可视化脚本用于使用MMDetection库进行图像的目标检测
# Copyright (c) OpenMMLab. All rights reserved.
import asyncio
from argparse import ArgumentParserfrom mmdet.apis import (async_inference_detector, inference_detector,init_detector, show_result_pyplot)
import denseclip# 解析命令行参数
def parse_args():parser = ArgumentParser()parser.add_argument('img', help='Image file') # 图像文件路径parser.add_argument('config', help='Config file') # 配置文件路径parser.add_argument('checkpoint', help='Checkpoint file') # 检查点文件路径parser.add_argument('--out-file', default=None, help='Path to output file') # 输出结果文件路径parser.add_argument('--device', default='cuda:0', help='Device used for inference') # 使用进行推理的设备parser.add_argument('--palette',default='coco',choices=['coco', 'voc', 'citys', 'random'],help='Color palette used for visualization') # 可视化使用的颜色调色板parser.add_argument('--score-thr', type=float, default=0.3, help='bbox score threshold') # 框得分阈值parser.add_argument('--async-test',action='store_true',help='whether to set async options for async inference.') # 是否进行异步推理args = parser.parse_args()return args# 主函数
def main(args):# 从配置文件和检查点文件构建模型model = init_detector(args.config, args.checkpoint, device=args.device)# 对单张图像进行测试result = inference_detector(model, args.img)# 显示结果show_result_pyplot(model,args.img,result,palette=args.palette,score_thr=args.score_thr,out_file=args.out_file)# 异步主函数
async def async_main(args):# 从配置文件和检查点文件构建模型model = init_detector(args.config, args.checkpoint, device=args.device)# 对单张图像进行异步测试tasks = asyncio.create_task(async_inference_detector(model, args.img))result = await asyncio.gather(tasks)# 显示结果show_result_pyplot(model,args.img,result[0],palette=args.palette,score_thr=args.score_thr,out_file=args.out_file)# 主程序入口
if __name__ == '__main__':args = parse_args()if args.async_test:asyncio.run(async_main(args)) # 如果设置了异步选项,则运行异步主函数else:main(args) # 否则运行同步主函数
用命令行指定具体文件
基本示例
python your_script.py path/to/image.jpg path/to/config.py path/to/checkpoint.pth
指定输出文件
python your_script.py path/to/image.jpg path/to/config.py path/to/checkpoint.pth --out-file path/to/output.jpg
设置边界框得分阈值
python your_script.py path/to/image.jpg path/to/config.py path/to/checkpoint.pth --score-thr 0.5
或者用下面的分布式测试
import argparse
import os
import warningsimport mmcv
import torch
from mmcv import Config, DictAction
from mmcv.cnn import fuse_conv_bn
from mmcv.parallel import MMDataParallel, MMDistributedDataParallel
from mmcv.runner import (get_dist_info, init_dist, load_checkpoint,wrap_fp16_model)from mmdet.apis import multi_gpu_test, single_gpu_test
from mmdet.datasets import (build_dataloader, build_dataset,replace_ImageToTensor)
from mmdet.models import build_detector
import denseclipdef parse_args():parser = argparse.ArgumentParser(description='MMDet test (and eval) a model')parser.add_argument('config', help='test config file path')parser.add_argument('checkpoint', help='checkpoint file')parser.add_argument('--out', help='output result file in pickle format')parser.add_argument('--fuse-conv-bn',action='store_true',help='Whether to fuse conv and bn, this will slightly increase''the inference speed')parser.add_argument('--format-only',action='store_true',help='Format the output results without perform evaluation. It is''useful when you want to format the result to a specific format and ''submit it to the test server')parser.add_argument('--eval',type=str,nargs='+',help='evaluation metrics, which depends on the dataset, e.g., "bbox",'' "segm", "proposal" for COCO, and "mAP", "recall" for PASCAL VOC')parser.add_argument('--show', action='store_true', help='show results')parser.add_argument('--show-dir', help='directory where painted images will be saved')parser.add_argument('--show-score-thr',type=float,default=0.3,help='score threshold (default: 0.3)')parser.add_argument('--gpu-collect',action='store_true',help='whether to use gpu to collect results.')parser.add_argument('--tmpdir',help='tmp directory used for collecting results from multiple ''workers, available when gpu-collect is not specified')parser.add_argument('--cfg-options',nargs='+',action=DictAction,help='override some settings in the used config, the key-value pair ''in xxx=yyy format will be merged into config file. If the value to ''be overwritten is a list, it should be like key="[a,b]" or key=a,b ''It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" ''Note that the quotation marks are necessary and that no white space ''is allowed.')parser.add_argument('--options',nargs='+',action=DictAction,help='custom options for evaluation, the key-value pair in xxx=yyy ''format will be kwargs for dataset.evaluate() function (deprecate), ''change to --eval-options instead.')parser.add_argument('--eval-options',nargs='+',action=DictAction,help='custom options for evaluation, the key-value pair in xxx=yyy ''format will be kwargs for dataset.evaluate() function')parser.add_argument('--launcher',choices=['none', 'pytorch', 'slurm', 'mpi'],default='none',help='job launcher')parser.add_argument('--local_rank', type=int, default=0)args = parser.parse_args()if 'LOCAL_RANK' not in os.environ:os.environ['LOCAL_RANK'] = str(args.local_rank)if args.options and args.eval_options:raise ValueError('--options and --eval-options cannot be both ''specified, --options is deprecated in favor of --eval-options')if args.options:warnings.warn('--options is deprecated in favor of --eval-options')args.eval_options = args.optionsreturn argsdef main():args = parse_args()assert args.out or args.eval or args.format_only or args.show \or args.show_dir, \('Please specify at least one operation (save/eval/format/show the ''results / save the results) with the argument "--out", "--eval"'', "--format-only", "--show" or "--show-dir"')if args.eval and args.format_only:raise ValueError('--eval and --format_only cannot be both specified')if args.out is not None and not args.out.endswith(('.pkl', '.pickle')):raise ValueError('The output file must be a pkl file.')cfg = Config.fromfile(args.config)if args.cfg_options is not None:cfg.merge_from_dict(args.cfg_options)# import modules from string list.if cfg.get('custom_imports', None):from mmcv.utils import import_modules_from_stringsimport_modules_from_strings(**cfg['custom_imports'])# set cudnn_benchmarkif cfg.get('cudnn_benchmark', False):torch.backends.cudnn.benchmark = Truecfg.model.pretrained = Noneif cfg.model.get('neck'):if isinstance(cfg.model.neck, list):for neck_cfg in cfg.model.neck:if neck_cfg.get('rfp_backbone'):if neck_cfg.rfp_backbone.get('pretrained'):neck_cfg.rfp_backbone.pretrained = Noneelif cfg.model.neck.get('rfp_backbone'):if cfg.model.neck.rfp_backbone.get('pretrained'):cfg.model.neck.rfp_backbone.pretrained = None# in case the test dataset is concatenatedif isinstance(cfg.data.test, dict):cfg.data.test.test_mode = Trueelif isinstance(cfg.data.test, list):for ds_cfg in cfg.data.test:ds_cfg.test_mode = True# init distributed env first, since logger depends on the dist info.if args.launcher == 'none':distributed = Falseelse:distributed = Trueinit_dist(args.launcher, **cfg.dist_params)# build the dataloadersamples_per_gpu = cfg.data.test.pop('samples_per_gpu', 1)if samples_per_gpu > 1:# Replace 'ImageToTensor' to 'DefaultFormatBundle'cfg.data.test.pipeline = replace_ImageToTensor(cfg.data.test.pipeline)dataset = build_dataset(cfg.data.test)data_loader = build_dataloader(dataset,samples_per_gpu=samples_per_gpu,workers_per_gpu=cfg.data.workers_per_gpu,dist=distributed,shuffle=False)# build the model and load checkpointif 'DenseCLIP' in cfg.model.type:cfg.model.class_names = list(dataset.CLASSES)if not hasattr(cfg, 'test_cfg'):cfg.test_cfg = Nonemodel = build_detector(cfg.model, train_cfg=None, test_cfg=cfg.test_cfg)fp16_cfg = cfg.get('fp16', None)if fp16_cfg is not None:wrap_fp16_model(model)checkpoint = load_checkpoint(model, args.checkpoint, map_location='cpu')if args.fuse_conv_bn:model = fuse_conv_bn(model)# old versions did not save class info in checkpoints, this walkaround is# for backward compatibilityif 'CLASSES' in checkpoint['meta']:model.CLASSES = checkpoint['meta']['CLASSES']else:model.CLASSES = dataset.CLASSESif not distributed:model = MMDataParallel(model, device_ids=[0])outputs = single_gpu_test(model, data_loader, args.show, args.show_dir,args.show_score_thr)else:model = MMDistributedDataParallel(model.cuda(),device_ids=[torch.cuda.current_device()],broadcast_buffers=False)outputs = multi_gpu_test(model, data_loader, args.tmpdir,args.gpu_collect)rank, _ = get_dist_info()if rank == 0:if args.out:print(f'\nwriting results to {args.out}')mmcv.dump(outputs, args.out)kwargs = {} if args.eval_options is None else args.eval_optionsif args.format_only:dataset.format_results(outputs, **kwargs)if args.eval:eval_kwargs = cfg.get('evaluation', {}).copy()# hard-code way to remove EvalHook argsfor key in ['interval', 'tmpdir', 'start', 'gpu_collect', 'save_best','rule']:eval_kwargs.pop(key, None)eval_kwargs.update(dict(metric=args.eval, **kwargs))print(dataset.evaluate(outputs, **eval_kwargs))if __name__ == '__main__':main()相关文章:

可视化脚本用于使用MMDetection库进行图像的目标检测
# Copyright (c) OpenMMLab. All rights reserved. import asyncio from argparse import ArgumentParserfrom mmdet.apis import (async_inference_detector, inference_detector,init_detector, show_result_pyplot) import denseclip# 解析命令行参数 def parse_args():pars…...
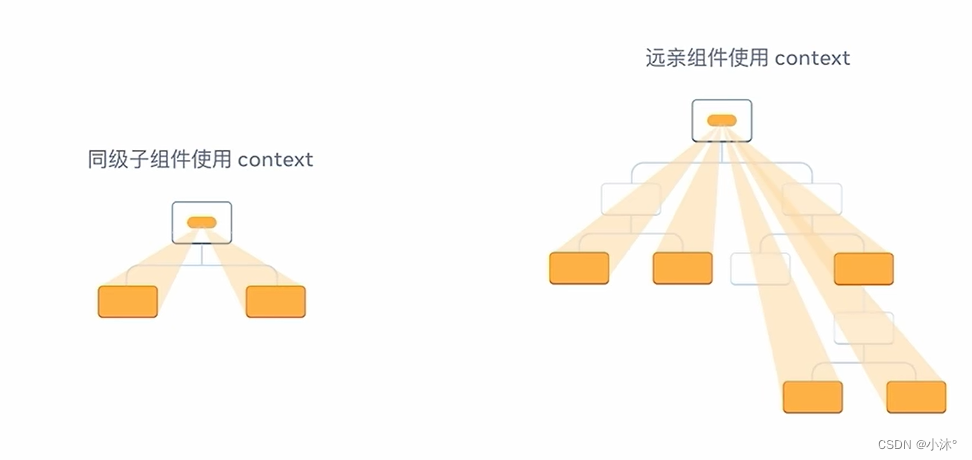
React-组件通信
组件通信 概念:组件通信就是组件之间的数据传递,根据组件嵌套关系的不同,有不同的通信方法 父传子 基础实现 实现步骤: 1.父组件传递数据-在子组件标签上绑定属性 2.子组件接收数据-子组件通过props参数接收数据 props说明 1.…...
低代码选型要注意什么问题?
低代码选型时,确实需要从多个角度综合考虑,以下是根据您给出的角度进行的分析和建议: 公司的人才资源: 评估团队中是否有具备编程能力的开发人员,以确保能够充分利用低代码平台的高级功能和进行必要的定制开发。考察实…...
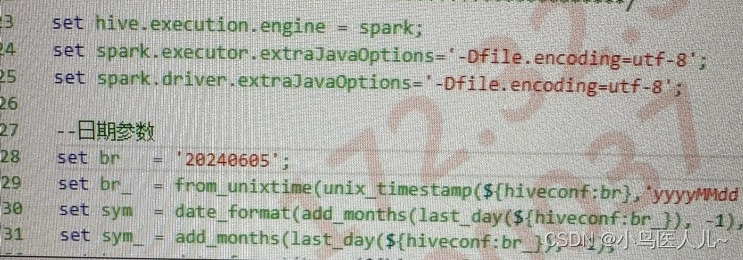
fpga入门 串口定时1秒发送1字节
一、 程序说明 FPGA通过串口定时发送数据,每秒发送1字节,数据不断自增 参考小梅哥教程 二、 uart_tx.v timescale 1ns / 1psmodule uart_tx(input wire sclk,input wire rst_n,output reg uart_tx);parameter …...

总结一下自己,最近三年,我做了哪些工作
简单总结下吧,我算是业务架构师,确实对得起这个名字,经常冲在一线,业务和架构相关的东西都有做,系统比较复杂,不过逐步了解谁都会熟悉的 下面简单列一列我这三年的工作情况吧,也算是给自己一个交…...

SpringCloud Gateway基础入门与使用实践总结
官网文档:点击查看官网文档 Cloud全家桶中有个很重要的组件就是网关,在1.x版本中都是采用的Zuul网关。但在2.x版本中,zuul的升级一直跳票,SpringCloud最后自己研发了一个网关替代Zuul,那就是SpringCloud Gateway一句话…...
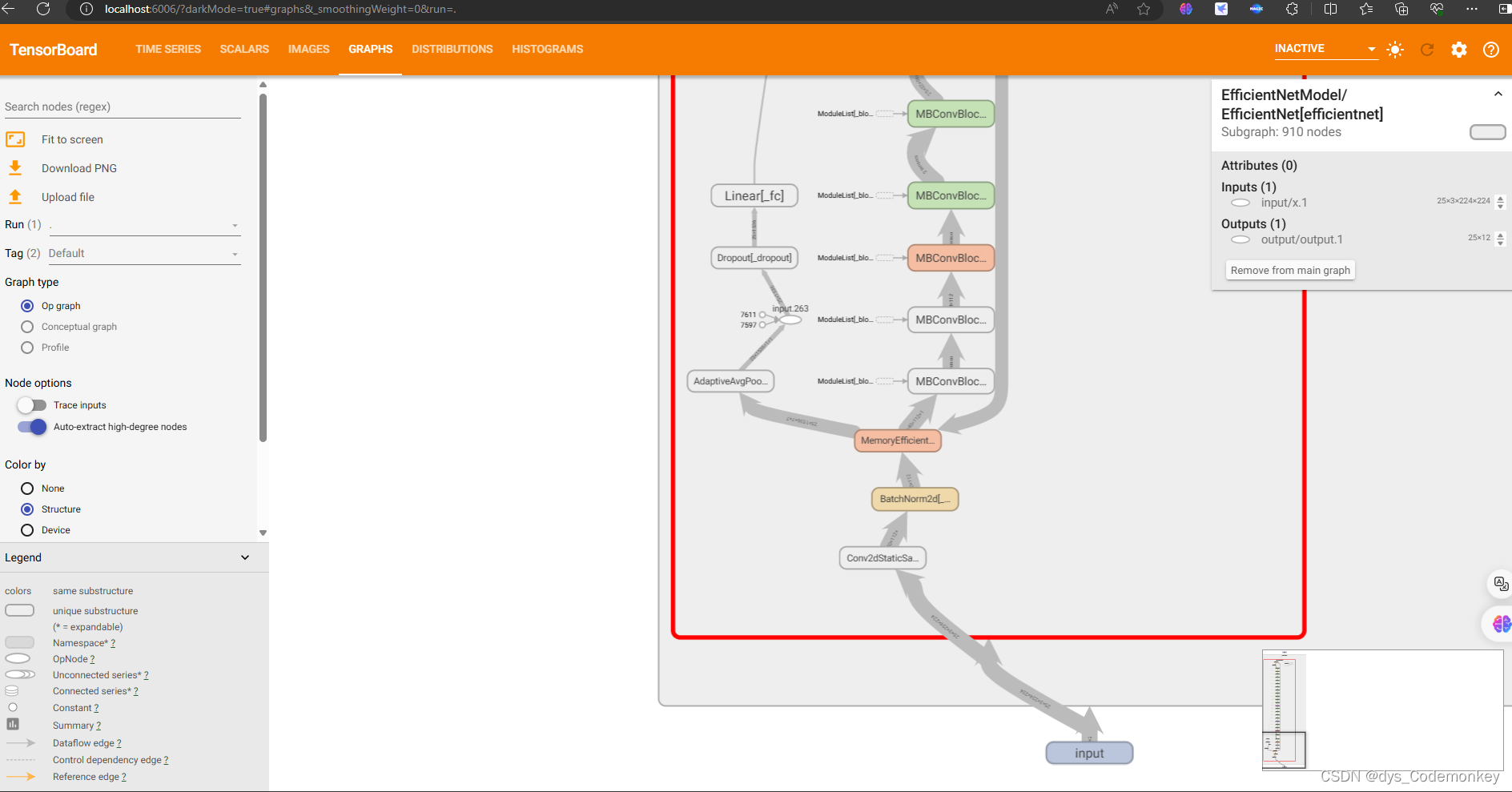
TensorBoard在pytorch训练过程中如何使用,及数据读取问题解决方法
TensorBoard 模块导入日志记录文件的创建训练中如何写入数据如何提取保存的数据调用TensorBoard面板可能会遇到的问题 模块导入 首先从torch中导入tensorboard的SummaryWriter日志记录模块 from torch.utils.tensorboard import SummaryWriter然后导入要用到的os库࿰…...

【Vue】普通组件的注册使用-全局注册
文章目录 一、使用步骤二、练习 一、使用步骤 步骤 创建.vue组件(三个组成部分)main.js中进行全局注册 使用方式 当成HTML标签直接使用 <组件名></组件名> 注意 组件名规范 —> 大驼峰命名法, 如 HmHeader 技巧…...
爬虫之反爬思路与解决手段
阅读时间建议:4分钟 本篇概念比较多,嗯。。 0x01 反爬思路与解决手段 1、服务器反爬虫的原因 因为爬虫的访问次数高,浪费资源,公司资源被批量抓走,丧失竞争力,同时也是法律的灰色地带。 2、服务器反什么…...
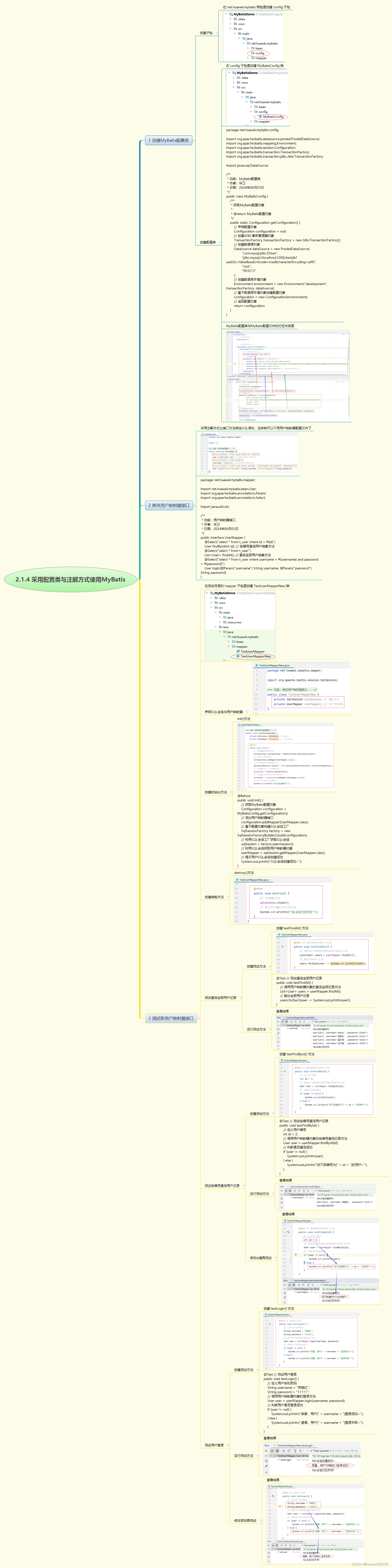
2.1.4 采用配置类与注解方式使用MyBatis
实战概述:采用配置类与注解方式使用MyBatis 创建MyBatis配置类 在net.huawei.mybatis.config包中创建MyBatisConfig类,用于配置MyBatis核心组件,包括数据源、事务工厂和环境设置。 配置数据源和事务 使用PooledDataSource配置MySQL数据库连接…...
微信小程序云开发实现利用云函数将数据库表的数据导出到excel中
实现目标 将所有订单信息导出到excel表格中 思路 1、在页面中bindtap绑定一个导出点击事件daochu() 2、先获取所有订单信息,并将数据添加到List数组中 3、传入以List数组作为参数,调用get_excel云函数 4、get_excel云函数利用node-xlsx第三方库&#…...

python 字符串(str)、列表(list)、元组(tuple)、字典(dict)
学习目标: 1:能够知道如何定义一个字符串; [重点] 使用双引号引起来: 变量名 "xxxx" 2:能够知道切片的语法格式; [重点] [起始: 结束] 3:掌握如何定义一个列表; [重点] 使用[ ]引起来: 变量名 [xx,xx,...] 4:能够说出4个列表相关的方法; [了解] ap…...

【源码】SpringBoot事务注册原理
前言 对于数据库的操作,可能存在脏读、不可重复读、幻读等问题,从而引入了事务的概念。 事务 1.1 事务的定义 事务是指在数据库管理系统中,一系列紧密相关的操作序列,这些操作作为一个单一的工作单元执行。事务的特点是要么全…...

技巧:合并ZIP分卷压缩包
如果ZIP压缩文件文件体积过大,大家可能会选择“分卷压缩”来压缩ZIP文件,那么,如何合并zip分卷压缩包呢?今天我们分享两个ZIP分卷压缩包合并的方法给大家。 方法一: 我们可以将分卷压缩包,通过解压的方式…...
数据挖掘 | 实验三 决策树分类算法
文章目录 一、目的与要求二、实验设备与环境、数据三、实验内容四、实验小结 一、目的与要求 1)熟悉决策树的原理; 2)熟练使用sklearn库中相关决策树分类算法、预测方法; 3)熟悉pydotplus、 GraphViz等库中决策树模型…...

Python机器学习预测区间估计工具库之mapie使用详解
概要 在数据科学和机器学习领域,预测的不确定性估计是一个非常重要的课题。Python的mapie库是一种专注于预测区间估计的工具,旨在提供简单易用的接口来计算和评估预测的不确定性。通过mapie库,用户可以为各种回归和分类模型计算预测区间,从而更好地理解模型预测的可靠性。…...

Linux基础指令磁盘管理002
LVM(Logical Volume Manager)是Linux系统中一种灵活的磁盘管理和存储解决方案,它允许用户在物理卷(Physical Volumes, PV)上创建卷组(Volume Groups, VG),然后在卷组上创建逻辑卷&am…...

Python怎么添加库:深入解析与操作指南
Python怎么添加库:深入解析与操作指南 在Python编程中,库(Library)扮演着至关重要的角色。它们为我们提供了大量的函数、类和模块,使得我们可以更高效地编写代码,实现各种功能。那么,Python如何…...

Python | 虚拟环境的增删改查
mkvirtualenv创建虚拟环境 mkvirtualenv是用于在Pyhon中创建虚拟环境的命令。它通过使用vitualenv库来创建一个隔离的Python环境,以便您可以安装特定版本的Python包,而不会影响全局Python环境。 使用方法: 安装virtualenv:pip install vir…...

革新性无人机数据分析工具:UAV Log Viewer实战指南
革新性无人机数据分析工具:UAV Log Viewer实战指南 【免费下载链接】UAVLogViewer An online viewer for UAV log files 项目地址: https://gitcode.com/gh_mirrors/ua/UAVLogViewer UAV Log Viewer作为一款开源的无人机日志分析神器,正在彻底改变…...

linux中systemctl详细理解及常用命令解析
一、systemctl理解Linux 服务管理两种方式service和systemctlsystemd是Linux系统最新的初始化系统(init),作用是提高系统的启动速度,尽可能启动较少的进程,尽可能更多进程并发启动。systemd对应的进程管理命令是systemctl1. systemctl命令兼容了service即…...

Windows 11安装终极指南:5分钟绕过所有硬件限制
Windows 11安装终极指南:5分钟绕过所有硬件限制 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat 还在为Wind…...

Kandinsky-5.0-I2V-Lite-5s效果展示:背景变化趋势+主体动作精准还原案例
Kandinsky-5.0-I2V-Lite-5s效果展示:背景变化趋势主体动作精准还原案例 1. 惊艳的轻量级图生视频体验 想象一下,你只需要上传一张照片,再简单描述想要的动态效果,就能获得一段5秒的专业级短视频。这就是Kandinsky-5.0-I2V-Lite-…...

PyTorch 2.9镜像使用指南:Jupyter与SSH两种方式详细解析
PyTorch 2.9镜像使用指南:Jupyter与SSH两种方式详细解析 1. 镜像概述 PyTorch 2.9镜像是一个开箱即用的深度学习开发环境,预装了PyTorch 2.9框架和CUDA工具包。这个镜像特别适合需要快速搭建GPU加速开发环境的用户,无论是进行模型训练、推理…...
)
MOSFET栅极电阻选型实战:从波形分析到最佳阻值确定(附IRF540实测数据)
MOSFET栅极电阻选型实战:从波形分析到最佳阻值确定(附IRF540实测数据) 在电力电子设计中,MOSFET的栅极电阻选型往往被工程师视为"小问题",但实际调试中却可能成为影响系统稳定性的关键因素。记得去年参与一款…...

s2-proWeb工具深度体验:响应速度、试听流畅度与下载稳定性评测
s2-proWeb工具深度体验:响应速度、试听流畅度与下载稳定性评测 1. 产品概览 s2-pro是Fish Audio开源的专业级语音合成模型镜像,作为一款专注于文本转语音(TTS)的工具,它提供了两种核心功能模式: 基础语音合成:直接输…...

Kook Zimage真实幻想Turbo企业级应用:SpringBoot微服务架构实战
Kook Zimage真实幻想Turbo企业级应用:SpringBoot微服务架构实战 1. 微服务架构下的AI图像生成价值 在内容创作平台的后台重构过程中,我们将Kook Zimage真实幻想Turbo的AI图像生成能力独立封装为微服务,这种架构设计带来了显著优势ÿ…...

OpenClaw配置备份:千问3.5-35B-A3B-FP8环境快速迁移方案
OpenClaw配置备份:千问3.5-35B-A3B-FP8环境快速迁移方案 1. 为什么需要配置备份? 上周我的主力开发机突然硬盘故障,导致OpenClaw与千问3.5-35B-A3B-FP8的对接配置全部丢失。重新配置花了整整两天时间——从模型地址验证、飞书通道重建到技能…...

【ProtoBuf 实战训练】网络版通讯录
文章目录1. 通讯录 4.0 实现(网络版)2. 环境搭建2.1 搭建服务端2.2 搭建客户端2.3 运行结果3. 新增联系人功能3.1 协议约定3.2 协议接口定义 (.proto)3.2.1 AddContactRequest(请求消息)3.2.2 AddContactResponse(响应…...