数据库练习题
1行程和用户
表:Trips
+-------------+----------+ | Column Name | Type | +-------------+----------+ | id | int | | client_id | int | | driver_id | int | | city_id | int | | status | enum | | request_at | date | +-------------+----------+ id 是这张表的主键(具有唯一值的列)。 这张表中存所有出租车的行程信息。每段行程有唯一 id ,其中 client_id 和 driver_id 是 Users 表中 users_id 的外键。 status 是一个表示行程状态的枚举类型,枚举成员为(‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’) 。
表:Users
+-------------+----------+ | Column Name | Type | +-------------+----------+ | users_id | int | | banned | enum | | role | enum | +-------------+----------+ users_id 是这张表的主键(具有唯一值的列)。 这张表中存所有用户,每个用户都有一个唯一的 users_id ,role 是一个表示用户身份的枚举类型,枚举成员为 (‘client’, ‘driver’, ‘partner’) 。 banned 是一个表示用户是否被禁止的枚举类型,枚举成员为 (‘Yes’, ‘No’) 。
取消率 的计算方式如下:(被司机或乘客取消的非禁止用户生成的订单数量) / (非禁止用户生成的订单总数)。
编写解决方案找出 "2013-10-01" 至 "2013-10-03" 期间非禁止用户(乘客和司机都必须未被禁止)的取消率。非禁止用户即 banned 为 No 的用户,禁止用户即 banned 为 Yes 的用户。其中取消率 Cancellation Rate 需要四舍五入保留 两位小数 。
返回结果表中的数据 无顺序要求 。
结果格式如下例所示。
示例 1:
输入: Trips 表: +----+-----------+-----------+---------+---------------------+------------+ | id | client_id | driver_id | city_id | status | request_at | +----+-----------+-----------+---------+---------------------+------------+ | 1 | 1 | 10 | 1 | completed | 2013-10-01 | | 2 | 2 | 11 | 1 | cancelled_by_driver | 2013-10-01 | | 3 | 3 | 12 | 6 | completed | 2013-10-01 | | 4 | 4 | 13 | 6 | cancelled_by_client | 2013-10-01 | | 5 | 1 | 10 | 1 | completed | 2013-10-02 | | 6 | 2 | 11 | 6 | completed | 2013-10-02 | | 7 | 3 | 12 | 6 | completed | 2013-10-02 | | 8 | 2 | 12 | 12 | completed | 2013-10-03 | | 9 | 3 | 10 | 12 | completed | 2013-10-03 | | 10 | 4 | 13 | 12 | cancelled_by_driver | 2013-10-03 | +----+-----------+-----------+---------+---------------------+------------+ Users 表: +----------+--------+--------+ | users_id | banned | role | +----------+--------+--------+ | 1 | No | client | | 2 | Yes | client | | 3 | No | client | | 4 | No | client | | 10 | No | driver | | 11 | No | driver | | 12 | No | driver | | 13 | No | driver | +----------+--------+--------+ 输出: +------------+-------------------+ | Day | Cancellation Rate | +------------+-------------------+ | 2013-10-01 | 0.33 | | 2013-10-02 | 0.00 | | 2013-10-03 | 0.50 | +------------+-------------------+ 解释: 2013-10-01:- 共有 4 条请求,其中 2 条取消。- 然而,id=2 的请求是由禁止用户(user_id=2)发出的,所以计算时应当忽略它。- 因此,总共有 3 条非禁止请求参与计算,其中 1 条取消。- 取消率为 (1 / 3) = 0.33 2013-10-02:- 共有 3 条请求,其中 0 条取消。- 然而,id=6 的请求是由禁止用户发出的,所以计算时应当忽略它。- 因此,总共有 2 条非禁止请求参与计算,其中 0 条取消。- 取消率为 (0 / 2) = 0.00 2013-10-03:- 共有 3 条请求,其中 1 条取消。- 然而,id=8 的请求是由禁止用户发出的,所以计算时应当忽略它。- 因此,总共有 2 条非禁止请求参与计算,其中 1 条取消。- 取消率为 (1 / 2) = 0.50
思路:
- 从 Trips 表中选择请求日期(request_at)和取消率(Cancellation Rate)字段。
- 在查询条件中限定请求日期在2013年10月1日至10月3日之间。
- 使用子查询来排除在 Users 表中被封禁(banned=‘Yes’)的客户和司机。
- 使用条件表达式(IF 函数)来检查每次旅程的状态是否为“completed”,如果不是,则计算取消率。
- 最后按请求日期分组,以得出每天的取消率。
代码:
select request_at 'Day', -- 选择请求日期作为“Day”
round(count(if(status!='completed',status,null))/count(*),2) 'Cancellation Rate' -- 计算取消率
from Trips
where request_at between '2013-10-01' and '2013-10-03' -- 筛选请求日期在2013年10月1日至10月3日期间的记录
and client_id not in (select users_id from Users where banned='Yes') -- 排除被封禁用户作为客户
and driver_id not in (select users_id from Users where banned='Yes') -- 排除被封禁用户作为司机
group by request_at; -- 按请求日期分组2体育馆的人流量
表:Stadium
+---------------+---------+ | Column Name | Type | +---------------+---------+ | id | int | | visit_date | date | | people | int | +---------------+---------+ visit_date 是该表中具有唯一值的列。 每日人流量信息被记录在这三列信息中:序号 (id)、日期 (visit_date)、 人流量 (people) 每天只有一行记录,日期随着 id 的增加而增加
编写解决方案找出每行的人数大于或等于 100 且 id 连续的三行或更多行记录。
返回按 visit_date 升序排列 的结果表。
查询结果格式如下所示。
示例 1:
输入:
Stadium 表:
+------+------------+-----------+
| id | visit_date | people |
+------+------------+-----------+
| 1 | 2017-01-01 | 10 |
| 2 | 2017-01-02 | 109 |
| 3 | 2017-01-03 | 150 |
| 4 | 2017-01-04 | 99 |
| 5 | 2017-01-05 | 145 |
| 6 | 2017-01-06 | 1455 |
| 7 | 2017-01-07 | 199 |
| 8 | 2017-01-09 | 188 |
+------+------------+-----------+
输出:
+------+------------+-----------+
| id | visit_date | people |
+------+------------+-----------+
| 5 | 2017-01-05 | 145 |
| 6 | 2017-01-06 | 1455 |
| 7 | 2017-01-07 | 199 |
| 8 | 2017-01-09 | 188 |
+------+------------+-----------+
解释:
id 为 5、6、7、8 的四行 id 连续,并且每行都有 >= 100 的人数记录。
请注意,即使第 7 行和第 8 行的 visit_date 不是连续的,输出也应当包含第 8 行,因为我们只需要考虑 id 连续的记录。
不输出 id 为 2 和 3 的行,因为至少需要三条 id 连续的记录。思路:
- 从 stadium 表中使用 t1、t2、t3 三个表别名分别代表三个场馆。
- 在 WHERE 子句中,筛选出人数大于等于100的场馆记录。
- 使用嵌套的 OR 逻辑运算符来确定 t1、t2、t3 三个场馆的 id 之间的关系:
- t1, t2, t3 的 id 分别相差1和2;
- t2, t1, t3 的 id 分别相差1和2;
- t3, t2, t1 的 id 分别相差1和2。
- 使用 distinct 关键字去重,确保结果集中没有重复的记录。
- 最后按 t1 表中的 id 字段进行升序排序,以便更清晰地展示满足条件的场馆记录。
代码:
select distinct t1.* -- 选择所有 t1 表中的字段
from stadium t1, stadium t2, stadium t3 -- 从 stadium 表中分别使用 t1、t2、t3 三个表别名
where t1.people >= 100 and t2.people >= 100 and t3.people >= 100 -- 筛选满足人数大于等于100的记录
and
((t1.id - t2.id = 1 and t1.id - t3.id = 2 and t2.id - t3.id = 1) -- t1, t2, t3 的 id 差距均为1或2or(t2.id - t1.id = 1 and t2.id - t3.id = 2 and t1.id - t3.id = 1) -- t2, t1, t3 的 id 差距均为1或2or(t3.id - t2.id = 1 and t2.id - t1.id = 1 and t3.id - t1.id = 2) -- t3, t2, t1 的 id 差距均为1或2
)
order by t1.id; -- 按照 t1 表的 id 升序排序3部门工资前三高的所有员工
表: Employee
+--------------+---------+ | Column Name | Type | +--------------+---------+ | id | int | | name | varchar | | salary | int | | departmentId | int | +--------------+---------+ id 是该表的主键列(具有唯一值的列)。 departmentId 是 Department 表中 ID 的外键(reference 列)。 该表的每一行都表示员工的ID、姓名和工资。它还包含了他们部门的ID。
表: Department
+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | name | varchar | +-------------+---------+ id 是该表的主键列(具有唯一值的列)。 该表的每一行表示部门ID和部门名。
公司的主管们感兴趣的是公司每个部门中谁赚的钱最多。一个部门的 高收入者 是指一个员工的工资在该部门的 不同 工资中 排名前三 。
编写解决方案,找出每个部门中 收入高的员工 。
以 任意顺序 返回结果表。
返回结果格式如下所示。
示例 1:
输入: Employee 表: +----+-------+--------+--------------+ | id | name | salary | departmentId | +----+-------+--------+--------------+ | 1 | Joe | 85000 | 1 | | 2 | Henry | 80000 | 2 | | 3 | Sam | 60000 | 2 | | 4 | Max | 90000 | 1 | | 5 | Janet | 69000 | 1 | | 6 | Randy | 85000 | 1 | | 7 | Will | 70000 | 1 | +----+-------+--------+--------------+ Department 表: +----+-------+ | id | name | +----+-------+ | 1 | IT | | 2 | Sales | +----+-------+ 输出: +------------+----------+--------+ | Department | Employee | Salary | +------------+----------+--------+ | IT | Max | 90000 | | IT | Joe | 85000 | | IT | Randy | 85000 | | IT | Will | 70000 | | Sales | Henry | 80000 | | Sales | Sam | 60000 | +------------+----------+--------+ 解释: 在IT部门: - Max的工资最高 - 兰迪和乔都赚取第二高的独特的薪水 - 威尔的薪水是第三高的在销售部: - 亨利的工资最高 - 山姆的薪水第二高 - 没有第三高的工资,因为只有两名员工
思路:
-
从 Employee 表和 Department 表中选择部门名称(Department)、员工名称(Employee)和工资(Salary),同时使用
JOIN来关联这两个表,关联条件是 Employee 表中的 DepartmentId 字段与 Department 表中的 id 字段相匹配。 -
在子查询中使用 dense_rank
()函数来为每个部门的员工工资进行降序排名,生成密集排名值 rk。dense_rank()函数会根据每个部门的工资高低对员工进行排名,且不会有排名值的间隔。 -
将第2步生成的结果作为临时表 t,并筛选出排名在前3位以内的记录,即 where
t.rk <= 3。 -
最终查询结果包括符合条件的部门、员工和工资信息。
DENSE_RANK() 是 SQL 中的一个窗口函数,用于计算一个值的密集排名,即在结果集中按照指定的排序条件为每个行分配一个唯一的整数排名值,并且没有间隔。下面是 DENSE_RANK() 的基本用法和一个相关例子:
基本用法:
DENSE_RANK() OVER (PARTITION BY col1 ORDER BY col2)
PARTITION BY用于指定分组的字段或表达式,根据该字段分组计算排名。ORDER BY用于指定根据哪个字段或表达式排序计算排名,可以是升序或降序
相关例子:
假设有一个学生成绩表 Scores,包含字段 StudentID、Subject 和 Score。我们想要计算每个科目的学生成绩密集排名(按分数从高到低排名),可以使用 DENSE_RANK() 函数如下:
SELECT StudentID, Subject, Score,
DENSE_RANK() OVER (PARTITION BY Subject ORDER BY Score DESC) AS DenseRank
FROM Scores;
上面的例子中,DENSE_RANK() 函数根据科目(Subject)对学生的成绩(Score)进行降序排名,生成密集的排名值 DenseRank。在每个科目内,排名值不会有间隔,即如果有相同的分数,会跳过后续的排名值以保持连续。
本题代码:
-- 选择部门、雇员和工资
select Department, Employee, Salary
from (-- 从雇员表 e 和部门表 d 中选择部门名为 Department,雇员名为 Employee,工资为 Salary-- 使用 dense_rank() 函数根据部门ID对工资进行降序排名,生成排名为 rkselect d.name as Department, e.name as Employee, e.salary as Salary,dense_rank() over(partition by DepartmentId order by salary desc) as rkfrom Employee as ejoin Department as don e.DepartmentId = d.id
) as t
-- 只选择排名前三的记录
where t.rk <= 3;相关文章:

数据库练习题
1行程和用户 表:Trips ----------------------- | Column Name | Type | ----------------------- | id | int | | client_id | int | | driver_id | int | | city_id | int | | status | enum | | request_at…...

【每日一函数】uname 函数介绍及代码演示
Linux uname 函数介绍及代码演示 引言 Linux 系统中,uname 是一个常用的命令行工具,用于显示系统信息。然而,在编程过程中,我们有时需要在程序中获取这些信息,此时就可以使用 uname 函数。本文将对 uname 函数进行详…...

linux:命令别名,文件描述符及重定向
命令别名 命令别名是Shell提供的一种快捷方式,允许为命令创建简短的替代名称。,可以通过输入较短的别名来执行较长的命令,从而提高效率。 1.查看所有别名: [rootlocalhost ~]# alias 2.创建临时别名,当前会话关闭即清除 alias 别名完整命令…...
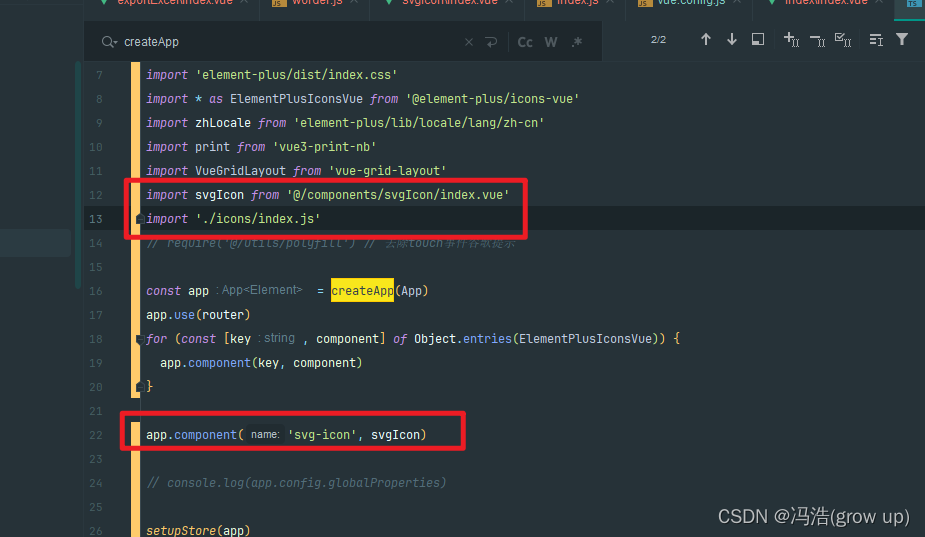
前端开发之中svg图标的使用和实例
svg图标的使用和实例 前言效果图1、安装插件2、vue3中使用2.1、 在components文件夹中,创建公共类SvgIcon/index.vue2.2、创建icons文件,存放svg图标和将所有的svg图标进行引用并注册成全局组件2.3、在man.js 中注册2.4、在vue.config.js中配置svg2.5、在vue中的调用svg图标3…...
BeagleBone Black入门总结
文章目录 参考连接重要路径系统镜像下载访问 BeagleBone 参考连接 镜像下载启动系统制作:SD卡烧录工具入门书籍推荐:BeagleBone cookbookBeagleBone概况? 重要路径 官方例程及脚本路径:/var/lib/cloud9 系统镜像下载 疑问&am…...

笔记:Mysql的安全策略
1,安装安全插件 1.检查是否已安装该插件 SELECT PLUGIN_NAME, PLUGIN_STATUS FROM INFORMATION_SCHEMA.PLUGINS WHERE PLUGIN_NAME validate_password;2.安装插件 INSTALL PLUGIN validate_password SONAME validate_password.so;3.修改配置文件 vi /etc/my.cn…...

AI绘画中的图像格式技术
在数字艺术的广阔天地里,AI绘画作为一种新兴的艺术形式,正在逐渐占据一席之地。不同于传统绘画,AI绘画依赖于复杂的算法和机器学习模型来生成图像,而这一切的背后,图像格式技术发挥着至关重要的作用。图像格式不仅关系…...

前端如何封装自己的npm包并且发布到npm注册源
前言 在前端开发中,复用代码是一种常见且高效的实践。通过封装和发布自己的npm包,你可以轻松地在多个项目之间共享代码,并且贡献给社区。以下是一步一步指导你如何封装自己的npm包并发布到npm注册源。 步骤一:创建并设置项目 首…...

vue油色谱画 大卫三角形|大卫五边形|PD图
大卫三角形 大卫五边形 PD图...

【React】前端插件 uuidjs 的使用 --随机生成id
文档1 文档2 使用 1.安装 npm install uuid2.Create a UUID import { v4 as uuidv4 } from uuid; uuidv4(); // ⇨ 9b1deb4d-3b7d-4bad-9bdd-2b0d7b3dcb6d3.或使用 CommonJS语法 const { v4: uuidv4 } require(uuid); uuidv4(); // ⇨ 1b9d6bcd-bbfd-4b2d-9b5d-ab8dfbbd4…...
ctfshow-web入门-信息搜集(web11-web20)
目录 1、web11 2、web12 3、web13 4、web14 5、web15 6、web16 7、web17 8、web18 9、web19 10、web20 1、web11 域名其实也可以隐藏信息,比如flag.ctfshow.com 就隐藏了一条信息 查询域名的 DNS 记录,类型为 TXT(域名的说明&#…...
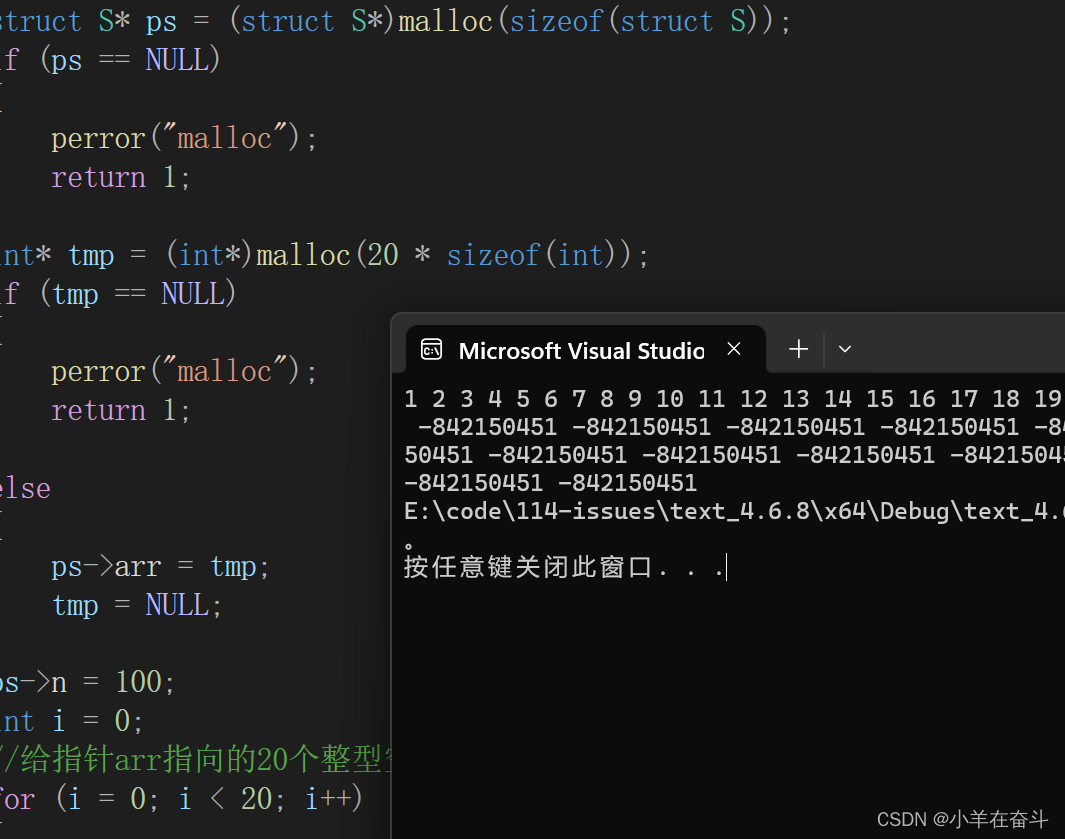
C语言详解(动态内存管理)2
Hi~!这里是奋斗的小羊,很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~~ 💥💥个人主页:奋斗的小羊 💥💥所属专栏:C语言 🚀本系列文章为个人学习…...
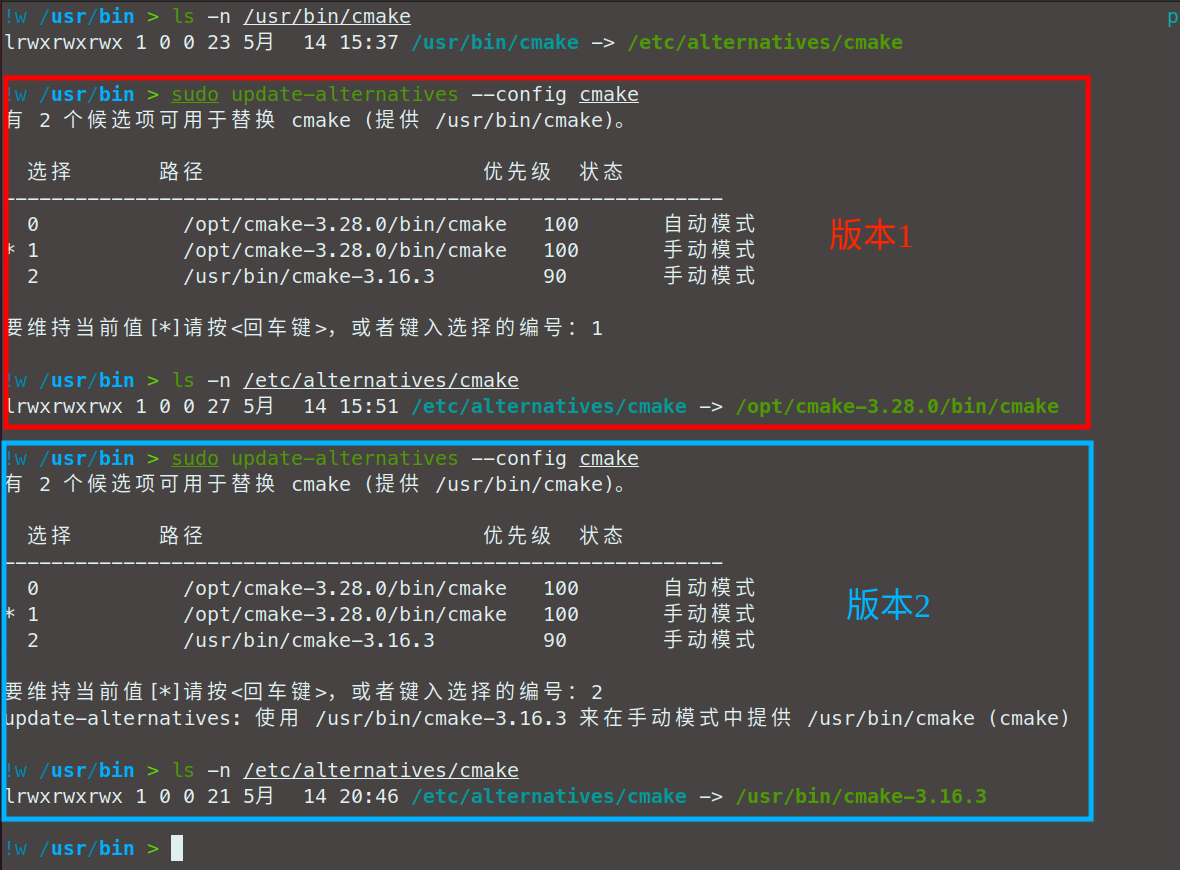
【ubuntu软件版本管理】利用update-alternatives管理ubuntu软件
我们有的时候希望在安装了新软件之后保留旧版本的软件,比如希望保留旧版本的gcc,以防以前写的C编译出问题,这时候就需要版本管理软件update-alternatives。 在此之前我们需要先弄清楚,什么是ubuntu的软件?拿C源…...

如何把linux安装到单片机中
1.如何把linux安装到单片机中 将Linux安装到单片机中通常不是一个直接的过程,因为单片机(如51系列、STC系列等)的硬件资源和处理能力有限,而Linux是一个为更强大硬件平台(如个人电脑、服务器)设计的操作系…...

Ubuntu bash按Table不联想
Ubuntu bash按Table不联想 bash-completion包未安装或损坏: 自动补全功能依赖于bash-completion包。首先,需要确保这个包已经安装。可以通过下面的命令安装或重新安装它: sudo apt install --reinstall bash-completion安装完成后,…...
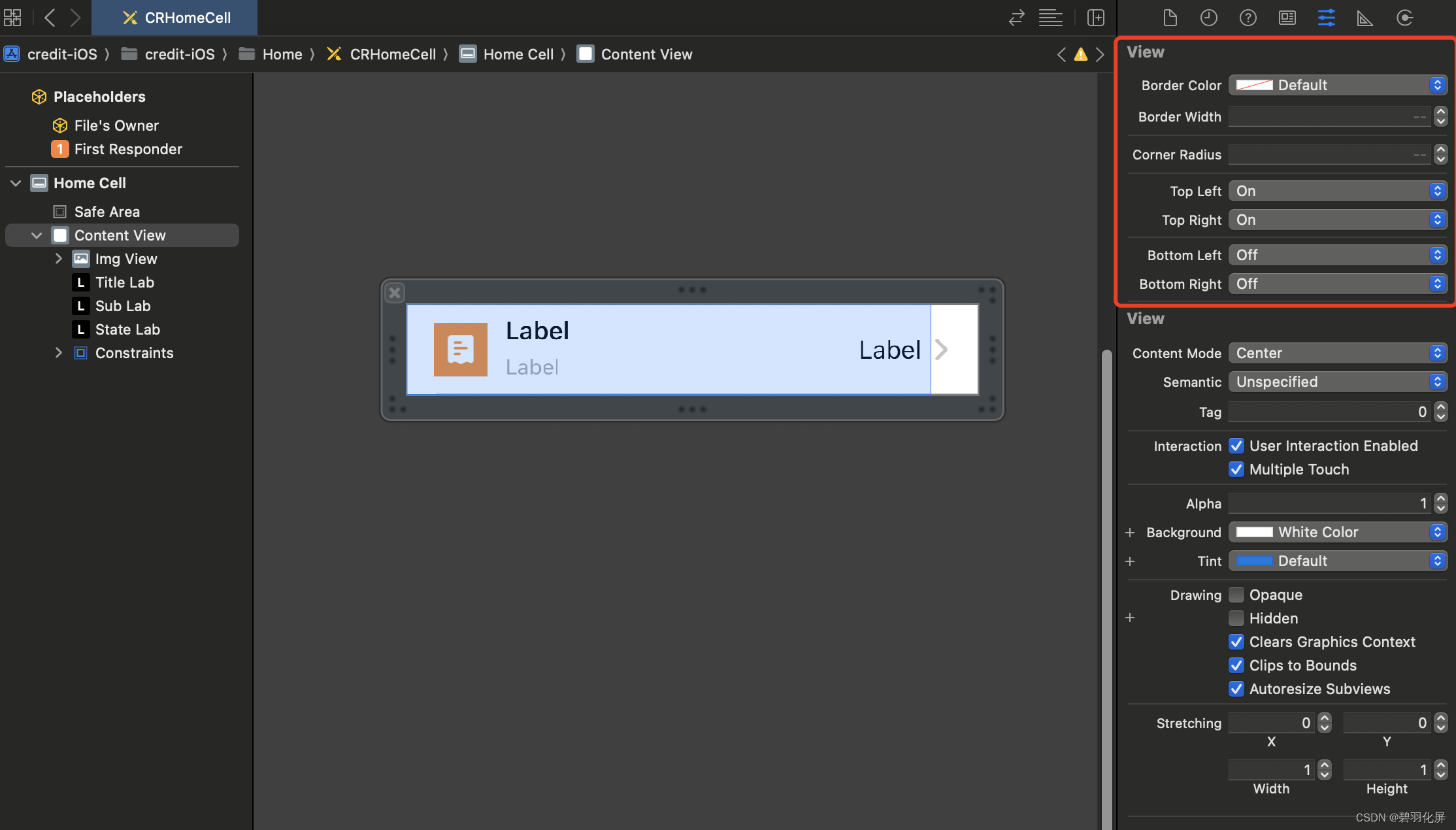
Xcode中给UIView在xib中添加可视化的属性
给UIView在xib中添加可视化的属性 效果如下图: 可以直接设置view 的 borderColor 、borderWidth、cornerRadius,也可以单独指定view的某个角是圆角。减少了代码中的属性。 完整代码: UIViewBorder.h #import <UIKit/UIKit.h>inter…...

中缀表达式和前缀后缀
在中缀表达式中,操作数可能与两个操作符相结合 但是,想要不带括号无歧义,且不需要考虑运算符优先级和结合性 所以考虑 前缀表达式,波兰表达式 后缀表达式 逆波兰表达式 对于人来说,中缀表达式是最容易读懂的。但是对于…...

强化学习面试题
强化学习面试题通常会涵盖该领域的多个方面,包括基本概念、算法、应用以及实践问题。以下是一些常见的强化学习面试题及其简要回答: 基本概念题: 什么是强化学习? 强化学习是一种通过智能体与环境交互来学习最优行为策略的机器学习范式。智能体根据当前状态选择动作,环境…...

Pytorch中的广播机制
一、广播(broadcast)机制概述 在PyTorch中,广播机制(Broadcast)允许对不同形状的张量执行逐元素操作,而无需显式地复制数据。这一机制使得编写代码更加简洁和高效。广播机制遵循一定的规则来扩展较小的张量,使其与较大的张量具有相同的形状 …...

2024年全国一高考数学压轴题
(3) 证明: 显然, 等差数列 { a 1 , . . . , a 4 n 2 } \{a_{1},...,a_{4n2}\} {a1,...,a4n2} 是 ( i , j ) (i, j) (i,j)-可分的等价于等差数列 { 1 , . . . , 4 n 2 } \{1,...,4n2\} {1,...,4n2} 是 ( i , j ) (i,j) (i,j)-可分的. 前推后显然, 我们考虑后推前, 在去…...

Orama混合搜索实战:从全文检索到向量搜索的轻量级实现
1. 项目概述:从“全文搜索”到“向量搜索”的现代演进如果你做过Web开发,尤其是需要处理大量文本内容的应用,比如博客站、文档中心或者电商平台,那么“搜索”功能绝对是你绕不开的核心需求。传统上,我们可能会直接想到…...

企业安全运维:轻量级OpenClaw检测脚本的设计、部署与MDM集成实战
1. 项目概述:为什么我们需要一个轻量级的OpenClaw检测脚本?在当今的企业IT环境中,开发工具和AI辅助编程代理的普及带来了前所未有的效率提升,但同时也引入了新的安全与合规盲区。想象一下,一个未经批准的开发工具&…...

uHabits习惯追踪应用完整指南:从入门到精通的5个实用技巧
uHabits习惯追踪应用完整指南:从入门到精通的5个实用技巧 【免费下载链接】uhabits Loop Habit Tracker, a mobile app for creating and maintaining long-term positive habits 项目地址: https://gitcode.com/gh_mirrors/uh/uhabits uHabits习惯追踪应用是…...

个人开发者如何利用 Taotoken 管理多个项目的 AI 调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 个人开发者如何利用 Taotoken 管理多个项目的 AI 调用成本 对于独立开发者或自由职业者而言,同时维护多个小型项目是常…...

别再死记硬背截止、放大、饱和了!用Arduino+面包板,5分钟直观理解NPN/PNP三极管
用Arduino实验破解三极管的三大工作状态之谜 记得第一次翻开电子学教材看到三极管章节时,那些密密麻麻的曲线图和公式让我头皮发麻。"截止区"、"放大区"、"饱和区"——这些抽象概念就像天书一样难以理解。直到有一天,我拿…...

从零构建开源语音AI交互中枢:EchoKit Server部署与调优指南
1. 项目概述:构建你自己的语音AI交互中枢 如果你对智能音箱、语音助手这类设备感兴趣,但又觉得市面上的产品要么功能封闭,要么隐私堪忧,那么今天聊的这个项目——EchoKit Server,可能会让你眼前一亮。简单来说&#x…...

VirtualBox 6.1+ 搭配Win10:除了装系统,这些高效设置让你的虚拟机真正好用起来
VirtualBox 6.1 与Win10深度整合:解锁专业级虚拟化生产力的5个关键策略 当你已经成功在VirtualBox中安装好Windows 10虚拟机,这仅仅是虚拟化旅程的起点。真正的高手懂得如何将这个看似隔离的环境转变为无缝融入日常工作流的生产力引擎。本文将揭示那些鲜…...

从‘不好用的CE’到‘好用的OD’:一次逆向实战中的工具选择与思路转换
逆向工程实战:从工具局限到思维跃迁的破解之道 当那个MFC程序弹出第一个窗口时,我习惯性地打开了Cheat Engine——这个在游戏修改领域堪称神器的工具。但十分钟后,面对毫无进展的扫描结果和不断跳出的错误提示,我突然意识到&#…...

Butlerclaw:OpenClaw AI Agent的图形化桌面管理工具
1. 项目概述如果你和我一样,对AI Agent的潜力感到兴奋,但又对OpenClaw这类框架复杂的安装、配置和日常管理感到头疼,那么Butlerclaw的出现,绝对是一个值得庆祝的消息。简单来说,Butlerclaw是一个为OpenClaw量身打造的“…...

告别硬件!用OneNET官方simulate-device工具5分钟搞定MQTT设备云端调试
5分钟实现云端MQTT调试:OneNET模拟设备实战指南 物联网开发中最令人头疼的环节莫过于硬件与云端的联调——硬件没到位时开发停滞,硬件到手后又要面对各种通信问题。OneNET的simulate-device工具彻底改变了这种被动局面,它让开发者能在零硬件依…...