自定义类型:结构体类型
在学习完指针相关的知识后将进入到c语言中又一大重点——自定义类型,在之前学习操作符以及指针时我们对自定义类型中的结构体类型有了初步的了解,学习了结构体类型的创建以及如何创建结构体变量,还有结构体成员操作符的使用,现在我们将继续结构体相关知识的学习,希望在在看完本篇后你将会有新的收获,一起加油吧!!!
1. 结构体类型的声明
1.1结构体回顾
在之前c语言常用操作符(2)中已经对结构体的声明进行了讲解,那么现在我们简单的复习一下
struct tag//tag的名字可是自定义的
{
member-list;//成员列表
}variable-list;//变量列表
例如创建一个描述学生的结构体
struct Stu//学生类型
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
}; //分号不能丢
对结构体进行声明后就可以创建结构体变量并进行初始化了
struct Stu//学生类型
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
};int main()
{
//按照结构体成员的顺序初始化
struct Stu s = { "张三", 20, "男", "20230818001" };
printf("name: %s\n", s.name);
printf("age : %d\n", s.age);
printf("sex : %s\n", s.sex);
printf("id : %s\n", s.id);
//按照指定的顺序初始化
struct Stu s2 = { .age = 18, .name = "lisi", .id = "20230818002", .sex =
"⼥" };
printf("name: %s\n", s2.name);
printf("age : %d\n", s2.age);
printf("sex : %s\n", s2.sex);
printf("id : %s\n", s2.id);
return 0;
}1.2结构体的特殊声明
在结构体中如果我们在创建结构体类型时不给结构体加上名字,那么这个结构体就是匿名结构体类型,例如以下代码就两个都是是匿名结构体类型
struct
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
}s1,s2;struct
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
}*p1,*p2;int main()
{p1=&s1;return 0;
}在以上代码中你认为s1=*p1这种写法是合法的吗?
在以上代码中先是创建了一个匿名结构体类型并创建了两个变量,之后又创建了一个结构体类型的指针,后将结构体变量s1的地址传给指针p1,这时就会存在问题了,原因是但我们创建两个结构体类型,虽然这两个结构体类型的成员都相同,但当创建两个匿名结构体类型时,编译器会默认这两个结构体的类型不相同,所以这时将s1的地址传给指针p1会使得等号两边的变量类型不相同
注:匿名的结构体类型,如果没有对结构体类型重命名的话,基本上只能使用⼀次,
所以使用匿名结构体类型时基本上是只打算对该结构体类型使用一次,之后不再使用
1.3结构体的自引用
数据在内存当中可能是连续存放的,也可能是像以下这样随机存放的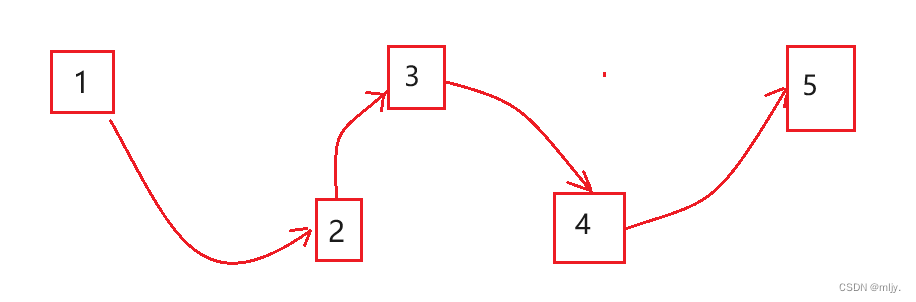
把1,2,3,4,5叫做节点,在节点中除了要存放数据外还要能有下一个节点的信息,这时我们就可以认为一个节点是一个结构体,那么各结构体能写成以下形式吗?
struct Node
{int data;struct Node next;
};这时将结构体里面的一个成员为相同的结构体类型,这时就存在一个问题,当我们用sizeof求struct Node的大小,那么使得大小为无穷大,所以以上这种写法是错误的
每各节点中我们是要存放下一个节点的信息,所以在节点中存放下一个结构体的地址也是符合要求的,因此就可以在结构体里面存放一个结构体指针类型,这时两个结构体类型不同就不会存在计算struct Node结构体时候出现无穷大的问题了
struct Node {int data;struct Node* next; };
我们知道使用typedef可以将变量类型简单化,如果在以下代码中将struct Node重命名为Node,那么结构体内的成员也可以简化为Node* next吗?
typedef struct Node
{int data;Node* next;
}Node;答案是不行的,原因是在对struct Node重命名前就使用简化后的名称Node会使得Node* next是未定义的,这时程序就会报错
修改以下形式就是正确的了
typedef struct Node {int data;struct Node* next; }Node;
2.结构体的内存对齐
在想要学习计算结构体在内存当中的大小,就需要学习一个重要的知识点:结构体的内存对齐
2.1内存对齐规则
#include<stdio.h>
struct s1
{char c1;char c2;int n;
};struct s2
{char c1;int n;char c2;
};
int main()
{printf("%zd", sizeof(struct s1));printf("%zd", sizeof(struct s2));return 0;
}以上两个结构体的大小相同吗?
运行程序发现结果不一样,这是为什么呢?

结构体的对齐规则:
1. 结构体的第一个成员对齐到和结构体变量起始位置偏移量为0的地址处
2. 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数 = 编译器默认的一个对齐数 与 该成员变量大小的较小值
- VS 中默认的值为 8
- Linux中 gcc 没有默认对齐数,对齐数就是成员自身的大小
3. 结构体总大小为最大对齐数(结构体中每个成员变量都有一个对齐数,所有对齐数中最大的)的
整数倍。
4. 如果嵌套了结构体的情况,嵌套的结构体成员对齐到自己的成员中最大对齐数的整数倍处,结构
体的整体大小就是所有最大对齐数(含嵌套结构体中成员的对齐数)的整数倍
要理解以上的对齐规则首先要了解偏移量偏移的是什么
其实偏移量就是相较于起始位置的字节偏移量

如果我们想知道s1中的各个成员变量的偏移量是多少,这时就可以用到一个宏offsetof,是c语言提供给我们的宏,作用是计算结构体成员相较结构体变量起始位置的偏移量
这时我们打开c++官网查看offsetof
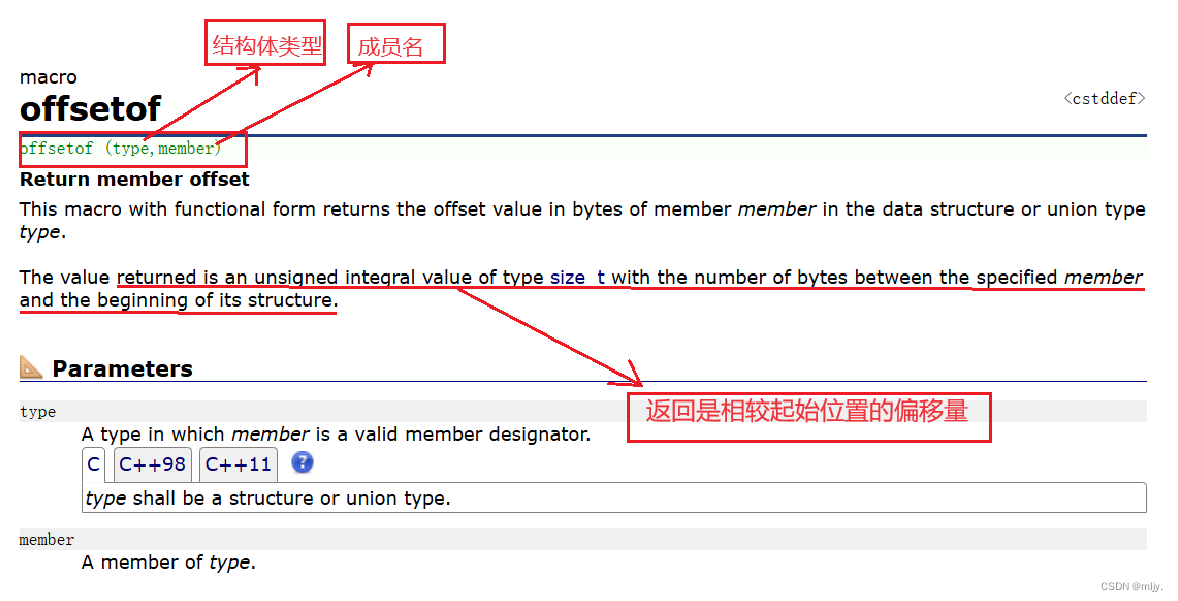
注:使用offsetof需要引用头文件#include<stddef.h>
#include<stdio.h>
#include<stddef.h>
struct s1
{char c1;char c2;int n;
};int main()
{printf("%zd\n", offsetof(struct s1,c1));printf("%zd\n", offsetof(struct s1,c2));printf("%zd\n", offsetof(struct s1, n));return 0;
}
这时运行程序就可以得到c1,c2,n相较起始位置的偏移量分别为0,1,4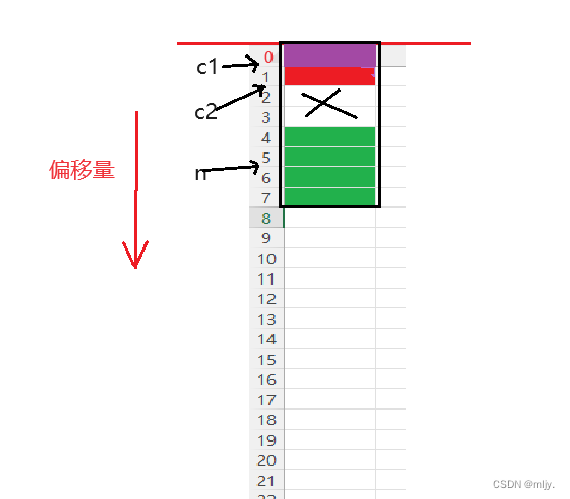
这时就会发现与以上计算出的struct s1的大小8字节相同
#include<stdio.h>
#include<stddef.h>
struct s1
{char c1;char c2;int n;
};
struct s2
{char c1;int n;char c2;};int main()
{printf("%zd\n", offsetof(struct s2,c1));printf("%zd\n", offsetof(struct s2,c2));printf("%zd\n", offsetof(struct s2, n));return 0;
}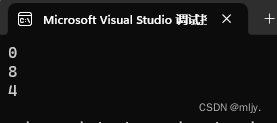
这时就会发现这样计算出的struct s2大小为9个字节,这就与以上运行程序计算出的12不相同了,这是为什么呢?
这时我们就要来了解结构体内存对齐的规则:
结构体的对齐规则:
1. 结构体的第一个成员对齐到和结构体变量起始位置偏移量为0的地址处
2. 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数 = 编译器默认的一个对齐数 与 该成员变量大小的较小值
- VS 中默认的值为 8
- Linux中 gcc 没有默认对齐数,对齐数就是成员自身的大小
3. 结构体总大小为最大对齐数(结构体中每个成员变量都有一个对齐数,所有对齐数中最大的)的整数倍。
4. 如果嵌套了结构体的情况,嵌套的结构体成员对齐到自己的成员中最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体中成员的对齐数)的整数倍
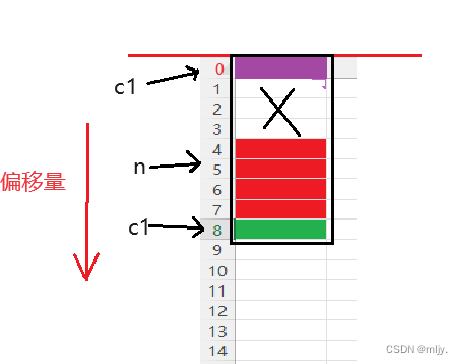
所以在以上struct s2中一开始第一个成员c1的大小为1,比vs默认偏移数8小,所以偏移数就是1,c1大小为1

第二个成员n的大小为4,比vs默认偏移数8小,所以偏移数就是4,所以n从第五个字节开始,n大小为4字节
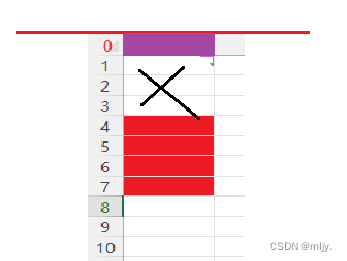
第三个成员c2的大小为1,比vs默认偏移数8小,所以偏移数就是1,所以n从第九个字节开始,c2大小为1字节
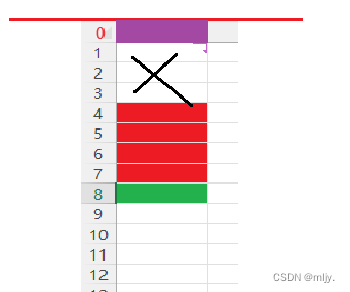
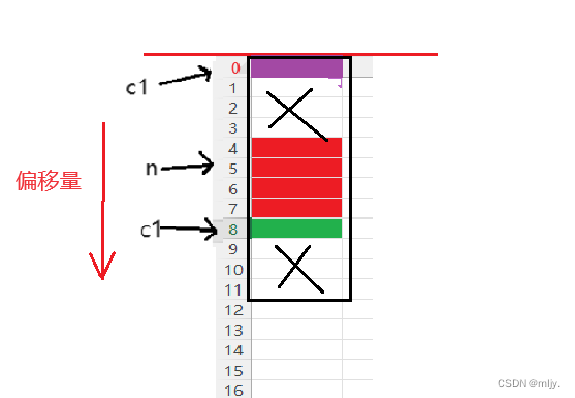
在此还未结束,因为结构体总大小为最大对齐数(结构体中每个成员变量都有一个对齐数,所有对齐数中最大的)的整数倍,该结构体struct s2最大对齐数为4,所以结构体大小必须是4的整数倍,以上的9字节不是4的整数倍,所以struct s2大小为12字节
练习1
#include<stdio.h>
struct S3
{double x;char c;int n;
};
int main()
{printf("%zd\n", sizeof(struct s3));return 0;
}以上代码的输出结果是什么呢?
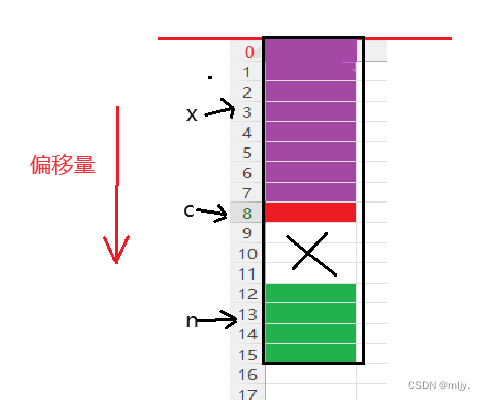
x的大小为8个字节,偏移量为0,c的大小为1个字节,偏移量为9,n大小为4字节,偏移量为12,以上结构体大小为16字节满足结构体总大小为最大对齐数的整数倍
程序输出结果与分析结果相同
练习2
#include<stdio.h>
struct S3
{double x;char c;int n;
};
struct S4
{
char c1;
struct S3 s3;
double d;
};
int main()
{printf("%zd\n", sizeof(struct S4));return 0;
}以上代码的输出结果是什么呢?
在以上代码就涉及到了结构体嵌套问题,在struct S4中c1的大小为1个字节,偏移量为0,因为在以上已经求出了struct S3的大小为16字节,我们需要再了解一个规律如果嵌套了结构体的情况,嵌套的结构体成员对齐到自己的成员中最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体中成员的对齐数)的整数倍,所以 s3偏移量为8,大小为16字节,d的大小为8个字节,偏移量为24,最终结构体struct S4大小就为32个字节,符合结构体的整体大小就是所有最大对齐数(含嵌套结构体中成员的对齐数)的整数倍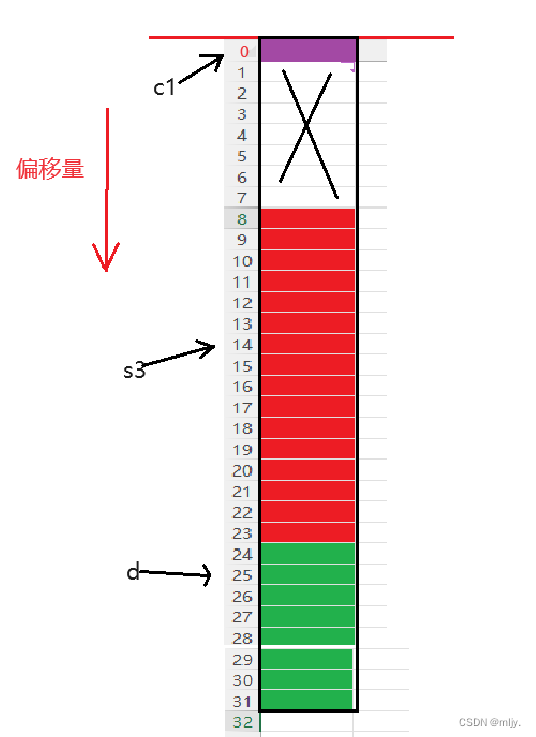
2.2 为什么存在内存对齐
1. 平台原因 (移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2. 性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对⻬的内存,处理器需要作两次内存访问;⽽对⻬的内存访问仅需要⼀次访问。假设⼀个处理器总是从内存中取8个字节,则地址必须是8的倍数。如果我们能保证将所有的double类型的数据的地址都对齐成8的倍数,那么就可以用⼀个内存操作来读或者写值了。否则,我们可能需要执行两次内存访问,因为对象可能被分放在两个8字节内存块中。
例如在以上结构体struct S中如果机器每次内存读取4个字节,在未对齐情况下就要读取两次,而在对齐的情况下就只要读取一次

总体来说:结构体的内存对齐是拿空间来换取时间的做法
那在设计结构体的时候,我们既要满足对齐,又要节省空间,如何做到:
让占用空间小的成员尽量集中在一起
struct s1
{char c1;char c2;int n;
};struct s2
{char c1;int n;char c2;
};例如在以上两个结构体中成员都一样,s1将占空间小的成员集中在了一起就使得结构体所占空间小了一些
2.3 修改默认对齐数
在以上的学习中我们知道了VS的默认对齐数是8,那么有什么办法可以修改默认对齐数呢?
其实是有办法的,利用#pragma 这个预处理指令,可以改变编译器的默认对齐数。
#include<stdio.h>
#pragma pake(1)//修改默认对齐数为2
struct s1
{char c1;char c2;int n;
};
#pragma pake()//恢复默认对齐数
int main()
{printf("%zd", sizeof(struct s1));return 0;
}使用了#pragma后默认对齐数就被修改为了2,这时以上结构体struct s1的大小就变成6字节
3.结构体传参
#include<stdio.h>
struct S
{int data[1000];int num;
};
struct S s = { {1,2,3,4}, 1000 };
//结构体传参
void print1(struct S s)
{for (int i = 0; i < 4; i++){printf("%d ", s.data[i]);}printf("\n");printf("%d\n", s.num);
}
//结构体地址传参
void print2(struct S* ps)
{for (int i = 0; i < 4; i++){printf("%d ", ps->data[i]);}printf("\n");printf("%d\n", ps->num);
}
int main()
{print1(s); //传结构体print2(&s); //传地址return 0;
}我们知道在函数传参存在传值调用与传址调用,在结构体传参当中也是存在这两种方式的,以上代码中print1就是使用了传值调用,而print是使用了传址调用 ,两种方式都能找到结构体变量s以及其成员,但在结构体传参时一般是使用传址调用,原因是使用传址调用不用再开辟一块内存空间,新创建的指针就指向了原来的那块内存空间,而使用传值调用时,需要再创建一块新的内存空间,如果这个结构体像以上struct S一样所占内存空间很大的话,再创建新的内存就很浪费内存,还有函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。
结论:
结构体传参的时候,要传结构体的地址
4. 结构体实现位段
4.1 什么是位段
位段的声明和结构是类似的,有两个不同:
1. 位段的成员必须是 int、unsigned int 或signed int ,在C99中位段成员的类型也可以
选择其他类型。
2. 位段的成员名后边有⼀个冒号和⼀个数字。
例如以下结构体就是使用了位段
struct A { int _a:2; int _b:5; int _c:10; int _d:30; };在此结构体中如果成员a知道自存0~3的整数,就可以在a后加上位段,2,这也就表示a成员只占2比特位,而用来a变量位int类型是占32个比特位,位段后就节省了许多空间,同理b,c,d也分别加上位段5,10,30
那么这和不使用位段的结构体大小有什么差别吗?
struct A
{
int _a;
int _b;
int _c;
int _d;
};我们通过使用sizeof计算看看
这时就可以发现使用位段可以节省空间
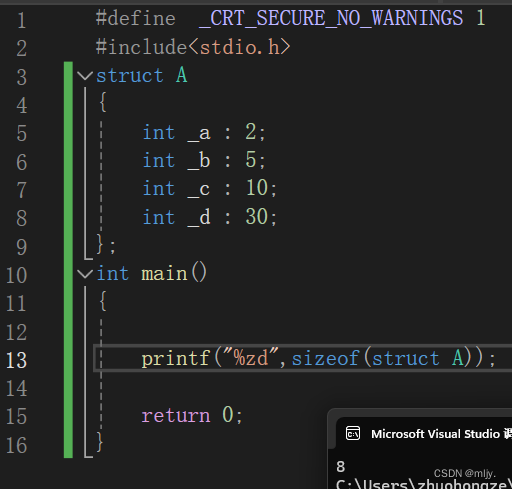

那么为什么使用位段后以上结构体大小为8字节呢?这时我们就要学习位段的内存分配
4.2位段的内存分配
1. 位段的成员可以是 int unsigned int signed int 或者是 char 等类型
2. 位段的空间上是按照需要以4个字节( int )或者1个字节( char )的方式来开辟的。
3. 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段。
例如以下结构体
struct S
{
char a:3;
char b:4;
char c:5;
char d:4;
}; 这时我们知道成员a所占大小为3比特位,类型为char,大小为8比特位,这时就存在一个问题在给了成员变量后在空间内部是从左向右使用还是从右向左使用?这时假设是从右向左使用,这时又存在一个问题了当剩下空间不满足存放下一个成员时候,空间是浪费还是使用呢?这里假设是浪费
这时我们创建一个struct S类型的变量并给各成员初始化为0,再给其赋值调试程序观察内存
struct S
{char a : 3;char b : 4;char c : 5;char d : 4;
};int main()
{struct S s = { 0 };s.a = 10;s.b = 12;s.c = 3;s.d = 4;return 0;
}

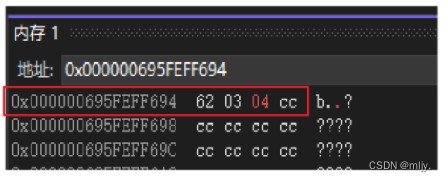
存放入成员变量a的数是10二进制表示形式是1010,但成员a空间大小只有3比特位,所以存入是010, 存放入成员变量b的数是12二进制表示形式是1100,所以存入是1100, 存放入成员变量c的数是3二进制表示形式是11,所以存入是00011, 存放入成员变量d的数是4二进制表示形式是100,所以存入是0100
这时用16进制表示内存当中就为62 03 04
通过调试,查看内存与以上分析结果相同
4.3 位段的跨平台问题
1. int 位段被当成有符号数还是⽆符号数是不确定的。
2. 位段中最大位的数目不能确定。(16位机器最大16,32位机器最大32,写成27,在16位机器会出问题。
3. 位段中的成员在内存中从左向右分配,还是从右向左分配,标准尚未定义。
4. 当⼀个结构包含两个位段,第⼆个位段成员比较大,无法容纳于第⼀个位段剩余的位时,是舍弃剩余的位还是利用,这是不确定的。
总结:
跟结构相比,位段可以达到同样的效果,并且可以很好的节省空间,但是有跨平台的问题存在。
4.4 位段使用的注意事项
位段的几个成员共有同⼀个字节,这样有些成员的起始位置并不是某个字节的起始位置,那么这些位置处是没有地址的。内存中每个字节分配⼀个地址,⼀个字节内部的bit位是没有地址的。
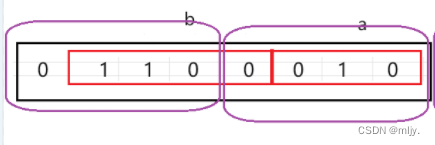
正如以上的结构体中的a成员就没有相应的地址
所以不能对位段的成员使用&操作符,这样就不能使用scanf直接给位段的成员输⼊值,只能是先输⼊放在⼀个变量中,然后赋值给位段的成员。
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
int main()
{
struct A sa = {0};
scanf("%d", &sa._b);//这是错误的
//正确的⽰范
int b = 0;
scanf("%d", &b);
sa._b = b;
return 0;
}4.5位段的应用
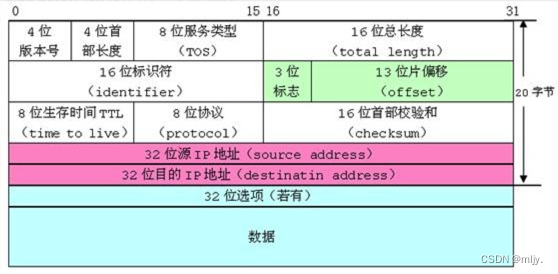
下图是⽹络协议中,IP数据报的格式,我们可以看到其中很多的属性只需要几个bit位就能描述,这⾥使用位段,能够实现想要的效果,也节省了空间,这样⽹络传输的数据报大小也会较小⼀些,对⽹络的畅通是有帮助的。
相关文章:
自定义类型:结构体类型
在学习完指针相关的知识后将进入到c语言中又一大重点——自定义类型,在之前学习操作符以及指针时我们对自定义类型中的结构体类型有了初步的了解,学习了结构体类型的创建以及如何创建结构体变量,还有结构体成员操作符的使用,现在我…...

C++对象移动
在某些情况下,对象拷贝后就立即被销毁了,这时利用新标准(C11)提供的对象移动而非拷贝将大幅提升性能. 1.右值引用 为了支持移动操作,c11新增了一种引用 - 右值引用(rvalue reference)。这种引用必须指向右值,使用&&声明。 右值引用只能引用临时变量或常量值. 右值引用…...
)
“华为杯”第十三届中国研究生 数学建模竞赛-E题:粮食最低收购价政策问题研究(续)
目录 4.3 问题三:粮食价格的特殊规律性模型 4.3.1 分析和建模 4.3.2 求解和结果...

(一)django目录介绍
1、生成django项目,得到的目录如下 manage.py:命令行工具,内置多种方式与项目进行交互。在命令提示符窗口下,将路径切换到项目并输入python manage.py help,可以查看该工具的指令信息。 默认的数据库工具,sqlite 在…...

leetcode5 最长回文子串
给你一个字符串 s,找到 s 中最长的 回文 子串。 示例 1: 输入:s "babad" 输出:"bab" 解释:"aba" 同样是符合题意的答案。示例 2: 输入:s "cbbd" 输…...
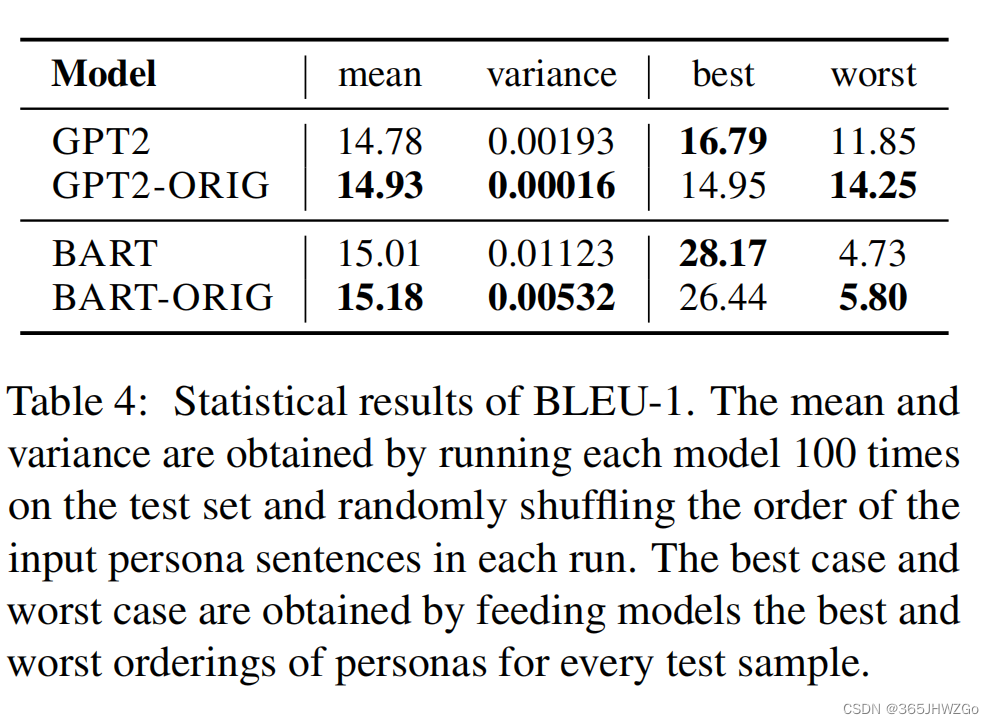
《论文阅读》通过顺序不敏感的表示正则化实现稳健的个性化对话生成 ACL 2023
《论文阅读》通过顺序不敏感的表示正则化实现稳健的个性化对话生成 ACL 2023 前言 相关个性化生成论文推荐简介问题定义方法损失函数实验结果 前言 亲身阅读感受分享,细节画图解释,再也不用担心看不懂论文啦~ 无抄袭,无复制,纯手…...

python采集汽车价格数据
python采集汽车价格数据 一、项目简介二、完整代码一、项目简介 本次数据采集的目标是车主之家汽车价格数据,采集的流程包括寻找数据接口、发送请求获取响应、解析数据和持久化存储,先来看一下数据情况,完整代码附后: 二、完整代码 #输入请求页面url #返回html文档 imp…...

德克萨斯大学奥斯汀分校自然语言处理硕士课程汉化版(第四周) - 语言建模
语言建模 1. 统计语言模型2. N-gram语言建模 2.1. N-gram语言模型中的平滑处理 3. 语言模型评估4. 神经语言模型5. 循环神经网络 5.1. Vanilla RNN5.2. LSTM 1. 统计语言模型 统计语言模型旨在量化自然语言文本中序列的概率分布,即计算一个词序列(如一…...

Jitsi meet 退出房间后,用户还在房间内
前言 Jitsi Meet 如果客户端非正常退出会议,会产生用户还在房间内,实际用户已经退出的情况,需要一段时间内,才会在UI离开房间,虽然影响不大,但是也容易导致体验不好。 保活 Jitsi Meet 会和前端做一个保…...

Java 18 新特性
Java 作为一门广泛应用于企业级开发和系统编程的编程语言,一直以来都在不断进化和改进。2022 年发布的 Java 18 版本为开发者带来了一些新的特性和改进,这些特性不仅提升了开发效率,还进一步增强了 Java 语言的功能和灵活性。本文将深入探讨 …...

c++基础创建对象
在C中,test a; 和 test a new test(); 是两种不同的初始化或创建对象的方式,而且它们之间存在根本的区别。 test a; 这是对象a的栈上分配。在声明test a;时,编译器会在栈上为a分配内存,并调用test类的默认构造函数(…...
- docker)
WHAT - 容器化系列(二)- docker
目录 一、前言二、Docker镜像:可运行软件包三、Docker容器:可执行环境四、容器和镜像的关系五、创建镜像的过程5.1 编写Dockerfile5.2 构建Docker镜像5.3 查看构建的镜像5.4 运行Docker容器5.5 验证容器运行状态5.6 推送镜像到镜像仓库(可选&…...

力扣 19题 删除链表的倒数第 N 个结点 记录
题目描述 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 示例 1: 输入:head [1,2,3,4,5], n 2 输出:[1,2,3,5]示例 2: 输入:head [1], n 1 输出:[]示例 3&am…...
)
渗透测试之Web安全系列教程(二)
今天,我们来讲一下Web安全! 本文章仅提供学习,切勿将其用于不法手段! 目前,在渗透测试领域,主要分为了两个发展方向,分别为Web攻防领域和PWN(二进制安全)攻防领域。Web…...

【算法】在?复习一下快速排序?
基本概念 快速排序是一种基于交换的排序算法,该算法利用了分治的思想。 整个算法分为若干轮次进行。在当前轮次中,对于选定的数组范围[left, right],首先选取一个标志元素pivot,将所有小于pivot的元素移至其左侧,大于…...
matlab安装及破解
一、如何下载 软件下载链接,密码:98ai 本来我想自己生成一个永久百度网盘链接的,但是: 等不住了,所以大家就用上面的链接吧。 二、下载花絮 百度网盘下载速度比上载速度还慢,我给充了个会员,…...
Tree——输出项目的文件结构(Linux)
输出项目中的文件结构可以使用tree命令。tree是一个用于以树状结构显示目录内容的命令行工具。它非常适合快速查看项目的文件结构。安装: sudo apt-get install tree 使用: 在命令行中导航到项目的根目录,输出文件结构。 tree 也可以将结构输…...

UE5 读取本地图片并转换为base64字符串
调试网址:在线图像转Base64 - 码工具 (matools.com) 注意要加(data:image/png;base64,) FString UBasicFuncLib::LoadImageToBase64(const FString& ImagePath) {TArray<uint8> ImageData;// Step 1: 读取图片文件到字节数组if (!…...

【NOIP普及组】税收与补贴问题
【NOIP普及组】税收与补贴问题 💖The Begin💖点点关注,收藏不迷路💖 每样商品的价格越低,其销量就会相应增大。现已知某种商品的成本及其在若干价位上的销量(产品不会低于成本销售),…...

Docker 部署 mysql 服务
linux用法 Container(容器)集合成 Services(服务) 交互集合成 Stack(堆栈)卸载可能存在的旧版本 sudo apt-get update使apt可以通过HTTPS使用存储库(repository) sudo apt-get ins…...

ComfyUI-Impact-Pack V8:AI图像增强的模块化架构革新与性能突破
ComfyUI-Impact-Pack V8:AI图像增强的模块化架构革新与性能突破 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址:…...

Windows CE嵌入式开发:实时USB设备插拔监控与信息持久化实战
1. 项目概述与核心思路 在嵌入式开发,尤其是涉及数据采集、文件交换或外设管理的项目中,实时感知USB设备的插拔状态是一个高频且关键的需求。想象一下,你正在开发一个工业数据记录仪,需要自动将U盘中的数据导入系统,或…...

AI赋能能耗管理:解锁智能照明低碳运维新范式
摘要在双碳战略全面落地、智慧楼宇数字化转型的浪潮下,智能照明已广泛应用于商业园区、市政道路、写字楼等各类场景。传统照明能耗管理模式粗放,存在能耗数据模糊、浪费隐蔽、管控滞后、节能无依据等痛点,大量无效耗电持续增加运营成本。新一…...

RK3568与RK3399深度对比:从架构到实战,边缘计算如何选型?
1. 项目概述:为什么我们需要重新审视RK3568与RK3399?最近在给一个边缘计算项目做硬件选型,客户的需求很明确:需要一块性能足够、接口丰富、功耗可控且长期供货稳定的核心板。在国产处理器的候选名单里,瑞芯微的RK3399和…...

构建智能交易系统:高效掌握缠论量化实战技巧
构建智能交易系统:高效掌握缠论量化实战技巧 【免费下载链接】chan.py 开放式的缠论python实现框架,支持形态学/动力学买卖点分析计算,多级别K线联立,区间套策略,可视化绘图,多种数据接入,策略开…...
)
5G手机省电的秘密:一文搞懂NR C-DRX中的Inactivity Timer(附工作流程图解)
5G手机续航优化的核心技术:深入解析C-DRX中的Inactivity Timer机制 当你在咖啡厅刷社交媒体时,是否注意到手机屏幕熄灭后仍能即时收到消息?这种"随叫随到"的体验背后,是5G NR中一项精妙的省电技术——C-DRX(…...

433MHz无线模块解码避坑指南:从示波器抓波形到STM32代码实现的完整流程
433MHz无线模块解码实战:从波形分析到STM32代码优化的全流程解析 1. 解码前的硬件准备与信号捕获 当你第一次拿到433MHz无线模块时,最令人困惑的往往是"为什么我的代码无法正确解码?"要解决这个问题,我们需要从最基础的…...

Sora 2生成帧精度达99.7%的LUT匹配方案,DaVinci色彩科学全链路对齐指南
更多请点击: https://kaifayun.com 第一章:Sora 2与DaVinci整合的底层逻辑与技术共识 Sora 2 作为新一代视频生成基础模型,其核心能力建立在时空联合建模与长程依赖捕获之上;DaVinci 则是面向专业影视工作流的高性能非线性编辑与…...
)
别再乱接线了!手把手教你用SC-09电缆搞定三菱FX2N PLC通讯(附GX Developer配置)
三菱FX2N PLC通讯实战:SC-09电缆的正确打开方式 第一次接触三菱FX2N PLC时,很多人都会被通讯问题难住。那些看似简单的接线背后藏着不少门道——用错线序可能导致通讯失败,甚至损坏设备。本文将带你避开常见陷阱,从硬件连接到软件…...

1951-2025年中国1km月平均气温逐年变化率数据集
摘要本数据集为中国1000米分辨率月平均气温数据集(1951-2025)衍生生成的“1951-2025年中国1千米月平均气温逐年变化率数据集”产品,输出格式为TIF,覆盖中国范围,时间表达为1951-2025年。产品围绕“年际变化率”算法组织…...