【pytorch】大模型训练张量并行
Large Scale Transformer model training with Tensor Parallel (TP)
张量并行如何工作
原始 Tensor Parallel (TP) 模型并行技术于Megatron-LM论文中被提出,是一种用于培育大规模Transformer模型的高效模型并行技术。我们在本练习指南中介绍的序列并行 (SP) 实际上是TP模型并行技术的一个变种,这里使用序列划分对 nn.LayerNorm 或 RMSNorm 进行划分,以节省在训练过程中的活动内存。随着模型体量的扩大,其运算内存就会成为主要瓶颈,因此TP模型并行技术通常是将序列并行应用于 LayerNorm 或 RMSNorm 层。
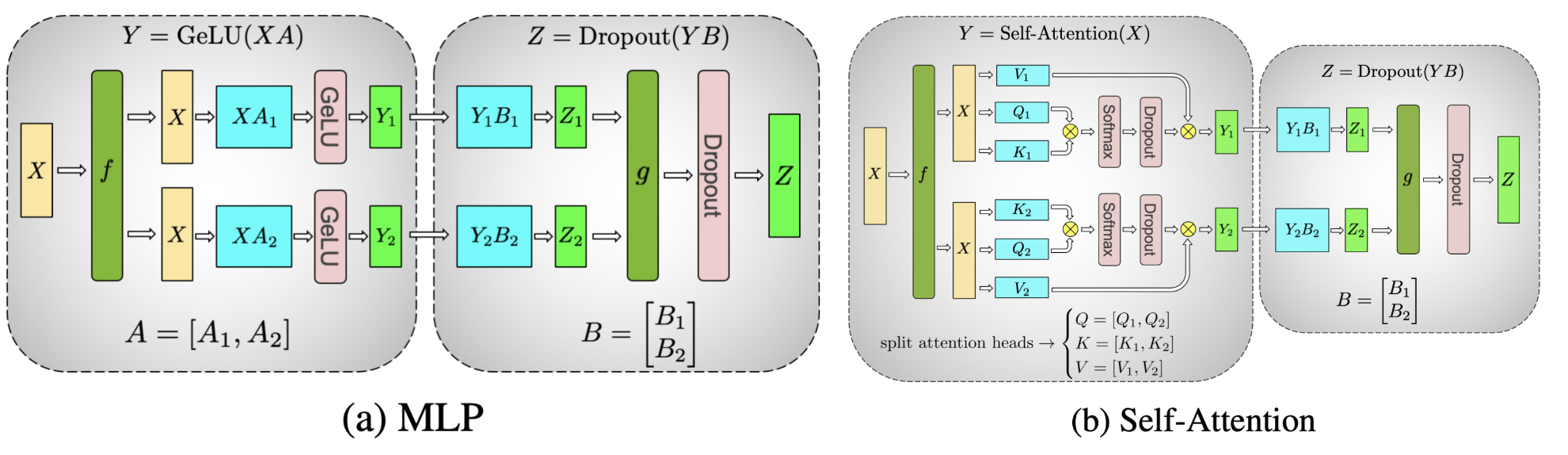
图1 示意了在 Transformer 模型的自注意力层和多层感知表征器 (MLP) 上,通过分布式计算来实现碎片化计算(图源)。该分布式计算中的向量乘法都发生在自注意力层和 MLP 之间:
在每种并行执行风格下,根据用户指定的输入/输出DTensor数组布局,将按照指定模式运行所需的通信操作,从而转换DTensor数组进行输入/输出操作(例如:allreduce、allgather和reduce_scatter)。
在并行层分片执行计算以节省计算和存储空间(例如,nn.Linear、nn.Embedding)。
为什么需要以及什么时候需要 Tensor Parallel¶
PyTorch的数据并行方法 (FSDP)已经具有了可以根据GPU数量来调节模型训练效果的能力。但是,当需要扩大模型训练时间及GPU数量的范围时,就会遇到一系列新问题,这可能还需要结合Tensor Parallel方法和FSDP相结合:
随着世界尺度 (GPU数量)的不断增加(超过128/256个GPU),FSDP集群(如allgather等)的性能将被大量环路延迟所打垮。 通过在FSDP集群基础上投入TP和SP,并使其只依附于各主机,这样可以降低8个单位世界尺度(GPU数量)。 因此FSDP的延迟成本将大大降低。
如果数据并行性削弱了最大全局批处理量,因为模型训练会导致内存消耗过高而无法增加GPU的数目,那么 Tensor/序列并行技术将是现阶段唯一知晓的“能够近似测算”全局批处理量的方式。这意味着模型的大小和GPU数目都可以进行更好地规模化发展。
对于某些特定类型的模型,当本地批次大小变得更小时,TP/SP可以实现矩阵乘法运算的形式,这种形式在进行浮点数操作(FLOPS)时比较有效。
所以在进行预训练时,能够达到这些限制要求是否太过容易?目前为止,只需用上数千个GPU,就可以用大量的语言模型来训练百亿或者万亿词汇量的模型。这样的预训练过程可能要花上很多月才能完成。
在对大规模推理时训练LLM时,始终会遇到限制1。例如,在使用2000个GPU进行35天的训练后,可以发现多维度并行运算对于规模为2k的LLM来说是必要的。
当 Transformer 模型越来越大时 (比如 70B 的 llama2),它也会迅速遇到瓶颈 2。即使在本地批量大小为1的情况下,只用 FSDP 是不足以应对内存和收敛约束条件所造成的问题的。例如,llama 2 的全局批处理大小是1K,因此在 2K GPU 上单独使用数据并行化将无法解决问题。
如何开启 Tensor Parallel¶
PyTorch 数据并行 API提供了一组模块级基本操作(分片方法),用于配置每个网络中的特定层次对象进行分片映像:包括以下内容:
在 colwise parallel 和row wise parallel模式下,分别将 Linear 层和 Embedding 层的网络叠加成为 nn.Linear 和 nn.Embedding。
序列并行运算:在nn.LayerNorm、nn.Dropout、RMSNormPython等层面上进行分片计算。
调整模块输入和输出的拆分方式,使用正确的通讯操作设置模块输入/输出。
以下我们将介绍 PyTorch 原生的 Tensor Parallel API在使用时的示例,先从一个常见的 Transformer 模型开始。本教程采用最新版 Llama2 Transformer 作为基准实现的参考案例,因为这个模型在业界也广泛使用。
由于 Tensor Parallel 将数据分割到多个设备上,因此我们需要在部署跨设备环境(例如通信库)之前进行准备。Tensor Parallel 遵循单程式多数据 (SPMD) 的分片算法,类似于 PyTorch DDP/FSDP,内部使用了 PyTorch DTensor 实现分片。它还将 DeviceMesh 抽象进行设备管理和分片,详情可参见本教程。Tensor Parallel 通常在单个节点上运行,因此我们需要首先使用 DeviceMesh 连接该节点上的 8 个 GPU。
# run this via torchrun: torchrun --standalone --nproc_per_node=8 ./tp_tutorial.pyfrom torch.distributed.device_mesh import init_device_meshtp_mesh = init_device_mesh("cuda", (8,))
现在我们已经初始化了 DeviceMesh,接下来让我们仔细探索 Llama2的模型结构并看看如何对 Tensor Parallel进行分片操作。具体来说,TransformerBlock是 Transformer 模型中的主要组件,通过在其上栈出相同 TransformerBlock 实现规模化效果。
转换器块的核心部分是一个注意力层和前向传播层。让我们先看看后者更为简单的前向传播层:
前向传播层中包含三个线性层,在运行时使用SwiGLU模型来进行多层感知器(MLP)计算。接下来我们看看前向传播层的输出函数:
# forward in the FeedForward layer
def forward(self, x):return self.w2(F.silu(self.w1(x)) * self.w3(x))
它并行运行 W1、W3 乘法和之后,再运行一次 W2 的乘法操作,将这两个部分的线性投影结果相加得到最终结果。因此,我们可以根据《Tensor Parallelism》论文中所介绍的思想,对 W1、W3 层和 W2 层分别按阵列方式投影并且进行分片操作,这样最后只需要一次全局广播就可以了。在 PyTorch 原生的 Tensor Parallel 中,我们可以使用如下语句创建 FeedForward 层的并行计划:
from torch.distributed.tensor.parallel import ColwiseParallel, RowwiseParallel, parallelize_modulelayer_tp_plan = {# by default ColwiseParallel input layouts is replicated# and RowwiseParallel output layouts is replicated"feed_foward.w1": ColwiseParallel(),"feed_forward.w2": RowwiseParallel(),"feed_forward.w3": ColwiseParallel(),
}
这只不过是我们在使用 Pytorch 张量并行 API 时将FeedForward层设置成纵向扩展的方式。值得注意的是,用户无需为每个层进行分片配置,只要知道如何处理通信(比如,allreduce)即可。
接下来我们讨论 Attention Layer。该层拥有 wq、wk 和 wv三个线性层,用于将输入进行 q/ k / v 的编码,然后再通过 w0 线性层实现注意力机制和输出项目化。我们计划在这里沿着数据维度进行分片操作,对 q/k/v 编码部分采用列向分片操作,而对 w0 线性层的输出则使用行向分片。因此我们可以将 Attention 计划添加到我们前面制定的 tp_plan 中:
layer_tp_plan = {# by default ColwiseParallel input layouts is replicated# and RowwiseParallel output layouts is replicated"attention.wq": ColwiseParallel(),"attention.wk": ColwiseParallel(),"attention.wv": ColwiseParallel(),"attention.wo": RowwiseParallel(),"feed_forward.w1": ColwiseParallel(),"feed_forward.w2": RowwiseParallel(),"feed_forward.w3": ColwiseParallel(),
}
这样的层_tp_plan就是我们对TransformerBlock中线性层应用Tensor Parallelism所需要的几乎一模一样的形式,不过需注意的是在对线性层进行行列维护时,线性层的输出将会被碾压到最后一个维度,而对应的行列维护的线性层是直接使用相互串联的多维数组作为输入的。 如果之间还有其他多维操作(例如视图操作),则我们需要对所有透过线性层的形状操作进行相应调整至碾压后的形状。
在 llama模型的注意层中,有一些视图相关操作。其中,针对 wq/wk/wv线性层并行运算(column-wise parallel for)时,活化张量会通过 num_heads 维度进行分片处理,这意味着需要调整数据集中的 num_heads 变量为当地数值。
最后,我们需要调用 parallelize_module API,才能使 TransformerBlock层的计划有效。在这里,它将模型参数分配给Attention和FeedForward两个层,并以 DTensor 形式存放;如果需要的话,也会预留沟通信息处理的接口(前置处理与后置处理):
for layer_id, transformer_block in enumerate(model.layers):layer_tp_plan = {...} # i.e. the plan we just generated# Adjust attention module to use the local number of headsattn_layer = transformer_block.attentionattn_layer.n_heads = attn_layer.n_heads // tp_mesh.size()attn_layer.n_kv_heads = attn_layer.n_kv_heads // tp_mesh.size()parallelize_module(module=transformer_block,device_mesh=tp_mesh,parallelize_plan=layer_tp_plan,)
现在我们对每个 TransformerBlock都已经细化了分片计划,通常在第一层是有 nn.Embedding 这样的前向传播层,并且后面还会包含 nn.Linear 这样的最后一层卷积神经网络层,用户可以在其中选择行与列分片到前者的方式和选择横向分片到后者的方式。我们还会针对这两种方法设定相应的输入、输出布局。 下面举例说明:
model = parallelize_module(model,tp_mesh,{"tok_embeddings": RowwiseParallel(input_layouts=Replicate(),),"output": ColwiseParallel(output_layouts=Replicate(),),}
)
注释
如果要进行分片的模型体积过大且不能放入 CPU 内存,则可以选择先初始化元设备 (比如将模型从元设备开始初始化后再进行分片处理),或者在 Transformer 模型初始化过程中逐层并行化 TransformerBlock 块。若体积过大而无法放入 CPU 内存,则需要采取此种方式。
LayerNorm/RMSNorm层应用 Sequence Parallel¶
序列并行层结构在上面介绍的Tensor并行框图之上,与基本Tensor并行相比,后者只对Attention模块和FeedForward模块的输入和输出(即前向传播阶段中的激活值和反向传播阶段的梯度值)进行碎片,而序列并行则是对其进行了在时间维度上的碎片。
在典型的TransformerBlock模块中,前向函数通常包括标准化层(LayerNorm或RMSNorm)、注意力层、逐层前向传播层以及反向连接。例如:
# forward in a TransformerBlock
def forward(self, x):h = x + self.attention(self.attention_norm(x))out = h + self.feed_forward(self.ffn_norm(h))return out
在大多数使用案例中,卷积的输出形式(及其导数)是[batch size、序列长度、隐藏单元]这样的形式,除了具有注意力模块和输入模块外。在DTensor语言中,Sequence Parallel执行对两个方向(前向或者反向)的脆弱层的活动化操作时使用了Shard(1)形式。 下面的代码示例展示了在TransformerBlock内部如何将Sequence Parallel应用于轮回卷积层上:
首先我们来设置序列并行所需要的依赖包:
from torch.distributed.tensor.parallel import (PrepareModuleInput,SequenceParallel,
)
现在,我们可以调整 layer_tp_plan 选项,并启用 RMSNorm 层的序列平行模式:
layer_tp_plan = {# Now the input and output of SequenceParallel has Shard(1) layouts,# to represent the input/output tensors sharded on the sequence dimension"attention_norm": SequenceParallel(),"attention": PrepareModuleInput(input_layouts=(Shard(1),),desired_input_layouts=(Replicate(),),),"attention.wq": ColwiseParallel(),"attention.wk": ColwiseParallel(),"attention.wv": ColwiseParallel(),"attention.wo": RowwiseParallel(output_layouts=Shard(1)),"ffn_norm": SequenceParallel(),"feed_forward": PrepareModuleInput(input_layouts=(Shard(1),),desired_input_layouts=(Replicate(),),),"feed_forward.w1": ColwiseParallel(),"feed_forward.w2": RowwiseParallel(output_layouts=Shard(1)),"feed_forward.w3": ColwiseParallel(),
}
我们现在使用 PrepareModuleInput 来修改 Attention 层与前向传播层 Shard(1) 到 Replicate() 的模型输入布局,并将两者的输出布局标记为 Shard(1)。 这是类似于 Tensor Parallelism 在使用中所采用的操作方式,只需要对模型的输入和输出进行一次布局设置,就能让内部交流自动生成并运行。
请注意,Sequence Parallel假设TransformerBlock的输入和输出总是会在序列维度进行分片,这样就可以将多个TransformerBlock实现无缝连接。为了方便地实现此功能,我们需要明确指定嵌入层的输出和线性投影层的输入都是 Shard(1):
model = parallelize_module(model,tp_mesh,{"tok_embeddings": RowwiseParallel(input_layouts=Replicate(),output_layouts=Shard(1),),"norm": SequenceParallel(),"output": ColwiseParallel(input_layouts=Shard(1),output_layouts=Replicate()),}
)
使用 Loss Parallel¶
在计算损失函数的时候,可以使用“Loss Parallel”技术来降低内存和通信成本,因为输出大多比较庞大。 “Loss Parallel”是将模型输出按照(通常非常大的)词表维度进行分片,从而可以高效地计算交叉熵损失并避免每个GPU都要获取所有模型输出。这样不但能大大减少内存消耗量,还能提高训练速度,因为通过分片来实现并行计算可以避免所需的数据传输过程。图3-1 对比了“Loss Parallel”技术与传统方法的不同之处:后者会在每个GPU上都集中加载所有模型输出。
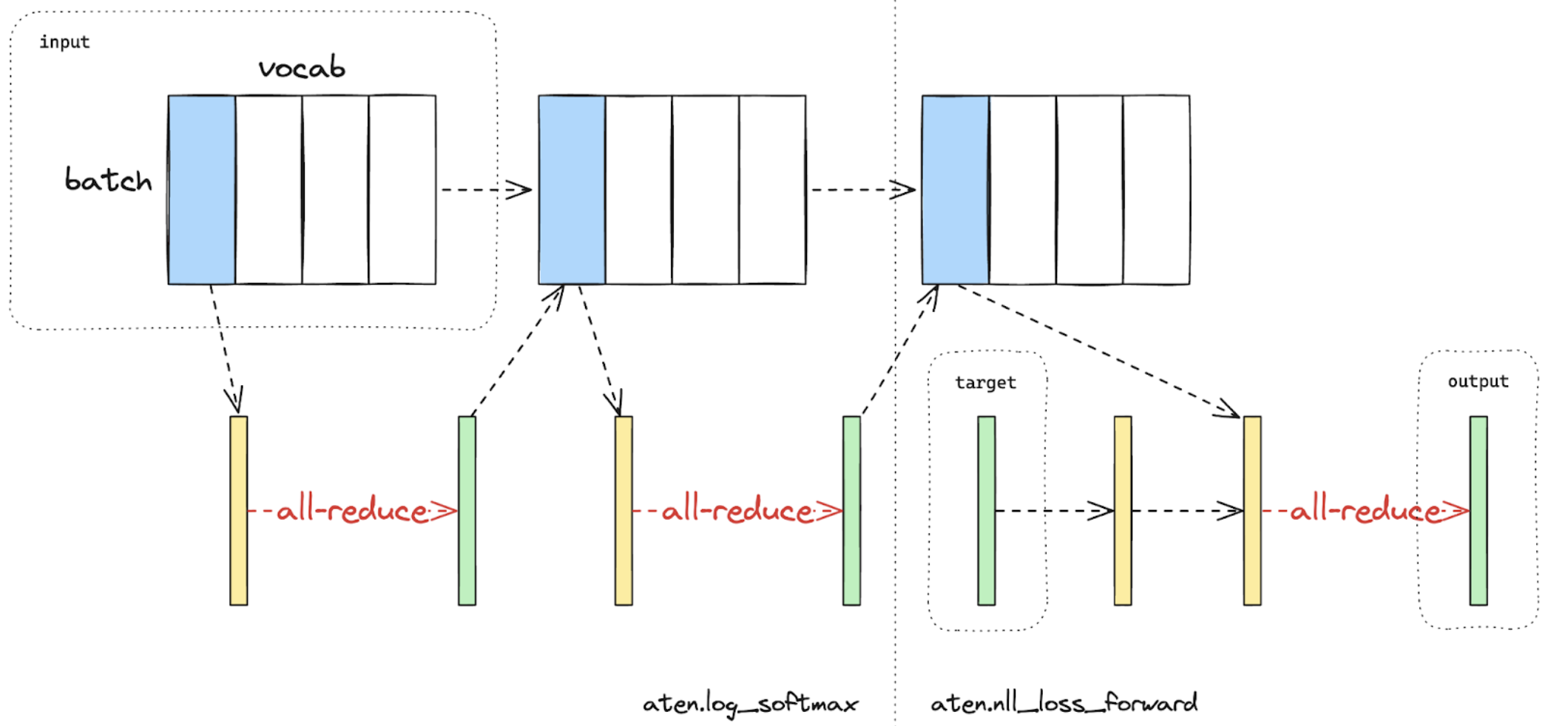
图2为使用一块显存进行梯度下降时的交错熵损失计算示意图。 蓝色代表分片的张量; 绿色代表重复的张量;黄色代表部分值张量(需要全局求和),以上三种张量各自标记为一个位置点、重复张量点或者部分值张量点。黑线代表本地计算;红线则是显存之间的函数集合。¶
在PyTorch Tensor并行 API中,可通过loss_parallel上下文管理器启用 Loss Parallel 功能,从而直接使用torch.nn.functional.cross_entropy 或者 torch.nn.CrossEntropyLoss,无需修改代码以达到其他目的。
要使用 Loss Parallel,模型预测应将输出格式拆分为[数据集大小、序列长度和词库大小]的组合。这可以通过标记最后一层线性投影层的输出位置来实现,并将其分解到词汇维度:
model = parallelize_module(model,tp_mesh,{"tok_embeddings": RowwiseParallel(input_layouts=Replicate(),output_layouts=Shard(1),),"norm": SequenceParallel(),"output": ColwiseParallel(input_layouts=Shard(1),# use DTensor as the outputuse_local_output=False,),},
)
上面的代码还加入了序列并行操作,在前向推理之后用于输出层。我们使用use_local_output=False参数来防止输出变成一个 DTensor 类型,以便与loss_parallel模式管理器进行工作。接下来就可以通过跨样本负担函数计算交叉熵了。需要注意的是,逆向推理操作还应该在同一个模式管理器内进行。
import torch.nn.functional as F
from torch.distributed.tensor.parallel import loss_parallelpred = model(input_ids)
with loss_parallel():# assuming pred and labels are of the shape [batch, seq, vocab]loss = F.cross_entropy(pred.flatten(0, 1), labels.flatten(0, 1))loss.backward()
将 Tensor Parallel 和 Fully Sharded Data Parallel 结合起来¶
现在,我们已经讲解了如何应用序列并行和张量并行技术在模型上的部署方式。此外,接下来还要介绍张量并行与全分片数据并行技术是否可以合作工作。
因为张量并行使用了交叉通信操作,所以会导致计算效率下降,此时我们希望其能在高速通讯通道上运行,比如 NVLink。实际上,张量并行通常是在单个主机中进行的,而全分片数据并行技术则应用于多个主机之间。
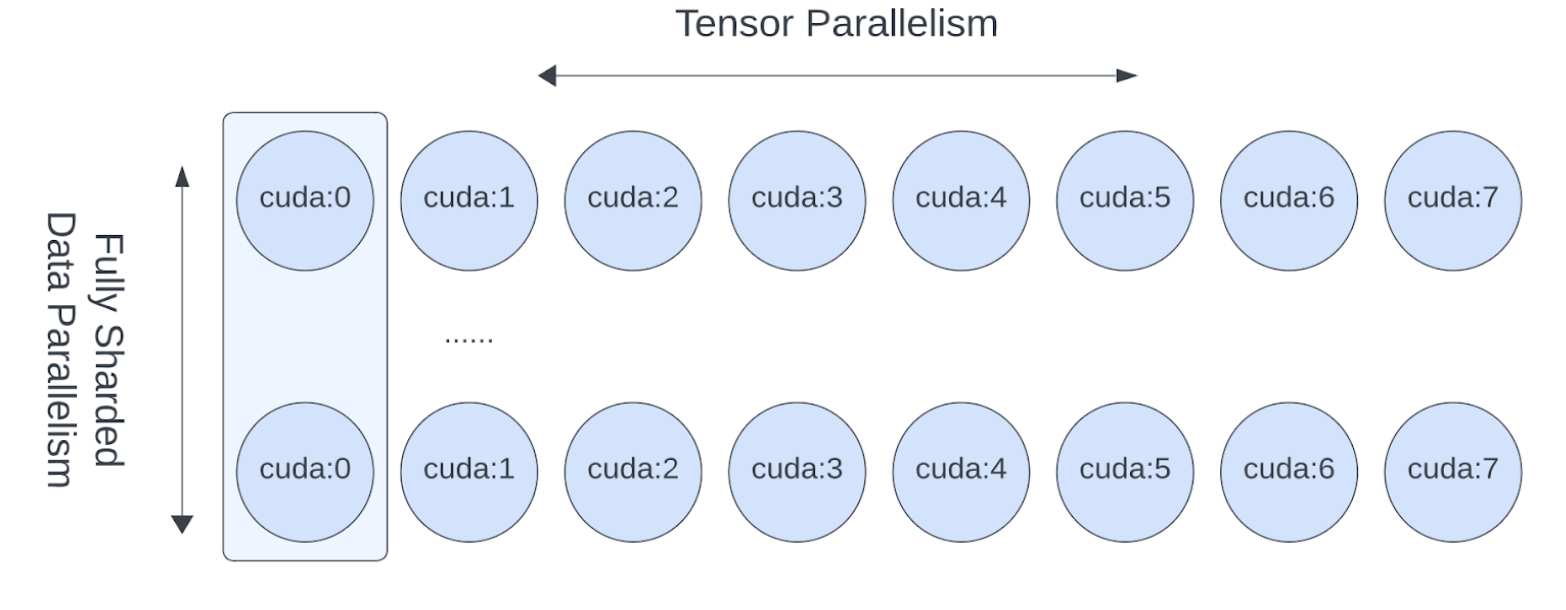
图 3: FSDP 和 TP 的工作涉及不同设备维度,FSDP 通信以跨主机为单位进行,TP通信则在主机内部进行。
这种以二维形式描述并表达的平行运算模型,可通过使用二维DeviceMesh来实现,只需将“子”DeviceMesh块逐个传给每一个平行化API即可:
from torch.distributed.device_mesh import init_device_mesh
from torch.distributed.tensor.parallel import ColwiseParallel, RowwiseParallel, parallelize_module
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP# i.e. 2-D mesh is [dp, tp], training on 64 GPUs that performs 8 way DP and 8 way TP
mesh_2d = init_device_mesh("cuda", (8, 8))
tp_mesh = mesh_2d["tp"] # a submesh that connects intra-host devices
dp_mesh = mesh_2d["dp"] # a submesh that connects inter-host devicesmodel = Model(...)tp_plan = {...}# apply Tensor Parallel intra-host on tp_mesh
model_tp = parallelize_module(model, tp_mesh, tp_plan)
# apply FSDP inter-host on dp_mesh
model_2d = FSDP(model_tp, device_mesh=dp_mesh, use_orig_params=True, ...)
这样的方法可以让我们在很容易地利用Tensor Parallel技术来加速模型训练并进行数据并行计算,而且无需更改代码就能实现在不同主机(intra-host)和不同主机之间的并行计算 (inter-hosts)。 通过Tensor(Model) Parallel技术与数据并行技术结合使用,我们可以继续增大模型训练集成度,同时利用大量GPU进行高效的计算。
相关文章:
【pytorch】大模型训练张量并行
Large Scale Transformer model training with Tensor Parallel (TP) 张量并行如何工作 原始 Tensor Parallel (TP) 模型并行技术于Megatron-LM论文中被提出,是一种用于培育大规模Transformer模型的高效模型并行技术。我们在本练习指南中介绍的序列并行 (SP) 实际…...

Flutter 中的 CupertinoSliverNavigationBar 小部件:全面指南
Flutter 中的 CupertinoSliverNavigationBar 小部件:全面指南 Flutter 是一个由 Google 开发的跨平台 UI 框架,它允许开发者使用 Dart 语言来构建高性能、美观的移动、Web 和桌面应用。在 Flutter 的丰富组件库中,CupertinoSliverNavigation…...

【数据库系统概论】程序题
“学生管理数据库”包含以下三个表,即学生表Student、课程表Course和选课表SC,结构如下: Student(Sno,Sname,Ssex,Sage,Sdept)Course (Cno,Cname&…...
群体优化算法---蝙蝠优化算法分类Iris数据集
介绍 蝙蝠算法(Bat Algorithm, BA)是一种基于蝙蝠回声定位行为的优化算法。要将蝙蝠算法应用于分类问题,可以通过将蝙蝠算法用于优化分类器的参数,图像分割等 本文示例 我们使用一个经典的分类数据集,如Iris数据集&…...

【C++】类和对象1.0
本鼠浅浅介绍一些C类和对象的知识,希望能得到读者老爷们的垂阅! 目录 1.面向过程和面向对象 2.类的引入 3.类的定义 4.类的访问限定符及封装 4.1.类的访问限定符 4.2.封装 5.C中struct和class的区别 6.类域 7.类的实例化 8.类对象模型 8.1.类…...

Linux下gcc编译32位程序报错
gcc使用-m32选项,编译32位程序时,报错:/usr/include/stdio.h:27:10: fatal error: bits/libc-header-start.h: No such file or directory gcc编译32位程序时,报错:/usr/include/stdio.h:27:10: fatal error: bits/li…...
godot.bk
1.搜索godot国内镜像,直接安装,mono是csharp版本 2.直接解压,50m,无需安装,直接运行 3.godot里分为场景,节点 主场景用control场景,下面挂textureact放背景图片,右键实例化子场景把…...

【C++修行之道】类和对象(三)拷贝构造函数
目录 一、 概念 二、特征 正确的拷贝构造函数写法: 拷贝函数的另一种写法 三、若未显式定义,编译器会生成默认的拷贝构造函数。 四、编译器生成的默认拷贝构造函数已经可以完成字节序的值拷贝了,还需要自己显式实现吗? 深拷…...

校园外卖系统的技术架构与实现方案
随着校园生活的日益现代化,外卖需求在高校学生群体中迅速增长。为了满足这一需求,校园外卖系统应运而生。本文将详细探讨校园外卖系统的技术架构及其实现方案,帮助读者了解这一系统的核心技术与实现路径。 一、系统概述 校园外卖系统主要包…...

AI的制作思维导图
AI(人工智能)的实现通常涉及以下几个步骤: 1.问题定义:首先确定你想要解决的问题是什么,这将决定你需要设计什么样的系统。 2.数据收集:根据你的需求,收集相关的数据集来训练你的AI模型。数据的…...

Amazon云计算AWS(四)
目录 八、其他Amazon云计算服务(一)快速应用部署Elastic Beanstalk和服务模板CloudFormation(二)DNS服务Router 53(三)虚拟私有云VPC(四)简单通知服务和简单邮件服务(五&…...

数据库(21)——数值函数
数值函数 函数功能CEIL(x)向上取整FLOOR(x)向下取整MOD(x,y)返回x/y的余数RAND()返回0~1内的随机数ROUND(x,y) 求参数x的四舍五入的值,保留y位小数 演示 select ceil(66.4); select floor(8.9); select mod(3,10); select rand(); select round…...
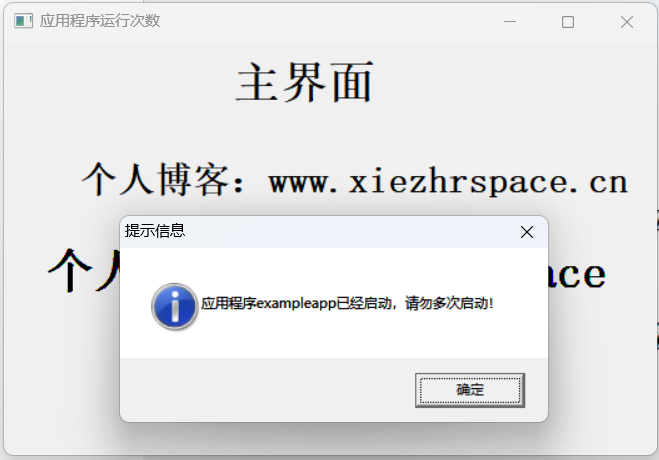
【PB案例学习笔记】-15怎样限制应用程序运行次数?
写在前面 这是PB案例学习笔记系列文章的第15篇,该系列文章适合具有一定PB基础的读者。 通过一个个由浅入深的编程实战案例学习,提高编程技巧,以保证小伙伴们能应付公司的各种开发需求。 文章中设计到的源码,小凡都上传到了gite…...

Spring为什么不支持static字段注入
Spring不支持直接依赖注入到静态变量中。在Spring框架中,依赖注入是一个核心概念,它允许开发者将对象间的依赖关系定义转移到容器中,由容器负责管理这些依赖关系。然而,当涉及到静态变量时,情况就变得复杂了。 首先从…...

AI数据分析:用Kimi根据Excel表格数据绘制多条折线图
工作任务:将Excel文件中的学生姓名和他们的语文、数学、英语成绩绘制成三条折线图,以便于比较不同科目的成绩分布情况。 在kimi中输入提示词: 你是一个Python编程专家,要完成一个Python脚本编写的任务,具体步骤如下&a…...

高级 Go 程序设计:使用 net/http/httputil 包构建高效网络服务
高级 Go 程序设计:使用 net/http/httputil 包构建高效网络服务 介绍ReverseProxy 的使用基本概念实现步骤高级配置实际案例 DumpRequest 的使用功能说明代码示例应用场景NewSingleHostReverseProxy 的特性功能概述 详细教程 注意事项使用 NewChunkedWriter 实现高效…...

Android11 AudioTrack 创建过程
Android 系统播放声音,需要创建AudioTrack来和AudioFlinger通信,其创建过程如下 根据传入的声音属性得到output通过得到的output,找到播放线程AudioFlinger在播放线程内,创建Track,和AudioTrack对应。后续通过它们进…...

数学建模 —— 层次分析法(2)
目录 一、层次分析法(AHP) 二、构造比较判断矩阵 2.1 两两比较法 三、单准则下的排序及一致检验 3.1 单准则下的排序 3.2 一致性检验 四、层次总排序 4.1 层次总排序的步骤 4.2 总排序一致性检验 一、层次分析法(AHP) 方…...

Nvidia Jetson/Orin +FPGA+AI大算力边缘计算盒子:人工智能消防应用
青鸟消防股份有限公司成立于2001年6月,于2019年8月在深圳证券交易所挂牌上市,成为中国消防报警行业首家登陆A股的企业。公司始终聚焦于消防安全与物联网领域,主营业务为“一站式”消防安全系统产品的研发、生产和销售。公司产品已覆盖了火灾报…...

Flutter 中的 KeepAlive 小部件:全面指南
Flutter 中的 KeepAlive 小部件:全面指南 Flutter 是一个由 Google 开发的跨平台 UI 框架,它允许开发者使用 Dart 语言构建高性能、美观的移动、Web 和桌面应用。在 Flutter 的丰富组件库中,KeepAlive 是一个用于维护组件活跃状态的组件&…...

ST7789显示屏驱动实战指南:从基础配置到高级应用
ST7789显示屏驱动实战指南:从基础配置到高级应用 【免费下载链接】st7789py_mpy 项目地址: https://gitcode.com/gh_mirrors/st/st7789py_mpy ST7789显示屏驱动是一款专为嵌入式系统设计的高性能TFT LCD控制器解决方案,支持多种分辨率与丰富显示…...

3步打造waifu2x-caffe轻量化部署方案:图像增强绿色版打包全流程
3步打造waifu2x-caffe轻量化部署方案:图像增强绿色版打包全流程 【免费下载链接】waifu2x-caffe waifu2xのCaffe版 项目地址: https://gitcode.com/gh_mirrors/wa/waifu2x-caffe waifu2x-caffe是一款基于深度学习的图像增强工具,能够通过AI算法实…...
)
从信号处理到量化交易:我是如何用Python+miniQMT搭建实时行情数据管道的(附避坑经验)
从信号处理到量化交易:PythonminiQMT构建高可靠行情管道的工程实践 第一次尝试用Python连接miniQMT获取实时行情时,我的回调函数在开盘瞬间就被数据洪流冲垮了——这让我意识到金融数据流的处理与信号处理领域的实时系统设计竟有惊人的相似。本文将分享如…...

MySQL函数及条件查询相关用法
文章目录 前言 一、函数(可跳过) 1.字符串函数 2.数值函数 3.日期和时间函数 4.聚合函数(常用) 5.控制流函数 6.加密和压缩函数 7.系统信息函数 二、条件查询(select) 1.筛选条件子句where与hav…...

DDrawCompat:让经典软件重获新生的兼容性解决方案
DDrawCompat:让经典软件重获新生的兼容性解决方案 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_mirrors/dd/DDrawCompa…...

DreamZero技术解析:当视频扩散模型成为机器人“物理大脑“
原文摘要翻译最先进的视觉-语言-动作(VLA)模型在语义泛化方面表现出色,但在新环境中难以泛化到未见过的物理动作。我们提出了 DreamZero,一种基于预训练视频扩散主干网络构建的世界动作模型(WAM)。与 VLA 不…...

Windows下OpenClaw全攻略:Qwen3.5-9B-AWQ-4bit接入与避坑指南
Windows下OpenClaw全攻略:Qwen3.5-9B-AWQ-4bit接入与避坑指南 1. 为什么选择OpenClawQwen3.5组合? 去年我在处理大量图片素材归档时,发现手动分类效率极低。直到尝试将OpenClaw与Qwen3.5-9B-AWQ-4bit镜像结合,才真正体会到本地A…...

LTspice2Matlab:电路仿真数据导入MATLAB的高效解决方案
LTspice2Matlab:电路仿真数据导入MATLAB的高效解决方案 【免费下载链接】ltspice2matlab LTspice2Matlab - Import LTspice data into MATLAB 项目地址: https://gitcode.com/gh_mirrors/lt/ltspice2matlab 在电路设计与仿真工作中,如何将LTspice…...

如何快速掌握Unity资产编辑:面向开发者的完整教程
如何快速掌握Unity资产编辑:面向开发者的完整教程 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA UABEA是一款专业的Unity Asset Bundle编辑器,专为游戏开发者和模组制作者设计…...

OpenCode-Tokenscope 安装和使用指南
OpenCode-Tokenscope 安装和使用指南全面的 OpenCode AI 会话 token 使用分析和成本追踪插件安装 方法 1: npm (推荐) 步骤 1: 全局安装 npm install -g ramtinj95/opencode-tokenscope步骤 2: 配置 opencode.json 在以下位置之一创建 opencode.json: 项目根目录~/.…...