数据仓库核心:维度表设计的艺术与实践

文章目录
- 1. 引言
- 1.1基本概念
- 1.2 维度表定义
- 2. 设计方法
- 2.1 选择或新建维度
- 2.2 确定维度主维表
- 2.3 确定相关维表
- 2.14 确定维度属性
- 3. 维度的层次结构
- 3.1 举个例子
- 3.2 什么是数据钻取?
- 3.3 常见的维度层次结构
- 4. 高级维度策略
- 4.1 维度整合
- 维度整合:构建数据的统一视图
- 4.1 维度拆分
- 5. 写在最后
在之前的文章中,我们已经深入探讨了数据 数据仓库核心:揭秘事实表与维度表的角色与区别 和 解锁数据潜能:深入理解数据仓库建模及其模型对比 。这两篇文章为我们奠定了数据仓库的基础知识,让我们对数仓的架构和模型有了初步的认识。
在本章中,我们将聚焦于维度表——维度建模中不可或缺的核心元素。维度表不仅为事实表提供了丰富的上下文信息,更是数据仓库查询性能和易用性的关键。本文将带你深入了解维度表的设计要点,帮助你构建一个高效、灵活且易于维护的数据仓库。
1. 引言
1.1基本概念
维度表则是用来描述事实的表,它提供了分析数据的上下文。维度表通常包含描述性的信息,如产品名称、客户信息、时间等。
维度表就是你观察该事物的角度, 维度表就像故事中的背景,它包含了描述事实表中数据的上下文信息,比如时间、地点、产品、顾客等等,这些信息帮助我们理解事实表中的数据。维度表通常描述了事实表中数据的各种属性,比如产品的类别,客户的地理位置等。
维度表就像是事实表的说明书。它们帮助我们理解事实表中的数字背后的故事。例如,我们可能会有一个产品维度表,它包含了产品的详细信息:
CREATE TABLE Product_Dimension (ProductID INT PRIMARY KEY,ProductName VARCHAR(255),Category VARCHAR(100),SupplierID INT
);
在这个产品维度表中,ProductID 是产品的唯一标识,它与事实表中的 ProductID 相匹配,ProductName 和 Category 提供了产品的描述性信息,SupplierID 可能与另一个维度表相关联。
具体维度表和事实表的区别可以看这篇文章 :数据仓库核心:揭秘事实表与维度表的角色与区别
1.2 维度表定义
说回维度表,它承载着丰富的描述性信息,是连接事实表的桥梁。在维度表中,我们能够找到两样宝贵的东西:
- 主键:它是维度表的“身份证”,一个独特的标签,确保了每一行数据的唯一性。
- 描述性属性:这些属性是维度表的灵魂,它们描绘了维度的细节,比如时间的流逝、地点的特色、产品的特性等。
其就像一个精心编排的目录,它通过主键来确保每个条目都是独一无二的。这个主键就像是一把钥匙,不仅打开了数据的大门,还确保了与它相连的任何事实表之间的联系是牢固和完整的。主键有两种类型:代理键和自然键,它们都是用来标识维度表中的特定条目的。
-
想象一下,代理键就像是图书馆里的索引号,它没有特定的业务意义,但是它能够确保我们能够快速找到想要的书籍。在数据仓库中,代理键通常用来处理那些会随着时间变化的维度,比如缓慢变化维。这样,即使业务数据发生变化,代理键也能保持稳定,帮助我们追踪数据的历史。
-
而自然键则像是书的ISBN号,它与书的内容紧密相关,具有实际的业务意义。比如,对于商品这个维度来说,商品的自然键可能是商品
ID,这个ID在业务中有着明确的含义。
有趣的是,对于前台应用系统来说,商品ID可能是代理键,因为它只是用来标识商品的一个符号。但对于数据仓库系统来说,商品ID则变成了自然键,因为它代表了商品的实际业务属性。
总的来说,无论是代理键还是自然键,它们都是数据仓库中不可或缺的部分,帮助我们确保数据的准确性和完整性。通过合理地使用这两种键,我们可以构建一个既灵活又稳定的数据仓库,为业务决策提供强有力的支持。
2. 设计方法
让我们以商品维度表的设计为例,一步步揭开维度设计的神秘面纱。
2.1 选择或新建维度
在构建维度表时,我们首先需要确保它在数据仓库中的唯一性。这意味着,对于商品这一维度,整个数据仓库中只能有一个商品维度表,以保证数据的一致性和准确性。
2.2 确定维度主维表
维度的主维表表通常是ODS层(操作数据存储)中的表,它与业务系统的表结构保持一致。例如,商品表jd_items_info,就是商品维度的主维表。
2.3 确定相关维表
数据仓库的设计遵循高内聚低耦合的原则。在确定了主来源表之后,我们还需要根据实际的业务需求,扩展商品的相关信息。这可能包括类目、所属卖家、所属店铺等维度。
高内聚原则:维度表中的属性应该高度相关。
低耦合原则:不同维度表之间的属性应该尽量独立。
一致性原则:相同含义的属性在不同维度表中应保持一致。
可理解性原则:维度表的命名和属性应该易于理解和使用。
2.14 确定维度属性
在主来源表和相关维表的基础上,我们开始创建或补充维度属性:
- 生成新的维度属性:尽可能地从现有数据中派生出新的维度属性,以丰富维度表的内容。
- 文字描述属性:提供包含文字描述的属性,而不仅仅是编码。例如,除了一级类目
ID之外,还应该包含一级类目名称,使得维度表更加易于理解和使用。 - 度量作为维度:某些数字度量也可以作为维度属性。例如,商品单价既可以作为观察商品价格段的维度,也可以在计算平均商品价格时作为事实。
- 沉淀常用字段:尽量沉淀出常用和公用的字段,如商品状态,这通常需要通过上架时间等信息来判断。
通过这样的设计过程,我们不仅能够确保维度表的完整性和可用性,还能够提升数据仓库的分析能力。
3. 维度的层次结构
3.1 举个例子
以商品维度表为例,我们可以看到这样的层次结构:
CREATE TABLE IF NOT EXISTS dw.dw_commodity_jd_items_info_td (product_id INT COMMENT '商品ID',product_name STRING COMMENT '商品名称',product_category STRING COMMENT '商品类目',first_level_category_id INT COMMENT '一级类目ID',first_level_category_name STRING COMMENT '一级类目名称',second_level_category_id INT COMMENT '二级类目ID',second_level_category_name STRING COMMENT '二级类目名称',third_level_category_id INT COMMENT '三级类目ID',third_level_category_name STRING COMMENT '三级类目名称',listing_time TIMESTAMP COMMENT '上架时间'
)
COMMENT '商品维度表'
在这里,类目层次清晰地展示了从宏观到微观的划分:
- 一级类目 → 二级类目 → 三级类目
而时间层次则按照时间的流逝,由大到小排列:
- 年 → 月 → 季度 → 周 → 天
这种层次结构在什么场景下大放异彩呢?答案就是数据钻取。
3.2 什么是数据钻取?
数据钻取是一种强大的数据分析技术,它包括两个方向的操作:
- 上钻(Roll-up):减少维度的详细程度,从更细的粒度提升到更粗的粒度。例如,从每天的数据提升到按季度或年度来查看数据。
- 下钻(Drill-down):增加维度的详细程度,深入到更细的数据粒度。比如,从年度数据深入到具体的月份或天。
简单来说,如果你想从年份数据中查看更详细的月度或日度数据,这个过程就是下钻;相反,如果你从每天的数据转向查看季度或年度数据,那就是上钻。
3.3 常见的维度层次结构
在数据仓库中,有几个常见的维度层次结构,它们极大地方便了数据钻取操作:
- 日期维度:年、月、日、季度等,方便按时间序列进行数据分析。
- 地址维度:国家、省、市、区等,有助于地理空间分析。
- 类目维度:如商品的一级、二级、三级类目,有助于了解商品的分类和层次。
通过这些层次化的设计,维度表不仅仅是数据的存储容器,它们成为了数据分析的有力工具,帮助我们从不同角度和深度洞察业务的各个方面。
4. 高级维度策略
4.1 维度整合
想象一下,如果你的团队成员来自世界各地,大家说不同的语言,沟通起来肯定费劲。维度整合的目的,就是要让大家说同一种“语言”。比如,不同系统可能用不同的方式表示用户ID或性别,我们的任务就是把它们统一起来,这样无论数据来自哪里,我们都能轻松识别。
维度整合是数据仓库的核心之一,它要求我们将来自不同源系统的维度属性统一起来。这包括统一表名、字段名,以及同步公共代码和编码值。例如,将不同系统中表示性别的不同代码(如1:TRUE、0:FALSE)统一为一个标准。此外,我们还可能需要决定是否将具有部分重合字段的表合并,或者保持它们独立以避免产生大量空值。
维度整合:构建数据的统一视图
维度整合是数据仓库设计中的精妙手法,它帮助我们将分散的数据汇聚成一个易于理解和使用的统一视图。
- 垂直整合:集中同一主题的信息
垂直整合就像是将同一主题的不同信息层次叠加起来。以会员数据为例,源系统中可能分散着会员的基础信息、扩展信息以及不同平台的会员等级信息等多个表。这些表虽然都关注同一实体——会员,但每个表都存储着不同的细节。垂直整合的目的,就是将这些分散的信息汇集到一个统一的会员维度模型中,让我们对会员的了解更加全面。
- 水平整合:合并不同来源的数据集
水平整合则是将关注不同实体且可能存在交集的数据集进行合并。设想一下,一个大型电商平台的数据仓库,它可能收集了来自不同购物平台的会员数据。面对这种情况,我们需要决定是否将这些数据合并到一个统一的会员表中。
如果选择进行整合,我们首先需要检查这些不同的会员数据集之间是否有重叠,并相应地进行去重处理。接下来,如果不存在重叠,我们还需要考虑不同数据集的自然键是否会冲突。如果自然键不冲突,我们可以将它们作为整合后表的自然键。如果存在冲突,我们可能需要创建一个超自然键,将不同来源的自然键合并为一个新的字段。
在实践中,一种常见的方法是将不同来源的自然键作为联合主键,并在物理实现时将来源字段用作分区字段。这种方法的好处在于,它既保留了数据的原始来源信息,又提高了数据查询的效率。
4.1 维度拆分
当一张维度表变得太庞大,就像一本厚重的电话簿,用起来很不方便时,我们就需要考虑把它拆分成几张表。这就好比把电话簿按字母顺序分开,查找起来就快多了。
拆分的方法有好几种,比如我们可以按照商品的类型来拆分,普通商品和特殊商品各一张表;或者按照属性的使用频率来拆分,常用的信息放在一张表,不常用的放在另一张表。常见的拆分方法包括:
-
水平拆分:在数据层面上,根据类别或类型细分维度,如将特殊商品和普通商品分别维护在不同的子维度表中。
-
垂直拆分:在维度属性层面上,根据属性的重要性、使用频率或稳定性进行拆分。
-
历史归档:对积累的大量过时或不再使用的维度记录进行归档,以优化性能和存储。
5. 写在最后
在本章,我们像搭积木一样,一块块地搭建起对维度表的理解。维度表,这个数据仓库里的重要角色,其实就是个大目录,帮我们把数据整理得井井有条。
首先,我们明白了维度表的基本构成:它就像个故事背景,告诉我们事实表里数字背后的故事。每个维度表都有个独一无二的“身份证”——主键,它可能是个没特殊意义的编号,也可能是和业务紧密相关的实际ID。
接着,我们一步步走进了维度表的设计世界。好比挑选食材做大餐,我们得从业务需求出发,挑出最合适的维度属性,还得考虑怎么让这个大餐更易消化——也就是让数据模型既灵活又易于理解。
我们还聊到了维度表的层次结构,这就像是给数据分门别类,让我们能从不同的角度看问题,无论是时间的流转还是商品的分类,都能轻松应对。
最后,我们探讨了维度表整合和拆分的高级策略。就像是整理衣橱,有时候我们需要把相似的衣服挂在一起,有时候又需要把不合季节的衣服收起来。整合和拆分让我们的数据模型更加高效,也更适应变化。
通过本章的内容,希望你能像拿着一张地图一样,对维度表设计有清晰的认识。。
相关文章:
数据仓库核心:维度表设计的艺术与实践
文章目录 1. 引言1.1基本概念1.2 维度表定义 2. 设计方法2.1 选择或新建维度2.2 确定维度主维表2.3 确定相关维表2.14 确定维度属性 3. 维度的层次结构3.1 举个例子3.2 什么是数据钻取?3.3 常见的维度层次结构 4. 高级维度策略4.1 维度整合维度整合:构建…...

SQL实验 连接查询和嵌套查询
一、实验目的 1.掌握Management Studio的使用。 2.掌握SQL中连接查询和嵌套查询的使用。 二、实验内容及要求(请同学们尝试每道题使用连接和嵌套两种方式来进行查询,如果可以的话) 1.找出所有任教“数据…...

【JAVA WEB实用技巧与优化方案】Maven自动化构建与Maven 打包技巧
文章目录 一、MavenMaven生命周期介绍maven生命周期命令解析二、如何编写maven打包脚本maven 配置详解setting.xml主要配置元素setting.xml 详细配置使用maven 打包springboot项目maven 引入使用package命令来打包idea打包三、使用shell脚本自动发布四、使用maven不同环境配置加…...

详细分析Mysql中的SQL_MODE基本知识(附Demo讲解)
目录 前言1. 基本知识2. Demo讲解2.1 ONLY_FULL_GROUP_BY2.2 STRICT_TRANS_TABLES2.3 NO_ZERO_IN_DATE2.4 NO_ENGINE_SUBSTITUTION2.5 ANSI_QUOTES 前言 了解Mysql内部的机制有助于辅助开发以及形成整体的架构思维 对于基本的命令行以及优化推荐阅读: 数据库中增…...

vue3+uniapp
1.页面滚动 2.图片懒加载 3.安全区域 4.返回顶部,刷新页面 5.grid布局 place-self: center; 6.模糊效果 7.缩放 8.微信小程序联系客服 9.拨打电话 10.穿透 11.盒子宽度 12.一般文字以及盒子阴影 13.选中文字 14.顶部安全距离 15.onLoad周期函数在setup语法糖执行后…...
组织病理学结合人工智能之后,如何实际应用于临床?|顶刊精析·24-06-06
小罗碎碎念 今天这篇文章选自21年5月发表的nature medicine,标题名为——Deep learning in histopathology: the path to the clinic,这篇文章也是我规划的病理组学文献精析的第三篇,如果你能坚持把七篇都看完,相信你脑海中一定会…...
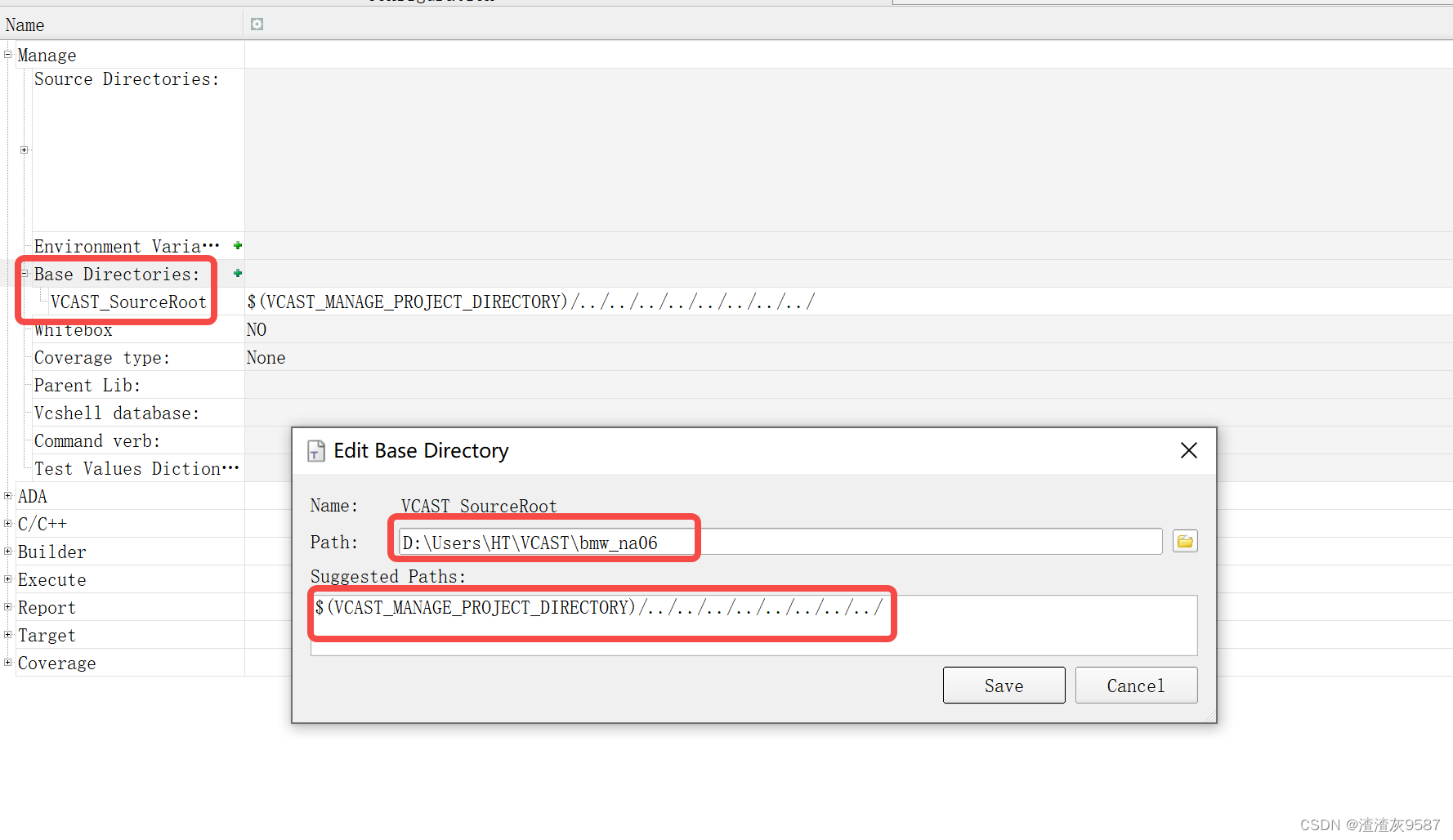
VCAST创建单元测试工程
1. 设置工作路径 选择工作目录,后面创建的 UT工程 将会生成到这个目录。 2. 新建工程 然后填写 工程名称,选择 编译器,以及设置 基础路径。注意 Base Directory 必须要为代码工程的根目录,否则后面配置环境会失败。 这样工程就创建好了。 把基础路径设置为相对路径。 …...

数据结构之归并排序算法【图文详解】
P. S.:以下代码均在VS2019环境下测试,不代表所有编译器均可通过。 P. S.:测试代码均未展示头文件stdio.h的声明,使用时请自行添加。 博主主页:LiUEEEEE …...
设计模式基础
什么是设计模式 设计模式是一种在软件设计过程中反复出现的问题和相应解决方案的描述。它是一种被广泛接受的经验总结,可以帮助开发人员解决常见的设计问题并提高代码的重用性、可维护性和可扩展性。 设计模式可以分为三类: 创建型模式(Crea…...

Glide支持通过url加载本地图标
序言 glide可以在load的时候传入一个资源id来加载本地图标,但是在开发过程中。还得区分数据类型来分别处理。这样的使用成本比较大。希望通过自定义ModelLoader实现通过自定义的url来加载Drawab。降低使用成本 实现 一共四个类 类名作用GlideIcon通过自定义url的…...
网络安全形势与WAF技术分享
我一个朋友的网站,5月份时候被攻击了,然后他找我帮忙看看,我看他的网站、网上查资料,不看不知道,一看吓一跳,最近几年这网络安全形势真是不容乐观,在网上查了一下资料,1、中国信息通…...

【实战JVM】-实战篇-06-GC调优
文章目录 1 GC调优概述1.1 调优指标1.1.1 吞吐量1.1.2 延迟1.1.3 内存使用量 2 GC调优方法2.1 发现问题2.1.1 jstat工具2.1.2 visualvm插件2.1.3 PrometheusGrafana2.1.4 GC Viewer2.1.5 GCeasy 2.2 常见GC模式2.2.1 正常情况2.2.2 缓存对象过多2.2.3 内存泄漏2.2.4 持续FullGC…...

深入解析智慧互联网医院系统源码:医院小程序开发的架构到实现
本篇文章,小编将深入解析智慧互联网医院系统的源码,重点探讨医院小程序开发的架构和实现,旨在为相关开发人员提供指导和参考。 一、架构设计 智慧互联网医院系统的架构设计是整个开发过程的核心,直接影响到系统的性能、扩展性和维…...
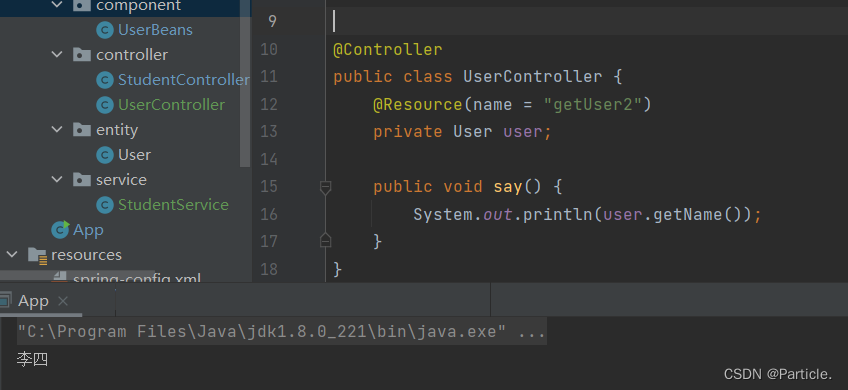
获取 Bean 对象更加简单的方式
获取 bean 对象也叫做对象装配,是把对象取出来放到某个类中,有时候也叫对象注⼊。 对象装配(对象注⼊)即DI 实现依赖注入的方式有 3 种: 1. 属性注⼊ 2. 构造⽅法注⼊ 3. Setter 注⼊ 属性注入 属性注⼊是使⽤ Auto…...

ChatGPT基本原理
技术背景与基础: 深度学习:ChatGPT建立在深度学习技术之上,通过复杂的神经网络结构模拟人类的语言处理过程。深度学习使得ChatGPT能够处理海量的文本数据,并从中提取出复杂的语言模式和规律。GPT架构:ChatGPT基于GPT&a…...

几种更新 npm 项目依赖的实用方法
几种更新 npm 项目依赖的实用方法 引言1. 使用 npm update 命令2. 使用 npm-check-updates 工具3. 使用 npm outdated 命令4. 直接手动更新 package.json 文件5. 直接安装最新版本6. 使用自动化工具结语 引言 在软件开发的过程中,我们知道依赖管理是其中一个至关重…...
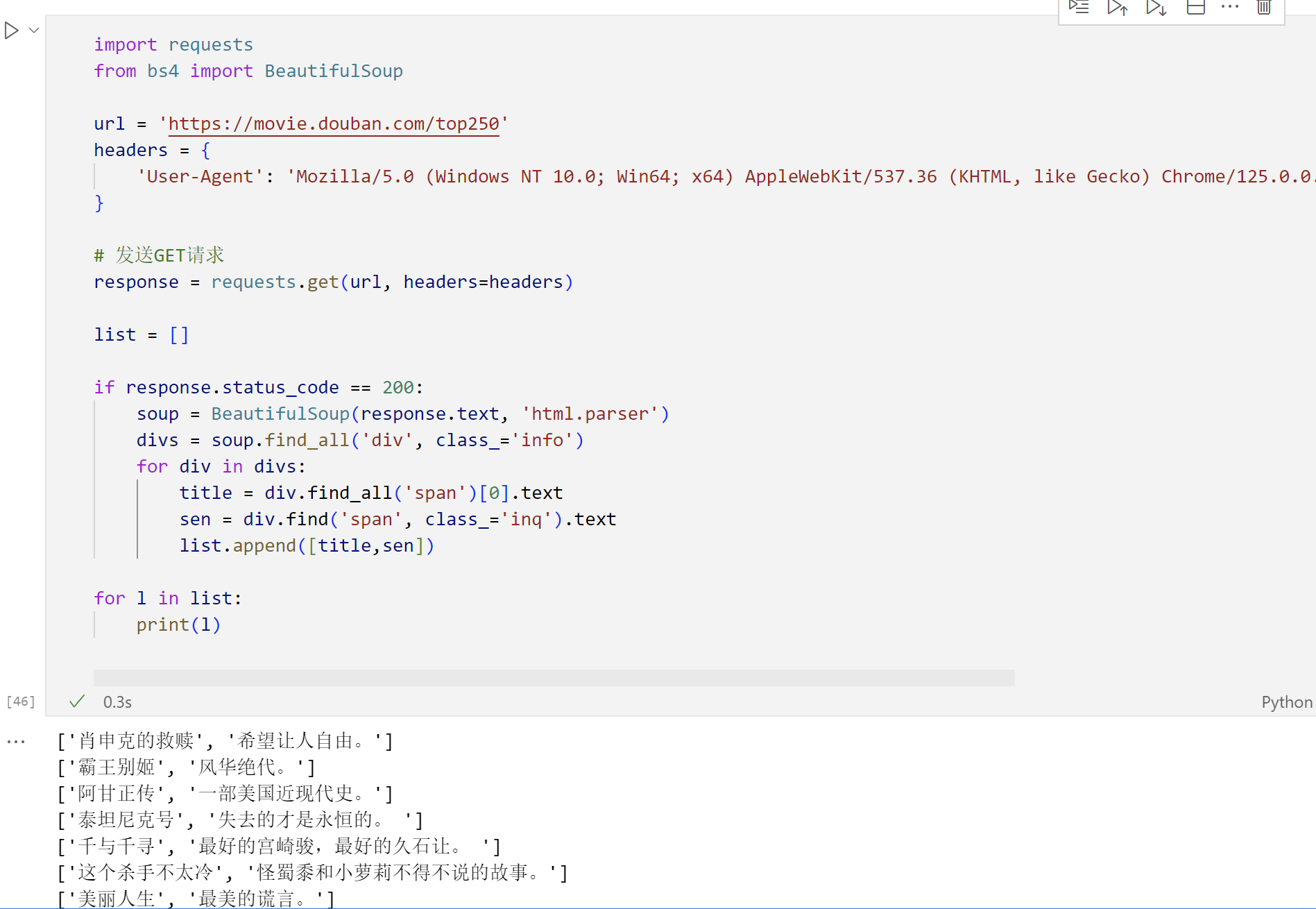
Python爬虫之简单学习BeautifulSoup库,学习获取的对象常用方法,实战豆瓣Top250
BeautifulSoup是一个非常流行的Python库,广泛应用于网络爬虫开发中,用于解析HTML和XML文档,以便于从中提取所需数据。它是进行网页内容抓取和数据挖掘的强大工具。 功能特性 易于使用: 提供简洁的API,使得即使是对网页结构不熟悉…...

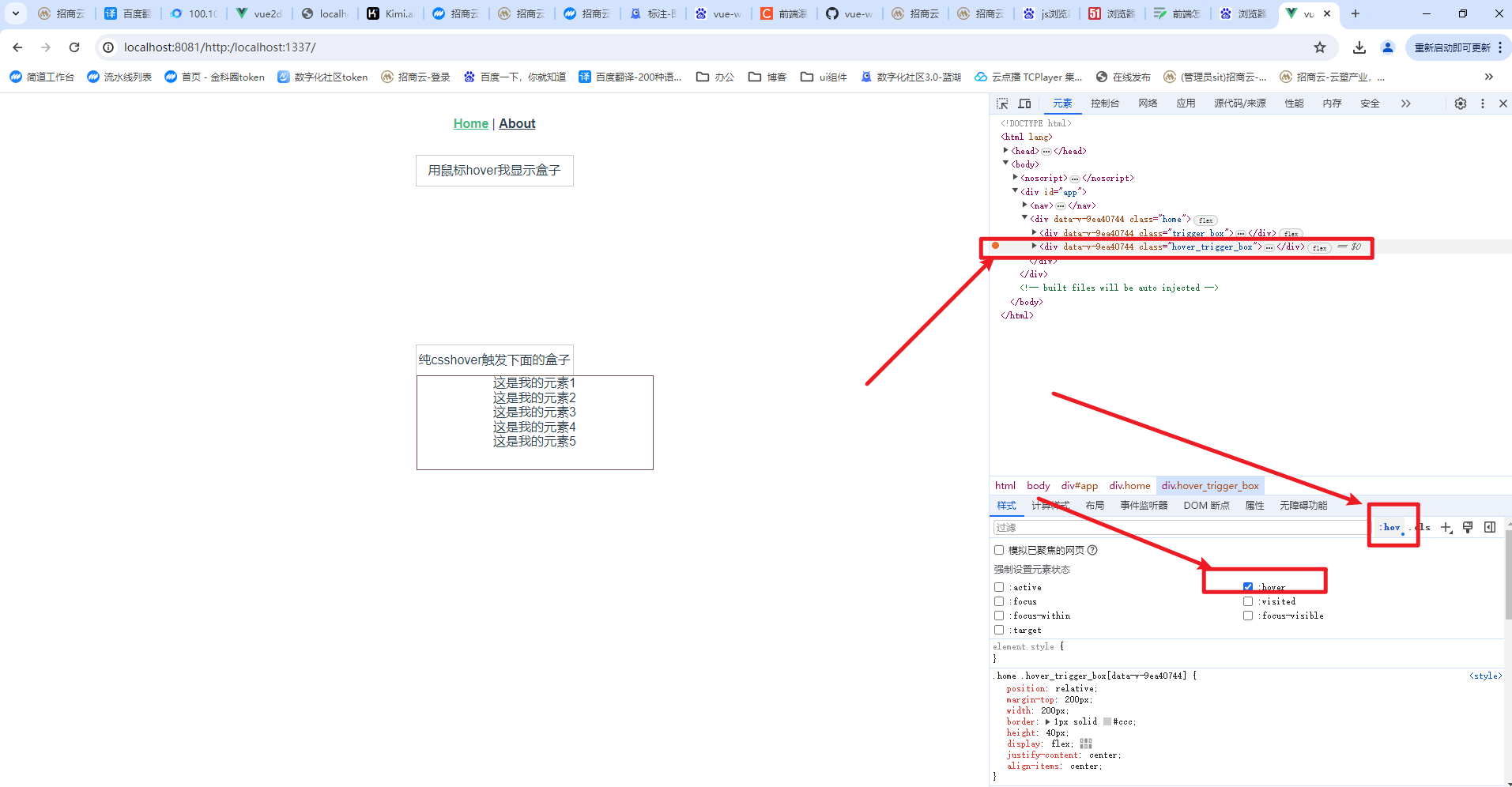
前端怎么debugger排查线上问题
前端怎么debugger排查线上问题 1.问题背景2.问题详细说明3.处理方案a.开发环境怎么找,步骤一样的:b.生产环境怎么找,步骤一样的:还有一种情况就是你的子盒子是使用csshover父盒子出来的, 4.demo地址: 1.问题…...
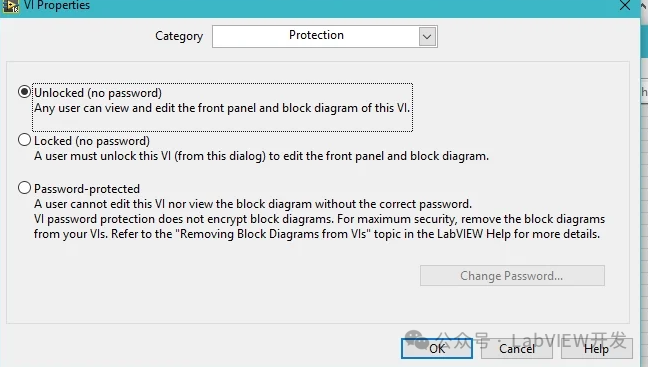
LabVIEW源程序安全性保护综合方案
LabVIEW源程序安全性保护综合方案 一、硬件加密保护方案 选择和安装硬件设备 选择加密狗和TPM设备:选择Sentinel HASP加密狗和支持TPM(可信平台模块)的计算机主板。 安装驱动和开发工具:安装Sentinel HASP加密狗的驱动程序和开发…...

JiYuTrainer:如何在不影响学习的前提下解除极域电子教室限制的3种方法
JiYuTrainer:如何在不影响学习的前提下解除极域电子教室限制的3种方法 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 在数字化教学环境中,极域电子教室&a…...

Python量化投资终极指南:用mootdx轻松获取通达信金融数据
Python量化投资终极指南:用mootdx轻松获取通达信金融数据 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 还在为获取金融数据而烦恼吗?面对复杂的API接口和昂贵的数据服务&…...
Pixel Dream Workshop生成内容的数据存储与数据库设计
Pixel Dream Workshop生成内容的数据存储与数据库设计 1. 引言:当AI绘画遇上数据管理 想象一下,你运营着一个拥有10万活跃用户的AI绘画平台。每天,用户们上传数十万条创意提示词,生成数百万张风格各异的数字艺术作品。这些数据不…...

AcousticSense AI入门指南:零代码实现专业级音乐风格识别
AcousticSense AI入门指南:零代码实现专业级音乐风格识别 1. 为什么选择AcousticSense AI? 1.1 音乐风格识别的技术革新 传统音乐分类方法通常需要复杂的特征工程和专业知识,而AcousticSense AI采用了一种革命性的方法——让AI"看&qu…...

SEO推广合作价目表对网站排名有什么影响_SEO推广合作价目表的合理定价原则是什么
SEO推广合作价目表对网站排名有什么影响 在当今数字化时代,网站的SEO推广合作价目表不仅仅是企业与营销公司之间的商业协议,更是影响网站在搜索引擎上排名的一个重要因素。SEO推广合作价目表如何制定,对于提升网站的搜索引擎排名有着至关重要…...

HunyuanVideo-FoleyGPU算力适配:RTX4090D与A100/H100推理性能对比
HunyuanVideo-FoleyGPU算力适配:RTX4090D与A100/H100推理性能对比 1. 引言 在视频生成与音效合成领域,HunyuanVideo-Foley作为一款集成视频生成和Foley音效合成的AI模型,对GPU算力有着极高的要求。本文将重点对比RTX4090D与专业级A100/H100…...

OpenClaw压力测试:gemma-3-12b-it持续任务下的资源占用优化
OpenClaw压力测试:gemma-3-12b-it持续任务下的资源占用优化 1. 为什么需要关注OpenClaw的资源占用? 上周我在自己的MacBook Pro上部署了OpenClaw,想让它帮我自动化处理一些日常文档整理工作。最初几小时运行得很顺利,但第二天早…...

Youtu-VL-4B-Instruct WebUI部署教程:Nginx反向代理配置+HTTPS安全访问完整方案
Youtu-VL-4B-Instruct WebUI部署教程:Nginx反向代理配置HTTPS安全访问完整方案 1. 引言:为什么需要反向代理和HTTPS? 如果你已经成功部署了Youtu-VL-4B-Instruct的WebUI,现在可以直接通过 http://服务器IP:7860 访问,…...
)
手把手教你用Python复刻‘双紫擒龙’量化指标(附完整源码与回测)
手把手教你用Python复刻‘双紫擒龙’量化指标(附完整源码与回测) 在量化交易领域,技术指标的神秘面纱常常让初学者望而却步。今天,我们将用Python彻底拆解这个名为"双紫擒龙"的指标,从数据获取到可视化回测&…...

OpenClaw语音交互扩展:Qwen3-14b_int4_awq对接Whisper实现语音指令
OpenClaw语音交互扩展:Qwen3-14b_int4_awq对接Whisper实现语音指令 1. 为什么需要语音交互能力 作为一个长期依赖键盘输入的开发者,我最初对语音交互持怀疑态度——直到上个月连续加班导致手腕腱鞘炎发作。当连敲空格键都变成折磨时,才意识…...