详解 Spark Streaming 的 DStream 对象
一、DStream 的创建
1. 通过 RDD 队列
DStream 在内部实现上是一系列连续的 RDD 来表示。每个 RDD 包含有采集周期内的数据
/**
基本语法:StreamingContext.queueStream(queueOfRDDs: Queue, oneAtATime = false)
*/
object DStreamFromRddQueue {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("ds")val ssc = new StreamingContext(conf, Seconds(3))val queueOfRdds = mutable.Queue[RDD[Int]]()val ds = ssc.queueStream(queueOfRdds, oneAtATime = false)ds.print()ssc.start()// 向 RDD 队列中添加元素for(i <- 1 to 5) {queueOfRdds += ssc.sparkContext.makeRDD(1 to 300, 10)Thread.sleep(2000)}ssc.awaitTermination()}
}
2. 通过自定义数据源
通过继承 Receiver 抽象类,并实现 onStart、onStop 方法来自定义数据源采集
/**实现步骤:1.继承 Receiver[T]() 抽象类,定义泛型,并传递参数1.1 泛型是采集的数据类型1.2 传递的参数是存储级别,StorageLevel 中的枚举值2.实现 onStart、onStop 方法3.使用 receiverStream(receiver) 创建 DStream
*/
object DStreamFromDiy {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("ds")val ssc = new StreamingContext(conf, Seconds(3))// 使用自定义数据源采集数据val ds: ReceiverInputDStream[String] = ssc.receiverStream(new MyReceiver())ds.print()ssc.start()ssc.awaitTermination()}
}// 自定义数据源采集
class MyReceiver extends Receiver[String](StorageLevel.MEMORY_ONLY) {private val flag = true// 当 ssc.start() 调用后,启动一个独立的线程去采集数据override def onStart(): Unit = {new Thread(new Runnable(){override def run() {while(flag) {val data = "数据为:" + new Random().nextInt(10)// 将数据存储封装为 DStreamstore(data)Thread.sleep(500)}}}, "receiver").start()}// 停止数据采集override def onStop(): Unit = {flag = false}
}
3. 通过 Kafka 数据源
3.1 版本选型
- ReceiverAPI:需要一个专门的 Executor 去接收数据,然后发送给其他的 Executor 做计算。所以当接收数据的 Executor 和计算的 Executor 速度不同时,特别在接收数据的 Executor 速度大于计算的 Executor 速度时,会导致计算数据的节点内存溢出。(早期版本中提供此方式,当前版本不适用)
- DirectAPI:是由计算的 Executor 来主动接收消费 Kafka 的数据,速度由自身控制
3.2 实现
-
引入依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming-kafka-0-10_2.12</artifactId><version>3.0.0</version> </dependency> <dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>2.10.1</version> </dependency> -
编码
/** 基本语法:使用 KafkaUtils 工具类的 createDirectStream[K, V] 方法连接 Kafka 创建 相关参数:1.StreamingContext:环境对象2.LocationStrategies:位置策略,PreferConsistent 表示自动匹配3.ConsumerStrategies:消费策略,Subscribe[K,V](Set(topic)) 订阅主题4.Map[String, Object]:Kafka 连接配置参数 */ object DStreamFromKafka {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("ds")val ssc = new StreamingContext(conf, Seconds(3))// 封装 Kafka 配置参数val kafkaConf: Map[String, Object] = Map[String, Object](ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "linux1:9092,linux2:9092,linux3:9092",ConsumerConfig.GROUP_ID_CONFIG -> "atguigu","key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer","value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer")// 创建 Kafka 数据源的 DStreamval ds: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String, String](Set("topic1")),kafkaConf)// 打印输出val data: DStream[String] = ds.map(_.value())data.print()ssc.start()ssc.awaitTermination()} } -
测试
- 启动 Zookeeper 和 Kafka 集群
- 运行程序 main 方法
- 向 Kafka 的主题中生产数据,并查看程序控制台输出
二、DStream 的转换
1. 无状态转换操作
无状态的操作只作用于一个采集周期的 RDD 中,不同采集周期的 RDD 之间的操作结果不会归约汇总
1.1 常见操作
/**
常见原语:map/flatMap/filter/repartition/reduceByKey/groupByKey
*/
object DStreamNoStateChange {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("ds")val ssc = new StreamingContext(conf, Seconds(3))val word = ssc.socketTextStream("localhost", 9999)val wordAsOne = line.map((_, 1))val wordCount = wordAsOne.reduceByKey(_ + _)wordCount.print()/*测试:在 cmd 窗口执行 nc -lp 999,然后分次输入 10 个 hello结果:由于采集周期为 3 秒,所以输出结果为多个 (hello, num),数量与采集周期个数一致,不同的采集周期结果是独立输出的*/ssc.start()ssc.awaitTermination()}
}1.2 transform
/**
功能:可以将 DStream 中底层的 RDD 获取进行操作,可以扩展功能和实现周期性代码执行
基本语法:Dstream.transform(func: RDD => RDD): Dstream
*/
object DStreamTransform {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("ds")val ssc = new StreamingContext(conf, Seconds(3))val word = ssc.socketTextStream("localhost", 9999)word.transform(rdd => {// Driver端:此处的代码会周期性的执行,每个采集周期执行一次rdd.map(str => {// Executor 端str })})ssc.start()ssc.awaitTermination()}
}
1.3 join
/**
功能:对当前批次(采集周期)内的两个 DStream 中各自的 RDD 中相同的 key 进行 join,效果与两个 RDD 的 join 相同
基本语法:Dstream1.join(Dstream2)
*/
object DStreamTransform {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("ds")val ssc = new StreamingContext(conf, Seconds(3))val ds9999 = ssc.socketTextStream("localhost", 9999)val ds8888 = ssc.socketTextStream("localhost", 8888)val data: DStream[(String, (Int, Int))] = ds9999.map((_, 1)).join(ds888.map((_, 2)))data.print()ssc.start()ssc.awaitTermination()}
}
2. 有状态转换操作
有状态转换操作会将一个采集周期的结果(状态)保存到检查点,并且不断将下一个采集周期的结果(状态)更新保存到检查点中,最终输出所有采集周期归约汇总的结果
2.1 updateStateByKey
/**基本语法:DStream.updateStateByKey(func: (seq: Seq[T], op: Option[T]) => op)参数:1.seq 表示当前采集周期相同 key 的 Value 集合2.op 表示检查点中相同 key 的总 Value (Some 或 None)说明:1.使用 updateStateByKey 需要对检查点目录进行配置,会使用检查点来保存状态2.updateStateByKey会根据 key 对数据的状态进行更新
*/
object DStreamStateChange {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("ds")val ssc = new StreamingContext(conf, Seconds(3))// 必须设置检查点保存路径ssc.checkpoint("cp")val word = ssc.socketTextStream("localhost", 9999)val wordAsOne = line.map((_, 1))// val wordCount = wordAsOne.reduceByKey(_ + _)val wordCount = wordAsOne.updateStateByKey((seq: Seq[Int], op: Option[Int]) => {val sum = seq.sumval newVal = op.getOrElse(0) + sumOption(newVal)})wordCount.print()/*测试:在 cmd 窗口执行 nc -lp 999,然后分次输入 10 个 hello结果:最终的输出结果为 (hello, 10)*/ssc.start()ssc.awaitTermination()}
}2.2 window 操作
/**基本语法:1.DStream.window(windowSize: Duration, step: Duration)参数:1.windowSize 表示窗口大小2.step 表示窗口滑动步长说明:1.窗口大小和步长必须为采集周期大小的整数倍2.步长默认为一个采集周期大小2.countByWindow(windowSize: Duration, step: Duration):统计滑动窗口计数流中的元素个数3.reduceByWindow(func, windowSize: Duration, step: Duration):通过自定义函数聚合滑动窗口流中的元素4.reduceByKeyAndWindow(func, windowSize: Duration, step: Duration, [numTasks]):通过自定义函数聚合滑动窗口流中相同 key 的 value5.reduceByKeyAndWindow(func, invFunc, windowSize: Duration, step: Duration, [numTasks])参数说明:1.func 表示窗口中相同 key 的聚合计算方式2.invFunc 表示删除在窗口滑动后不再存在的数据值
*/
object DStreamWindow {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("ds")val ssc = new StreamingContext(conf, Seconds(3))ssc.checkpoint("cp")val word = ssc.socketTextStream("localhost", 9999)val wordAsOne = line.map((_, 1))// val ds = wordAsOne.window(Seconds(6)) // 会有重复数据val ds = wordAsOne.window(Seconds(6), Seconds(6))val wordCount = ds.reduceByKey(_ + _)// 必须设置检查点保存路径val wordCount1 = wordAsOne.reduceByKeyAndWindow((x: Int, y: Int) => x + y,(x: Int, y: Int) => x - y,Seconds(6), Seconds(6))wordCount.print()// wordCount1.print()ssc.start()ssc.awaitTermination()}
}
三、DStream 的输出
SparkStreaming 也有惰性机制,执行输出操作才会触发所有 DStream 计算的执行
/**基本语法:1.print():将 DStream 输出到控制台,只有这个输出会带时间戳2.saveAsTextFiles(prefix, [suffix]):将 DStream 保存为 text 格式文件,每一批次的存储文件名基于参数中的 prefix 和 suffix (prefix-Time_IN_MS[.suffix])3.saveAsObjectFiles(prefix, [suffix]):以 Java 对象序列化的方式将 DStream 中的数据保存为SequenceFiles,每一批次的存储文件名为 "prefix-TIME_IN_MS[.suffix]"4.saveAsHadoopFiles(prefix, [suffix]):将 DStream 中的数据保存为 Hadoop files,每一批次的存储文件名为 "prefix-TIME_IN_MS[.suffix]"5.foreachRDD(func):最通用的输出操作,将函数 func 用于 DStream 的每一个 RDD,可以将 RDD 存入文件或者通过网络将其写入数据库说明:使用foreachRDD(func)把数据写到 MySQL 的外部数据库的注意事项:1.创建连接对象不能写在 driver 层面(因为所有的连接对象都不能序列化)2.如果写在 foreachRDD 中则每个 RDD 中的每一条数据都会创建连接,影响性能和资源;3.推荐使用 RDD 的 foreachPartition() 算子,在每个分区迭代中创建连接
*/
object DStreamOutput {def main(args: Array[String]): Unit = {val conf = new SparkConf().setMaster("local[*]").setAppName("ds")val ssc = new StreamingContext(conf, Seconds(3))val word = ssc.socketTextStream("localhost", 9999)val wordAsOne = line.map((_, 1))val wordCount = wordAsOne.reduceByKey(_ + _)// wordCount.print() // SparkStreaming 没有输出操作会报错wordCount.foreachRDD(rdd => {rdd.foreach(println)})ssc.start()ssc.awaitTermination()}
}
四、SparkStreaming 优雅的关闭
SparkStreaming 任务需要 7*24 小时执行,但是有时涉及到升级代码需要主动停止程序,而分布式程序没办法做到一个个进程去停止,所以需要使用第三方系统 (MySQL/Redis/Zookeepr/HDFS) 来控制内部程序关闭
import java.net.URI
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.streaming.{StreamingContext, StreamingContextState}class MonitorStop(ssc: StreamingContext) extends Runnable {override def run(): Unit = {val fs: FileSystem = FileSystem.get(new URI("hdfs://linux1:9000"), new Configuration(), "hello")while(true) {try{Thread.sleep(5000)} catch {case e: InterruptedException => e.printStackTrace()}val state: StreamingContextState = ssc.getStateval bool: Boolean = fs.exists(new Path("hdfs://linux1:9000/stopSpark"))if(bool) {if(state == StreamingContextState.ACTIVE) {// 优雅地关闭,停止接收新数据,并将已有的数据处理完后再关闭ssc.stop(stopSparkContext = true, stopGracefully = true)System.exit(0)}}}}
}import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}object SparkTest {def createSSC(): _root_.org.apache.spark.streaming.StreamingContext = {val update: (Seq[Int], Option[Int]) => Some[Int] = (values: Seq[Int], status:
Option[Int]) => {//当前批次内容的计算val sum: Int = values.sum//取出状态信息中上一次状态 val lastStatu: Int = status.getOrElse(0)Some(sum + lastStatu)}val sparkConf: SparkConf = new SparkConf().setMaster("local[4]").setAppName("SparkTest")//设置优雅的关闭sparkConf.set("spark.streaming.stopGracefullyOnShutdown", "true")val ssc = new StreamingContext(sparkConf, Seconds(5))ssc.checkpoint("./ck")val line: ReceiverInputDStream[String] = ssc.socketTextStream("linux1", 9999)val word: DStream[String] = line.flatMap(_.split(" "))val wordAndOne: DStream[(String, Int)] = word.map((_, 1))val wordAndCount: DStream[(String, Int)] = wordAndOne.updateStateByKey(update)wordAndCount.print()ssc}def main(args: Array[String]): Unit = {// 从检查点恢复数据val ssc: StreamingContext = StreamingContext.getActiveOrCreate("./ck", () => createSSC())new Thread(new MonitorStop(ssc)).start()ssc.start()ssc.awaitTermination()}}
相关文章:

详解 Spark Streaming 的 DStream 对象
一、DStream 的创建 1. 通过 RDD 队列 DStream 在内部实现上是一系列连续的 RDD 来表示。每个 RDD 包含有采集周期内的数据 /** 基本语法:StreamingContext.queueStream(queueOfRDDs: Queue, oneAtATime false) */ object DStreamFromRddQueue {def main(args: Ar…...

QT常用控件
目录 1.控件概述 2. QWidget 核⼼属性 设置组件是否可用 获取组件当前位置和尺⼨ QWidget的图标 组件的透明度设置 QWidget光标的设置 字体的设置 组件提示 设置组件获取到焦点的策略 stylesheet样式表 3.常用组件 QPushButton RadioButton Check Box QLabel …...
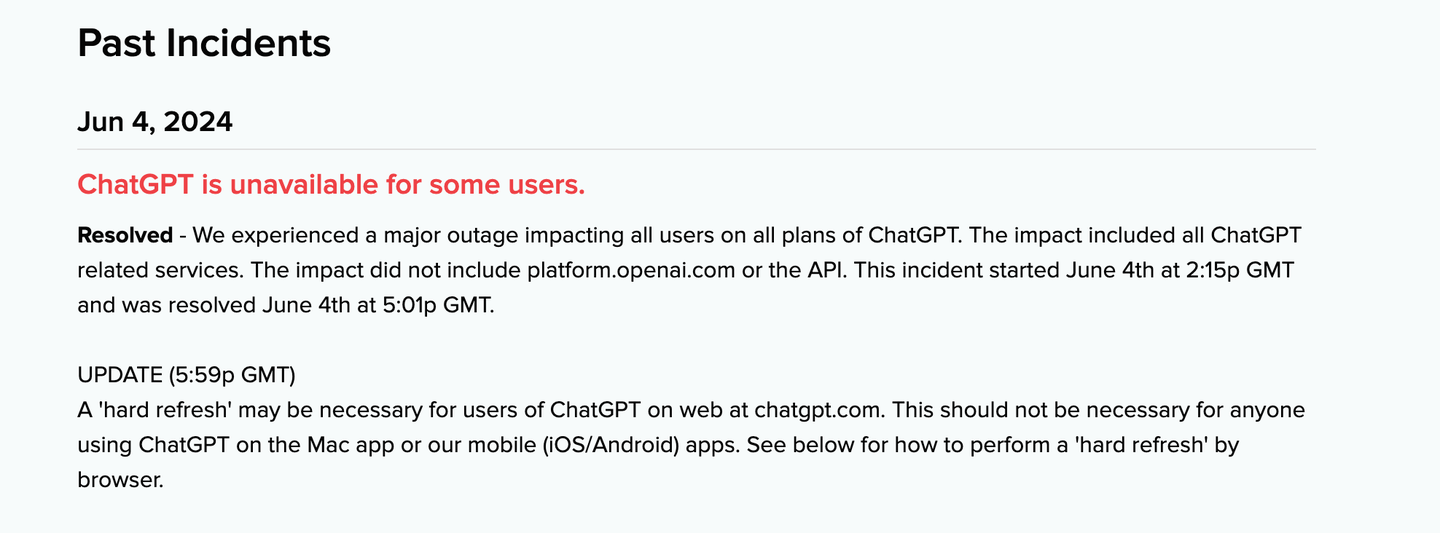
如何解决chatgpt出现503 bad gateway的问题
昨日,ChatGPT官网挂了,也就是使用web网页端访问的用户,会出现 bad gateway 情况。我们去ChatGPT官方的监控查看,已经展示相关错误。 影响的范围有: 影响了 ChatGPT 所有计划的所有用户。影响包括所有与 ChatGPT 相关…...
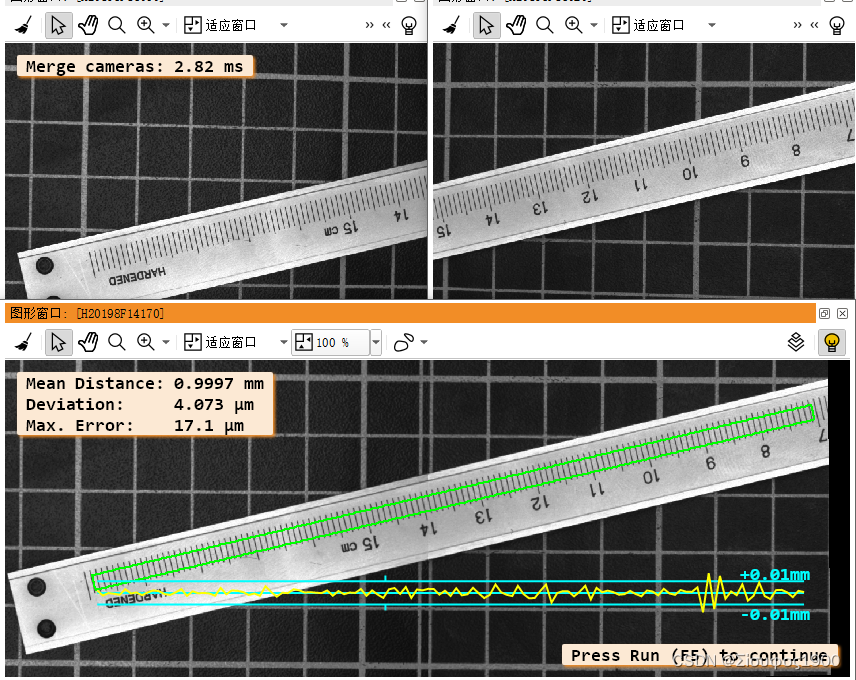
Halcon 双相机标定与拼图(二)
一、概述 这种标定有两种模式,有一个标定板和多个标定板两种 一个标定板 两个相机的重叠区域比较大,那么我们可以把标定板放到那个重叠区域来统一坐标系,如下 这种是只需要一个标定板,这种是推荐的方式 。这种是比较简单的&…...

【加密与解密】【04】Java安全架构
JAVA安全模块划分 JCA,Java Cryptography Architecture,Java加密体系结构JCE,Java Cryptography Extension,Java加密扩展包JSSE,Java Secure Sockets Extension,Java安全套接字扩展包JAAS,Java…...

论文阅读:Neural Scene Flow Prior
目录 概要 Motivation 整体架构流程 技术细节 小结 论文地址:...

如何通过 6 种简单方法将照片从华为转移到 PC?
华为作为全球领先的智能手机供应商之一,最近推出了其自主研发的操作系统——HarmonyOS 2.0,旨在为智能手机、平板电脑和智能手表等设备提供更流畅的用户体验。随着Mate 40/P40等系列手机计划升级到HarmonyOS 2.0,用户可能需要将手机中的文件备…...
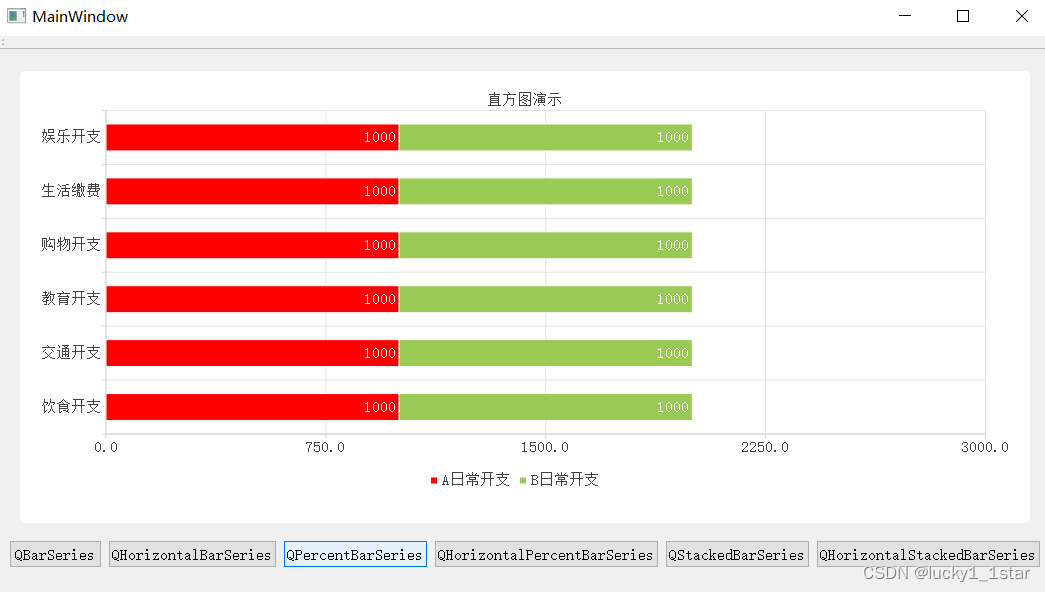
QtCharts使用
1.基础配置 1.QGraphicsView提升为QChartView#include <QtCharts> QT_CHARTS_USE_NAMESPACE #include "ui_widget.h"2. QT charts 2.柱状图 2.1QBarSeries //1.创建Qchart对象QChart *chart new QChart();chart->setTitle("直方图演示");//设…...

深入分析 Flink SQL 工作机制
摘要:本文整理自 Flink Forward 2020 全球在线会议中文精华版,由 Apache Flink PMC 伍翀(云邪)分享,社区志愿者陈婧敏(清樾)整理。旨在帮助大家更好地理解 Flink SQL 引擎的工作原理。文章主要分…...

Spring Bean参数校验Validator
Spring Bean参数校验Validator 以下2种方式可以用于所有的 Spring bean 不仅仅是 Controller 控制器。 一、原始类型参数 在控制器(或者其他Bean)上使用Validated注解。 控制器类 RestController RequestMapping("account") Validated pub…...
AOP案例
黑马程序员JavaWeb开发教程 文章目录 一、案例1.1 案例1.2 步骤1.2.1 准备1.2.2 编码 一、案例 1.1 案例 将之前案例中增、删、改相关节后的操作日志记录到数据库表中。 操作日志:日志信息包含:操作人、操作时间、执行方法的全类名、执行方法名、方法…...

Facebook海外户Facebook广告被暂停的原因
有很多伙伴在Facebook广告时,有时会遇到账号被暂停,并通知你违反了哪些规则,那么Facebook广告被暂停的原因有哪些呢?今天小编详细梳理了一些原因,可以往下看哦~ 您的Facebook广告被暂停可能有以下几个原因:…...

网站企业需要适用于什么服务器?
对于网站企业会选择什么样的服务器呢? 为了保证网站能够稳定的运行需要选择高可用性和可靠性的网站服务器,选择具备高可用性架构的云服务器供应商,能够提供多可用区部署、自动故障转移和备份恢复等功能,保障网站在各种故障情况下的…...
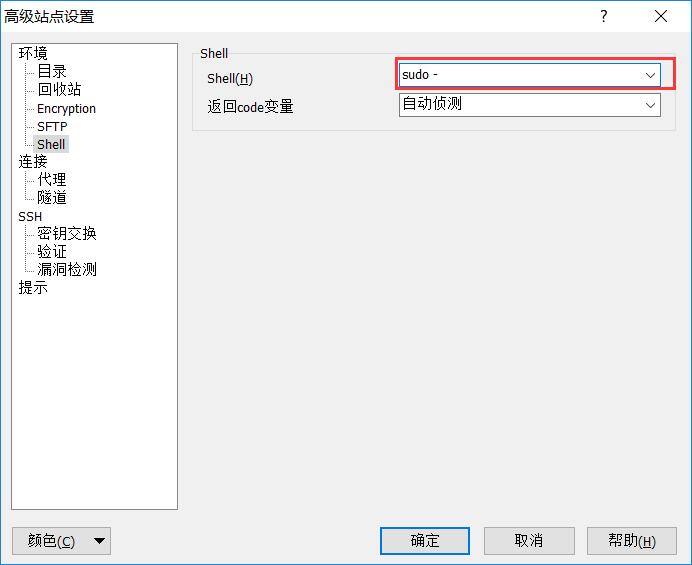
winscp无法上传,删除,修改文件并提示权限不够的分析
使用winscp删除文件,报了个错如下 根据这个错就去百度,网上大部分都是通过下面这种方法解决: 在winscp端进行设置 输入主机名(即IP地址)、用户名和密码,然后点击高级 在箭头所指位置输入sudo + sftp应用程序的路径 先查询 sudo find / -name sftp-server -print点击Sh…...

Hadoop3:MapReduce之InputFormat数据输入过程整体概览(0)
一、MapReduce中数据流向 二、MapTask并行度 1、原理概览 数据块:Block是HDFS物理上把数据分成一块一块。数据块是HDFS存储数据单位。 数据切片:数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。数据切片是MapRed…...

【Leetcode Python】70.爬楼梯
麻烦大家要自己去leetcode看题目 第一个思路 用递归会超时 return self.climbStairs(n - 1) self.climbStairs(n - 2)第二个思路 滚动数组思想 class Solution(object):def climbStairs(self, n):""":type n: int:rtype: int"""if(n<2)…...

深度学习 - 张量的广播机制和复杂运算
张量的广播机制(Broadcasting)是一种处理不同形状张量进行数学运算的方式。通过广播机制,PyTorch可以自动扩展较小的张量,使其与较大的张量形状兼容,从而进行元素级的运算。广播机制遵循以下规则: 如果张量…...

【CSS】will-change 属性详解
目录 基本语法属性值常见用途will-change 如何用于优化动画效果示例: will-change 是一个 CSS 属性,用于告诉浏览器某个元素在未来可能会发生哪些变化。这可以帮助浏览器优化渲染性能,提前做一些准备工作,从而提高性能。 基本语法…...
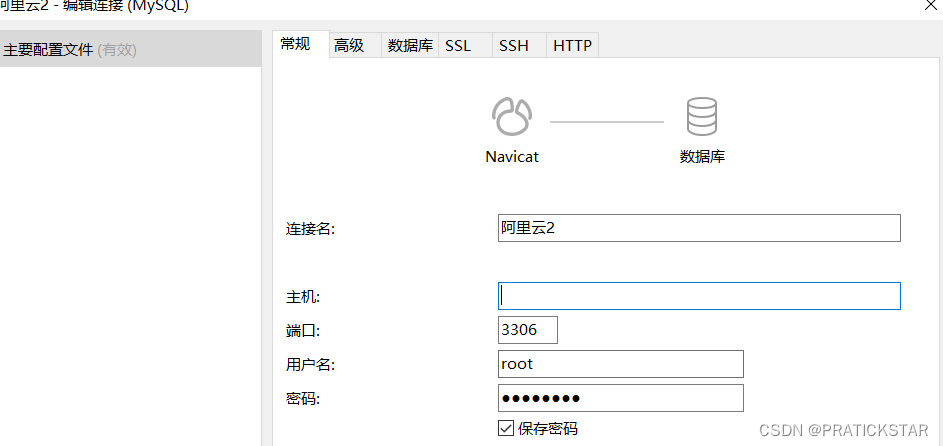
linux安装mysql后,配置mysql,并连接navicat软件
Xshell连接登陆服务器 输入全局命令 mysql -u root -p 回车后,输入密码,不显示输入的密码 注意mysql服务状态,是否运行等 修改配置文件my.cnf,这里没找到就找my.ini,指定有一个是对的 find / -name my.cnf 接下…...

【学习笔记】Axios、Promise
TypeScript 1、Axios 1.1、概述 1.2、axios 的基本使用 1.3、axios 的请求方式及对应的 API 1.4、axios 请求的响应结果结构 1.5、axios 常用配置选项 1.6、axios.create() 1.7、拦截器 1.8、取消请求2、Promise 2.1、封装 fs 读…...
)
华为防火墙IPsec点对点配置实战:从零到通的完整流程(附常见错误排查)
华为防火墙IPsec点对点配置实战:从零到通的完整流程(附常见错误排查) 在当今企业网络架构中,跨地域分支机构之间的安全通信已成为刚需。IPsec VPN凭借其强大的加密能力和标准化协议支持,成为构建安全通道的首选方案。华…...

如何用GetQzonehistory高效备份QQ空间历史说说实现青春记忆永久保存
如何用GetQzonehistory高效备份QQ空间历史说说实现青春记忆永久保存 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 解决数字记忆流失的痛点方案 在这个信息快速迭代的时代,…...

企业级解决方案:Magma智能体集群部署实战
企业级解决方案:Magma智能体集群部署实战 1. 引言 在当今AI技术快速发展的时代,企业级AI应用对计算资源的需求呈指数级增长。单个AI实例往往难以满足高并发、高可用的生产环境要求,而集群化部署成为解决这一挑战的关键方案。今天我们将深入…...

你的杜邦线和PCB走线,可能正在‘谋杀’J-Link SWD的高速信号
你的杜邦线和PCB走线,可能正在‘谋杀’J-Link SWD的高速信号 在嵌入式开发中,我们常常会遇到一个令人头疼的问题:昨天还能正常工作的调试接口,今天突然就无法识别芯片了。更令人困惑的是,降低SWD时钟速率后࿰…...

藏在OpenBMC里的黑科技:拆解dbus-broker如何用socketpair实现父子进程通信
藏在OpenBMC里的黑科技:拆解dbus-broker如何用socketpair实现父子进程通信 在嵌入式系统开发领域,OpenBMC作为开源基板管理控制器解决方案,其底层通信机制的设计往往蕴含着许多精妙的技术细节。今天我们将深入探讨dbus-broker中那个鲜为人知…...

大模型学习笔记------SAM模型架构拆解与实战指引
1. SAM模型架构全景拆解 第一次看到SAM模型时,就像拿到了一台精密的瑞士手表——外表简洁但内部构造复杂。这个由Meta提出的"分割一切"模型,确实改变了计算机视觉领域的游戏规则。想象一下,你只需要在图片上随便点几个点࿰…...
3步打造个性化Windows任务栏:轻量级桌面美化工具TranslucentTB使用指南
3步打造个性化Windows任务栏:轻量级桌面美化工具TranslucentTB使用指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是否…...

手机生成剧本杀软件2025推荐,创新剧情设计工具助力创作
手机生成剧本杀软件2025推荐,创新剧情设计工具助力创作随着剧本杀市场的蓬勃发展,越来越多的创作者和爱好者希望借助科技的力量来提升创作效率和质量。在2025年,一款名为量子探险AI剧本杀工坊的手机生成剧本杀软件脱颖而出,成为众…...

小白也能当对联大师!春联生成模型-中文-base开箱即用教程
小白也能当对联大师!春联生成模型-中文-base开箱即用教程 1. 前言:人人都能创作春联 春节贴春联是中国人延续千年的传统习俗,但创作一副对仗工整、寓意美好的春联并非易事。传统春联创作需要掌握平仄、对仗等复杂规则,这让许多对…...

万象熔炉 | Anything XL多风格尝试:动漫/写实/赛博朋克提示词模板库
万象熔炉 | Anything XL多风格尝试:动漫/写实/赛博朋克提示词模板库 1. 工具简介 万象熔炉 | Anything XL 是一款基于 Stable Diffusion XL 框架开发的本地图像生成工具。它最大的特点是支持直接加载 safetensors 单文件权重,无需复杂的配置和权重拆分…...