OpenAI发布GPT-4思维破解新策略,Ilya亦有贡献!
OpenAI正在研究如何破解GPT-4的思维,并公开了超级对齐团队的工作,Ilya Sutskever也在作者名单中。
论文地址:https://cdn.openai.com/papers/sparse-autoencoders.pdf
代码:https://github.com/openai/sparse_autoencoder
特征可视化:https://openaipublic.blob.core.windows.net/sparse-autoencoder/sae-viewer/index.html
GPT-4o是否具备记忆能力?DeepMind和开源社区解开LLM记忆的谜团 !_
GPT-4o深夜发布!Plus免费可用!![]() https://www.zhihu.com/pin/1773645611381747712
https://www.zhihu.com/pin/1773645611381747712
没体验过OpenAI最新版GPT-4o?快戳最详细升级教程,几分钟搞定:
升级ChatGPT-4o Turbo步骤![]() https://www.zhihu.com/pin/1768399982598909952
https://www.zhihu.com/pin/1768399982598909952
该研究提出了一种改进大规模训练稀疏自编码器的方法,并成功将GPT-4的内部表征解构为1600万个可理解的特征。
这使得复杂语言模型的内部工作变得更加透明。
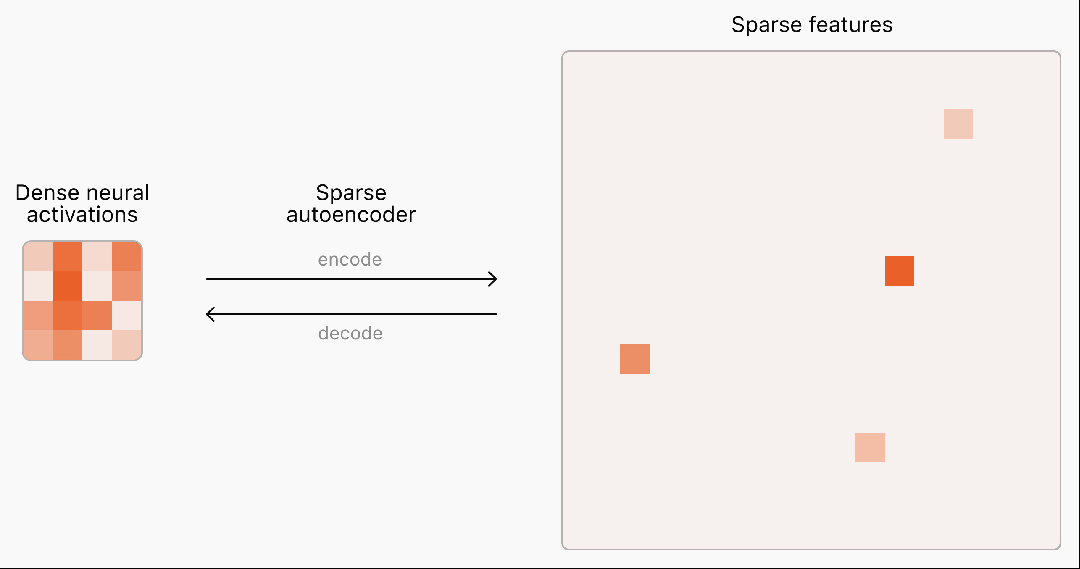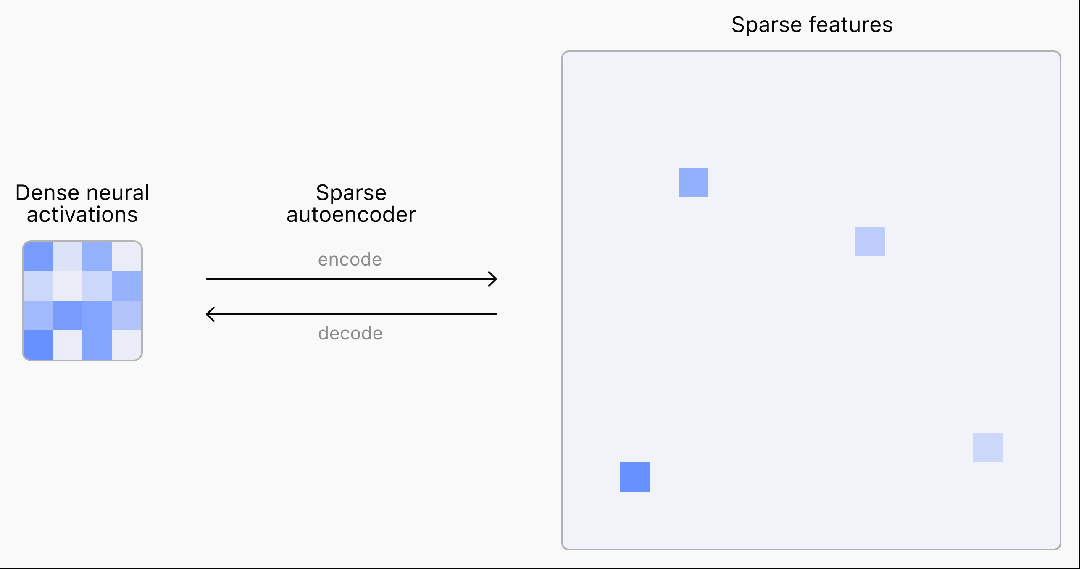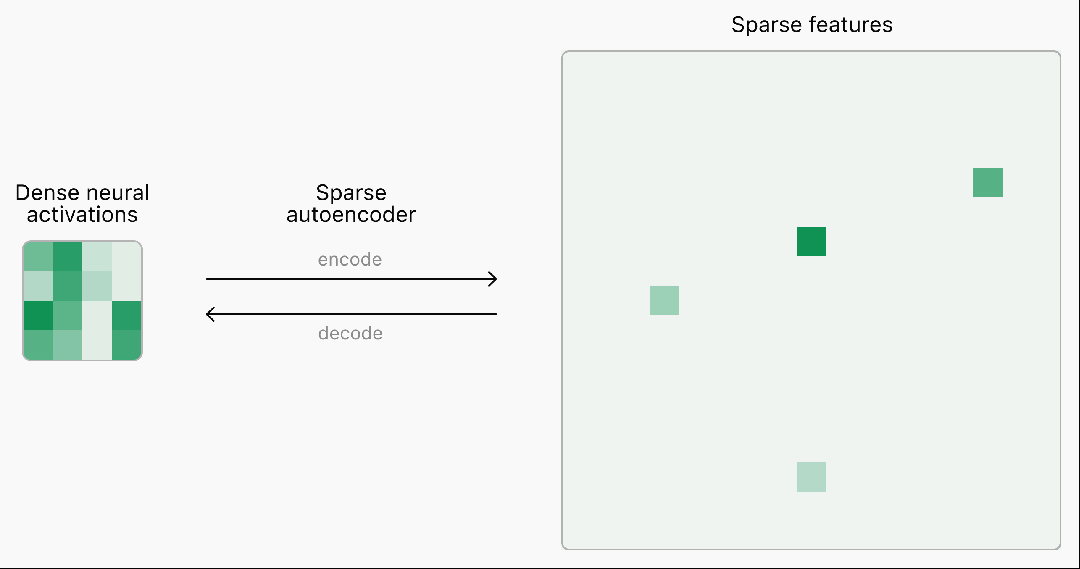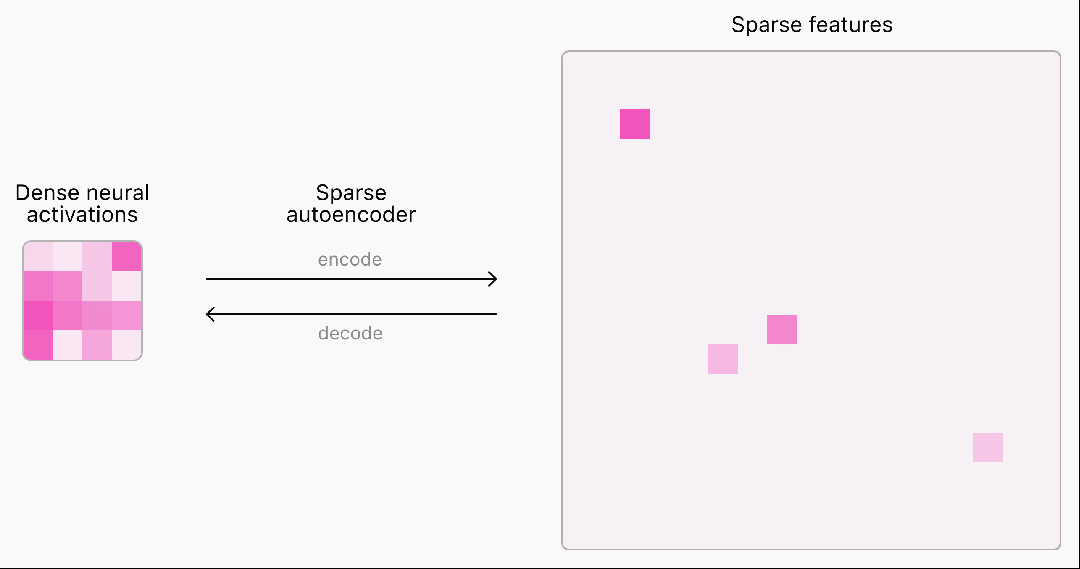
目前,语言模型神经网络的内部工作原理仍是一个“黑盒”,无法完全理解。
为了理解和解释神经网络,首先需要找到对神经计算有用的基本构件。
然而,神经网络中的激活通常表现出不可预测和复杂的模式,每次输入几乎总会引发密集的激活。
而现实世界中其实很稀疏,在任何给定的情境中,人脑只有一小部分相关神经元会被激活。
在OpenAI超级对齐团队的这项研究中,他们推出了一种基于TopK激活函数的新稀疏自编码器(SAE)训练技术栈,消除了特征缩小问题,能够直接设定L0(直接控制网络中非零激活的数量)。
该方法在均方误差(MSE)与L0评估指标上表现优异,即使在1600万规模的训练中,几乎不产生失活的潜在单元(latent)。
具体来说,他们使用GPT-2 small和GPT-4系列模型的残差流作为自编码器的输入,选取网络深层(接近输出层)的残差流,如GPT-4的5/6层、GPT-2 small的第8层。
并使用之前工作中提出的基线ReLU自编码器架构,编码器通过ReLU激活获得稀疏latent z,解码器从z中重建残差流。
损失函数包括重建MSE损失和L1正则项,用于促进latent稀疏性。
此外,自编码器训练时容易出现大量latent永远不被激活(失活)的情况,导致计算资源浪费。
团队的解决方案包括两个关键技术:
1. 将编码器权重初始化为解码器权重的转置,使latent在初始化时可激活。
2. 添加辅助重建损失项,模拟用top-kaux个失活latent进行重建的损失。
通过这些方法,即使是1600万latent的大规模自编码器,失活率也只有7%。
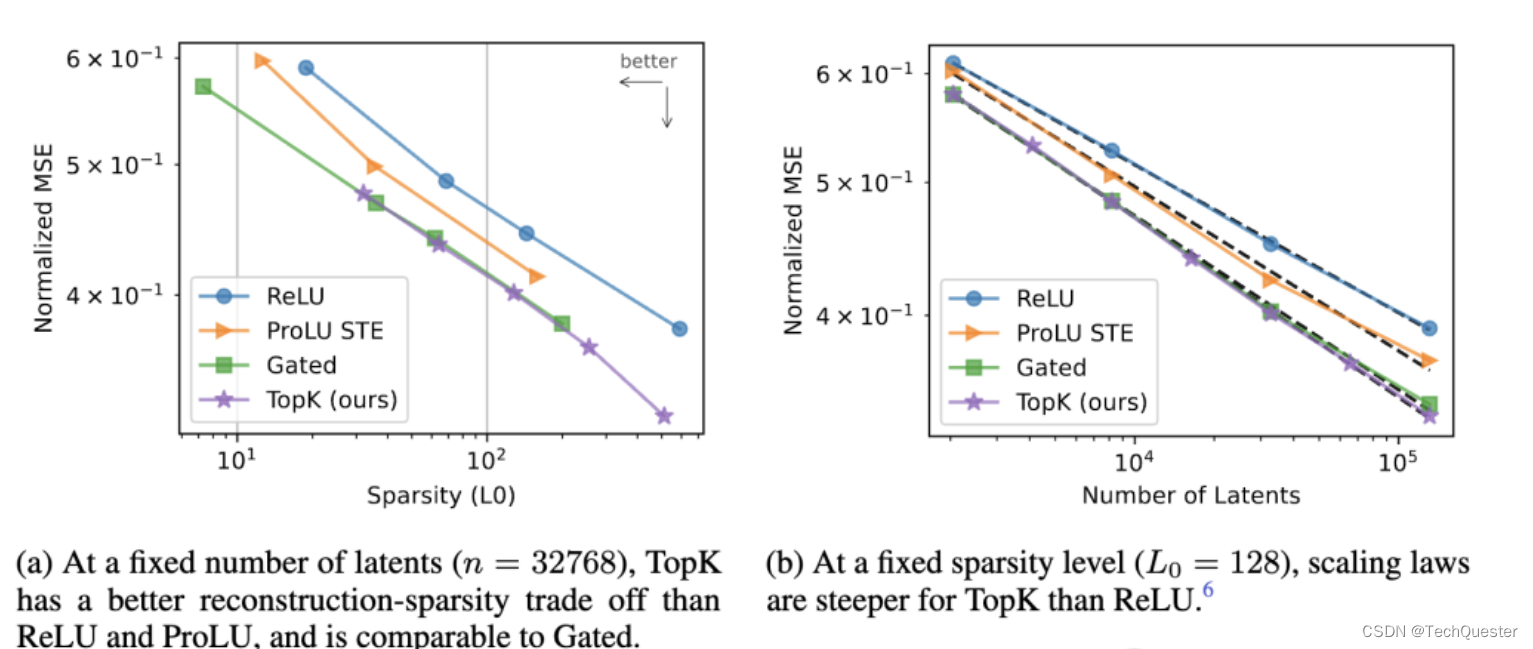
团队还提出了多重TopK损失函数的改进方案,提高了高稀疏情况下的泛化能力,并且探讨了两种不同的训练策略对latent数量的影响,这里就不过多展开了。
推荐阅读:
GPT-4o是否具备记忆能力?DeepMind和开源社区解开LLM记忆的谜团 !
如何免费使用GPT-4o?如何升级GPT...
更强大Mamba-2正式发布啦!!!
黎曼猜想取得重大进展!!
相关文章:
OpenAI发布GPT-4思维破解新策略,Ilya亦有贡献!
OpenAI正在研究如何破解GPT-4的思维,并公开了超级对齐团队的工作,Ilya Sutskever也在作者名单中。 论文地址:https://cdn.openai.com/papers/sparse-autoencoders.pdf 代码:https://github.com/openai/sparse_autoencoder 特征可…...
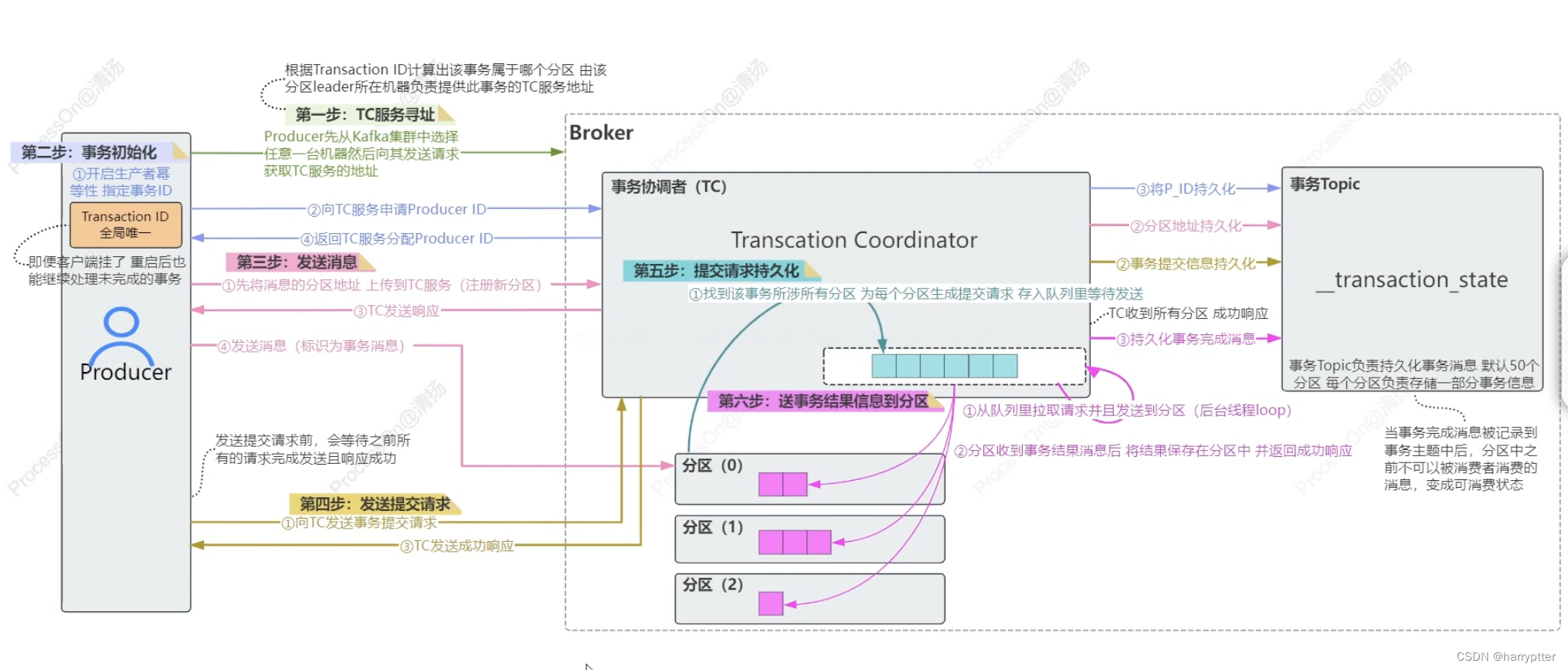
[消息队列 Kafka] Kafka 架构组件及其特性(二)Producer原理
这边整理下Kafka三大主要组件Producer原理。 目录 一、Producer发送消息源码流程 二、ACK应答机制和ISR机制 1)ACK应答机制 2)ISR机制 三、消息的幂等性 四、Kafka生产者事务 一、Producer发送消息源码流程 Producer发送消息流程如上图。主要是用…...

faiss ivfpq索引构建
假设已有训练好的向量值,构建索引(nlist和随机样本按需选取) import numpy as np import faiss import pickle from tqdm import tqdm import time import os import random# 读取嵌入向量并保留对应关系 def read_embeddings(directory, ba…...

ffmpeg视频编码原理和实战-(2)视频帧的创建和编码packet压缩
源文件: #include <iostream> using namespace std; extern "C" { //指定函数是c语言函数,函数名不包含重载标注 //引用ffmpeg头文件 #include <libavcodec/avcodec.h> } //预处理指令导入库 #pragma comment(lib,"avcodec.…...

数据结构:线索二叉树
目录 1.线索二叉树是什么? 2.包含头文件 3.结点设计 4.接口函数定义 5.接口函数实现 线索二叉树是什么? 线索二叉树(Threaded Binary Tree)是一种对普通二叉树的扩展,它通过在树的某些空指针上添加线索来实现更高效的遍…...
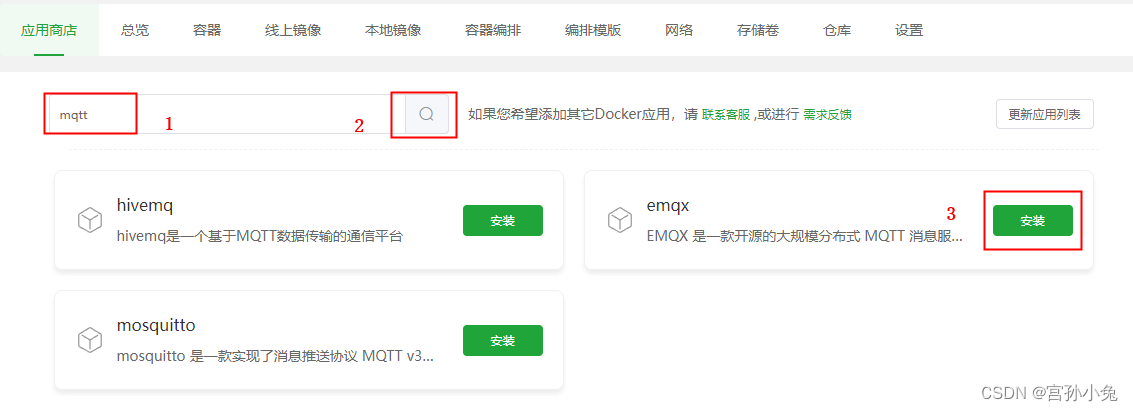
宝塔Linux面板-Docker管理(2024详解)
上一篇文章《宝塔Linux可视化运维面板-详细教程2024》,详细介绍了宝塔Linux面板的详细安装和配置方法。本文详细介绍使用Linux面板管理服务器Docker环境。 目录 1、安装Docker 1.1 在线安装 编辑 1.2 手动安装 1.3 运行状态 1.4 镜像加速 2 应用商店 3 总览 4 容器 …...

【Linux】进程(8):Linux真正是如何调度的
大家好,我是苏貝,本篇博客带大家了解Linux进程(8):Linux真正是如何调度的,如果你觉得我写的还不错的话,可以给我一个赞👍吗,感谢❤️ 目录 之前我们讲过,在大…...

R语言探索与分析14-美国房价及其影响因素分析
一、选题背景 以多元线性回归统计模型为基础,用R语言对美国部分地区房价数据进行建模预测,进而探究提高多元回 归线性模型精度的方法。先对数据进行探索性预处理,随后设置虚拟变量并建模得出预测结果,再使用方差膨胀因子对 多重共…...

golang websocket 数据处理和返回JSON数据示例
golang中websocket数据处理和返回json数据示例, 直接上代码: // author tekintiangmail.com // golang websocket 数据处理和返回JSON数据示例, // 这个函数返回 http.HandlerFunc // 将http请求升级为websocket请求 这个需要依赖第三方包 …...

【Mac】Downie 4 for Mac(视频download工具)兼容14系统软件介绍及安装教程
前言 Downie 每周都会更新一个版本适配视频网站,如果遇到视频download不了的情况,请搜索最新版本https://mac.shuiche.cc/search/downie。 注意:Downie Mac特别版不能升级,在设置中找到更新一列,把自动更新和自动downl…...
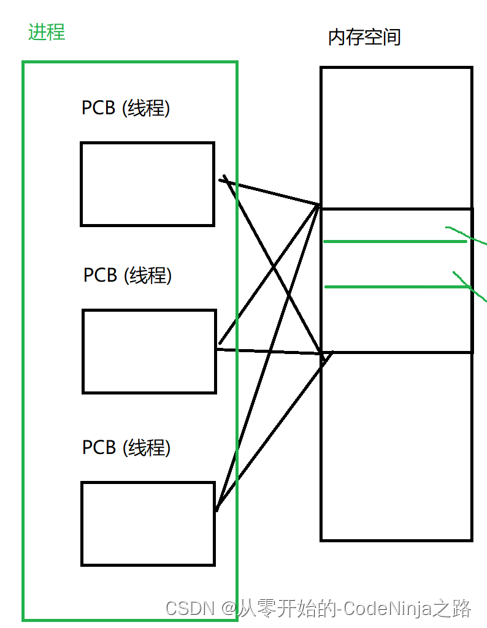
【操作系统】进程与线程的区别及总结(非常非常重要,面试必考题,其它文章可以不看,但这篇文章最后的总结你必须要看,满满的全是干货......)
目录 一、 进程1.1 PID(进程标识符)1.2 内存指针1.3 文件描述符表1.4 状态1.5 优先级1.6 记账信息1.7 上下文 二、线程三、总结:进程和线程之间的区别(非常非常非常重要,面试必考题) 一、 进程 简单来介绍一下什么是进程…...

自动驾驶仿真(高速道路)LaneKeeping
前言 A high-level decision agent trained by deep reinforcement learning (DRL) performs quantitative interpretation of behavioral planning performed in an autonomous driving (AD) highway simulation. The framework relies on the calculation of SHAP values an…...

数据挖掘实战-基于Catboost算法的艾滋病数据可视化与建模分析
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

分水岭算法分割和霍夫变换识别图像中的硬币
首先解释一下第一种分水岭算法: 一、分水岭算法 分水岭算法是一种基于拓扑学的图像分割技术,广泛应用于图像处理和计算机视觉领域。它将图像视为一个拓扑表面,其中亮度值代表高度。算法的目标是通过模拟雨水从山顶流到山谷的过程࿰…...

什么是AVIEXP提前发货通知?
EDI(电子数据交换)报文是一种用于电子商务和供应链管理的标准化信息传输格式。AVIEXP 是一种特定类型的 EDI 报文,用于传输提前发货通知信息。 AVIEXP 报文简介 AVIEXP 是指 Advanced Shipping Notification提前发货通知报文,用…...
Python 之SQLAlchemy使用详细说明
目录 1、SQLAlchemy 1.1、ORM概述 1.2、SQLAlchemy概述 1.3、SQLAlchemy的组成部分 1.4、SQLAlchemy的使用 1.4.1、安装 1.4.2、创建数据库连接 1.4.3、执行原生SQL语句 1.4.4、映射已存在的表 1.4.5、创建表 1.4.5.1、创建表的两种方式 1、使用 Table 类直接创建表…...
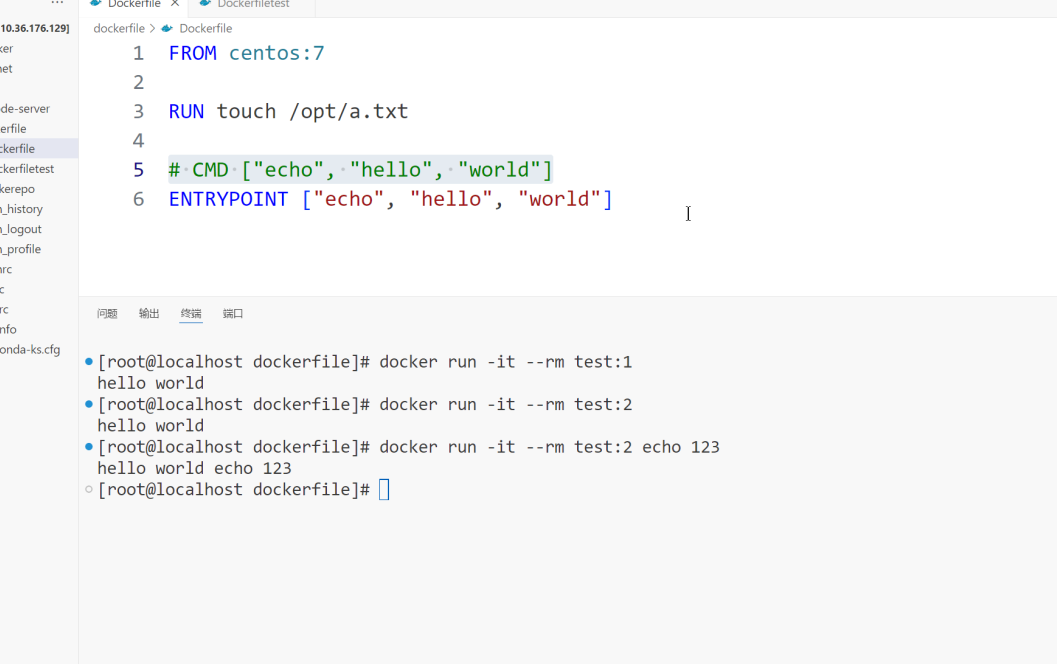
就业班 第四阶段(docker) 2401--5.29 day3 Dockerfile+前后段项目若依ruoyi
通过Dockerfile创建镜像 Docker 提供了一种更便捷的方式,叫作 Dockerfile docker build命令用于根据给定的Dockerfile构建Docker镜像。docker build语法: # docker build [OPTIONS] <PATH | URL | ->1. 常用选项说明 --build-arg,设…...

【运维项目经历|026】Redis智能集群构建与性能优化工程
🍁博主简介: 🏅云计算领域优质创作者 🏅2022年CSDN新星计划python赛道第一名 🏅2022年CSDN原力计划优质作者 🏅阿里云ACE认证高级工程师 🏅阿里云开发者社区专家博主 💊交流社区:CSDN云计算交流社区欢迎您的加入! 目…...

Linux编程for、while循环if判断以及case语句用法
简介 语法描述if条件语句if else条件判断语句if else-if else多条件判断语句for循环执行命令while循环执行命令until直到条件为真时停止循环case ... esac多选择语句break跳出循环continue跳出当前循环 1. for 循环 for语句,定量循环,可以遍历一个列表…...

docker命令 docker ps -l (latest)命令在 Docker 中用于列出最近一次创建的容器
文章目录 12345 1 docker ps -l 命令在 Docker 中用于列出最近一次创建的容器。具体来说: docker ps:这个命令用于列出当前正在运行的容器。-l 或 --latest:这个选项告诉 docker ps 命令只显示最近一次创建的容器,不论该容器当前…...

pkNX:定制宝可梦游戏体验的全能编辑工具指南
pkNX:定制宝可梦游戏体验的全能编辑工具指南 【免费下载链接】pkNX Pokmon (Nintendo Switch) ROM Editor & Randomizer 项目地址: https://gitcode.com/gh_mirrors/pk/pkNX 你是否曾想过在宝可梦游戏中拥有独一无二的精灵阵容?是否希望调整训…...
)
Python新手必看:PyCharm 2021.2.3社区版安装与配置全攻略(附环境变量检查)
Python开发环境搭建指南:PyCharm社区版安装与高效配置实战 如果你正准备踏入Python编程的世界,选择一款趁手的开发工具至关重要。JetBrains推出的PyCharm社区版凭借其智能代码补全、强大调试功能和丰富的插件生态,成为众多Python初学者的首选…...

深入解析74181芯片中Cn+1的进位逻辑与实现原理
1. 74181芯片与Cn1进位的基础认知 第一次接触74181这块经典ALU芯片时,我被它内部精巧的进位逻辑设计震撼到了。这块诞生于上世纪60年代的4位算术逻辑单元,至今仍是理解计算机运算基础的绝佳教学案例。其中最精妙的部分莫过于Cn1进位信号的生成机制——它…...

嵌入式开源项目解析与复刻实践指南
1. 嵌入式软件开源项目深度解析与复刻指南1.1 项目概述在嵌入式开发领域,工程化代码设计能力是区分初级与高级工程师的关键指标。本文精选五个经过实际验证的开源项目,从架构设计到实现细节进行深度剖析,为嵌入式开发者提供可复用的设计模式和…...

奇偶判断算法的极端实现与优化
1. 奇偶判断算法的极端实现:从40亿条if语句到机器码优化1.1 项目背景与设计动机在计算机科学领域,判断数字奇偶性通常采用取模运算这一经典方法。然而,一个看似荒谬的想法引发了技术人员的深入思考:是否可以通过穷举所有可能的数字…...

别再手动调参了!用Matlab+NRBO-BP+NSGAII搞定工艺优化,自动生成最优参数组合Excel
工艺优化新范式:基于NRBO-BP与NSGAII的智能参数寻优系统 在化工、材料、制造等领域的工艺优化过程中,工程师和研究人员常常面临一个共同的挑战:如何在有限的实验资源和时间约束下,从海量的参数组合中找到最优解。传统的手动调参方…...

智能日程管理系统:OpenClaw+Qwen3-32B自动安排会议时间
智能日程管理系统:OpenClawQwen3-32B自动安排会议时间 1. 为什么需要自动化日程管理 每天早晨打开邮箱,总能看到十几封会议邀请混杂在各类邮件中。手动核对时间、检查日历冲突、协调参会人可用性——这些重复性工作消耗了我至少30%的工作时间。直到上个…...

LeetCode知识点总结 - 524
LeetCode 524. Longest Word in Dictionary through Deleting考点难度ArrayMedium题目 Given a string s and a string array dictionary, return the longest string in the dictionary that can be formed by deleting some of the given string characters. If there is mor…...
)
DanKoe 视频笔记:一人企业构建指南:从零到百万美元的教育业务(每日工作2-4小时)
在本课程中,我们将学习如何构建一个单人教育业务,实现从零到年收入百万美元的目标,同时将每日工作时间控制在2-4小时。我们将探讨其核心理念、实施步骤以及背后的进化逻辑。 概述 传统的创业路径往往伴随着高风险、高投入和漫长的工作时间。…...

FDS火灾动力学模拟器完整指南:从入门到精通建筑消防安全分析
FDS火灾动力学模拟器完整指南:从入门到精通建筑消防安全分析 【免费下载链接】fds Fire Dynamics Simulator 项目地址: https://gitcode.com/gh_mirrors/fd/fds 想要准确预测火灾中的烟雾扩散路径?需要科学评估建筑物的人员疏散时间?F…...