MQ之初识kafka
1. MQ简介
1.1 MQ的诞生背景
以前网络上的计算机(或者说不同的进程)传递数据,通信都是点对点的,而且要实现相同的协议(HTTP、 TCP、WebService)。1983 年的时候,有个在 MIT 工作的印度小伙突发奇想,能不能发明一种专门用来通 信的中间件,就像主板(BUS)一样,把不同的软件集成起来呢?于是他搞了一家公司(Teknekron),开发 了世界上第一个消息队列软件 The Information Bus(TIB)。
1.2 什么是MQ
MQ全称是Message Queue,直译过来叫消息队列,在消息的传输中用于保存消息的容器,主要是作为分布式应用之间实现异步通信的方式。
主要由三部分组成,分别是 生产者、消息服务端和消费者
生产者( Producer ),是生产消息的一端,相当于消息的发起方,主要负责载业务信息的消息的创建。消息服务端( Server ),是处理消息的单元,本质就是用来创建和保存消息队列,它主要负责消息的存储、投递以及跟消息队列相关的附加功能。消息服务端是整个消息队列最核心的组成部分。第三个是消费者( Consumer ),是消费消息的一端,主要是根据消息所承载的信息去处理各种业务逻辑。
何为生产者? 何为消息队列?何为消费者? 举个例子,如下图,第一阶段是爸爸点对点的把书送到儿子手中,即为我们的点对点通信,但后面爸爸发现这种方式即耗时又费力,因此买了个书架,每次只用把书放到书架上就行了,儿子在规定时间内去学完就可以了,后面妈妈也发现了这个好处,于是她也向书架中放书,小明的姐姐也可以去书架上消费。爸爸妈妈就是我们的生产者,书架就是一个消息队列,小明以及小明的姐姐就是消费者。

1.3 MQ的应用场景
1.3.1 应用解耦
由上图可以看出,后面引入了书架后,爸爸就不需要单独给小明书了,因此这是一种应用的解耦。比如我们下面的例子,订单系统模块直接调用库存系统模块,依赖性太强,当某天库存系统出问题时,连带的订单系统模块就也有问题了,我们引入了MQ以后,订单系统只用把消息发布到MQ即可,不管库存系统暂时有没有问题,等它没有问题的时候再去MQ中订阅消息

1.3.2 异步提速
如下图所示,没有使用MQ之前。用户注册,发送邮件,发送短信是同步的,总耗时300ms,而引入MQ之后,用户注册后,只用把消息发送给MQ,然后MQ异步分别发送注册邮件和发送注册短信,注册成功的总耗时就只有110ms.因此MQ可以起到异步提速的作用

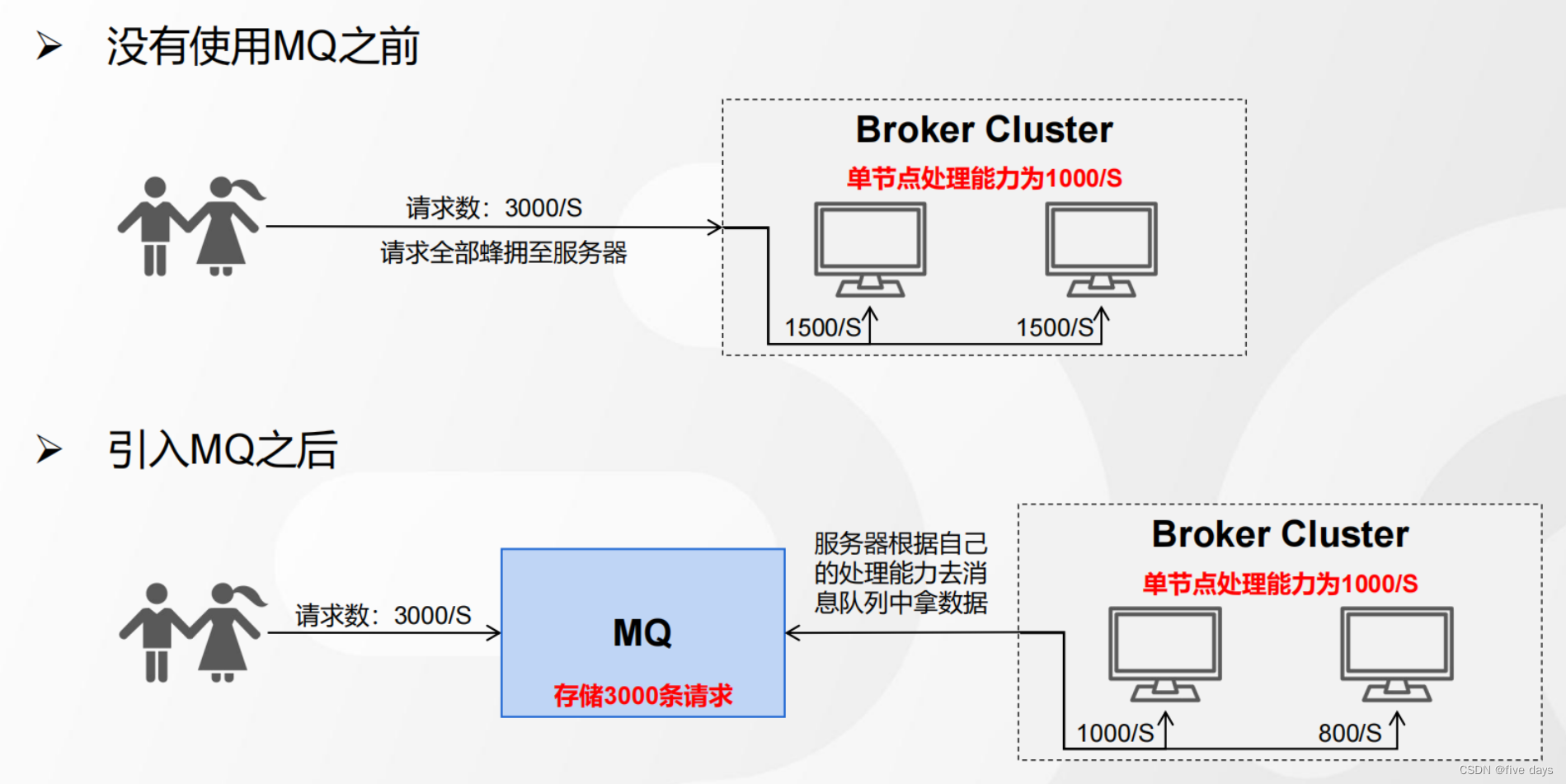
1.3.3 限流削峰
几个例子,大家都去饭店吃过饭把,当饭店特别火爆的时候,店长怎么处理了,肯定是不会让你滚蛋把,而是给你一个票进行排队,那么这些排队的方式就是一个削峰的场景,排队的这些号码就是我们的MQ;也就是说,当没有MQ的时候,我们的服务器处理能力有限,当请求全部涌入进来时,就会造成服务器极大的压力,甚至承受不住。当我们引入MQ之后,就可以先把这个请求放到MQ中,服务器根据自己的处理能力去MQ中拿。
2. Kafka重要组件
kafka是MQ的一种,基于TCP的二进制协议。内部是通过长度来分隔。单机吞吐量支持十万级别。时效性延迟在ms级以内,高可用性,kafaka是分布式的,一个数据多个读本,少数机器宕机,不会丢失数量,不会导致不可用。经过参数的优化配置,消息可以做到0丢失。功能上较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用。那么kafaka由哪些组件组成的呢?
2.1 Broker

1.Broker就是Kafka的服务器,用于存储和管理消息,默认是9092的端口
2.生产者和Broker建立连接,将消息发送到服务器上、存储起来
3.消费者跟Broker建立连接,订阅和消费服务器上存储的消息
2.2 Record

1.客户端之间传输的数据叫做消息,在Kafka中也叫Record(记录)
2.Record在客户端中是一个KV键值对(ProducerRecord、ConsumerRecord)
3.Record在服务端中的存储格式也是KV键值对(RecordBatch 或 Record)
2.3 Rroducer
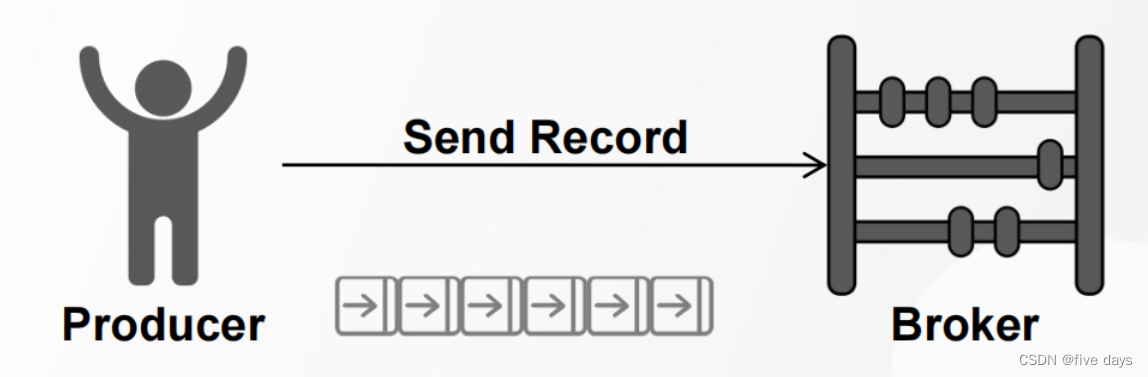
1.发送消息的一方叫做生产者
2.Kafka为提升消息发送速率,生产者默认采用批量发送的方式发送消息至Broker
3.Kafka为提升消息发送速率,生产者默认采用批量发送的方式发送消息至Broker
2.4 Consumer
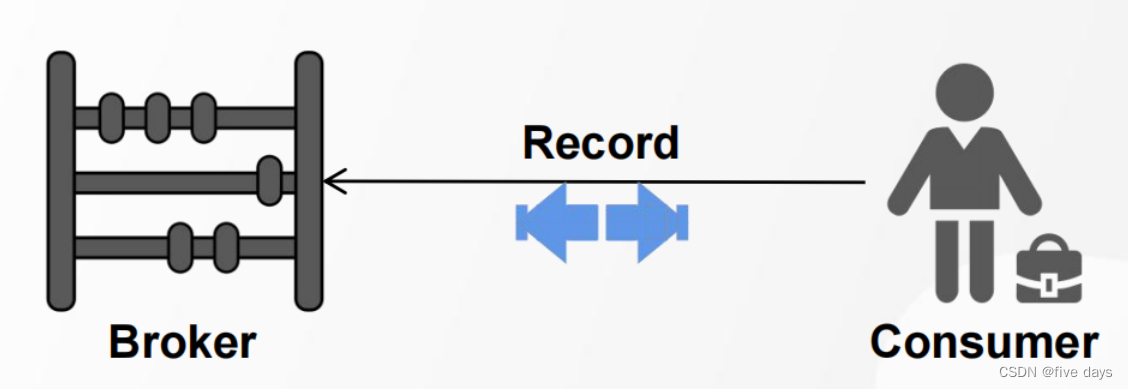
1. 订阅、接收消息的一方叫做消费者
2. 消费者端获取消息有两种模式:Pull模式[拉]、Push模式[推]
3. Pull模式,消费者可以自己控制一次到底获取多少条消息(max.poll.records)
2.5 Topic
在Broken中会采用topi主题的方式用来划分不同的业务线

1. Topic(主题)是一个逻辑概念,可以理解为一组消息的集合
2. 生产者和消费者通过Topic进行消息的写入和读取
3. 生产者发送消息时,若Topic不存在,是否自动创建:auto.create.topics.enable(但一般禁用,因为不便于维护)
2.6 Partition
在一个topic中,当数据量特别大的时候,就会极大的影响我们的查询效率,就好比mysql的分库分表,因此在kafka中,也引入了一个partition分区的这样的一个概念,从而提升查询效率,也实现了消息的负载均衡。

1. 所谓分区(Partition)就是把一个Topic分成几个不同的部分
2. 一个Topic可以在创建时划分成多个分区
3. 若没有指定分区数,默认分区数为1,通过参数可修改(num.partitions)
4. Kafka中修改分区的规则:可加、不可减
可以指定以下参数进行配置 为不同的topic主题配置对应的partition分区
./kafka-topics.sh --create --topic TopicA --bootstrap-server 192.168.61.100:9092 --replication-factor 1 --partitions 3
./kafka-topics.sh --create --topic TopicB --bootstrap-server 192.168.61.100:9092 --replication-factor 1 --partitions 3
2.7 Replica机制(副本机制)
partition虽然实现了消息的负载,但还是在一台服务器上,并没有实现真正意义上的负载均衡,因此引入了replica副本机制,实现真正的负载均衡

1. Replica(副本)是Partition(分区)的副本,每个分区可以有若干个副本
2. 副本必须在不同的Broker节点上,副本包括了主从节点(Leader、Follower)
3. 服务端可以通过参数控制默认副本数(offsets.topic.replication.factor)
副本的配置可以通过replication-factor参数指定
sh kafka-topics.sh --create --topic TopicA --bootstrap-server 192.168.61.100:9092 --replication-factor 3 --partitions 3
2.7 Segment
每一个partition里面都有一个log文件,当这个文件越来越大的时候,也会影响查询效率,因此kafka又引进了一个segment段的概念,来提升查询的效率。

1.Segment(段)的目的是:将一个分区中的数据划分、存储到不同的文件中
2.每个 Segment 至少由 1 个数据文件和 2 个索引文件构成, 3 个文件是成套出现的3.引入段带来的意义:3.1 加快查询效率3.2 删除数据时减少逐条 IO4. Segment 大小控制4.1 按时间周期生成( log.roll.hours )4.2 按文件大小生成( log.segment.bytes )
2.8 Consumer Group
假设生产者生产消息速度很快。势必就会造成大量的消息堆积,入口快,对应的出口就也很快,因此需要采用一些策略来提升消息的消费速率,假设我没用消费者组,则来了几个消费者,我们怎么直到要消费这个主题topic呢?所以才有了消费者组的概念,让这个组去订阅这个主题。
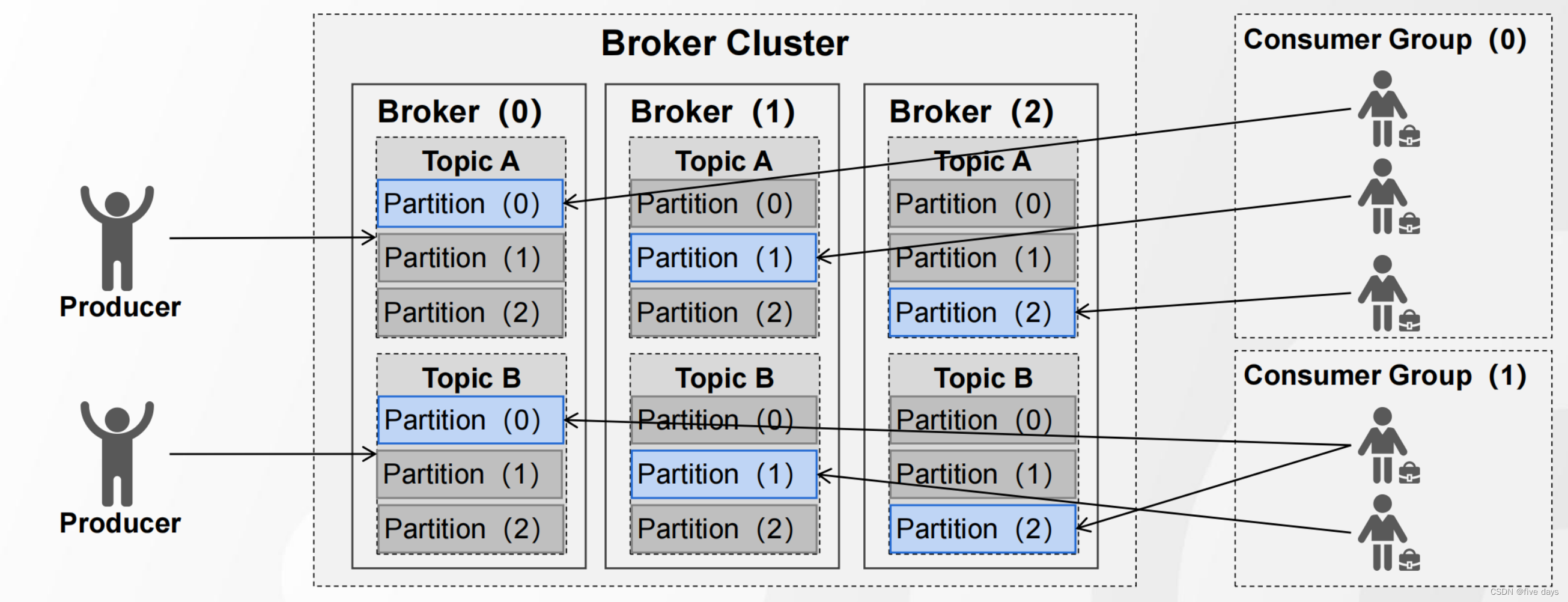
1. 使用消费者组,提升消费效率和吞吐量
2. 同一个Group中的消费者,不能消费相同的Partition(group id相同,在一个组中)
2.9 Cunsumer Offset

在kafka中,消息消费完后,并不会立即删除,假设我们消费完前面的两个消息后,服务节点挂了,我们再次重启服务的时候,是不是希望从第3个节点开始消费,于是就引入了偏移量consumer offset。

Offset(偏移量)的目的在于:记录消费者的消费位置
Kafka 现行版本将 Offset 保存在服务器( __consumer_offsets )主题中
3. Kafka整体架构
从第2章我们简单了解到了kafka的各个组件以及各个组件的基本作用,那么kafka的一个整体架构是怎么样的呢?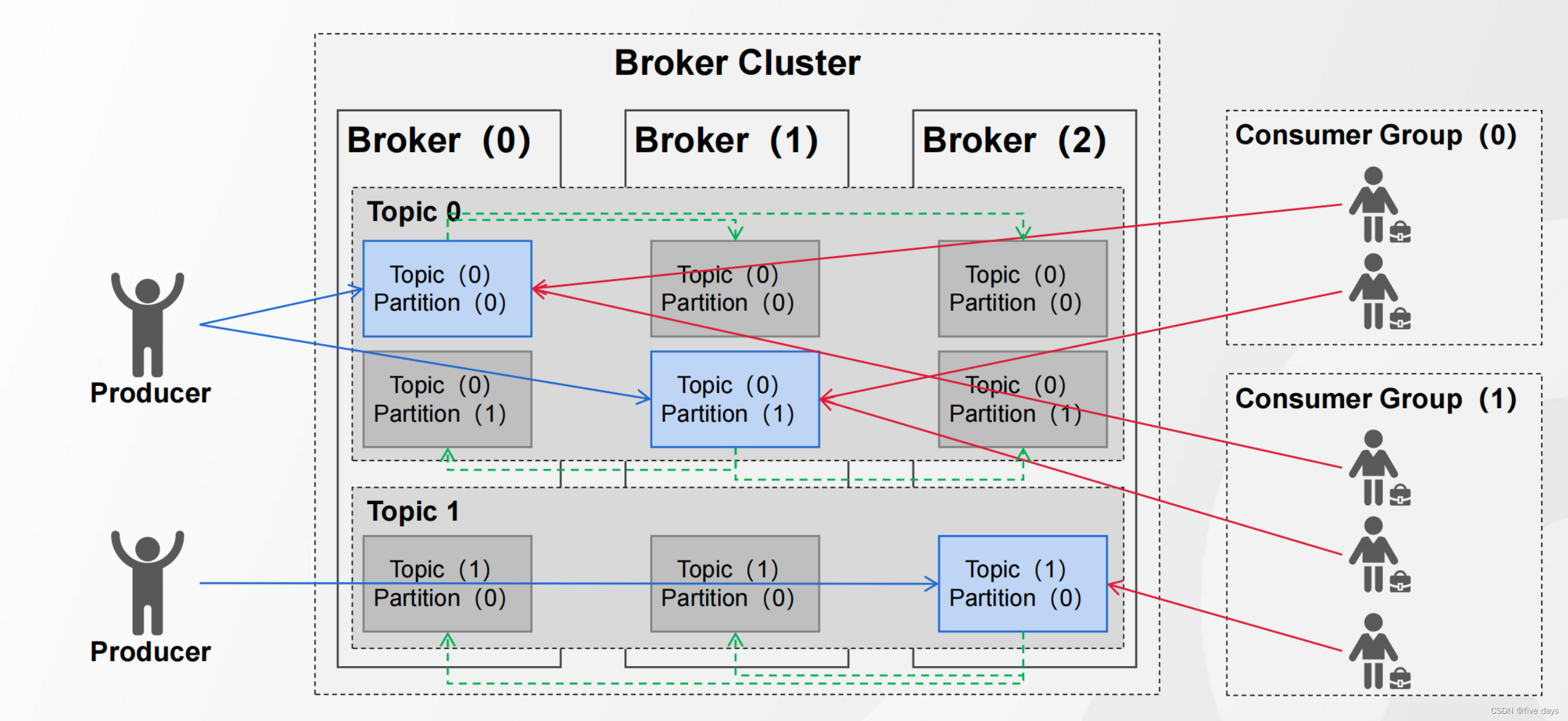
生产者producer向broker中的topic发送消息,消息的存储会有一个主分区叫做leader,实现负载均衡,消息分别保存在不同服务器的leader上面,然后在另外的两个服务器上有两个副本叫做follow,由leader异步同步数据到follow中,保证了数据的可靠性。consumer端,又分为不同的group,每个group中的消费者去这些分区中订阅。
4. Kafka特性
kafa要想保证消息的可靠性,就必须落到磁盘中,那么既然kafka是要跟磁盘进行IO的,那又是如何保证高吞吐,低延迟的呢? 主要有以下4个特性
- 磁盘顺序IO
- 索引
- 批量读写和压缩算法
- 零拷贝
4.1 磁盘顺序IO
磁盘随机IO和磁盘顺序IO
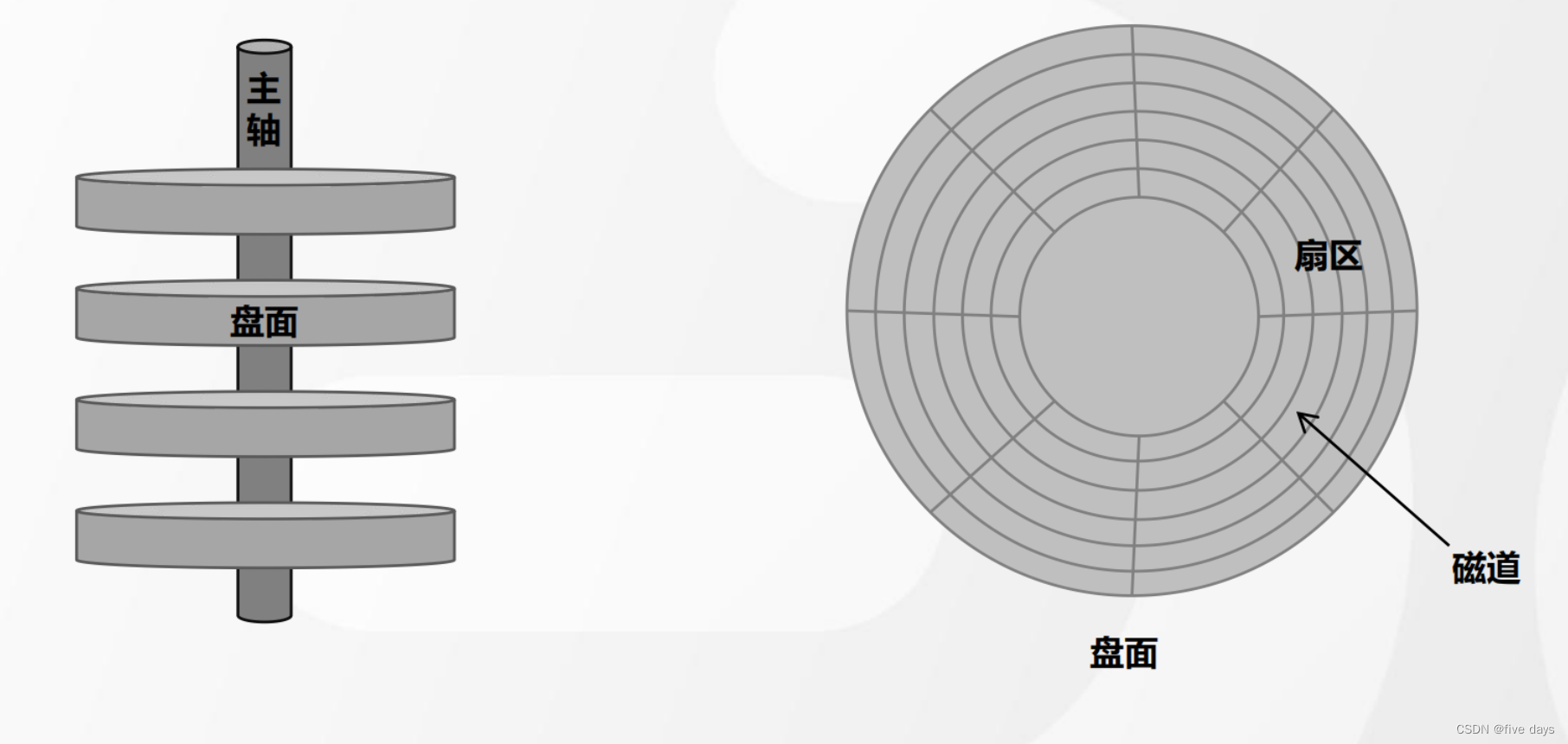
如下图,磁盘交互的主要时间消耗主要在磁盘选址中。磁盘的构成如上图所示,是一个个的扇区和磁道构成的,随机IO的数据存储是分散性的,因此选址比较浪费时间,而磁盘顺序IO是几种存储追加的形式,一旦确定了一个物理地址,后面的存储就在这个物理地址后面追加,因此寻址的时候,可能只需要一次寻址就可以了。磁盘顺序IO的读写速度是不逊于内存读写的。
4.2 索引
Broker 端原理数据存储Offset 索引、时间戳索引、稀疏索引
4.3 批量处理和压缩传递
收发消息时批量处理压缩算法进行压缩后传递
4.4 零拷贝
在了解零拷贝前,我们先来看一个传统的IO
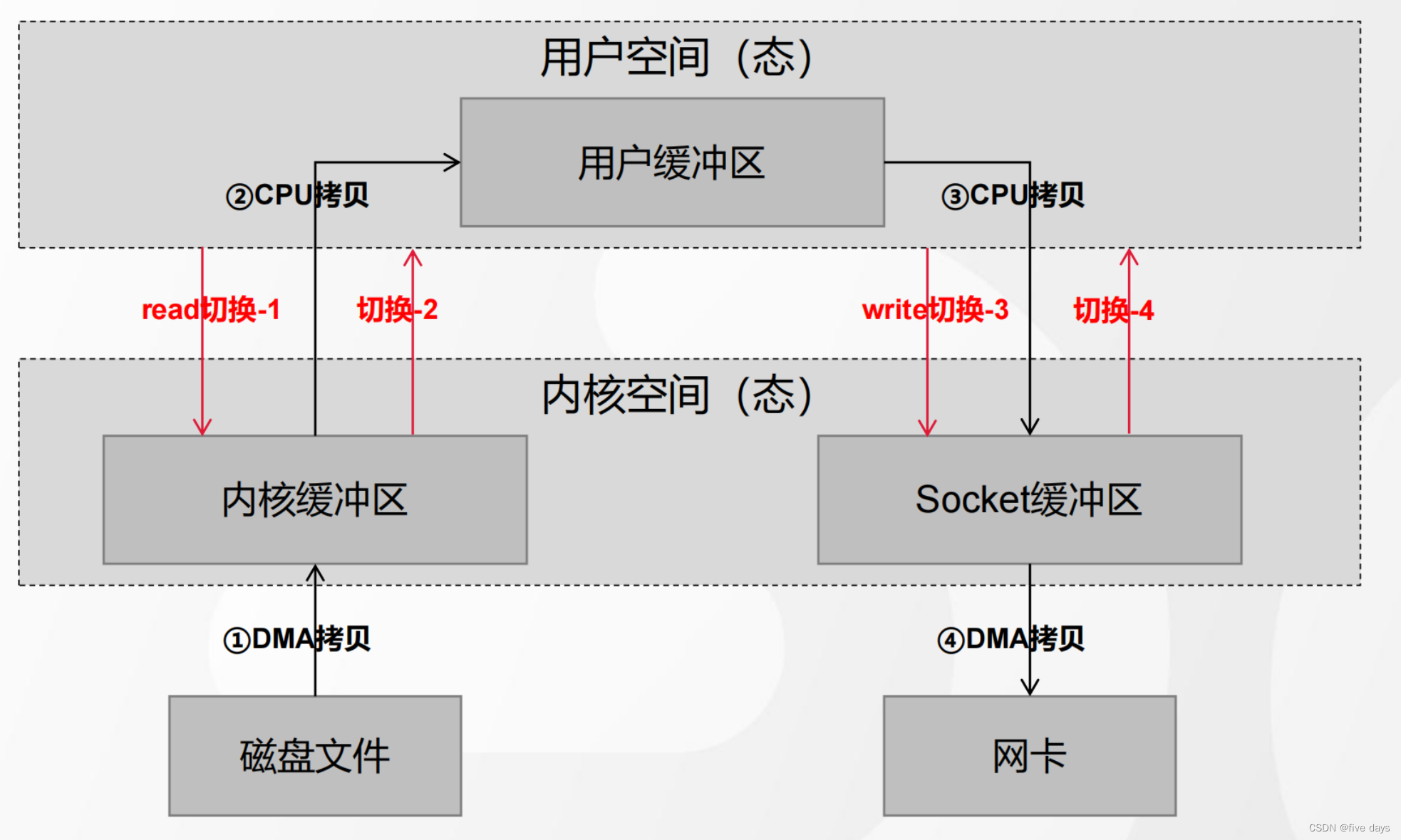
我们直到,在计算机层面是会分为用户态和内核态的,这主要是为了保护操作系统,防止用户空间的进程操作到内核中。有了这么的一个概念,我们从用户程序中读写磁盘的数据,就难免要去与内核空间进行交互,那么传统的交互方式是怎么样的呢?
我们从用户空间出发,会先进行read从内核空间中读取。内核空间中的磁盘数据经由DMA拷贝到内核态中,然后会在经过PU拷贝到用户态中,用户态在经过拷贝到网络的sockect缓冲区,随后DMA拷贝到网卡中,也就是我们的网络交互传输的一个IO设备中。可以看到,传统的io形式经历了4次的用户态与内核态的交互,会大大的降低响应速度。因此kafak引入了一个零拷贝的技术。

直接从内核态的内核缓冲区经SG-DMA拷贝到网卡中。
5. 总结
本文主要从宏观的角度上介绍了消息队列MQ的背景、原理以及应用场景。随后分析了现在主流的MQ技术的落地Kafka,先是认识了kafka的各个组件,整体架构设计,还有kafak能够实现高吞吐低延时的一些保证特性,先大概有个整体的认识,随后会对每个模块进行详细的展开阐述以及原理分析。
相关文章:
MQ之初识kafka
1. MQ简介 1.1 MQ的诞生背景 以前网络上的计算机(或者说不同的进程)传递数据,通信都是点对点的,而且要实现相同的协议(HTTP、 TCP、WebService)。1983 年的时候,有个在 MIT 工作的印度小伙突发…...

linux驱动学习(七)之混杂设备
需要板子一起学习的可以这里购买(含资料):点击跳转 一、混杂设备 混杂设备也叫杂项设备,是对普通的字符设备(struct cdev)的一种封装,设计目的就是为了简化字符设备驱动设计的流程。具有以下特点: 1) 主设备号为10&a…...

【数据结构与算法 | 堆篇】力扣215, 703
1. 力扣215 : 数组中的第k个最大元素 (1). 题 给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。 请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。 你必须设计并实现时间复杂度为 O(n) 的算法解…...

项目经理进入职场都会经历的三个阶段
对于项目经理而言,进入职场是一个不断学习和成长的过程。在这个过程中,项目经理通常会经历三个主要阶段,每个阶段都有其独特的特点和挑战。 一、基础建设与学习阶段 对于新入行的项目经理来说,最初的阶段主要是基础技能的积累和…...

消防设施工程乙级资质全解析:申请条件与流程“
消防设施工程乙级资质全解析:申请条件与流程 消防设施工程乙级资质,作为衡量企业从事特定规模消防设施设计能力的重要标尺,对于想要在消防工程领域拓展业务的企业而言至关重要。本文将全面解析申请消防设施工程乙级资质所需的条件、流程及相…...
【C语言】03.分支结构
本文用以介绍分支结构,主要的实现方式为if语句和switch语句。 一、if语句 1.1 if语句 if (表达式)语句表达式为真则执行语句,为假就不执行。在C语言中,0表示假,非0表示真.下图表示if的执行过程: 1.2 else语句 当…...

uniapp手机屏幕左滑返回上一页支持APP,H5
核心:touchstart"touchStart" touchend"touchEnd" 代码示例: <template><view class"payPasswordSetting" touchstart"touchStart" touchend"touchEnd"></view> </template&g…...
【Java毕业设计】基于JavaWeb的洗衣店管理系统
文章目录 摘要ABSTRACT目 录1 概述1.1 研究背景及意义1.2 国内外研究现状1.3 拟研究内容1.4 系统开发技术1.4.1 SpringBoot框架1.4.2 MySQL数据库1.4.3 MVC模式 2 系统需求分析2.1 可行性分析2.2 功能需求分析 3 系统设计3.1 功能模块设计3.2 系统流程设计3.3 数据库设计3.3.1 …...

使用sqlldr向oracle导入大量数据
(1)在Oracle主机安装oracle客户端 sqlldr,在命令行输入sqlldr,若有help指导即已经安装了; (2)创建一个xxx.ctl文件 这个文件是执行导入数据的语句,其中包含需要导入的数据&#x…...

Milvus LIKE操作符
在Milvus中,虽然LIKE操作符被用于模糊匹配字符串,但其支持的模式匹配能力有限。根据你收到的错误信息,Milvus目前只支持两种类型的LIKE模式匹配: 前缀匹配,例如LIKE ab%,这意味着任何以ab开头的字符串都会…...

iQOO neo 5精简内置组件
无他!系统自带了太多组件,都用不到,连打开都不曾打开过。 下午整理一篇精简组件的列表,各自按照各自的需要进行精简哦。别盲目跟风,要不然手机使用会出问题。 精简步骤 使用任意刷机工具,开启手机的开发权限,然后adb连接 删除组件列表如下: pm uninstall --user 0…...
为什么给网站安装SSL证书之后还是有被提示不安全?
分为两种情况一种是安装了付费证书之后还是显示无效,另一种是安装了免费SSL证书的。 付费SSL证书:直接找厂商帮助解决遇到的问题,一般都是有专业的客服来对接这些的。 免费SSL证书:出现这种情况的原因会有很多。因为免费SSL证书的…...

创建Frame单例,实现WPF页面跳转
需求: 有一个F0View主页面入口,三个子页面(First.xaml/Second.xaml/Third.xaml)用Frame默认加载第一个页面 First.xaml。实现三个页面之间顺序跳转,并且每个页面只初始化一次。 实现: 1,将三…...

正宇软件助力江西数字人大建设,高效解决群众“急难愁盼”问题
近日,赣州市南康区群众通过“江西数字人大”小程序成功解决道路塌陷等民生问题,引发社会广泛关注。这一成功案例不仅彰显了“数字人大”在解决群众“急难愁盼”问题中的重要作用,也凸显了江西地区近年来在数字化人大建设方面的显著成效。正宇…...

打造AIPC轻量化方案 360AI浏览器及360AI搜索全新发布
“搜索这20多年来没有发生变化,我们希望这次能来一场革命。”6月6日,360AI新品发布会暨开发者沟通会在京举办。会上,三六零(股票代码:601360.SH,以下简称360)集团发布全新360AI搜索及360AI浏览器…...

《effective c++》学习笔记
从今天开始看《effective c》这本书,把学到的东西当做笔记记下来,算是督促自己学习吧,也算是和大家一起分享一点东西,理解不当的地方,请谅解。(每天更新三个条款)。 一:让自己习惯C…...
11.盛水最多的容器
给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。 找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。 返回容器可以储存的最大水量。 说明:你不能倾斜容器。 示例 1&a…...

通过在idea上搭建虚拟hadoop环境使用MapReduce做词频去重
idea上的MapReduce 一般在开发中,若是等到环境搭配好了再进行测试或者统计数据,数据处理等操作,那会很耽误时间,所以一般都是2头跑,1波人去在客户机上搭建环境,1波人通过在idea上搭建虚拟hadoop环境&am…...

AI技术变革与企业服务创新
1、AI的技术变革 1)AI市场规模 2)AI大模型发展历程 3)AIGC发展背景 4)AIGC技术能力 AIGC的技术架构逻辑上分为基础层、技术层、能力层、应用层、终端层五大板块,其中核心技术层涵盖AI技术群和大模型的融合创新&#…...

探秘Facebook:社交媒体的未来之路
Facebook,作为全球最大的社交媒体平台之一,一直处于数字社交革命的前沿。然而,随着科技和社会的不断发展,Facebook正面临着新的挑战和机遇。本文将探索Facebook的未来之路,揭示社交媒体的新趋势和发展方向。 1. 深度社…...

内网渗透初探保姆级教程!零基础小白从零入门,轻松学会内网渗透核心知识
0x01 基础知识 内网渗透,从字面上理解便是对目标服务器所在内网进行渗透并最终获取域控权限的一种渗透。内网渗透的前提需要获取一个Webshell,可以是低权限的Webshell,因为可以通过提权获取高权限。 在进行内网渗透之前需要了解一个概念&…...
模型)
【AI】开源文字转语音(TTS)模型
目前开源界在文字转语音(TTS)领域非常活跃,特别是针对多角色对话、情感控制和声音克隆方面,涌现了几个非常强大的模型。 结合(多角色、好用、开源),以下几款目前(截至2026年4月&…...
)
I.MX6U-MINI开发板系统固化全流程:从uboot编译到rootfs烧录(附网络配置技巧)
I.MX6U-MINI开发板系统固化实战指南:从零构建到网络调优 第一次拿到I.MX6U-MINI开发板时,面对系统固化的多个环节总有种无从下手的感觉。作为嵌入式Linux开发的入门门槛,系统固化不仅关系到后续应用开发的基础环境,更是理解嵌入式…...

MIKE URBAN中如何添加污水管水质
管网中的水质一直是管网模型中的一个难题,很多群友也要求小编更新水质方面的内容,一方面,其实水质相关的内容官方资料已经很多了, 觉得没必要重复更新。另一方面,管道水质率定实在太难以率定,很难算的准确。…...

k8s中部署prometheus并监控k8s集群以及nginx案例
4台主机 node1主机:k8s集群中的master node2主机:搭建了harbor仓库,存储所需的docker镜像 test3、4主机:k8s集群中的woker 搭建prometheus https://github.com/prometheus-operator/kube-prometheus 获取prometheus压缩包的…...

Excel 根据A列标签拆分为多个列数据
举例:如下图所示将AB列内容拆分为红色框内的格式方便绘制图表Sub SplitCategoriesToColumns()Dim ws As WorksheetDim lastRow As LongDim startRow As LongDim dict As ObjectDim keyOrder As New CollectionDim i As Long, j As LongDim key As VariantDim val As…...

实战派指南:用MaPLe思路优化你的CLIP下游任务,附关键配置与避坑建议
实战派指南:用MaPLe思路优化你的CLIP下游任务,附关键配置与避坑建议 当CLIP遇上业务场景,90%的开发者都会遇到相同的问题:模型在新类别上的表现总是不尽如人意。上周团队用默认参数跑跨模态检索任务时,基类准确率82%的…...
Qwen Pixel Art企业级应用:游戏公司美术外包降本提效实战路径
Qwen Pixel Art企业级应用:游戏公司美术外包降本提效实战路径 1. 游戏美术外包的痛点与机遇 游戏开发中,美术资源制作往往占据大量成本和时间。传统像素美术外包存在三个核心痛点: 成本高:资深像素画师日薪通常在800-1500元&am…...

OpenShamrock:零基础搭建QQ智能交互系统完全指南
OpenShamrock:零基础搭建QQ智能交互系统完全指南 【免费下载链接】OpenShamrock A Bot Framework based on Xposed with OneBot11 项目地址: https://gitcode.com/gh_mirrors/op/OpenShamrock 核心价值解析:为什么选择OpenShamrock构建QQ机器人&a…...

告别手动调参:Neural MHE如何让无人机在风扰中‘稳如老狗’
Neural MHE:无人机抗风扰控制的智能调参革命 四旋翼无人机在物流配送、农业喷洒、电力巡检等场景的应用日益广泛,但突发的风场扰动始终是飞控系统面临的严峻挑战。传统移动视界估计(MHE)虽能有效处理状态估计问题,却困在手动调参的泥潭中——…...