Llama改进之——分组查询注意力
引言
今天介绍LLAMA2模型引入的关于注意力的改进——分组查询注意力(Grouped-query attention,GQA)1。
Transformer中的多头注意力在解码阶段来说是一个性能瓶颈。多查询注意力2通过共享单个key和value头,同时不减少query头来提升性能。多查询注意力可能导致质量下降和训练不稳定,因此常用的是分组查询注意力。
然后我们结合上篇文章3探讨的旋转位置编码,将选择位置编码应用到分组查询注意力上。
多头注意力
我们先回顾以下原始多头注意力的实现。
import torch
from torch import nn, Tensorimport math
from dataclasses import dataclass@dataclass
class ModelArgs:hidden_size: int = 512num_heads: int = 8attention_dropout: float = 0.1class MultiHeadAttention(nn.Module):def __init__(self, args: ModelArgs) -> None:super().__init__()self.hidden_size = args.hidden_sizeself.num_heads = args.num_headsself.head_dim = self.hidden_size // self.num_headsself.attention_dropout = args.attention_dropoutself.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)self.k_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)self.v_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)self.o_proj = nn.Linear(self.hidden_size, self.hidden_size, bias=False)def forward(self, hidden_states: Tensor, attention_mask: Tensor = None):batch_size, seq_len, _ = hidden_states.shapequery_states, key_states, value_states = (self.q_proj(hidden_states),self.k_proj(hidden_states),self.v_proj(hidden_states),)query_states = query_states.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)key_states = key_states.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)value_states = value_states.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)if attention_mask is not None:causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]attn_weights = attn_weights + causal_mask# upcast attention to fp32 see https://github.com/huggingface/transformers/pull/17437attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)attn_output = torch.matmul(attn_weights, value_states)attn_output = attn_output.transpose(1, 2).contiguous()attn_output = attn_output.reshape(batch_size, seq_len, self.hidden_size)attn_output = self.o_proj(attn_output)return attn_output别忘了测试一下:
args = ModelArgs()attention = MultiHeadAttention(args)inputs = torch.randn(32, 8, args.hidden_size)print(attention(inputs).shape)
torch.Size([32, 8, 512])
原始多头注意力就不再赘述了,之前的文章有过详细介绍。
分组查询注意力
分组查询注意力使用折中数量的key-value头(超过一个,但少于多头注意力全部的头数量)来提升性能。
多头注意力、分组查询注意力以及多查询注意力之间的区别如下:

该图来自参考1中的论文。

如上图所示,分组查询注意力是针对多头注意力的一种改进,每组Query头(这里两个Query一组)共享同一个Key和Value头,使得推理更加高效。
实际上在实现的时候,会将共享的Key和Value头进行广播(复制)成与Query头相同的数量:

这样,我们就可以像普通多头注意力一样去计算了。
我们增加num_key_value_heads表示key、value头数;num_heads还是表示query头数。
@dataclass
class ModelArgs:hidden_size: int = 512num_heads: int = 8num_key_value_heads: int = 4attention_dropout: float = 0.1
分组查询注意力和多查询注意力可以合并在一起实现:
class GroupedQueryAttention(nn.Module):def __init__(self, args: ModelArgs) -> None:super().__init__()self.hidden_size = args.hidden_sizeself.num_heads = args.num_heads# 每个头的维度计算和之前一样self.head_dim = self.hidden_size // self.num_heads# 保存key/value头数self.num_key_value_heads = args.num_key_value_heads# 每组内要复制的次数,若为1,即退化为多头注意力;若为num_heads,则为多查询注意力self.num_key_value_groups = self.num_heads // args.num_key_value_headsself.attention_dropout = args.attention_dropoutself.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)# 注意Key和Value的映射这里节省了参数,加速了推理效率。self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)# 最后的输出映射和之前一样self.o_proj = nn.Linear(self.hidden_size, self.hidden_size, bias=False)def forward(self, hidden_states: Tensor, attention_mask: Tensor = None):batch_size, seq_len, _ = hidden_states.shapequery_states, key_states, value_states = (self.q_proj(hidden_states),self.k_proj(hidden_states),self.v_proj(hidden_states),)query_states = query_states.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)# 转换为对应的形状key_states = key_states.view(batch_size, seq_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)value_states = value_states.view(batch_size, seq_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)# 重复num_key_value_groups次,使得和query头数一致key_states = repeat_kv(key_states, self.num_key_value_groups)value_states = repeat_kv(value_states, self.num_key_value_groups)# 后面和普通多头注意力一样计算attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)if attention_mask is not None:causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]attn_weights = attn_weights + causal_mask# upcast attention to fp32 see https://github.com/huggingface/transformers/pull/17437attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)attn_output = torch.matmul(attn_weights, value_states)attn_output = attn_output.transpose(1, 2).contiguous()attn_output = attn_output.reshape(batch_size, seq_len, self.hidden_size)attn_output = self.o_proj(attn_output)return attn_output
其中num_key_value_groups为每组内要复制的次数,若为1,即退化为多头注意力;若为num_heads,则为多查询注意力。
复制时调用repeat_kv方法,如其名所示,只针对key和value:
def repeat_kv(hidden_states: Tensor, n_rep: int) -> Tensor:"""The hidden states go from (batch, num_key_value_heads, seq_len, head_dim) to (batch, num_attention_heads, seq_len, head_dim)n_rep is the number of repeat times."""batch, num_key_value_heads, seq_len, head_dim = hidden_states.shapeif n_rep == 1:# do nothingreturn hidden_states# add a new dimension and repeat n_rep timeshidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, seq_len, head_dim)# reshape to (batch, num_attention_heads, seq_len, head_dim)return hidden_states.reshape(batch, num_key_value_heads * n_rep, seq_len, head_dim)
有了分组查询注意力,下面我们来看如何应用上篇文章3介绍的旋转位置编码到query和key上。
应用旋转位置编码
注意,实现的时候要考虑维度,因此代码和上篇文章的旋转位置编码3有所不同。
首先,我们实现RotaryEmbedding,它缓存了频率张量inv_freq的计算。
class RotaryEmbedding(nn.Module):def __init__(self, dim: int, max_position_embeddings: int = 2048, theta: int = 10000):super().__init__()self.dim = dim # head dimself.max_position_embeddings = max_position_embeddingsself.theta = thetainv_freq = 1.0 / (theta** (torch.arange(0, self.dim, 2, dtype=torch.int64).float() / self.dim))self.register_buffer("inv_freq", inv_freq, persistent=False)# 不需要计算梯度@torch.no_grad()def forward(self, position_ids: torch.LongTensor):freqs = torch.outer(position_ids, self.inv_freq).float()return torch.polar(torch.ones_like(freqs), freqs)
该实现修改自旋转位置编码文章3中的precompute_freqs_cis函数。
然后我们改写apply_rotary_emb函数,主要是确定了输入和输出维度的正确性:
def apply_rotary_emb(q: Tensor, k: Tensor, freq_cis: Tensor):"""Args:q (Tensor): (batch_size, num_heads, seq_len, head_dim)k (Tensor): (batch_size, num_key_value_heads, seq_len, head_dim)freq_cis (Tensor): (seq_len, batch_size)"""# q_ (batch_size, num_heads, seq_len, head_dim // 2, 2)q_ = q.float().reshape(*q.shape[:-1], -1, 2)# k_ (batch_size, num_key_value_heads, seq_len, head_dim // 2, 2)k_ = k.float().reshape(*k.shape[:-1], -1, 2)# turn to complex# q_ (batch_size, num_heads, seq_len, head_dim // 2)q_ = torch.view_as_complex(q_)# k_ (batch_size, num_key_value_heads, seq_len, head_dim // 2)k_ = torch.view_as_complex(k_)# freq_cis (batch_size, 1, seq_len, 1)freq_cis = reshape_for_broadcast(freq_cis, q_)# 应用旋转操作,然后将结果转回实数# view_as_real (batch_size, num_heads, seq_len, head_dim // 2, 2)# xq_out (batch_size, num_heads, seq_len, head_dim)xq_out = torch.view_as_real(q_ * freq_cis).flatten(-2)# view_as_real (batch_size, num_key_value_heads, seq_len, head_dim // 2, 2)# xk_out (batch_size, num_key_value_heads, seq_len, head_dim)xk_out = torch.view_as_real(k_ * freq_cis).flatten(-2)return xq_out.type_as(q), xk_out.type_as(k)
其中需要调用reshape_for_broadcast将频率张量的维度从(seq_len, batch_size)调整到(batch_size, 1, seq_len, 1):
def reshape_for_broadcast(freqs_cis: torch.Tensor, x: torch.Tensor):"""Args:freqs_cis (torch.Tensor): (seq_len, batch_size)x (torch.Tensor): (batch_size, num_heads, seq_len, head_dim // 2)"""# enumerate(x.shape) = [(0, batch_size), (1, num_heads), (2, seq_len), (3, head_dim // 2)]# (batch_size, 1, seq_len, 1)shape = [d if i == 0 or i == 2 else 1 for i, d in enumerate(x.shape)]return freqs_cis.view(*shape)
我们把每个维度都写出来就不会出错。
再确保下repeat_kv函数的维度:
def repeat_kv(hidden_states: Tensor, n_rep: int) -> Tensor:"""The hidden states go from (batch, num_key_value_heads seq_len, head_dim) to (batch, num_attention_heads, seq_len, head_dim)n_rep is the number of repeat times."""batch, num_key_value_heads, seq_len, head_dim = hidden_states.shapeif n_rep == 1:# do nothingreturn hidden_states# add a new dimension and repeat n_rep timeshidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, seq_len, head_dim)# reshape to (batch, num_attention_heads, seq_len, head_dim)return hidden_states.reshape(batch, num_key_value_heads * n_rep, seq_len, head_dim)
最后将旋转位置编码整合到GroupedQueryAttention中:
class GroupedQueryAttention(nn.Module):def __init__(self, args: ModelArgs) -> None:super().__init__()self.hidden_size = args.hidden_sizeself.num_heads = args.num_heads# 每个头的维度计算和之前一样self.head_dim = self.hidden_size // self.num_heads# 保存key/value头数self.num_key_value_heads = args.num_key_value_heads# 每组内要复制的次数,若为1,即退化为多头注意力;若为num_heads,则为多查询注意力self.num_key_value_groups = self.num_heads // args.num_key_value_headsself.attention_dropout = args.attention_dropoutself.max_position_embeddings = args.max_position_embeddingsself.rope_theta = args.thetaself.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)# 注意Key和Value的映射这里节省了参数,加速了推理效率。self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=False)# 最后的输出映射和之前一样self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)# 定义了RotaryEmbedding实例self.rotary_emb = RotaryEmbedding(self.head_dim,max_position_embeddings=self.max_position_embeddings,theta=self.rope_theta,)def forward(self,hidden_states: Tensor,attention_mask: Tensor = None,position_ids: torch.LongTensor = None,):batch_size, seq_len, _ = hidden_states.shapequery_states, key_states, value_states = (self.q_proj(hidden_states),self.k_proj(hidden_states),self.v_proj(hidden_states),)# query_states(batch_size, num_heads, seq_len, head_dim)query_states = query_states.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)# 转换为对应的形状# key_states (batch_size, num_key_value_heads, seq_len, head_dim)key_states = key_states.view(batch_size, seq_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)# value_states (batch_size, num_key_value_heads, seq_len, head_dim)value_states = value_states.view(batch_size, seq_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)# 计算频率张量# freq_cis (seq_len, batch_size)freq_cis = self.rotary_emb(position_ids)# 针对query和key应用旋转位置编码# query_states (batch_size, num_heads, seq_len, head_dim)# key_states (batch_size, num_key_value_heads, seq_len, head_dim)query_states, key_states = apply_rotary_emb(query_states, key_states, freq_cis)# 重复num_key_value_groups次,使得和query头数一致# key_states (batch_size, num_heads, seq_len, head_dim)key_states = repeat_kv(key_states, self.num_key_value_groups)# value_states (batch_size, num_heads, seq_len, head_dim)value_states = repeat_kv(value_states, self.num_key_value_groups)# 后面和普通多头注意力一样计算attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)if attention_mask is not None:causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]attn_weights = attn_weights + causal_mask# upcast attention to fp32 see https://github.com/huggingface/transformers/pull/17437attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)attn_output = torch.matmul(attn_weights, value_states)attn_output = attn_output.transpose(1, 2).contiguous()attn_output = attn_output.reshape(batch_size, seq_len, self.hidden_size)attn_output = self.o_proj(attn_output)return attn_output
主要修改是在调用repeat_kv之前应用旋转位置编码到(每个Attention的)query和key中:
# 计算频率张量
# freq_cis (seq_len, batch_size)
freq_cis = self.rotary_emb(position_ids)# 针对query和key应用旋转位置编码
# query_states (batch_size, num_heads, seq_len, head_dim)
# key_states (batch_size, num_key_value_heads, seq_len, head_dim)
query_states, key_states = apply_rotary_emb(query_states, key_states, freq_cis)
这里简单探讨下为什么旋转位置编码只是应用到query和key上,没有应用到value上,考虑Attention的计算公式:
a m , n = exp ( q m T k n d ) ∑ j = 1 N exp q m T k j d o m = ∑ n = 1 N a m , n v n \begin{aligned} a_{m,n} &= \frac{\exp(\frac{\pmb q^T_m \pmb k_n}{\sqrt d})}{\sum_{j=1}^N \exp \frac{\pmb q^T_m \pmb k_j}{\sqrt d}} \\ \pmb o_m &= \sum_{n=1}^N a_{m,n}\pmb v_n \\ \end{aligned} am,nooom=∑j=1NexpdqqqmTkkkjexp(dqqqmTkkkn)=n=1∑Nam,nvvvn
我们可以看到,实际上只有query和key之间会进行交互(点乘),而value只是用于计算加权和,不参与交互,因此没有必要应用旋转位置编码,但也可以尝试应用到value上。
苏神在博客也说了:“通过在q,k中施行该位置编码,那么效果就等价于相对位置编码,而如果还需要显式的绝对位置信息,则可以同时在v上也施行这种位置编码。总的来说,我们通过绝对位置的操作,可以达到绝对位置的效果,也能达到相对位置的效果。”
最后,进行一个简单的测试:
@dataclass
class ModelArgs:hidden_size: int = 512num_heads: int = 8num_key_value_heads: int = 4attention_dropout: float = 0.1max_position_embeddings: int = 2048theta: int = 10000if __name__ == "__main__":args = ModelArgs()attention = GroupedQueryAttention(args)inputs = torch.randn(32, 16, args.hidden_size)seq_len = inputs.size(1)position_ids = torch.arange(seq_len, dtype=torch.long)print(attention(inputs, position_ids=position_ids).shape)torch.Size([32, 16, 512])
参考
[论文翻译]GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints ↩︎
Fast Transformer Decoding: One Write-Head is All You Need ↩︎
Llama改进之——RoPE旋转位置编码 ↩︎ ↩︎ ↩︎ ↩︎
相关文章:
Llama改进之——分组查询注意力
引言 今天介绍LLAMA2模型引入的关于注意力的改进——分组查询注意力(Grouped-query attention,GQA)1。 Transformer中的多头注意力在解码阶段来说是一个性能瓶颈。多查询注意力2通过共享单个key和value头,同时不减少query头来提升性能。多查询注意力可能导致质量下…...
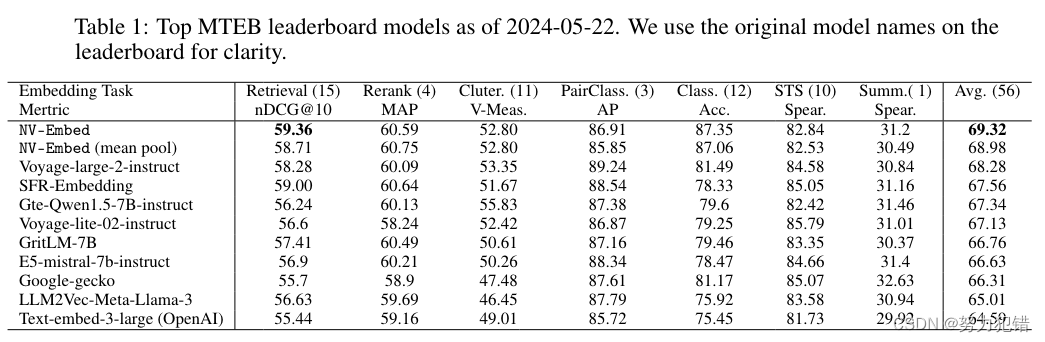
英伟达开源新利器NV-Embed向量模型,基于双向注意力的LLM嵌入模型,MTEB 56项任务排名第一
前言 文本嵌入模型能够将文本信息转化为稠密的向量表示,并在信息检索、语义相似度计算、文本分类等众多自然语言处理任务中发挥着关键作用。近年来,基于解码器的大型语言模型 (LLM) 开始在通用文本嵌入任务中超越传统的 BERT 或 T5 嵌入模型,…...

JVM之【GC-垃圾清除算法】
Java虚拟机(JVM)中的垃圾收集算法主要分为以下几种: 标记-清除算法(Mark-Sweep)复制算法(Copying)标记-整理算法(Mark-Compact)分代收集算法(Generational C…...
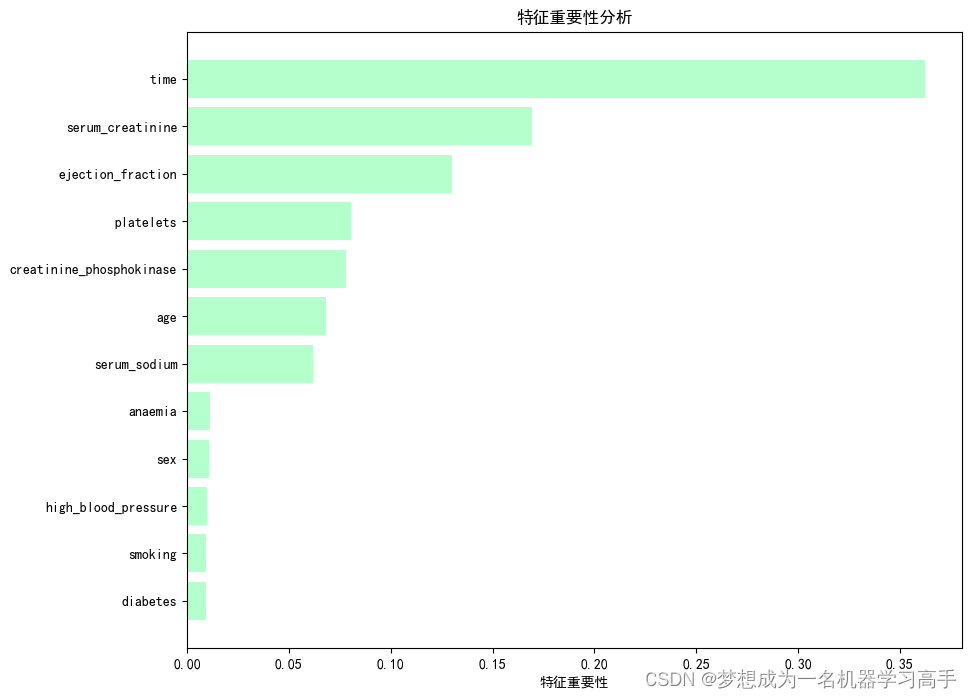
数据分析每周挑战——心衰患者特征数据集
这是一篇关于医学数据的数据分析,但是这个数据集数据不是很多。 背景描述 本数据集包含了多个与心力衰竭相关的特征,用于分析和预测患者心力衰竭发作的风险。数据集涵盖了从40岁到95岁不等年龄的患者群体,提供了广泛的生理和生活方式指标&a…...
)
单例模式(Java实现)
我的相关文章: JavaSE 学习记录-CSDN博客 多线程笔记-CSDN博客 单例模式(Java实现)-CSDN博客 JUC笔记-CSDN博客 注解与反射(Java,类加载机制,双亲委派机制)-CSDN博客 1. 懒汉式线程不安全 pu…...

24.面向对象六大原则
目录介绍 00.面向对象六大原则01.代码单一职责原则02.代码开放封闭原则03.代码里氏替换原则04.代码依赖倒置原则05.代码接口隔离原则06.代码迪米特原则00.面向对象六大原则 六大原则一句话介绍 单一职责原则:指一个类的功能要单一,不能包罗万象。开放封闭原则:指一个模块在扩…...

Vue3-shallowRef与shallowReactive
shallowRef 作用:创建一个响应式数据,但只对顶层属性进行响应式处理。 用法: let myVar shallowRef(initialValue);特点:只跟踪引用值的变化,不关心值内部的属性变化。 shallowReactive 作用:创建一个浅…...

CI/CD(基于ESP-IDF)
主要参考资料 B站乐鑫信息科技《【乐鑫全球开发者大会】DevCon23 #15 |通过 CI/CD 进行流水线开发》 pytest-embedded乐鑫文档: https://docs.espressif.com/projects/pytest-embedded/en/latest/api.html 目录 CI/CD简介乐鑫内部CI/CD测试GitLab CI/CDGitHub Actio…...

聚观早报 | 东风奕派eπ008将上市;苹果Vision Pro发布会
聚观早报每日整理最值得关注的行业重点事件,帮助大家及时了解最新行业动态,每日读报,就读聚观365资讯简报。 整理丨Cutie 6月3日消息 东风奕派eπ008将上市 苹果Vision Pro发布会 特斯拉Model 3高性能版开售 小米14推送全新澎湃OS系统 …...

k8s牛客面经篇
k8s的pod版块: k8s的网络版块: k8s的deployment版块: k8s的service版块: k8s的探针板块: k8s的控制调度板块: k8s的日志监控板块: k8s的流量转发板块: k8s的宏观版块:...

第9周 基于MinIO与OSS实现分布式与云存储
第9周 基于MinIO与OSS实现分布式与云存储 1. 基于mybatis-plus数据修改非空属性忽略更新2. 文件上传3. 分布式文件存储3.1 文件存储架构演变4. Minio docker安装5. 文件服务整合minio依赖minio API测试yml配置minio信息minio配置类业务:上传文件6. 云存储阿里OSS:要钱6.1 依赖6…...

【Linux内核-编程指南】
■ IPC组件 添加链接描述 ■ ■ ■ ■ ■...

Go 编程风格指南 - 最佳实践
Go 编程风格指南 - 最佳实践 原文:https://google.github.io/styleguide/go 概述 | 风格指南 | 风格决策 | 最佳实践 注意: 本文是 Google Go 风格 系列文档的一部分。本文档是 规范性(normative) 但不是强制规范(canonical),并且从属于Goo…...

awk的应用
步骤一:awk的基本用法 1)基本操作方法 格式1:awk [选项] [条件]{指令} 文件 格式2:前置指令 | awk [选项] [条件]{指令} 其中,print 是最常用的编辑指令;若有多条编辑指令,可用分号分隔。 …...
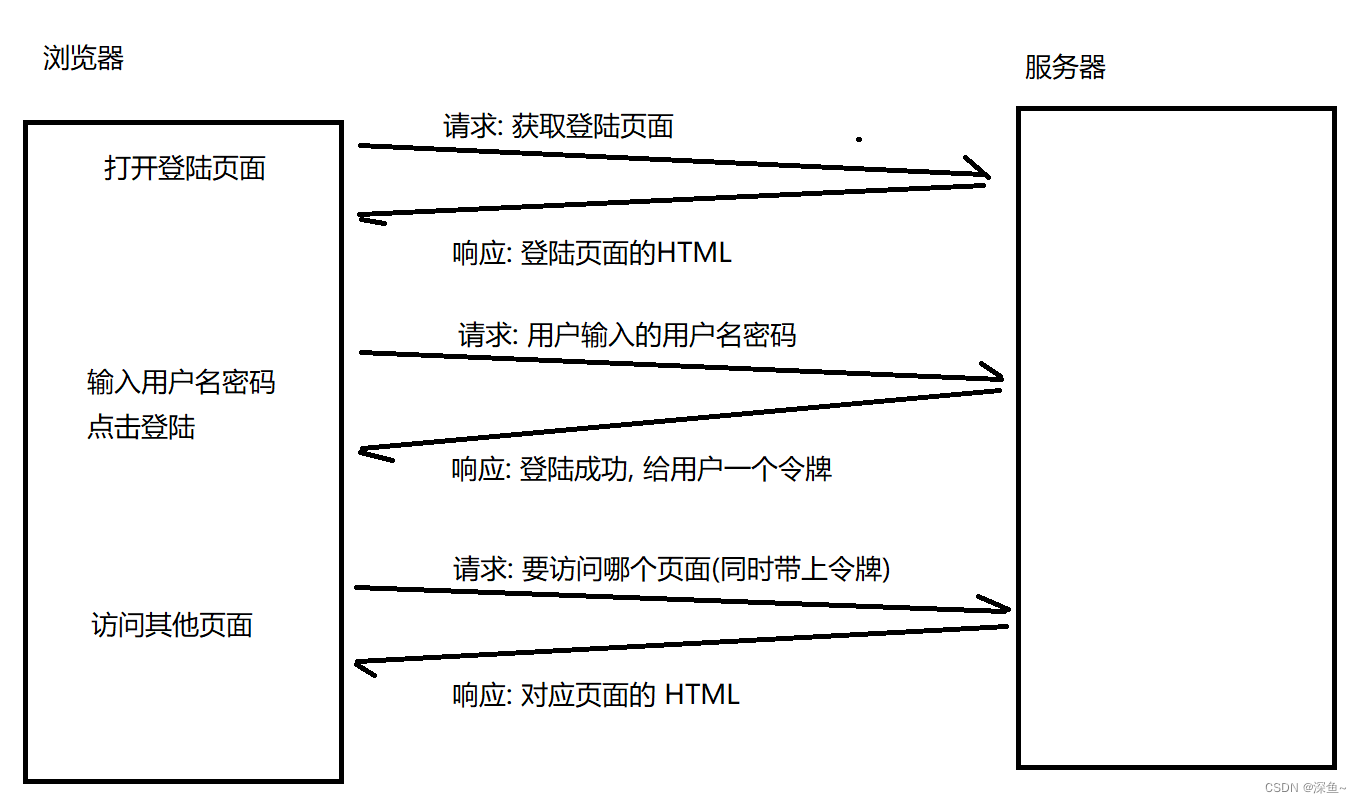
【网络原理】HTTP|认识请求“报头“|Host|Content-Length|Content-Type|UA|Referer|Cookie
目录 认识请求"报头"(header) Host Content-Length Content-Type User-Agent(简称UA) Referer 💡Cookie(最重要的一个header,开发&面试高频问题) 1.Cookie是啥? 2.Cookie怎么存的? …...

深入React Hoooks:从基础到自定义 Hooks
使用 useContext useContext 是另一个常用的 Hook,它可让我们在函数组件中轻松访问 React 的 context。如果你的应用程序依赖于一些全局状态,或者你希望避免将 props 一层一层地传递到子组件,context 很有用。你可以在父组件设置一个值&…...

9.7 Go语言入门(映射 Map)
Go语言入门(映射 Map) 目录六、映射 Map1. 声明和初始化映射1.1 使用 make 函数1.2 使用映射字面量 2. 映射的基本操作2.1 插入和更新元素2.2 访问元素2.3 检查键是否存在2.4 删除元素2.5 获取映射的长度 3. 遍历映射4. 映射的注意事项4.1 映射的零值4.2…...
过期视频怎么恢复?如何从手机、电脑和其他设备中恢复?
过期视频是指那些被误删、丢失或因系统升级等原因而无法正常访问的视频文件。这些视频可能包含了我们珍贵的回忆、重要的信息或者具有商业价值的内容。过期视频的恢复可以帮助我们找回失去的数据,减少损失,提高工作效率和生活质量。过期视频怎么恢复&…...

LeetCode刷题第2题
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。 请你将两个数相加,并以相同形式返回一个表示和的链表。 你可以假设除了数字 0 之外,这两个数都不会以 0 …...

mysql执行拼接的sql语句
在MySQL中,可以使用 CONCAT() 函数来拼接SQL语句。但是,请注意,直接拼接SQL语句可能会导致SQL注入问题,因此应当使用参数化查询来避免这个问题。 以下是一个使用 CONCAT() 函数拼接SQL语句的例子: SET tableName us…...

RP2040硬件加速步进电机控制库picoasyncstepper
1. picoasyncstepper:面向RP2040平台的硬件加速异步步进电机控制库1.1 工程定位与核心价值picoasyncstepper 是一款专为 Raspberry Pi Pico 及兼容 RP2040 微控制器设计的轻量级、高精度步进电机驱动库。其根本设计目标并非简单实现“电机转动”,而是在极…...

三维空间频谱时序预测模型开发完整报告
三维空间频谱时序预测模型开发完整报告 一、项目背景与目标 本项目基于UrbanRadio3D静态数据集,构建端到端的深度学习模型,实现对低空三维空间频谱(路径损耗)的时序演化预测。城市环境中的无线电传播受建筑物遮挡、反射等因素影响,呈现出复杂的空间分布和时间动态特性(…...

架桥记:耐达讯自动化CC-Link IE转EtherCAT的工业协议融合实战
在工业自动化行业中,生产线的智能化升级常面临一个核心难题:如何让基于不同通信协议的设备“读懂”彼此,协同工作?特别是当代表日系高速网络技术的CC-Link IE,遇上盛行于欧系设备的实时以太网EtherCAT时,协…...

第6章 Mosquitto用户认证与访问控制
第6章 用户认证与访问控制 6.1 认证机制概览 #mermaid-svg-MTeZFweZQcx9XrLR{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:…...

高效全方位网页资源捕获方案:猫抓扩展技术解析与应用指南
高效全方位网页资源捕获方案:猫抓扩展技术解析与应用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 引言:网页资源获取…...

dji 妙算3编译ffmpeg启用h264_nvmpi h264_nvenc硬件加速
1. nvidia-codec-headers #版本 12.0.16 cd nv-codec-headers#更改Makefile文件,指定安装目录 vim Makefile PREFIX /open_app/user_installMakefile文件更改后如下所示make && make install2. nvidia-l4t-jetson-multimedia-api 下载包 wget https://repo…...

GraceTheme定义“优雅大气”的WordPress主题新标准
网站不仅是信息的载体,更是品牌气质的延伸。无论是企业官网、个人博客还是作品集展示,如何在茫茫网海中脱颖而出,给用户留下深刻的第一印象?答案往往就藏在网站的“气质”之中。如果你正在寻找一款能够完美平衡美学设计与功能实用性的WordPr…...

Air8101 搭载 RGB 直驱与 AirUI 适配工业电容屏开发
Air8101专为工业电容屏优化设计,RGB接口可直驱各类尺寸LCD电容屏,最高可支持1024*720分辨率屏,无需额外转接,大幅降低硬件开发成本。 一、硬件直驱: 目前正在支持完善:480*272分辨率:4.3寸屏800…...
)
实践之漏洞挖掘(弱口令)
前言:经过我的不懈努力,也是挖到了弱口令,嘻嘻,学校的,虽然没有泄露什么隐私,但是我交了要更新就是学校的漏洞,过不过都没关系,没过我下次就找有隐私的后台再交嘻嘻正题:…...

BiliTools AI视频总结:让B站学习效率提升300%的智能解决方案
BiliTools AI视频总结:让B站学习效率提升300%的智能解决方案 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools …...