用索引。"独立的列"是指索引不能是表达式的一部分,也不能是函数的参数。例如,下面这个查询无法使用actor_id列的索引:
mysql> SELECT actor_id FROM actor WHERE actor_id + 1 =5;
凭肉眼很容易看出WHERE中的表达式其实等价于actor_id=4,但是MySQL无法自动解析这个方程式。这完全是用户行为。我们应该养成简化WHERE条件的习惯,始终将索引列单独放在比较符号的一侧。下面是另一个常见的错误:
mysql> SELECT .... WHERE TO_DAYS(CURRENT_DATE) - TO_DAYS(date_col) <= 10;
前缀索引和索引选择性
有时候需要索引很长的字符列,这会让索引变得大且慢。一个策略是前面提到过的模拟哈希索引。但有时候这样做还不够,还可以做些什么呢?
通常可以索引开始的部分字符,这样可以大大节约索引空间,从而提高索引效率。但这样也会降低索引的选择姓。索引的选择性是指,不重复的所引致(也成为技术,cardinality)和数据表的记录总数(#T)的比值。范围从1/#T到1之间。索引的选择性越高则查询效率越高,因为选择性高的索引可以让MySQL在查找时过滤掉更多的行。唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
一般情况下某个列前缀的选择性也是足够高的,足以满足查询性能。对于BLOB、TEXT或者很长的VARCHAR类型的列,必须使用前缀索引,因为MySQL不允许索引这些列的完整长度。诀窍在于要选择足够长的前缀以保证较高的选择性,同时又不能太长(以便节约空间)。前缀应该足够长,以使得前缀索引的选择性接近于索引整个列。换句话说,前缀的"技术"应该接近于完整列的"基数"。为了决定前缀的合适长度,需要找到最常见的值得列表,然后和最常见得前缀列表进行比较。(MySQL Sakila官方链接http://downloads.mysql.com/docs/sakila-db.zip)大家可以下载下来导入进去。这里从表city中生成一个示例表,这样就有足够得数据进行演示:
use sakila;
CREATE TABLE city_demo(city VARCHAR(50) NOT NULL);INSERT INTO city_demo(city) SELECT city FROM city;INSERT INTO city_demo(city) SELECT city FROM city_demo;# 执行五次UPDATE city_demo SET city = (SELECT city FROM city ORDER BY RAND() LIMIT 1);
现在我们有了示例数据集。数据分布当然不是真实得分布;因为我们使用了RAND().所以你的结果会与此不同,但对这个例子说这并不重要。首先,我们找到最常见的城市列表:
mysql> SELECT COUNT(*) AS cnt,city FROM city_demo GROUP BY city ORDER BY cnt DESC LIMIT 10;
+-----+-------------+
| cnt | city |
+-----+-------------+
| 64 | London |
| 50 | Bagé |
| 49 | Brockton |
| 48 | Soshanguve |
| 47 | Bucuresti |
| 47 | El Alto |
| 47 | Balašiha |
| 46 | Osmaniye |
| 46 | Arecibo |
| 45 | Santo André |
+-----+-------------+
10 rows in set (0.09 sec)
注意到,上面每隔值都出现了45~64次。现在查找结果最频繁出现的城市前缀,先从前3个前缀字母开始:
mysql> SELECT COUNT(*) AS cnt, LEFT(city, 3) AS pref FROM city_demo GROUP BY pref ORDER BY cnt DESC LIMIT 10;
+-----+------+
| cnt | pref |
+-----+------+
| 456 | San |
| 175 | Cha |
| 174 | Tan |
| 172 | Sou |
| 165 | Sal |
| 144 | al- |
| 128 | Man |
| 127 | Hal |
| 124 | Bal |
| 122 | Shi |
+-----+------+
10 rows in set (0.08 sec)
每个前缀都比原来的城市出现的次数更多,因此唯一前缀比唯一城市要少得多。然后我们增加前缀长度,直到这个前缀的选择性接近完整列的选择性。经过实验后发现前缀为7时比较合适:
mysql> SELECT COUNT(*) AS cnt, LEFT(city, 7) AS pref FROM city_demo GROUP BY pref ORDER BY cnt DESC LIMIT 10;
+-----+---------+
| cnt | pref |
+-----+---------+
| 64 | London |
| 62 | San Fel |
| 60 | Santiag |
| 58 | Valle d |
| 50 | Bagé |
| 49 | Brockto |
| 48 | Soshang |
| 47 | El Alto |
| 47 | Bucures |
| 47 | Balaših |
+-----+---------+
10 rows in set (0.08 sec)
计算合适的前缀长度的另外一个办法就是计算完整列的选择性,并使前缀的选择性接近于完整列的选择性。下面显式如何计算完整列的选择性:
mysql> SELECT COUNT(DISTINCT city)/COUNT(*) FROM city_demo;
+-------------------------------+
| COUNT(DISTINCT city)/COUNT(*) |
+-------------------------------+
| 0.0312 |
+-------------------------------+
1 row in set (0.08 sec)
通常来说(尽管也有例外情况)。这个例子中如何前缀的选择性能够接近0.031,基本上就可以可用了。可以在一个查询中针对不同前缀长度进行计算,这对于大表非常有用,下面给出了如何在同一个查询中计算不同前缀长度的选择性:
mysql> SELECT
COUNT(DISTINCT LEFT(city,3))/COUNT(*) AS sel3,COUNT(DISTINCT LEFT(city,4))/COUNT(*) AS sel4,
COUNT(DISTINCT LEFT(city,5))/COUNT(*) AS sel5,COUNT(DISTINCT LEFT(city,6))/COUNT(*) AS sel6,COUNT(DISTINCT LEFT(city,7))/COUNT(*) AS sel7
FROM city_demo;
+--------+--------+--------+--------+--------+
| sel3 | sel4 | sel5 | sel6 | sel7 |
+--------+--------+--------+--------+--------+
| 0.0237 | 0.0293 | 0.0305 | 0.0309 | 0.0310 |
+--------+--------+--------+--------+--------+
查询显式当前缀长度达到7的时候,再增加前缀长度,选择性能提升的复度已经很小了,只看平均选择性使不够的,也有例外的情况,需要考虑最坏情况下的选择性。平均选择性会让你认为前缀长度4或者5的索引已经足够了,但如果数据分布很不均匀,可能就会有陷阱。如果观察前缀为4的最常出现城市的次数,可以看到明显不均匀:
mysql> SELECT COUNT(*) AS cnt, LEFT(city,4) AS pref FROM city_demo GROUP BY pref ORDER BY cnt DESC LIMIT 5;
+-----+------+
| cnt | pref |
+-----+------+
| 203 | San |
| 190 | Sant |
| 141 | Sout |
| 98 | Chan |
| 85 | Toul |
+-----+------+
如果前缀事4个字节,则最常出现的前缀的出现次数比最常出现的城市的出现次数要大很多。即使这些值的选择性比平均选择性要地。如果有比这个随机生成的示例更真实地数据,就更有可能看到这种现象。例如在真实的城市名上建一个长度为4地前缀索引,对于以"San"和"New"开头地城市地选择性就会非常糟糕,因为很多城市都以这两个词开头。
在上面地示例中,已经找到了合适的前缀长度,下面演示如何创建前缀素银:
mysql> ALTER TABLE city_demo ADD KEY(city(7));
前缀索引是一种使索引更小、更快的有效方法,但另一方面也有其缺点:MySQL无法使用前缀索引做ORDER BY 和GROUP BY,也无法使用前缀索引做覆盖扫描。一个常见的场景使针对很长的十六进制唯一ID使用前缀索引。
有时候后缀索引(suffix index)也有用途(例如,找到某个域名的所有电子邮件地址)。MySQL原生不支持反向索引,但是可以把字符串反转后存储,并基于词建立前缀索引
相关文章:
)
MySQL之创建高性能的索引(四)
创建高性能的索引 空间数据索引(R-Tree) MyISAM表支持空间索引,可以用作地理数据存储。和B-Tree索引不同,这类索引无须前缀查询。空间索引会从所有维度来索引数据。查询时,可以有效地使用任意维度来组合查询。必须使用MySQL的GIS相关函数如…...

Python 限制输入数的范围
Python 限制输入数的范围 在 Python 编程中,我们经常需要限制用户输入的数据范围,以避免一些可能出现的问题。例如,在一个游戏程序中,我们可能想要确保玩家的分数在某个范围内,而不是太高或太低。在这个博文中&#x…...

STM32两轮平衡小车原理详解
STM32两轮平衡小车是一种基于STM32微控制器的智能机器人,它能够通过传感器和算法实现自我平衡。以下是对STM32两轮平衡小车原理的详解,以及一些基础的代码示例。 原理详解 1. 系统组成 主控制器:STM32系列微控制器,作为小车的大…...
如何评价一个数仓的好坏)
(笔记)如何评价一个数仓的好坏
如何评价一个数仓的好坏 1数据质量产生原因评估方法流程 2模型建设产生问题原因评估方法流程 3数据安全产生问题原因评估方法流程 4成本/性能产生问题原因评估方法流程 5 用户用数体验产生问题原因评估方法流程 6数据资产覆盖产生问题原因评估方法流程 数仓评价好坏是对数仓全流…...
友善RK3399v2平台利用rkmpp实现硬件编解码加速
测试VPU 编译mpp sudo apt update sudo apt install gcc g cmake make cd ~ git clone https://github.com/rockchip-linux/mpp.git cd mpp/build/linux/aarch64/ sed -i s/aarch64-linux-gnu-gcc/gcc/g ./arm.linux.cross.cmake sed -i s/aarch64-linux-gnu-g/g/g ./arm.lin…...
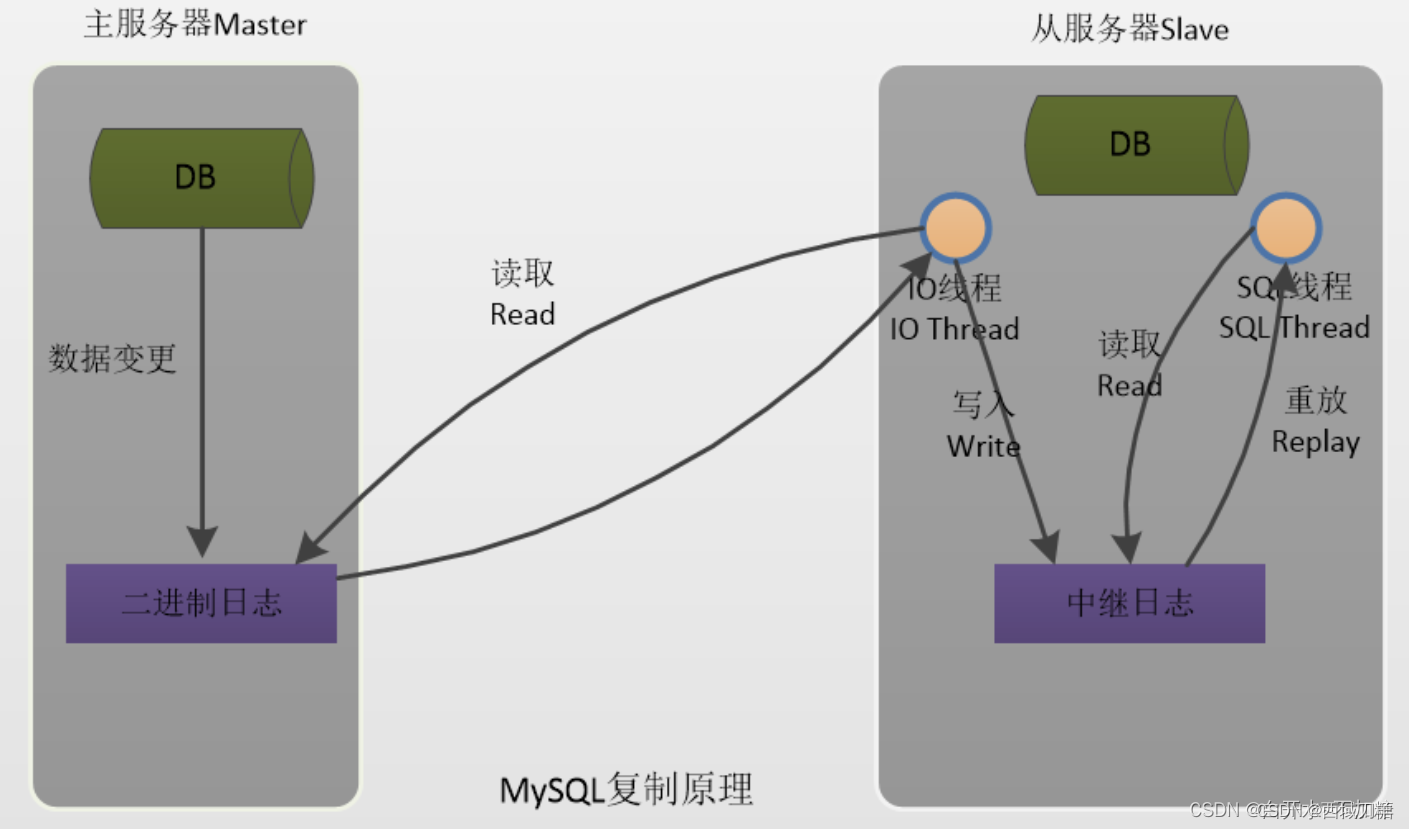
Mysql 8.0 主从复制及读写分离搭建记录
前言 搭建参考:搭建Mysql主从复制 为什么要做主从复制? 做数据的热备,作为后备数据库,主数据库服务器故障后,可切换到从数据库继续工作,避免数据丢失。架构的扩展。业务量越来越大,I/O访问频…...

PyTorch、显卡、CUDA 和 cuDNN 之间的关系
概述 PyTorch、显卡、CUDA 和 cuDNN 之间的关系及其工作原理可以这样理解: 显卡 (GPU) 显卡,特别是 NVIDIA 的 GPU,具有大量的并行处理单元,这些单元可以同时执行大量相似的操作,非常适合进行大规模矩阵运算&#x…...

Lambda 表达式练习
目录 sorted() 四种排序 List 转 Map map 映射 对象中 String 类型属性为空的字段赋值为 null BiConsumer,> T reduce(T identity, BinaryOperator accumulator) allMatch(Predicate p) groupingBy(Function f) flatMap(Function f) Optional.ofNullable(T t) 和 …...

JavaScript第七讲:数组,及练习题
目录 今天话不多说直接进入正题! 1. 创建数组对象 2. 数组长度 3. 遍历一个数组 4. 连接数组 5. 通过指定分隔符,返回一个数组的字符串表达 6. 分别在最后的位置插入数据和获取数据(获取后删除) 7. 分别在最开始的位置插入数据和获取数据(获取后删…...

从docker镜像反推Dockerfile
在项目运维的过程中,偶尔会遇到某个docker image打包时候的Dockerfile版本管理不善无法与image对应的问题,抑或需要分析某个三方docker image的构建过程,这时,就希望能够通过image反推构建时的instruction. 想实现这个过程可以使…...

车载软件架构 - AUTOSAR 的信息安全框架
车载软件架构 - AUTOSAR 的信息安全架构 我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗…...

欧洲版“OpenAI”——Mistral 举办的 AI 大模型马拉松
近期,法国的 Mistral AI 举办了一场别开生面的 AI 大模型马拉松。要知道,Mistral 可是法国对 OpenAI 的有力回应,而且其技术还是完全开源的呢!这场在巴黎举行的黑客马拉松,规模空前盛大,竟然有超过 1000 名…...

Java | Leetcode Java题解之第128题最长连续序列
题目: 题解: class Solution {public int longestConsecutive(int[] nums) {Set<Integer> num_set new HashSet<Integer>();for (int num : nums) {num_set.add(num);}int longestStreak 0;for (int num : num_set) {if (!num_set.contai…...

C++的List
List的使用 构造 与vector的区别 与vector的区别在于不支持 [ ] 由于链表的物理结构不连续,所以只能用迭代器访问 vector可以排序,list不能排序(因为快排的底层需要随机迭代器,而链表是双向迭代器) (算法库里的排序不支持)(需要单独的排序) list存在vector不支持的功能 链…...

网易有道QAnything使用CPU模式和openAI接口安装部署
网易有道QAnything可以使用本地部署大模型(官网例子为qwen)也可以使用大模型接口(OPENAI或者其他大模型AI接口 )的方式,使用在线大模型API接口好处就是不需要太高的硬件配置。 本机环境windows11 首先安装WSL环境, 安装方法参考https://zhuan…...

量子加速超级计算简介
本文转载自:量子加速超级计算简介(2024年 3月 13日) By Mark Wolf https://developer.nvidia.cn/zh-cn/blog/an-introduction-to-quantum-accelerated-supercomputing/ 文章目录 一、概述二、量子计算机的构建块:QPU 和量子位三、量子计算硬件和算法四、…...

Unity3D 基于YooAssets的资源管理详解
前言 Unity3D 是一款非常流行的游戏开发引擎,它提供了丰富的功能和工具来帮助开发者快速创建高质量的游戏和应用程序。其中,资源管理是游戏开发中非常重要的一部分,它涉及到如何有效地加载、管理和释放游戏中的各种资源,如模型、…...

Linux 自动化升级Jar程序,指定Jar程序版本进行部署脚本
文章目录 一、环境准备二、脚本1. 自动化升级Jar程序2. 指定Jar程序版本进行部署总结一、环境准备 本文在 CentOS 7.9 环境演示,以springboot为例,打包后生成文件名加上版本号,如下打包之后为strategy-api-0.3.2.jar: pom.xml<?xml version="1.0" encoding=&…...

python练习五
Title1:请实现一个装饰器,每次调用函数时,将函数名字以及调用此函数的时间点写入文件中 代码: import time time time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) # 获取当前的时间戳 # 定义一个有参装饰器来实…...
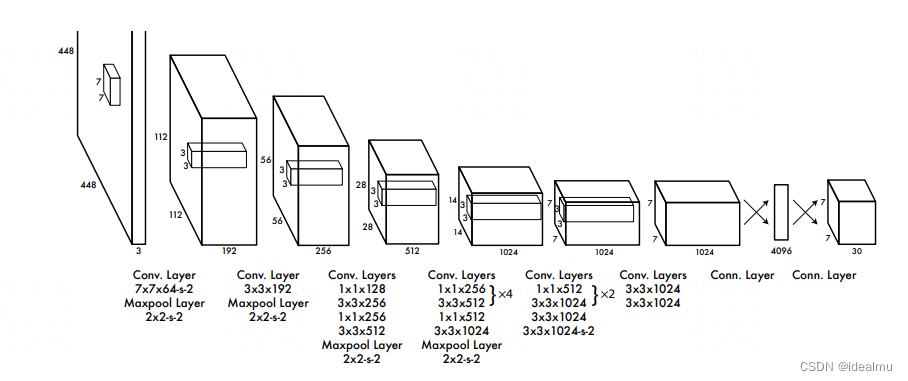
YOLOv1深入解析与实战:目标检测算法原理
参考: https://zhuanlan.zhihu.com/p/667046384 https://blog.csdn.net/weixin_41424926/article/details/105383064 https://arxiv.org/pdf/1506.02640 1. 算法介绍 学习目标检测算法,yolov1是必看内容,不同于生成模型,没有特别…...

告别手动撮合!这款插件让量化回测全程智能省心
当你的策略信号发出买入指令,资金是否足够?保证金怎么算?扣完手续费和印花税,账户还剩多少? 这些“交易后处理”逻辑,听起来不难,亲手写过就知道有多绕。不同券商的计费规则各异,昨仓…...

AI横扫各行各业,为什么唯独啃不动数字孪生?
当下AI技术席卷全网,画图、写代码、生成素材样样全能,让不少人产生了“AI万能”的认知错觉。行业内不断传出声音,声称AI将彻底取代数字孪生开发、替代技术从业者,实现项目全自动落地。但深耕数字孪生可视化领域的从业者都清楚&…...

Taotoken审计日志功能在满足企业合规与安全需求中的作用观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken审计日志功能在满足企业合规与安全需求中的作用观察 1. 引言:企业API治理中的可观测性挑战 在企业技术架构中…...

写论文用什么软件?精选7款AI论文生成工具深度测评,AI率精准控制无压力!
论文写作的痛点,AI工具来化解! 面对开题报告、文献综述到正文撰写的全流程压力,选对AI论文写作工具能让效率提升数倍。本文将基于真实体验,为你深度测评7款主流工具,帮你找到最适合的学术助手。 测评围绕四大核心维度…...
)
【独家首发】Midjourney 6.6+新增--depth-map指令实战手册:从单通道灰度图到可编辑景深层次(含Blender预处理模板)
更多请点击: https://codechina.net 第一章:Midjourney景深效果控制 景深(Depth of Field)是图像中清晰区域与虚化区域的过渡表现,在 Midjourney 中虽无原生 DSLR 式光圈参数,但可通过提示词工程、版本特性…...

STM32G474的HRTIM驱动DAC:你的锯齿波‘毛刺’和失真,可能是这两个寄存器配置反了
STM32G474的HRTIM驱动DAC:锯齿波失真问题深度解析与优化方案 在精密模拟电路设计中,STM32G474系列微控制器凭借其高性能HRTIM(高分辨率定时器)和DAC(数模转换器)的组合,成为生成高精度波形的重要…...
)
手把手教你用Google Cloud语音API为Android App加个“耳朵”和“嘴巴”(附免费额度避坑指南)
实战指南:在Android应用中集成Google Cloud语音技术 想象一下,你的Android应用能够听懂用户说话,还能用自然流畅的语音回应——这不再是科幻电影里的场景。借助Google Cloud的语音API,即使是独立开发者也能快速为应用添加专业的语…...

[260520] x-cmd v0.9.5:x install 支持 skill 安装,新增 git ci 命令让 AI 帮你写 commit
[260520] x-cmd v0.9.5:x install 支持 skill 安装,新增 git ci 命令让 AI 帮你写 commit x install 全面升级:支持 skill 安装、前缀语法、三种自动化模式、AI Agent 友好选项x git ci/commit 支持 AI 自动生成 Conventional Commits 提交信…...

从AT24C02 EEPROM的I2C时序出发,手把手调试你的蓝桥杯单片机存储模块
从AT24C02 EEPROM的I2C时序出发,手把手调试你的蓝桥杯单片机存储模块 在蓝桥杯单片机竞赛中,AT24C02 EEPROM存储模块的稳定读写是基本功,但真正的高手往往能在底层通信协议层面发现问题、解决问题。本文将带你从I2C时序的微观视角,…...

别再死记硬背ELMo、GPT、BERT的区别了!一张图带你搞懂它们的核心差异与适用场景
一图胜千言:ELMo、GPT、BERT技术差异与实战选型指南 刚接触NLP时,我也曾被各种预训练模型绕得头晕眼花——它们看起来都能处理文本,但面试官一问"为什么用BERT不用GPT"就瞬间语塞。直到我把这些模型拆解成汽车零件,才真…...