高效数据处理的前沿:【C++】、【Redis】、【人工智能】与【大数据】的深度整合

目录
1.为什么选择 C++ 和 Redis?
2.人工智能与大数据的背景
1.大数据的挑战
2.人工智能的需求
3.C++ 与 Redis 的完美结合
1.安装 Redis 和 Redis C++ 客户端
2.连接 Redis 并进行数据操作
高级数据操作
列表操作
哈希操作
4.与大数据和人工智能结合
5.实际应用案例分析
案例一:实时推荐系统
案例二:实时监控系统
进一步优化与扩展
性能优化
功能扩展
6.总结
在现代软件开发中,C++、人工智能、Redis和大数据已经成为不可或缺的技术元素。C++以其高性能和灵活性著称,广泛应用于系统编程和高性能计算。人工智能正在改变我们的生活方式,从自动驾驶汽车到智能助手,其应用无处不在。Redis作为一种内存数据结构存储,被广泛用于缓存、消息队列和实时数据处理。大数据技术则在处理和分析大量数据方面发挥着关键作用。
1.为什么选择 C++ 和 Redis?

C++ 作为一门高性能的编程语言,广泛应用于系统编程和大规模数据处理。它的主要优势在于:
- 性能:C++ 提供了对硬件的直接控制,能够实现高度优化的代码,特别是在需要高性能计算的场景下。
- 资源管理:通过 RAII(Resource Acquisition Is Initialization)等技术,C++ 能够高效地管理资源,避免内存泄漏等问题。
- 灵活性:C++ 支持面向对象编程、泛型编程和函数式编程,能够根据不同的需求选择最合适的编程范式。
Redis 是一个开源的内存数据结构存储系统,支持丰富的数据结构,如字符串、哈希、列表、集合等,常用于缓存、消息队列等场景。它的优势在于:
- 高性能:Redis 通过将数据存储在内存中,实现了极高的读写速度,适用于需要快速访问的数据。
- 多种数据结构:支持字符串、哈希、列表、集合、有序集合等多种数据结构,能够满足不同的应用需求。
- 简单易用:提供简单的命令行接口和丰富的客户端库,便于开发和维护。
将 C++ 与 Redis 结合,可以充分发挥两者的优势,实现高效的数据处理。
2.人工智能与大数据的背景
随着数据量的爆炸性增长,人工智能(AI)和大数据技术成为了处理和分析这些数据的关键手段。AI 依赖于大量数据进行训练和推理,而大数据技术则提供了存储和处理这些数据的工具。通过 C++ 和 Redis,我们可以构建高性能的系统来满足 AI 和大数据的需求。
1.大数据的挑战
在大数据时代,数据的规模、速度和多样性给传统的数据处理方法带来了巨大的挑战。主要挑战包括:
- 数据存储和管理:如何高效地存储和管理海量数据是一个关键问题。传统的关系型数据库在面对大规模数据时往往表现不佳。
- 数据处理速度:在需要实时处理的数据场景中,高效的数据处理速度至关重要。
- 数据分析和挖掘:如何从海量数据中提取有价值的信息,进行有效的分析和挖掘,是大数据技术的核心。
2.人工智能的需求
人工智能技术的核心在于算法和数据。随着深度学习和机器学习技术的发展,AI 对数据的需求越来越高。主要需求包括:
- 数据量:AI 模型的训练需要大量的数据,数据量越大,模型的性能通常越好。
- 数据质量:高质量的数据能够显著提升模型的准确性和鲁棒性。
- 数据访问速度:AI 训练过程中,需要频繁地访问和处理数据,因此数据的访问速度对整体性能有着重要影响。
3.C++ 与 Redis 的完美结合
通过结合 C++ 和 Redis,我们可以构建一个高效的数据处理系统,满足 AI 和大数据的需求。下面,我们通过具体的代码实例来展示如何实现这一目标。
1.安装 Redis 和 Redis C++ 客户端
首先,我们需要安装 Redis 服务器和 C++ Redis 客户端库。在 Ubuntu 上可以使用以下命令安装 Redis:
sudo apt-get update
sudo apt-get install redis-server
安装完成后,启动 Redis 服务器:
sudo service redis-server start
接下来,安装 C++ 的 Redis 客户端库,我们这里使用 hiredis:
sudo apt-get install libhiredis-dev
2.连接 Redis 并进行数据操作
接下来,我们编写一个简单的 C++ 程序,演示如何连接 Redis 并进行数据存储和检索。
#include <iostream>
#include <hiredis/hiredis.h>int main() {// 连接到 Redis 服务器redisContext *context = redisConnect("127.0.0.1", 6379);if (context == NULL || context->err) {if (context) {std::cerr << "Error: " << context->errstr << std::endl;redisFree(context);} else {std::cerr << "Can't allocate redis context" << std::endl;}return 1;}// 设置一个键值对redisReply *reply = (redisReply *)redisCommand(context, "SET %s %s", "key", "value");std::cout << "SET: " << reply->str << std::endl;freeReplyObject(reply);// 获取一个键值对reply = (redisReply *)redisCommand(context, "GET %s", "key");std::cout << "GET: " << reply->str << std::endl;freeReplyObject(reply);// 断开连接redisFree(context);return 0;
}
编译并运行上述代码:
g++ -o redis_example redis_example.cpp -lhiredis
./redis_example
输出结果应显示:
SET: OK
GET: value
高级数据操作
Redis 不仅支持简单的键值对操作,还支持更复杂的数据结构操作。下面我们来看一些高级的数据操作示例。
列表操作
Redis 的列表是一种简单的链表结构,支持插入、删除和读取操作。以下是一个示例,展示如何使用 C++ 操作 Redis 列表:
#include <iostream>
#include <hiredis/hiredis.h>int main() {// 连接到 Redis 服务器redisContext *context = redisConnect("127.0.0.1", 6379);if (context == NULL || context->err) {if (context) {std::cerr << "Error: " << context->errstr << std::endl;redisFree(context);} else {std::cerr << "Can't allocate redis context" << std::endl;}return 1;}// 向列表中添加元素redisReply *reply = (redisReply *)redisCommand(context, "LPUSH %s %s", "mylist", "world");freeReplyObject(reply);reply = (redisReply *)redisCommand(context, "LPUSH %s %s", "mylist", "hello");freeReplyObject(reply);// 获取列表中的所有元素reply = (redisReply *)redisCommand(context, "LRANGE %s 0 -1", "mylist");if (reply->type == REDIS_REPLY_ARRAY) {for (size_t i = 0; i < reply->elements; i++) {std::cout << "Element " << i << ": " << reply->element[i]->str << std::endl;}}freeReplyObject(reply);// 断开连接redisFree(context);return 0;
}
在这个示例中,我们首先向列表 mylist 中添加了两个元素,然后获取并打印出列表中的所有元素。编译并运行代码,输出应类似于:
Element 0: hello
Element 1: world
哈希操作
Redis 的哈希是一种键值对集合,类似于 Python 中的字典。以下是一个示例,展示如何使用 C++ 操作 Redis 哈希:
#include <iostream>
#include <hiredis/hiredis.h>int main() {// 连接到 Redis 服务器redisContext *context = redisConnect("127.0.0.1", 6379);if (context == NULL || context->err) {if (context) {std::cerr << "Error: " << context->errstr << std::endl;redisFree(context);} else {std::cerr << "Can't allocate redis context" << std::endl;}return 1;}// 设置哈希字段redisReply *reply = (redisReply *)redisCommand(context, "HSET %s %s %s", "myhash", "field1", "value1");freeReplyObject(reply);reply = (redisReply *)redisCommand(context, "HSET %s %s %s", "myhash", "field2", "value2");freeReplyObject(reply);// 获取哈希字段的值reply = (redisReply *)redisCommand(context, "HGET %s %s", "myhash", "field1");std::cout << "field1: " << reply->str << std::endl;freeReplyObject(reply);reply = (redisReply *)redisCommand(context, "HGET %s %s", "myhash", "field2");std::cout << "field2: " << reply->str << std::endl;freeReplyObject(reply);// 断开连接redisFree(context);return 0;
}
编译并运行代码,输出应类似于:
field1: value1
field2: value2
4.与大数据和人工智能结合

在实际应用中,我们可以将上述技术与大数据和人工智能算法结合。例如,利用 C++ 和 Redis 实现一个实时数据处理系统,将数据存储在 Redis 中,并通过 C++ 调用 AI 模型进行数据分析和预测。
以下是一个简化的示例,展示如何结合大数据和 AI 进行实时数据处理:
#include <iostream>
#include <hiredis/hiredis.h>
#include <vector>
#include "ai_model.h" // 假设我们有一个 AI 模型的头文件int main() {// 连接到 Redis 服务器redisContext *context = redisConnect("127.0.0.1", 6379);if (context == NULL || context->err) {if (context) {std::cerr << "Error: " << context->errstr << std::endl;redisFree(context);} else {std::cerr << "Can't allocate redis context" << std::endl;}return 1;}// 假设我们从大数据平台获取了一批数据std::vector<std::string> data = {"data1", "data2", "data3"};for (const auto& item : data) {// 将数据存储在 Redis 中redisCommand(context, "LPUSH %s %s", "data_list", item.c_str());}// 从 Redis 中读取数据并进行 AI 分析redisReply *reply = (redisReply *)redisCommand(context, "LRANGE %s 0 -1", "data_list");if (reply->type == REDIS_REPLY_ARRAY) {for (size_t i = 0; i < reply->elements; i++) {std::string data_item = reply->element[i]->str;// 调用 AI 模型进行分析std::string result = ai_model::analyze(data_item);std::cout << "Data: " << data_item << ", Analysis Result: " << result << std::endl;}}freeReplyObject(reply);// 断开连接redisFree(context);return 0;
}
在这个示例中,我们首先将一批数据存储在 Redis 的列表 data_list 中,然后从列表中读取数据,并调用 AI 模型对数据进行分析。通过这种方式,我们可以实现一个简单的实时数据处理系统。
5.实际应用案例分析
为了更好地理解上述技术在实际中的应用,我们来分析几个具体的应用案例。
案例一:实时推荐系统
实时推荐系统是电子商务网站和社交媒体平台中的重要组成部分。它通过分析用户的行为数据,实时推荐个性化的内容。以下是一个简单的实时推荐系统的实现思路:
- 数据采集:使用 C++ 程序从用户行为日志中提取数据,如浏览记录、点击记录等。
- 数据存储:将用户行为数据存储在 Redis 中,方便快速访问。
- 实时分析:使用 AI 模型对用户行为数据进行实时分析,生成个性化的推荐列表。
- 结果展示:将推荐结果返回给用户,并更新推荐模型。
下面是一个简化的示例代码,展示如何实现上述过程:
#include <iostream>
#include <hiredis/hiredis.h>
#include <vector>
#include "recommendation_model.h" // 假设我们有一个推荐模型的头文件int main() {// 连接到 Redis 服务器redisContext *context = redisConnect("127.0.0.1", 6379);if (context == NULL || context->err) {if (context) {std::cerr << "Error: " << context->errstr << std::endl;redisFree(context);} else {std::cerr << "Can't allocate redis context" << std::endl;}return 1;}// 假设我们从用户行为日志中提取了一批数据std::vector<std::string> user_behavior = {"click:product1", "view:product2", "click:product3"};for (const auto& item : user_behavior) {// 将数据存储在 Redis 中redisCommand(context, "LPUSH %s %s", "user_behavior_list", item.c_str());}// 从 Redis 中读取数据并进行推荐分析redisReply *reply = (redisReply *)redisCommand(context, "LRANGE %s 0 -1", "user_behavior_list");if (reply->type == REDIS_REPLY_ARRAY) {for (size_t i = 0; i < reply->elements; i++) {std::string behavior_item = reply->element[i]->str;// 调用推荐模型进行分析std::string recommendation = recommendation_model::analyze(behavior_item);std::cout << "Behavior: " << behavior_item << ", Recommendation: " << recommendation << std::endl;}}freeReplyObject(reply);// 断开连接redisFree(context);return 0;
}
案例二:实时监控系统
实时监控系统广泛应用于工业控制、网络安全等领域。通过实时采集和分析监控数据,可以及时发现和处理异常情况。以下是一个简单的实时监控系统的实现思路:
- 数据采集:使用传感器或日志系统采集实时数据。
- 数据存储:将监控数据存储在 Redis 中,方便快速访问。
- 实时分析:使用 AI 模型对监控数据进行实时分析,检测异常情况。
- 报警和处理:根据分析结果触发报警,并进行相应的处理。
下面是一个简化的示例代码,展示如何实现上述过程:
#include <iostream>
#include <hiredis/hiredis.h>
#include <vector>
#include "anomaly_detection_model.h" // 假设我们有一个异常检测模型的头文件int main() {// 连接到 Redis 服务器redisContext *context = redisConnect("127.0.0.1", 6379);if (context == NULL || context->err) {if (context) {std::cerr << "Error: " << context->errstr << std::endl;redisFree(context);} else {std::cerr << "Can't allocate redis context" << std::endl;}return 1;}// 假设我们从传感器中获取了一批监控数据std::vector<std::string> monitoring_data = {"temp:30", "temp:35", "temp:40"};for (const auto& item : monitoring_data) {// 将数据存储在 Redis 中redisCommand(context, "LPUSH %s %s", "monitoring_data_list", item.c_str());}// 从 Redis 中读取数据并进行异常检测redisReply *reply = (redisReply *)redisCommand(context, "LRANGE %s 0 -1", "monitoring_data_list");if (reply->type == REDIS_REPLY_ARRAY) {for (size_t i = 0; i < reply->elements; i++) {std::string data_item = reply->element[i]->str;// 调用异常检测模型进行分析bool is_anomaly = anomaly_detection_model::analyze(data_item);std::cout << "Data: " << data_item << ", Anomaly: " << (is_anomaly ? "Yes" : "No") << std::endl;}}freeReplyObject(reply);// 断开连接redisFree(context);return 0;
}
进一步优化与扩展
在实际应用中,我们可以进一步优化和扩展上述系统,以满足更复杂的需求。
性能优化
为了提高系统的性能,可以考虑以下优化措施:
- 多线程和并行处理:通过多线程或多进程技术,充分利用多核 CPU 的计算能力,提高数据处理速度。
- 批处理:将数据分批处理,减少每次处理的数据量,从而提高系统的响应速度。
- 缓存:使用 Redis 作为缓存,减少对数据库的访问次数,提高系统的性能。
以下是一个示例,展示如何使用多线程技术优化数据处理:
#include <iostream>
#include <hiredis/hiredis.h>
#include <vector>
#include <thread>void process_data(const std::string& data) {// 模拟数据处理std::this_thread::sleep_for(std::chrono::milliseconds(100));std::cout << "Processed data: " << data << std::endl;
}int main() {// 连接到 Redis 服务器redisContext *context = redisConnect("127.0.0.1", 6379);if (context == NULL || context->err) {if (context) {std::cerr << "Error: " << context->errstr << std::endl;redisFree(context);} else {std::cerr << "Can't allocate redis context" << std::endl;}return 1;}// 假设我们从数据源中获取了一批数据std::vector<std::string> data_list = {"data1", "data2", "data3", "data4", "data5"};// 启动多个线程并行处理数据std::vector<std::thread> threads;for (const auto& data : data_list) {threads.emplace_back(std::thread(process_data, data));}// 等待所有线程完成for (auto& t : threads) {t.join();}// 断开连接redisFree(context);return 0;
}
功能扩展
根据具体需求,可以进一步扩展系统的功能,例如:
- 数据清洗和预处理:在数据存储之前,对数据进行清洗和预处理,提高数据质量。
- 日志和监控:实现系统的日志记录和监控,方便问题排查和性能优化。
- 容错和恢复:增加容错和恢复机制,提高系统的可靠性和稳定性。
以下是一个示例,展示如何实现简单的数据清洗和预处理:
#include <iostream>
#include <hiredis/hiredis.h>
#include <vector>
#include <regex>std::string clean_data(const std::string& data) {// 使用正则表达式去除数据中的无效字符std::regex e("[^a-zA-Z0-9]");return std::regex_replace(data, e, "");
}int main() {// 连接到 Redis 服务器redisContext *context = redisConnect("127.0.0.1", 6379);if (context == NULL || context->err) {if (context) {std::cerr << "Error: " << context->errstr << std::endl;redisFree(context);} else {std::cerr << "Can't allocate redis context" << std::endl;}return 1;}// 假设我们从数据源中获取了一批数据std::vector<std::string> raw_data_list = {"data1#", "data2@", "data3$", "data4%", "data5^"};// 对数据进行清洗和预处理std::vector<std::string> cleaned_data_list;for (const auto& raw_data : raw_data_list) {cleaned_data_list.push_back(clean_data(raw_data));}// 将清洗后的数据存储在 Redis 中for (const auto& data : cleaned_data_list) {redisCommand(context, "LPUSH %s %s", "cleaned_data_list", data.c_str());}// 从 Redis 中读取数据并打印redisReply *reply = (redisReply *)redisCommand(context, "LRANGE %s 0 -1", "cleaned_data_list");if (reply->type == REDIS_REPLY_ARRAY) {for (size_t i = 0; i < reply->elements; i++) {std::cout << "Cleaned Data: " << reply->element[i]->str << std::endl;}}freeReplyObject(reply);// 断开连接redisFree(context);return 0;
}
6.总结
结合 C++ 和 Redis 构建高效的数据处理系统,并应用于人工智能和大数据领域。C++ 的高性能和 Redis 的高效存储,使得我们能够应对大规模数据处理的挑战,并为 AI 算法提供快速的数据访问支持。在实际应用中,可以根据具体需求进一步扩展和优化,以实现更复杂的功能。
相关文章:
高效数据处理的前沿:【C++】、【Redis】、【人工智能】与【大数据】的深度整合
目录 1.为什么选择 C 和 Redis? 2.人工智能与大数据的背景 1.大数据的挑战 2.人工智能的需求 3.C 与 Redis 的完美结合 1.安装 Redis 和 Redis C 客户端 2.连接 Redis 并进行数据操作 高级数据操作 列表操作 哈希操作 4.与大数据和人工智能结合 5.实际应…...

Vitis HLS 学习笔记--控制驱动与数据驱动混合编程
目录 1. 简介 2. 示例分析 2.1 代码分析 2.2 控制驱动TLP的关键特征 2.3 数据驱动TLP的关键特征 3. 总结 1. 简介 在 HLS 硬件加速领域,Vitis HLS 提供了强大的抽象并行编程模型。这些模型包括控制驱动和数据驱动的任务级并行性(TLP)&…...
VUE3 学习笔记(12):对比Vuex与Pinia状态管理的基本理解
在组件传值中,当嵌套关系越来越复杂的时候必然会将混乱,是否可以把一些值存在一个公共位置,无须传值直接调用呢?VUEX应运而生,但是从VUE3开始对VUEX的支持就不那么高了,官方推荐使用Pinia。 Vuex配置 ST1:…...
区间预测 | Matlab实现QRCNN-BiGRU-Attention分位数回归卷积双向门控循环单元注意力机制时序区间预测
区间预测 | Matlab实现QRCNN-BiGRU-Attention分位数回归卷积双向门控循环单元注意力机制时序区间预测 目录 区间预测 | Matlab实现QRCNN-BiGRU-Attention分位数回归卷积双向门控循环单元注意力机制时序区间预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实…...
)
TypeScript算法每日一题:赎金信(383)
作者:前端小王hs 阿里云社区博客专家/清华大学出版社签约作者✍/CSDN百万访问博主/B站千粉前端up主 题库:力扣 题目序号:383(简单) 题目:赎金信 给你两个字符串ransomNote 和 magazine,判断ran…...
springboot 作为客户端接收服务端的 tcp 长连接数据,并实现自定义结束符,解决 粘包 半包 问题
博主最近的项目对接了部分硬件设备,其中有的设备只支持tcp长连接方式传输数据,博主项目系统平台作为客户端发起tcp请求到设备,设备接收到请求后作为服务端保持连接并持续发送数据到系统平台。 1.依赖引入 连接使用了netty,如果项…...

kuka编程怎么加中文:解锁KUKA机器人编程中的中文支持
kuka编程怎么加中文:解锁KUKA机器人编程中的中文支持 在工业自动化领域,KUKA机器人以其卓越的性能和广泛的应用而备受赞誉。然而,对于许多中国用户来说,如何在KUKA编程中加入中文支持却成为了一个挑战。本文将从四个方面、五个方…...

hadoop集群中zookeeper的搭建与原理解释
搭建zookeeper 将zookeeper的apache-zookeeper-3.5.7-bin.tar.gz解压到/export/servers下 tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /export/servers为了方便后期使用解压后的文件夹改名为zookeeper-3.5.7 mv apache-zookeeper-3.5.7-bin zookeeper-3.5.7先进入zoo_…...

HTML静态网页成品作业(HTML+CSS)—— 父亲节节日介绍网页(4个页面)
🎉不定期分享源码,关注不丢失哦 文章目录 一、作品介绍二、作品演示三、代码目录四、网站代码HTML部分代码 五、源码获取 一、作品介绍 🏷️本套采用HTMLCSS,未使用Javacsript代码,共有4个页面。 二、作品演示 三、代…...

Client ID 与Client Secret
什么是 Client ID 和 Client Secret? 在现代应用程序中,特别是在涉及到OAuth 2.0身份验证和授权时,Client ID 和 Client Secret是非常重要的概念。它们通常用于验证和授权第三方应用程序,以便安全地访问受保护的资源或API。 Cli…...

React中实现大模型的打字机效果
React 想实现一个打字机的效果,类似千问、Kimi 返回的效果。调用大模型时,模型的回答通常是流式输出的,如果等到模型所有的回答全部完成之后再展示给最终用户,交互效果不好,因为模型计算推理时间比较长。本文将采用原生…...

十二、配置注解执行SQL
简化一下流程,主要可以分为下面几步: 1.解析配置,写入配置项 2.执行SQL 3.封装结果 通过注解配置SQL主要体现在解析部分,这部分要分别做解析XML还是配置注解的接口,拿到sql以后,select的处理和insert/upda…...
)
阿里云计算之运维概念学习笔记(一)
运维管理 运维管理(Operation and Maintenance Management, 简称O&M管理)是指通过科学的管理方法和技术手段,对IT系统和基础设施进行监控、维护、优化和保障,以确保系统的高可用性、稳定性、安全性和性能。运维管理涵盖了硬件…...

异常概述
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 在程序运行过程中,经常会遇到各种各样的错误,这些错误统称为“异常”。这些异常有的是由于开发者将关键字敲错导致的…...
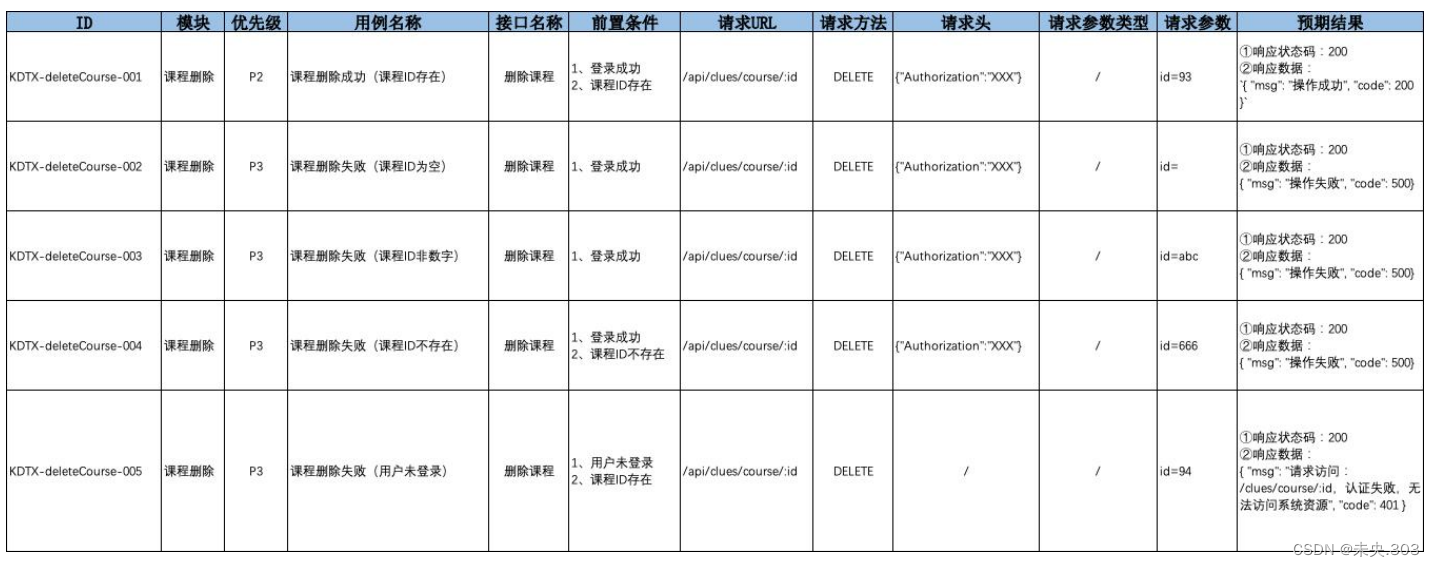
【Postman接口测试】第五节.Postman接口测试项目实战(下)
文章目录 前言七、课程添加接口postman测试 7.1 课程添加接口文档 7.2 针对课程添加设计接口测试用例 7.2.1 提取测试点 7.2.2 设计测试用例 7.2.2 使用Postman进行接口测试八、查询课程列表接口postman测试 8.1 查询…...

医用腕带朔源用的条形码与二维码如何选择
在医疗环境中的医用腕带作为患者身份识别和管理的重要工具,做为条形码和二维码腕带上的溯源技术,更是为患者信息快速获取、准确传递的保障,实现更加高效和准确的患者身份识别和管理,这种技术可以大大提高医疗服务的效率和质量&…...
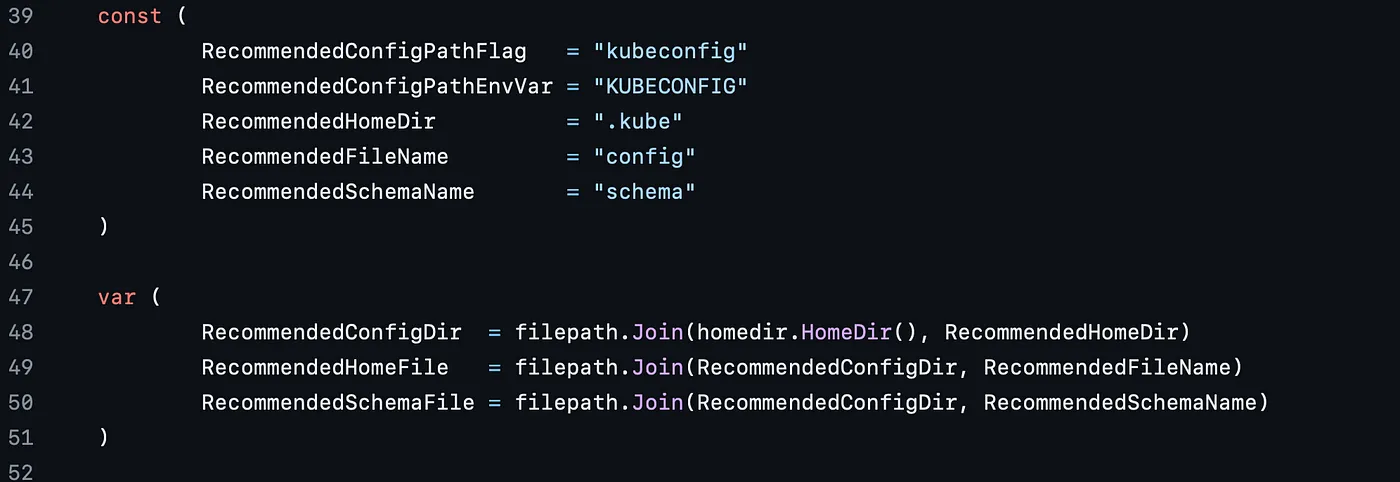
“Kubectl 如何工作案例:编写自定义 Kubectl 命令
Kubernetes 工作起来就像魔法,但它并不是魔法。它本质上是基于 REST API 调用的简单性。这种直截了当的机制是其强大功能的关键。今天,我们将深入探讨 Kubernetes 的内部工作原理,特别是当我们执行 kubectl 命令时幕后发生了什么。 1.1 AUTHENTICATION 默认情况下,kubect…...

opencv-python(五)
opencv的颜色通道中顺序是B,G,R。 图像属性 import cv2img cv2.imread(jk.jpg) print(fshape{img.shape}) print(fsize{img.size}) print(fdtype{img.dtype}) shape:图像像素的行,列,通道 size:行数 X …...
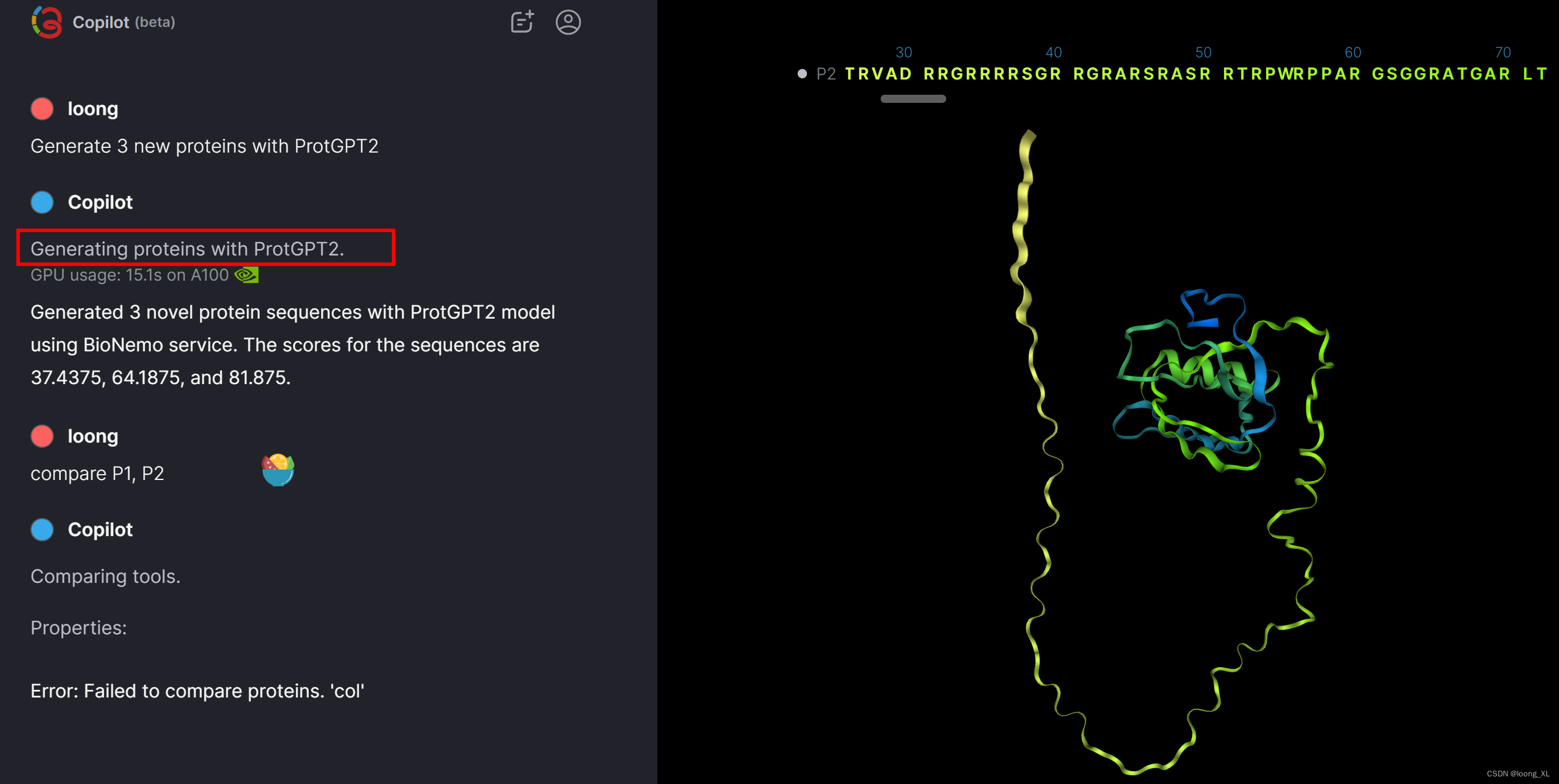
免费生物蛋白质的类chatgpt工具助手copilot:小分子、蛋白的折叠、对接等
参考: https://310.ai/copilot 可以通过自然语言对话形式实现小分子、蛋白质的相关处理:生成序列、折叠等 应该是agent技术调用不同工具实现 从UniProt数据库中搜索和加载蛋白质。使用ESM Fold方法折叠蛋白质。使用310.ai基础模型设计新蛋白质。使用TM-Align方法比较蛋白质…...

Mybatis01-初识Mybatis
简介 1、 什么是Mybatis MyBatis 是一款优秀的持久层框架; 它支持自定义 SQL、存储过程以及高级映射 MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。 MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Ol…...

CCF和中国科协对NeurIPS更正投稿政策做出回应
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达点击进入—>【顶会/顶刊】投稿交流群添加微信号:CVer2233,小助手拉你进群!扫描下方二维码,加入CVer学术星球!可以获得最新顶会/顶…...

2025.12晶晨S905L3S-L3SB安卓9通刷实战:当贝桌面加持,解锁多品牌盒子新玩法
1. 晶晨S905L3S-L3SB通刷包的前世今生 第一次听说晶晨S905L3S-L3SB芯片能通刷时,我正对着家里三台不同品牌的电视盒子发愁。这些盒子有的来自运营商赠送,有的是二手市场淘来的,虽然硬件配置相近,但系统体验天差地别。直到发现这个…...

专业数据恢复工具对决:UFS Explorer与R-Studio的实战选型指南
1. 数据恢复工具的核心价值与选型逻辑 当硬盘突然罢工或重要文件被误删时,专业数据恢复软件就像数字世界的急救医生。我经历过太多凌晨三点被叫醒处理服务器崩溃的案例,选对工具往往能决定数据"复活"的成功率。UFS Explorer和R-Studio这对老对…...

MedGemma-X精彩案例分享:自然语言提问触发的专业级影像分析报告
MedGemma-X精彩案例分享:自然语言提问触发的专业级影像分析报告 1. 重新定义智能影像诊断的新标杆 想象一下这样的场景:一位放射科医生面对堆积如山的X光片,只需要用自然语言问一句"这张胸片有没有肺炎迹象?"…...

从云端到指尖:巧用Aspose组件实现Office/PDF文档秒级HTML预览,攻克移动端大文件访问瓶颈
1. 移动端大文件预览的痛点与解决思路 最近接手一个企业级项目时,遇到了一个非常典型的场景:用户通过PC端上传各种办公文档(Word、Excel、PPT、PDF),需要在移动端随时查看。但当文件体积较大时(比如超过50M…...

告别兼容性问题:手把手教你用canvas和base64转换TIFF图片
前端工程师必备:TIFF图片处理全攻略与实战解决方案 在当今数字内容爆炸式增长的时代,图片处理已成为前端开发中不可或缺的一环。作为专业开发者,我们经常需要面对各种图片格式的兼容性问题,其中TIFF(Tagged Image Fil…...

解锁JSON Viewer 3大效率黑科技:从数据解析到开发提效的全流程解决方案
解锁JSON Viewer 3大效率黑科技:从数据解析到开发提效的全流程解决方案 【免费下载链接】json-viewer It is a Chrome extension for printing JSON and JSONP. 项目地址: https://gitcode.com/gh_mirrors/js/json-viewer JSON Viewer是一款专为开发者打造的…...

5个步骤掌握MelonLoader:让Unity游戏模组开发变得轻松有趣
5个步骤掌握MelonLoader:让Unity游戏模组开发变得轻松有趣 【免费下载链接】MelonLoader The Worlds First Universal Mod Loader for Unity Games compatible with both Il2Cpp and Mono 项目地址: https://gitcode.com/gh_mirrors/me/MelonLoader 你是否曾…...

SmolVLA开发环境搭建:从操作系统安装到模型运行的完整路径
SmolVLA开发环境搭建:从操作系统安装到模型运行的完整路径 如果你刚拿到一台新电脑,或者想把旧机器彻底清理干净,从头开始搭建一个能跑SmolVLA模型的环境,那这篇文章就是为你准备的。很多教程都假设你已经有了一个可用的系统&…...

AntdUI实战:用WinForm和.NET 6给老旧内部管理系统“换肤”的完整记录
AntdUI实战:用WinForm和.NET 6给老旧内部管理系统“换肤”的完整记录 当企业内部的WinForm系统运行超过十年,那些灰底蓝框的界面早已与现代审美格格不入。去年接手某制造业ERP系统改造时,我面对的是一个基于.NET Framework 4.0的"古董&q…...