数据分析每周挑战——心衰患者特征数据集
这是一篇关于医学数据的数据分析,但是这个数据集数据不是很多。
背景描述
本数据集包含了多个与心力衰竭相关的特征,用于分析和预测患者心力衰竭发作的风险。数据集涵盖了从40岁到95岁不等年龄的患者群体,提供了广泛的生理和生活方式指标,以帮助研究人员和医疗专业人员更好地理解心衰的潜在风险因素。
每条患者记录包含以下关键信息:
- 年龄(Age):记录患者的年龄,心脏病的风险随年龄增长而增加。
- 贫血(Anaemia):贫血可能影响心脏功能,记录患者是否患有贫血。
- 高血压(High blood pressure):高血压是心脏病的主要风险因素之一。
- 肌酸激酶(Creatinine phosphokinase, CPK):血液中的CPK水平可以反映心肌损伤。
- 糖尿病(Diabetes):糖尿病与心脏病风险增加有关。
- 射血分数(Ejection fraction):心脏每次收缩时泵出的血液百分比,是心脏功能的重要指标。
- 性别(Sex):性别可能影响心脏病的风险和表现形式。
- 血小板(Platelets):血小板水平可能与血液凝固和心脏病风险相关。
- 血清肌酐(Serum creatinine):血液中的肌酐水平可以反映肾脏功能,与心脏病风险有关。
- 血清钠(Serum sodium):钠水平的异常可能与心脏疾病相关。
- 吸烟(Smoking):吸烟是心脏病的一个重要可预防风险因素。
- 时间(Time):记录患者的随访期,用于观察长期健康变化。
- 死亡事件(death event):记录患者在随访期间是否发生了死亡事件,作为研究的主要结果指标。
数据说明
| 字段 | 解释 | 测量单位 | 区间 |
|---|---|---|---|
| Age | 患者的年龄 | 年(Years) | [40,…, 95] |
| Anaemia | 是否贫血(红细胞或血红蛋白减少) | 布尔值(Boolean) | 0, 1 |
| High blood pressure | 患者是否患有高血压 | 布尔值(Boolean) | 0, 1 |
| Creatinine phosphokinase, CPK | 血液中的 CPK (肌酸激酶)水平 | 微克/升(mcg/L) | [23,…, 7861] |
| Diabetes | 患者是否患有糖尿病 | 布尔值(Boolean) | 0, 1 |
| Ejection fraction | 每次心脏收缩时离开心脏的血液百分比 | 百分比(Percentage) | [14,…, 80] |
| Sex | 性别,女性0或男性1 | 二进制(Binary) | 0, 1 |
| Platelets | 血液中的血小板数量 | 千血小板/毫升(kiloplatelets/mL) | [25.01,…, 850.00] |
| Serum creatinine | 血液中的肌酐水平 | 毫克/分升(mg/dL) | [0.50,…, 9.40] |
| Serum sodium | 血液中的钠水平 | 毫摩尔/升(mEq/L) | [114,…, 148] |
| Smoking | 患者是否吸烟 | 布尔值(Boolean) | 0, 1 |
| Time | 随访期 | 天(Days) | [4,…,285] |
| DEATH_EVENT | 患者在随访期间是否死亡 | 布尔值(Boolean) | 0, 1 |
!pip install lifelines -i https://pypi.tuna.tsinghua.edu.cn/simple/
!pip install imblearn -i https://pypi.tuna.tsinghua.edu.cn/simple/这是我们这次用到的一些第三方库,大家如果没有安装,可以在jupyter notebook中直接下载。
一:导入第三方库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from lifelines import KaplanMeierFitter,CoxPHFitter
import scipy.stats as stats
from sklearn.model_selection import train_test_split
from imblearn.over_sampling import RandomOverSampler
from sklearn.metrics import classification_report,confusion_matrix,roc_curve,auc
from sklearn.ensemble import RandomForestClassifier
from pylab import mplplt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False二:读取数据
data = pd.read_csv("D:/每周挑战/heart_failure_clinical_records_dataset.csv")
data.head()三:对数据进行预处理
data = data.rename(columns={'age':'年龄','anaemia':'是否贫血','creatinine_phosphokinase':'血液中的CPK水平','diabetes':'患者是否患有糖尿病','ejection_fraction':'每次心脏收缩时离开心脏的血液百分比','high_blood_pressure':'患者是否患有高血压','platelets':'血液中的血小板数量','serum_creatinine':'血液中的肌酐水平','serum_sodium':'血液中的钠水平','sex':'性别(0为男)','smoking':'是否吸烟','time':'随访期(day)','DEATH_EVENT':'是否死亡'})
data.head()
# 将标签修改为中文更好看上面这一段可以不写,如果你喜欢英语可以不加,如果你喜欢汉字,那你可以更改一下。
data.info() # 从这里可以观察出应该是没有缺失值
data.isnull().sum() # 没有缺失值
data_ = data.copy() # 方便我们后期对数据进行建模区分连续数据和分类数据。
for i in data.columns:if set(data[i].unique()) == {0,1}:print(i)
print('-'*50)
for i in data.columns:if set(data[i].unique()) != {0,1}:print(i) 四:数据分析绘图
classify = ['anaemia','high_blood_pressure','diabetes','sex','smoking','DEATH_EVENT'] # DEATH_EVENT 这个是研究的主要结果指标
numerical = ['age','creatinine_phosphokinase','ejection_fraction','platelets','serum_creatinine','serum_sodium','time']plt.figure(figsize=((16,20)))
for i,col in enumerate(numerical):plt.subplot(4,2,i+1)sns.boxplot(y = data[col])plt.title(f'{col}的箱线图', fontsize=14)plt.ylabel('数值', fontsize=12)plt.grid(axis='y', linestyle='--', alpha=0.7)plt.tight_layout()
plt.show()
从箱型图来看,有些数据有部分异常值,但是,由于缺乏医学知识,所以这里我们不能对异常值进行处理。
colors = ['#63FF9D', '#C191FF']
plt.figure(figsize=(10,12))
for i,col in enumerate(classify):statistics = data[col].value_counts().reset_index()plt.subplot(3,2,i+1)sns.barplot(x=statistics['index'],y=statistics[col],palette=colors)plt.title(f'{col}的条形图', fontsize=14)plt.tight_layout()
plt.show()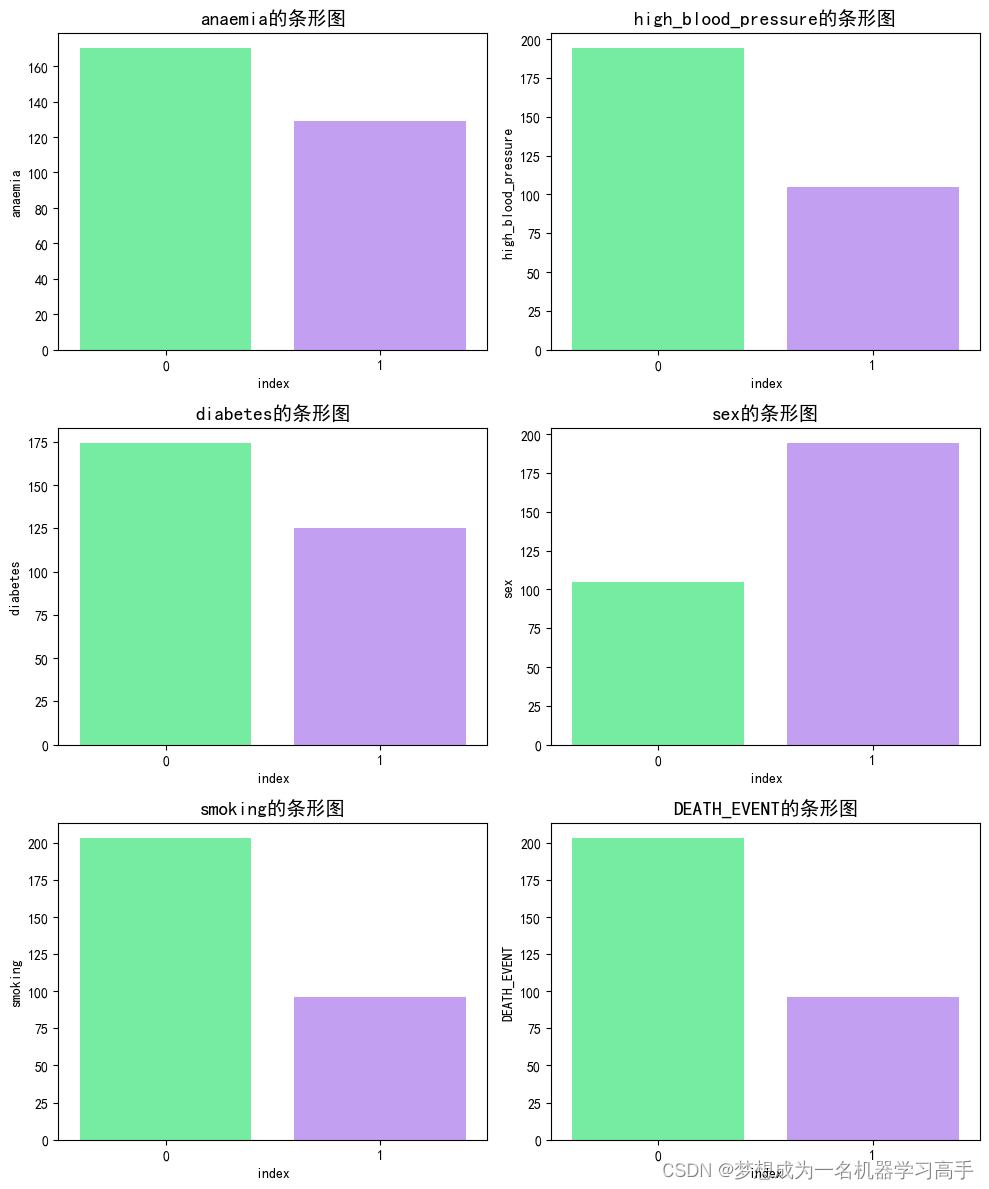
接下里,我们看时间对于生存率的影响,这里我们就用到了前面安装的KaplanMeierFitter。
kmf = KaplanMeierFitter()
kmf.fit(durations=data['time'],event_observed=data['DEATH_EVENT'])plt.figure(figsize=(10,8))
kmf.plot_survival_function()
plt.title('Kaplan-Meier 生存曲线', fontsize=14)
plt.xlabel('时间(天)', fontsize=12)
plt.ylabel('生存概率', fontsize=12)plt.show()
随着时间的推移,生存概率逐渐下降。 在随访结束时,生存概率大约为60%。 接下来,我们对特征相关性进行分析。
corr = data.corr(method="spearman")plt.figure(figsize=(10,8))
sns.heatmap(corr,annot=True,cmap='coolwarm',fmt='.2g')
plt.title("斯皮尔曼相关性矩阵")
plt.show()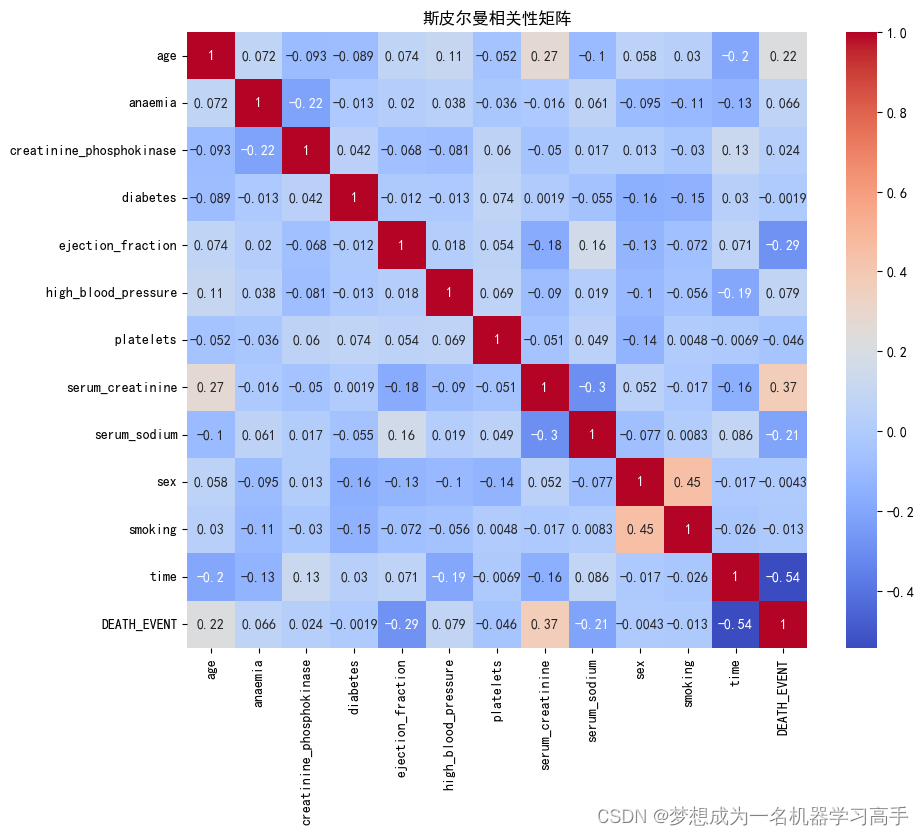
显著相关性:
年龄、射血分数、血清肌酐 血清钠 和 随访期 与死亡事件之间的相关性较强。 射血分数和血清肌酐与死亡事件的相关性尤为显著,这表明这些变量对死亡事件的预测可能具有重要意义。 弱相关性或无相关性:
贫血、高血压 与死亡事件有轻微相关性,但不显著。
肌酸激酶、糖尿病、血小板、性别 和 吸烟 与死亡事件几乎没有相关性。
def t_test(fea):group1 = data[data['DEATH_EVENT'] == 0][fea]group2 = data[data['DEATH_EVENT'] == 1][fea]t,p = stats.ttest_ind(group1,group2)return t,p# 对数值变量进行t检验
t_test_results = {feature: t_test(feature) for feature in numerical}t_test_df = pd.DataFrame.from_dict(t_test_results,orient='index',columns=['T-Statistic','P-Value'])
t_test_df| T-Statistic | P-Value | |
|---|---|---|
| age | -4.521983 | 8.862975e-06 |
| creatinine_phosphokinase | -1.083171 | 2.796112e-01 |
| ejection_fraction | 4.805628 | 2.452897e-06 |
| platelets | 0.847868 | 3.971942e-01 |
| serum_creatinine | -5.306458 | 2.190198e-07 |
| serum_sodium | 3.430063 | 6.889112e-04 |
| time | 10.685563 | 9.122223e-23 |
t检验是一种统计方法,用于比较两组数据是否存在显著差异。该方法基于以下步骤和原理:
建立假设:首先建立零假设(H0),通常表示两个比较群体间没有差异,以及备择假设(H1),即存在差异。
计算t值:计算得到一个t值,这个值反映了样本均值与假定总体均值之间的差距大小。
确定P值:通过t分布理论,计算出在零假设为真的条件下,观察到当前t值或更极端情况的概率,即P值。
做出结论:如果P值小于事先设定的显著性水平(通常为0.05),则拒绝零假设,认为样本来自的两个总体之间存在显著差异;否则,不拒绝零假设。
对于连续数据的特征我们采用t检验进行分析,而对于离散数据,我们采用卡方检验进行分析
# 卡方检验
def chi_square_test(fea1, fea2):contingency_table = pd.crosstab(data[fea1], data[fea2])chi2, p, dof, expected = stats.chi2_contingency(contingency_table)return chi2, pchi_square_results = {}
chi_square_results = {feature: chi_square_test(feature, 'DEATH_EVENT') for feature in classify}chi_square_df = pd.DataFrame.from_dict(chi_square_results,orient='index',columns=['Chi-Square','P-Value'])
chi_square_df| Chi-Square | P-Value | |
|---|---|---|
| anaemia | 1.042175 | 3.073161e-01 |
| high_blood_pressure | 1.543461 | 2.141034e-01 |
| diabetes | 0.000000 | 1.000000e+00 |
| sex | 0.000000 | 1.000000e+00 |
| smoking | 0.007331 | 9.317653e-01 |
| DEATH_EVENT | 294.430106 | 5.386429e-66 |
所有分类变量(贫血、糖尿病、高血压、性别、吸烟)的p值均大于0.05,表明它们与死亡事件无显著相关性。
最后我们对数据进行建模,这里我们使用随机森林,由于数据量较少,因此我们采用随机采样的方法进行过采样。
x = data.drop('DEATH_EVENT',axis=1)
y = data['DEATH_EVENT']
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3,random_state=15) #37分
# 实例化随机过采样器
oversampler = RandomOverSampler()# 在训练集上进行随机过采样
x_train, y_train = oversampler.fit_resample(x_train, y_train)rf_clf = RandomForestClassifier(random_state=15)
rf_clf.fit(x_train, y_train)y_pred_rf = rf_clf.predict(x_test)
class_report_rf = classification_report(y_test, y_pred_rf)
print(class_report_rf)precision recall f1-score support0 0.84 0.85 0.84 601 0.69 0.67 0.68 30accuracy 0.79 90macro avg 0.76 0.76 0.76 90 weighted avg 0.79 0.79 0.79 90
cm = confusion_matrix(y_test,y_pred_rf)plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='g', cmap='Blues', xticklabels=['预测值 0', '预测值 1'], yticklabels=['真实值 0', '真实值 1'])
plt.title('混淆矩阵')
plt.show()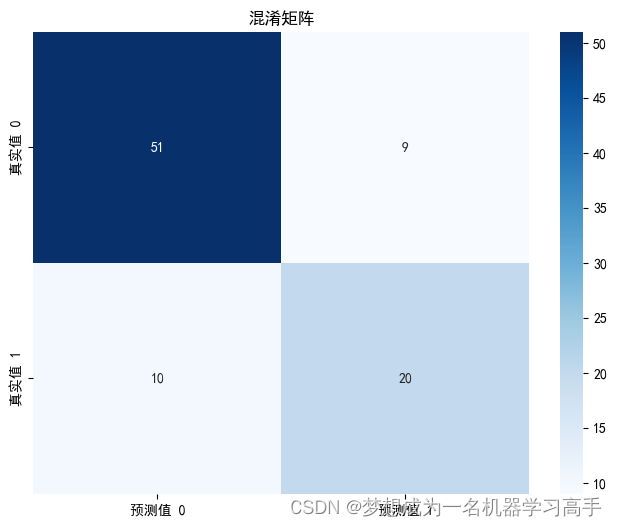
feature_importance = rf_clf.feature_importances_
feature = x.columnssort_importance = feature_importance.argsort()
plt.figure(figsize=(10,8))
plt.barh(range(len(sort_importance)), feature_importance[sort_importance],color='#B5FFCD')
plt.yticks(range(len(sort_importance)), [feature[i] for i in sort_importance])
plt.xlabel('特征重要性')
plt.title('特征重要性分析')plt.show()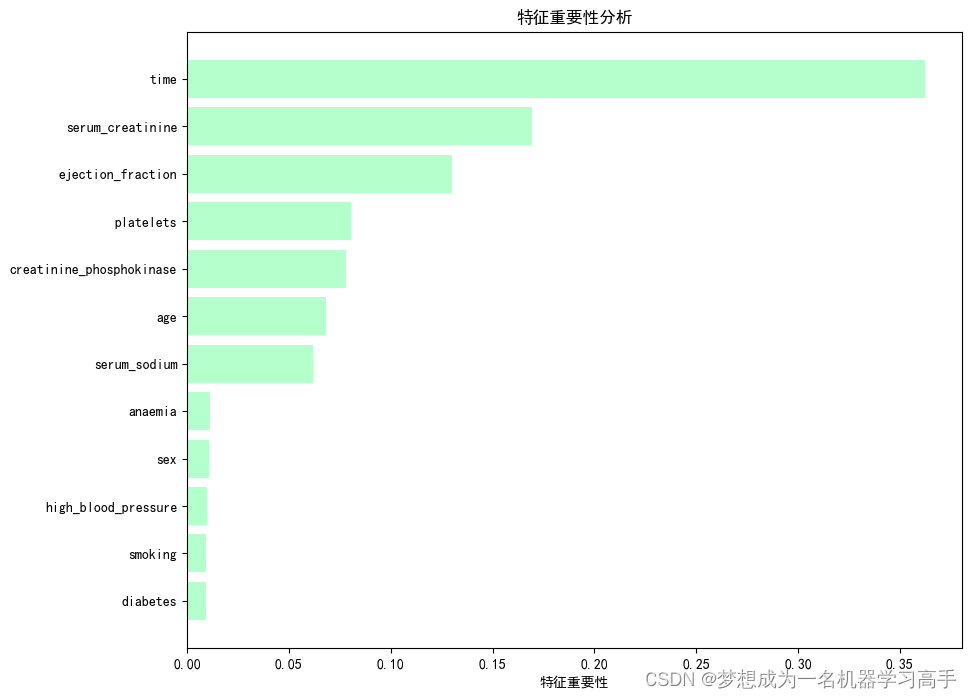
相关文章:
数据分析每周挑战——心衰患者特征数据集
这是一篇关于医学数据的数据分析,但是这个数据集数据不是很多。 背景描述 本数据集包含了多个与心力衰竭相关的特征,用于分析和预测患者心力衰竭发作的风险。数据集涵盖了从40岁到95岁不等年龄的患者群体,提供了广泛的生理和生活方式指标&a…...
)
单例模式(Java实现)
我的相关文章: JavaSE 学习记录-CSDN博客 多线程笔记-CSDN博客 单例模式(Java实现)-CSDN博客 JUC笔记-CSDN博客 注解与反射(Java,类加载机制,双亲委派机制)-CSDN博客 1. 懒汉式线程不安全 pu…...

24.面向对象六大原则
目录介绍 00.面向对象六大原则01.代码单一职责原则02.代码开放封闭原则03.代码里氏替换原则04.代码依赖倒置原则05.代码接口隔离原则06.代码迪米特原则00.面向对象六大原则 六大原则一句话介绍 单一职责原则:指一个类的功能要单一,不能包罗万象。开放封闭原则:指一个模块在扩…...

Vue3-shallowRef与shallowReactive
shallowRef 作用:创建一个响应式数据,但只对顶层属性进行响应式处理。 用法: let myVar shallowRef(initialValue);特点:只跟踪引用值的变化,不关心值内部的属性变化。 shallowReactive 作用:创建一个浅…...

CI/CD(基于ESP-IDF)
主要参考资料 B站乐鑫信息科技《【乐鑫全球开发者大会】DevCon23 #15 |通过 CI/CD 进行流水线开发》 pytest-embedded乐鑫文档: https://docs.espressif.com/projects/pytest-embedded/en/latest/api.html 目录 CI/CD简介乐鑫内部CI/CD测试GitLab CI/CDGitHub Actio…...

聚观早报 | 东风奕派eπ008将上市;苹果Vision Pro发布会
聚观早报每日整理最值得关注的行业重点事件,帮助大家及时了解最新行业动态,每日读报,就读聚观365资讯简报。 整理丨Cutie 6月3日消息 东风奕派eπ008将上市 苹果Vision Pro发布会 特斯拉Model 3高性能版开售 小米14推送全新澎湃OS系统 …...

k8s牛客面经篇
k8s的pod版块: k8s的网络版块: k8s的deployment版块: k8s的service版块: k8s的探针板块: k8s的控制调度板块: k8s的日志监控板块: k8s的流量转发板块: k8s的宏观版块:...

第9周 基于MinIO与OSS实现分布式与云存储
第9周 基于MinIO与OSS实现分布式与云存储 1. 基于mybatis-plus数据修改非空属性忽略更新2. 文件上传3. 分布式文件存储3.1 文件存储架构演变4. Minio docker安装5. 文件服务整合minio依赖minio API测试yml配置minio信息minio配置类业务:上传文件6. 云存储阿里OSS:要钱6.1 依赖6…...

【Linux内核-编程指南】
■ IPC组件 添加链接描述 ■ ■ ■ ■ ■...

Go 编程风格指南 - 最佳实践
Go 编程风格指南 - 最佳实践 原文:https://google.github.io/styleguide/go 概述 | 风格指南 | 风格决策 | 最佳实践 注意: 本文是 Google Go 风格 系列文档的一部分。本文档是 规范性(normative) 但不是强制规范(canonical),并且从属于Goo…...

awk的应用
步骤一:awk的基本用法 1)基本操作方法 格式1:awk [选项] [条件]{指令} 文件 格式2:前置指令 | awk [选项] [条件]{指令} 其中,print 是最常用的编辑指令;若有多条编辑指令,可用分号分隔。 …...
【网络原理】HTTP|认识请求“报头“|Host|Content-Length|Content-Type|UA|Referer|Cookie
目录 认识请求"报头"(header) Host Content-Length Content-Type User-Agent(简称UA) Referer 💡Cookie(最重要的一个header,开发&面试高频问题) 1.Cookie是啥? 2.Cookie怎么存的? …...

深入React Hoooks:从基础到自定义 Hooks
使用 useContext useContext 是另一个常用的 Hook,它可让我们在函数组件中轻松访问 React 的 context。如果你的应用程序依赖于一些全局状态,或者你希望避免将 props 一层一层地传递到子组件,context 很有用。你可以在父组件设置一个值&…...

9.7 Go语言入门(映射 Map)
Go语言入门(映射 Map) 目录六、映射 Map1. 声明和初始化映射1.1 使用 make 函数1.2 使用映射字面量 2. 映射的基本操作2.1 插入和更新元素2.2 访问元素2.3 检查键是否存在2.4 删除元素2.5 获取映射的长度 3. 遍历映射4. 映射的注意事项4.1 映射的零值4.2…...
过期视频怎么恢复?如何从手机、电脑和其他设备中恢复?
过期视频是指那些被误删、丢失或因系统升级等原因而无法正常访问的视频文件。这些视频可能包含了我们珍贵的回忆、重要的信息或者具有商业价值的内容。过期视频的恢复可以帮助我们找回失去的数据,减少损失,提高工作效率和生活质量。过期视频怎么恢复&…...

LeetCode刷题第2题
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。 请你将两个数相加,并以相同形式返回一个表示和的链表。 你可以假设除了数字 0 之外,这两个数都不会以 0 …...

mysql执行拼接的sql语句
在MySQL中,可以使用 CONCAT() 函数来拼接SQL语句。但是,请注意,直接拼接SQL语句可能会导致SQL注入问题,因此应当使用参数化查询来避免这个问题。 以下是一个使用 CONCAT() 函数拼接SQL语句的例子: SET tableName us…...

使用 pm2 或 screen 等工具来管理和后台运行你的 Node.js 应用
使用 pm2 或 screen 等工具来管理和后台运行你的 Node.js 应用。 使用 pm2 pm2 是一个用于 Node.js 应用的进程管理工具,提供了守护进程、日志管理和应用重启等功能。 安装 pm2: npm install pm2 -g启动你的 Node.js 应用: pm2 start se…...

leetcode4 寻找两个正序数组的中位数
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。 算法的时间复杂度应该为 O(log (mn)) 。 示例 1: 输入:nums1 [1,3], nums2 [2] 输出:2.00000 解释&a…...

水库大坝安全监测系统建设方案
一、背景 随着自动化技术的进步,大部分水库大坝不同程度地实现了安全监测自动化。但仍存在以下问题: 1、重建轻管,重视安全监测系统建设,不够重视运行维护。 2、缺乏系统性、综合性及相关性的资料分析功能。 3、软件大多为数据…...

Thrust安全最佳实践:保护你的桌面应用免受安全威胁
Thrust安全最佳实践:保护你的桌面应用免受安全威胁 【免费下载链接】thrust Chromium-based cross-platform / cross-language application framework 项目地址: https://gitcode.com/gh_mirrors/thru/thrust Thrust作为基于Chromium的跨平台应用框架&#x…...

GeoIP2-CN项目的用户调研结果:需求分析与功能规划
GeoIP2-CN项目的用户调研结果:需求分析与功能规划 项目背景与调研目标 GeoIP2-CN项目作为一款小巧精悍、准确、实用的GeoIP2数据库,旨在解决传统GeoIP2数据库在中国大陆用户使用中存在的痛点。本次用户调研通过收集代理工具用户的实际使用反馈…...

Ryujinx模拟器技术指南:在PC上运行Switch游戏的完整方案
Ryujinx模拟器技术指南:在PC上运行Switch游戏的完整方案 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx Ryujinx是一款用C#编写的开源Nintendo Switch模拟器,它…...

Docker常用指令速查手册
以下是 Docker 常用指令的表格汇总,按功能分类整理,便于日常查阅。一、镜像管理命令说明示例docker images列出本地所有镜像docker imagesdocker pull <镜像名>从仓库拉取镜像docker pull nginx:alpinedocker push <镜像名>将镜像推送到仓库…...
)
别再混淆了!一张图搞懂Node.js的process和浏览器环境的区别(附Webpack/Vite配置)
彻底掌握Node.js与浏览器环境差异:从process对象到构建工具实战 第一次在浏览器控制台看到"Uncaught ReferenceError: process is not defined"时,我盯着屏幕愣了三秒——明明在Node.js后端代码里用得好好的process.env,怎么到了前…...

第11天:函数组合、记忆化与定时器
今天复习了函数组合、记忆化、setTimeout 和 setInterval,以下是知识点梳理与问答整理。一、函数组合(Compose / Pipe)1. 什么是函数组合?我的回答:把上一个函数的返回值作为下一个函数的参数,形成流水线式…...

2025届必备的五大降重复率平台实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 于学术写作和论文创作的范畴之内,维普检测是颇为常见的查重办法。当遭遇人工智能…...

Lepton AI农业监测:作物生长分析服务构建实践
Lepton AI农业监测:作物生长分析服务构建实践 【免费下载链接】leptonai A Pythonic framework to simplify AI service building 项目地址: https://gitcode.com/gh_mirrors/le/leptonai Lepton AI是一个Pythonic框架,专为简化AI服务构建而设计&…...

终极指南:优化uid-generator内存管理的7个实用技巧,显著降低GC压力
终极指南:优化uid-generator内存管理的7个实用技巧,显著降低GC压力 【免费下载链接】uid-generator UniqueID generator 项目地址: https://gitcode.com/gh_mirrors/ui/uid-generator 在高并发系统中,uid-generator作为一款高效的唯一…...

Anthropic 源代码泄露:Claude Code 安全漏洞敲响 AI 警钟
Claude Code 源代码泄露,安全防线告急 人工智能公司 Anthropic 遭遇了严重的源代码泄露事件,此次事件直接影响了其 Claude Code 工具的安全性。研究人员在泄露的代码中发现了一个关键漏洞,这一漏洞的存在使得 Claude Code 可能执行其本不愿执…...