python手动搭建transformer,并实现自回归推理
以下是添加了详细注释的代码和参数介绍:
Transformer 实现及自回归推理
本文展示了如何手动实现一个简化版的Transformer模型,并用自回归方式实现一个seq2seq任务,例如机器翻译。
导入必要的库
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import numpy as np
定义位置编码
Transformer 使用位置编码来捕捉序列中的位置信息。
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super(PositionalEncoding, self).__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-np.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0).transpose(0, 1)self.register_buffer('pe', pe)def forward(self, x):return x + self.pe[:x.size(0), :]
参数介绍:
d_model: 词嵌入和位置编码的维度。max_len: 序列的最大长度。
定义自注意力机制
class MultiHeadAttention(nn.Module):def __init__(self, d_model, num_heads):super(MultiHeadAttention, self).__init__()self.num_heads = num_headsself.d_model = d_modelassert d_model % num_heads == 0self.depth = d_model // num_headsself.wq = nn.Linear(d_model, d_model)self.wk = nn.Linear(d_model, d_model)self.wv = nn.Linear(d_model, d_model)self.dense = nn.Linear(d_model, d_model)def split_heads(self, x, batch_size):x = x.view(batch_size, -1, self.num_heads, self.depth)return x.permute(0, 2, 1, 3)def forward(self, v, k, q, mask):batch_size = q.size(0)q = self.split_heads(self.wq(q), batch_size)k = self.split_heads(self.wk(k), batch_size)v = self.split_heads(self.wv(v), batch_size)matmul_qk = torch.matmul(q, k.transpose(-1, -2))dk = torch.tensor(k.size(-1)).float()scaled_attention_logits = matmul_qk / torch.sqrt(dk)if mask is not None:scaled_attention_logits += (mask * -1e9)attention_weights = F.softmax(scaled_attention_logits, dim=-1)output = torch.matmul(attention_weights, v)output = output.permute(0, 2, 1, 3).contiguous()output = output.view(batch_size, -1, self.d_model)return self.dense(output)
参数介绍:
d_model: 词嵌入和注意力机制的维度。num_heads: 注意力头的数量。
定义前馈神经网络
class FeedForward(nn.Module):def __init__(self, d_model, dff):super(FeedForward, self).__init__()self.linear1 = nn.Linear(d_model, dff)self.linear2 = nn.Linear(dff, d_model)def forward(self, x):return self.linear2(F.relu(self.linear1(x)))
参数介绍:
d_model: 词嵌入的维度。dff: 前馈神经网络的隐藏层维度。
定义编码器层
class EncoderLayer(nn.Module):def __init__(self, d_model, num_heads, dff, dropout=0.1):super(EncoderLayer, self).__init__()self.mha = MultiHeadAttention(d_model, num_heads)self.ffn = FeedForward(d_model, dff)self.layernorm1 = nn.LayerNorm(d_model)self.layernorm2 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)def forward(self, x, mask):attn_output = self.mha(x, x, x, mask)out1 = self.layernorm1(x + self.dropout1(attn_output))ffn_output = self.ffn(out1)out2 = self.layernorm2(out1 + self.dropout2(ffn_output))return out2
参数介绍:
d_model: 词嵌入和注意力机制的维度。num_heads: 注意力头的数量。dff: 前馈神经网络的隐藏层维度。dropout: Dropout 概率。
定义编码器
class Encoder(nn.Module):def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size, max_len, dropout=0.1):super(Encoder, self).__init__()self.d_model = d_modelself.num_layers = num_layersself.embedding = nn.Embedding(input_vocab_size, d_model)self.pos_encoding = PositionalEncoding(d_model, max_len)self.enc_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, dff, dropout) for _ in range(num_layers)])self.dropout = nn.Dropout(dropout)def forward(self, x, mask):seq_len = x.size(1)x = self.embedding(x)x *= torch.sqrt(torch.tensor(self.d_model, dtype=torch.float32))x = self.pos_encoding(x.permute(1, 0, 2))x = x.permute(1, 0, 2)x = self.dropout(x)for i in range(self.num_layers):x = self.enc_layers[i](x, mask)return x
参数介绍:
num_layers: 编码器层的数量。d_model: 词嵌入和注意力机制的维度。num_heads: 注意力头的数量。dff: 前馈神经网络的隐藏层维度。input_vocab_size: 输入词汇表大小。max_len: 序列的最大长度。dropout: Dropout 概率。
定义解码器层
class DecoderLayer(nn.Module):def __init__(self, d_model, num_heads, dff, dropout=0.1):super(DecoderLayer, self).__init__()self.mha1 = MultiHeadAttention(d_model, num_heads)self.mha2 = MultiHeadAttention(d_model, num_heads)self.ffn = FeedForward(d_model, dff)self.layernorm1 = nn.LayerNorm(d_model)self.layernorm2 = nn.LayerNorm(d_model)self.layernorm3 = nn.LayerNorm(d_model)self.dropout1 = nn.Dropout(dropout)self.dropout2 = nn.Dropout(dropout)self.dropout3 = nn.Dropout(dropout)def forward(self, x, enc_output, look_ahead_mask, padding_mask):attn1 = self.mha1(x, x, x, look_ahead_mask)attn1 = self.dropout1(attn1)out1 = self.layernorm1(attn1 + x)attn2 = self.mha2(enc_output, enc_output, out1, padding_mask)attn2 = self.dropout2(attn2)out2 = self.layernorm2(attn2 + out1)ffn_output = self.ffn(out2)ffn_output = self.dropout3(ffn_output)out3 = self.layernorm3(ffn_output + out2)return out3
参数介绍:
d_model: 词嵌入和注意力机制的维度。num_heads: 注意力头的数量。dff: 前馈神经网络的隐藏层维度。dropout: Dropout 概率。
定义解码器
class Decoder(nn.Module):def __init__(self, num_layers, d_model, num_heads, dff, target_vocab_size, max_len, dropout=0.1):super(Decoder, self).__init__()self.d_model = d_modelself.num_layers = num_layersself.embedding = nn.Embedding(target_vocab_size, d_model)self.pos_encoding = PositionalEncoding(d_model, max_len)self.dec_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, dff, dropout) for _ in range(num_layers)])self.dropout = nn.Dropout(dropout)def forward(self, x, enc_output, look_ahead_mask, padding_mask):seq_len = x.size(1)attention_weights = {}x = self.embedding(x)x *= torch.sqrt(torch.tensor(self.d_model, dtype=torch.float32))x = self.pos_encoding(x.permute(1, 0, 2))x = x.permute(1, 0, 2)x = self.dropout(x)for i in range(self.num_layers):x = self.dec_layers[i](x, enc_output, look_ahead_mask, padding_mask)return x
参数介绍:
num_layers: 解码器层的数量。d_model: 词嵌入和注意力机制的维度。num_heads: 注意力头的数量。dff: 前馈神经网络的隐藏层维度。target_vocab_size: 目标词汇表大小。max_len: 序列的最大长度。dropout: Dropout 概率。
定义Transformer模型
class Transformer(nn.Module):def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size, target_vocab_size, pe_input, pe_target, dropout=0.1):super(Transformer, self).__init__()self.encoder = Encoder(num_layers, d_model, num_heads, dff, input_vocab_size, pe_input, dropout)self.decoder = Decoder(num_layers, d_model, num_heads, dff, target_vocab_size, pe_target, dropout)self.final_layer = nn.Linear(d_model, target_vocab_size)def forward(self, inp, tar, enc_padding_mask, look_ahead_mask, dec_padding_mask):enc_output = self.encoder(inp, enc_padding_mask)dec_output = self.decoder(tar, enc_output, look_ahead_mask, dec_padding_mask)final_output = self.final_layer(dec_output)return final_output
参数介绍:
num_layers: 编码器和解码器层的数量。d_model: 词嵌入和注意力机制的维度。num_heads: 注意力头的数量。dff: 前馈神经网络的隐藏层维度。input_vocab_size: 输入词汇表大小。target_vocab_size: 目标词汇表大小。pe_input: 输入序列的最大长度。pe_target: 目标序列的最大长度。dropout: Dropout 概率。
创建掩码
def create_padding_mask(seq):seq = torch.eq(seq, 0)return seq[:, None, None, :]def create_look_ahead_mask(size):mask = torch.triu(torch.ones((size, size)), 1)return mask
自回归推理
实现一个简化的自回归推理过程:
def generate_text(model, input_sequence, start_token, max_length, target_vocab_size):generated = [start_token]model.eval()enc_padding_mask = create_padding_mask(input_sequence)with torch.no_grad():enc_output = model.encoder(input_sequence, enc_padding_mask)for _ in range(max_length):dec_input = torch.tensor(generated).unsqueeze(0)look_ahead_mask = create_look_ahead_mask(dec_input.size(1))dec_padding_mask = create_padding_mask(dec_input)with torch.no_grad():output = model.decoder(dec_input, enc_output, look_ahead_mask, dec_padding_mask)output = model.final_layer(output)next_token = torch.argmax(output[:, -1, :], dim=-1).item()generated.append(next_token)if next_token == eos_token:breakreturn generated
参数介绍:
model: 训练好的Transformer模型。input_sequence: 输入的序列张量。start_token: 生成序列的开始标记。max_length: 生成序列的最大长度。target_vocab_size: 目标词汇表大小。
使用示例
创建一个简单的模型并进行文本生成:
input_vocab_size = 1000 # 输入词汇表大小
target_vocab_size = 1000 # 目标词汇表大小
max_len = 50 # 序列最大长度
num_layers = 2 # 编码器和解码器层的数量
d_model = 512 # 词嵌入和注意力机制的维度
num_heads = 8 # 注意力头的数量
dff = 2048 # 前馈神经网络的隐藏层维度# 创建Transformer模型
transformer = Transformer(num_layers, d_model, num_heads, dff, input_vocab_size, target_vocab_size, max_len, max_len)# 输入序列,假设输入序列为[1, 2, 3, 4, 0, 0, 0]
input_sequence = torch.tensor([[1, 2, 3, 4, 0, 0, 0]])# 假设开始标记为1,结束标记为2
start_token = 1
eos_token = 2# 生成序列
generated_sequence = generate_text(transformer, input_sequence, start_token, max_length=20, target_vocab_size=target_vocab_size)
print("Generated sequence:", generated_sequence)
以上代码展示了一个简化的Transformer模型的实现,包括位置编码、自注意力机制、前馈神经网络、编码器层、解码器层、编码器和解码器整体的实现,以及一个基本的自回归推理过程。你可以根据需要进行调整和扩展。
关于mask的解释
以下关于掩码函数 create_padding_mask 和 create_look_ahead_mask 的详细介绍以及示例。
create_padding_mask
该函数用于生成填充掩码,以忽略序列中的填充值(通常是0)。在Transformer模型中,填充掩码用于屏蔽掉填充值在计算注意力时的影响。
代码实现
def create_padding_mask(seq):seq = torch.eq(seq, 0) # 查找填充值(假设填充值为0),返回一个布尔张量return seq[:, None, None, :] # 扩展维度以适配注意力机制中的广播
示例
假设我们有一个输入序列,其中0是填充值:
seq = torch.tensor([[7, 6, 0, 0, 0], [1, 2, 3, 0, 0]])padding_mask = create_padding_mask(seq)
print(padding_mask)
输出
tensor([[[[False, False, True, True, True]]],[[[False, False, False, True, True]]]])
在输出中,True 表示填充值的位置,这些位置将在计算注意力时被忽略。
create_look_ahead_mask
该函数用于生成前瞻掩码,以确保解码器中的每个位置只能看到该位置之前的序列,不能看到未来的信息。在自回归生成中,前瞻掩码用于防止解码器在生成下一个标记时看到未来的标记。
代码实现
def create_look_ahead_mask(size):mask = torch.triu(torch.ones((size, size)), 1) # 生成上三角矩阵,主对角线以上的元素为1return mask # 返回前瞻掩码
示例
假设我们有一个序列长度为5:
size = 5
look_ahead_mask = create_look_ahead_mask(size)
print(look_ahead_mask)
输出
tensor([[0., 1., 1., 1., 1.],[0., 0., 1., 1., 1.],[0., 0., 0., 1., 1.],[0., 0., 0., 0., 1.],[0., 0., 0., 0., 0.]])
在输出中,1 表示被掩盖的位置,这些位置在计算注意力时将被屏蔽。
综合示例
结合以上两种掩码,假设我们有以下输入序列:
seq = torch.tensor([[7, 6, 0, 0, 0], [1, 2, 3, 0, 0]])
size = seq.size(1)padding_mask = create_padding_mask(seq)
look_ahead_mask = create_look_ahead_mask(size)print("Padding Mask:\n", padding_mask)
print("Look Ahead Mask:\n", look_ahead_mask)
输出
Padding Mask:tensor([[[[False, False, True, True, True]]],[[[False, False, False, True, True]]]])
Look Ahead Mask:tensor([[0., 1., 1., 1., 1.],[0., 0., 1., 1., 1.],[0., 0., 0., 1., 1.],[0., 0., 0., 0., 1.],[0., 0., 0., 0., 0.]])
在实际使用中,编码器使用 padding_mask 来屏蔽填充值的影响,解码器则同时使用 look_ahead_mask 和 padding_mask 来屏蔽未来标记和填充值的影响。
相关文章:
python手动搭建transformer,并实现自回归推理
以下是添加了详细注释的代码和参数介绍: Transformer 实现及自回归推理 本文展示了如何手动实现一个简化版的Transformer模型,并用自回归方式实现一个seq2seq任务,例如机器翻译。 导入必要的库 import torch import torch.nn as nn import…...

AI数据分析:用deepseek进行贡献度分析(帕累托法则)
帕累托法则,也称为80/20法则,是由意大利经济学家维尔弗雷多帕累托提出的。它指出在许多情况下,大约80%的效益来自于20%的原因。这个原则在很多领域都有应用,包括商业、经济、社会问题等。 在数据分析中,帕累托法则可以…...

生成式人工智能的风险与治理——以ChatGPT为例
文 | 西南政法大学经济法学院 马羽男 以ChatGPT为代表的生成式人工智能在创造社会福利的同时,也带来了诸多风险。因此,当务之急是结合我国生成式人工智能发展状况,厘清其应用价值与潜在风险之间的关系,以便在不影响应用发展的前提…...
十足正式在山东开疆拓土!首批店7月初开业,地区便利店现全新面貌!
十足便利店将正式进军山东市场,以济南、淄博两座城市为核心发展起点,目前济南市已经有三家十足门店正在装修施工中,首批15家门店将于7月初开业,这标志着十足集团市场战略布局迈出了至关重要的一步。 随着3月份罗森品牌在济南成功开…...

Unity2D游戏开发-玩家控制
在Unity2D游戏开发中,玩家控制是游戏互动性的核心。本文将解析一个典型的Unity2D玩家控制脚本,探讨如何实现流畅的玩家移动、跳跃和动画切换。以下是一个Unity脚本示例,实现了这些基础功能。 1. 脚本结构 using System.Collections; using …...
如何在 Windows 11 上免费恢复永久删除的文件
虽然Windows 上的已删除文件恢复不简单,但您可能希望免费或无需任何软件即可恢复已删除的文件。下面,我们列出了一个指南,其中包含有关如何在 Windows 11 上免费检索永久删除的文件的说明。 #1 奇客数据恢复 奇客数据恢复是一个广受好评的免…...
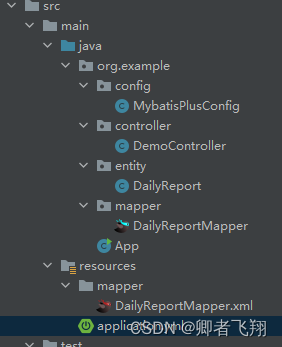
Spring boot 集成mybatis-plus
Spring boot 集成mybatis-plus 背景 Spring boot集成mybatis后,我们可以使用mybatis来操作数据。然后,我们还是需要写许多重复的代码和sql语句,比如增删改查。这时候,我们就可以使用 mybatis-plus了,它可以极大解放我…...

数据仓库之缓慢变化维
缓慢变化维(Slowly Changing Dimensions, SCD)是数据仓库设计中的一个重要概念,用于处理维度表中随时间缓慢变化的属性。维度表中的数据通常描述业务实体(如客户、产品、员工等),而这些实体的某些属性&…...

跑mask2former(自用)
1. 运行docker 基本命令: sudo docker ps -a (列出所有容器状态) sudo docker run -dit -v /hdd/lyh/mask2former:/mask --gpus "device0,1" --shm-size 16G --name mask 11.1:v6 (创建docker容器&…...

Linux日志服务rsyslog深度解析(上)
🐇明明跟你说过:个人主页 🏅个人专栏:《Linux :从菜鸟到飞鸟的逆袭》🏅 🔖行路有良友,便是天堂🔖 目录 一、引言 1、日志在Linux系统中的作用 2、rsyslog历史背景 …...
函数)
python的df.describe()函数
一、初识describe()函数 在数据分析和处理的过程中,我们经常需要了解数据的基本统计信息,如均值、标准差、最小值、最大值等。pandas库中的describe()函数为我们提供了这样的功能,它可以快速生成数据集的描述性统计信息。 二、describe()函数的基本用法 describe()函数是pan…...

Feign的介绍与说明
Feign是Spring Cloud提供的一个声明式、模板化的HTTP客户端,旨在使编写Java HTTP客户端变得更容易。它的设计目标是让Web服务调用变得更加简单,无论是在本地还是在远程。使用Feign,开发者可以像调用本地服务一样调用远程服务,提供…...

【Linux】用户和组的管理、综合实训
目录 实训1:用户的管理 实训2:组的管理 实训3:综合实训 实训1:用户的管理 (1)创建一个新用户userl,设置其主目录为/home/user 1。 (2)查看/etc/passwd 文件的最后一行,看看是如何记录的。 (3)查看文件/etc/shadow文件的最后一…...
B=2W,奈奎斯特极限定理详解
一直没搞明白奈奎斯特极限定理的含义,网上搜了很久也没得到答案。最近深思几天后,终于有了点心得。顺便吐槽一下,csdn的提问栏目,有很多人用chatgpt秒回这个事,实在是解决不了问题,有时候人的问题大多数都是…...

【Pytorch 】Dataset 和Dataloader制作数据集
文章目录 Dataset 和 Dataloader定义Dataset定义Dataloader综合案例1 导入两个列表到Dataset综合案例2 导入 excel 到Dataset综合案例3 导入图片到Dataset导入官方数据集Dataset 和 Dataloader Dataset指定了数据集包含了什么,可以是自定义数据集,也可以是以及官方数据集Data…...
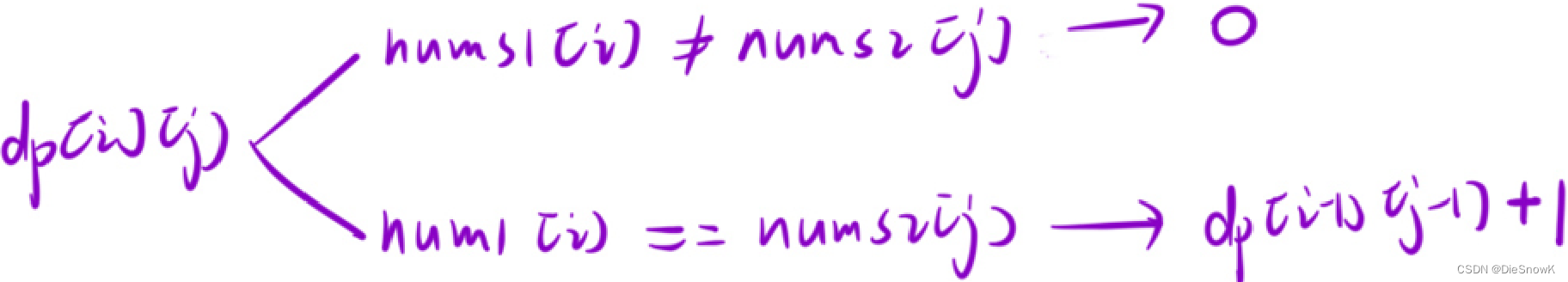
[Algorithm][动态规划][两个数组的DP][正则表达式匹配][交错字符串][两个字符串的最小ASCII删除和][最长重复子数组]详细讲解
目录 1.正则表达式匹配1.题目链接2.算法原理详解3.代码实现 2.交错字符串1.题目链接2.算法原理详解3.代码实现 3.两个字符串的最小ASCII删除和1.题目链接2.算法原理详解3.代码实现 4.最长重复子数组1.题目链接2.算法原理详解3.代码实现 1.正则表达式匹配 1.题目链接 正则表达…...
Ffmpeg安装和简单使用
Ffmpeg安装 下载并解压 进入官网 (https://ffmpeg.org/download.html),选择 Window 然后再打开的页面中下滑找到 release builds,点击 zip 文件下载 环境变量配置 下载好之后解压,找到 bin 文件夹,里面有3个 .exe 文件 然后复制…...

29、matlab算数运算汇总2:加、减、乘、除、幂、四舍五入
1、乘法:times, .* 语法 C A.*B 通过将对应的元素相乘来将数组 A 和 B 相乘。 C times(A,B) 是执行 A.*B 的替代方法, 1)将两个向量相乘 代码及运算 A [1 0 3]; B [2 3 7]; C A.*BC 2 0 212) 将两个数组相乘 代码及运算 A [1 0 3;…...

<Rust><iced>基于rust使用iced库构建GUI实例:动态改变主题色
前言 本专栏是Rust实例应用。 环境配置 平台:windows 软件:vscode 语言:rust 库:iced、iced_aw 概述 本篇构建了这样的一个实例,可以动态修改UI的主题,通过菜单栏来选择预设的自定义主题和官方主题&#…...

k8s——安全机制
一、安全机制说明 Kubernetes作为一个分布式集群的管理工具,保证集群的安全性是其一个重要的任务。API Server是集群内部各个组件通信的中介, 也是外部控制的入口。所以Kubernetes的安全机制基本就是围绕保护API Server来设计的。 比如 kubectl 如果想…...
Pixel Script Temple 企业知识库图解:将文档内容自动转化为像素示意图
Pixel Script Temple 企业知识库图解:将文档内容自动转化为像素示意图 1. 企业知识管理的痛点与机遇 技术文档和操作手册是企业知识管理的重要组成部分,但传统文档形式存在明显的可读性问题。密密麻麻的文字说明、复杂的流程图和晦涩的专业术语&#x…...

2026年AI就业风口!这5个神仙岗位,高薪低门槛,普通人也能转行!
根据LinkedIn数据,2026年AI相关岗位增长迅猛,其中AI咨询顾问、机器学习工程师、AI产品经理、数据与检索工程师等岗位需求旺盛,且部分岗位对计算机科学学位要求不高。文章详细介绍了这5个岗位的火热原因、转行路径及薪资范围,并给出…...

音乐版权检测新方案:CCMusic模型与MySQL数据库集成
音乐版权检测新方案:CCMusic模型与MySQL数据库集成 用AI技术解决音乐版权保护难题,让每一首作品都能得到应有的尊重 1. 引言:音乐版权保护的现实挑战 音乐创作者们经常面临这样的困境:自己的作品在各大平台被无授权使用ÿ…...

GNSS数据处理避坑指南:从CDDIS、IGS等官网下载BSX、DCB文件的保姆级教程
GNSS数据处理避坑指南:从CDDIS、IGS等官网下载BSX、DCB文件的保姆级教程 第一次接触GNSS数据处理时,面对各种数据中心的复杂目录和神秘的文件命名规则,我完全懵了。记得当时为了找一个.BSX文件,整整花了两天时间在不同网站间来回切…...

瑞芯微RK3399固件急救指南:用upgrade_tool搞定系统崩溃后的快速还原
RK3399固件灾难恢复实战:从分区表重建到全系统还原 当一块搭载RK3399的开发板因固件损坏而变砖时,那种面对黑屏的无力感,相信每个嵌入式开发者都深有体会。去年我们产线就遭遇过因批量升级失败导致30台设备集体罢工的紧急状况,正…...

3步掌握WindowResizer:免费强制调整任意窗口大小的终极方案
3步掌握WindowResizer:免费强制调整任意窗口大小的终极方案 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些顽固的窗口尺寸而烦恼吗?无论你面对的…...

我的实用设计模式之 关于Policy-based design在Windows Mobile网络连接管理的应用
Raw Data(原数据)使用不要的分析器(分析器使用不同的算法)分析出关心的Event(事件,对象,告警等等)。同时作为behavior模式之一,stragety模式也可以使用在 定义多个behavi…...

掌握LiteDB.Studio:嵌入式文档数据库可视化管理工具全攻略
掌握LiteDB.Studio:嵌入式文档数据库可视化管理工具全攻略 【免费下载链接】LiteDB.Studio A GUI tool for viewing and editing documents for LiteDB v5 项目地址: https://gitcode.com/gh_mirrors/li/LiteDB.Studio 在现代软件开发中,嵌入式数…...

新手入门:借助快马AI实现你的第一个超能力选择网页
作为一个刚接触编程的新手,我最近想尝试做一个有趣的网页项目。看到网上那些酷炫的交互效果,总觉得很神奇但又无从下手。直到发现了InsCode(快马)平台,它让我这个小白也能轻松实现"超能力选择器"这样的创意想法。 项目构思 我想做一…...

GitHub资源精准下载:DownGit实现90%带宽节省的技术方案
GitHub资源精准下载:DownGit实现90%带宽节省的技术方案 【免费下载链接】DownGit github 资源打包下载工具 项目地址: https://gitcode.com/gh_mirrors/dow/DownGit 在开源开发流程中,开发者经常需要从GitHub仓库获取特定文件夹资源。传统方式下&…...