Python文本处理利器:jieba库全解析
文章目录
- Python文本处理利器:jieba库全解析
- 第一部分:背景和功能介绍
- 第二部分:库的概述
- 第三部分:安装方法
- 第四部分:常用库函数介绍
- 1. 精确模式分词
- 2. 全模式分词
- 3. 搜索引擎模式分词
- 4. 添加自定义词典
- 5. 关键词提取
- 第五部分:库的应用场景
- 场景一:文本分析
- 场景三:中文分词统计
- 第六部分:常见bug及解决方案
- Bug 1:UnicodeDecodeError
- Bug 2:ModuleNotFoundError
- Bug 3:AttributeError: 'str' object has no attribute 'decode'
- 第七部分:总结
Python文本处理利器:jieba库全解析

第一部分:背景和功能介绍
在文本处理和自然语言处理领域,分词是一个重要的任务。jieba是一个流行的Python中文分词类库,它提供了高效而灵活的中文分词功能,被广泛应用于文本挖掘、搜索引擎、信息检索等领域。
在使用jieba之前,我们需要先导入它的相关内容,以便后续介绍和演示。
import jieba
第二部分:库的概述
jieba库是一个基于前缀词典实现的中文分词工具。它支持三种分词模式:精确模式、全模式和搜索引擎模式。jieba还提供了添加自定义词典、关键词提取和词性标注等功能,使得中文文本处理更加便捷。
第三部分:安装方法
要安装jieba库,可以通过命令行使用pip来进行安装:
pip install jieba
第四部分:常用库函数介绍
1. 精确模式分词
text = "我爱自然语言处理"
seg_list = jieba.cut(text, cut_all=False)
print("精确模式分词结果:")
print("/ ".join(seg_list))
输出结果:
精确模式分词结果:
我/ 爱/ 自然语言/ 处理
2. 全模式分词
text = "我爱自然语言处理"
seg_list = jieba.cut(text, cut_all=True)
print("全模式分词结果:")
print("/ ".join(seg_list))
输出结果:
全模式分词结果:
我/ 爱/ 自然/ 自然语言/ 处理/ 语言/ 处理
3. 搜索引擎模式分词
text = "我爱自然语言处理"
seg_list = jieba.cut_for_search(text)
print("搜索引擎模式分词结果:")
print("/ ".join(seg_list))
输出结果:
搜索引擎模式分词结果:
我/ 爱/ 自然/ 语言/ 自然语言/ 处理
4. 添加自定义词典
jieba.add_word('自然语言处理')
text = "我爱自然语言处理"
seg_list = jieba.cut(text)
print("添加自定义词典后分词结果:")
print("/ ".join(seg_list))
输出结果:
添加自定义词典后分词结果:
我/ 爱/ 自然语言处理
5. 关键词提取
text = "自然语言处理是人工智能领域的重要研究方向"
keywords = jieba.analyse.extract_tags(text, topK=3)
print("关键词提取结果:")
print(keywords)
输出结果:
关键词提取结果:
['自然语言处理', '人工智能', '研究方向']
第五部分:库的应用场景
场景一:文本分析
text = "自然语言处理是人工智能领域的重要研究方向"
seg_list = jieba.cut(text)
print("分词结果:")
print("/ ".join(seg_list))keywords = jieba.analyse.extract_tags(text, topK=3)
print("关键词提取结果:")
print(keywords)
输出结果:
分词结果:
自然语言处理/ 是/ 人工智能/ 领域/ 的/ 重要/ 研究方向
关键词提取结果:
['自然语言处理', '人工智能', '研究方向']### 场景二:搜索引擎关键词匹配```python
query = "自然语言处理"
seg_list = jieba.cut_for_search(query)
print("搜索引擎模式分词结果:")
print("/ ".join(seg_list))
输出结果:
搜索引擎模式分词结果:
自然/ 语言/ 处理/ 自然语言/ 处理
场景三:中文分词统计
text = "自然语言处理是人工智能领域的重要研究方向,自然语言处理的应用非常广泛。"
seg_list = jieba.cut(text)
word_count = {}
for word in seg_list:if word not in word_count:word_count[word] = 1else:word_count[word] += 1print("分词统计结果:")
for word, count in word_count.items():print(f"{word}: {count} 次")
输出结果:
分词统计结果:
自然语言处理: 2 次
是: 1 次
人工智能: 1 次
领域: 1 次
的: 2 次
重要: 1 次
研究方向: 1 次
应用: 1 次
非常: 1 次
广泛: 1 次
第六部分:常见bug及解决方案
Bug 1:UnicodeDecodeError
错误信息:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xa3 in position 0: invalid start byte
解决方案:
在读取文本文件时,指定正确的编码方式,例如:
with open('text.txt', 'r', encoding='utf-8') as f:text = f.read()
Bug 2:ModuleNotFoundError
错误信息:
ModuleNotFoundError: No module named 'jieba'
解决方案:
确保jieba库已经正确安装,可以使用以下命令安装:
pip install jieba
Bug 3:AttributeError: ‘str’ object has no attribute ‘decode’
错误信息:
AttributeError: 'str' object has no attribute 'decode'
解决方案:
在Python 3.x 版本中,str对象没有decode方法。如果代码中使用了decode方法,需要去除该方法的调用。
第七部分:总结
通过本文,我们详细介绍了jieba库的背景、功能、安装方法,以及常用的库函数和应用场景。我们还解决了一些常见的bug,并给出了相应的解决方案。jieba库是一个强大而灵活的中文分词工具,为中文文本处理提供了便利,希望本文能帮助你更好地了解和使用jieba库。
相关文章:
Python文本处理利器:jieba库全解析
文章目录 Python文本处理利器:jieba库全解析第一部分:背景和功能介绍第二部分:库的概述第三部分:安装方法第四部分:常用库函数介绍1. 精确模式分词2. 全模式分词3. 搜索引擎模式分词4. 添加自定义词典5. 关键词提取 第…...

【C/C++】C语言如何实现类似C++的智能指针?
在C中,智能指针是为了自动化资源管理而引入的工具。比如std::unique_ptr和std::shared_ptr等,它们管理着所持有对象的生命周期,可以在智能指针被销毁时自动释放其所持有的资源。在C语言中,虽然没有直接的智能指针概念,…...
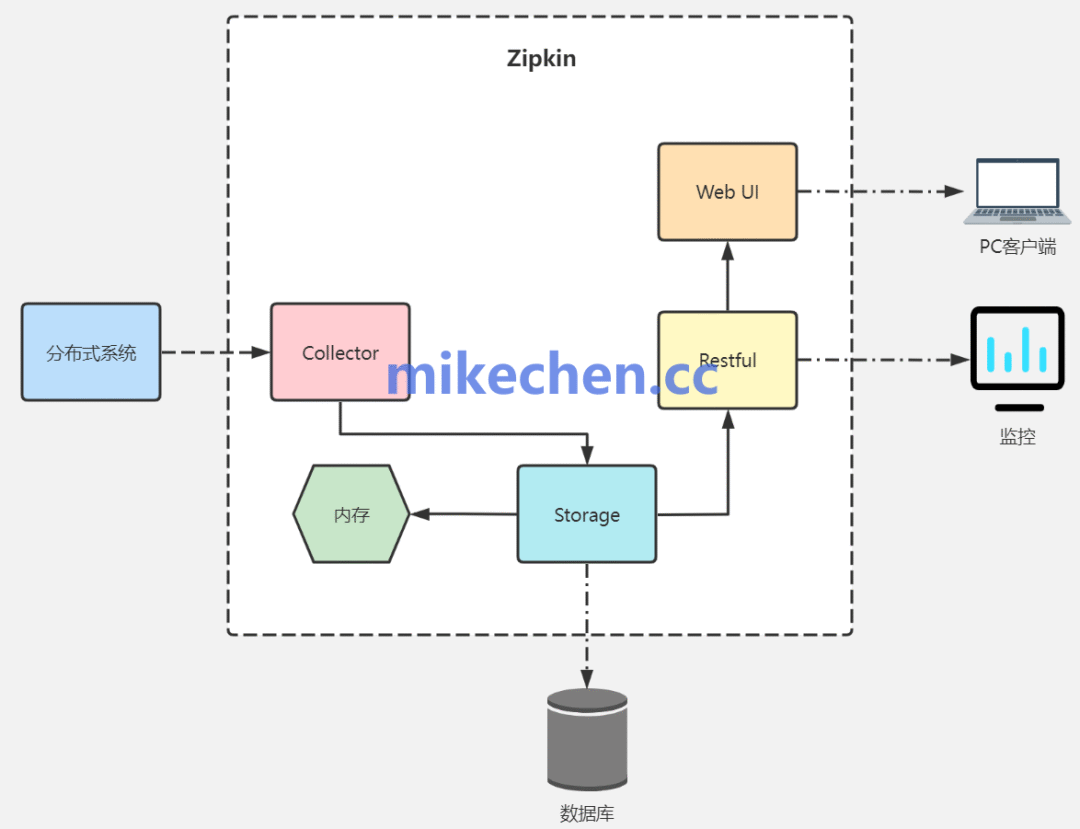
九大微服务监控工具详解
Prometheus Prometheus 是一个开源的系统监控、和报警工具包,Prometheus 被设计用来监控“微服务架构”。 主要解决: 监控和告警:Prometheus 可以对系统、和应用程序进行实时监控,并在出现问题时发送告警;数据收集和…...

java aliyun oss上传和下载工具类
java aliyun oss上传和下载工具类 依赖 <dependency><groupId>com.aliyun.oss</groupId><artifactId>aliyun-sdk-oss</artifactId><version>3.8.0</version></dependency>工具类 import com.alibaba.fastjson.JSON; import c…...

P7 品牌管理
逆向生成页面 新增菜单—商品系统的品牌管理 —product/brand 在代码生成器得到的文件中, main-resources-src-views-modules-product brand.vue、brand-add-or-update.vue放到category.vue同级vue文件有新增、删除按钮,但页面未显示,是因…...

C语言详解(动态内存管理)1
Hi~!这里是奋斗的小羊,很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~~ 💥💥个人主页:奋斗的小羊 💥💥所属专栏:C语言 🚀本系列文章为个人学习…...

106.网络游戏逆向分析与漏洞攻防-装备系统数据分析-在UI中显示装备与技能信息
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 如果看不懂、不知道现在做的什么,那就跟着做完看效果,代码看不懂是正常的,只要会抄就行,抄着抄着就能懂了 内容…...
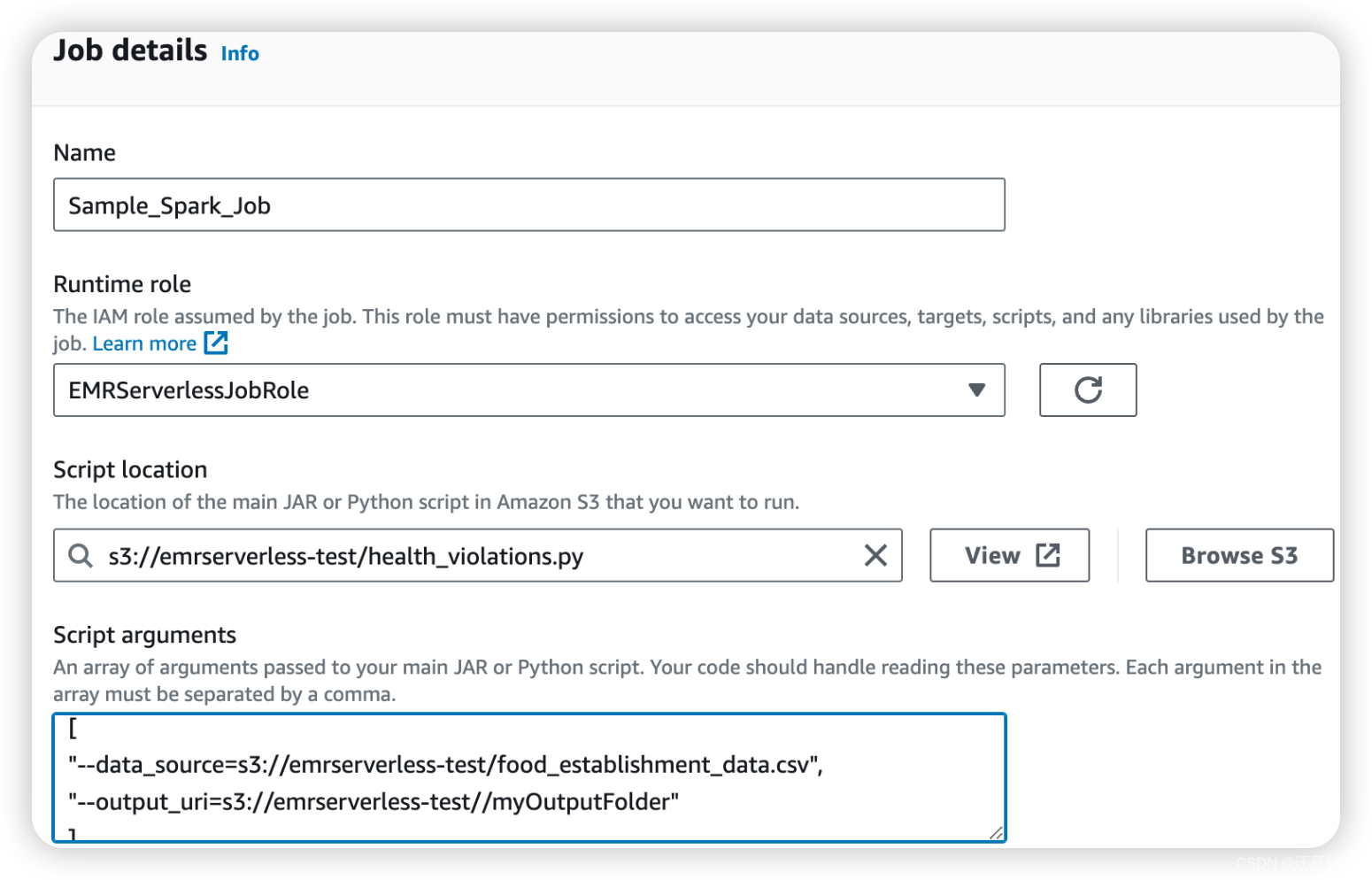
AWS EMR Serverless
AWS概述 EMR Serverless 简介 在AWS概述一文中简单介绍过AWS EMR, 它是AWS提供的云端大数据平台。借助EMR可以设置集群以便在几分钟内使用大数据框架处理和分析数据。创建集群可参考官方文档:Amazon EMR 入门。但集群创建之后需要一直运行,用户需要管理…...
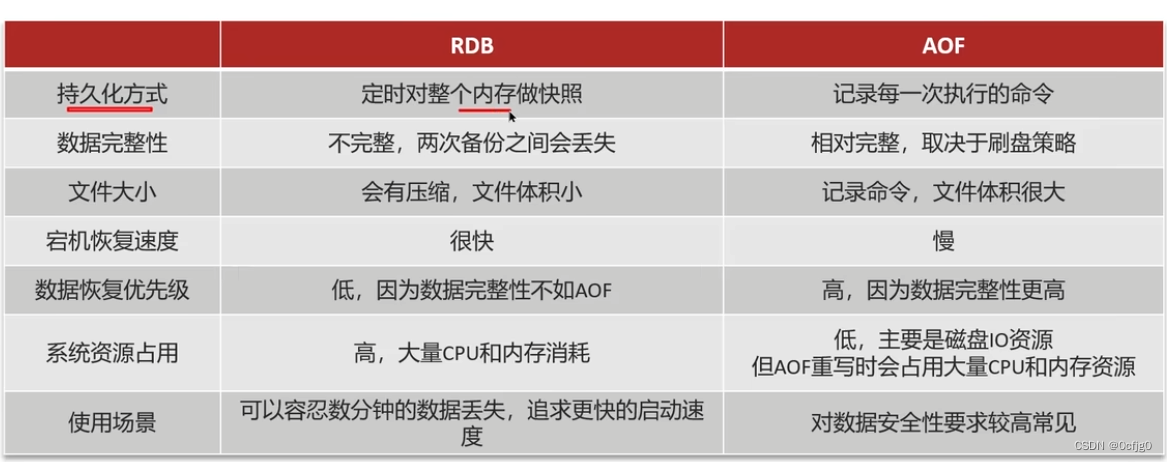
Java面试题:Redis持久化问题
Redis持久化问题 RDB (Redis Database Backup File) Redis数据快照 将内存中的所有数据都记录到磁盘中做快照 当Redis实例故障重启时,从磁盘读取快照文件恢复数据 使用 save/bgsave命令进行手动快照 save使用主进程执行RDB,对所有命令都进行阻塞 bgsave使用子进程执行R…...

【Java】解决Java报错:ClassCastException
文章目录 引言1. 错误详解2. 常见的出错场景2.1 错误的类型转换2.2 泛型集合中的类型转换2.3 自定义类和接口转换 3. 解决方案3.1 使用 instanceof 检查类型3.2 使用泛型3.3 避免不必要的类型转换 4. 预防措施4.1 使用泛型和注解4.2 编写防御性代码4.3 使用注解和检查工具 5. 示…...
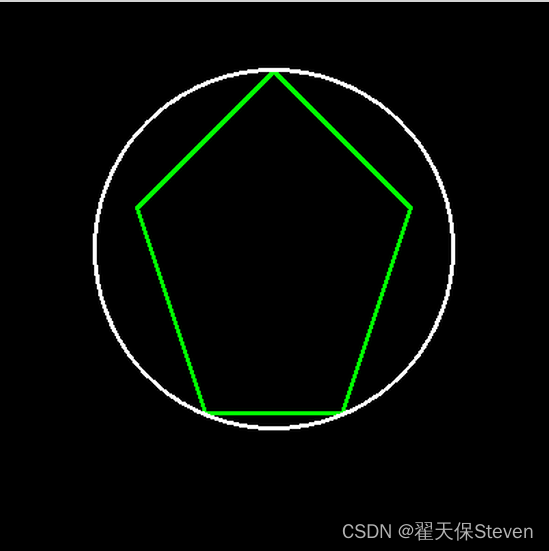
OpenCV-最小外接圆cv::minEnclosingCircle
作者:翟天保Steven 版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处 函数原型 void minEnclosingCircle(InputArray points, Point2f& center, float& radius); 参数说明 InputArray类型的…...
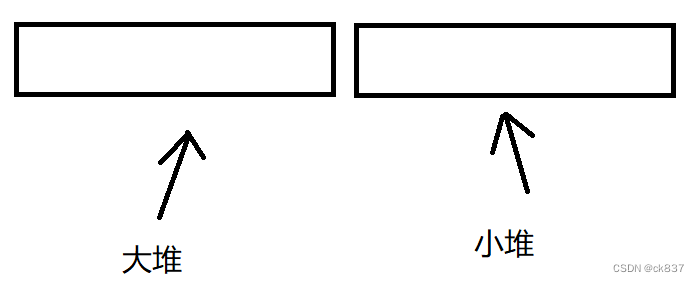
大小堆运用巧解数据流的中位数
一、思路 我们将所有数据平分成两份,前面那一部分用小堆来存,后面的部分用大堆来存,这样我们就能立刻拿到中间位置的值。 如果是奇数个数字,那么我们就将把中间值放在前面的大堆里,所以会有两种…...

AI能力边界不断扩展,将对国家安全产生深远影响
文 | 中国信息安全测评中心 王欣 随着 ChatGPT 的发布及相关应用的落地,人工智能技术给全球各个行业带来了一波又一波冲击。GPT-4 多模态大型语言模型更是将人工智能的能力提升到新的高度,无论从技术先进性还是应用实践能力来看,此模型均可被…...

【UnityShader入门精要学习笔记】第十六章 Unity中的渲染优化技术 (上)
本系列为作者学习UnityShader入门精要而作的笔记,内容将包括: 书本中句子照抄 个人批注项目源码一堆新手会犯的错误潜在的太监断更,有始无终 我的GitHub仓库 总之适用于同样开始学习Shader的同学们进行有取舍的参考。 文章目录 移动平台上…...

GPT-4o:免费且更快的模型
OpenAI GPT-4o 公告 OpenAI 推出了增强版 GPT-4 模型——OpenAI GPT-4o,用于支持 ChatGPT。首席技术官 Mira Murati 表示,更新后的模型速度更快,并在文本、视觉和音频处理方面有了显著提升。GPT-4o 将免费向所有用户开放,付费用户…...
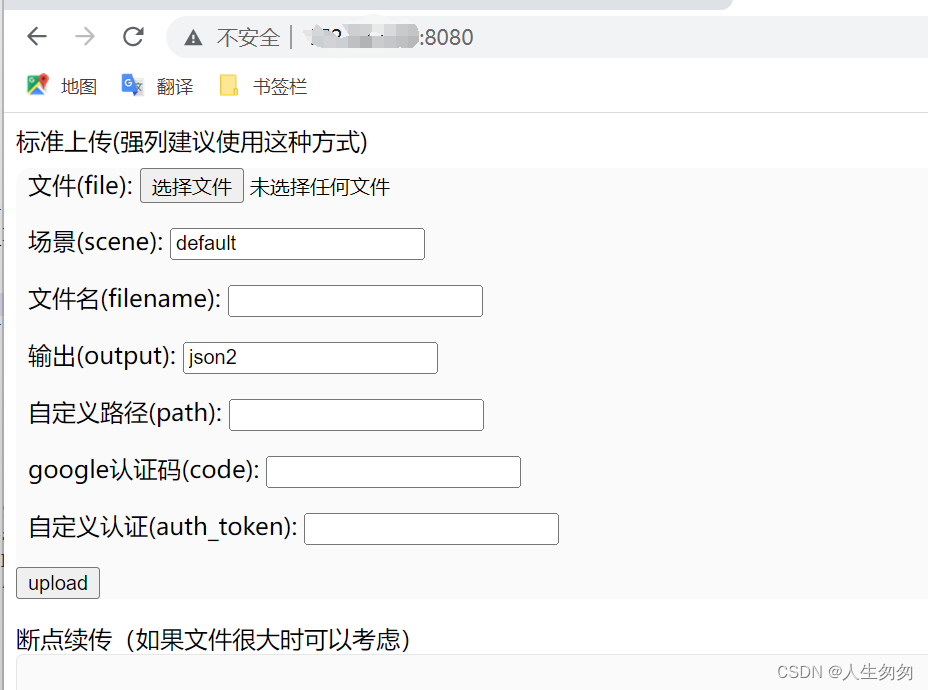
docker部署fastdfs
我的镜像包地址 链接:https://pan.baidu.com/s/1j5E5O1xdyQVfJhsOevXvYg?pwdhcav 提取码:hcav docker load -i gofast.tar.gz拉取gofast docker pull sjqzhang/go-fastdfs启动gofast docker run -d --name fastdfs -p 8080:8080 -v /opt/lijia/lijia…...

【劲舞团game】
编写《劲舞团》这样的游戏代码是一个复杂的过程,涉及到游戏引擎的使用、图形渲染、物理模拟、音频处理、网络通信等多个方面。以下是一个非常简化的步骤,用于说明如何开始编写一个基于Unity引擎的简单舞蹈游戏: 1. 准备开发环境 下载并安装…...

Day15—图像爬虫与简单处理
图像爬虫是一种专门用于从互联网上下载图像的网络爬虫。除了文本内容,图像也是网站中的重要组成部分,它们可以用于多种目的,如图像识别、内容分析、数据备份等。 环境准备 首先,确保你的环境中已安装Python和必要的库。如果没有安装Pillow库,可以通过以下命令安装:pip in…...
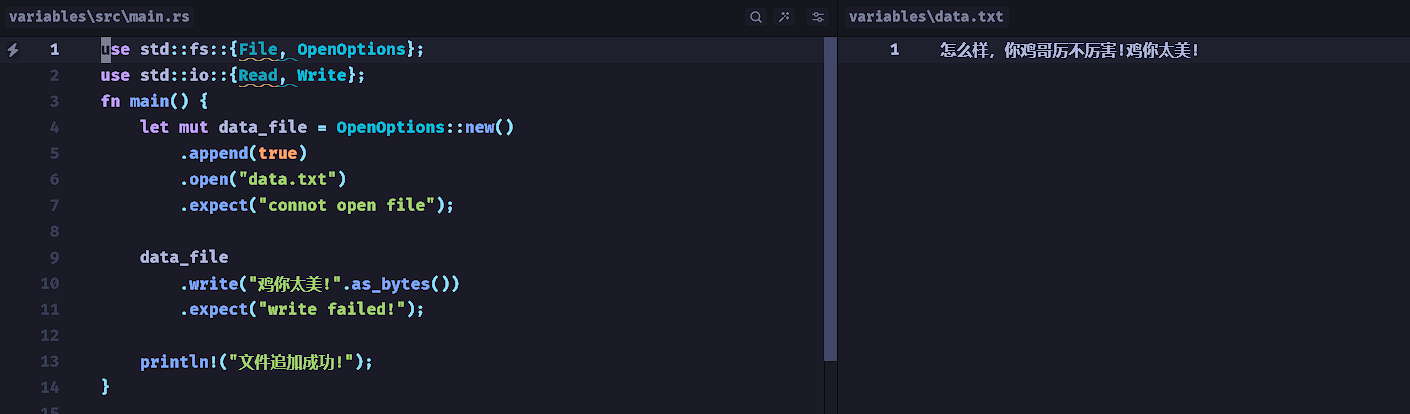
Rust基础学习-Rust中的文件操作
文件结构 在Rust中,std::fs::File 结构体代表一个文件。它允许我们对文件执行读/写操作。文件 I/O 是通过提供与文件系统交互的功能的 std::fs 模块执行的。 File 结构体中的所有方法都返回std::io::Result的变体,或者简单地是 Result 枚举。这里会涉及…...

Activator.CreateInstance 与 Type.InvokeMember的区别
文章目录 一、使用 Activator.CreateInstance 创建实例1、使用 Activator.CreateInstance 的优点和缺点2、使用 Activator.CreateInstance 的代码示例 二、使用 Type.InvokeMember 创建实例1、使用 Type.InvokeMember 的优点和缺点2、使用 Type.InvokeMember 的代码示例 三、Ac…...

别再只会复制代码了!用CubeMX配置STM32F407的PWM驱动TB6612,从原理到实战一次搞懂
从零构建PWM电机控制系统:STM32F407与TB6612的深度实践指南 引言:为什么你需要摆脱复制粘贴的陷阱 在实验室里,我见过太多学生面对电机控制项目时的第一反应——打开搜索引擎,寻找"STM32 PWM驱动电机代码",然…...

5步定制UEFI启动界面:技术爱好者的HackBGRT实战指南
5步定制UEFI启动界面:技术爱好者的HackBGRT实战指南 【免费下载链接】HackBGRT Windows boot logo changer for UEFI systems 项目地址: https://gitcode.com/gh_mirrors/ha/HackBGRT 一、问题发现:启动界面定制的3大痛点 在计算机使用体验中&am…...

终极指南:如何用Locale Emulator轻松解决Windows多语言软件兼容性问题
终极指南:如何用Locale Emulator轻松解决Windows多语言软件兼容性问题 【免费下载链接】Locale-Emulator Yet Another System Region and Language Simulator 项目地址: https://gitcode.com/gh_mirrors/lo/Locale-Emulator 你是否曾经因为日文游戏乱码而烦恼…...

突破百度网盘限速:Mac用户7分钟解锁SVIP级下载体验
突破百度网盘限速:Mac用户7分钟解锁SVIP级下载体验 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘非会员100KB/s的龟速下载…...

避开这些坑!算法工程师自学必备的5个高效学习法与工具推荐
避开这些坑!算法工程师自学必备的5个高效学习法与工具推荐 1. 为什么大多数自学算法工程师会失败? 在咖啡馆见到老张时,他正对着电脑屏幕上的LeetCode题目发呆。这位转行学习算法的前机械工程师已经坚持了8个月,但最近一次面试还是…...

终极指南:5分钟上手BepInEx,打造你的Unity游戏插件帝国 [特殊字符]
终极指南:5分钟上手BepInEx,打造你的Unity游戏插件帝国 🚀 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx是一款专为Unity游戏设计的强…...

Windows/Linux双平台实战:用Docker快速部署MySQL 5.7.36并导入数据
跨平台Docker实战:MySQL 5.7.36高效部署与数据迁移指南 在混合开发环境中,数据库的快速部署与迁移往往是影响团队协作效率的关键因素。想象一下这样的场景:一位开发者刚在Windows笔记本上完成本地测试,需要将包含复杂表结构的MySQ…...

网盘直链解析技术指南:突破下载限制的高效解决方案
网盘直链解析技术指南:突破下载限制的高效解决方案 【免费下载链接】Online-disk-direct-link-download-assistant 可以获取网盘文件真实下载地址。基于【网盘直链下载助手】修改(改自6.1.4版本) ,自用,去推广…...

MusePublic显存利用率提升方案:CPU卸载+自动清理策略详解
MusePublic显存利用率提升方案:CPU卸载自动清理策略详解 1. 项目背景与显存挑战 MusePublic是一款专为艺术感时尚人像创作设计的轻量化文本生成图像系统。基于专属大模型和safetensors格式封装,系统针对艺术人像的优雅姿态、细腻光影和故事感画面进行了…...

fre:ac音频转换全攻略:跨平台高效工作流搭建指南
fre:ac音频转换全攻略:跨平台高效工作流搭建指南 【免费下载链接】freac The fre:ac audio converter project 项目地址: https://gitcode.com/gh_mirrors/fr/freac 在数字音频处理领域,开源工具的选择往往决定了工作流的效率与质量。fre:ac作为一…...