爬虫(没)入门:用 node-crawler 爬取 blog
起因
前几天想给一个项目加 eslint,记得自己曾经在博客里写过相关内容,所以来搜索。但是发现 csdn 的只能按标题,没办法搜正文,所以我没搜到自己想要的内容。
没办法只能自己又重新折腾了一通 eslint,很烦躁。迁怒于 CSDN(?),所以打算写一个爬虫,自己搜。
新建项目
只想做一个很简单的爬虫,爬取我自己的 blog,获取所有文章的标题、摘要、分类、标签、内容、发布更新时间。
一说到爬虫我就想到 python,但是懒得配置 python 的开发环境了,用 nodejs 随便搞一搞吧。简单查了一下,决定用 node-crawler
npm init -y
git init
创建 .gitignore
pnpm i crawler
创建 index.js
爬取文章内容页面
此页面可以获取标题、分类、标签、正文内容。
页面中也展示了发布和更新日期,但获取较麻烦,不在此页面爬取。
// index.js
const Crawler = require("crawler");const crawler = new Crawler();
crawler.direct({uri: `https://blog.csdn.net/tangran0526/article/details/125663417`,callback: (error, res) => {if (error) {console.error(error);} else {const $ = res.$; // node-crawler 内置 cheerio 包。$ 是 cheerio 包提供的,用法和 jQuery 基本一致const title = $("#articleContentId").text();const content = $("#article_content").text();}},
});
获取标题、正文很简单,通过 id 直接锁定元素,然后用 text() 获取文本内容。但是分类和标签就要复杂一点了。

对应的 html 结构是:

分类和标签的 class 都是 tag-link,只能从 attr 区分。
注意:cheerio 的 map() 返回伪数组对象,需要调用 get() 获取真数组
const categories = $(`.tag-link[href^="https://blog.csdn.net/tangran0526"]`).map((_i, el) => $(el).text()).get();
const tags = $(`.tag-link[href^="https://so.csdn.net/so/search"]`).map((_i, el) => $(el).text()).get();
发布和更新日期就不在详情页面获取了。因为对有更新和无更新的文章,日期的展示形式不同,而且没有特殊的 class 能锁定元素,获取起来比较麻烦。
获取文章列表
找到文章列表页面,惊喜的发现有滚动加载,也许能找到获取列表的接口。打开浏览器控制台,Network 中看到疑似请求:

返回值为:
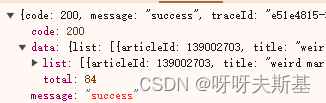
因为是 get 请求,所以可以直接把接口地址放到浏览器地址栏里访问。这样改参数看效果更直接。可以避免吭哧吭哧写代码试,最后发现参数无效或者哪有错的倒霉情况。
在地址栏里改参数发现 size 能正常工作。给它设大一点,就可以一次获取所有文章。
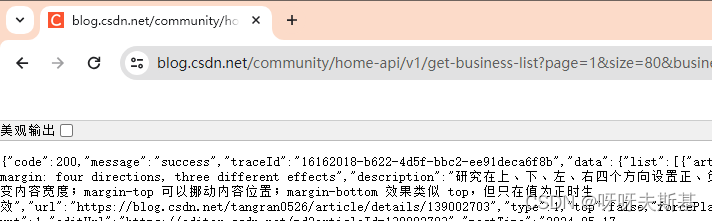
let url = "https://blog.csdn.net/community/home-api/v1/get-business-list";
const queryParams = {businessType: "blog",username: "tangran0526",page: 1,size: 1000, // 设大一点,一次取完所有文章
};
url += "?" + Object.entries(queryParams).map(([key, value]) => key + "=" + value).join("&");
crawler.direct({uri: url,callback: (error, res) => {if (error) {console.error(error);} else {console.log(res);}},
});
这次返回值是 json,不是 html 了。不确定返回的 res 是什么结构,node-crawler 的官方文档中有写:
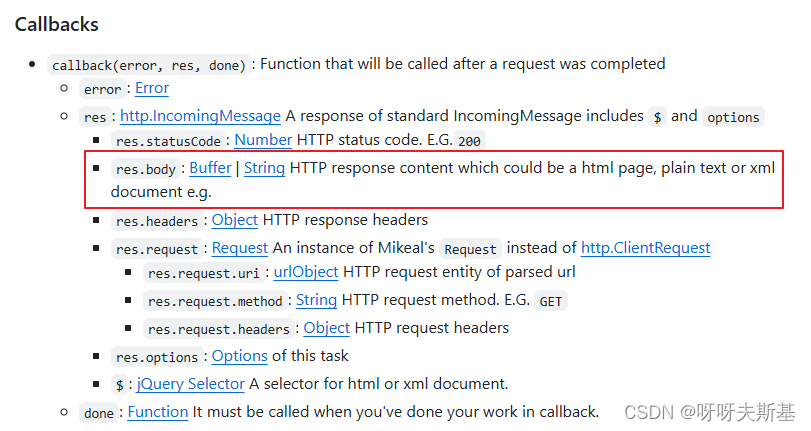
打断点查看:
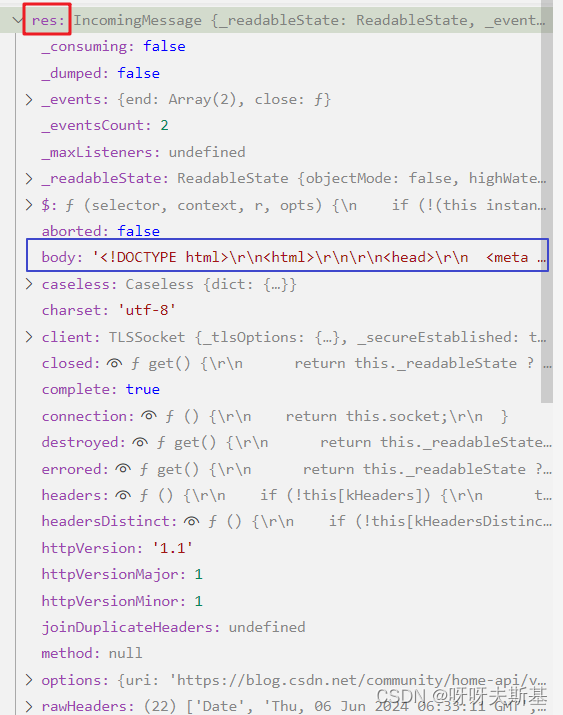
res.body 是一段 html。内容是提示:当前访问人数过多,请完成安全认证后继续访问。
应该是网站的防爬虫、防网络攻击的策略。google 了“爬虫、安全验证、验证码”等相关内容,找到了解决方法。
找到刚才用浏览器成功访问的请求,把它的 request header 全部赋给 crawler 里面的 header
crawler.direct({uri: url,headers: { // 全部放这里},callback,
}
再次重试,res.body 是想要的结果了。现在是字符串, 再 JSON.parse 一下就可以了。

下面来精简 request headers。之前是把所有的 headers 都拿过来了,但应该不需要那么多。筛查哪些 headers 是必不可少的:
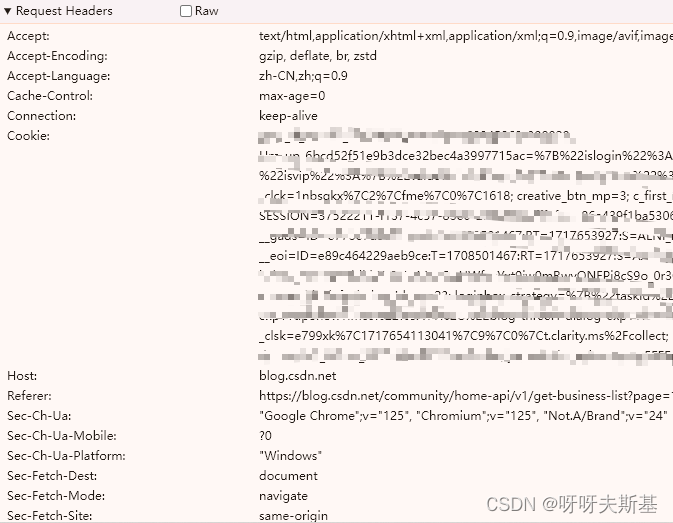
二分法排除,确认了只有 cookie 是必须的。
去浏览器中清除 cookie 后,在浏览器中重新访问接口,也弹出了这个安全验证页面。双重实锤 cookie 是关键!
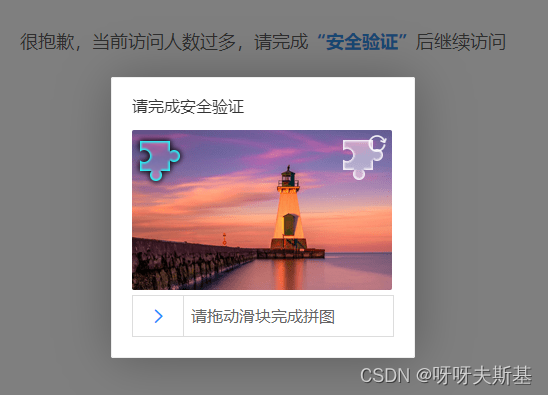
cookies 内容也很多,根据名称猜测,二分法筛查找到了两个关键cookie:

只要有它们两个,就不会触发安全验证。
const cookie_yd_captcha_token = "略";
const cookie_waf_captcha_marker = "略";
crawler.direct({uri: url,headers: {Cookie: `yd_captcha_token=${cookie_yd_captcha_token}; waf_captcha_marker=${cookie_waf_captcha_marker}`,},callback
});
这两个 cookie 的值应该是有时效的。每次失效后都必须:打开浏览器——清除cookies后访问接口——遇到安全验证——通过后获取新的有效cookie。
所以这是一个人工爬虫——需要人力辅助的爬虫。。。。我知道这很烂,但没兴趣继续研究了,就这样吧。
如果想真正解决,应该使用 puppeteer 这类爬虫:内置 Headless Browser,可以模拟用户操作,也许能解决图形、滑块等验证。
将爬取结果输出到文件
先调用 list,再对每一篇文章获取详情。最后将结果输出到文件。
执行 node index.js,等待一会后,输出 result.json 文件:
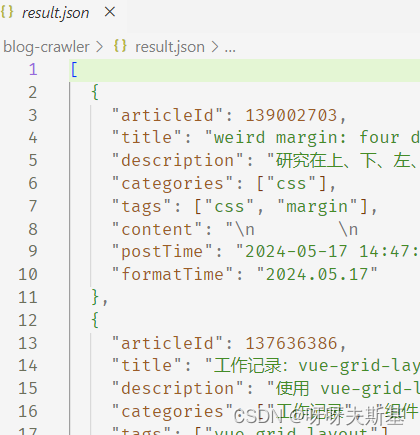
完整代码如下:
// index.jsconst Crawler = require("crawler");
const { writeFile } = require("fs");
const { username, cookie_yd_captcha_token, cookie_waf_captcha_marker } = require("./configs.js");const crawler = new Crawler();// https://github.com/request/request
// https://github.com/bda-research/node-crawler/tree/master?tab=readme-ov-file#basic-usage
// https://github.com/cheeriojs/cheerio/wiki/Chinese-READMEconst articleList = [];function getArticleList() {let url = "https://blog.csdn.net/community/home-api/v1/get-business-list";const queryParams = {businessType: "blog",username,page: 1,size: 1000,};url +="?" +Object.entries(queryParams).map(([key, value]) => key + "=" + value).join("&");return new Promise((resolve, reject) => {crawler.direct({uri: url,headers: {Cookie: `yd_captcha_token=${cookie_yd_captcha_token}; waf_captcha_marker=${cookie_waf_captcha_marker}`,},callback: (error, res) => {if (error) {reject(error);} else {const { code, data, message } = JSON.parse(res.body);if (code === 200) {resolve(data);} else {reject({ code, message });}}},});});
}function getArticleDetail(articleId) {return new Promise((resolve, reject) => {crawler.direct({uri: `https://blog.csdn.net/${username}/article/details/${articleId}`,callback: (error, res) => {if (error) {reject(error);} else {const $ = res.$;const title = $("#articleContentId").text();const content = $("#article_content").text();const categories = $(`.tag-link[href^="https://blog.csdn.net"]`).map((_i, el) => $(el).text()).get();const tags = $(`.tag-link[href^="https://so.csdn.net/so/search"]`).map((_i, el) => $(el).text()).get();const articleDetail = {title,categories,tags,content,};resolve(articleDetail);}},});});
}async function start() {const { list } = await getArticleList();for (let i = 0; i < list.length; i++) {const { articleId, description, formatTime, postTime, title } = list[i];const { categories, tags, content } = await getArticleDetail(articleId);articleList.push({articleId,title,description,categories,tags,content,postTime,formatTime,});}outputToJson();
}function outputToJson() {const path = "./result.json";writeFile(path, JSON.stringify(articleList), (error) => {if (error) {console.log("An error has occurred ", error);return;}console.log("Data written successfully to disk");});
}
start();
相关文章:
爬虫(没)入门:用 node-crawler 爬取 blog
起因 前几天想给一个项目加 eslint,记得自己曾经在博客里写过相关内容,所以来搜索。但是发现 csdn 的只能按标题,没办法搜正文,所以我没搜到自己想要的内容。 没办法只能自己又重新折腾了一通 eslint,很烦躁。迁怒于…...

GAMES104笔记
GAMES104 文章目录 GAMES10401.从入门到实践什么是游戏引擎学习顺序 02.引擎架构分层资源层功能层核心层平台层工具层总结 03.如何构建游戏世界其它需要管理的复杂情况 04.游戏引擎中的渲染实践Rendering游戏引擎中的绘制知识点(结合实际进化而来)渲染基…...

ARM功耗管理架构演进及变迁
安全之安全(security)博客目录导读 目录 一、功耗管理架构演进及变迁概述 二、多核 三、big.LITTLE 四、DynamIQ...
系统架构之系统能力的设备隔离和保护)
ARM-V9 RME(Realm Management Extension)系统架构之系统能力的设备隔离和保护
安全之安全(security)博客目录导读 目录 三、设备隔离和保护 1、外设隔离 2、非pe请求者(设备)...
如何为律师制作专业的商务名片?含电子名片二维码
律师关注细节,律师名片也不例外。它们不仅仅是身份的象征,更是律师专业形象的代表,传递专业知识和信任。今天就来和我们一起来看看制作律师商务名片的注意事项,以及如何制作商务名片上的电子名片二维码? 一、名片的主…...

方案设计|汽车轮胎数显胎压计方案
一、引言 数显轮胎胎压计是一个专门测量车辆轮胎气压的工具,它具有高精度测量的功能,能够帮助快速准确获取轮胎气压正确数值,保证轮胎使用安全。本文将对数显轮胎胎压计的方案技术进行分析,包括其基本原理、硬件构成、软件设计等方…...

MySQL学习——选项文件的使用
MySQL 的许多程序都可以从选项文件(有时也被称为配置文件)中读取启动选项。选项文件提供了一种方便的方式来指定常用的选项,这样你就不必每次运行程序时都在命令行上输入这些选项。 要确定一个程序是否读取选项文件,你可以使用 -…...
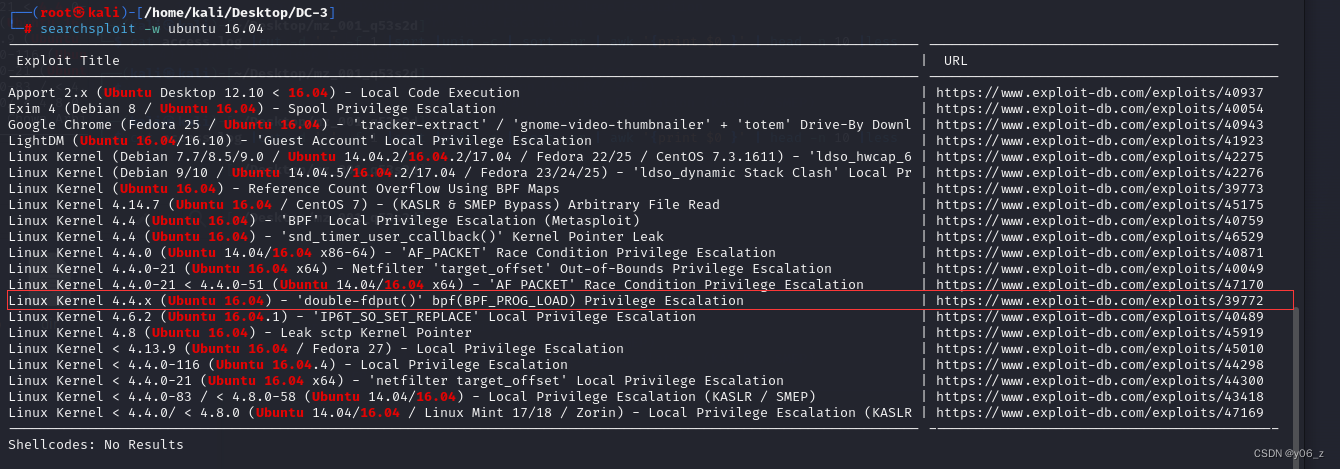
Vulnhub-DC-3
joomla3.7.0的提权 信息收集 靶机IP:192.168.20.136 kaliIP:192.168.20.128 网络有问题的可以看下搭建Vulnhub靶机网络问题(获取不到IP) 首先nmap扫端口和版本,dirsearch跑下目录,wappalyzer也可以用下 发现服务器用的ubuntu,JoomlaCMS…...

docker 停止重启容器命令start/stop/restart详解(容器生命周期管理教程-2)
Docker 提供了多个命令来管理容器的生命周期, 其中start、stop 和 restart。这些命令允许用户控制容器的运行状态。 1. docker start 命令格式: docker start [OPTIONS] CONTAINER [CONTAINER...]功能: 启动一个或多个已经停止的 Docker …...

lua字符串模式匹配
string.gmatch()不支持匹配首字符 string.gmatch(s, pattern)中,如果s的开头是’^字符,不会被当成首字符标志,而是被当成一个普通字符。 比如 s"hello world from lua" for w in string.gmatch(s, "^%a") doprint(w) e…...
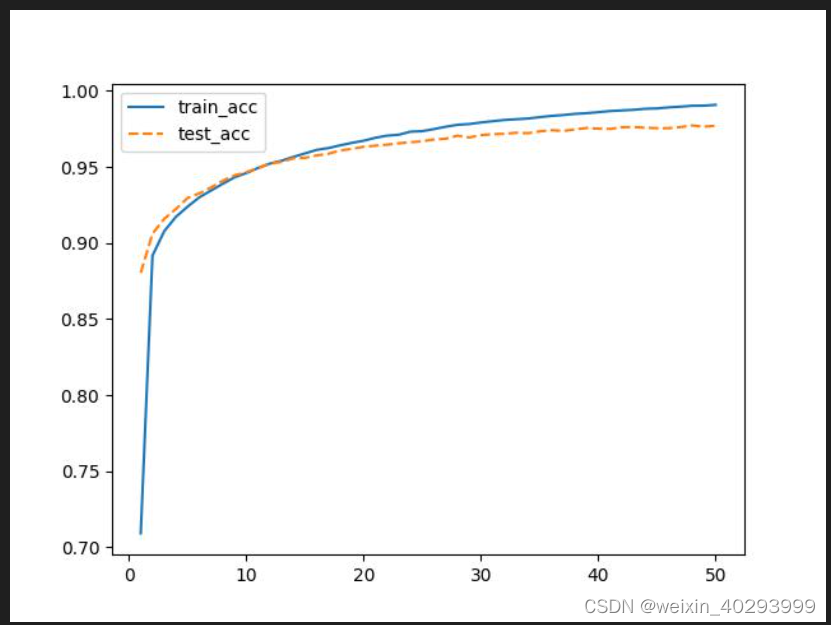
【深度学习】温故而知新4-手写体识别-多层感知机+CNN网络-完整代码-可运行
多层感知机版本 import torch import torch.nn as nn import numpy as np import torch.utils from torch.utils.data import DataLoader, Dataset import torchvision from torchvision import transforms import matplotlib.pyplot as plt import matplotlib import os # 前…...

ChatGPT 论文翻译指南!解锁高质量翻译的秘密!
博主猫头虎的技术世界 🌟 欢迎来到猫头虎的博客 — 探索技术的无限可能! 专栏链接: 🔗 精选专栏: 《面试题大全》 — 面试准备的宝典!《IDEA开发秘籍》 — 提升你的IDEA技能!《100天精通鸿蒙》 …...
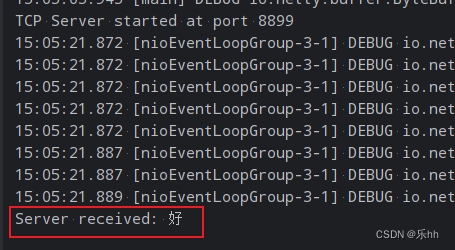
SQLserver通过CLR调用TCP接口
一、SQLserver启用CLR 查看是否开启CRL,如果run_value1,则表示开启 EXEC sp_configure clr enabled; GO RECONFIGURE; GO如果未启用,则执行如下命令启用CLR sp_configure clr enabled, 1; GO RECONFIGURE; GO二、创建 CLR 程序集 创建新项…...
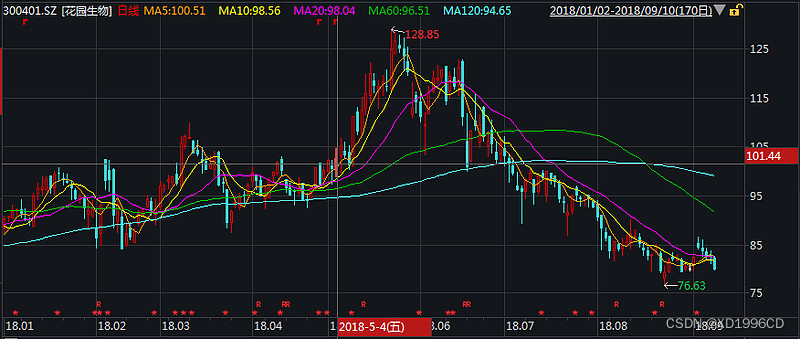
前复权、后复权,技术分析看哪个?价值投资呢?
先说结论, 前复权可以实现技术指标的连续性,适合技术分析, 后复权可以实现股价走势的连续性,适合价值投资者 从头来说,一家公司盈利后,可以选择用盈利购买新的生产设备或者拓展生产,但是…...

Python正则表达式:深度解析URL匹配与操作
Python正则表达式:深度解析URL匹配与操作 在Python编程中,正则表达式(Regular Expression,简称regex或regexp)是一种强大的文本处理工具,它可以帮助我们快速匹配、查找、替换复杂的文本模式。在处理URL&am…...

[C][数据结构][顺序表]详细讲解+实现
目录 1.线性表2.顺序表 - SeqList3.实现4.顺序表缺点 1.线性表 线性表(linear list)是n个具有相同特性的数据元素的有限序列线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串…线性表在逻辑上是线性结构࿰…...

vscode运行Java utf-8文件中文乱码报错
问题现象 vscode 运行utf-8 java文,爆出如下错误 hello.java:5: ����: ����GBK�IJ���ӳ���ַ&a…...

Mybatis杂记
group by查询返回map类型 1,2 List<Map<String, Object>> getCount();xml: <select id"getCount" resultType"java.util.HashMap">SELECT company_id, ifnull(sum(count_a count_b),0) ctFROM test.com_countWHERE is_del 0 GROUP BY…...

修改缓存供应商--EhCache
除了我们默认的缓存形式simlpe之外, 我们其实还有许多其他种类的缓存供应 Ehcache就是其中的一种形式 Ehcache在SpringBoot当中的使用: 其实跟我们之前整合第三方的资源是一样的形式 1>导入依赖: <!-- 更换缓存, 将默认使用的 Simple 更换为Ehcache--> <depe…...
20240606更新Toybrick的TB-RK3588开发板在Android12下的内核
20240606更新Toybrick的TB-RK3588开发板在Android12下的内核 2024/6/6 10:51 0、整体编译: 1、cat android12-rk-outside.tar.gz* | tar -xzv 2、cd android12 3、. build/envsetup.sh 4、lunch rk3588_s-userdebug 5、./build.sh -AUCKu -d rk3588-toybrick-x0-a…...

comsol实能带建模、与Matlab能带数据后处理 文献复现---“周期嵌套声学黑洞结构的复...
comsol实能带建模、与Matlab能带数据后处理 文献复现---“周期嵌套声学黑洞结构的复能带和凋落波研究”-“二维声学黑洞声子晶体的宽频振动抑制”-“ Broadband vibration mitigation using a two-dimensional acoustic black hole phononic crystal” 包括comsol实能带模型、M…...

ThinkJS路由系统终极指南:构建RESTful API的10个最佳实践
ThinkJS路由系统终极指南:构建RESTful API的10个最佳实践 【免费下载链接】thinkjs Use full ES2015 features to develop Node.js applications, Support TypeScript. 项目地址: https://gitcode.com/gh_mirrors/thi/thinkjs ThinkJS路由系统是构建现代Node…...

一站式数据健康解决方案:docta项目架构与核心组件深度剖析
一站式数据健康解决方案:docta项目架构与核心组件深度剖析 【免费下载链接】docta A Doctor for your data 项目地址: https://gitcode.com/gh_mirrors/do/docta docta作为一款强大的数据健康诊断工具,能够帮助用户轻松检测和修复数据集中的标签错…...

DeepSeek LintCode 3706 · 满足条件的数对的数量 public long countValidPairs(int[] nums1, int[] nums2, int dif
这个问题是 LintCode 3706 “满足条件的数对的数量”,要求统计满足 nums1[i] - nums1[j] < nums2[i] - nums2[j] diff(其中 i < j)的数对 (i, j) 的数量。 问题理解 给定两个数组 nums1 和 nums2,以及一个整数 diff&#…...

从顺序图反推代码:如何设计一个高内聚低耦合的网上书城后端服务?
从顺序图到高内聚低耦合架构:网上书城后端设计实战 当我们在白板上画完一张精美的顺序图时,真正的挑战才刚刚开始——如何将这些交互箭头转化为可维护、易扩展的代码结构?我曾参与过一个日均订单量超过5万单的图书电商平台重构,深…...

彻底搞懂ScheduledThreadPoolExecutor
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

OpenClaw性能优化:降低千问3.5-9B调用的Token消耗
OpenClaw性能优化:降低千问3.5-9B调用的Token消耗 1. 为什么需要关注Token消耗 去年冬天我第一次用OpenClaw对接千问3.5-9B模型时,被账单吓了一跳——一个简单的文件整理任务竟然消耗了将近2万Token。这让我意识到,在本地部署场景下&#x…...

AI 模型推理自动化部署方案实践
AI模型推理自动化部署方案实践 随着人工智能技术的快速发展,AI模型的训练和推理已成为企业智能化转型的核心环节。模型从开发到生产环境的部署往往面临效率低、运维复杂等问题。自动化部署方案能够显著提升推理服务的稳定性和可扩展性,成为企业降本增效…...

RoBERTa 微调:防过拟合终极调参手册
🛡️ RoBERTa 微调:防过拟合终极调参手册核心逻辑:在数据量有限(~2.6k)的情况下,通过限制模型容量(冻结/Dropout)和平滑优化过程(Weight Decay/Label Smoothingÿ…...

AI编程实战:从零到一搭建全栈项目
1. 引入 在现代 AI 工程中,Hugging Face 的 tokenizers 库已成为分词器的事实标准。不过 Hugging Face 的 tokenizers 是用 Rust 来实现的,官方只提供了 python 和 node 的绑定实现。要实现与 Hugging Face tokenizers 相同的行为,最好的办法…...