Linux网络编程:传输层协议|UDP|TCP
知识引入:
端口号:
当应用层获得一个传输过来的报文时,这时数据包需要知道,自己应该送往哪一个应用层的服务,这时就引入了“端口号”,通过区分同一台主机不同应用程序的端口号,来保证数据传输的可靠性!
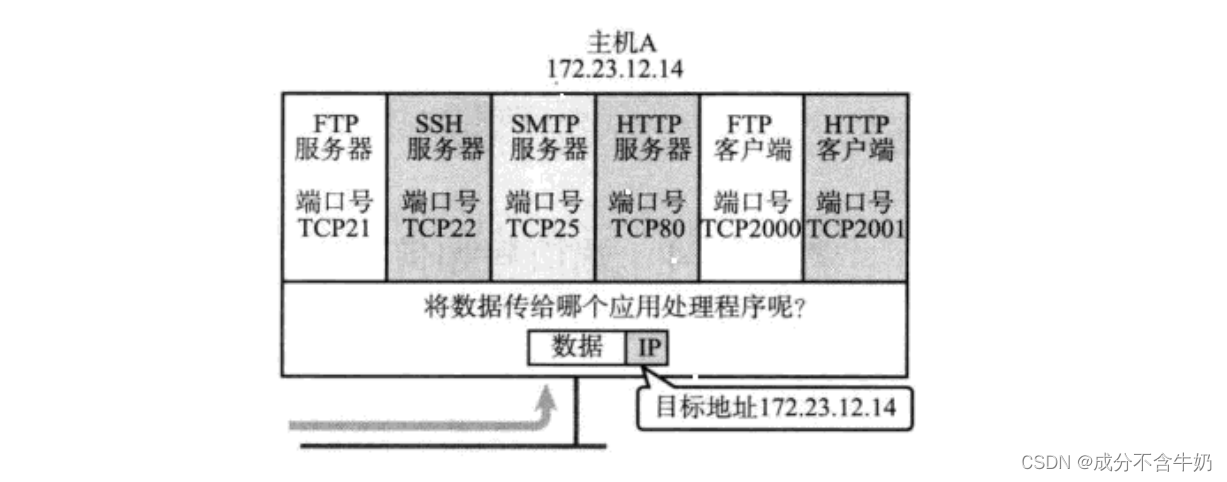
而我们在之前的学习知道,ip地址是唯一的地址标识,那么我们借助ip地址和端口号是不是就能找到网络中唯一的一台主机?答案是肯定的,这也就是传输层协议存在的意义之一!
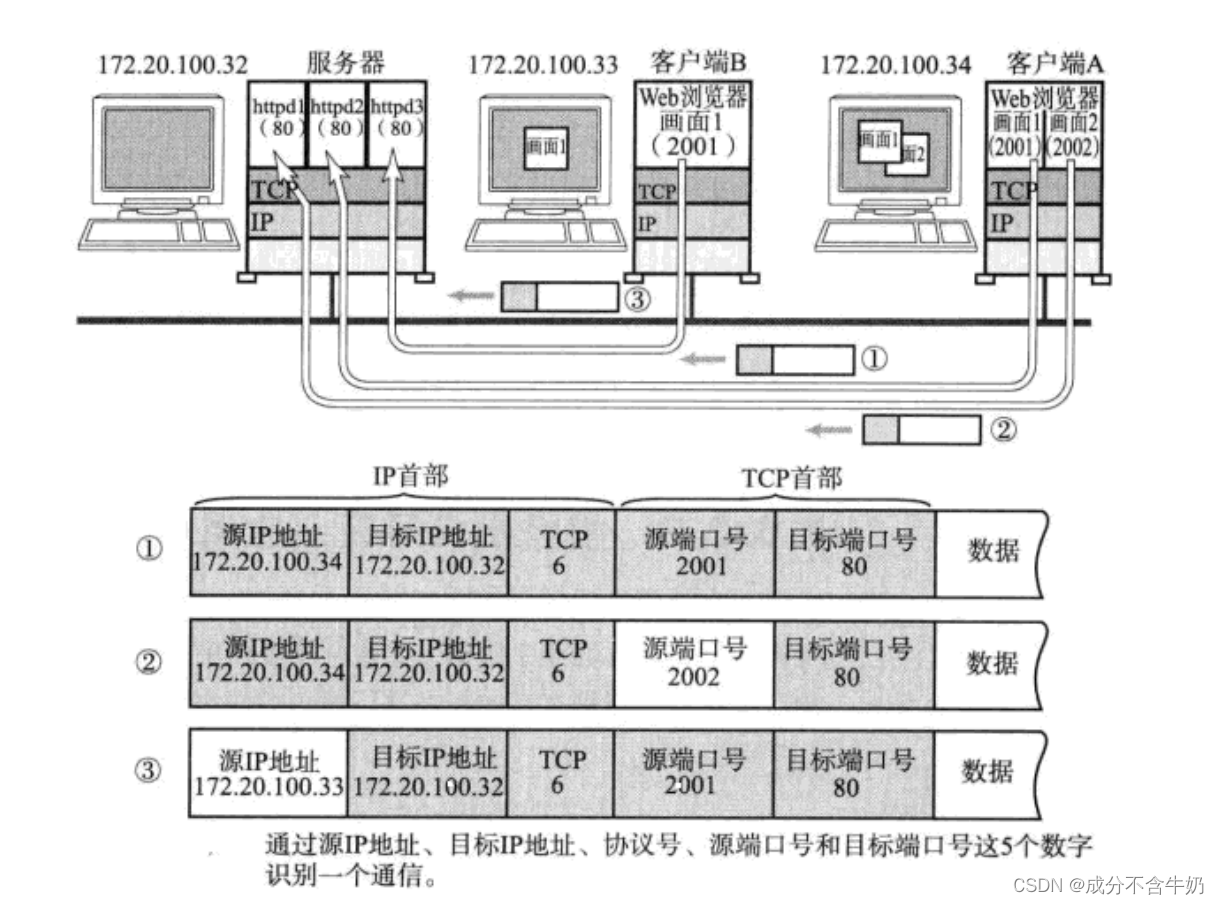
在TCP/IP协议中, 用 "源IP", "源端口号", "目的IP", "目的端口号", "协议号" 这样一个五元组来标识一个通信
如图我们通过源ip和源端口号,就知道信息是从哪来的,知道了目的ip和目的端口号就知道信息是去往哪里的。那么就能够实现网络中唯二的两个进程通过网络进行进程间通信了!!!
端口号划分:
- 0 - 1023: 知名端口号, HTTP, FTP, SSH等这些广为使用的应用层协议, 他们的端口号都是固定的.
- 1024 - 65535: 操作系统动态分配的端口号. 客户端程序的端口号, 就是由操作系统从这个范围分配的.
查看网络连接状态命令:
// -ntpl n-带数字 t-TCP协议 p-服务名称 l-只查看listen服务
sudo netstat -ntpl// ss命令也可以查网络服务
ss -nltp常用选项:
- n 拒绝显示别名,能显示数字的全部转化成数字l 仅列出有在 Listen (监听) 的服務状态
- p 显示建立相关链接的程序名
- t (tcp)仅显示tcp相关选项
- u (udp)仅显示udp相关选项
- a (all)显示所有选项默认不显示LISTEN相关
1.UDP协议
1.1.UDP协议端格式
如图:UDP协议报文前8字节为UDP协议的报头,后面的即为有效载荷。
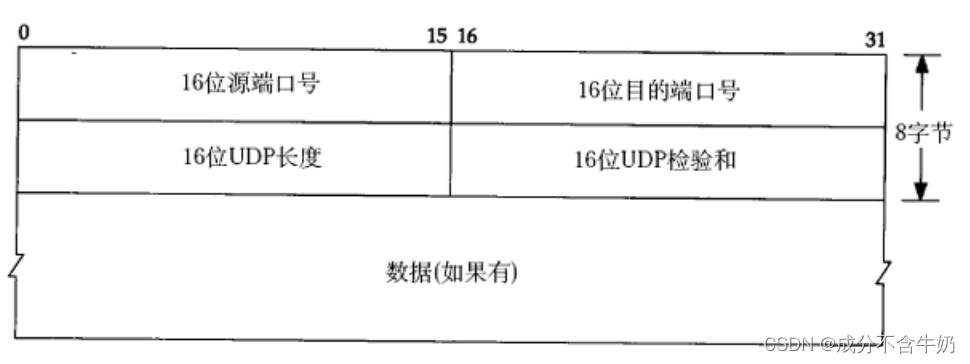
我们知道网络传输需要解决的四个问题:
- 报文如何将报头和有效载荷分离
- 有效载荷如何向上交付给对应应用层程序
- 报文内容是否完整
- 报文内容是否有误
联系UDP协议格式,我们发现以上四个问题对应:
- 解析固定报头长度来分开报头和有效载荷
- 再通过目的端口号将有效载荷交付给应用层服务
- 16位UDP长度对应着报文的长度(当长度不符时,直接丢包)
- 而16位UDP检验和检测是否在传输过程中出现0变成1、1变成0
通过UDP协议报头的设计,那么我们就解决了网络传输的4个问题,而在这里我们也能理解报头(协议)是一个结构化字段。
struct UdpHeader
{uint32_t src_port:16;uint32_t dest_port:16;uint32_t length:16;uint32_t check_sum:16;
}
又因为传输层是实现在操作系统中,也就是操作系统需要维护获得的UDP报文,需要对UDP报文实现“先描述再组织”
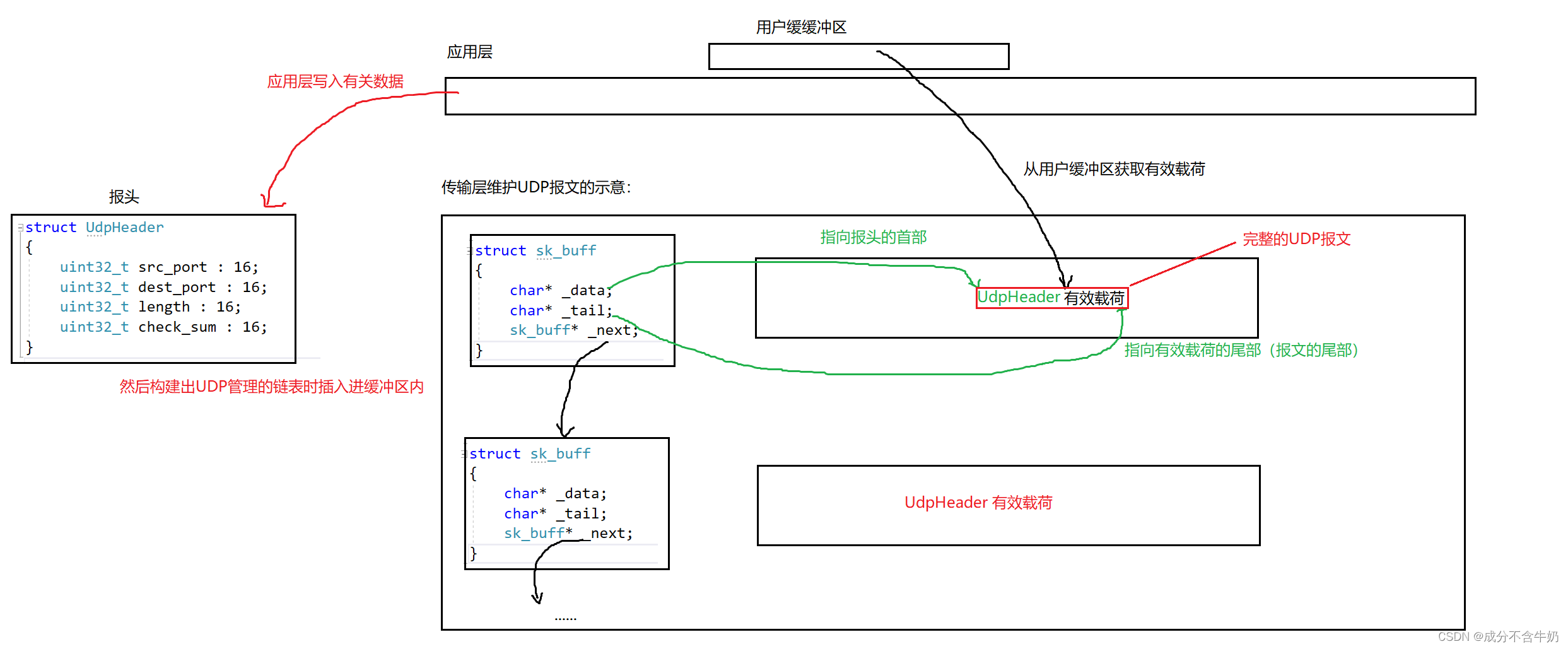
如图为:发送端如何形成UDP报文结构示意
- 首先应用层需要存在报头的结构化对象和管理报文信息的sk_buff结构化对象
- 当用户准备通过sendto进行发送时,通过bind函数将对应端口号写入进报头信息中,另外有效载荷写入sk_buff指向的缓冲区中,这时有tail执行有效载荷的尾,_data指向有效载荷的头部(_data-_tail即为有效载荷的长度)
- 传输层首先将_data向左移动8个字节,给UDP的报头放入,接着完善报头中的报文长度信息和check_num(通过二进制位运算)
- 最终就形成了一段UDP报文
因为系统中可能存在多份待发送的UDP报文,所以我们需要通过数据结构来管理这些报文。最终UDP协议就实现了!!!
当接收端接收到UDP报文时:
- 先分开报头和有效载荷(通过分离前8个字节数据),然后读取报头中的报文长度,就能找到有效载荷
- 通过对有效载荷进行二进制位运算,判断前后的check_num和为0,不为0就丢弃报文。
- 获取到报文后就可以通过对应端口,找到接受端的应用层服务
最终我们就完成了UDP通信!!!
1.2.UDP的特点
UDP传输的过程类似于寄信,为什么这么说呢,这和UDP的特点有关
- 无连接: 知道对端的IP和端口号就直接进行传输, 不需要建立连接;
- 不可靠: 没有确认机制, 没有重传机制; 如果因为网络故障该段无法发到对方, UDP协议层也不会给应用层 返回任何错误信息;
面向数据报: 不能够灵活的控制读写数据的次数和数量;(应用层交给UDP多长的报文, UDP原样发送, 既不会拆分, 也不会合并; )
我们在传输报文时,只要知道对端的地址就可以进行传输,不需要事先通知对方才能够寄信。另外,当我们写信出去后我们就无法获得这封信的状态,除非他被对方收到,并且返回收到信息给你。最终,信的寄和读都是一次的行为,跟你信里面写了多少内容无关,是一个整体。
值得注意的是:UDP协议允许报文最长为16位,也就是64k的大小,当我们传输的内容大于64k时,我们就需要多次将数据分为64kb的报文,接着不断传输。
2.TCP协议
TCP协议的学习任务十分繁重,建议慢慢品。
2.1.TCP协议格式
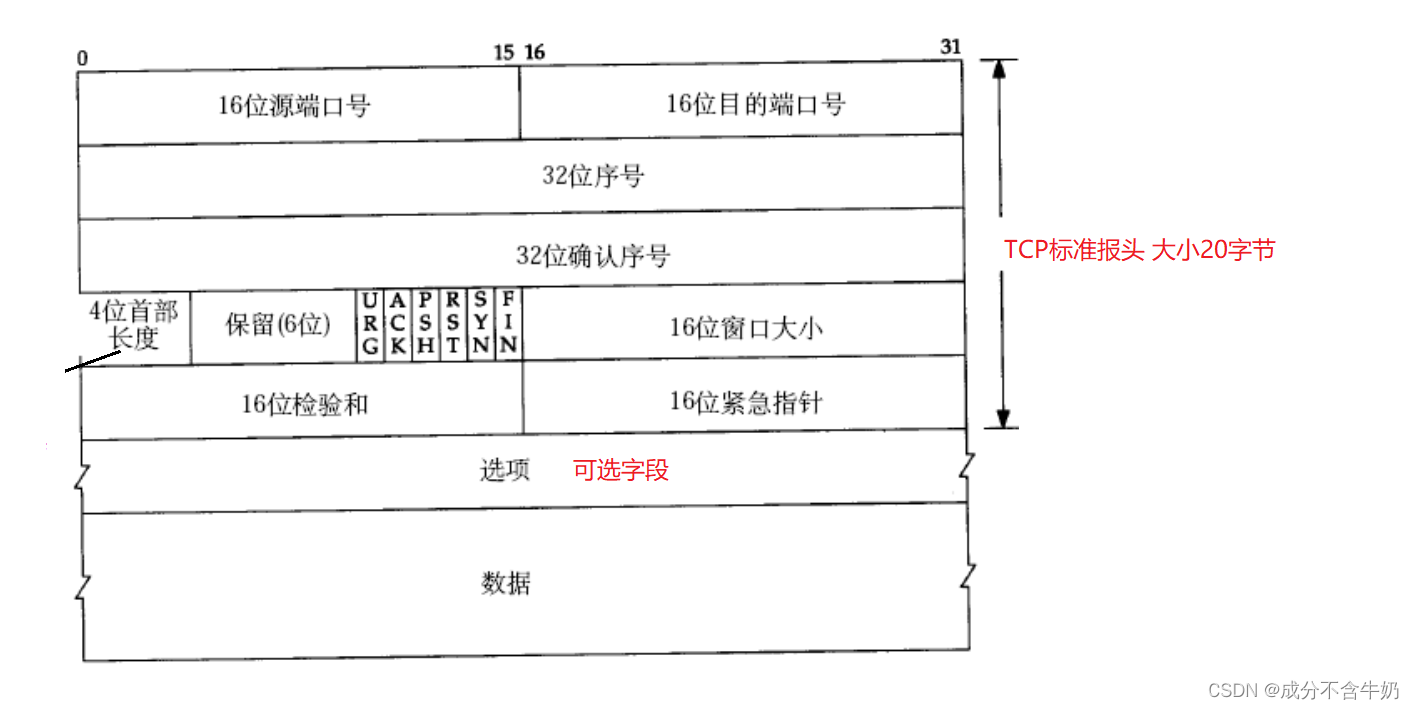
如图TCP协议格式明显复杂于UDP协议,接下来我们学习一下TCP协议中的重要字段。
ps:如果发现这些重要字段的学习过于抽象,可以大概记忆一下概念,结合下面的TCP机制学习!
选项
表示TCP协议标准报头携带的额外信息,用于增强TCP协议的功能和灵活性,大小为0-40字节(与4位首部长度有关)。
4位首部长度(4位TCP报头长度)
4位首部长度对应着0000-1111,即【0,15】,并且1单位对应着4个字节,所以最终4为首部长度对应着【0,60】字节。
在实际应用中4位首部长度是用来分离协议报头和有效载荷的!
- 首先当应用层获取到报文时,截取前20字节的标准报头,访问到4位首部地长度
- 获取到4位首部长度,如果4位首部长度为20(表示选项为空),那么后续数据就是有效载荷。如果大于20字节,说明需要截取大于部分之后为有效载荷
6位标志位
- URG: 紧急指针是否有效(紧急任务报文)
ACK: 确认号是否有效(确认报文)
PSH: 提示接收端应用程序立刻从TCP缓冲区把数据读走(询问报文段)
RST: 对方要求重新建立连接; 我们把携带RST标识的称为复位报文段
SYN: 请求建立连接; 我们把携带SYN标识的称为同步报文段
FIN: 通知对方, 本端要关闭了我们称携带FIN标识的为结束报文段
一个标志位对应着一个比特位!而6位标志位是为了定义报文的类型,因为服务器一般只有一个,而获取服务的客户端有无数个,那么服务器在通信时就需要标识不同的报文类型
16位窗口大小
窗口大小字段用于告诉接收端,发送端目前还有多少数据没有收到确认,还可以发送多少数据。用于实现流量控制!!!
32位序号和32位确认序号
32位序号用来保证数据的按序到达,32位确认序号用来保证发送端发送的哪些数据已经被接受到了(该序号之前的数据,全部收到)。
16位紧急指针
表示紧急数据在有效载荷中的偏移量。但是大小只有一字节
需要结合6位标志位中的URG标志
2.2.不同类型报文和TCP通信
我们知道在TCP协议字段中存在6位的标志位,而这6位的标志位对应着6种类型的报文,分别在TCP通信的不同场景中发挥着各自的作用。
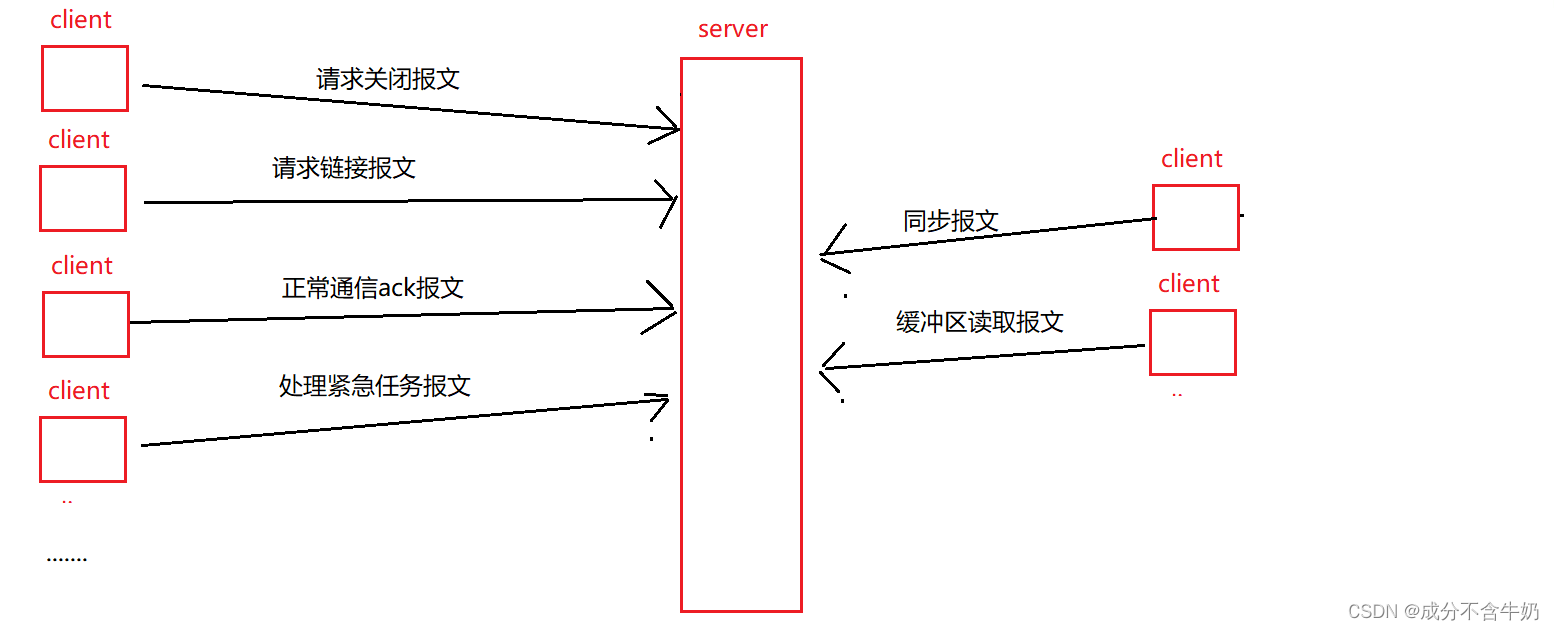 因为一个服务器会处理大量客户端的报文请求,所以我们也需要学习不同类型的报文请求!!!在这部分内容中我们主要讲解URG、RSH、RST标志位对应字段的报文,其他标志位都是比较常见的我们会在TCP整个模块或多或少会有提及……
因为一个服务器会处理大量客户端的报文请求,所以我们也需要学习不同类型的报文请求!!!在这部分内容中我们主要讲解URG、RSH、RST标志位对应字段的报文,其他标志位都是比较常见的我们会在TCP整个模块或多或少会有提及……
处理紧急任务报文---URG
在接收端,报文的维护是通过链表式的队列,也就是处理任务时需要遵守先进先出原则,当出现一些紧急任务时(比如:客户端发现传输的大文件数据传错了,这时取消传输),就需要将这个任务及时的关闭,那么就需要将该报文插入特定的标志位,当操作系统读取到报文的这个标志位时,就允许这个任务插队!!!
询问报文---RSH
我们在流量控制的学习中知道,每次报文发送时会携带本端的缓冲区的窗口大小,在极端场景下,可能某一次回复的报文中窗口大小为0,也就是当时本端的缓冲区不支持传输(读取速度过慢)。那么这时另一端,就暂时不再发送报文!!!
那么另一端知道什么时候再次发送报文呢?所以这时发送端可以定一段时间发送一个询问报文,并且带上RSH字段来告诉接收端尽快进行数据的读取!!!
除了发送询问报文这个方式,当接收端发现缓冲区的大小达到某一个标准时,会给发送端发送新的窗口大小的报文。
链接重置报文---RST
网络通信过程中我们无法避免报文在网络中丢失,在TCP三次握手中,对于客户端建立连接是在给服务器发送ACK报文时完成,对于服务端则是接收到这个ACK才完成链接。而这次ACK报文的传输出现丢包时,会导致服务端无法完成链接。
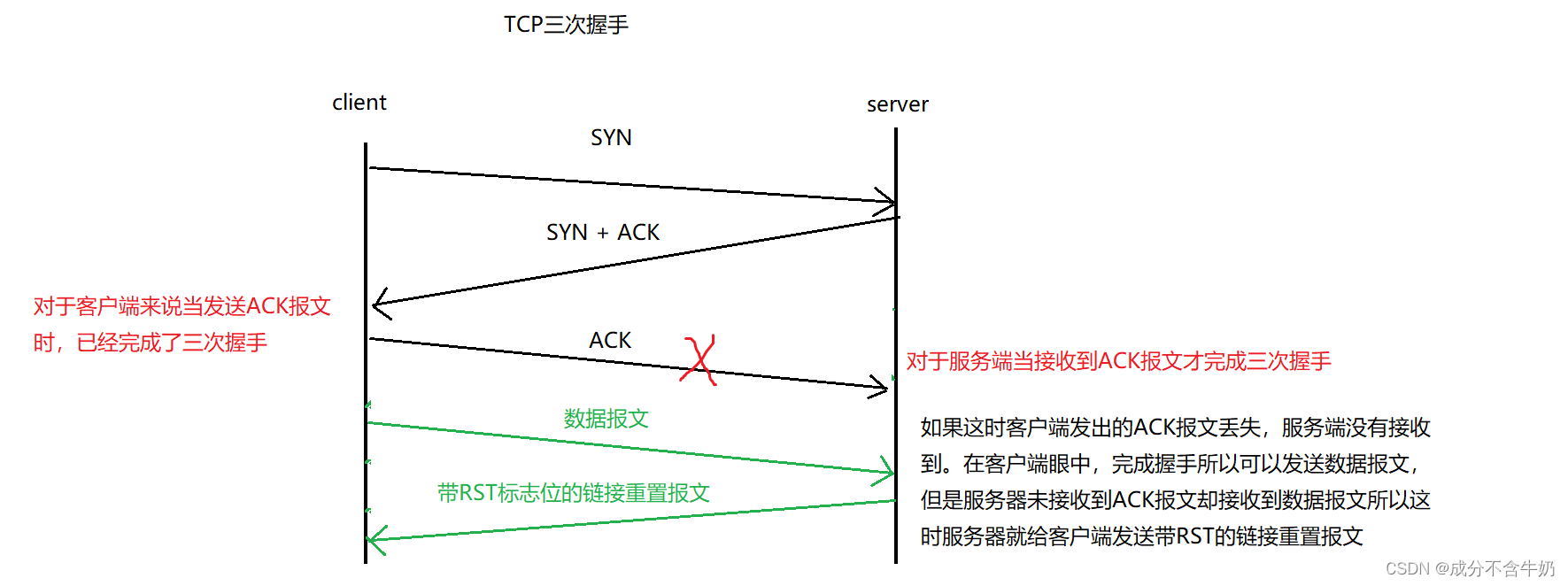
另外当出现网络链接认知不一致时(某一端以为完成链接了,另一端却认为没有完成),就需要发送RST标志的报文来实现重新链接。例如:当我们使用某个APP时,突然网络断开了,并且客户端断链了,这时网络恢复后,客户端就可以通过发送RST标志的报文来实现重新链接。
2.3.确认应答机制
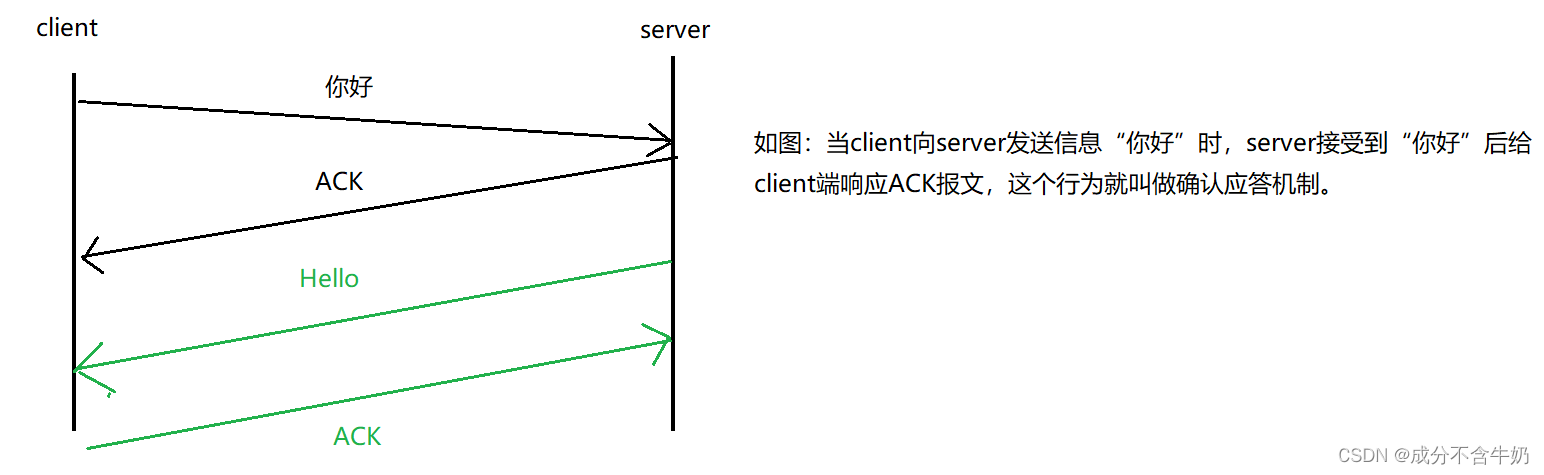
在网络传输中,因为距离变长的问题,可能会出现信息传递无法到达另一端的问题,所以TCP协议为了保证发送端和接收端的高精度的信息交互,实现了确认应答机制。这种应答机制双方都遵守
当发送端发送一段报文后,如果接收端收到就向发送端发送ACK确认报文!
这样就实现了:如果接收到应答,对于发送方,就能保证上一条信息对方已经收到!!!
因为网络传输存在时延,并且TCP发送报文可以是并行同时发送大量报文,发送端发送报文的顺序和接收端接收到报文的顺序很可能出现不同,所以我们需要保证数据的按序到达!!!
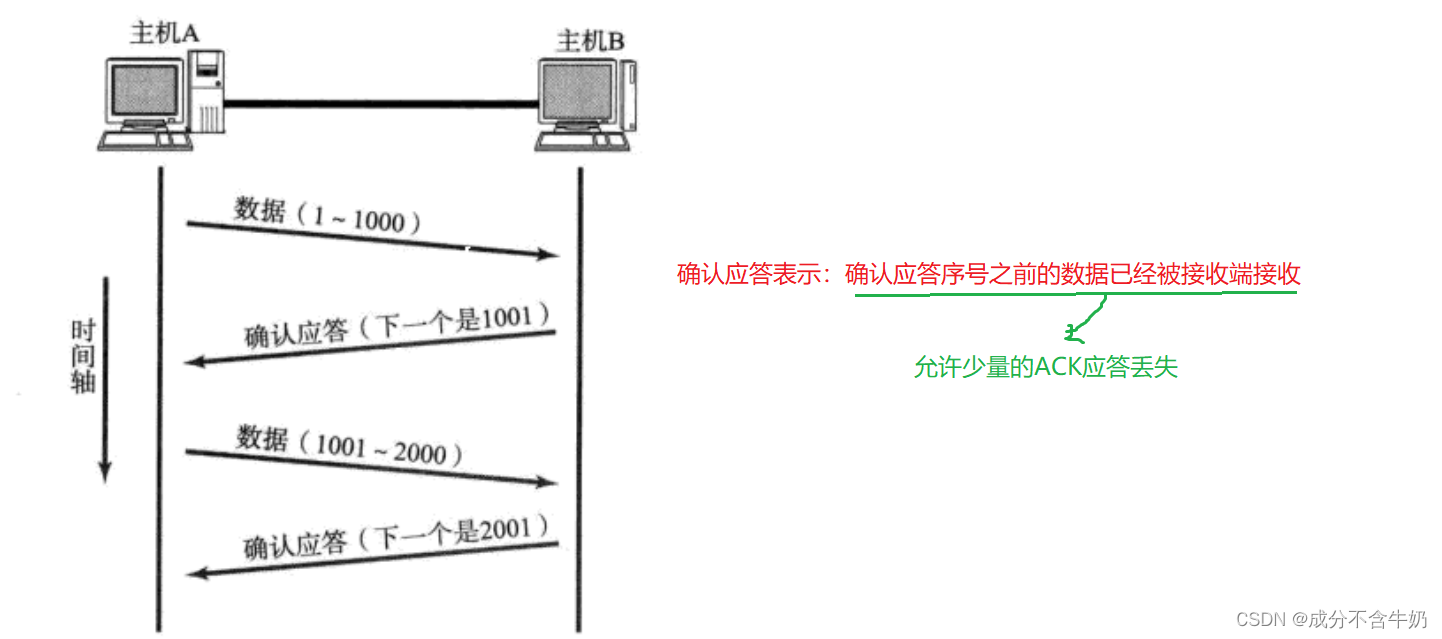
这时我们结合报文中报头字段32位序号,将信息进行排序。然而对于每一个发送的报文,我们需要通过确认应答机制获取对应的ACK报文,这时通过报头字段的32位确认信号。
这时就衍生了一个问题:为什么需要分开两个字段,不能将32位序号和32位确认序号合并?
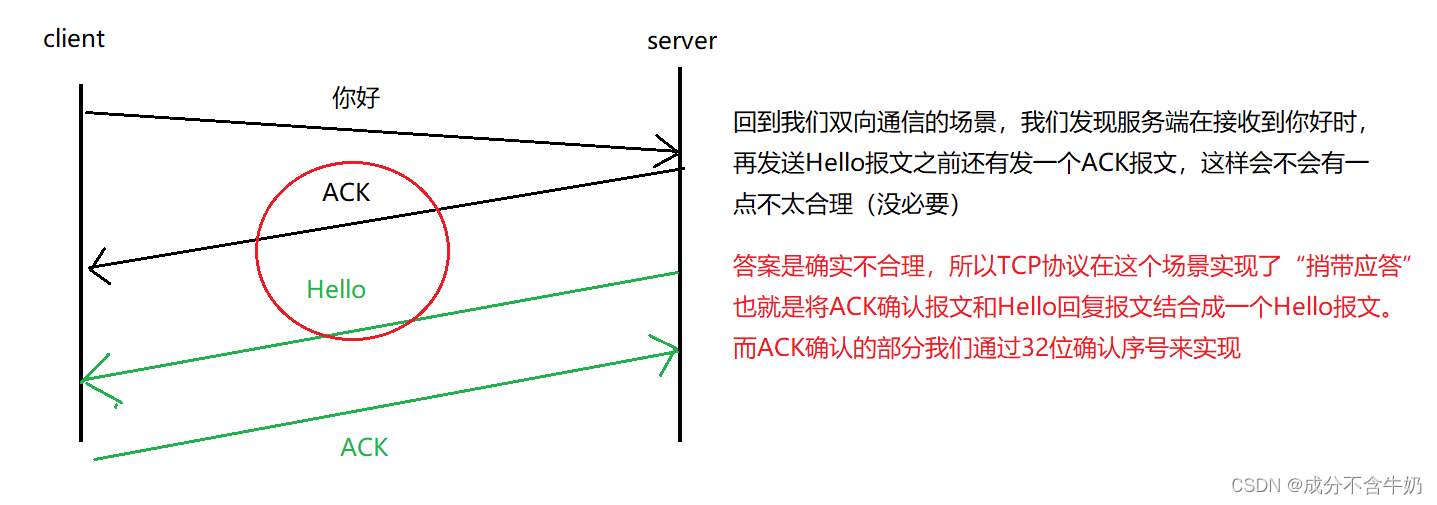
为了让TCP协议的应答机制更加的合理化,于是在TCP报头协议字段就分开了32位序号和32位确认序号。
- 32位序号保证了数据在应用层按序到达。
- 32位确认序号既实现了确认发送端的哪些数据已经被收到,又可以让双向通信时应答报文既可以作为ACK报文,又可以作为数据的报文。
在这种场景中,同一时间这两种序号都需要被使用,完成自己各自的功能,也就是不能够将他们合并成一个模块,实现不同的功能!!!
讲到这里还是有点抽象,我们来看一下这个场景
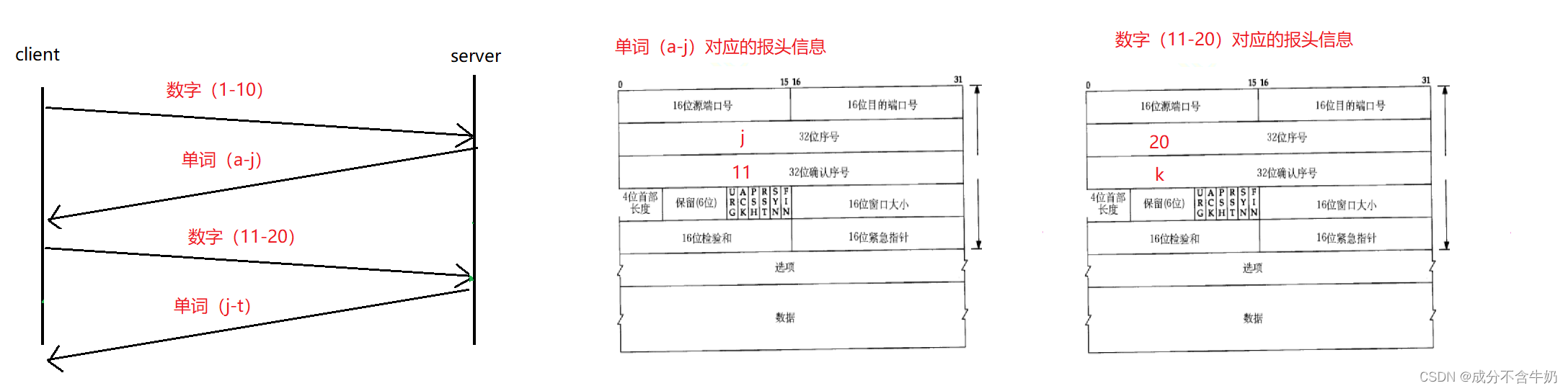
假设客户端发送数字1-10,服务端回应对应的单词a-j,而这时服务端发送的报头信息32位序号为j,表示当前发送的最后一个为j,32位确认信息为11,表示接收到数字1-10。(注意这里我们只是大概模拟,过程可能是错误的)
2.4.流量控制
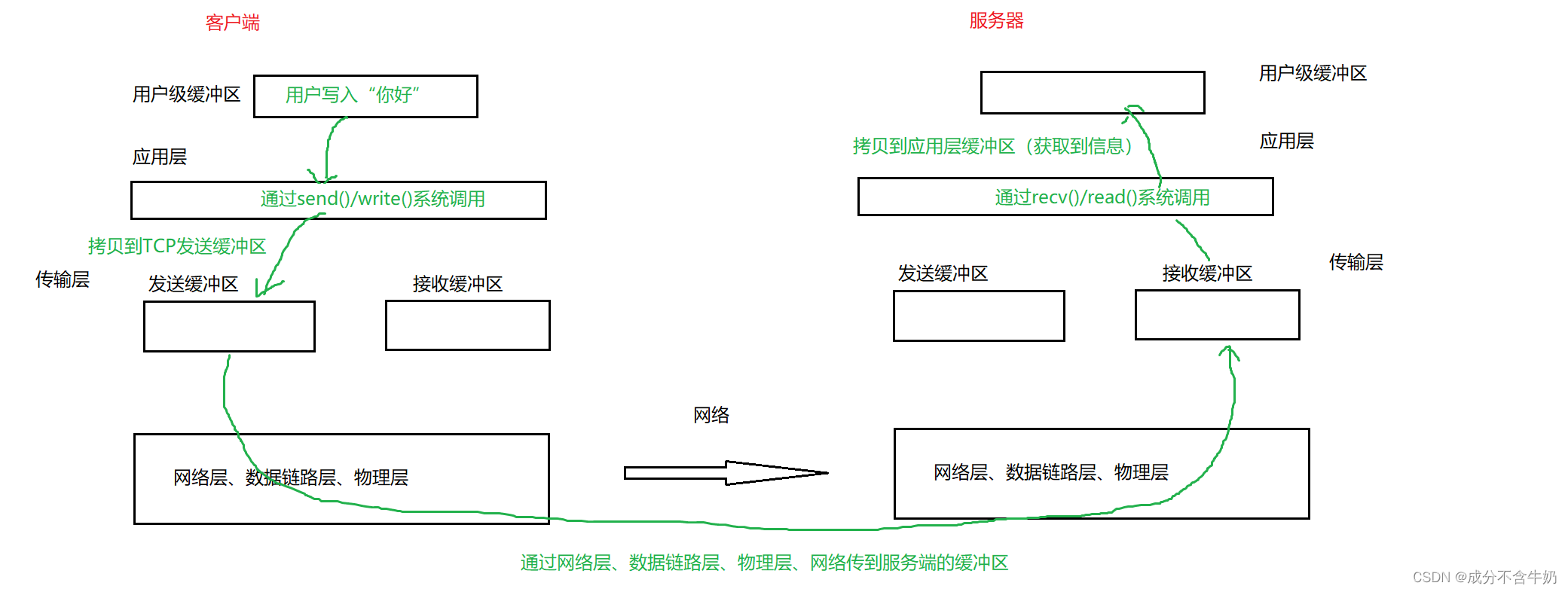
如图为:客户端和服务器通过TCP协议进行通信的示意,我们知道TCP协议在传输层分别维护了发送缓冲区和接收缓冲区,而缓冲区的大小是有限的,当发送方发送数据过多时,会导致接收方的接受缓冲区收满了!!!
这时我们有两种解决方法:
- 将后续的数据包全部丢弃(显然是不合理的,浪费资源)
- 进行流量控制,控制发送方的发送速度,并且允许随时查询接受缓冲区的接收能力。
那么如何进行流量控制?
- 我们在确认应答机制中知道TCP协议中,发送方发送一条消息(也是一段报文)后,如果接收方接收到一定要回复一条ACK报文。
- 并且TCP协议字段中,维护了一个16位窗口大小,内置了当前发送方目前接收缓冲区还有多少数据没有得到确认,即发送端告诉接收端,我(发送端发送ACK)还可以接收多少数据
- 当接收端接收到发送端的ACK报文时,一方面知道上一条自己发送的信息成功被接受了,另一方面获取了对端的接受缓冲区的接收能力,那么接下来就能够进行发送策略修改
- 注意以上的发送端也可以是接收端!!!

但是我们还会存在疑惑,上层我们使用TCP协议时,并没有感受到流量控制和对应的策略的修改。
TCP协议是在传输层实现的,而传输层协议的实现是在操作系统中的。回到上图,我们知道TCP协议数据传输是以字节流的形式,并且在上层我们无法控制一次发多少数据,并且应用层也不关心如何发送,这是因为操作系统需要在传输层的发送缓冲区控制发送策略。
也就是流量控制是通过操作系统中的TCP模块来实现的!!!是操作系统完成的!!!
2.5.超时重传机制
我们知道TCP通信是基于“确认应答机制”的,那么发送端发送一个报文,理论上就一定会获得一个ACK报文。
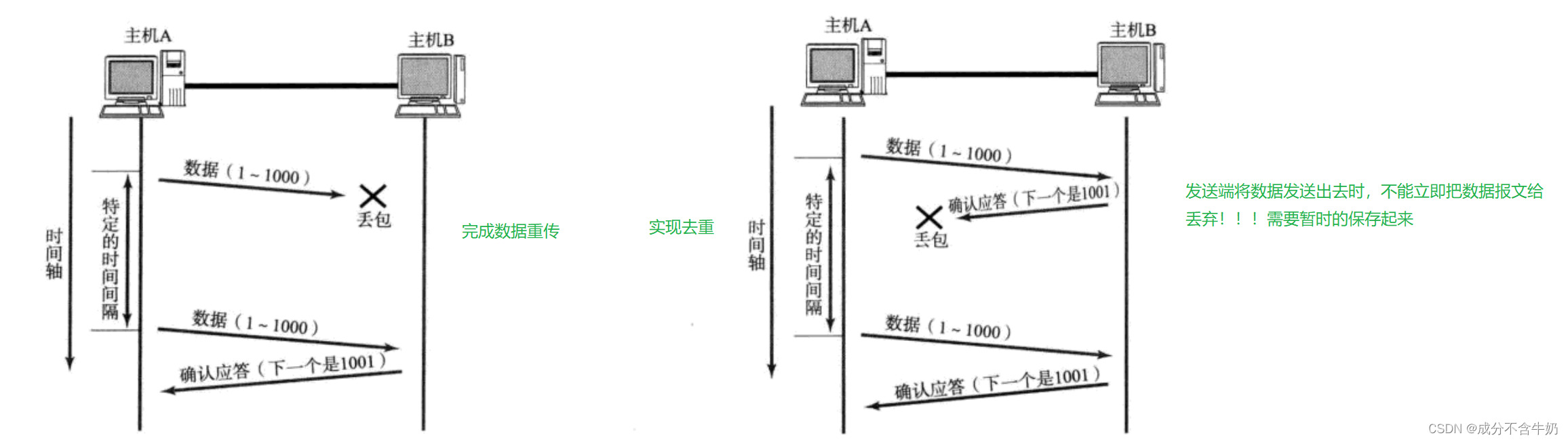
但是网络并不能保证百分百传输,所以没获得ACK报文就对应着两种情况:
- 发送的报文丢失了,接收端没收到。
- 接收端收到了,但是发送的ACK报文丢失了
为了解决这种问题,我们发出数据报文后,在接收到ACK报文之前,发送端需要暂时保留上一层发出的数据报文!!!(这些数据就维护在滑动窗口中)
- 那么为了解决第一种情况我们就需要通过超时重传机制,在我们发送数据报文后没有收到ACK报文时,发送端会间隔一段时间,重新发送数据报文。
- 但是如果是接收端接收到,而ACK报文丢失,那么这时接收端就获得了两个相同的数据报文,就会造成数据冗余。那么这个问题如何解决呢?这时就可以结合TCP的32位序号字段,如果序号相同,表示数据冗余!!!缓冲区就丢包
那么这个超时策略怎么设置呢???
- 最理想的情况下, 找到一个最小的时间, 保证 "确认应答一定能在这个时间内返回".
- 但是这个时间的长短, 随着网络环境的不同, 是有差异的.
- 如果超时时间设的太长, 会影响整体的重传效率;
- 如果超时时间设的太短, 有可能会频繁发送重复的包;
TCP为了保证无论在任何环境下都能比较高性能的通信, 因此会动态计算这个最大超时时间.
- Linux中(BSD Unix和Windows也是如此), 超时以500ms为一个单位进行控制, 每次判定超时重发的超时 时间都是500ms的整数倍.
- 如果重发一次之后, 仍然得不到应答, 等待 2*500ms 后再进行重传.
- 如果仍然得不到应答, 等待 4*500ms 进行重传. 依次类推, 以指数形式递增.
- 累计到一定的重传次数, TCP认为网络或者对端主机出现异常, 强制关闭连接.
2.6.TCP链接管理机制|三次握手|四次挥手
说到管理,我们条件反射地回答对数据结构的“增删查改”,在TCP通信中,因为一个服务器会接收到大量用户的服务请求,这就无法避免服务器对这些客户端进行管理,而管理我们就需要定义结构化字段……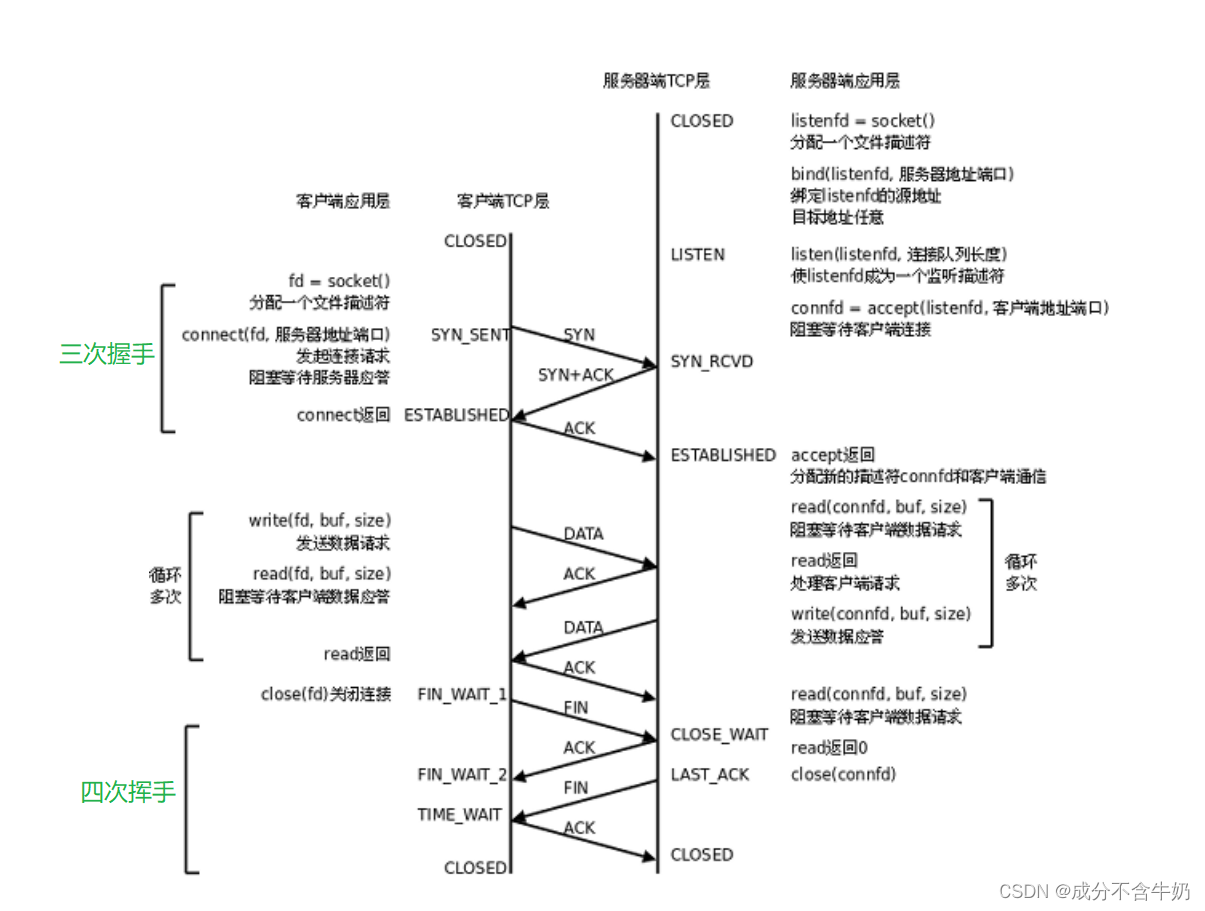
如图为:TCP通信的流程图。当我们在上层获取到连接时,先是定义结构体!然后抽象成链表形式,最终在服务端我们就能够实现对客户端请求进行增删查改和访问……
struct client_links
{int start_seq; // 客户端的排序字段std::string src_ip;std::string src_port;std::string dest_ip;std::string dest_port;uint64_t timestamp;int status; // 状态栏 CLOSED、CLOSED_WAIT、ESTABLISHEDstruct client_links* next;
}因为定义了数据结构,这也体现了客户端、服务端在进行TCP通信时是有成本的,需要消耗空间来维护数据结构,和消耗时间对数据结构进行操作。这也是TCP比UDP复杂的体现!!!
这里我们也能看出:为什么TCP建立连接需要进行三次握手?
首先TCP在维护链接,服务器需要开辟空间来维护客户端的请求字段,所以如果只进行一次链接,就可能有单机客户端恶意发送大量的SYN请求(SYN Flood),造成服务器过载!!如果只进行两次握手,即是客户端发送SYN,服务端发送SYN+ACK,本质上还是客户端只发出一次报文,那么还是存在这种情况……
那么进行三次握手的原因为:
- 以最小成本验证全双工通信,防止出现接收到单机客户端的大量的异常SYN请求。
- 客户端建立好链接之后,服务器收到ACK才建立连接,分配内存给结构体字段。
- 本质上可以看做4次握手,其中服务器ACK和SYN形成了捎带应答报文SYN+ACK,因此减少了一次握手!!!
ps:三次握手是TCP建立连接时,客户端与服务器之间相互发送SYN和ACK报文,以确认双方都已准备好且可以接收数据的一个过程。
我们已经知道了三次握手的原因,那么为什么TCP断开连接需要四次挥手呢?
tcp通信是全双工的,所以当我们关闭tcp通信时,需要客户端、服务端之间互相发送关闭连接的请求报文,来确认双方都完成了断开连接。所以当客户端发送FIN结束链接的报文,相应的服务端也需要发送FIN报文,又因为TCP的确认应答机制,所以需要两次ACK报文,最终显现出4次挥手来结束链接。
那么这时我们会有一个问题:为什么不能将中间的服务端发送ACK和FIN捎带应答呢?
这是因为,当服务器发送ACK时,表示许可客户端发送关闭请求,但是可能出现服务端传给客户端的数据还没有传输完毕,当数据传输完毕时,服务端发送FIN报文,当客户端接收到FIN报文后,向服务端发送ACK报文后就关闭了链接。
在某些场景下,也是可以实现3次挥手的,但是主流的还是四次挥手。
ps:四次挥手是TCP断开连接时,客户端和服务器之间通过互相发送FIN和ACk报文,来确认双方都断开连接的过程。
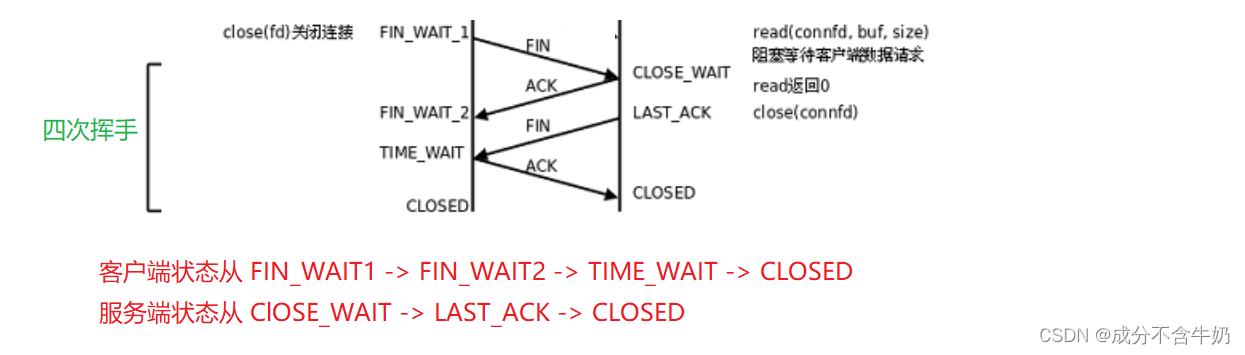
如图:客户端发送FIN报文后,处于FIN_WAIT1和FIN_WAIT2状态,接收到服务端发送的FIN报文后,状态变为TIME_WAIT,一段时间后状态变为CLOSED,表示客户端关闭链接。
FIN_WAIT状态我们可以理解,这是为了等待服务端的FIN报文。那为什么出现TIME_WAIT状态?这是因为网络中,可能存在尚未达到客户端的报文中,所以我们需要一个等待时间,等待网络中的滞留报文消散!!!
而服务端接收到客户端的FIN报文后装处于CLOSE_WAIT状态,接着发送FIN给客户端,这时处于LAST_ACK状态,当接收到客户端的ACK报文后,然后变为CLOSED,表示服务端关闭链接。
2.7.滑动窗口
滑动窗口是TCP为了并发发送大量数据,并且暂时不需要发送ACK报文字段的一种提高通信效率的解决方案。
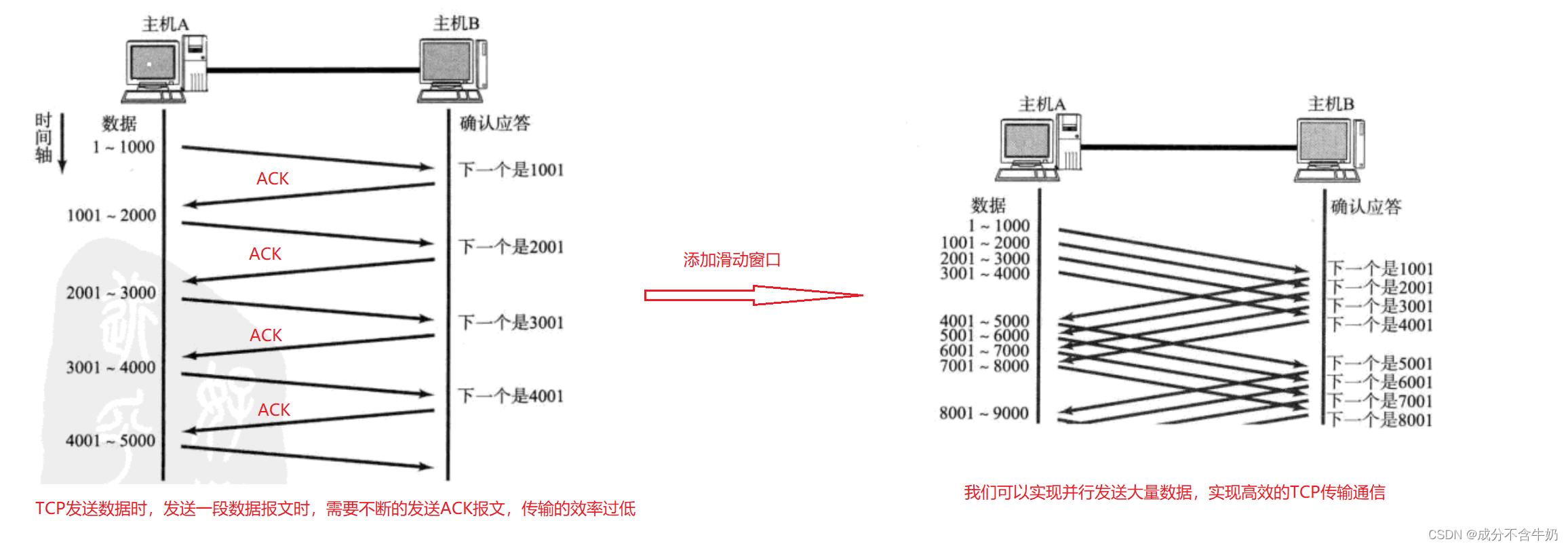
滑动窗口的原理:
- 发送前四个段的时候, 不需要等待任何ACK, 直接发送;
- 收到第一个ACK后, 滑动窗口向后移动, 继续发送第五个段的数据;
- 依次类推; 操作系统内核为了维护这个滑动窗口, 需要开辟发送缓冲区 来记录当前还有哪些数据没有应答; 只有确认应答过的数据, 才能从缓冲区删掉;
- 窗口越大, 则网络的吞吐率就越高;
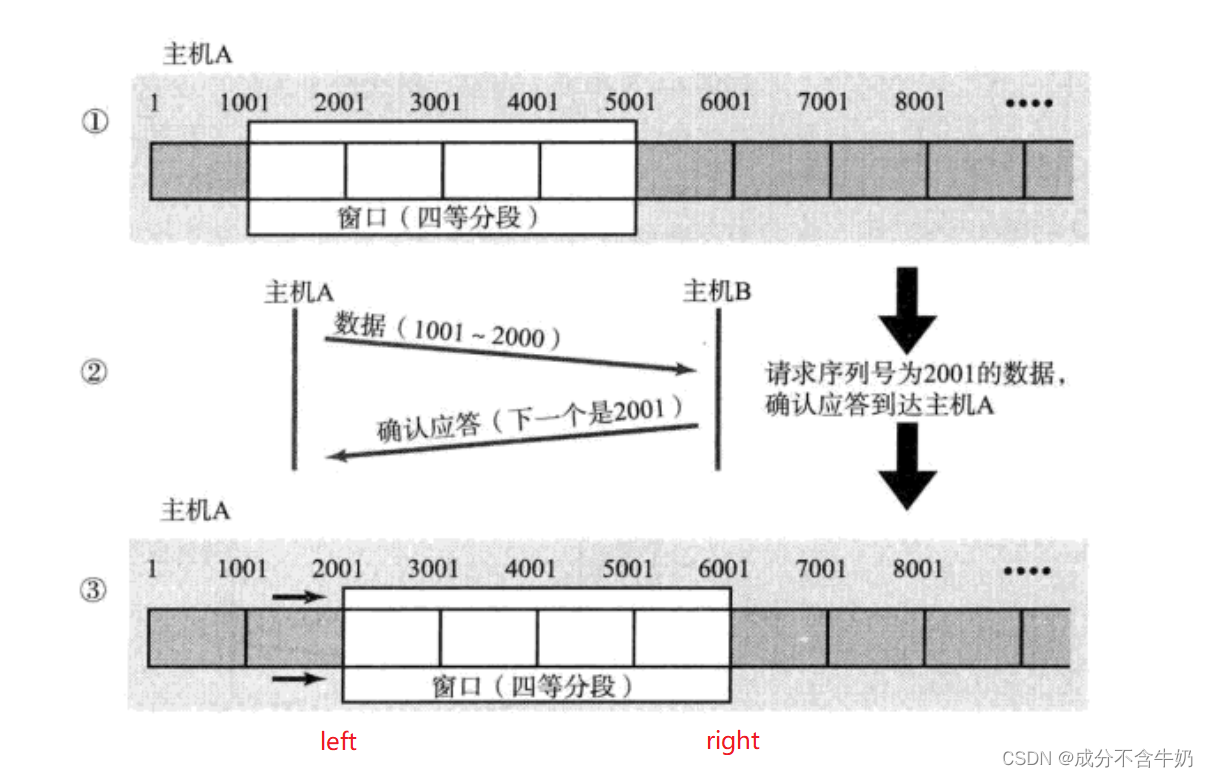
那什么是滑动窗口呢?
我们知道tcp的数据是一段字节流(char),而滑动窗口本质上是在数据流中发送数据的一段范围,也就是两个指针维护的一块空间。
// 本质上就可以看成双指针维护的字节流中的小数组
int left = 最新返回ACK报文确认序号;
int right = left + 返回ACK报文的接收端缓冲区可接收数据大小;
// 滑动窗口的大小
right - left
关于这两个下标的的值大家结合一下上图和TCP协议字段进行思考,我就不赘述了……
因为滑动窗口的大小跟这两个指针指向的下标有关,也就是可变的,实际上滑动窗口的大小由接收端的接收能力决定(联系上流量控制),并且在滑动窗口原理处,我们知道,接收到第一个ACK后才会继续移动。这时我们就能够通过这个ACK报文获取当前接收端缓冲区的接收能力,进而控制滑动窗口的大小(通过修改right)
这时我们知道通信时滑动窗口的大小是通过ACK报文进行调整的,那么刚建立连接时,滑动窗口的大小是多少呢?这时我们联系三次握手,是不是也有报文的收发?那么不就是和通信时一样,不同的是通过三次握手时接收端的报文获取到窗口大小信息来确定初始滑动窗口大小……
那么滑动窗口大小的改变是不是就是在进行流量控制呢?
滑动窗口中报文丢失问题
滑动窗口是发送端维护的,那么在滑动并传输报文的过程中,报文传输丢包了,我们如何解决报文重传? 通过超时重传机制或者快重传机制来实现数据重传

也就是当数据丢失时,确认序号下标对应的只会是丢失数据前的数据。这时就需要进行数据重传,因为此时最左段的ACK没有被发送端获得,此时滑动窗口不会移动。那么假如为3000的数据缺失,而2000、4000、5000未缺失,这时确认序号下标对应均为2000,并且与最左段丢失不同,此时2000的ACK报文已获得,因此滑动窗口会移动到3000处。也就是中间、右端报文缺失本质上都是最左段报文缺失
讲到这里,我们也要注意我们一定需要处理报文丢失问题,不然滑动窗口不会再次移动,也就是处于阻塞状态,这体现了TCP协议保证传输的可靠性。
2.8.拥塞控制
网络传输过程中,可能会出现网络崩溃的现象,而在TCP传输的角度,体现在发送的报文出现大面积丢包。这时TCP协议会认为网络处于拥塞状态,不同于以往丢包的处理策略:进行超时重传和快重传。但是如果在网络拥塞的状态下再次进行报文传输,就会加剧拥塞,所以需要进行拥塞控制。
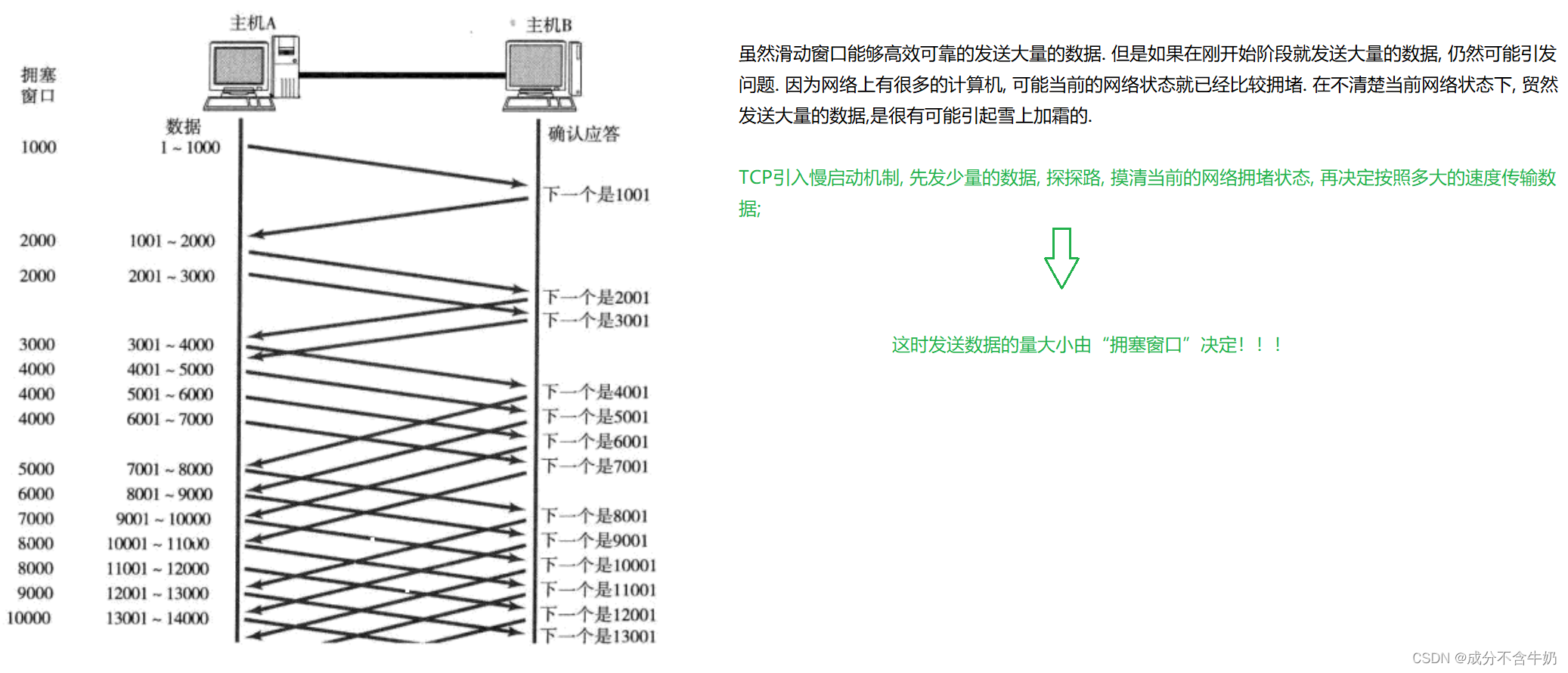
那么什么是拥塞窗口?
拥塞窗口跟滑动窗口类似,都是由两个指针维护的一段范围,但是在TCP刚建立通信时,由拥塞窗口主导来发送数据,当发送端发现数据正常发送(网络状态良好)就会更换成滑动窗口发送的逻辑
发送开始的时候, 定义拥塞窗口大小为1;
每次收到一个ACK应答, 拥塞窗口加1;
每次发送数据包的时候, 将拥塞窗口和接收端主机反馈的窗口大小做比较, 取较小的值作为实际发送的窗口;
// 拥塞窗口大小
int left = 确认信号的最大值
int right = left + min(拥塞窗口大小, 接收端窗口大小);
这里对拥塞窗口和接收端窗口大小取最小值,保证接收端能够正常的接收适量的数据!!!
拥塞控制算法
这时我们会发现如果拥塞窗口不断以指数级变大,最终就会导致发送数据过多,进而违背了拥塞控制的初衷。
- 为了不增长的那么快, 因此不能使拥塞窗口单纯的加倍.
- 此处引入一个叫做慢启动的阈值,当拥塞窗口超过这个阈值的时候, 不再按照指数方式增长, 而是按照线性方式增长
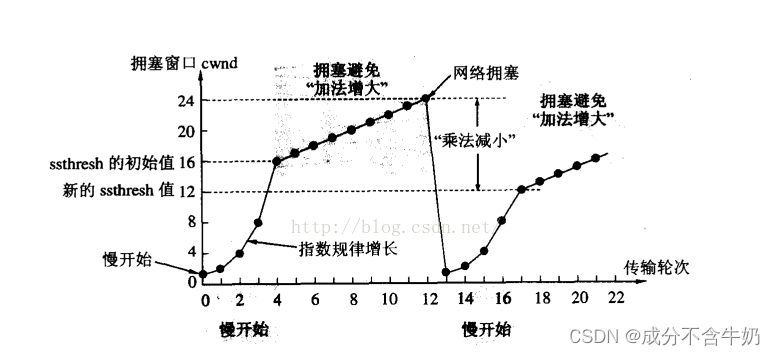
如图为拥塞控制算法:当网络正常时,拥塞窗口从1开始指数级增长至慢启动阈值,接着线性增长。当网络拥塞时,回到1重新开始拥塞控制算法,这时更新 慢启动阈值 = 拥塞窗口 / 2。
而拥塞窗口大小一直变化是因为需要不断的探测网络状态,来判定网络传输的上限值。因为TCP在进行传输时,不仅要考虑接受缓冲区的窗口大小,还要衡量当前网络许可的报文发送量,因为网络中存在无数的主机。
2.9.延迟应答|捎带应答
延迟应答
在确认应答机制中,我们知道回复上一条报文的ACK报文中会存储接收端的接收能力,那么如果我们ACK报文发送稍微延迟一下,在这段时间差中应用层可能会对缓冲区进行字节流的读取,那么延迟后的ACK报文中存储的接收能力就会稍微提高,这时就能够运行发送端发送更多数据,增加吞吐量。
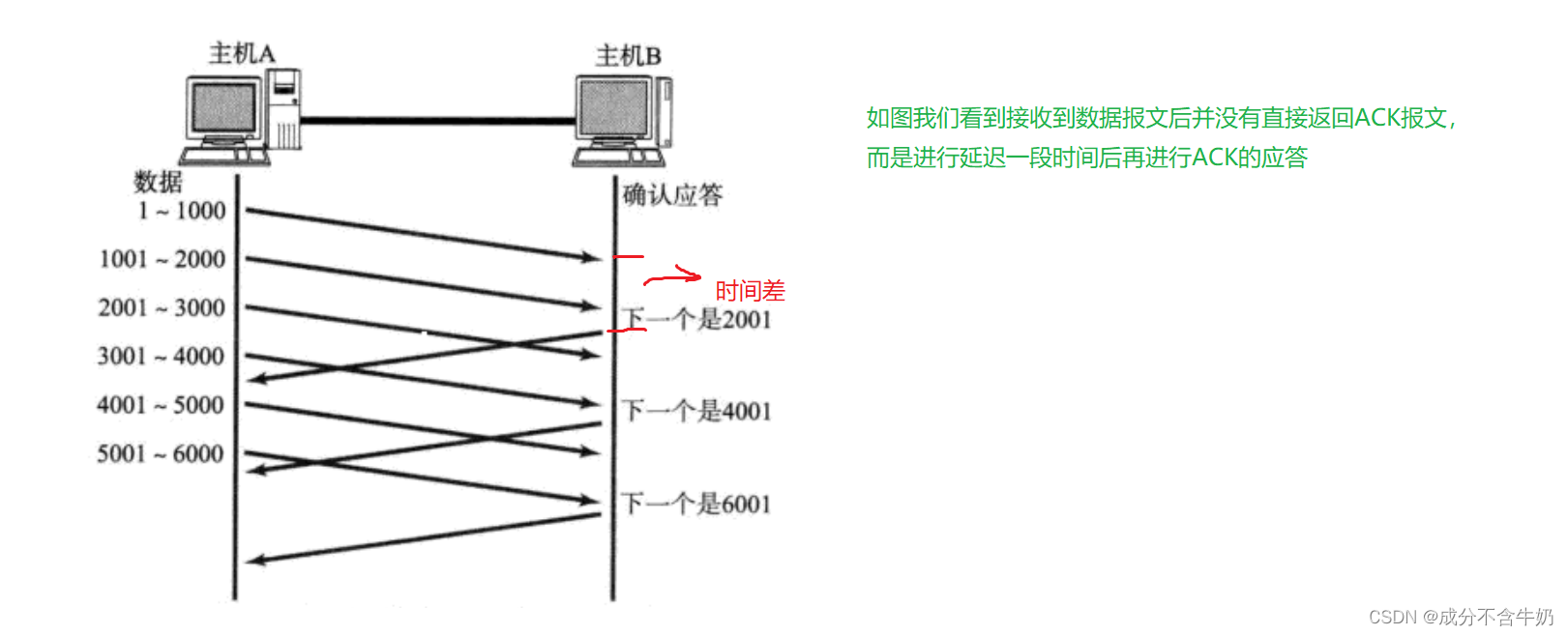
- 如果接收数据的主机立刻返回ACK应答, 这时候返回的窗口可能比较小.
- 假设接收端缓冲区为1M. 一次收到了500K的数据; 如果立刻应答, 返回的窗口就是500K;
- 但实际上可能处理端处理的速度很快, 10ms之内就把500K数据从缓冲区消费掉了;
- 在这种情况下, 接收端处理还远没有达到自己的极限, 即使窗口再放大一些, 也能处理过来;
- 如果接收端稍微等一会再应答, 比如等待200ms再应答, 那么这个时候返回的窗口大小就是1M;
另外 窗口越大, 网络吞吐量就越大, 传输效率就越高. 传输时保证网络不拥塞的情况下尽量提高传输 效率。同样如果所有的数据报文都采用延时应答,因为滑动窗口的移动需要获得窗口左端对应的ACK报文,那么这时也会导致网络传输效率的降低,所以我们需要有策略的使用延迟应答。
- 数量限制: 每隔N个包就应答一次;
- 时间限制: 超过最大延迟时间就应答一次;
具体的数量和超时时间, 依操作系统不同也有差异; 一般N取2, 超时时间取200ms;
捎带应答
很多情况下, 客户端服务器在应用层也是 "一发一收" 的. 意味着客户端给服务器说了 "你好", 服务器也会给客户端回一个 "Hello"。又因为报文的收发需要遵守确认应答机制,那么这个时候ACK就可以搭顺风车, 和服务器回应的 "Hello" 一起回给客户端

3.TCP的其他知识
3.1.面向字节流
我们在之前的学习中,了解到传输层进行报文数据发送时,是以TCP报文字段的32位序号作为发送多少数据的基准,底层原理就是TCP的传输是面向字节流的。

如图:我们可以把序号看成字符数组的下标,这就体现了TCP面向字节的的特点,并且实际上,在应用层结构化数据第一步就是需要通过序列化将数据转化为字符串!!!
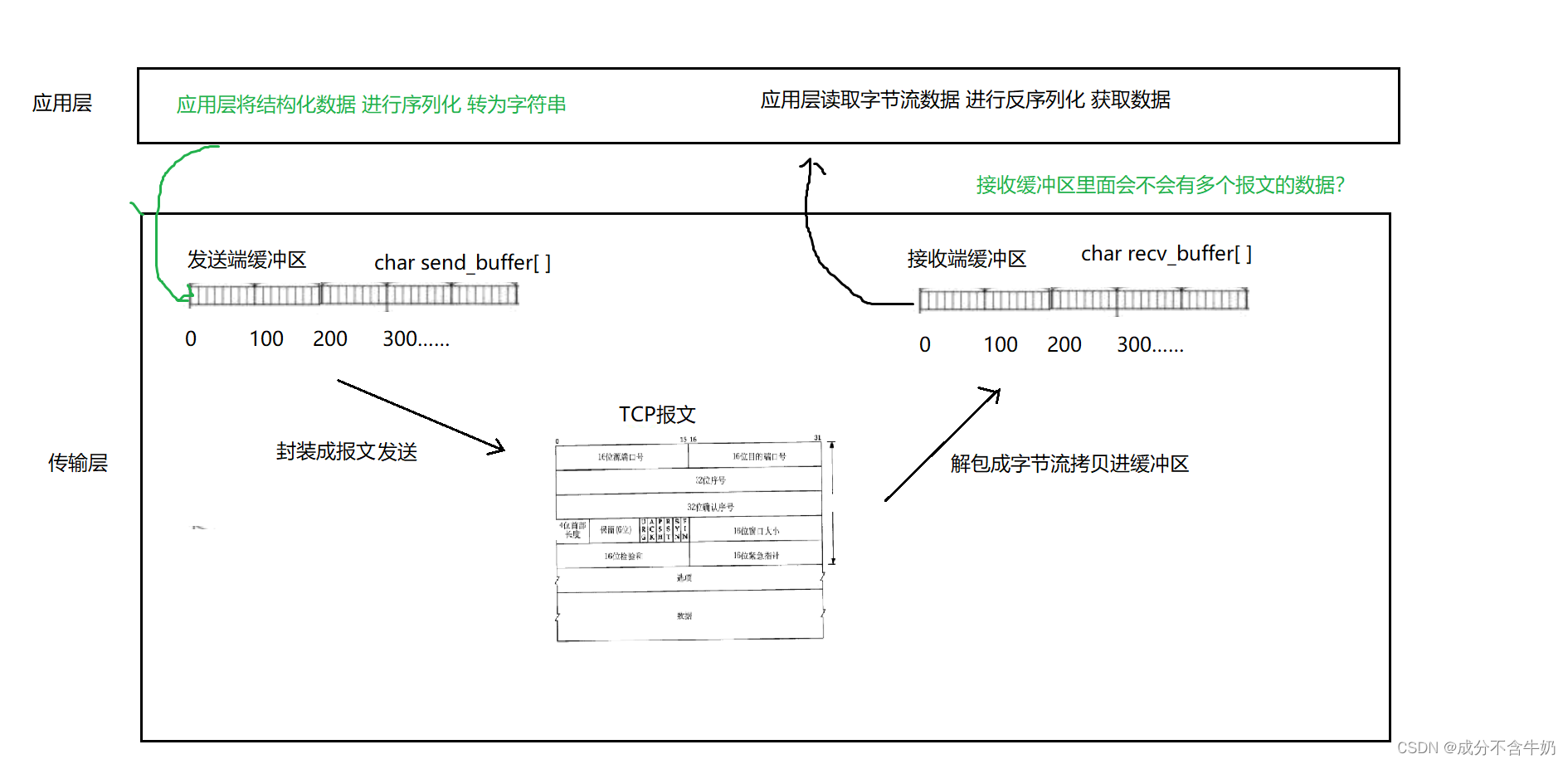
- 而在TCP通信的本质就是发送端的传输层中的发送缓冲区将数据拷贝到接收端的接收缓冲区
- 又因为操作系统进行数据发送时,对发多少、发什么我们在上层无法得知(也不关心)
- 这时就会出现可能接收端缓冲区中存在着若干个报文的数据,这些数据以字符串的形式存储
- 并且接收端的接收缓冲区也有自己的接收策略,那么这时的字符串数据就会一段一段地不断被接受,像水流一样被应用层读取并解析成数据
这就是TCP面向字节流的本质,序号就对应着字节下标,当读取数据时,读到哪里就用读到哪个下标来体现!!!
3.2.粘包问题
我们在3.1.中提及TCP是面向字节流的传输层协议,这导致了应用层在读取从传输层传来的数据,是一段一段的(可能是残缺的报文、一个完整的报文、多个报文),那么这时就会出现数据报文的“粘包问题”。
那么我们如何解决粘包问题呢?
- 采用定长的报文格式。因为我们定义相同长度为length的报文,我们只需要在应用层读取传输层字符流数据时,读取短于length的字符流时,先存储,直至读取到length长度后,作为一个报文。当读取到超过length长度的报文,就先截取n个length长度的报文,剩下的字符流就相当于读取短语length的字符流。
- 在字符流中设置特殊分割字符。我们在字符流数据中读取到一些我们设置的特殊字符时就可以作为报文的分界。
- 设置报头+自描述字段。例如:应用层HTTP协议中,content-length字段,表示有效载荷的长度,那么我们也可以在处理传输层的字符流数据时,也添加这些字段
一般来说,第一种方法就可以解决单独解决粘包问题,而第二种和第三种需要一起结合才能解决粘包问题。(下面即为特殊字符和自描述字段来解决粘包问题……)
std::string Encode(const std::string &message){// "message" -> "len\nmessage\n"std::string len = std::to_string(message.size());std::string package = len + line_seq + message + line_seq;return package;}// 循环式处理 字符型字符流数据bool Decode(std::string &package, std::string *message){// "len\nmessage\n" -> "message"// 但是无法保证获取的字节流是完整的报文// 1.出现一段残缺的报文 2.收到一段完整的报文和下一段报文拼接 3.恰好收到一段完整的报文auto left = package.find(line_seq);if (left == std::string::npos) // 未获取message中的长度return false;// 打包对应的len字段std::string len = package.substr(0, left);// 总长度为:len字段的长度 + len字段对应的message长度 + 两个换行符int length_package = len.size() + std::stoi(len) + 2 * line_seq.size();if (length_package > package.size()) // package为情况1return false;// 获取message并传到外部*message = package.substr(left + line_seq.size(), std::stoi(len));// 删除完整报文,将剩余部分返回给外部,重新进行Encodepackage.erase(0, length_package);return true;}3.3.TCP异常问题
进程终止
当服务器、客户端在正常通信时,客户端突然出现异常,导致进程终止。这时进程终止后,服务器、客户端之间会自动进行四次挥手。
机器重启
机器重启时,可以视为进程终止,那么也是自动的进行四次挥手。
机器掉电/网线断开
接收端认为连接还在,一旦接收端有写入操作,接收端发现连接已经不在了,就会进行reset. 定期询问对方是否还在使没有写入操作 . 如果对方不在 , TCP自己也内置了一个保活定时器
3.4.全连接队列
Linux内核协议栈为一个tcp连接管理(三次握手期间)使用两个队列:
- 半链接队列(用来保存处于SYN_SENT和SYN_RECV状态的请求)
- 全连接队列(accpetd队列)(用来保存处于established状态,但是应用层没有调用accept取走的请求) 而全连接队列的长度会受到listen的第二个参数的影响. 全连接队列满了的时候, 就无法继续让当前连接的状态进入established状态了.
值得一提的是:这两个队列都是不进行实际上TCP客户端和服务端通信的!

对于全连接队列我们可以把他看成去饭店吃饭,当饭店繁忙(TCP维护的实际通信数目过多),那么为了提高效率(防止其他链接到来时,因繁忙就无法建立,而下一刻就有其他链接进行四次挥手断开的场景),我们就可以在饭店外放一些椅子供客人等待(全连接队列),如果有正在通信的客户端选择断开,那么全连接队列的队头出队进行通信……
这样子我们可以实现高效的处理服务器高负载的TCP通信场景,另外我们也不可设置过长的全连接队列,因为队列的维护也是需要资源的,并且也不符合正常的生活体验。
全连接、半连接队列始终在三次挥手过程中,并不进行实际的TCP客户端、服务端通信。
3.5.TCP总结
TCP(传输控制协议)是一个面向连接的、可靠的、基于字节流的传输层协议。而TCP协议的实现和TCP协议的模块都是围绕着可靠性、性能来进行的。
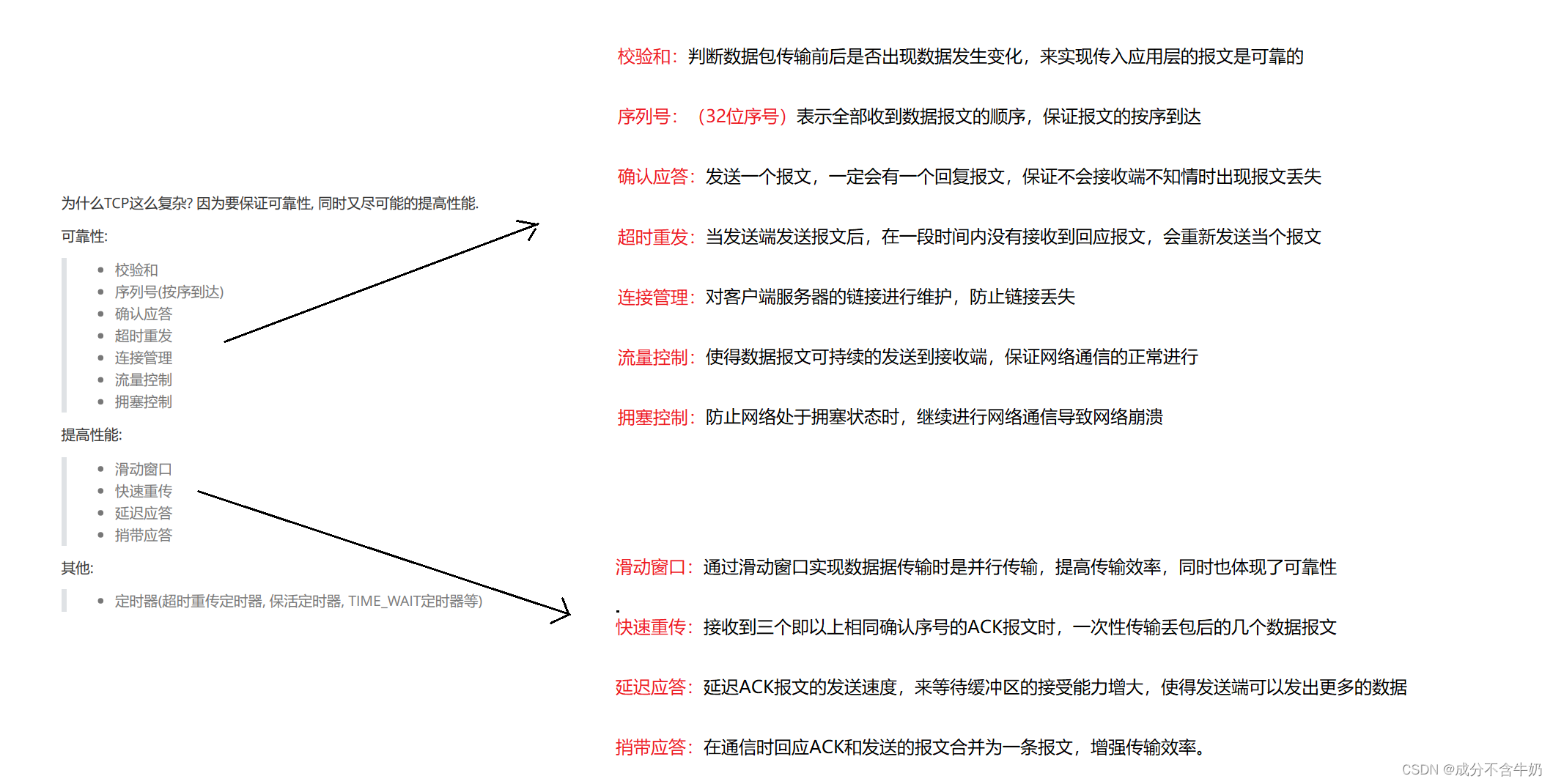
在2.TCP协议的学习中,我们也深刻的体会到了传输控制协议中,“控制” 体现在数据传输的控制、链接的控制、性能优化的控制……
4.TCP与UDP
4.1.UDP如何实现可靠传输
我们知道TCP是可靠的传输协议、而UDP因为其简单,可靠性较弱,为了让UDP协议实现可靠性传输,我们可以添加:
- 确认应答机制,确认报文在传输过程中是否缺失
- 超时重传机制,确保报文都能被接收端接收到
- 引入报文序列号,确保报文发送时有序的
简而言之:实现UDP的可靠传输本质上就是添加实现TCP可靠传输的模块。但是如果直接把UDP做成TCP,显然是不合理的,所以UDP实现可靠运输需要结合实际场景……
4.2.TCP与UDP比较
基本概念
TCP:
-
全称是传输控制协议。
-
面向连接的协议,即在数据传输前需要建立连接。
-
提供可靠的、按顺序的、无差错的数据传输。
-
主要用于需要高可靠性的数据传输,如网页浏览、文件传输、电子邮件等。
UDP:
-
全称是用户数据报协议。
-
无连接的协议,即在数据传输前不需要建立连接。
-
提供不可靠的数据传输,数据包可能会丢失、重复或乱序。
-
主要用于需要快速传输且对可靠性要求不高的场景,如视频流、在线游戏、DNS查询等。
连接与数据传输
TCP:
-
连接建立:通过三次握手建立连接。
-
客户端发送SYN包。
-
服务器回应SYN-ACK包。
-
客户端回应ACK包,连接建立。
-
-
数据传输:数据按顺序传输,使用序列号和确认机制确保数据包的到达和顺序。
-
连接终止:通过四次挥手断开连接。
-
一方发送FIN包表示终止连接。
-
对方回应ACK包。
-
对方发送FIN包表示同意断开连接。
-
一方回应ACK包,连接断开。
-
UDP:
-
无连接:无需建立连接,直接发送数据。
-
数据传输:数据以独立的报文形式发送,不保证顺序和可靠性。
可靠性
TCP:
-
可靠性:通过确认应答(ACK)、重传机制、序列号等保证数据的可靠传输。
-
流量控制:使用滑动窗口机制控制发送数据的速度,防止网络拥塞。
-
拥塞控制:使用慢启动、拥塞避免、快重传和快恢复等算法控制网络拥塞。
UDP:
-
不可靠性:没有确认应答和重传机制,数据包可能会丢失或乱序。
-
无流量控制和拥塞控制:没有内置的流量控制和拥塞控制机制。
头部开销
TCP:
-
头部较大:TCP头部通常是20字节,包含源端口、目的端口、序列号、确认号、数据偏移、保留位、控制位、窗口大小、校验和、紧急指针等字段。
UDP:
-
头部较小:UDP头部通常是8字节,包含源端口、目的端口、长度和校验和等字段。
使用场景
TCP:
-
网页浏览:需要可靠传输的HTTP/HTTPS协议。
-
文件传输:如FTP、SFTP。
-
电子邮件:如SMTP、IMAP、POP3。
UDP:
-
视频流:如视频会议、直播。
-
在线游戏:需要快速传输的实时数据。
-
DNS查询:快速的域名解析。
-
VoIP:实时语音通信。
相关文章:
Linux网络编程:传输层协议|UDP|TCP
知识引入: 端口号: 当应用层获得一个传输过来的报文时,这时数据包需要知道,自己应该送往哪一个应用层的服务,这时就引入了“端口号”,通过区分同一台主机不同应用程序的端口号,来保证数据传输…...

MongoDB CRUD操作:内嵌文档查询
MongoDB内嵌文档的查询 文章目录 MongoDB内嵌文档的查询使用点号.查询内嵌文档嵌套字段的相等匹配使用查询操作符进行匹配指定AND条件 嵌套文档的匹配使用 MongoDB Atlas 查询内嵌文档导航至集合指定查询过滤文档点击应用 可以使用下面几种方法查询MongoDB中的嵌入文档…...

JavaScript、Kotlin、Flutter可以开发鸿蒙APP吗?
自从去年华为宣布推出「鸿蒙Next」版本开始,标志着其操作系统的全面革新。鸿蒙Next将摒弃所有基于AOSP的代码,与Android系统彻底分离,实现完全自主的研发路径。通过精简约40%的冗余代码,鸿蒙Next致力于构建一个更高效、更流畅的系…...

刚体运动描述:欧拉角与四元数
在机器人学中,刚体的运动描述是非常重要的,特别是当我们需要精确控制机器人的姿态时。欧拉角和四元数是两种常用的描述刚体在三维空间中旋转的方法。下面将分别介绍这两种方法并给出其特点。 欧拉角 定义与特点: 定义:欧拉角是…...

一文速通23种设计模式——单例模式、工厂模式、建造者模式、原型模式、代理模式、装饰器模式、组合模式、组合模式、桥接模式、观察者模式、策略模式……
一文速通23种设计模式 写在前面 本文基于结城浩所著《图解设计模式》,其中所使用代码皆为Java版本。 随书代码下载地址-点击“随书下载” 全文15205字,全部读完需要约20分钟。 目录 一文速通23种设计模式写在前面 第一部分 适应设计模式迭代器模式 (…...

Lua 基础 04 模块
Lua 基础相关知识 第四期 require 模块,通常是一个表,表里存储了一些字段和函数,单独写在一个 lua 文件。 例如,这是一个 tools.lua 文件,定义了一个局部 tools 表,包含一个 log 函数,可以传…...

速递FineWeb:一个拥有无限潜力的15T Tokens的开源数据集
大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提…...

HDLBits答案汇总
一.Getting Started Getting started-CSDN博客 二.Verilog Basics-CSDN博客 Vectors-CSDN博客 Module Hierarchy-CSDN博客 Procedures-CSDN博客 More Verilog Features-CSDN博客 三.Circuits Combinational Basic-CSDN博客 Multiplexers-CSDN博客 Arithmetic-CSDN博客 Karnau…...

云端数据提取:安全、高效地利用无限资源
在当今的大数据时代,企业和组织越来越依赖于云平台存储和处理海量数据。然而,随着数据的指数级增长,数据的安全性和高效的数据处理成为了企业最为关心的议题之一。本文将探讨云端数据安全的重要性,并提出一套既高效又安全的数据提…...
Java开发:Spring Boot 实战教程
序言 随着技术的快速发展和数字化转型的深入推进,软件开发领域迎来了前所未有的变革。在众多开发框架中,Spring Boot凭借其“约定大于配置”的核心理念和快速开发的能力,迅速崭露头角,成为当今企业级应用开发的首选框架之一。 《…...
【Python3.11版本利用whl文件安装对应的dlib-19.24.1-cp311-cp311-win_amd64.whl库】
下载Python对应的安装包 找到自己Python版本对应的dlib whl库将网盘下载好的文件放在安装Python的Scripts路径下面接着在该路径输入cmdpip进行安装使用的是国内的源 找到自己Python版本对应的dlib whl库 python 3.11 对应 dlib-19.24.1-cp311-cp311-win_amd64.whl -i 也可以去…...
HW面试常见知识点2——研判分析(蓝队中级版)
🍀文章简介:又到了一年一度的HW时刻,本文写给新手想快速进阶HW蓝中的网安爱好者们, 通读熟练掌握本文面试定个蓝中还是没问题的!大家也要灵活随机应变,不要太刻板的回答) 🍁个人主页…...

鲁教版七年级数学下册-笔记
文章目录 第七章 二元一次方程组1 二元一次方程组2 解二元一次方程组3 二元一次方程组的应用4 二元一次方程与一次函数5 三元一次方程组 第八章 平行线的有关证明1 定义与命题2 证明的必要性3 基本事实与定理4 平行线的判定定理5 平行限的性质定理6 三角形内角和定理 第九章 概…...

带你走进在线直线度测量仪 解析测量方法!
在线直线度测量仪 在线直线度测量仪可安装于生产线上,进行非接触式的无损检测,能检测米直线度尺寸,对截面为圆形的产品,进性直线度检测的帮手。 测量方法 在线直线度拟采用我公司的光电测头对矫直后的棒材直线度进行测量。测量时…...

力扣1 两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。 你可以按任意顺序返回…...
AndroidFlutter混合开发
为什么要有混合开发 我们知道,Flutter是可以做跨平台开发的,即一份Flutter的Dart代码,可以编译到多个平台上运行。这么做的好处就是,在不降低多少性能的情况下,尽最大可能的节省开发的时间成本,直接将开发…...
Halcon 光度立体 缺陷检测
一、概述 halcon——缺陷检测常用方法总结(光度立体) - 唯有自己强大 - 博客园 (cnblogs.com) 上周去了康耐视的新品发布会,我真的感觉压力山大,因为VM可以实现现在项目中的80% 的功能,感觉自己的不久就要失业了。同时…...

关于找暑期实习后的一些反思
日期 2024年6月3日 写在前面:距离研究生毕业还有9个月,前端时间一直在不停地投简历,不停地刷笔试题,不停地被拒绝,今天悬着的心终于死透了,心情还是比较糟糕的,可能唯一的安慰就是一篇小论文终于…...

Rust struct
Rust struct 1.实例化需要初始化全部成员变量2.如果需要实例化对象可变,加上mut则所有成员变量均可变 Rust支持通过已实例化的对象,赋值给未赋值的对象的成员变量 #![allow(warnings)] use std::io; use std::error::Error; use std::boxed::Box; use s…...
【UE5:CesiumForUnreal】——加载无高度地形数据
目录 1.实现目的 2.数据准备 2.1下载数据 2.2 数据切片 3.加载无地形数据 1.实现目的 在CesiumForUnreal插件中,我们加载地图和地形图层之后,默认都是加载的带有高程信息的地形数据,在实际的项目和开发中,有时候我们需要加载无…...

snabbt.js与Hammer.js集成终极指南:打造流畅触摸手势动画的10个技巧
snabbt.js与Hammer.js集成终极指南:打造流畅触摸手势动画的10个技巧 【免费下载链接】snabbt.js Fast animations with javascript and CSS transforms 项目地址: https://gitcode.com/gh_mirrors/sn/snabbt.js snabbt.js是一个轻量级JavaScript动画库&#…...

OpenClaw备份策略:千问3.5-9B实现增量备份与版本对比
OpenClaw备份策略:千问3.5-9B实现增量备份与版本对比 1. 为什么需要智能备份方案 上周我的移动硬盘突然罢工,导致三个月的项目文档全部丢失。这次惨痛经历让我意识到:传统备份方式存在两个致命缺陷。第一,手动备份依赖记忆&…...

SQL分组Group By
一、先搞懂:分组查询是干嘛的?分组查询 GROUP BY 就是把表中数据按照某个字段「分类」,然后对每一类做统计。比如你 emp 表有 gender(性别)字段,用分组就能:统计「男员工有多少人、女员工有多少…...

Go 网络编程超时控制方案
Go网络编程中的超时控制方案 在分布式系统和微服务架构盛行的今天,网络通信的稳定性成为关键。Go语言凭借其高效的并发模型和简洁的语法,成为网络编程的热门选择。网络环境复杂多变,超时控制是确保系统健壮性的重要手段。本文将介绍Go网络编…...

AI绘画联动:OpenClaw调用Qwen3-32B生成Stable Diffusion提示词
AI绘画联动:OpenClaw调用Qwen3-32B生成Stable Diffusion提示词 1. 当AI助手遇上AI绘画:我的自动化创作实验 去年第一次接触Stable Diffusion时,我就被它的创作潜力震撼了。但很快发现一个问题:要得到理想的画面,往往…...
)
UE5地牢生成实战:从零搭建程序化地下城(附完整蓝图逻辑)
UE5地牢生成实战:从零搭建程序化地下城(附完整蓝图逻辑) 在游戏开发中,程序化内容生成(PCG)技术正变得越来越重要。想象一下,你正在开发一款Roguelike游戏,每次玩家进入地牢都能获得全新的探索体验——这正…...
)
merge sort(自用)
首先来看一下这道题目:# P1309 [NOIP 2011 普及组] 瑞士轮## 题目背景在双人对决的竞技性比赛,如乒乓球、羽毛球、国际象棋中,最常见的赛制是淘汰赛和循环赛。前者的特点是比赛场数少,每场都紧张刺激,但偶然性较高。后…...

2026届学术党必备的五大AI科研助手横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 为学术写作供给高效解决办法的是论文一键生成技术,此工具依据自然语言处理跟深度…...

2025届必备的六大降重复率平台横评
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 在内容创作范畴当中,要是打算削减 AIGC 特性,那就得从语言风格、逻辑…...
:信号产生)
Linux进程信号详解(二):信号产生
当前阶段:一、通过终端按键产生信号1.1 基本操作CtrlC → SIGINTCtrl\ → SIGQUIT 可以发送终止信号Ctrl Z -> SIGSTP 可以发送停止信号,将当前前台进程挂起到后台设置所有信号都可以自定义捕捉 : 1.2 理解OS如何得知键盘有数据1.3 初步理…...