Kafka之Producer原理
1. 生产者发送消息源码分析
public class SimpleProducer {public static void main(String[] args) {Properties pros=new Properties();pros.put("bootstrap.servers","192.168.8.144:9092,192.168.8.145:9092,192.168.8.146:9092");
// pros.put("bootstrap.servers","192.168.8.147:9092");pros.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");pros.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");// 0 发出去就确认 | 1 leader 落盘就确认| all(-1) 所有Follower同步完才确认pros.put("acks","1");// 异常自动重试次数pros.put("retries",3);// 多少条数据发送一次,默认16Kpros.put("batch.size",16384);// 批量发送的等待时间pros.put("linger.ms",5);// 客户端缓冲区大小,默认32M,满了也会触发消息发送pros.put("buffer.memory",33554432);// 获取元数据时生产者的阻塞时间,超时后抛出异常pros.put("max.block.ms",3000);// 创建Sender线程Producer<String,String> producer = new KafkaProducer<String,String>(pros);for (int i =0 ;i<1000000;i++) {producer.send(new ProducerRecord<String,String>("mytopic",Integer.toString(i),Integer.toString(i)));// System.out.println("发送:"+i);}//producer.send(new ProducerRecord<String,String>("mytopic","1","1"));//producer.send(new ProducerRecord<String,String>("mytopic","2","2"));producer.close();}a. 首先我们是创建一些kafka的连接配置以及参数配置,然后先new出来一个生产者,创建一个sender线程,由下图源码可以看出,我们在new生产者的时候,kafak会帮我们船舰一个sender线程,并进行了命名和启动
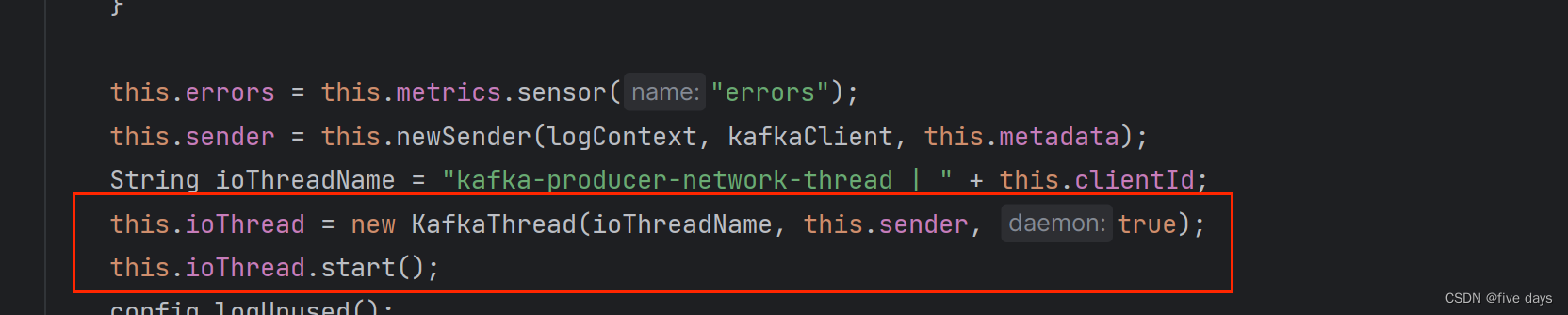
b.随后我们的main线程中,进行批量send发送,那么接下来我们看下send方法

可以看到,在send方法中,还有一个interceptors做了一个拦截器的处理, 那么拦截器应该怎么使用的呢?
我们只需要实现ProducerInterceptor中的onsend方法,并且在kafka send消息前进行配置就可以了
public class ChargingInterceptor implements ProducerInterceptor<String, String> {// 发送消息的时候触发@Overridepublic ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {System.out.println("1分钱1条消息,不管那么多反正先扣钱");return record;
}带有拦截器的kafka demo
public static void main(String[] args) {Properties props=new Properties();props.put("bootstrap.servers","192.168.8.144:9092,192.168.8.145:9092,192.168.8.146:9092");
// props.put("bootstrap.servers","192.168.8.147:9092");props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");// 0 发出去就确认 | 1 leader 落盘就确认| all 所有Follower同步完才确认props.put("acks","1");// 异常自动重试次数props.put("retries",3);// 多少条数据发送一次,默认16Kprops.put("batch.size",16384);// 批量发送的等待时间props.put("linger.ms",5);// 客户端缓冲区大小,默认32M,满了也会触发消息发送props.put("buffer.memory",33554432);// 获取元数据时生产者的阻塞时间,超时后抛出异常props.put("max.block.ms",3000);// 添加拦截器List<String> interceptors = new ArrayList<>();interceptors.add("com.zsc.mq.kafka.javaapi.interceptor.ChargingInterceptor");// 这个键就是拦截器的配置,因为拦截器是个list,因此可以实现多个拦截器props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors);Producer<String,String> producer = new KafkaProducer<String,String>(props);producer.send(new ProducerRecord<String,String>("mytopic","1","1"));producer.send(new ProducerRecord<String,String>("mytopic","2","2"));producer.close();}}c. send方法走完拦截器后,我们进入到dosend方法中,接着看

可以看到,kafka对我们的消息进行了一个序列化,那么序列化方式就是在我们初始配置参数的时候进行配置的,可以指定不同的序列化方式,并且也可以自定义序列化方式,实现序列化接口,增加到配置类中即可

d. 看完序列化,我们的消息发送接着往下面走, 进入到分区器流程



由上面可知,我们的分区器如果指定了分区就会走我们指定的分区;消息没有指定分区但是自定义了消息分区器,就会走到消息分区器中,自定义消息器代码如下(实现partitioer接口即可):
public class SimplePartitioner implements Partitioner {public SimplePartitioner() {}@Overridepublic void configure(Map<String, ?> configs) {}@Overridepublic int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {String k = (String) key;System.out.println(k);if (Integer.parseInt(k) % 2 == 0){return 0;}else{return 1;}// return Integer.parseInt(k)%2;}@Overridepublic void close() {}还有第三个情况,既没有指定也没有自定义分区器。那么key不为空,那就是走hash取模算法;key也会空的话,就是采用粘连策略(根据topic来确定在哪里存储)
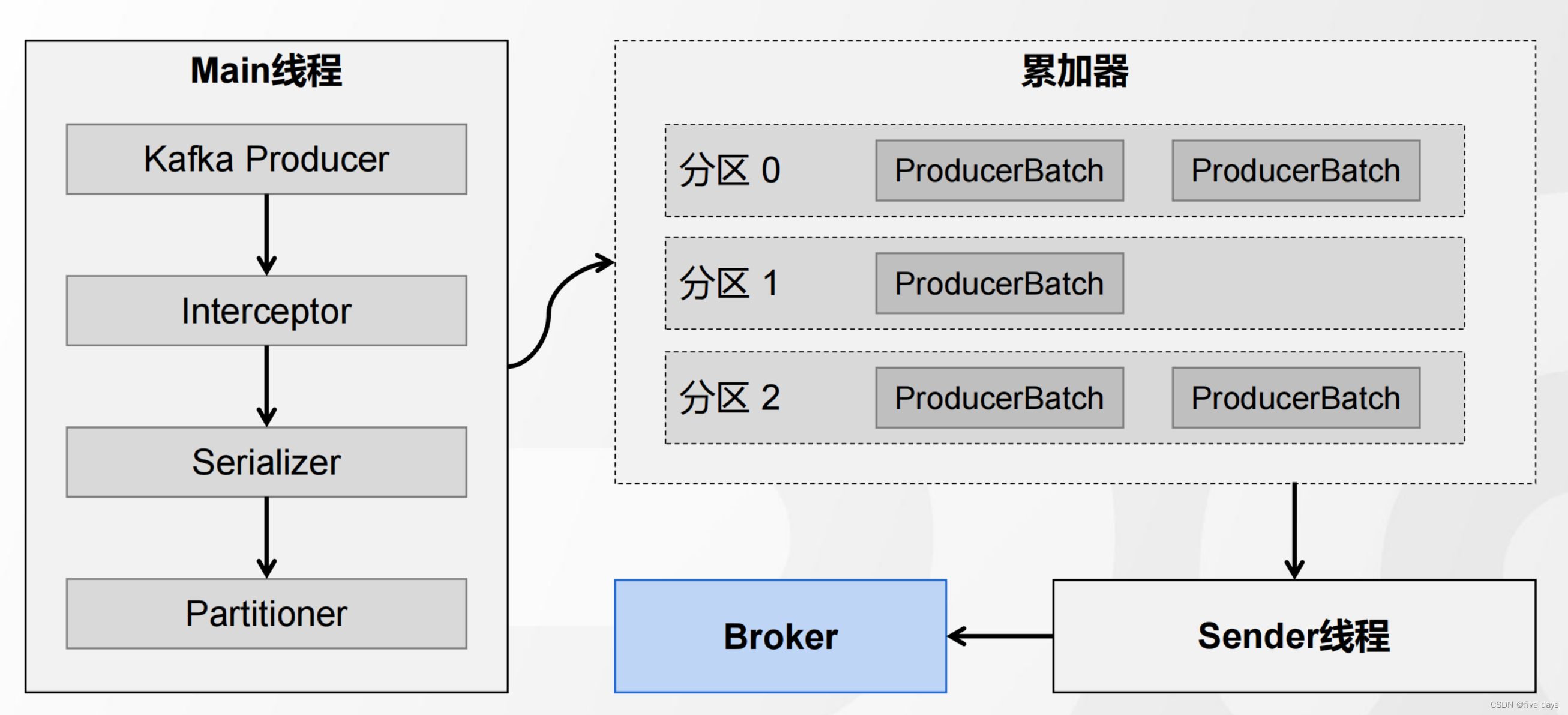
e. 当我们消息的分区器走完之后,就进入到我们的累加器,在上篇博客MQ之初识kafka-CSDN博客我们介绍组件的时候就提到过,kafka为了提升高吞吐,查询效率快,消息并不是堆积在一起的,而是一批一批去放的,因此经过一个累加器。

可以看到 按批次添加到累加器中,那么添加到累加器之后,是怎么触发流程的呢?
f . 顺着源码再往下看,可以看到一个判断,当累加器的批次满了的话或者是刚创建的批次,就会去唤醒sender线程,向Broker中发送消息。

生产者发送消息的整个流程图如下所示:
2. ACK应答机制与ISR机制
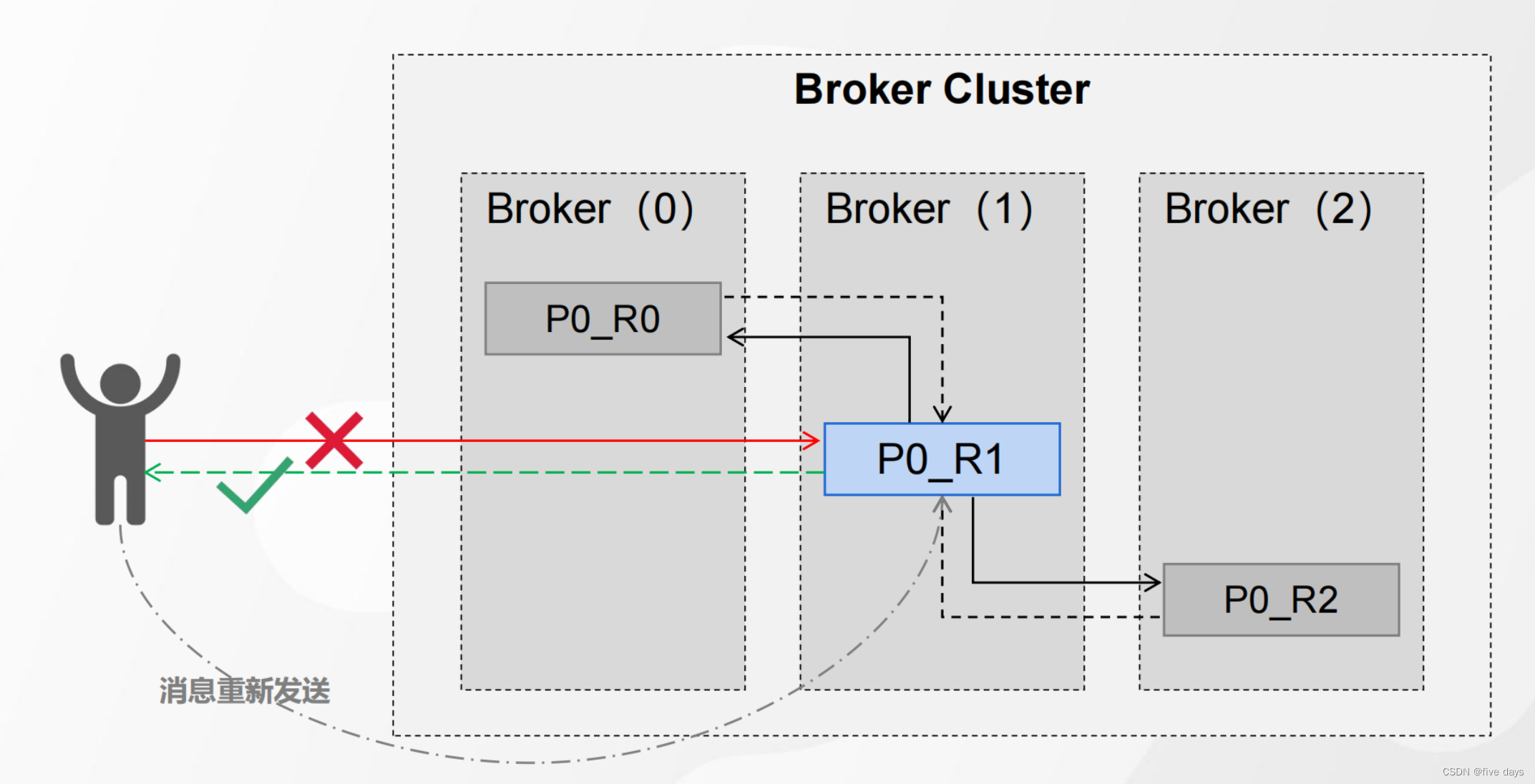
2.1 服务器端响应策略的必要性
如图所示,我们正常的执行流程是生产者producer向leader中发送消息,然后leader同步到两个follower副本中,那么当发送消息的过程中服务异常的话,我们的leader就接收不到消息了,因此需要一个应答机制来保证我们能够接收到消息,如果leader没有接收到消息,就触发重发机制,让producer重新发送消息给leader
2.2 ACK应答机制
kafka中提供了三种可靠性级别,可以根据对可靠性和延迟性的要求进行选择
1.acks = 0 producer 不等待 broker动作、直接返回ack2.acks = 1(默认) producer等待broker 动作、 leader 落盘成功、返回 ack3.acks=-1(all) producer 等待 broker 动作、 leader&follower 全部落盘成功、返回 ack
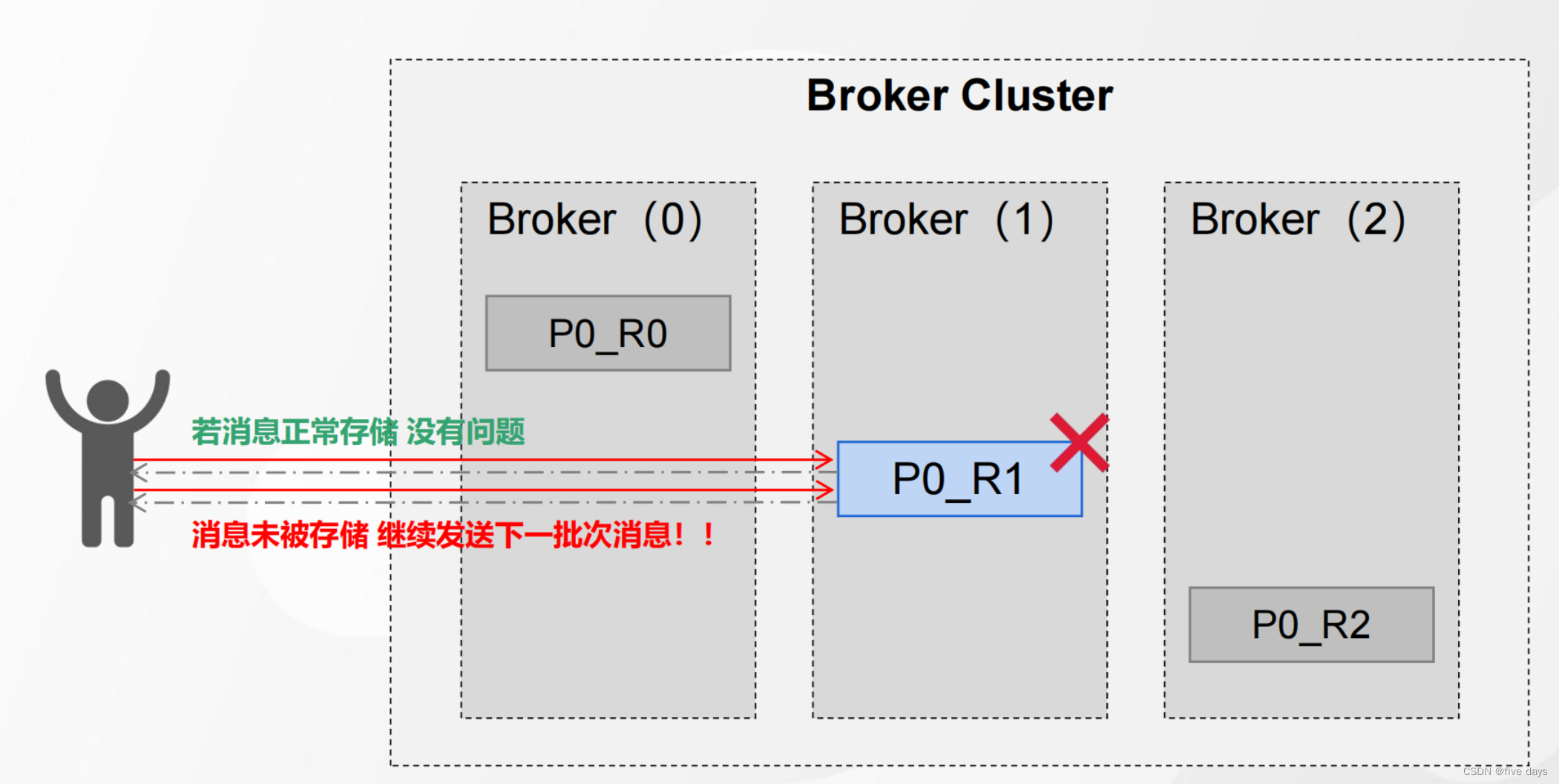
props.put("ack","0"); 不等待ACK
这种情况是说我们的producer发送消息给leader,leader异步返回ack给peoducer告诉消息已经发送成功了,这种正常存储的情况下肯定是没有问题的。但是如果还没有同步副本的情况下,我们的leader此时挂掉了,而producer已经收到了应答,因此不会再重发消息。当再次重启leader所在的服务器时,数据就丢失了
props.put("ack","1"); Leader落盘、返回ACK(默认)
这种下,我们peoducer确定了leader已经落盘了,但是如果极端情况下,leader还没有同步副本给follower,那么此时leader服务器挂了,数据是不是也就丢失了,因为也还没有进行备份
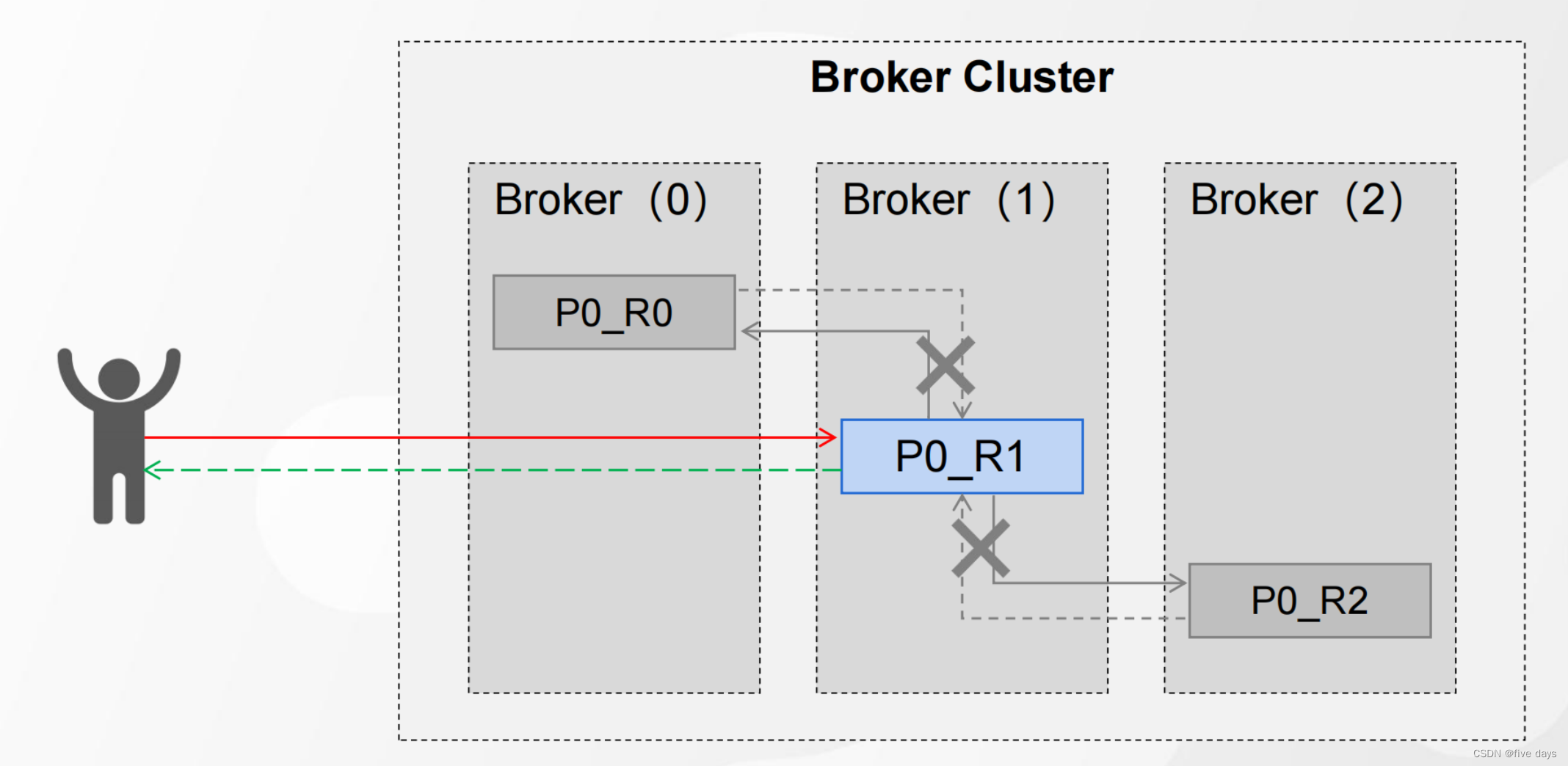
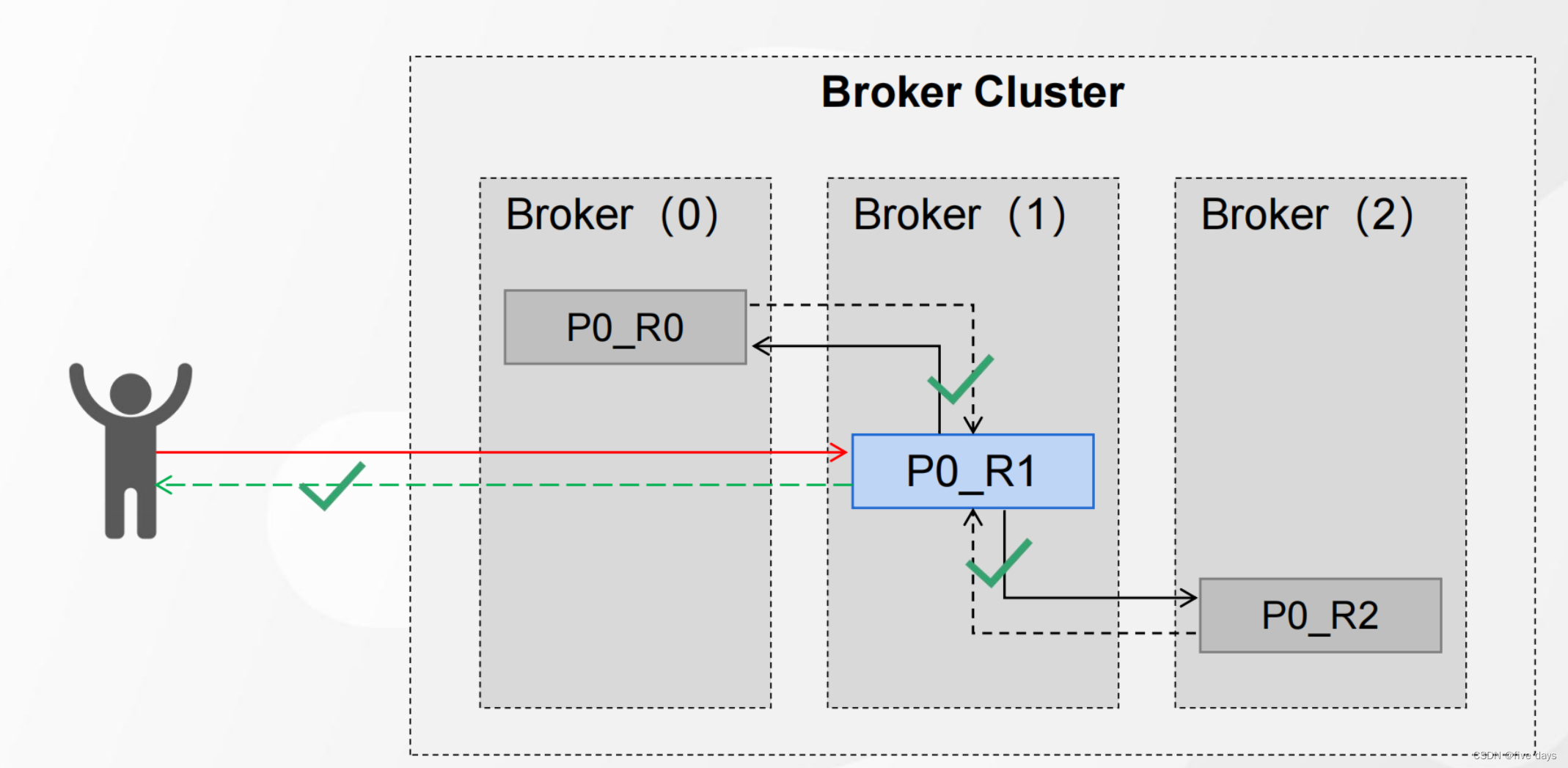
props.put("ack","-1"); Leader和全部Follower落盘、返回ACK
这种情况是我们的producer等待leader和follower全部落盘成功后,进行ack响应,这种策略的可靠性最高,但是吞吐量是最低的,因此要根据具体业务具体配置。那么这种策略是不是就没有什么问题了呢?当然也有,比如当leader和follower都落盘后,再返回应答信号时,leader挂了,那么peoducer没有收到消息,就会任务leader没有接收到消息,还是会对消息进行重发,那这个问题怎么解决呢? 可以用消息幂等性(在第三章进行赘述说明)
应答异常
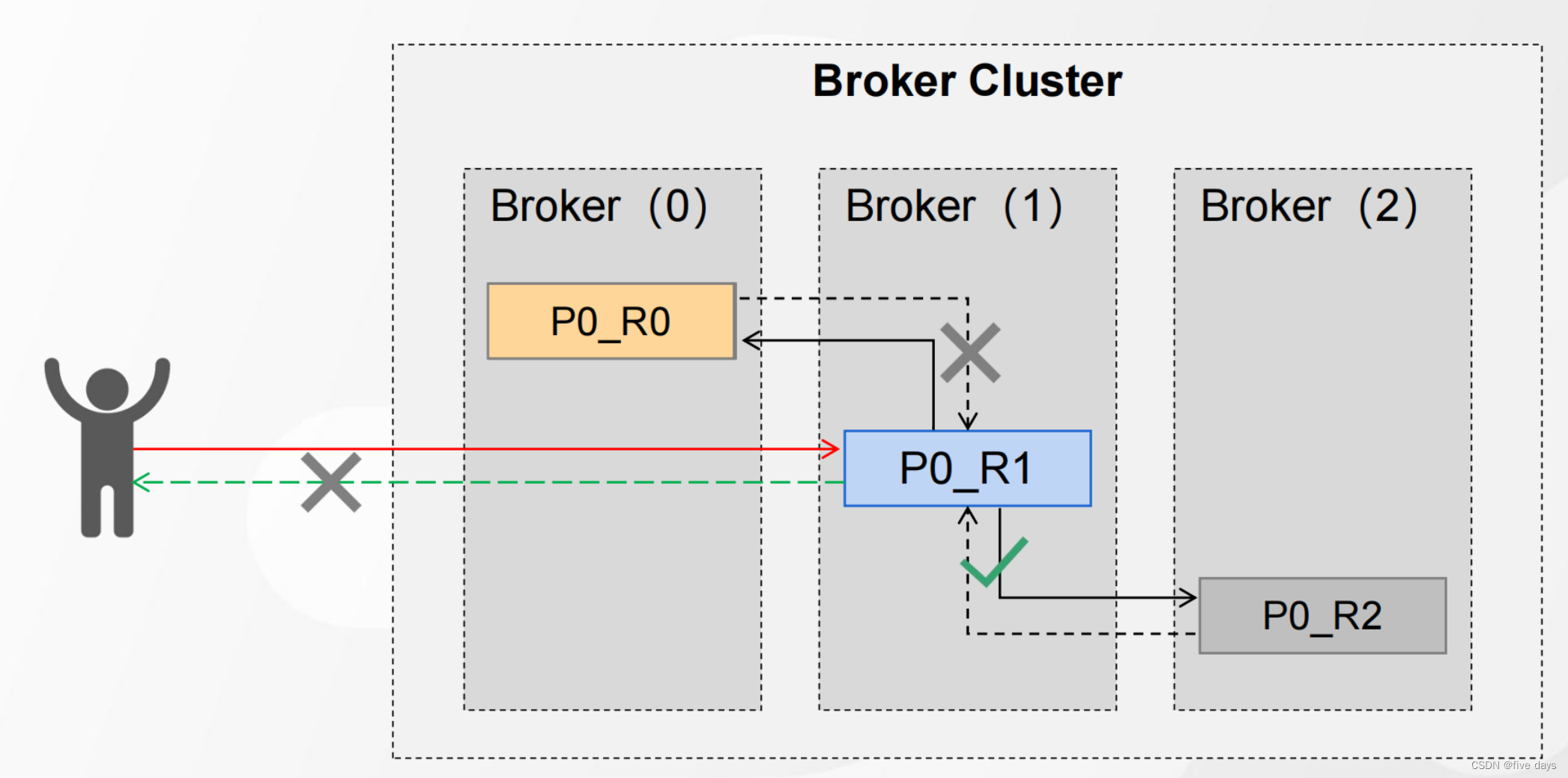
如上图,当一个flower挂了的情况下,是不是我们的leader就没法同步了,没法同步,就会造成整个链路的阻塞,peoducer没收到应答信息还啥也不知道,又往leader发消息,如果这样持续下去,服务是不是就该崩了,因此引入了一个ISR机制。
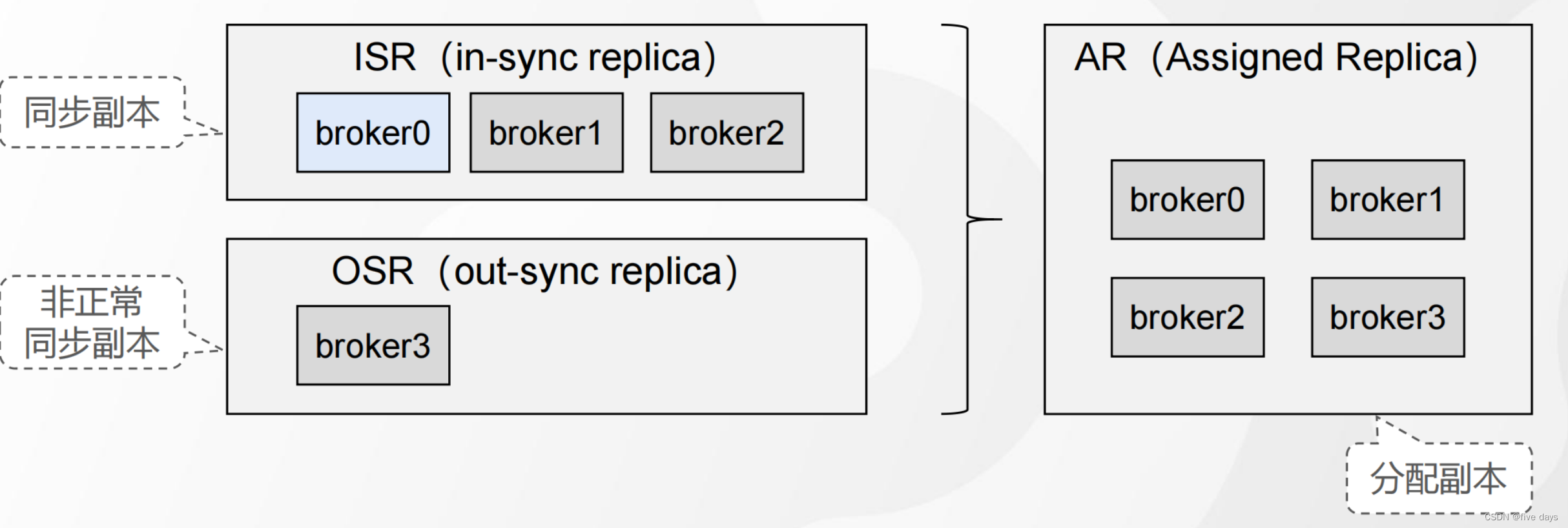
2.3 ISR机制
ISR是一组动态维护的同步副本集合,它的作用就是把leader和follower同时放到一个ISR队列中,比如上面的P0_R0挂掉了,同步不积极,那么就把它移除ISR队列,默认为30s,可以经过replica.lag.time.max.ms进行配置,当ISR中的队列都同步完了的话,就返回ACK应答信号
AR = ISR+OSR
3. 消息幂等性
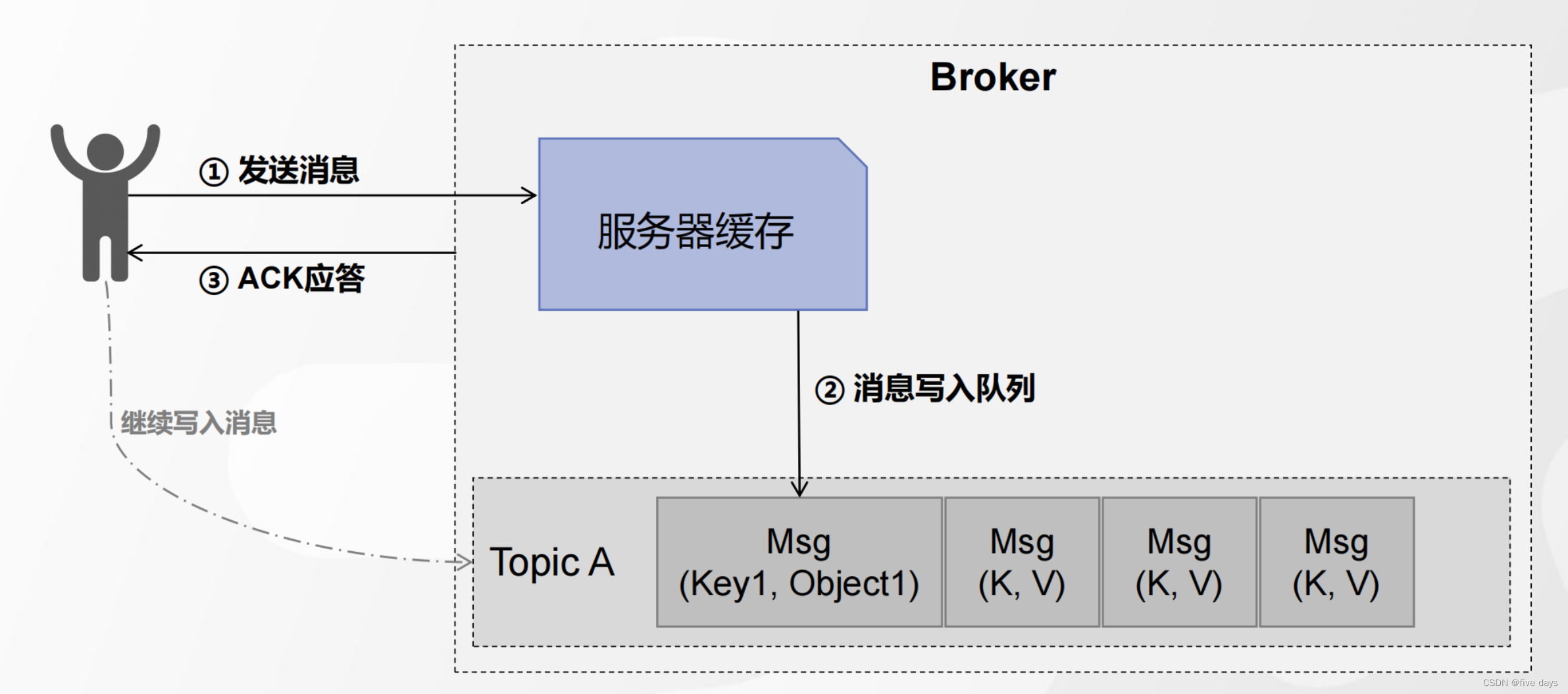
发送消息情形-1: 正常发送
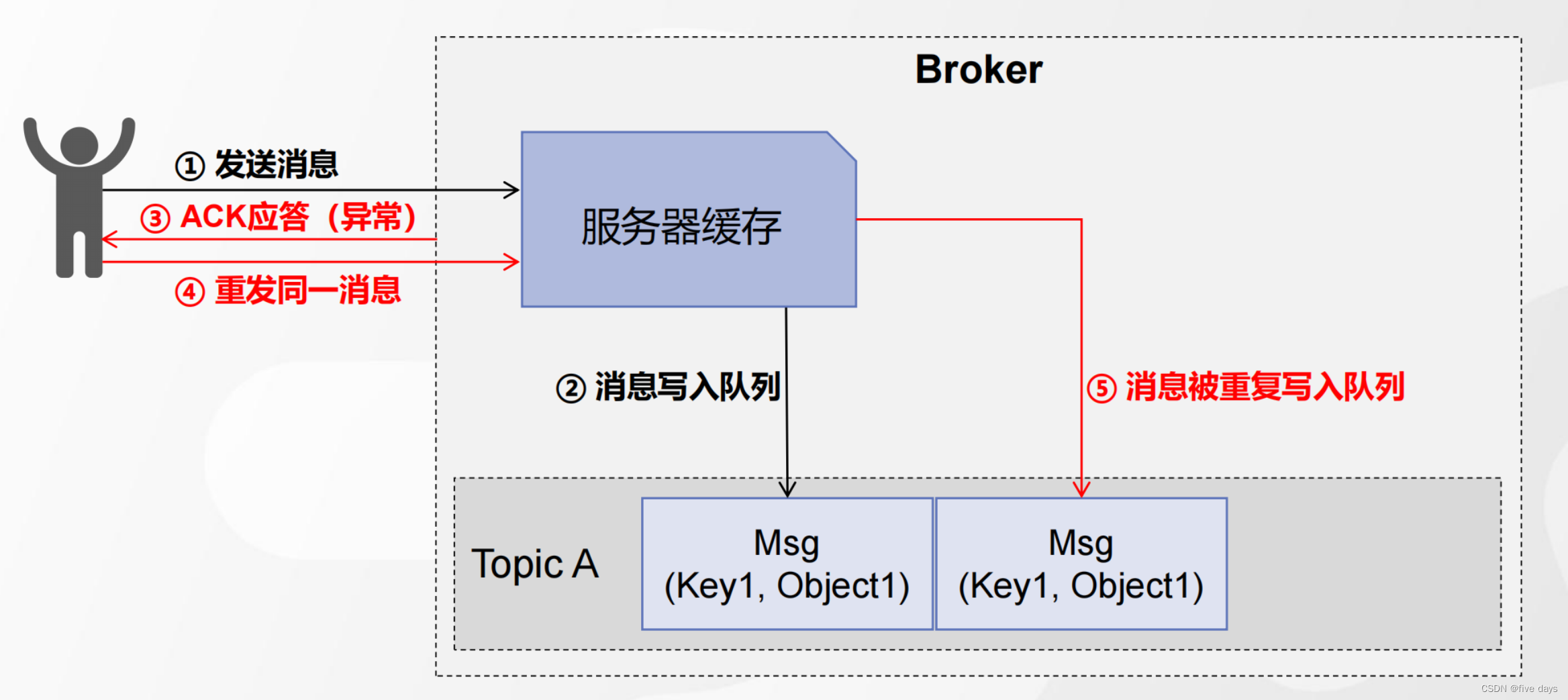
发送消息情形-2:消息发送失败,触发消息重发,造成消息重发写入
发送消息情形-3:消息发送失败,触发消息重发,消息不重复写入
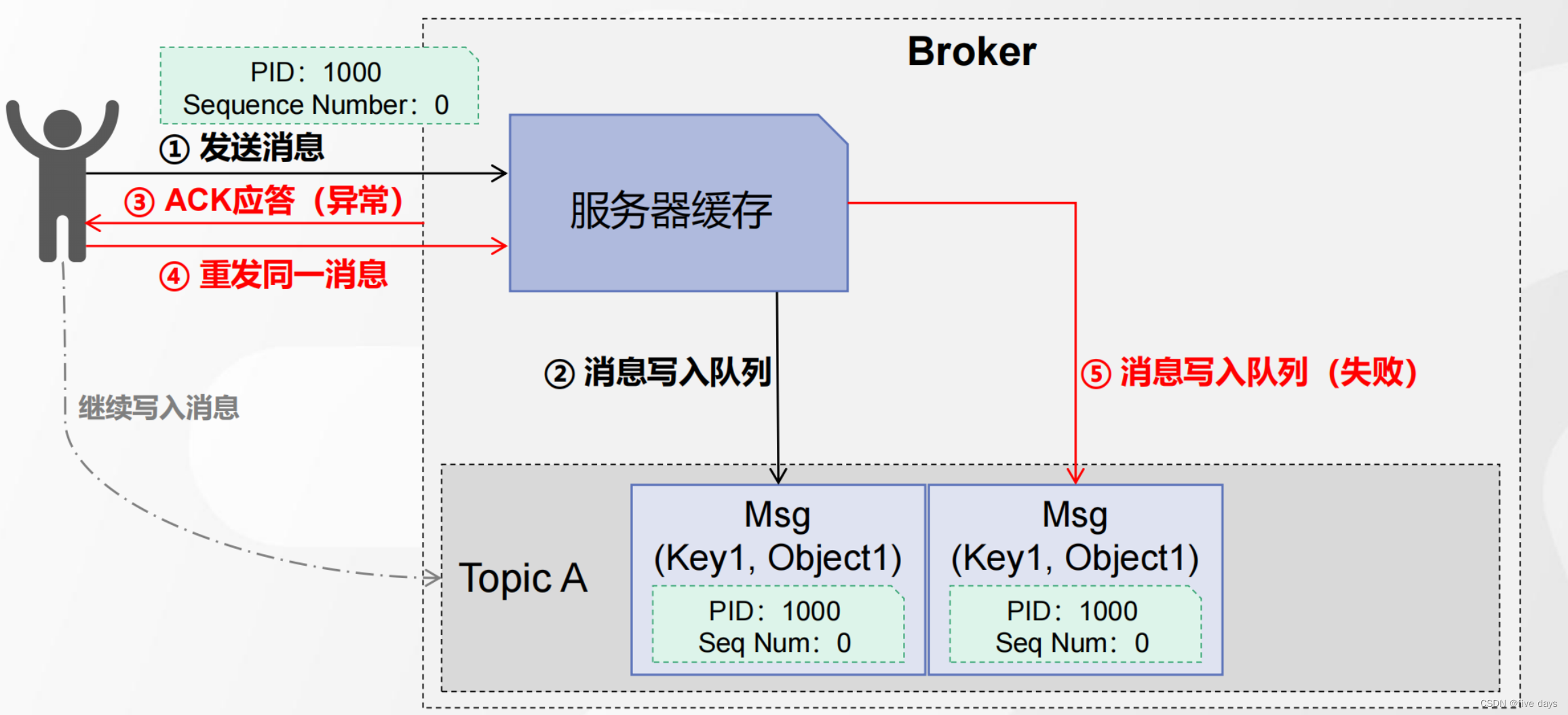
如上图所示,是怎么保证消息不被重复写入的呢?利用幂等性,在发送消息的时候新增两个参数PID与Sequence Number分别代表生产者ID和消息的编码,那么Broker存储的时候也会多加一点空间存储这两个值,当ack应答异常时,再次重发消息到队列中时,就会进行一次判断a.如果PID和sequence Number都相等,则消息写入队列失败,b.如果Sequence Number为1 则顺序写入 c.如果Sequence Number为2,则抛出异常,表示数据有丢失
幂等性生产者发送消息流程总结:
1 、 Producer 端发送消息(消息本身、 PID 、 Sequence Number )2 、 Broker 端接收到消息(将消息和 PID 、 Sequence Number 一起保存)3 、若 ACK 响应失败,生产者重试,再次发送消息
kafka是在Broker端完成的去重处理
4. Kafka生产者事务
生产者的幂等性只能保证在单分区单会话的场景下有效,因此对于多分区来说,kafka事务就提供了对多个分区写入操作的原子性。但是kafka事务的前提是开启幂等性。
kafka事务API的相关方法
initTransactions() 初始化事务beginTransaction() 开启事务commitTransaction() 提交事务abortTransaction() 中止事务sendOffsetsToTransaction()
事务的一个demo
public static void main(String[] args) {Properties props=new Properties();//props.put("bootstrap.servers","192.168.8.144:9092,192.168.8.145:9092,192.168.8.146:9092");props.put("bootstrap.servers","192.168.8.147:9092");props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");props.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");// 0 发出去就确认 | 1 leader 落盘就确认| all或-1 所有Follower同步完才确认props.put("acks","all");// 异常自动重试次数props.put("retries",3);// 多少条数据发送一次,默认16Kprops.put("batch.size",16384);// 批量发送的等待时间props.put("linger.ms",5);// 客户端缓冲区大小,默认32M,满了也会触发消息发送props.put("buffer.memory",33554432);// 获取元数据时生产者的阻塞时间,超时后抛出异常props.put("max.block.ms",3000);props.put("enable.idempotence",true);// 事务ID,唯一props.put("transactional.id", UUID.randomUUID().toString());Producer<String,String> producer = new KafkaProducer<String,String>(props);// 初始化事务producer.initTransactions();try {producer.beginTransaction();producer.send(new ProducerRecord<String,String>("transaction-test","1","1"));producer.send(new ProducerRecord<String,String>("transaction-test","2","2"));
// Integer i = 1/0;producer.send(new ProducerRecord<String,String>("transaction-test","3","3"));// 提交事务producer.commitTransaction();} catch (KafkaException e) {// 中止事务producer.abortTransaction();}producer.close();}
}kafka事务操作的基本流程
最后标记消费状态后,就可以进行消费了
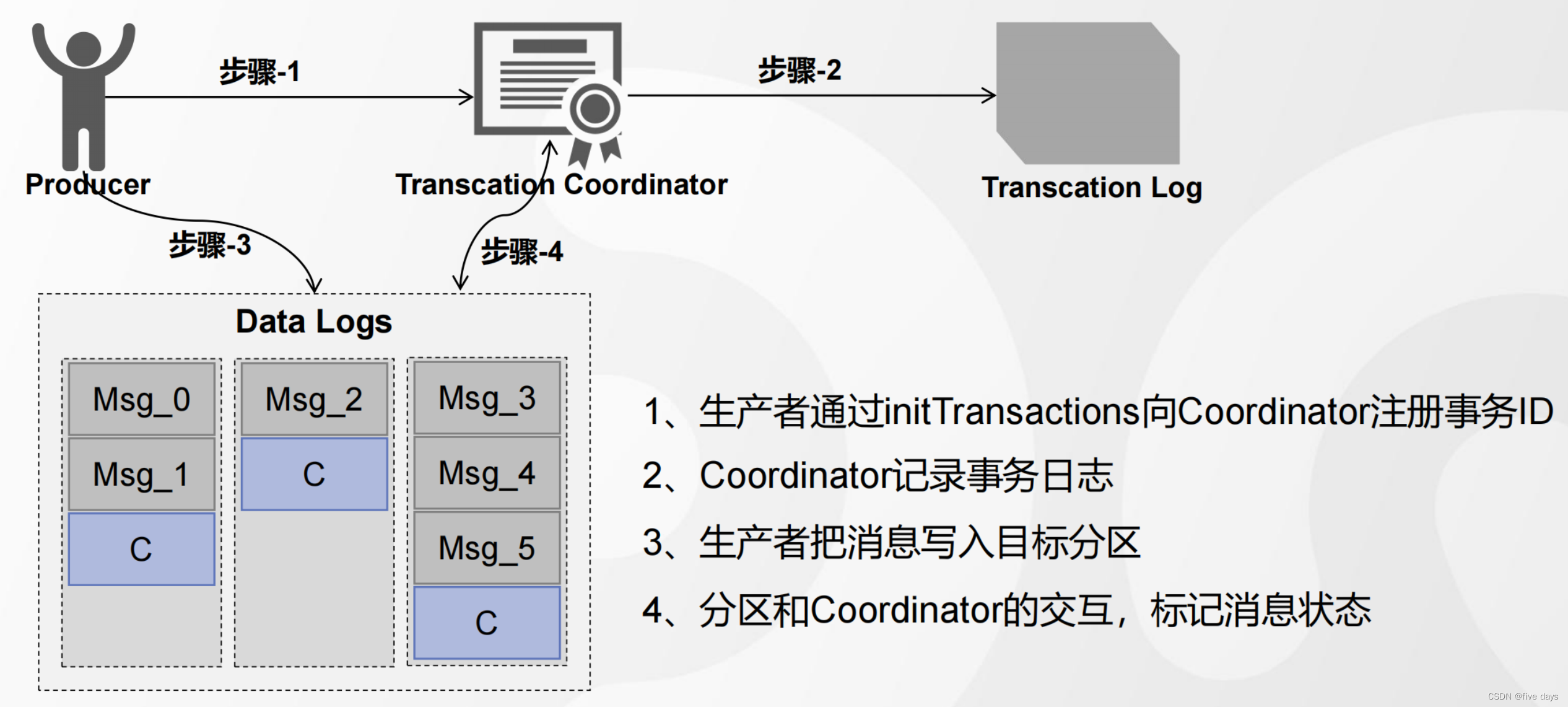
kafka的事务细节流程:
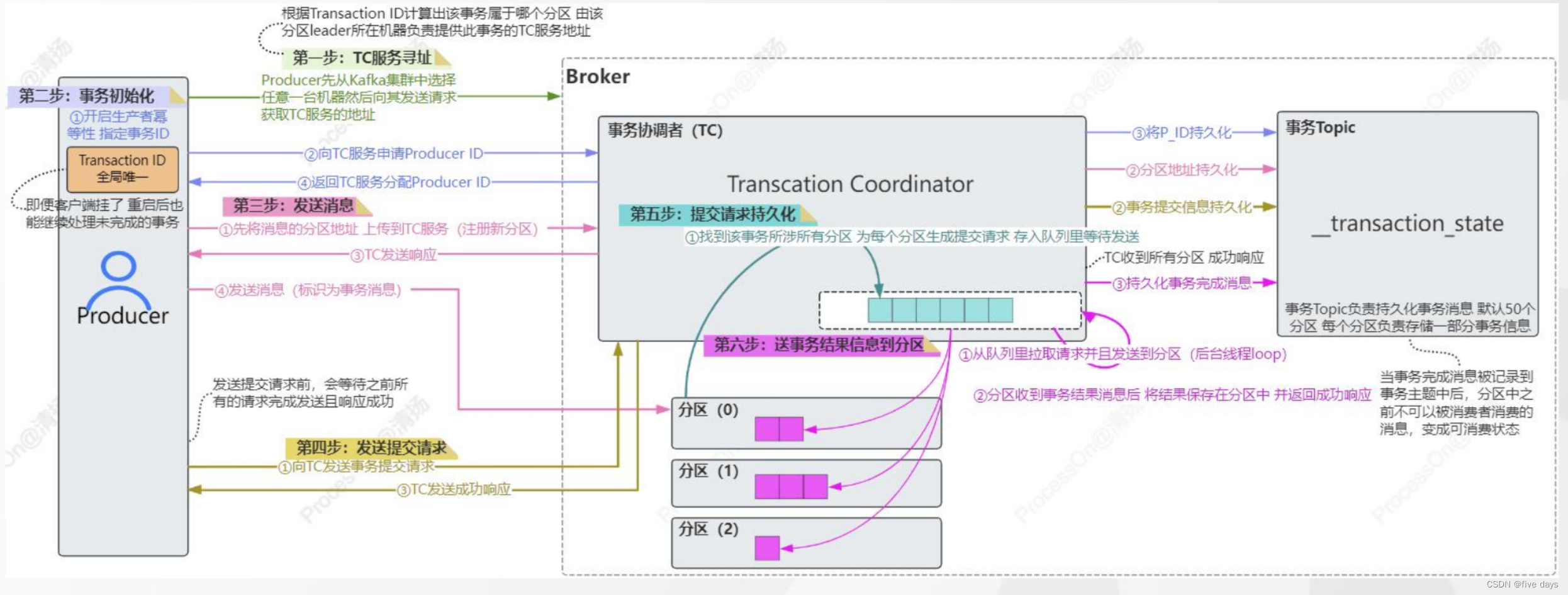
5. 总结
本文主要是介绍了kafka生产者端的一些原理,先是从源码出发,介绍了生产者发送消息到Broker经历的一系列过程:先是创建了一个sender线程,然后在发送消息的过程中一次经过拦截器、累加器、分区器最后根据分区的批量消息是否新建或者满了来触发sender线程发送到Broker服务器中。随后我们介绍了,peoducer跟broker服务器之间的交互采用的是应答机制,在这里有3种配置,可根据业务需要来具体配置,当配置-1的时候,我们分析了为什么会出现重发消息的问题,通过幂等性来保证,follower从节点挂了的情况下,应答异常,采用ISR队列机制进行避免。但是幂等性只能保证单分区单会话的场景,而针对多分区的情况下,kafka主要是采用分布式事务来解决,利用分布式ID,事务coordinattor和事务日志分二PC提交,并且对事务的状态进行存储标记,当事务的状态更改为可消费的时候,才会进行消费。
相关文章:
Kafka之Producer原理
1. 生产者发送消息源码分析 public class SimpleProducer {public static void main(String[] args) {Properties prosnew Properties();pros.put("bootstrap.servers","192.168.8.144:9092,192.168.8.145:9092,192.168.8.146:9092"); // pros.pu…...

ubuntu20.04部署gitlab流程
参考: https://blog.csdn.net/weixin_57025326/article/details/136048507 362 wget --content-disposition https://packages.gitlab.com/gitlab/gitlab-ce/packages/ubuntu/focal/gitlab-ce_16.2.1-ce.0_amd64.deb/download.deb367 sudo apt install gitlab-ce…...

C/C++动态内存管理(new与delete)
目录 1. 一图搞懂C/C的内存分布 2. 存在动态内存分配的原因 3. C语言中的动态内存管理方式 4. C内存管理方式 4.1 new/delete操作内置类型 4.2 new/delete操作自定义类型 1. 一图搞懂C/C的内存分布 说明: 1. 栈区(stack):在…...

搭建一个基于主流技术Spring Boot 2 + Vue 3 + Ant Design Vue的技术框架的简要步骤
搭建一个基于主流技术Spring Boot 2 Vue 3 Ant Design Vue的技术框架涉及前后端分离的开发模式。以下是一个简化的步骤指南,用于帮助你开始这个项目: 1. 后端(Spring Boot 2) 1.1 初始化项目 使用Spring Initializr(…...
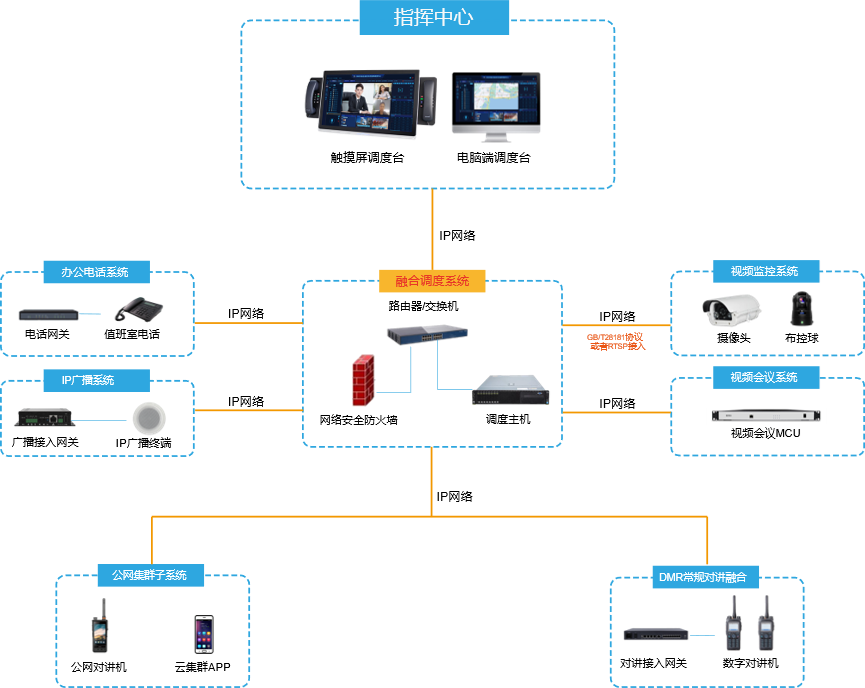
水电站生产指挥调度系统方案
一、方案背景 在碧波荡漾的大江大河之上,巍然屹立着一座座水电站,它们如同一个个巨人在默默地守护着我们的家园。在这些建设者的辛勤耕耘下,水电站在保障国家能源安全、优化能源结构以及减少环境污染等方面发挥着重要作用。 然而,…...

深度学习入门-第3章-神经网络
前面的待补充 3.6 手写数字识别 3.6.1 MNIST 数据集 本书提供了便利的 Python 脚本 mnist.py ,该脚本支持从下载 MNIST 数据集到将这些数据转换成 NumPy 数组等处理(mnist.py 在 dataset 目录下)。 使用 mnist.py 时,当前目录必须…...

如何使用AES128位进行视频解密
要实现AES128位加解密,可以使用JavaScript的crypto-js库。以下是一个简单的示例: HTML代码: <video controlsList"nodownload" controls></video> 首先,需要安装crypto-js库: npm install cr…...

ArkTS是前端语言吗
ArkTS是前端语言吗 ArkTS,这个名词在现代软件开发领域里逐渐崭露头角,但对于许多人来说,它仍旧是个神秘而令人困惑的存在。那么,ArkTS究竟是前端语言吗?为了回答这个问题,我们需要从多个方面进行深入剖析。…...

git上新down下来的项目,前端启动报错npm ERR! code 1 npm ERR! path E:\code\vuehr\node_modul
解决方法在下面 问题1:> vuehr0.1.0 serve > vue-cli-service serve vue-cli-service 不是内部或外部命令,也不是可运行的程序 或批处理文件。 在项目目录下执行命令npm i -D vue/cli-service来安装vue/cli-service依赖。 运行gitee上下载的…...

oc中的数据结构在都在什么位置
数据结构 在Objective-C中,数据结构可以存在于以下几个位置: 堆(Heap):堆是动态分配的内存空间,用于存储动态创建的对象和数据结构。堆上的数据需要手动进行内存管理,即手动分配和释放内存。 …...

多云世界中的 API 治理
随着企业不断拥抱数字化转型,许多企业正在采用多云战略,以充分利用不同云平台的独特优势和功能。这种方法使企业能够避免被供应商锁定,提高灵活性,并优化 IT 成本。然而,在多个云平台上管理应用程序接口并非易事。它带…...

【稳定检索/投稿优惠】2024年环境、资源与区域经济发展国际会议(ERRED 2024)
2024 International Conference on Environment, Resources and Regional Economic Development 2024年环境、资源与区域经济发展国际会议 【会议信息】 会议简称:ERRED 2024 大会地点:中国杭州 会议官网:www.icerred.com 会议邮箱࿱…...
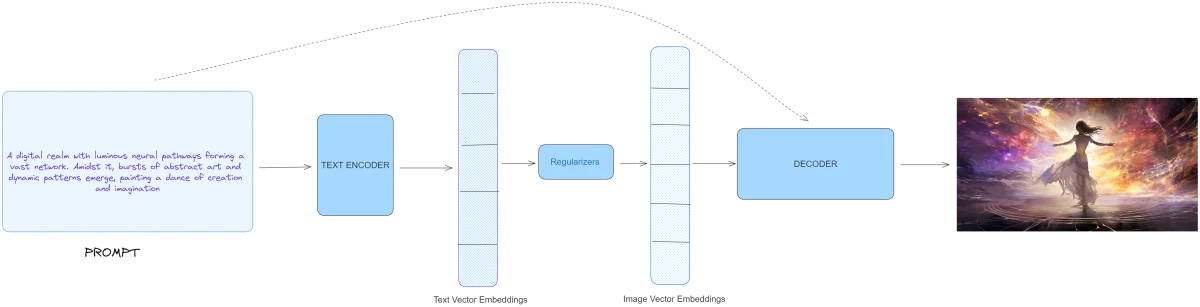
生成式 AI——ChatGPT、Dall-E、Midjourney 等算法理念探讨
1.概述 艺术、交流以及我们对现实世界的认知正在迅速地转变。如果我们回顾人类创新的历史,我们可能会认为轮子的发明或电的发现是巨大的飞跃。今天,一场新的革命正在发生——弥合人类创造力和机器计算之间的鸿沟。这正是生成式人工智能。 生成模型正在模…...

C-数据结构-树状存储基本概念
‘’’ 树状存储基本概念 深度(层数) 度(子树个数) 叶子 孩子 兄弟 堂兄弟 二叉树: 满二叉树: 完全二叉树: 存储:顺序,链式 树的遍历:按层遍历࿰…...

【Linux-Yocto】
Linux-Yocto ■ 1.1 安装 Git 与配置 Git 用户信息■ 1.2 获取 Yocto 项目■ 1.3 开始构建 Yocto 文件系统■ 1.4 构建 SDK 工具■■■ ■ 1.1 安装 Git 与配置 Git 用户信息 sudo apt-get install git git config --global user.name "username" // 配置 Git 用户名…...

一文掌握JavaScript 中类的用法
文章导读:AI 辅助学习前端,包含入门、进阶、高级部分前端系列内容,当前是 JavaScript 的部分,瑶琴会持续更新,适合零基础的朋友,已有前端工作经验的可以不看,也可以当作基础知识回顾。 这篇文章…...

国密算法:信息安全的守护者
在数字化时代,信息安全已成为国家安全的重要组成部分。国密算法,作为中国自主研发的一套密码算法体系,对于提升国家信息安全水平、保障关键信息基础设施的安全具有重要意义。本文将详细介绍国密算法的组成、特点以及在信息安全领域的应用。 国…...

产品经理瞎扯:餐饮门店怎么做好服务实现自救
温馨提示:全文4180字,阅读耗时约15分钟。 相信大家都能感觉到去年下半年到现在,很多行业特别是餐饮行业经营都比较困难。于是我就想是否可以通过产品设计以及运营动作,来帮助门店提高营业额以及顾客满意度呢? 正好前…...

字节裁员!开启裁员新模式。。
最近,互联网圈不太平,裁员消息此起彼伏。而一向以“狼性文化”著称的字节跳动,却玩起了“低调裁员”,用一种近乎“温柔”的方式,慢慢挤掉“冗余”的员工。 “细水长流”:裁员新模式? 不同于以往…...

计组雨课堂(5)知识点总结——备考期末复习(xju)
在汇编语言源程序中,“微指令语句"不是常见的组成部分,因为微指令通常是在硬件层面进行处理的,而不是在汇编语言层面。因此,不属于汇编语言源程序的是"微指令语句”。在汇编语言中,组成指令语句和伪指令语句…...
漏洞原理与漏洞复现(基于vulhub))
log4j2(CVE-2021-44228)漏洞原理与漏洞复现(基于vulhub)
声明:部分内容来源于网络,如若侵权请联系删除 什么是log4j2? Log for Java,Apache的开源日志记录组件,是一个Java的日志记录工具。在log4j框架的基础上进行了改进,并引入了丰富的特性,可以控制日志信息输送…...
)
【Gartner认证实践框架】:AI Agent客服上线前必须完成的12项合规性验证清单(含GDPR/等保2.0/金融信创适配)
更多请点击: https://intelliparadigm.com 第一章:AI Agent客服的合规性验证战略定位 在金融、医疗、电信等强监管行业,AI Agent客服系统不仅需满足功能与体验目标,更须将合规性嵌入其设计、开发与运营全生命周期。合规性验证不是…...

迷拟极速飞车——极致竞速新体验,重塑线下轻娱新标杆
随着国内文旅休闲、商业游乐行业的快速发展,消费者的线下娱乐审美与体验标准持续升级。传统游乐项目模式固化、玩法单一,同质化问题愈发突出,千篇一律的休闲设施早已无法满足全年龄段游客的多元化游玩需求。无论是城市商业综合体、城郊文旅景…...

告别断电重启就丢程序:深入聊聊紫光同创FPGA的Flash固化与CPLD内置eFlash配置差异
紫光同创FPGA与CPLD配置存储机制深度解析:从瞬态下载到永久固化的技术实现 在数字电路设计领域,FPGA和CPLD的可重构特性为硬件开发带来了极大灵活性。然而,这种灵活性背后需要可靠的配置存储机制作为支撑——断电后程序能否自动恢复…...

sdk-manager-plugin源码剖析:学习Gradle插件架构的完美案例 [特殊字符]
sdk-manager-plugin源码剖析:学习Gradle插件架构的完美案例 🚀 【免费下载链接】sdk-manager-plugin DEPRECATED Gradle plugin which downloads and manages your Android SDK. 项目地址: https://gitcode.com/gh_mirrors/sd/sdk-manager-plugin …...

基于STM32的智能小车:从硬件选型到PID算法实战
1. 项目概述:从零到一打造你的第一辆智能小车如果你对嵌入式开发感兴趣,想找一个能串联起单片机、传感器、电机控制和无线通信的综合项目,那么基于STM32F103的智能小车绝对是一个绝佳的选择。它不像一个简单的LED闪烁实验那样枯燥,…...

100行代码实现扩散模型:PyTorch版终极入门指南
100行代码实现扩散模型:PyTorch版终极入门指南 【免费下载链接】Diffusion-Models-pytorch Pytorch implementation of Diffusion Models (https://arxiv.org/pdf/2006.11239.pdf) 项目地址: https://gitcode.com/gh_mirrors/di/Diffusion-Models-pytorch 你…...

从零开始:如何用Fabric示例模组快速入门Minecraft模组开发
从零开始:如何用Fabric示例模组快速入门Minecraft模组开发 【免费下载链接】fabric-example-mod Example Fabric mod 项目地址: https://gitcode.com/gh_mirrors/fa/fabric-example-mod 你是否曾经想过为Minecraft添加自己的创意功能,却因为复杂的…...

Joy-Con Toolkit:一站式解决Switch手柄所有问题的智能管理工具
Joy-Con Toolkit:一站式解决Switch手柄所有问题的智能管理工具 【免费下载链接】jc_toolkit Joy-Con Toolkit 项目地址: https://gitcode.com/gh_mirrors/jc/jc_toolkit Joy-Con Toolkit是一款专为Nintendo Switch手柄设计的开源管理工具,为游戏玩…...

Finch微服务部署:基于Finagle的生产环境最佳实践
Finch微服务部署:基于Finagle的生产环境最佳实践 【免费下载链接】finch Scala combinator library for building Finagle HTTP services 项目地址: https://gitcode.com/gh_mirrors/fin/finch Finch是一个基于Scala的组合器库,专为构建Finagle H…...