【机器学习】解锁AI密码:神经网络算法详解与前沿探索
👀传送门👀
- 🔍引言
- 🍀神经网络的基本原理
- 🚀神经网络的结构
- 📕神经网络的训练过程
- 🚆神经网络的应用实例
- 💖未来发展趋势
- 💖结语

🔍引言
随着人工智能技术的飞速发展,神经网络作为机器学习的一个重要分支,已经广泛应用于图像识别、自然语言处理、推荐系统等领域。神经网络通过模拟人脑神经元的连接方式,实现对复杂数据的处理和预测。本文将详细介绍神经网络的基本原理、结构、训练过程以及应用实例。
🍀神经网络的基本原理
神经网络是由大量神经元相互连接而成的复杂网络结构。每个神经元接收来自其他神经元的输入信号,经过加权求和和激活函数的非线性变换后,产生输出信号。这些输出信号又作为其他神经元的输入信号,如此循环往复,形成网络的前向传播过程。
神经网络的训练过程则是通过反向传播算法不断调整网络中的权重参数,使得网络的输出逐渐接近真实值。具体而言,训练过程包括前向传播、计算损失函数、反向传播和更新权重四个步骤。
🚀神经网络的结构
神经网络的结构多种多样,但常见的结构包括全连接神经网络、卷积神经网络(CNN)、循环神经网络(RNN)等。
- 全连接神经网络:是最简单的神经网络结构,每个神经元都与前一层和后一层的所有神经元相连。全连接神经网络适用于处理简单的线性分类和回归问题。
- 卷积神经网络:是一种专门用于处理图像数据的神经网络结构。它通过卷积操作提取图像中的局部特征,并通过池化操作降低数据维度,从而实现对图像的有效识别。
- 循环神经网络:适用于处理序列数据,如文本、语音等。它通过引入循环连接,使得网络能够记忆之前的信息,从而实现对序列数据的长期依赖建模。
📕神经网络的训练过程
神经网络的训练过程主要包括以下几个步骤:
- 前向传播:将输入数据通过神经网络进行前向计算,得到网络的输出值。
计算损失函数:根据网络的输出值和真实值计算损失函数,衡量网络性能的好坏。 - 反向传播:根据损失函数计算梯度信息,通过反向传播算法将梯度信息从输出层逐层传递到输入层。
- 更新权重:根据梯度信息更新网络中的权重参数,使得网络的输出逐渐接近真实值。
在训练过程中,通常需要使用优化算法来加速训练过程并防止过拟合。常见的优化算法包括随机梯度下降(SGD)、动量法(Momentum)、Adam等。
🚆神经网络的应用实例

神经网络在各个领域都有广泛的应用,以下列举几个典型的实例:
🚲图像识别
卷积神经网络在图像识别领域取得了显著成果。例如,通过训练大量的图像数据,神经网络可以实现对各种物体的准确识别,如人脸识别、车辆识别等。
基于MNIST手写数字数据集的神经网络,使用TensorFlow和Keras
示例代码:
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D # 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data() # 数据预处理:归一化到0-1之间,并reshape以适应卷积层
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype('float32') / 255
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1).astype('float32') / 255 # 将类别标签转换为one-hot编码
y_train = tf.keras.utils.to_categorical(y_train, 10)
y_test = tf.keras.utils.to_categorical(y_test, 10) # 构建卷积神经网络模型
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax')) # 编译模型
model.compile(loss=tf.keras.losses.categorical_crossentropy, optimizer=tf.keras.optimizers.Adadelta(), metrics=['accuracy']) # 训练模型
model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1, validation_data=(x_test, y_test)) # 评估模型
score = model.evaluate(x_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
🚗自然语言处理

循环神经网络和注意力机制的结合在自然语言处理领域具有广泛应用。例如,通过训练文本数据,神经网络可以实现文本分类、情感分析、机器翻译等功能。
基于文本分类的神经网络,使用PyTorch和torchtext
注意:这个示例假设你已经有一个标记好的文本数据集,并且已经将其预处理
为适合神经网络输入的格式(如词嵌入向量)。
示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
from torchtext.legacy.data import Field, TabularDataset, BucketIterator # 定义文本字段和标签字段
TEXT = Field(sequential=True, tokenize='spacy', lower=True)
LABEL = Field(sequential=False, use_vocab=False) # 假设你有一个CSV文件,其中包含两列:'text'和'label'
data_fields = [('text', TEXT), ('label', LABEL)]
train_data, test_data = TabularDataset.splits( path='./data', train='train.csv', validation='test.csv', format='csv', skip_header=True, fields=data_fields
) # 构建词汇表
TEXT.build_vocab(train_data, max_size=10000, min_freq=1, vectors="glove.6B.100d", unk_init=torch.Tensor.normal_) # 迭代器设置
BATCH_SIZE = 64
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
train_iterator, test_iterator = BucketIterator.splits( (train_data, test_data), batch_size=BATCH_SIZE, device=device, sort_key=lambda x: len(x.text), sort_within_batch=False, repeat=False
) # 定义模型
class TextClassifier(
🛵推荐系统

神经网络在推荐系统中也发挥了重要作用。通过挖掘用户的历史行为和兴趣偏好,神经网络可以为用户推荐个性化的内容和服务,提高用户体验和满意度。
以下是一个简化的示例,展示了如何使用深度学习模型(如多层感知机,MLP)在基于用户-项目评分的推荐系统中进行预测。
请注意,由于推荐系统通常涉及大量数据和复杂的预处理步骤,这个示例将非常简化,并假设您已经有一些预处理过的数据。
示例代码(使用PyTorch)
首先,我们需要安装PyTorch(如果尚未安装):
pip install torch
import torch
import torch.nn as nn
import torch.optim as optim # 假设我们有以下用户-项目评分数据(非常简化)
# 用户ID(0-based index),项目ID(0-based index),评分(1-5)
ratings = [ (0, 0, 5), (0, 1, 3), (1, 0, 4), # ... 更多数据
] # 预处理数据(这里省略,通常包括one-hot编码、嵌入、归一化等)
# 假设我们已经有了用户嵌入和项目嵌入 # 神经网络模型定义
class RatingPredictor(nn.Module): def __init__(self, user_embedding_dim, item_embedding_dim, hidden_dim): super(RatingPredictor, self).__init__() self.user_embedding = nn.Embedding(num_embeddings=num_users, embedding_dim=user_embedding_dim) self.item_embedding = nn.Embedding(num_embeddings=num_items, embedding_dim=item_embedding_dim) self.fc = nn.Sequential( nn.Linear(user_embedding_dim + item_embedding_dim, hidden_dim), nn.ReLU(), nn.Linear(hidden_dim, 1) # 输出评分,假设已经归一化到[0, 1] ) def forward(self, user_idx, item_idx): user_emb = self.user_embedding(user_idx) item_emb = self.item_embedding(item_idx) combined = torch.cat([user_emb.squeeze(1), item_emb.squeeze(1)], 1) # 合并嵌入 return self.fc(combined).squeeze(1) # 输出评分预测 # 假设参数
num_users = 100 # 假设有100个用户
num_items = 200 # 假设有200个项目
user_embedding_dim = 10
item_embedding_dim = 10
hidden_dim = 50 # 实例化模型
model = RatingPredictor(user_embedding_dim, item_embedding_dim, hidden_dim) # 定义损失函数和优化器
criterion = nn.MSELoss() # 假设评分已经归一化到[0, 1],使用均方误差损失
optimizer = optim.Adam(model.parameters(), lr=0.001) # 假设我们有一些训练数据(user_indices, item_indices, ratings)
# 这里我们只是模拟一些数据
user_indices = torch.tensor([0, 0, 1], dtype=torch.long)
item_indices = torch.tensor([0, 1, 0], dtype=torch.long)
ratings_tensor = torch.tensor([0.9, 0.6, 0.8], dtype=torch.float) # 假设评分已经归一化 # 训练循环(这里只迭代一次作为示例)
for epoch in range(1): # 通常会有多个epoch # 前向传播 predicted_ratings = model(user_indices, item_indices) # 计算损失 loss = criterion(predicted_ratings, ratings_tensor) # 反向传播和优化 optimizer.zero_grad() loss.backward() optimizer.step() # 打印统计信息(这里只打印损失) print(f'Epoch [{epoch+1}/{1}], Loss: {loss.item():.4f}') # 现在模型已经训练过了,可以使用它来进行预测
# 例如,预测用户0对项目2的评分
user_idx = torch.tensor([0], dtype=torch.long)
item_idx = torch.tensor([2], dtype=torch.long)
predicted_rating = model(user_idx,
💖未来发展趋势

机器学习神经网络,特别是深度学习中的神经网络,已经取得了令人瞩目的成就,并在多个领域产生了深远的影响。机器学习神经网络未来发展有以下几点:
1. 更强大的网络架构:
随着研究的深入,我们期望看到更强大、更有效的神经网络架构。这些网络可能会引入新的层类型、激活函数或正则化策略,以进一步提高模型的性能。
神经网络架构的搜索(Neural Architecture Search, NAS)技术将继续发展,自动发现和优化网络结构,减少人工设计的需要。
2. 处理更大规模和更复杂的数据:
随着数据生成速度的加快和数据规模的扩大,我们期望神经网络能够处理更大规模和更复杂的数据集。这需要开发更高效的训练算法和更大的计算资源。
同时,我们也期望看到针对特定数据类型(如图像、文本、视频、时间序列等)的专用神经网络架构的出现。
3. 更高的可解释性和鲁棒性:
尽管神经网络在许多任务上取得了显著的性能提升,但它们的决策过程通常难以解释。我们期望未来能够开发出更具可解释性的神经网络模型,使人类能够理解并信任它们的预测结果。
神经网络的鲁棒性也是一个重要的问题。我们期望未来的神经网络能够更好地应对噪声、异常值和对抗性攻击,从而提高其在实际应用中的稳定性和可靠性。
4. 更广泛的应用场景:
随着技术的成熟和应用场景的不断拓展,我们期望神经网络能够在更多领域发挥重要作用。例如,在医疗诊断、自动驾驶、金融分析、教育等领域,神经网络都有巨大的应用潜力。
同时,我们也期望看到神经网络与其他技术的融合,如强化学习、自然语言处理、计算机视觉等,以创造出更加智能和复杂的系统。
5. 硬件与软件的协同优化:
神经网络的训练和推理需要大量的计算资源。我们期望未来能够开发出更加高效和节能的硬件加速器,如专用芯片(ASICs)、图形处理器(GPUs)和现场可编程门阵列(FPGAs)等,以支持神经网络的快速训练和推理。
在软件方面,我们期望能够开发出更加高效和灵活的深度学习框架和库,以支持神经网络的开发、训练和部署。
6. 持续的学习和改进:
神经网络是一个不断发展的领域,我们期望能够持续不断地学习和改进。这包括学习新的理论、方法和工具,以及不断挑战和突破现有的技术边界。
我们也期望看到更多的跨领域合作和开放研究,以推动神经网络技术的持续发展和创新。
💖结语
神经网络作为机器学习的重要分支,在人工智能领域具有广泛的应用前景。随着计算能力的提升和算法的优化,神经网络的性能将不断提升,应用领域也将不断扩展。未来,神经网络将在更多领域发挥重要作用,推动人工智能技术的持续发展。
相关文章:
【机器学习】解锁AI密码:神经网络算法详解与前沿探索
👀传送门👀 🔍引言🍀神经网络的基本原理🚀神经网络的结构📕神经网络的训练过程🚆神经网络的应用实例💖未来发展趋势💖结语 🔍引言 随着人工智能技术的飞速发…...
Java如何实现pdf转base64以及怎么反转?
问题需求 今天在做发送邮件功能的时候,发现邮件的附件部分,比如pdf文档,要求先把pdf转为base64,邮件才会发送。那接下来就先看看Java 如何把 pdf文档转为base64。 两种方式,一种是通过插件 jar 包的方式引入…...

动态规划5:62. 不同路径
动态规划解题步骤: 1.确定状态表示:dp[i]是什么 2.确定状态转移方程:dp[i]等于什么 3.初始化:确保状态转移方程不越界 4.确定填表顺序:根据状态转移方程即可确定填表顺序 5.确定返回值 题目链接:62. …...
-列表(List))
Python编程学习第一篇——Python零基础快速入门(五)-列表(List)
今天我们来一起学习Python的列表(list),Python中的列表(List)是一种有序、可变的数据结构,可以用来存储多个值。列表可以包含不同类型的数据,例如整数、浮点数、字符串等。以下是关于Python列表…...

c# - 运算符 << 不能应用于 long 和 long 类型的操作数
Compiler Error CS0019 c# - 运算符 << 不能应用于 long 和 long 类型的操作数 处理方法 特此记录 anlog 2024年5月30日...
)
问题排查|记录一次基于mymuduo库开发的服务器错误排查(回响服务器无法正常工作)
问题背景: 服务器程序如下: #include <mymuduo/TcpServer.h> #include <mymuduo/Logger.h>#include <string> #include <functional>class EchoServer { public:EchoServer(EventLoop *loop,const InetAddress &addr, con…...

中介模式实现聊天室
中介者模式的核心逻辑就是解耦对象‘多对多’的相互依赖关系。当遇到一大堆混乱的对象呈现“网状结构”,利用通过中介者模式解耦对象之间的通讯。 代码案例 抽象中介类 public abstract class AbstractChatRoom {public abstract void notice(String message , Us…...

游戏开发与游戏设计区别
游戏设计与游戏开发是两个紧密相关但有着不同重点的领域,通常需要不同的技能和流程。以下是对游戏设计与游戏开发的详细解释,以及两者的区别: 游戏设计是关于构思和规划游戏的内容、机制和体验的过程。 主要内容: 故事和情节:构…...
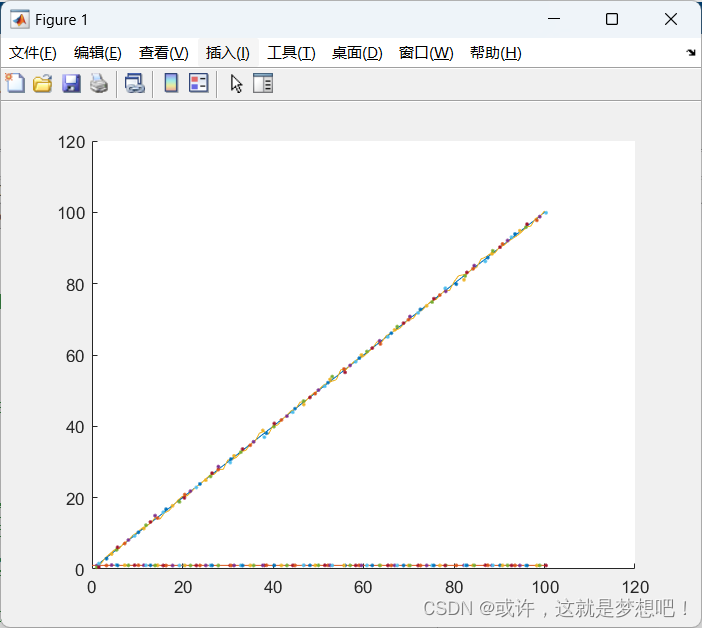
卡尔曼滤波算法的matlab实现
卡尔曼滤波算法的matlab实现 figure; hold on;Z(1:1:100); %观测值:第一秒观测1m 第二秒观测两米 匀速运动, 每秒1m, 最后拟合的也是速度 1m/splot(Z); plot([0,100], [1,1]);noiserandn(1,100)*0.5; %生成方差为1的高斯噪声 ZZnoise; % 加入噪声plot(Z);X[0;…...
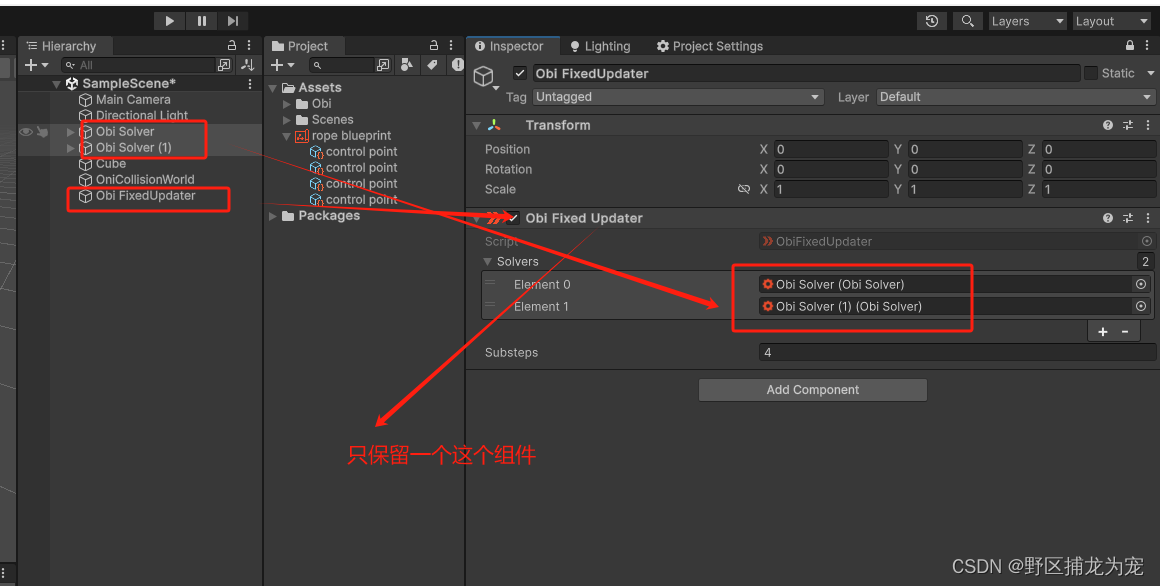
Unity Obi Rope失效
文章目录 前言一、WebGL端Obi Rope失效二、Obi Rope 固定不牢三、使用Obi后卡顿总结 前言 Obi 是一款基于粒子的高级物理引擎,可模拟各种可变形材料的行为。 使用 Obi Rope,你可以在几秒内创建绳索和杆子,同时完全控制它们的形状和行为&…...
基于Nginx和Consul构建自动发现的Docker服务架构——非常之详细
基于Nginx和Consul构建自动发现的Docker服务架构 文章目录 基于Nginx和Consul构建自动发现的Docker服务架构资源列表基础环境一、安装Docker1.1、Consul节点安装1.2、registrator节点安装 二、案例前知识点2.1、什么是Consul 三、基于Nginx和Consul构建自动发现的Docker服务架构…...

Gnu/Linux 系统编程 - 如何获取帮助及一个演示
Gnu/Linux 系统编程 - 如何获取帮助及一个演示 今天开始写 Gnu/Linux 环境下的系统编程,主要的用的语言是 C,主要是为了学习 C 语言,边学边写,这样的学习速度是比较快的。 今天就先介绍下如何在手头上没有任何资料的情况下&…...

ffmpeg 的sws_scale接口函数解析
ffmpeg 的 sws_scale 函数是 libswscale 库中的一个重要函数,用于进行图像的缩放和颜色空间转换。它的主要作用是将输入图像帧转换为另一种尺寸或颜色格式的输出图像帧。下面详细解析一下 sws_scale 函数的作用、参数等。 sws_scale 函数的作用 ffmpeg 的 sws_sca…...

MoonBit 本周新增类型标注语法、继续进行核心库 API 整理工作
MoonBit更新 类型标注增加了新的语法T? 来表示Option[T] struct Cell[T] {val: Tnext: Cell[T]? }fn f(x : Cell[T]?) -> Unit { ... }相当于 struct Cell[T] {val: Tnext: Option[Cell[T]] }fn f(x : Option[Cell[T]]) -> Unit { ... }旧的Option[T]仍然兼容&…...

YOLOv10训练自己的数据集
目录 0、引言 1、环境配置 2、数据集准备 3、创建配置文件 3.1、设置官方配置文件:default.yaml,可自行修改。 3.2、设置data.yaml 4、进行训练 4.1、方法一 4.2、方法二 5、验证模型 5.1、命令行输入 5.2、脚本运行 6、总结 0、引言 本文…...

探索Web前端三大主流框架:Angular、React和Vue.js
探索Web前端三大主流框架:Angular、React和Vue.js 在现代Web开发中,前端框架已经成为开发者构建复杂应用的重要工具。Angular、React和Vue.js是目前最受欢迎的三大前端框架,它们各具特色,适用于不同的开发需求。本文将详细介绍这…...
《HelloGitHub》第 98 期
兴趣是最好的老师,HelloGitHub 让你对编程感兴趣! 简介 HelloGitHub 分享 GitHub 上有趣、入门级的开源项目。 github.com/521xueweihan/HelloGitHub 这里有实战项目、入门教程、黑科技、开源书籍、大厂开源项目等,涵盖多种编程语言 Python、…...
Xtransfer面试内容
一、Xtransfer一轮面试内容 1.进程间的通信方式 2.redis的故障转移是如何选举主节点的 3.redis快的原因 4.redis、ES、mysql选型的场景 5.redis项目的挑战和难点 6.redis和ZK各自的应用场景 7.ZK选举的算法 8.socket建立连接的过程,与TCP是一回事吗? So…...
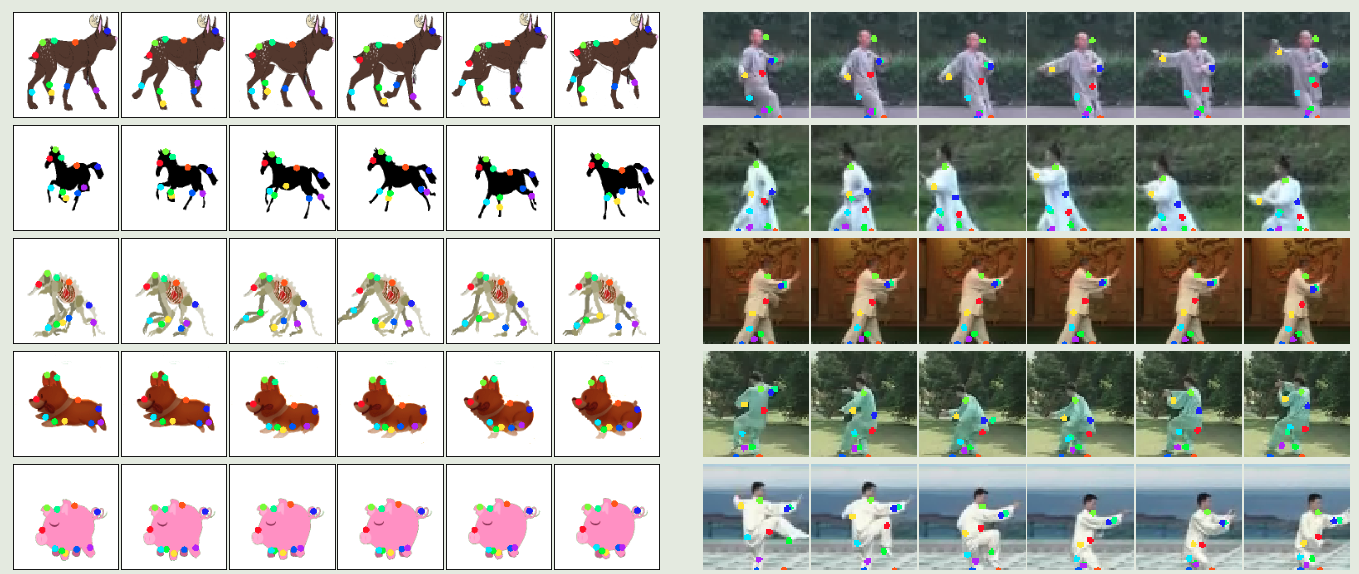
论文笔记:Image Anaimation经典论文-运动关键点模型(Monkey-Net)
Monkey-Net(MOviNg KEYpoints) paper: https://arxiv.org/pdf/1812.08861, CVPR 2019 code: https://github.com/AliaksandrSiarohin/monkey-net/tree/master 相关工作 视频生成演变过程: spatio-temporal network: 如基于GAN网络的生成模…...
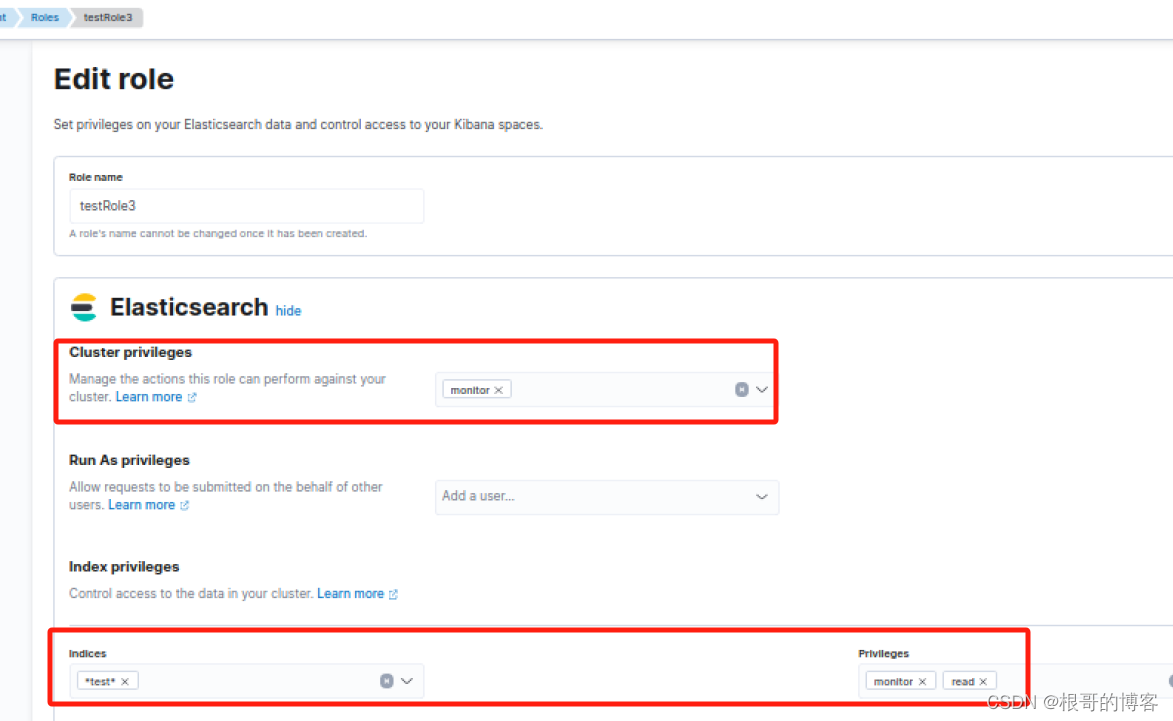
Kibana创建ElasticSearch 用户角色
文章目录 1, ES 权限参考2, 某应用的管理员权限:可以open/close/delete/cat/read/write 索引3, 某应用的读写权限:可以cat/read/write 索引 (不能删除索引或数据)4, 某应用的只读权限 1, ES 权限参考 https://www.elastic.co/gui…...

拆解RTX4090 24G GPU服务器,一文摸清硬件搭配逻辑
RTX4090 24G GPU凭借NVIDIA Ada Lovelace架构优势,以16384个CUDA核心、24GB GDDR6X显存、1008GB/s显存带宽的核心参数,成为个人开发者、中小企业、科研机构的首选算力核心,广泛应用于大模型训练、AI推理、工业仿真、视频渲染等场景。据IDC 20…...

完整B站字幕提取解决方案:三步搞定视频字幕获取与转换
完整B站字幕提取解决方案:三步搞定视频字幕获取与转换 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 你是否曾经在B站看到精彩的教学视频,…...

3大核心功能:智慧树网课自动化学习解决方案
3大核心功能:智慧树网课自动化学习解决方案 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 诊断学习痛点 在线教育平台在提供便利的同时,也带来…...

小白也能玩转大模型!Llama Factory免代码训练平台入门
小白也能玩转大模型!Llama Factory免代码训练平台入门 1. 什么是Llama Factory? 想象一下,你有一个智能助手,但它总是回答一些不太符合你需求的内容。这时候,你就需要"教"它变得更懂你——这就是大模型微调…...
、接收信号合成、时频分析、多算法定位【含Matlab源码 15278期】)
【无人机定位】无人机跳频信号 TDOA 定位仿真系统,信号生成(跳频、时延、衰减、噪声)、接收信号合成、时频分析、多算法定位【含Matlab源码 15278期】
💥💥💥💥💥💥💥💥💞💞💞💞💞💞💞💞💞Matlab武动乾坤博客之家💞…...

自动控制原理实验四:基于MATLAB/Simulink的系统频率特性分析与可视化
1. 实验背景与核心概念 频率特性分析是自动控制领域最实用的工具之一,它就像给系统做"心电图"——通过不同频率的输入信号,观察系统的"心跳反应"。我在工业现场调试时,经常用这种方法快速判断系统稳定性。这次我们要用M…...

Ostrakon-VL-8B实战教程:用Gradio替代Streamlit构建像素风新UI
Ostrakon-VL-8B实战教程:用Gradio替代Streamlit构建像素风新UI 1. 项目背景与目标 1.1 为什么选择Gradio替代Streamlit 在零售与餐饮场景的AI应用中,传统的工业级UI往往显得过于严肃和复杂。我们基于Ostrakon-VL-8B多模态大模型开发了一个全新的交互终…...

Vue3路由缓存优化指南:用keep-alive的include+max实现淘宝级页面保活
Vue3路由缓存优化实战:电商场景下的keep-alive高阶用法 电商平台的商品详情页与列表页频繁切换时,页面重载导致的性能损耗直接影响用户体验。去年双十一大促期间,某头部电商平台通过优化路由缓存策略,将页面切换速度提升了47%&…...

昆明波纹管供应商哪个好
在市政排水、农田灌溉、通信保护等工程领域,HDPE双壁波纹管因其优异的环刚度、耐腐蚀性和施工便捷性,已成为不可或缺的关键建材。然而,面对市场上琳琅满目的供应商,尤其是在地质气候条件独特的西南地区,如何选择一个真…...
)
终极指南:如何使用Ohm构建JavaScript解释器(10个完整步骤)
终极指南:如何使用Ohm构建JavaScript解释器(10个完整步骤) 【免费下载链接】ohm A library and language for building parsers, interpreters, compilers, etc. 项目地址: https://gitcode.com/gh_mirrors/oh/ohm Ohm是一个强大的解析…...