【JavaEE进阶】——MyBatis操作数据库 (#{}与${} 以及 动态SQL)
目录
🚩#{}和${}
🎈#{} 和 ${}区别
🎈${}使用场景
📝排序功能
📝like 查询
🚩数据库连接池
🎈数据库连接池使⽤
🚩MySQL开发企业规范
🚩动态sql
🎈<if>标签
🎈<trim>标签
🎈<where>标签
🎈<set>标签
🎈<foreach>标签
🎈<include>标签
🚩#{}和${}
<select id="selectById">select * from userinfo where id=#{id};</select>@Testvoid selectById() {UserInfo userInfo=userInfoXmlMapper2.selectById(1);System.out.println(userInfo);}
发现我们输出的SQL语句:Preparing: select * from userinfo where id=?;我们输⼊的参数并没有在后⾯拼接, id的值是使⽤ ? 进⾏占位. 这种SQL 我们称之为"预编译SQL"MySQL 课程 JDBC编程使⽤的就是预编译SQL, 此处不再多说

我们把 #{} 改成 ${} 再观察打印的⽇志:<select id="selectById">select * from userinfo where id=${id};</select>
我们看到,参数直接拼接到语句中去了。而不是像#{}这种先用?占位,然后传参的时候给1给?。

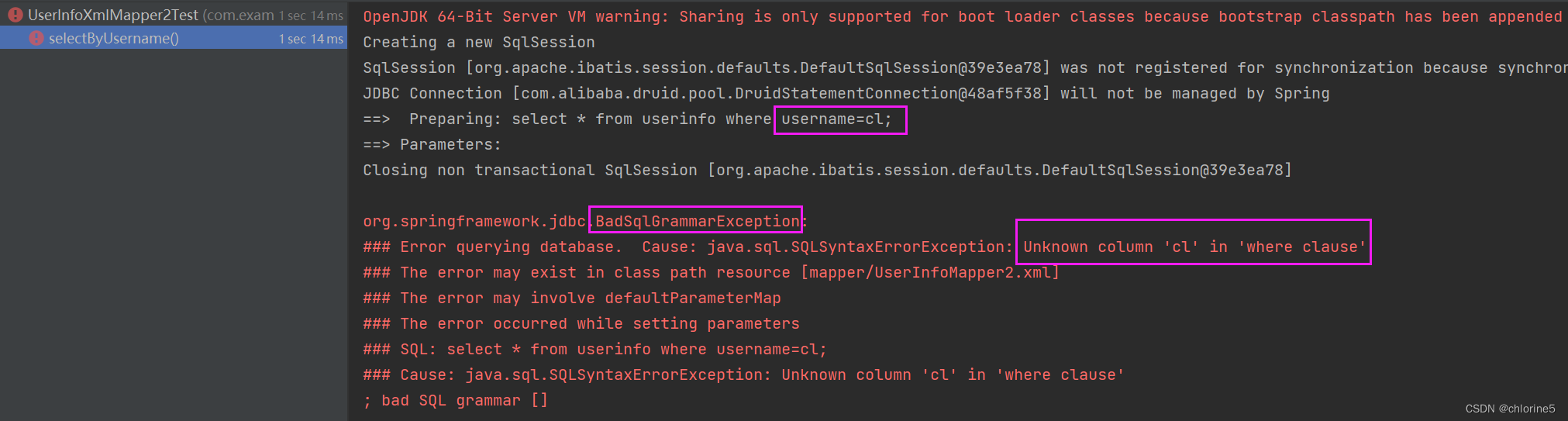
2、 接下来我们再看String类型的参数<select id="selectByUsername">select * from userinfo where username=#{username};</select>@Testvoid selectByUsername() {List<UserInfo> userInfos=userInfoXmlMapper2.selectByUsername("cl");System.out.println(userInfos);}
此时用?号进行占位,然后传参数cl(string)并标注了string类型的字符串。

我们把 #{} 改成 ${} 再观察打印的⽇志<select id="selectByUsername">select * from userinfo where username=${username};</select>
可以看到, 这次的参数依然是直接拼接在SQL语句中了, 但是 字符串作为参数时, 需要添加引号 '' , 使⽤ ${} 不会拼接引号 '' , 导致程序报错这时候我们就可以在 ${username}外加引号 ,因为${}是拼接,在string类型中不会自动加入引号,需要我们手动加入引号<select id="selectByUsername">select * from userinfo where username='${username}';</select>
此时运行成功。

从上⾯两个例⼦可以看出:
- #{} 使⽤的是预编译SQL, 通过 ? 占位的⽅式, 提前对SQL进⾏编译, 然后把参数填充到SQL语句中. #{} 会根据参数类型, ⾃动拼接引号 '' .
- ${} 会直接进⾏字符替换, ⼀起对SQL进⾏编译. 如果参数为字符串, 需要加上引号 '' .
参数为数字类型时, 也可以加上, 查询结果不变, 但是可能会导致索引失效, 性能下降
🎈#{} 和 ${}区别
#{} 和 ${} 的区别就是预编译SQL和即时SQL 的区别:
深层区别:当客⼾发送⼀条SQL语句给服务器后, ⼤致流程如下:
- 1. 解析语法和语义, 校验SQL语句是否正确
- 2. 优化SQL语句, 制定执⾏计划
- 3. 执⾏并返回结果
⼀条 SQL如果⾛上述流程处理, 我们称之为 Immediate Statements(即时 SQL)📝#{}性能更⾼绝⼤多数情况下, 某⼀条 SQL 语句可能会被反复调⽤执⾏, 或者每次执⾏的时候只有个别的值不同(⽐如 select 的 where ⼦句值不同, update 的 set ⼦句值不同, insert 的 values 值不同). 如果每次都需要经过上⾯的语法解析, SQL优化、SQL编译等,则效率就明显不⾏了预编译SQL,编译⼀次之后会将编译后的SQL语句缓存起来,后⾯再次执⾏这条语句时,不会再次编译 (只是输⼊的参数不同), 省去了解析优化等过程, 以此来提⾼效率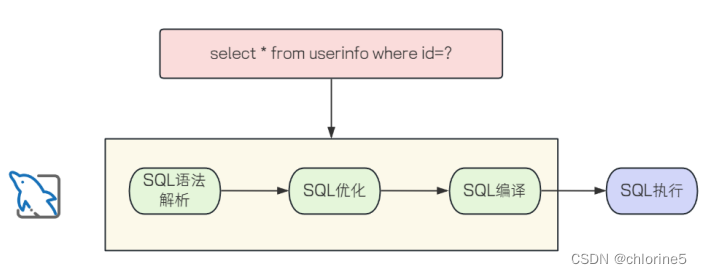
📝#{}更安全(防⽌SQL注⼊)SQL注⼊:是通过操作输⼊的数据来修改事先定义好的SQL语句,以达到执⾏代码对服务器进⾏攻击的⽅法。由于没有对⽤⼾输⼊进⾏充分检查,⽽ 即时SQL⼜是拼接⽽成 ,在⽤⼾输⼊参数时,在参数中添加⼀些SQL关键字,达到改变SQL运⾏结果的⽬的,也可以完成恶意攻击。sql 注⼊代码: ' or 1='1先来看看SQL注⼊的例⼦正常${username}拼接<select id="queryByUsername">select * from userinfo where username='${username}';</select>@Testvoid queryByUsername() {List<UserInfo> infoList=userInfoXmlMapper2.queryByUsername("admin");System.out.println(infoList);}
SQL注⼊场景: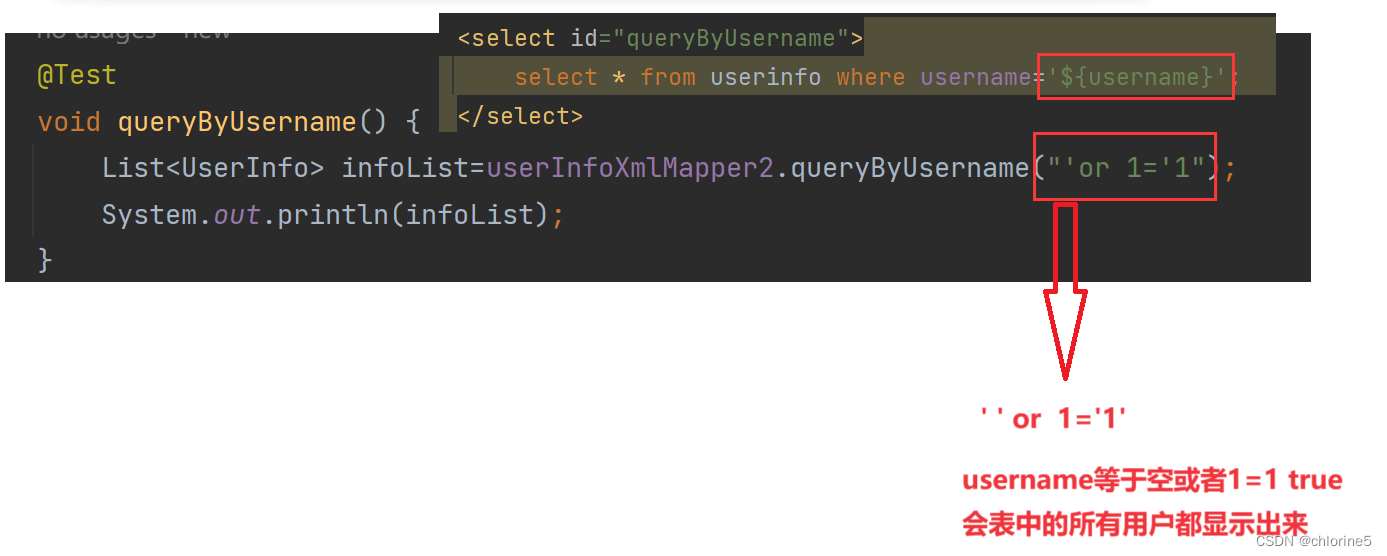 结果依然被正确查询出来了, 其中参数 or被当做了SQL语句的⼀部分
结果依然被正确查询出来了, 其中参数 or被当做了SQL语句的⼀部分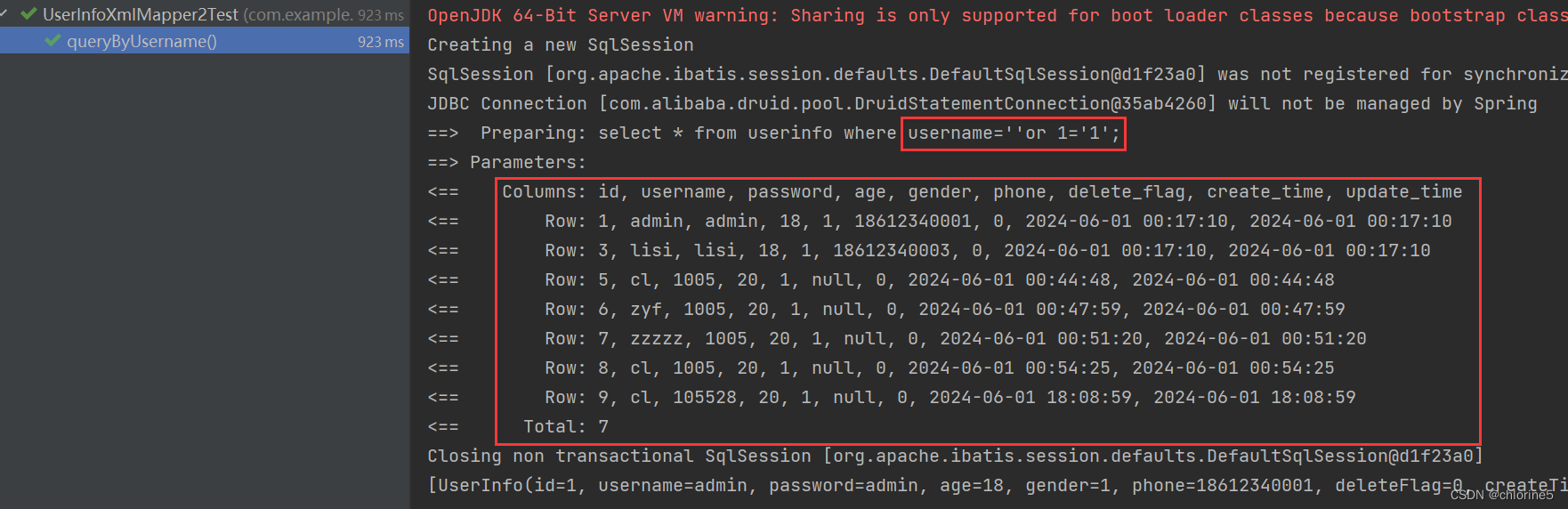 可以看出来, 查询的数据并不是⾃⼰想要的数据. 所以⽤于查询的字段,尽量使⽤ #{} 预查询的⽅式SQL注⼊是⼀种⾮常常⻅的数据库攻击⼿段, SQL注⼊漏洞也是⽹络世界中最普遍的漏洞之⼀. 如果发⽣在⽤⼾登录的场景中, 密码输⼊为 ' or 1='1 , 就可能完成登录(不是⼀定会发⽣的场景, 需要看登录代码如何写)
可以看出来, 查询的数据并不是⾃⼰想要的数据. 所以⽤于查询的字段,尽量使⽤ #{} 预查询的⽅式SQL注⼊是⼀种⾮常常⻅的数据库攻击⼿段, SQL注⼊漏洞也是⽹络世界中最普遍的漏洞之⼀. 如果发⽣在⽤⼾登录的场景中, 密码输⼊为 ' or 1='1 , 就可能完成登录(不是⼀定会发⽣的场景, 需要看登录代码如何写)

- #{}:预编译处理, ${}:字符直接替换
- #{} 可以防⽌SQL注⼊, ${}存在SQL注⼊的⻛险, 查询语句中, 可以使⽤ #{} ,推荐使⽤ #{}
- 但是⼀些场景, #{} 不能完成, ⽐如 排序功能, 表名, 字段名作为参数时, 这些情况需要使⽤${}
- 模糊查询虽然${}可以完成, 但因为存在SQL注⼊的问题,所以通常使⽤mysql内置函数concat来完成
🎈${}使用场景
📝排序功能
我们看到sql注入的风险之后,我们尽量是使用#{},但是有些场景就得需要使用拼接形式
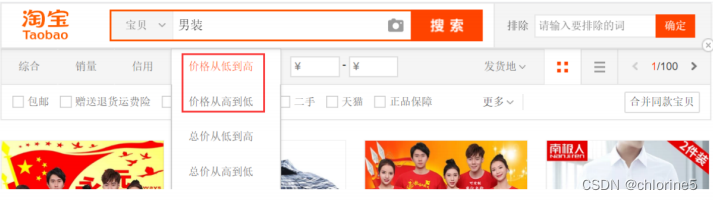
比如以下语句
- select * from userinfo order by id ${sort} 使⽤ ${sort} 可以实现排序查询, ⽽使⽤ #{sort} 就不能实现排序查询了.
这些都是不用加上单引号的 ,而我们的#{}方式虽然是预处理,但是都是会自动增加''形式。而${}形式则是以拼接的形式进行。
注意: 此处 sort 参数为String类型, 但是SQL语句中, 排序规则是不需要加引号 '' 的, 所以此时的 ${sort} 也不加引号
<select id="queryAllUserBySort">select * from userinfo order by id ${sort};</select> @Testvoid queryAllUserBySort() {List<UserInfo>infoList=userInfoXmlMapper2.queryAllUserBySort("asc");System.out.println(infoList);}让id以升序来排序。

<select id="queryAllUserBySort">select * from userinfo order by id #{sort};</select>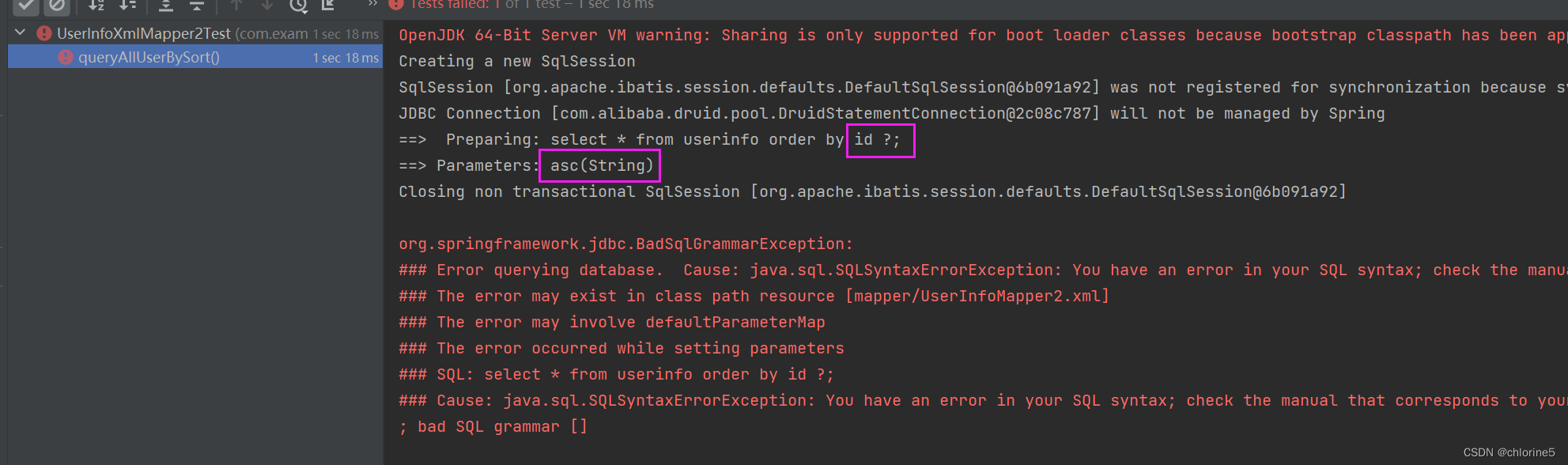

可以发现, 当使⽤ #{sort} 查询时, asc 前后⾃动给加了引号, 导致 sql 错误
除此之外, 还有表名作为参数时, 也只能使⽤ ${}
📝like 查询
我们回顾以下,like的语句是什么,我们在mysql中实验一波~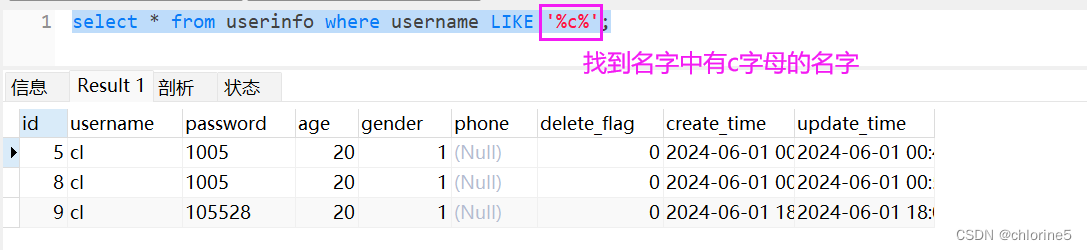 ‘%#{username}%’
‘%#{username}%’<select id="queryAllUserByLike">select * from userinfo where username like '%#{key}%';</select>‘%#{key}%’ —— ‘%?%’ —— ‘%’zhangsan’%’ 解析都无法完成
@Testvoid queryAllUserByLike() {List<UserInfo> infoList=userInfoXmlMapper2.queryAllUserByLike("c");System.out.println(infoList);}
这是我实验的三种方式,都是不行。
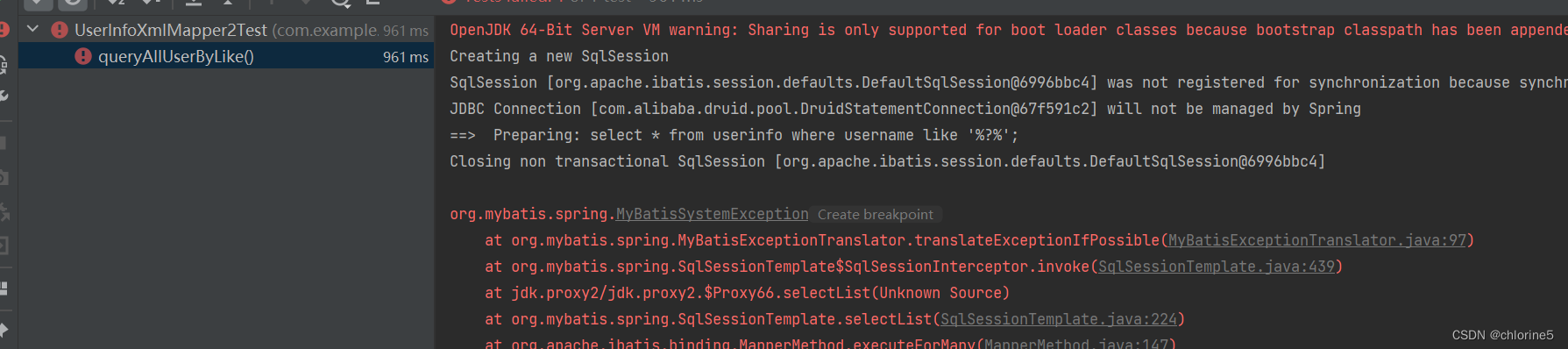

解决办法: 使⽤ mysql 的内置函数 concat() 来处理 ,实现代码如下<select id="queryAllUserByLike">select * from userinfo where username like concat('%',#{key},'%');</select>
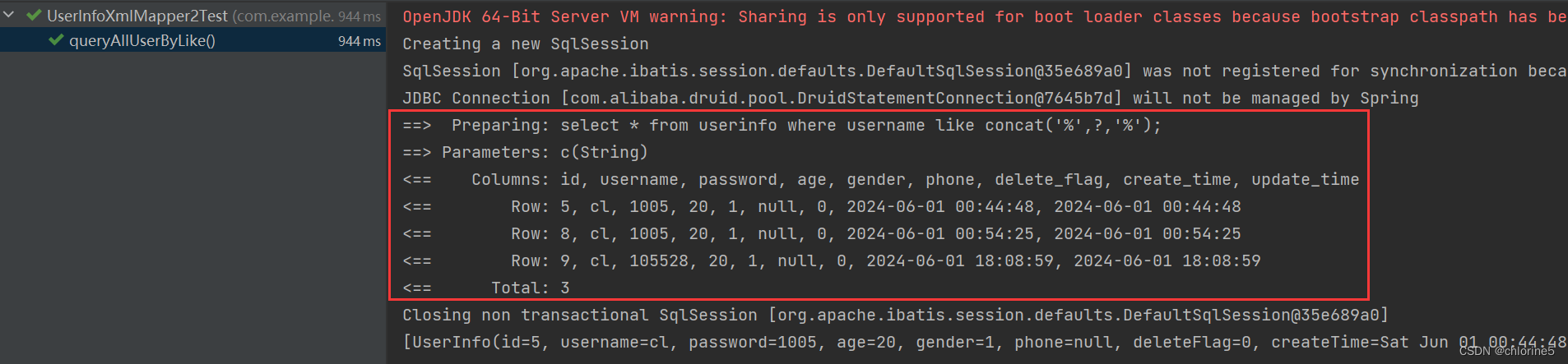
🚩数据库连接池
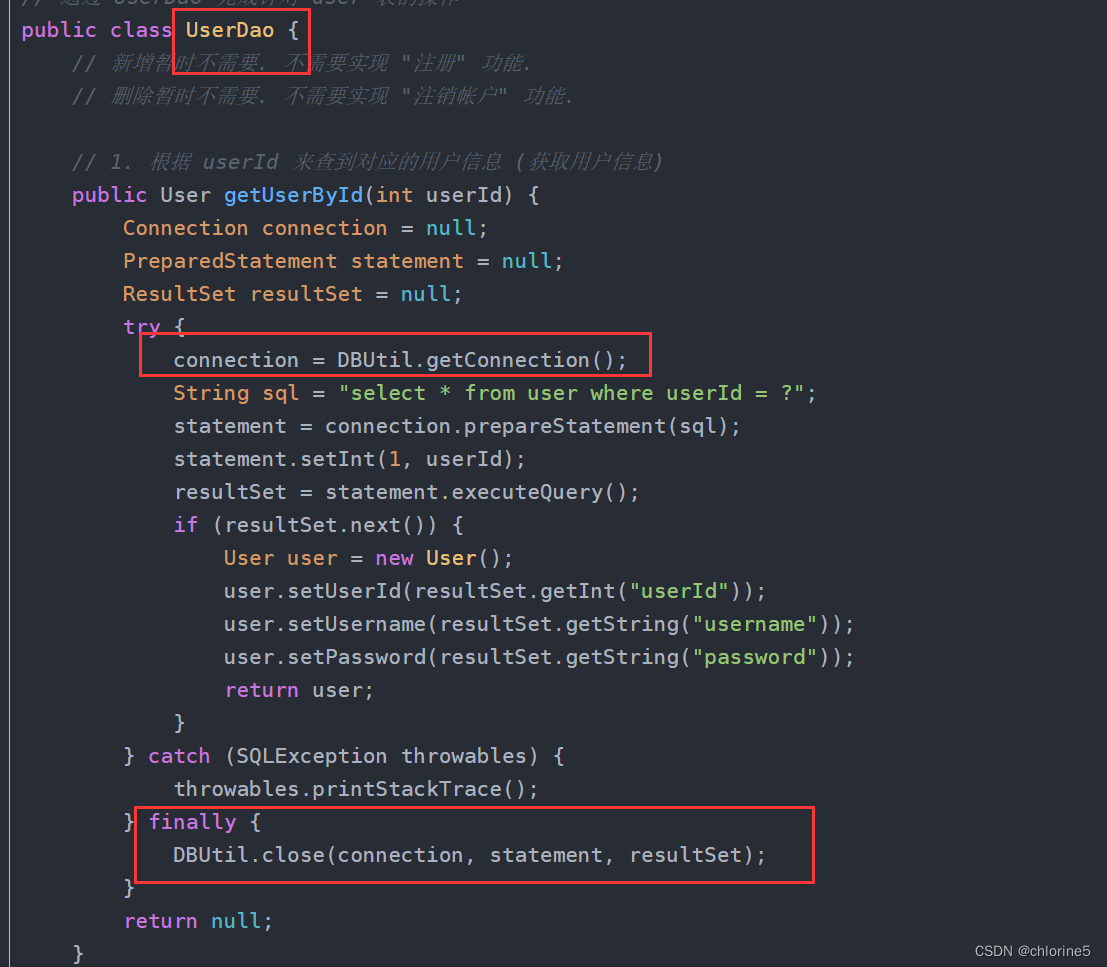
数据库连接池负责分配、管理和释放数据库连接,它允许应⽤程序重复使⽤⼀个现有的数据库连接,⽽不是再重新建⽴⼀个.我们在之前学习jdbc,我们都是没创建一个类都要进行创建连接和销毁连接。在管理博客列表和用户列表的时候,都是需要先建立连接,然后销毁连接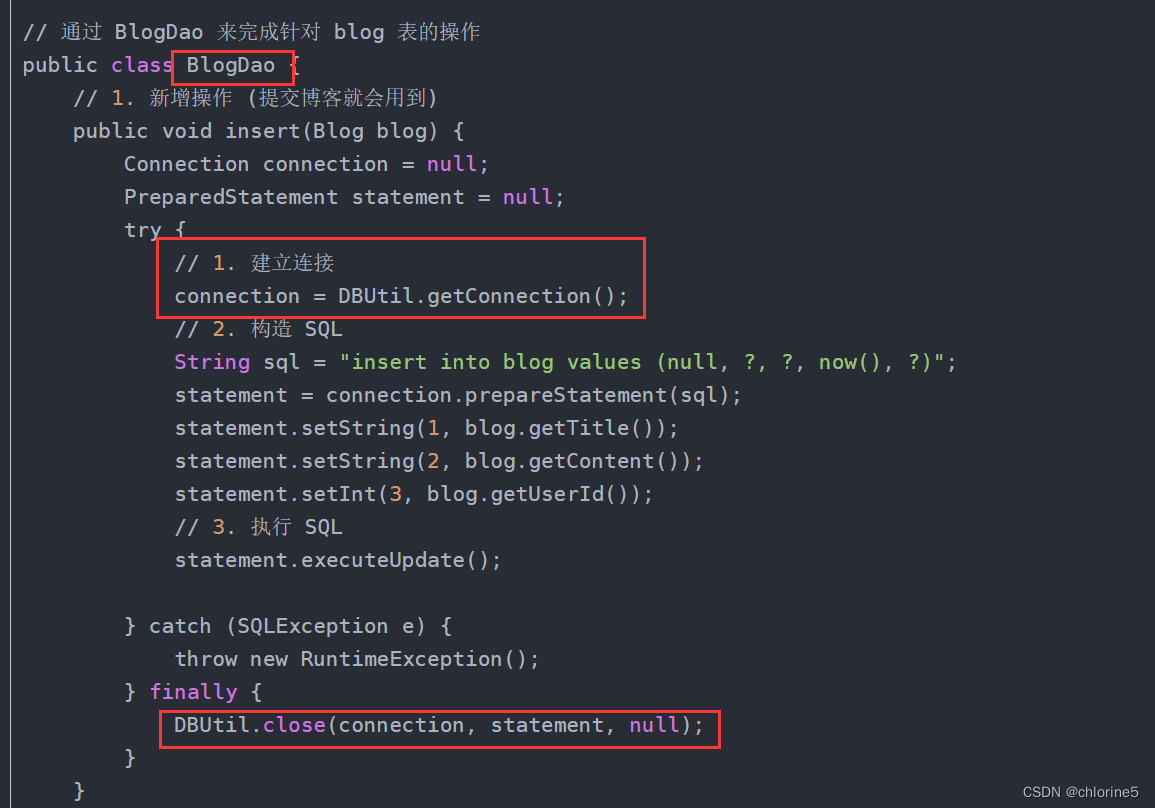
 我们现在用的就是数据库连接池,我们在配置文件中, 程序启动时, 会在数据库连接池中创建⼀定数量的Connection对象, 当客⼾ 请求数据库连接池, 会从数据库连接池中获取Connection对象, 然后执⾏SQL, SQL语句执⾏完, 再把 Connection归还给连接池
我们现在用的就是数据库连接池,我们在配置文件中, 程序启动时, 会在数据库连接池中创建⼀定数量的Connection对象, 当客⼾ 请求数据库连接池, 会从数据库连接池中获取Connection对象, 然后执⾏SQL, SQL语句执⾏完, 再把 Connection归还给连接池
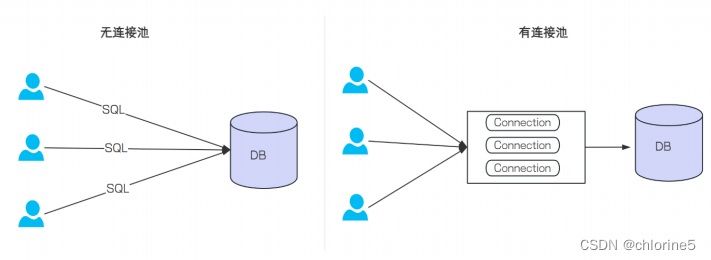
- 没有使⽤数据库连接池的情况: 每次执⾏SQL语句, 要先创建⼀个新的连接对象, 然后执⾏SQL语句, SQL 语句执⾏完, 再关闭连接对象释放资源. 这种重复的创建连接, 销毁连接⽐较消耗资源。
- 使⽤数据库连接池的情况: 程序启动时, 会在数据库连接池中创建⼀定数量的Connection对象, 当客⼾ 请求数据库连接池, 会从数据库连接池中获取Connection对象, 然后执⾏SQL, SQL语句执⾏完, 再把 Connection归还给连接池
优点:1. 减少了⽹络开销2. 资源重⽤3. 提升了系统的性能
🎈数据库连接池使⽤
常⻅的数据库连接池:
- • C3P0
- • DBCP
- • Druid
- • Hikari
⽬前⽐较流⾏的是 Hikari, Druid1. Hikari : SpringBoot默认使⽤的数据库连接池 Hikari 是⽇语"光"的意思(ひかり), Hikari也是以追求性能极致为⽬标2. Druid如果我们想把默认的数据库连接池切换为Druid数据库连接池, 只需要引⼊相关依赖即可
Hikari 是⽇语"光"的意思(ひかり), Hikari也是以追求性能极致为⽬标2. Druid如果我们想把默认的数据库连接池切换为Druid数据库连接池, 只需要引⼊相关依赖即可<dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-3-starter</artifactId><version>1.2.21</version></dependency>

🚩MySQL开发企业规范
MySQL 在 Windows 下不区分⼤⼩写, 但在 Linux 下默认是区分⼤⼩写. 因此, 数据库名, 表名, 字段名都不允许出现任何⼤写字⺟, 避免节外⽣枝正例: aliyun_admin, rdc_config, level3_name反例: AliyunAdmin, rdcConfig, level_3_name
id 必为主键, 类型为 bigint unsigned, 单表时⾃增, 步⻓为 1create_time, update_time 的类型均为 datetime 类型, create_time表⽰创建时间, update_time表⽰更新时间有同等含义的字段即可, 字段名不做强制要求
1. 增加查询分析器解析成本2. 增减字段容易与 resultMap 配置不⼀致3. ⽆⽤字段增加⽹络消耗, 尤其是 text 类型的字段
🚩动态sql
🎈<if>标签


⽐如添加的时候性别 gender 为⾮必填字段,具体实现如下:
<insert id="insertUserByCondition">insert into userinfo (username,`password`,age,<if test="gender!=null">gender,</if>phone) values (#{username},#{password},#{age},<if test="gender!=null">#{gender},</if>#{phone});</insert>
gender不为空的情况下:
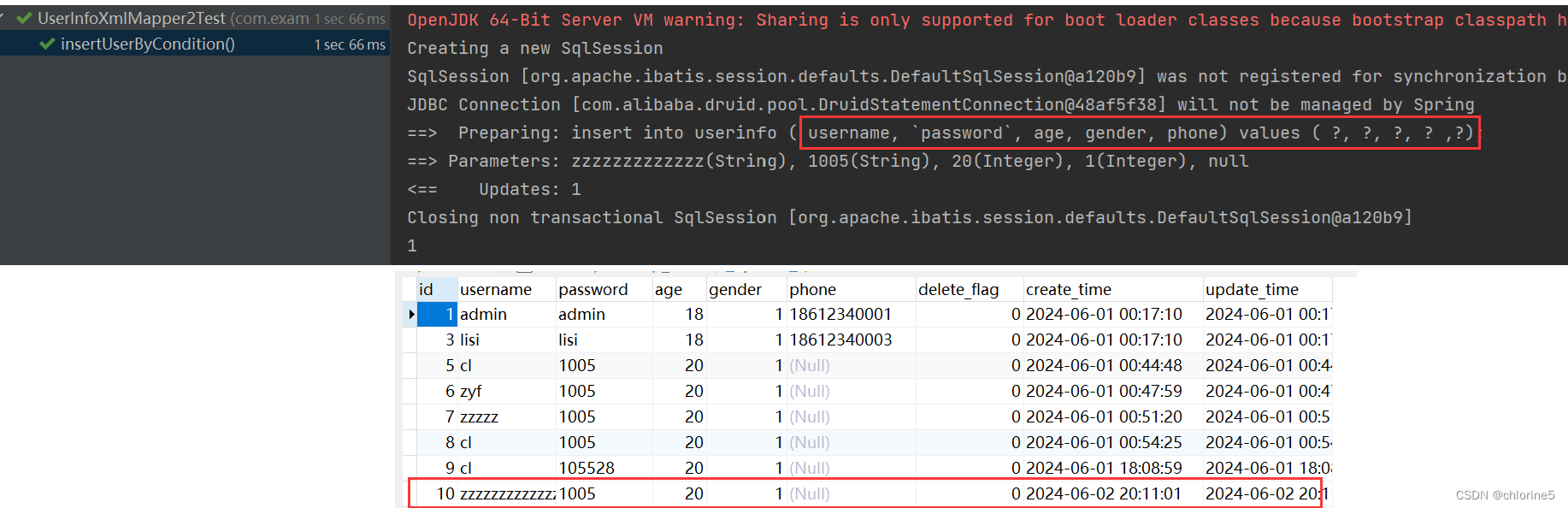 gender为空的情况下:
gender为空的情况下:
 没有gender字段。
没有gender字段。
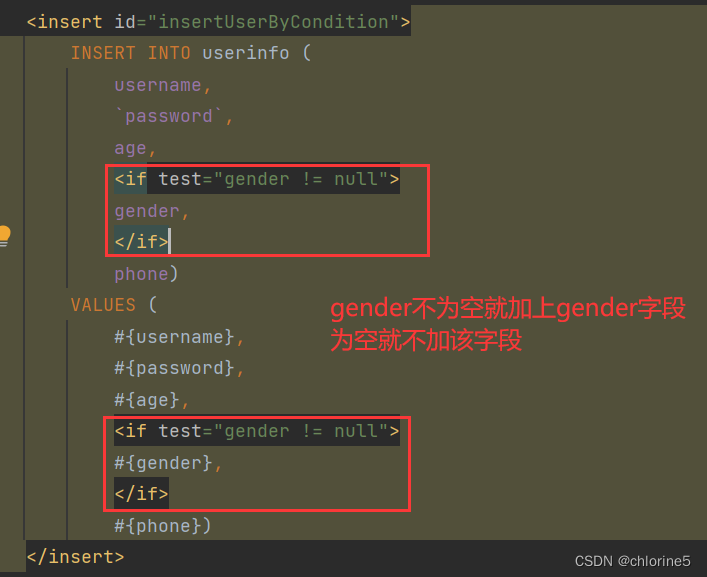
比如gender,phone都为不必要不填写的情况
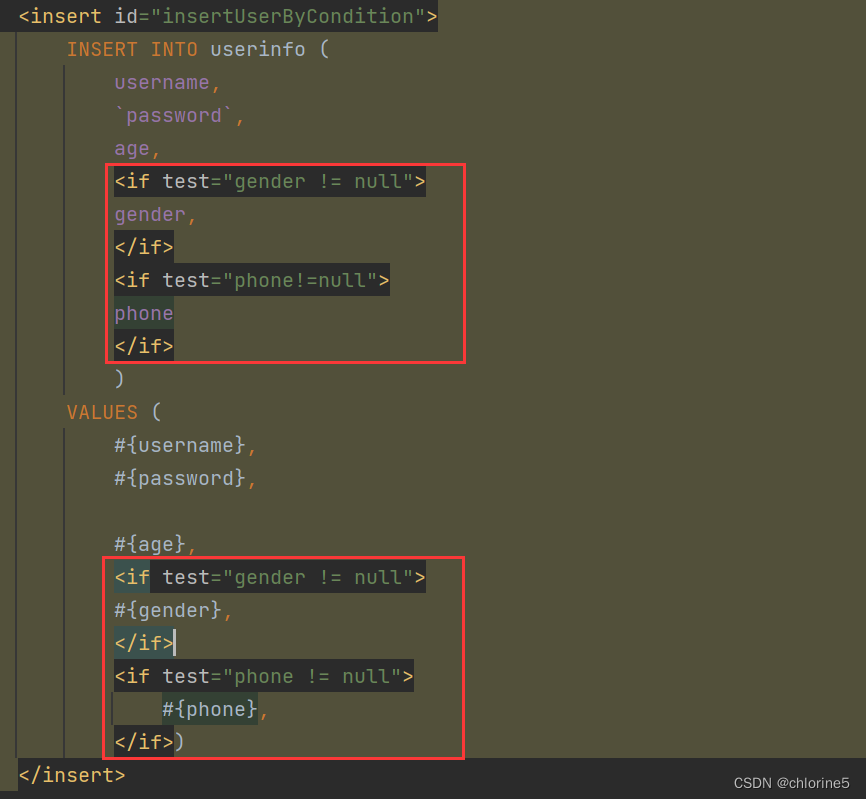
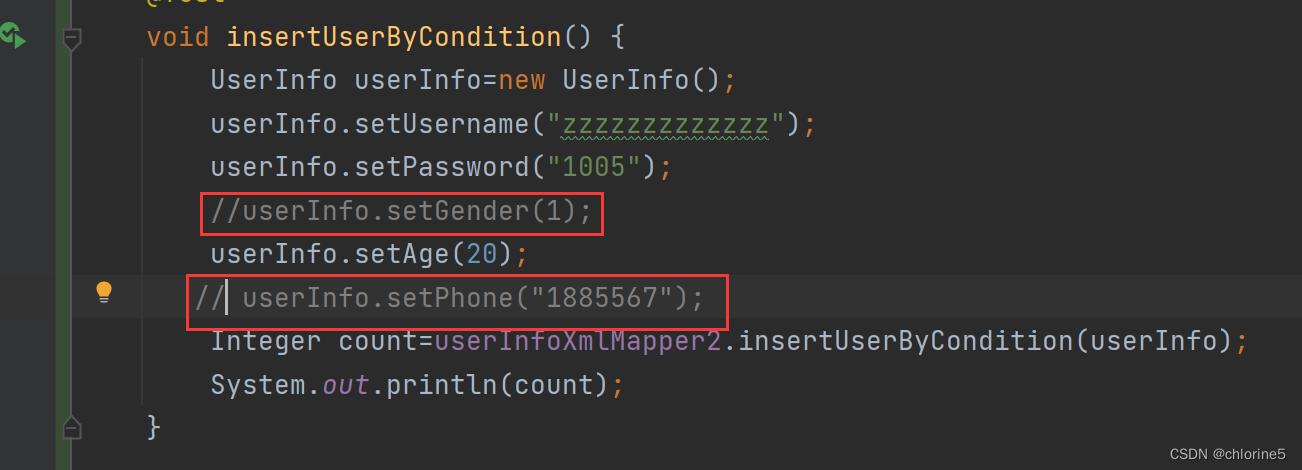
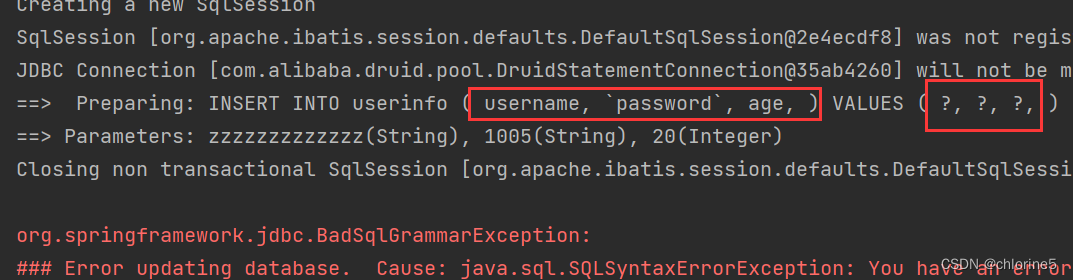
此时会让整个语句多了个逗号。
为了防止多加了前面逗号或者前面逗号,此时引入了<trim>标签形式。
🎈<trim>标签
标签中有如下属性:
- • prefix:表⽰整个语句块,以prefix的值作为前缀
- • suffix:表⽰整个语句块,以suffix的值作为后缀
- • prefixOverrides:表⽰整个语句块要去除掉的前缀
- • suffixOverrides:表⽰整个语句块要去除掉的后缀
<insert id="insertUserByCondition">INSERT INTO userinfo<trim prefix="(" suffix=")" suffixOverrides=","><if test="username != null">username,</if><if test="password != null">`password`,</if><if test="age != null">age,</if><if test="gender != null">gender,</if><if test="phone!=null">phone</if></trim>VALUES<trim prefix="(" suffix=")" suffixOverrides=","><if test="username != null">#{username},</if><if test="password != null">#{password},</if><if test="age != null">#{age},</if><if test="gender != null">#{gender},</if><if test="phone!=null">#{phone}</if></trim></insert>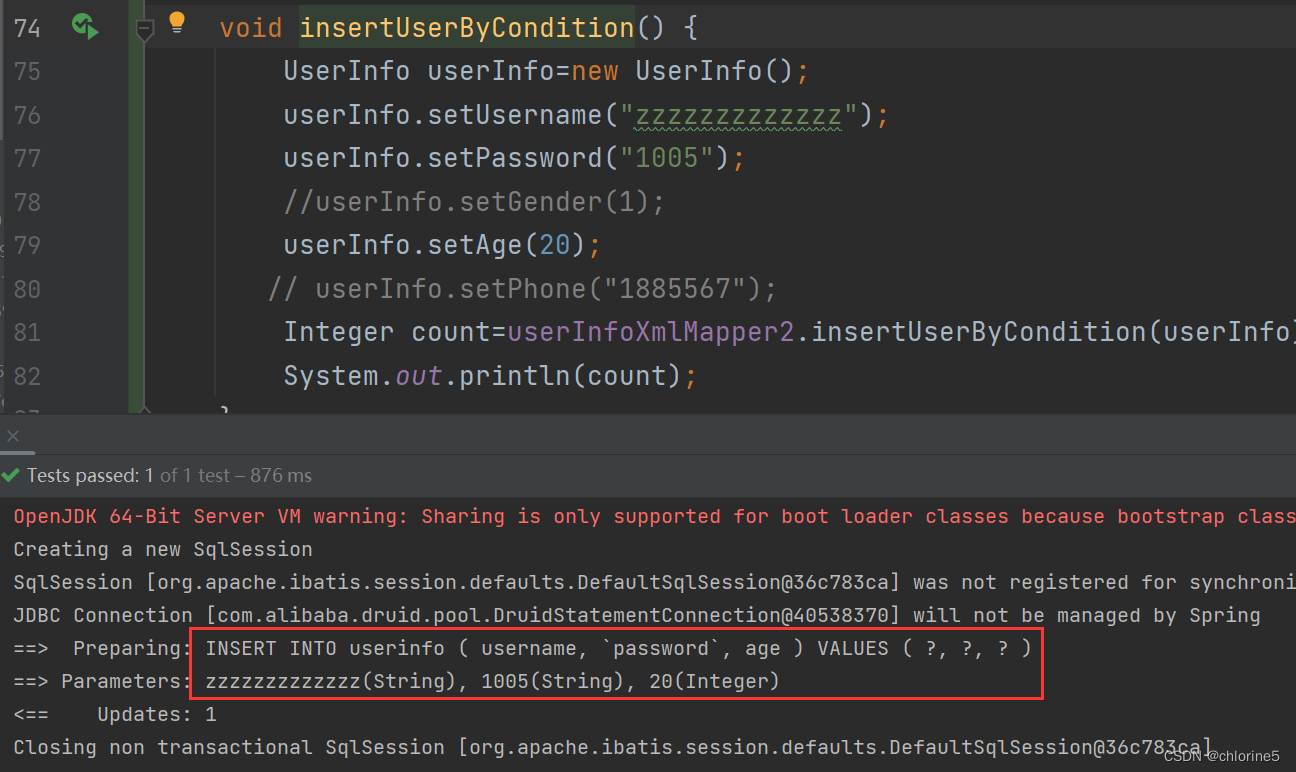
在以上 sql 动态解析时,会将第⼀个 部分做如下处理:
- • 基于 prefix 配置,开始部分加上 (
- • 基于 suffix 配置,结束部分加上 )
- • 多个 组织的语句都以 , 结尾,在最后拼接好的字符串还会以 , 结尾,会基于 suffixOverrides 配置去掉最后⼀个 ,
- • 注意 <if test="username !=null"> 中的 username 是传⼊对象的属性
🎈<where>标签
原有sql
select * from where age=18 and gender=1 and delete_flag=0;
<select id="queryByCondition">select id,username,password,age,gender,phone from userinfo<where><if test="age!=null">age=#{age}</if><if test="gender!=null">and gender=#{gender}</if><if test="deleteFlag!=null">and delete_flag=#{deleteFlag}</if></where></select> @Testvoid queryByCondition() {UserInfo userInfo=new UserInfo();userInfo.setAge(18);userInfo.setGender(1);userInfo.setDeleteFlag(0);List<UserInfo>infoList=userInfoXmlMapper2.queryByCondition(userInfo);System.out.println(infoList);}在三个字段都没填时运行成功。

如果我们没有给age赋值,此时gender不为空,前面有个and,此时where标签是否会自动删除掉前面的and呢?
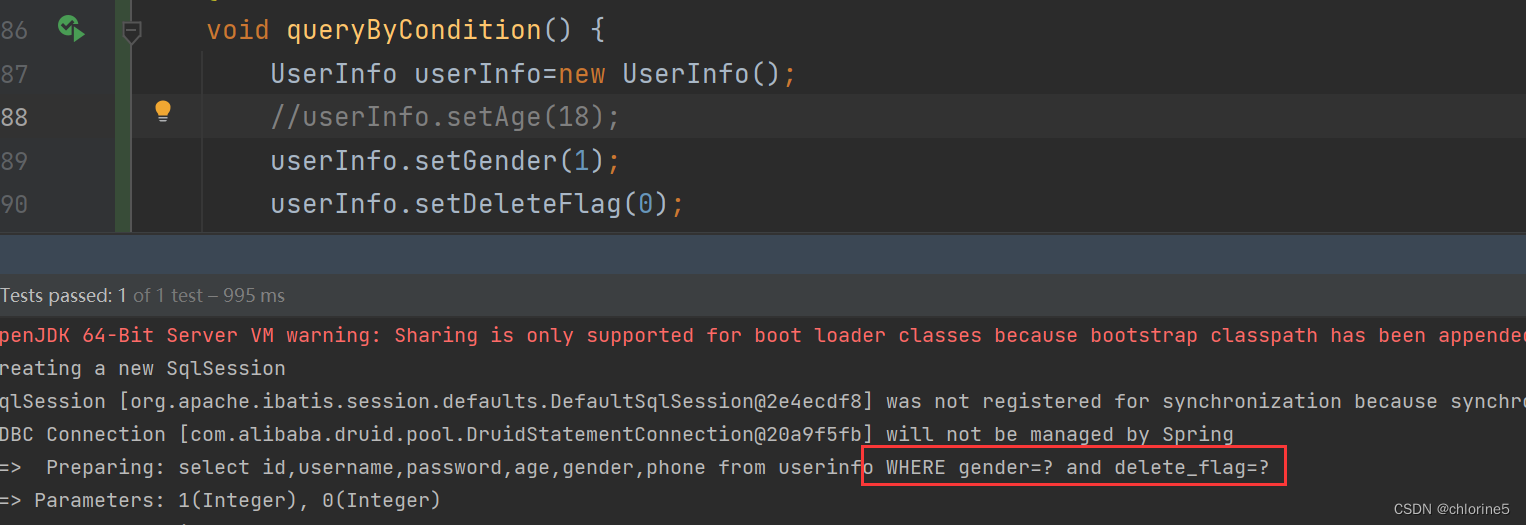
<where> 只会在⼦元素有内容的情况下才插⼊where⼦句,⽽且会⾃动去除⼦句的开头的AND或 OR 以上标签也可以使⽤ <trim prefix="where" prefixOverrides="and"> 替换, 但是此种 情况下, 当⼦元素都没有内容时, where关键字也会保留。
🎈<set>标签
set一般用于更新操作。
<update id="updateUserByCondition">update userinfo<set><if test="username!=null">username=#{username},</if><if test="age!=null">age=#{age},</if><if test="deleteFlag!=null">delete_flag=#{deleteFlag}</if></set>where id=#{id};</update>
如果我们不设置deleteFlag,此时age不为空的情况下,后面的,是多余的,set标签会进行去除掉嘛?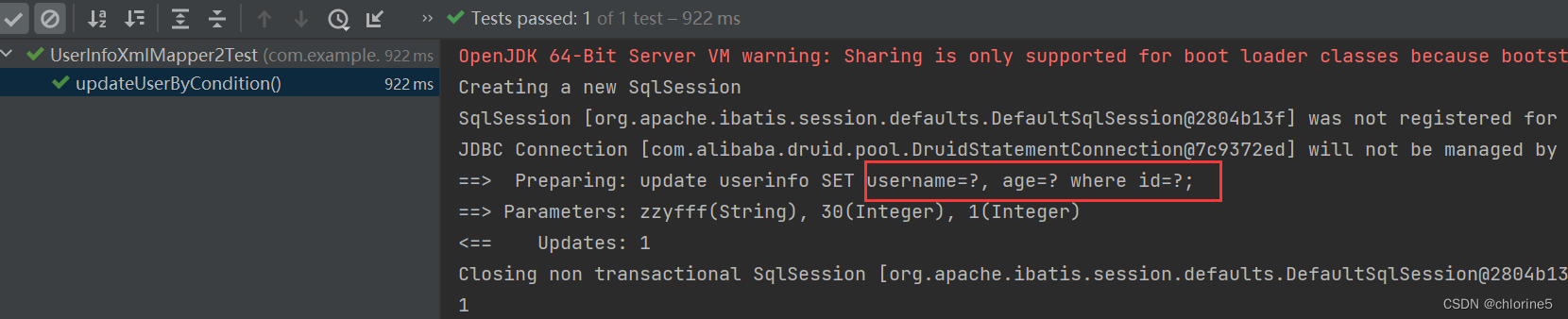 此时set标签会自动删除额外的逗号。
此时set标签会自动删除额外的逗号。
<set> :动态的在SQL语句中插⼊set关键字,并会删掉额外的逗号. (⽤于update语句中) 以上标签也可以使⽤ <trim prefix="set" suffixOverrides=","> 替换
🎈<foreach>标签
对集合进⾏遍历时可以使⽤该标签。标签有如下属性:
- • collection:绑定⽅法参数中的集合,如 List,Set,Map或数组对象
- • item:遍历时的每⼀个对象
- • open:语句块开头的字符串
- • close:语句块结束的字符串
- • separator:每次遍历之间间隔的字符串
需求: 根据多个userid, 删除⽤⼾数据。delete from userinfo where id in (1,2,3);
接⼝⽅法:
ArticleMapper.xml 中新增删除 sql:<delete id="deleteByIds">delete from userinfo where id in<foreach collection="ids" item="id" separator="," open="(" close=")">#{id}</foreach></delete>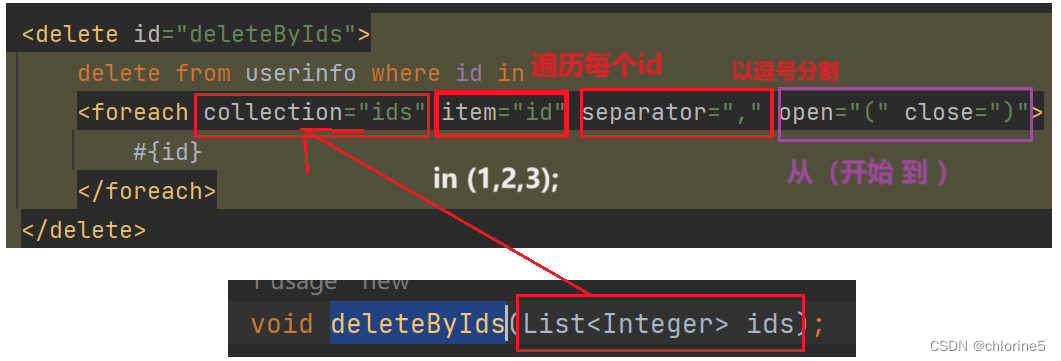
测试
@Testvoid deleteByIds() {List<Integer>integerList=new ArrayList<>();integerList.add(1);integerList.add(2);integerList.add(3);userInfoXmlMapper2.deleteByIds(integerList);}
此时批量删除了id为1,2,3的数据。

🎈<include>标签

我们可以对重复的代码⽚段进⾏抽取, 将其通过 <sql> 标签封装到⼀个SQL⽚段,然后再通过 <include> 标签进⾏引⽤。
- • <sql> :定义可重⽤的SQL⽚段
- • <include> :通过属性refid,指定包含的SQL⽚段

我们每次都只需要查询这几个字段即可(姓名,密码,年龄,性别,电话)即可。我们可以给这个片段抽取出来。
<sql id="allColumn">username,`password`,age,gender,phone</sql> <sql id="allColumn">username,`password`,age,gender,phone</sql><select id="queryAllUser">select<include refid="allColumn"></include>from userinfo</select>
世界变化太快,我只想做个缓慢的行者。
相关文章:
【JavaEE进阶】——MyBatis操作数据库 (#{}与${} 以及 动态SQL)
目录 🚩#{}和${} 🎈#{} 和 ${}区别 🎈${}使用场景 📝排序功能 📝like 查询 🚩数据库连接池 🎈数据库连接池使⽤ 🚩MySQL开发企业规范 🚩动态sql 🎈…...
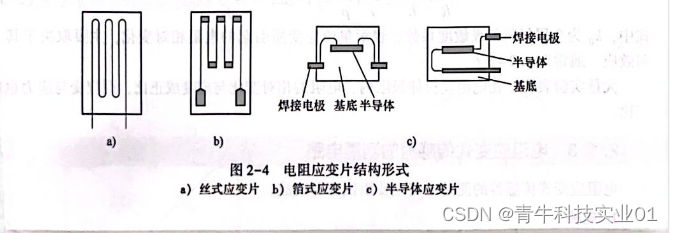
电阻应变片的结构
电阻应变片的结构 常用的电阻应变片有金属应变片和半导体应变片两种。金属应变片分为体型和薄膜型。半导体应变片常见的有体型、薄膜型、扩散型、外延型、PN结及其他形式。图2—2所示为工程常见的应变片实物。 电阻应变片的典型结构如图2—3所示。它由敏感栅、基底、覆盖层和引…...

云原生时代:从 Jenkins 到 Argo Workflows,构建高效 CI Pipeline
作者:蔡靖 Argo Workflows Argo Workflows [ 1] 是用于在 Kubernetes 上编排 Job 的开源的云原生工作流引擎。可以轻松自动化和管理 Kubernetes 上的复杂工作流程。适用于各种场景,包括定时任务、机器学习、ETL 和数据分析、模型训练、数据流 pipline、…...

【数据库系统概论】事务
概述 在数据库系统中,事务(Transaction)是指一组作为单个逻辑工作单元执行的操作。这些操作要么全部成功(提交),要么全部失败(回滚)。事务的主要目的是确保数据库的完整性和一致性&…...
C++-排序算法详解
目录 一. 冒泡排序: 二. 插入排序: 三. 快速排序: 四. 选择排序 五, 归并排序 六, 堆排序. 排序算法是一种将一组数据按照特定顺序(如升序或降序)进行排列的算法。 其主要目的是对一组无序的数据进行整理&#…...
)
Kotlin 引用(双冒号::)
文章目录 双冒号::引用函数普通函数成员函数类构造函数 引用变量(很少用)普通变量成员变量 双冒号:: Kotlin 中可以使用双冒号::对某一变量、函数进行引用。 Note:MyClass::class可用于获取KClass<MyClass>,此时的双冒号::…...
C++ day3练习
设计一个Per类,类中包含私有成员:姓名、年龄、指针成员身高、体重,再设计一个Stu类,类中包含私有成员:成绩、Per类对象p1,设计这两个类的构造函数、析构函数。 #include <iostream>using namespace std;class Per{private:…...
命令模式(行为型)
目录 一、前言 二、命令模式 三、总结 一、前言 命令模式(Command Pattern)是一种行为型设计模式,命令模式将一个请求封装为一个对象,从而可以用不同的请求对客户进行参数化;对请求排队或记录请求日志,以…...

韩雪医生针药结合效果好 患者赠送锦旗表感谢
任先生长年献血身体出现不适,身上多处发黑发冷,伴随疼痛,而且还有慢性腹泻的症状。他曾前往苏州各大医馆做过检查,均查不出异常,但身体确实不舒服,面色晦暗。 后来他来到李良济,求诊于韩雪医生。…...

【队列、堆、栈 解释与区分】
文章目录 概要队列(Queue)定义特性应用场景 堆(Heap)定义特性应用场景 栈(Stack)定义特性应用场景 总结 概要 队列、堆和栈是三种常见的数据结构,它们各自具有不同的特性和应用场景。下面是对这…...

NTP网络时间服务器_安徽京准电钟
NTP网络时间服务器_安徽京准电钟 NTP网络时间服务器_安徽京准电钟 概述 NTP网络时间服务器是一款支持NTP和SNTP网络时间同步协议,高精度、大容量、高品质的高科技时钟产品。 NTP网络时间服务器设备采用冗余架构设计,高精度时钟直接来源于北斗、GPS系统中…...

Java:爬虫框架
一、Apache Nutch2 【参考地址】 Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Nutch 致力于让每个人能很容易, 同时花费很少就可以配置世界一流的Web搜索引擎. 为了完成这一宏伟的目标, Nutch必须能够做到…...

ChatGPT基本原理详细解说
ChatGPT基本原理详细解说 引言 在人工智能领域,自然语言处理(NLP)一直是研究的热点之一。随着技术的发展,我们见证了从简单的聊天机器人到复杂的语言模型的演变。其中,ChatGPT作为一项突破性技术,以其强大…...

Java日期时间处理深度解析:从Date、Calendar到SimpleDateFormat
粉丝福利:微信搜索「万猫学社」,关注后回复「电子书」,免费获取12本Java必读技术书籍。 Java中的日期和时间处理 在Java中,日期和时间的处理一直是一个复杂而繁琐的任务。那么,为什么会这样呢?让我们先来看…...

Flutter 中的 CupertinoUserInterfaceLevel 小部件:全面指南
Flutter 中的 CupertinoUserInterfaceLevel 小部件:全面指南 Flutter 是一个功能强大的 UI 框架,由 Google 开发,允许开发者使用 Dart 语言构建跨平台的移动、Web 和桌面应用。在 Flutter 的 Cupertino(iOS 风格)组件…...

区块链学习记录01
在学习过程中所遇到的问题,及其解。 Q:区块链中分布式账本的存在,让所有人都知道资金的变动吗? A:区块链中的分布式账本确实让参与网络的所有节点都能够了解账户之间的资金变动。这是因为区块链是一个分布式数据库,其中包含着所…...

python--装饰器
[掌握]装饰器入门 语法糖 目标:掌握装饰器的快速使用。 装饰器本质上就是闭包,但装饰器有特殊作用,那就是:在不改变原有函数的基础上,给原有函数增加额外功能。 定义装饰器: def outer([外面参数列表]):…...

Docker:定义未来的软件部署
1. 概述 Docker,这个在技术圈里频频被提及的名词,实际上是一种开源的容器化技术。它允许开发者将应用程序及其依赖打包成一个标准化的单元——容器,确保应用在任何环境中都能够一致地运行。从开发者的本地机器到全球的云平台,Doc…...

ros常用环境变量
RMW层DDS实现 rti dds export RMW_IMPLEMENTATIONrmw_connextdds //rti dds 或者 RMW_IMPLEMENTATIONrmw_connextdds ros2 run ... export NDDS_QOS_PROFILES/qos.xml //配置qos文件fastdds export RMW_IMPLEMENTATIONrmw_fastrtps_cpp 或者 RMW_IMPLEMENTATIONrmw_fas…...

python学习 - 爬虫案例 - 爬取链接房产信息入数据库代码实例
#codingutf-8 #!/usr/bin/python # 导入requests库 import requests # 导入文件操作库 import os import re import bs4 from bs4 import BeautifulSoup import sys from util.mysql_DBUtils import mysql# 写入数据库 def write_db(param):try:sql "insert into house (…...
安卓Android逆向记录学习-Deepseek-AI辅助)
《永恒战士2-无双战神》无限金币版(提供apk下载)安卓Android逆向记录学习-Deepseek-AI辅助
《永恒战士2-无双战神》无限金币版(提供apk下载)安卓Android逆向记录学习-Deepseek-AI辅助 不知道会不会有人来技术论坛找一个10几年前的游戏安装包 我是前段时间,突然想起来这个游戏,上网搜,网上都说有 那我就去找&am…...

PWM技术原理与应用全解析
1. PWM技术基础解析脉冲宽度调制(PWM)作为现代电力电子领域的核心技术之一,其重要性不亚于电路设计中的"ABC"。我在工业自动化领域工作十年间,从伺服驱动器到开关电源,PWM技术无处不在。理解PWM的本质&#…...

Claude Code 之父:AI 的改变不止于代码,程序员需要改变整个工作流
高水平工程劳动,正在离开手写代码。编译 | 王启隆出品丨AI 科技大本营(ID:rgznai100)这两天,Claude Code 以一种多少有点尴尬的方式被更多人看见了。不是因为新模型发布,也不是因为哪场演示太惊艳ÿ…...

Agent Skill 快速开始
1 Agent Skill的基本概念 用一句简单的话来说的话,Agent Skill就是大模型随时翻阅的说明文档。 Skill 本质上是一个沉淀了自然语言描述 SOP 的 markdown 文件,能够避免重复性劳动,统一能力标准,实现高效且可复用的经验传递。 Sk…...

城通网盘解析终极指南:如何免费获取高速直连下载地址
城通网盘解析终极指南:如何免费获取高速直连下载地址 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 在数字化信息时代,城通网盘作为国内广泛使用的文件分享平台,却因…...

AMD新平台装CentOS7.9总报Kernel Panic?别折腾了,试试Rocky Linux 9.2吧
AMD新平台安装CentOS7.9遭遇Kernel Panic?Rocky Linux 9.2的完美替代方案 最近几年,AMD的Zen3架构处理器凭借出色的性能和能效比,赢得了大量开发者和技术爱好者的青睐。然而,当这些用户尝试在Ryzen 5000系列平台上安装某些较旧的L…...

Qt Windows自定义GUI界面自动化测试——uiautomatio通过树节点属性定位控件
Qt Windows自定义GUI界面自动化测试 提示:点击链接跳转其他相关文章 Windows自定义GUI界面自动化测试框架选择 autoit uiautomatio基本使用 uiautomatio通过树节点属性定位控件 uiautomatio通过树节点属性定位控件Qt Windows自定义GUI界面自动化测试前言一、实现方式…...

SwitchButton自定义样式完全教程:从基础到高级的完整指南
SwitchButton自定义样式完全教程:从基础到高级的完整指南 【免费下载链接】SwitchButton SwitchButton.An beautifullightweightcustom-style-easy switch widget for Android,minSdkVersion > 11 项目地址: https://gitcode.com/gh_mirrors/swi/SwitchButton …...

5分钟快速解锁QQ音乐加密文件:qmc-decoder终极使用指南
5分钟快速解锁QQ音乐加密文件:qmc-decoder终极使用指南 【免费下载链接】qmc-decoder Fastest & best convert qmc 2 mp3 | flac tools 项目地址: https://gitcode.com/gh_mirrors/qm/qmc-decoder 你是否曾经在QQ音乐下载了喜欢的歌曲,却发现…...

HardSourceWebpackPlugin插件生态:ExcludeModulePlugin和ParallelModulePlugin深度解析
HardSourceWebpackPlugin插件生态:ExcludeModulePlugin和ParallelModulePlugin深度解析 【免费下载链接】hard-source-webpack-plugin 项目地址: https://gitcode.com/gh_mirrors/ha/hard-source-webpack-plugin HardSourceWebpackPlugin是Webpack生态中一款…...