python的DataFrame和Series
Series、DataFrame
-
创建
pd.Series()
pd.DataFrame() # 字典{'列名':[值1,值2],} [[]] [()]
numpy Pandas的底层的数据结构,就是numpy的数组 ndarray
-
常用属性
-
shape (行数,) (行数,列数)
-
values → ndarray
-
index 索引名
-
size
-
columns 列名
-
-
常用方法
-
head() tail()
-
统计方法
-
describe()
-
min() max() mean() std() median() count()
-
-
修改数据的 inplace
-
drop_duplicates() 去重
-
sort_values() 排序
-
-
unique()
-
dataframe info() 返回相关的信息
-
-
布尔值列表做数据筛选 类似于SQL的where条件
-
df[ []]
-
多个条件进行筛选, 每个条件要使用() 包裹起来, 要是用 & | 。 不能使用 and or
-
-
Series、DataFrame 进行计算
-
行索引相同的会在一起进行计算, 找不到相同索引的行, 返回NaN
-
数值型的列和 数值的常量进行计算 , 不需要遍历的
-
数据的保存和加载
-
df.to_XXX
-
自动添加的行索引, 如果不想保存 index = False
-
-
pd.read_XXX
1 DataFrame查询数据操作
获取数据的一列或多列
import pandas as pd
df = pd.read_csv('data/LJdata.csv')
# 两种写法都可以获取数据中的一列
df['区域'] # 推荐这种写法 返回Series 获取的Series 会有一个name属性, 这个属性中会保存的是df的列名信息
df.区域 # 当列名比较特殊的时候, 和一些方法、属性的名字冲突, 得到的结果会想的不一样, 不会返回这一列数据
获取多列, [列名的列表]
df[['区域','价格']] # 如果列表里只有一个元素, 返回的也是一个dataframe
df.loc
-
loc 是属性 后面接[] 来获取df中的部分数据
-
loc[] []传入的是 行, 列名字, 不是编号
df.loc[0] df.[ 行名处理, 列名处理] df.loc[[2,4,6],['区域','价格']]
-
loc 支持切片, loc切片操作两边都是闭区间
df.loc[:3,:'朝向']
行名 3之前,包含3, 列名在朝向之前, 包含朝向, 返回对应的数据
df.iloc
-
iloc 是属性 后面接[] 来获取df中的部分数据
-
iloc [] []传入的是 行, 列编号, 不是名字
df.iloc[0,0] # 获取的是第0行,第0列 格里的数据 df.iloc[:2,:3] # iloc 切片 左闭右开 df.iloc[[0,1,2],[1,2,3]] # 获取第0,1,2行, 第1,2,3列数据
query方法
-
类似于SQL的where 条件 , 传入的条件是一个字符串
- 区域是望京租房的数据查询出来
df[df['区域']=='望京租房'].head()
df.loc[df['区域']=='望京租房'].head()
df.query('区域=="望京租房"').head()
query函数, 传入条件字符串, 条件中又包含了字符串,需要注意字符串 引号闭合的顺序
-
使用query传入多个条件
df.query('区域 in ["望京租房","回龙观租房"] and 朝向 in ["东","南"]')
多个条件在一起拼的时候要是用and or 而不是 & |
isin方法 在某个数据范围内
通过 df.isin(values=[值1, 值2, ...]) 判断df中的数据值是否在values列表值中, 返回由布尔值构成的新df
原df中数据值在values列表中返回True, 否则返回False
-
区域是望京租房的数据查询出来
df['区域'].isin(['望京租房','回龙观租房']) # 多个isin 用 & | 来拼接 df[(df['区域'].isin(['望京租房','回龙观租房'])) & (df['朝向'].isin(['西南 东北','南 北'])) ]
2 DataFrame增删改数据
2.1 增加一列数据
两种方法
-
df['新列名'] = ’新值‘ df['新列名'] = series_新值
-
df.insert(loc = 插入的位置编号 ,column ='新列名' ,value = 要插入的值)
-
区别,insert可以指定插入的位置编号, df['新列名'] = ’新值‘ 插入的新列在df的最后
import pandas as pd
df = pd.read_csv('data/LJdata.csv')
df_head = df.head() # 取出前五条并保存
df_head['省份']='北京' # 每一行都会赋值为 北京
df_head['区县'] = ['朝阳区','朝阳区','西城区','昌平区','朝阳区'] # 传入列表长度和df长度必须一致
insert
df.insert(loc=,column=,value=) - loc 插入的列的序号 - column 插入列的列名 - value 插入这一列具体的取值 df_head2.insert(0,column='省份',value='北京')
需要注意, insert 是我们课程中涉及到的唯一一个修改数据, 直接在原始数据上修改的api
其它修改数据的api 比如排序, 去重, 等都会有一个inplace参数 默认是False 默认会复制一份数据,在副本上修改, 这个insert不会
2.2 删除一列、一行数据
drop方法 默认是按行删除
-
axis 很多操作数据的方法, 既可以按行,也可以按列,比如删除, 比如 求和 求平均, 这一列方法都会有一个参数 axis 默认值是0 可选值是0,1
-
inplace = 默认False 改成True会在原来的数据上进行删除
df_head.drop('省份',axis=1,inplace=True)
2.3 数据去重 drop_duplicates()
df_head3.drop_duplicates(subset=['户型','朝向']) df_head3.drop_duplicates(subset=['户型','朝向'],keep='last',inplace=True) df_head3.drop_duplicates(subset=['户型','朝向'],keep='last',ignore_index=True)
subset 传入列名的列表, 用来做重复判断的条件
keep = 默认是first 满足重复条件的数据, 保留第一次出现的, 还可以选last 保留最后一次出现的
ignore_index = 默认是False 去重后会保留原来的索引, 改成True之后, 会重新给从0开始的索引
inplace
2.4 修改数据 直接修改和replace替换
如果只修改一个, 或者一列值整体替换, 可以用直接修改的方式
df.loc[0,’朝向‘] = ’东 北‘ 直接找到位置修改 df_head3['价格'] = [4800,5800,6800,7800,8800]
如果要批量替换某个值, 可以用replace方法
df_head3.replace(to_replace='东',value='北')
to_replace = 要被修改的值
value = 修改后的值
注意 to_replace 在dataframe中如果不存在, 代码不会报错, 什么都不会发生
inplace
2.5 series的apply方法 使用自定函数修改数据
apply 使用的场景, 修改的逻辑相对复杂, 使用自带的API不能满足需求
def func(x):print(x)if x=='天通苑租房':return '昌平区'else:return x # 遍历 区域这一列, 每遍历一条数据就会调用一次 func 把每个值传递给func函数 func函数的返回值 作为 apply的结果, 返回的还是Series s = df_head3['区域'].apply(func)
apply 可以传递出了 series值其它参数, 但是传参必须从第二个参数开始
df_head3 = df.head().copy() def func(x,arg1,arg2):print(x)if x=='天通苑租房':return arg1else:return arg2 df_head3['区域'].apply(func,args=['昌平区','其它区'])
2.6 DataFrame的apply方法 使用自定函数修改数据
df.apply(func , axis = 默认值0)
-
默认会传入每一列的series 对象, 如果数据有5列, func就会被调用5次 ,每次传入一列series对象
-
axis = 1 会传入每一行的Series对象, 如果数据有10行, func就会被调用10次, 每次传入一行的series对象
def func1(x):return x['价格']/x['面积'] df_head3 = df.head().copy() df_head3.apply(func1,axis=1)
df.apply() 传入自定义函数的时候,函数也可以接受额外的参数
def func2(x,arg1):# print(x)if x['区域']=='天通苑租房':x['价格'] = x['价格']+arg1return x df_head3.apply(func2,axis=1,args=[2000])
传参 args 一定是列表
2.7 df的applymap方法 (了解)
applymap 会遍历每一个格的数据, 一个一个数据取出来, 交给自定义函数处理
def func3(x):if x=='2室1厅':return '3室1厅'else:return x df_head3.applymap(func3)
遍历df中所有的数据, 如果值是'2室1厅'修改成3室一厅
3 对行列名字的修改
行索引 s.index df.index
列名(列索引) df.columns
要修改行、列名字,可以直接修改
-
s.index = [] df.index = []
-
df.columns = []
-
s.index[0] = 新值 这种修改方式不支持
修改行列名字的API 三个方法 , 都有Inplace参数
-
df.set_index(列名) 可以设置一列, 作为新的行索引
-
df.reset_index() 重置索引, 设置成从0开始的整数编号索引, 原来的索引会变成一列数据
-
df.rename()
-
可以修改指定取值的行索引, 列名
-
df.rename(index = {'老值':'新值'},columns={'老值':'新值'})
-
注意 rename和之前replace类似, 如果老值没有找到, 不会报错, 代码正常运行,只不过什么都不会发生
-
4 pandas操作Mysql
-
导包创建连接
from sqlalchemy import create_engine
engine = create_engine('mysql+pymysql://root:root12345@localhost:3306/test1?charset=utf8')
'mysql+pymysql://用户名:密码@mysql服务IP地址:3306/数据库名字?charset=utf8'
-
写入数据到Mysql
student.to_sql('student', con=engine, if_exists='append', index=False)
-
从Mysql读取数据
pd.read_sql(sql='student', con=engine.connect(),columns=['id','name','age'])
讲义上写的是engine, 这里由于版本的问题, 需要使用engine.connect()
相关文章:

python的DataFrame和Series
Series、DataFrame 创建 pd.Series() pd.DataFrame() # 字典{列名:[值1,值2],} [[]] [()] numpy Pandas的底层的数据结构,就是numpy的数组 ndarray 常用属性 shape (行数,) (行数,列数) values → ndarray index 索引名 siz…...
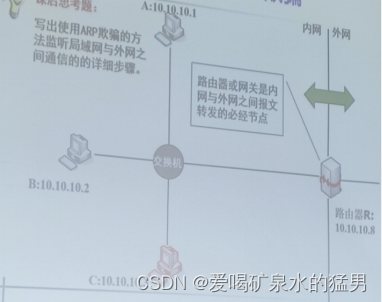
ARP欺骗的原理与详细步骤
ARP是什么: 我还记得在计算机网络课程当中,学过ARP协议,ARP是地址转换协议,是链路层的协议,是硬件与上层之间的接口,同时对上层提供服务。在局域网中主机与主机之间不能直接通过IP地址进行通信,…...

25、DHCP FTP
DHCP 动态主机配置协议 DHCP定义: 服务器配置好了地址池 192.168.233.10 192.168.233.20 客户端从地址池当中随机获取一个ip地址,ip地址会发生变化,使用服务端提供的ip地址,时间限制,重启之后也会更换。 DHCP优点&a…...

spark学习记录-spark基础概念
背景需求 公司有项目需要将大容量数据进行迁移,经过讨论,采用spark框架进行同步、转换、解析、入库。故此,这里学习spark的一些基本的概念知识。 Apache Spark 是一个开源的大数据处理框架,可以用于高效地处理和分析大规模的数据…...

BGP数据包+工作过程
BGP数据包 基于 TCP的179端口工作;故BGP协议中所有的数据包均需要在tcp 会话建立后; 基于TCP的会话来进行传输及可靠性的保障; 首先通过TCP的三次握手来寻找到邻居; Open 仅负责邻居关系的建立,正常进收发一次即可;携带route-id; Keepli…...
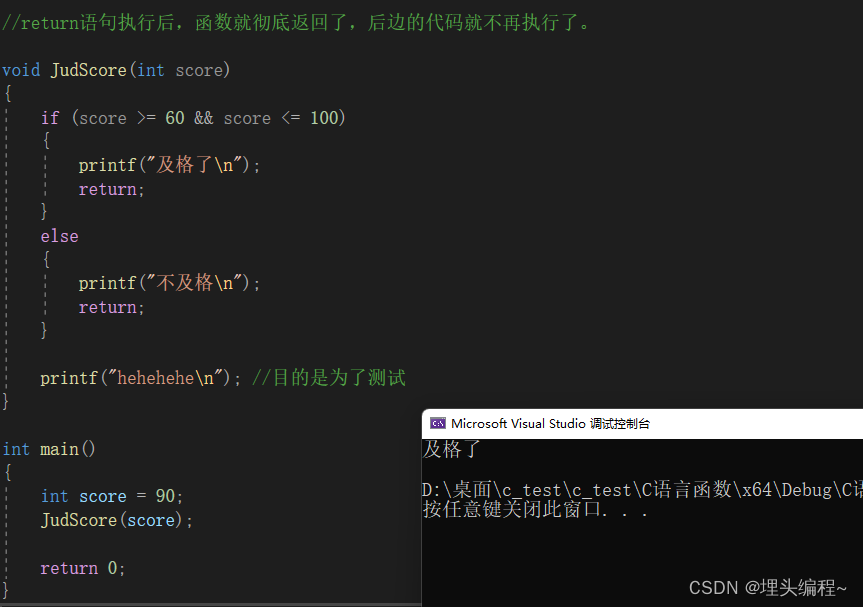
【C语言】详解函数(庖丁解牛版)
文章目录 1. 前言2. 函数的概念3.库函数3.1 标准库和头文件3.2 库函数的使用3.2.1 头文件的包含3.2.2 实践 4. 自定义函数4.1 自定义函数的语法形式4.2 函数的举例 5. 形参和实参5.1 实参5.2 形参5.3 实参和形参的关系 6. return 语句6. 总结 1. 前言 一讲到函数这块ÿ…...

createAsyncThunk完整用法介绍
createAsyncThunk 是 Redux Toolkit 库中的一个功能,它用于创建处理异步逻辑的 thunk action creator。Redux Toolkit 是一个官方推荐的库,用于简化 Redux 开发过程,特别是处理常见的 Redux 模式,如异步数据流。createAsyncThunk …...

[书生·浦语大模型实战营]——第六节 Lagent AgentLego 智能体应用搭建
1. 概述和前期准备 1.1 Lagent是什么 Lagent 是一个轻量级开源智能体框架,旨在让用户可以高效地构建基于大语言模型的智能体。同时它也提供了一些典型工具以增强大语言模型的能力。 Lagent 目前已经支持了包括 AutoGPT、ReAct 等在内的多个经典智能体范式&#x…...
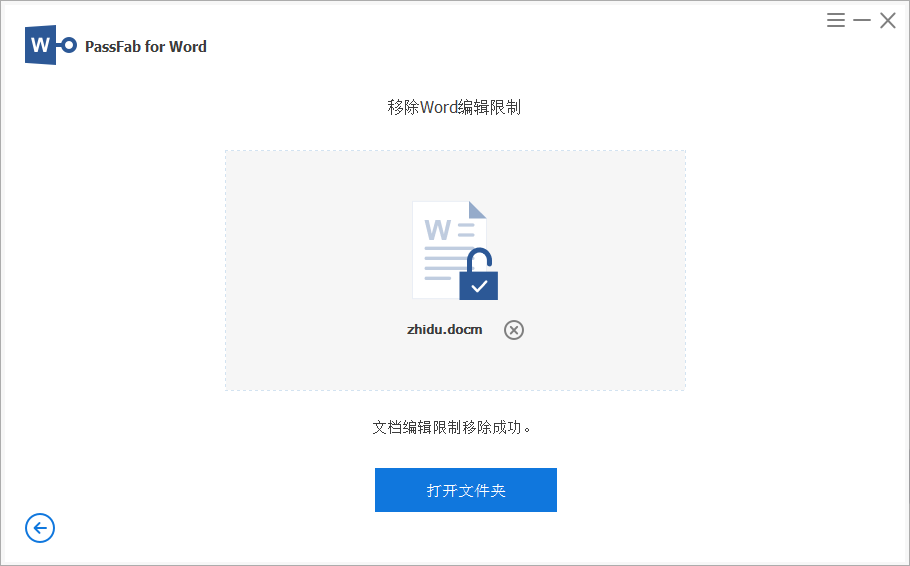
Word文档如何设置限制编辑和解除限制编辑操作
Word文档是大家经常使用的一款办公软件,但是有些文件内容可能需要进行加密保护,不过大家可能也不需要对word文件设置打开密码。只是需要限制一下编辑操作就可以了。今天和大家分享,如何对word文件设置编辑限制、以及如何取消word文档的编辑限…...
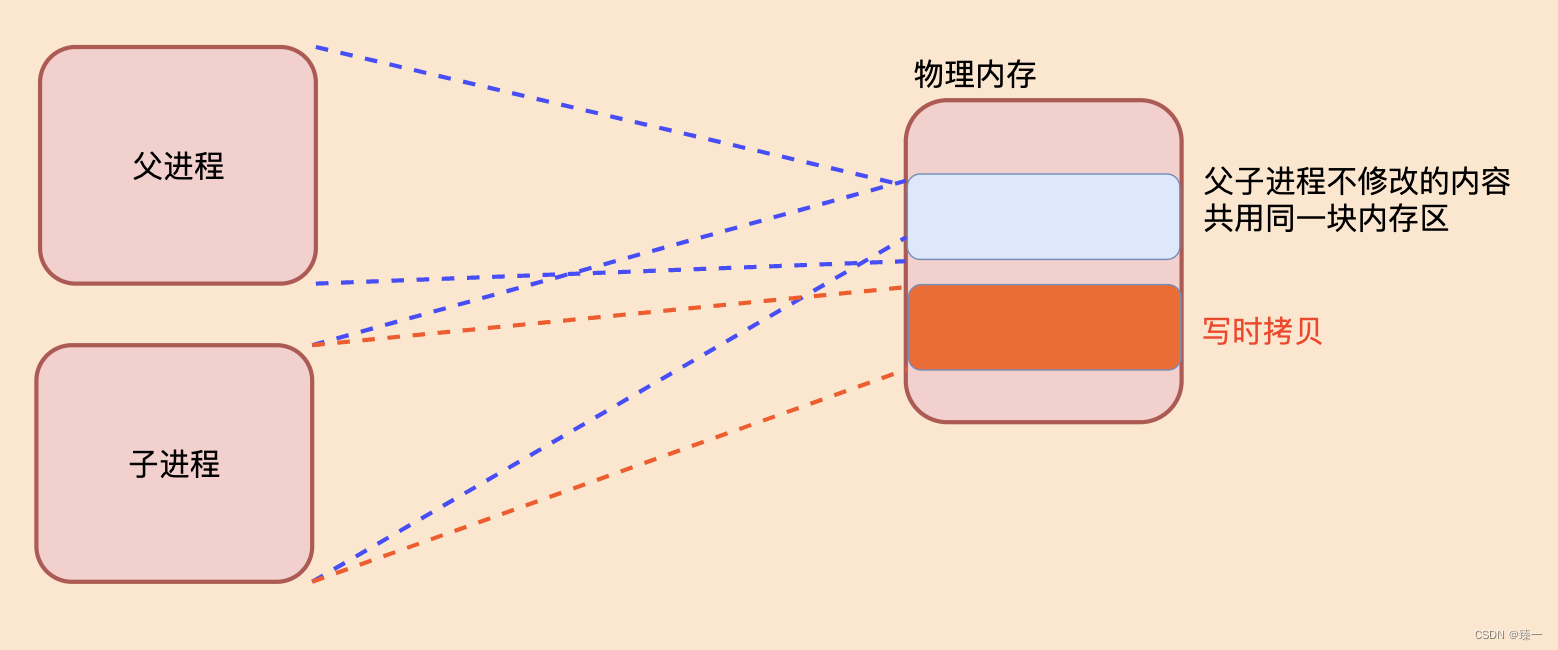
IO进程线程(六)进程
文章目录 一、进程状态(二)进程状态切换实例1. 实例1 二、进程的创建(一)原理(二)fork函数--创建进程1. 定义2. 不关注返回值3. 关注返回值 (三) 父子进程的执行顺序(四&…...

机器视觉——找到物块中心点
首先先介绍一下我用的是HALCON中的HDevelop软件。 大家下载好软件后可以测试一下: 在程序编辑器窗口中输入下面指令: read_image(Image,monkey) 那么如果出现这样的图片,说明是没有问题的 那么本次编程采用的是下面这张图片 我们要达到的…...

重磅消息! Stable Diffusion 3将于6月12日开源 2B 版本的模型,文中附候补注册链接。
在OpenAI发布Sora后,Stability AI也发布了其最新的模型Stabled Diffusion3, 之前的文章中已经和大家介绍过,感兴趣的小伙伴可以点击以下链接阅读。Sora是音视频方向,Stabled Diffusion3是图像生成方向,那么两者没有必然的联系&…...

Python报错:AttributeError: <unknown>.DeliveryStore 获取Outlook邮箱时报错
目录 报错提示: 现象描述 代码解释: 原因分析: 报错提示: in get_outlook_email return account.DeliveryStore.DisplayName line 106, in <module> email_address get_outlook_email() 现象描述 获取outlook本地邮箱…...
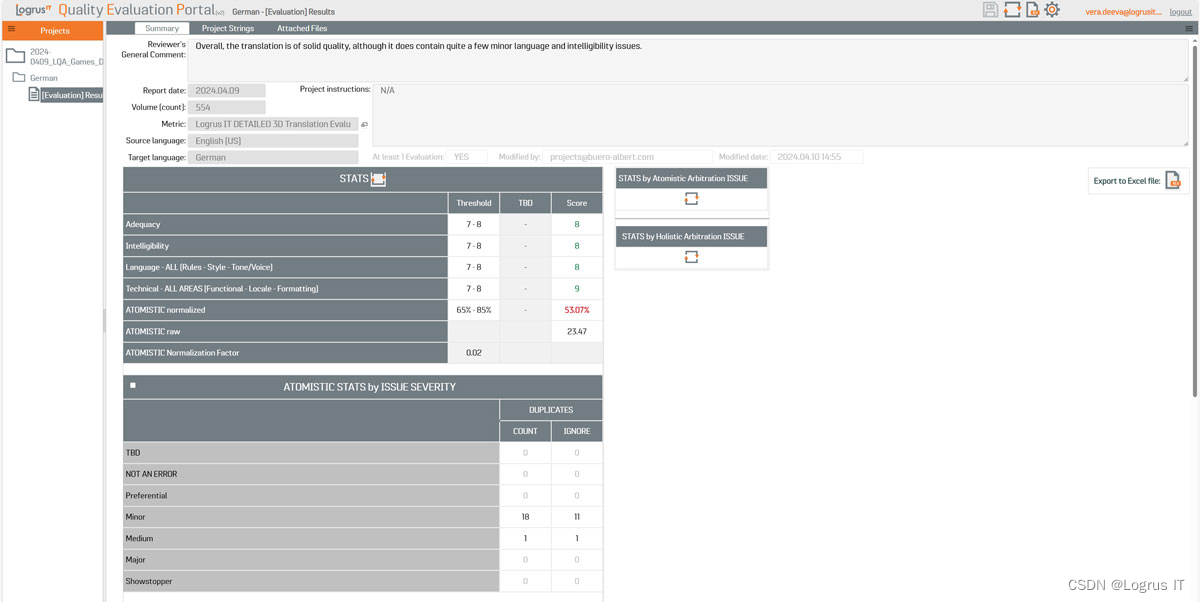
如何 Logrus IT 的质量评估门户帮助提升在线商店前端(案例研究)
在当今竞争激烈的电子商务环境中,一个运作良好的在线店面对商业成功至关重要。然而,确保目标受众获得积极的用户体验可能是一项挑战,尤其是在使用多种语言和平台时。Logrus IT的质量评估门户是一个强大的工具,可帮助企业简化内容和…...

程序调试
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 在程序开发过程中,免不了会出现一些错误,有语法方面的,也有逻辑方面的。对于语法方面的比较好检测,因…...
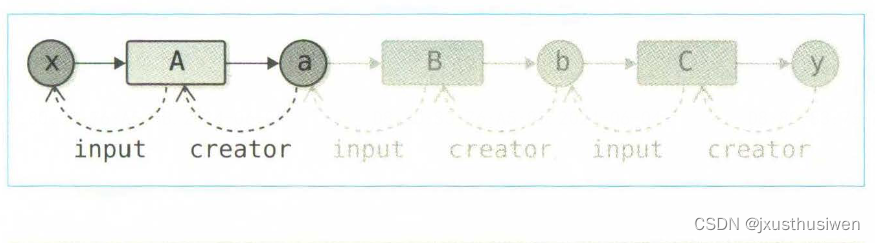
深度学习-07-反向传播的自动化
深度学习-07-反向传播的自动化 本文是《深度学习入门2-自製框架》 的学习笔记,记录自己学习心得,以及对重点知识的理解。如果内容对你有帮助,请支持正版,去购买正版书籍,支持正版书籍不仅是尊重作者的辛勤劳动…...

四川景源畅信:抖音做直播有哪些人气品类?
随着互联网科技的飞速发展,抖音作为新兴的社交媒体平台,已经成为了人们日常生活中不可或缺的一部分。而在抖音平台上,直播功能更是吸引了大量的用户和观众。那么,在抖音上做直播有哪些人气品类呢?接下来,就让我们一起…...

闲鱼无货源-高级班,最全·最新·最干,紧贴热点 深度学习(17节课)
课程目录 1-1:闲鱼潜规则_1.mp4 2-2:闲鱼的基础操作-养号篇_1.mp4 3-3:闲鱼实战运营-选品篇(一)_1.mp4 4-4:闲鱼实战运营-选图视频篇_1.mp4 5-5:闲鱼实战运营-标题筒_1.mp4 6-6࿱…...

力扣 739. 每日温度
题目来源:https://leetcode.cn/problems/daily-temperatures/description/ C题解:使用单调栈。栈里存放元素的索引,只要拿到索引就可以找到元素。 class Solution { public:vector<int> dailyTemperatures(vector<int>& tem…...

工业网关有效解决企业在数据采集、传输和整合方面的痛点问题-天拓四方
一、企业背景概述 随着信息技术的飞速发展,工业互联网已成为推动制造业转型升级的关键力量。在众多工业企业中,某公司凭借其深厚的技术积淀和广阔的市场布局,成为行业内的佼佼者。然而,在数字化转型的道路上,该公司也…...

GG3M贝叶斯决策数学体系:六大核心领域落地应用与差异化壁垒
GG3M贝叶斯决策数学体系:六大核心领域落地应用与差异化壁垒摘要 GG3M的贝叶斯更新与决策数学体系,基于原创“事实层—模型层—元模型层”三层级架构,以系统长期反熵增演化为核心决策标尺,从“智能参数优化”跨越至“智慧框架迭代”…...

LangChain + AgentRun 浏览器沙箱极简集成指南
AgentRun Browser Sandbox 介绍 什么是 Browser Sandbox? Browser Sandbox 是 AgentRun 平台提供的云原生无头浏览器沙箱服务,基于阿里云函数计算(FC)构建。它为智能体提供了一个安全隔离的浏览器执行环境,支持通过标准的 Chrome DevTools Protocol (…...
 - 搜索、分析和可视化,数据全面洞察平台)
Splunk Enterprise 10.2.2 (macOS, Linux, Windows) - 搜索、分析和可视化,数据全面洞察平台
Splunk Enterprise 10.2.2 (macOS, Linux, Windows) - 搜索、分析和可视化,数据全面洞察平台 Search, analysis, and visualization for actionable insights from all of your data 请访问原文链接:https://sysin.org/blog/splunk-10/ 查看最新版。原…...
)
自指宇宙学形式化验证套件 (Coq‑SRU v1.2.0)
自指宇宙学形式化验证套件 (Coq‑SRU v1.2.0)技术摘要 正式整编版 项目标识:Coq Formalization of Self‑Referential Universe (Coq‑SRU) 版本:v1.2.0(对齐《世毫九自指宇宙学》理论第三部分) 代码仓库:https://git…...

用ZYNQ PS-SPI给Flash测个速:华邦W25Q80在25MHz时钟下的真实读写性能报告
ZYNQ PS-SPI Flash性能深度评测:华邦W25Q80在25MHz时钟下的极限挖掘 当我们需要在嵌入式系统中选择一款Flash存储器时,数据手册上的理论参数往往无法反映真实应用场景下的性能表现。本文将基于Xilinx ZYNQ平台的PS-SPI接口,对华邦W25Q80 Flas…...

终极中文语义理解指南:text2vec-base-chinese如何让AI真正读懂中文
终极中文语义理解指南:text2vec-base-chinese如何让AI真正读懂中文 【免费下载链接】text2vec-base-chinese 项目地址: https://ai.gitcode.com/hf_mirrors/ai-gitcode/text2vec-base-chinese 还在为中文文本相似度计算而烦恼吗?text2vec-base-c…...

告别兼容性烦恼,让老旧应用在现代浏览器中“无缝”运行
在数字化转型的浪潮中,企业的技术架构往往承载着历史的痕迹。当我们享受着现代浏览器带来的极速体验与丰富扩展时,一个不容忽视的挑战正悄然影响着员工的工作效率与IT运维的平静——那就是“传统浏览器支持”问题。这并非一个遥不可及的技术概念…...
是如何被动态加载的)
深入ComfyUI插件系统:从启动流程看自定义节点(Custom Nodes)是如何被动态加载的
深入ComfyUI插件系统:从启动流程看自定义节点(Custom Nodes)是如何被动态加载的 在AIGC技术快速发展的今天,ComfyUI凭借其高度模块化的设计成为众多开发者的首选工具。对于想要深度定制工作流或开发专属插件的进阶开发者而言&…...

3个方法突破访问限制:Bypass Paywalls Clean让优质内容触手可及
3个方法突破访问限制:Bypass Paywalls Clean让优质内容触手可及 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 当一位医学研究员在凌晨三点急需查阅最新临床研究…...

厂房钢结构工程:从设计、制造到安装验收的关键要点全解析
一、什么是厂房钢结构工程,为什么越来越常见?厂房钢结构工程,简单说,就是以钢柱、钢梁、檩条、支撑体系、屋面系统和围护系统为主体,完成工业厂房、仓储车间、物流中心、生产车间及配套功能区建设的一类工程。相比传统…...