城市之旅:使用 LLM 和 Elasticsearch 简化地理空间搜索(二)
我们在之前的文章 “城市之旅:使用 LLM 和 Elasticsearch 简化地理空间搜索(一)”,在今天的练习中,我将使用本地部署来做那里面的 Jupyter notebook。
安装
Elasticsearch 及 Kibana
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的链接来进行安装:
- 如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
- Kibana:如何在 Linux,MacOS 及 Windows上安装 Elastic 栈中的 Kibana
在安装的时候,我们选择 Elastic Stack 8.x 来进行安装。特别值得指出的是:ES|QL 只在 Elastic Stack 8.11 及以后得版本中才有。你需要下载 Elastic Stack 8.11 及以后得版本来进行安装。
在首次启动 Elasticsearch 的时候,我们可以看到如下的输出:
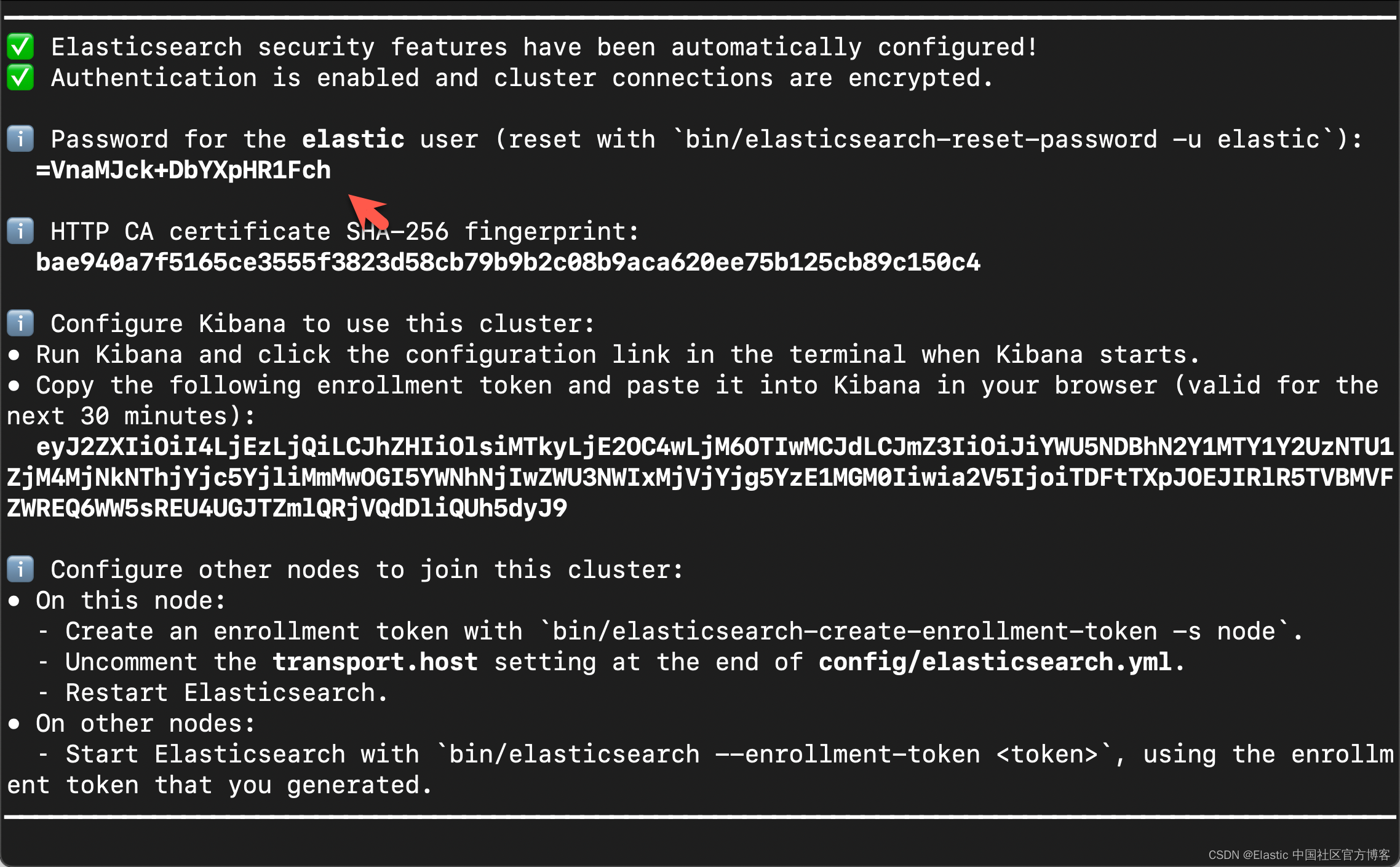
我们需要记下 Elasticsearch 超级用户 elastic 的密码。
我们还可以在安装 Elasticsearch 目录中找到 Elasticsearch 的访问证书:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.13.4/config/certs
$ ls
http.p12 http_ca.crt transport.p12在上面,http_ca.crt 是我们需要用来访问 Elasticsearch 的证书。
我们首先克隆已经写好的代码:
git clone https://github.com/liu-xiao-guo/elasticsearch-labs我们然后进入到该项目的根目录下:
$ pwd
/Users/liuxg/python/elasticsearch-labs/supporting-blog-content/geospatial-llm
$ cp ~/elastic/elasticsearch-8.13.4/config/certs/http_ca.crt .
$ ls
09-geospatial-search.ipynb http_ca.crt在上面,我们把 Elasticsearch 的证书拷贝到当前的目录下。上面的 09-geospatial-search.ipynb 就是我们下面要展示的 notebook。
启动白金试用
在下面,我们需要使用 ELSER。这是一个白金试用的功能。我们按照如下的步骤来启动白金试用:
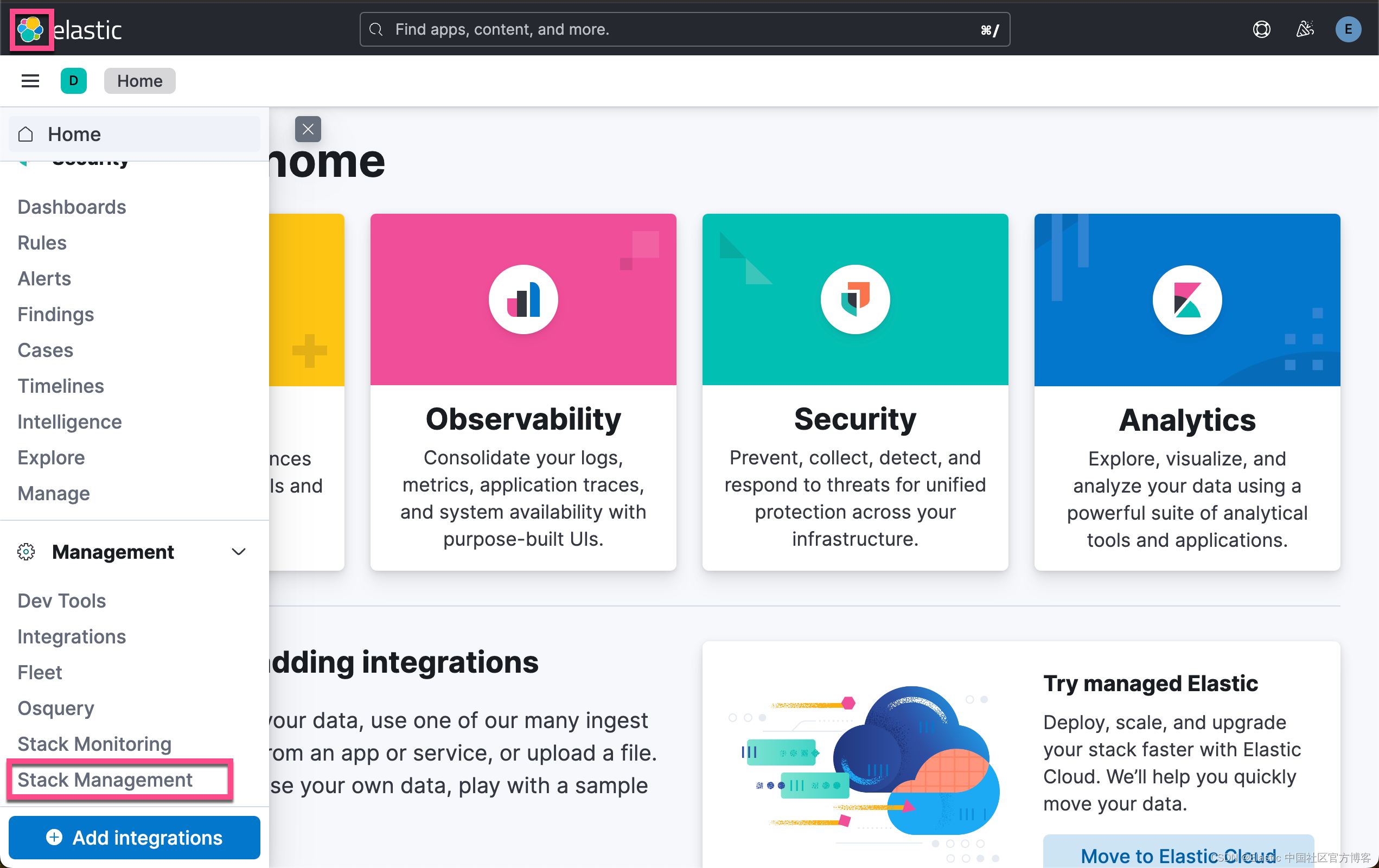
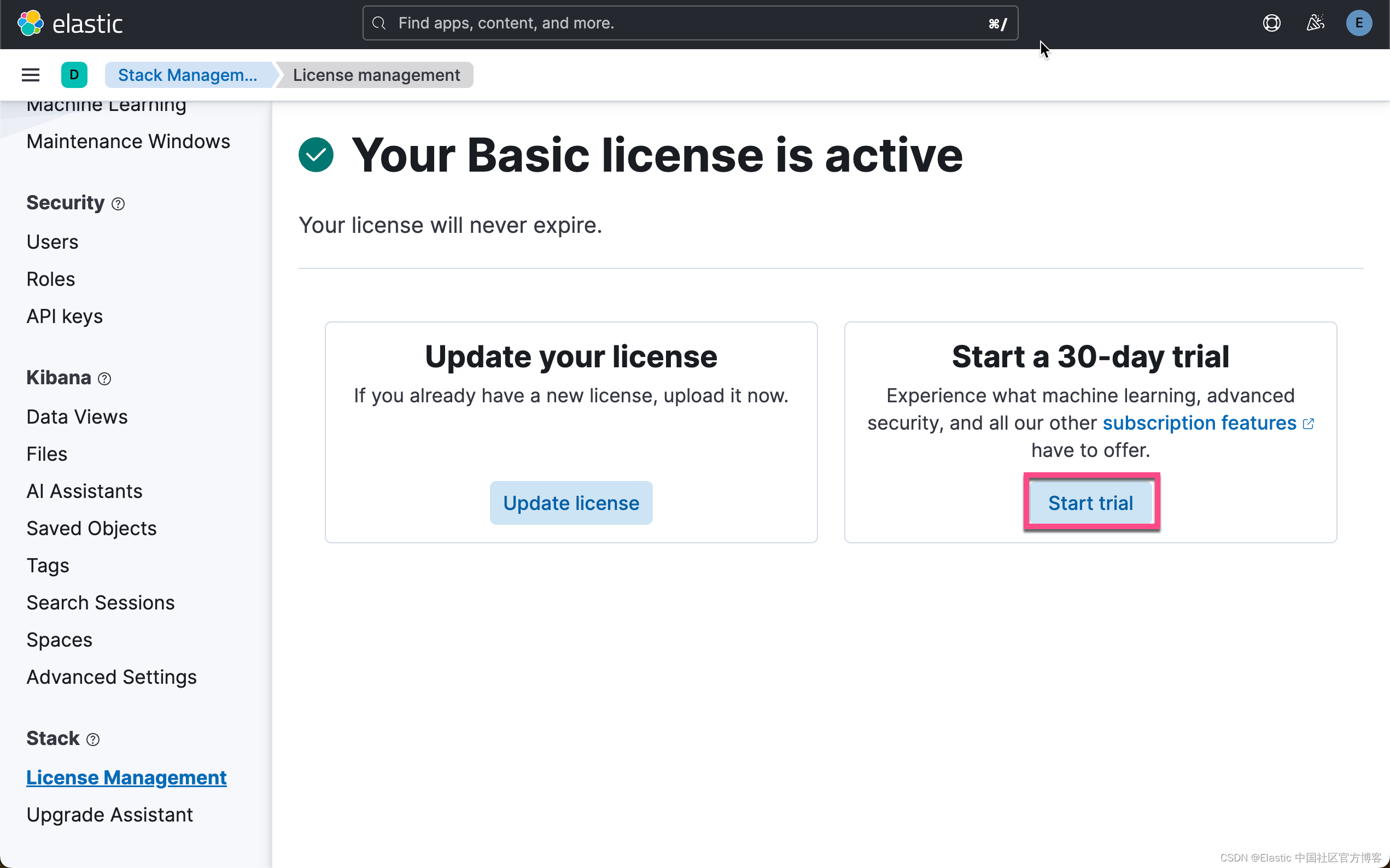
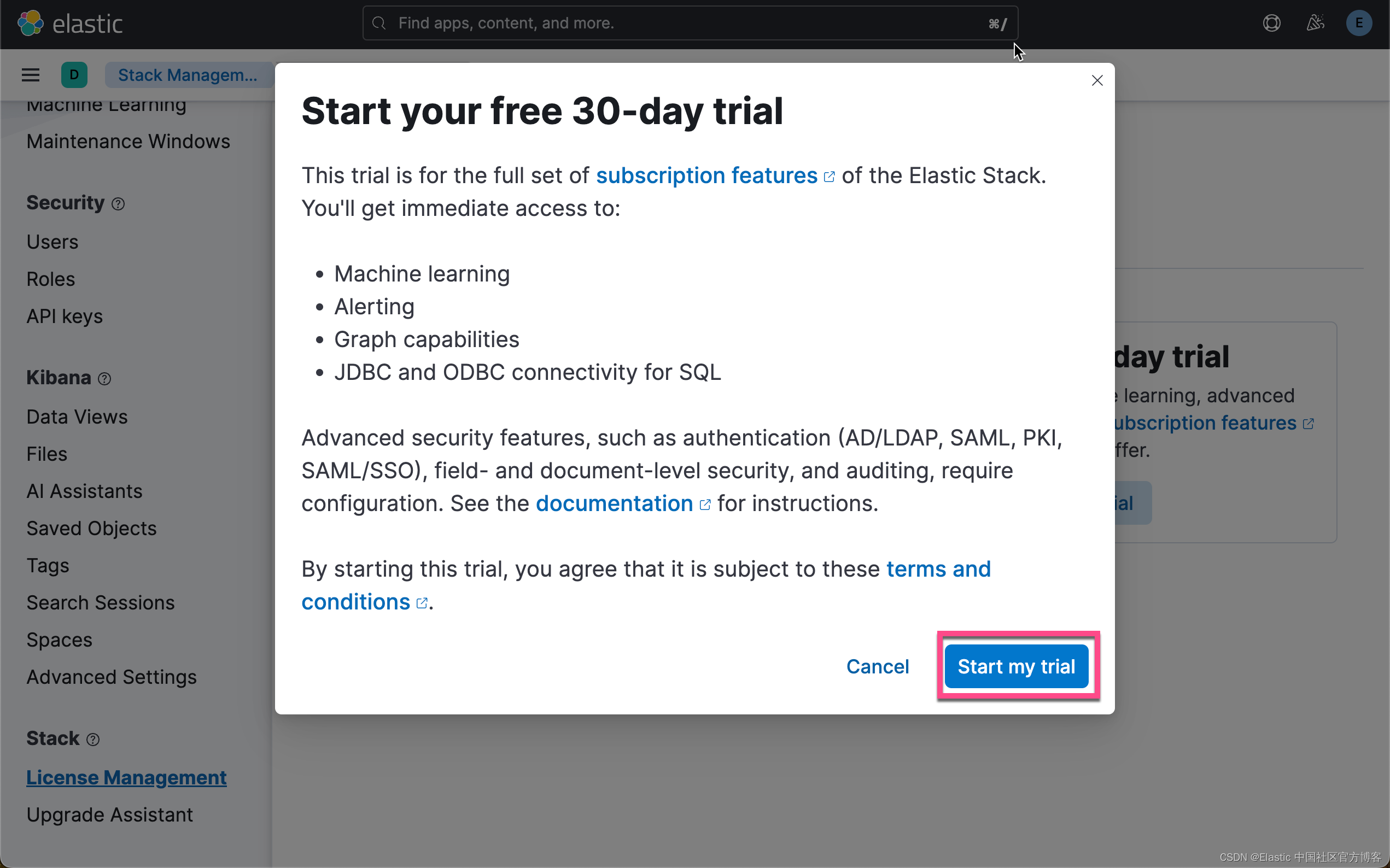
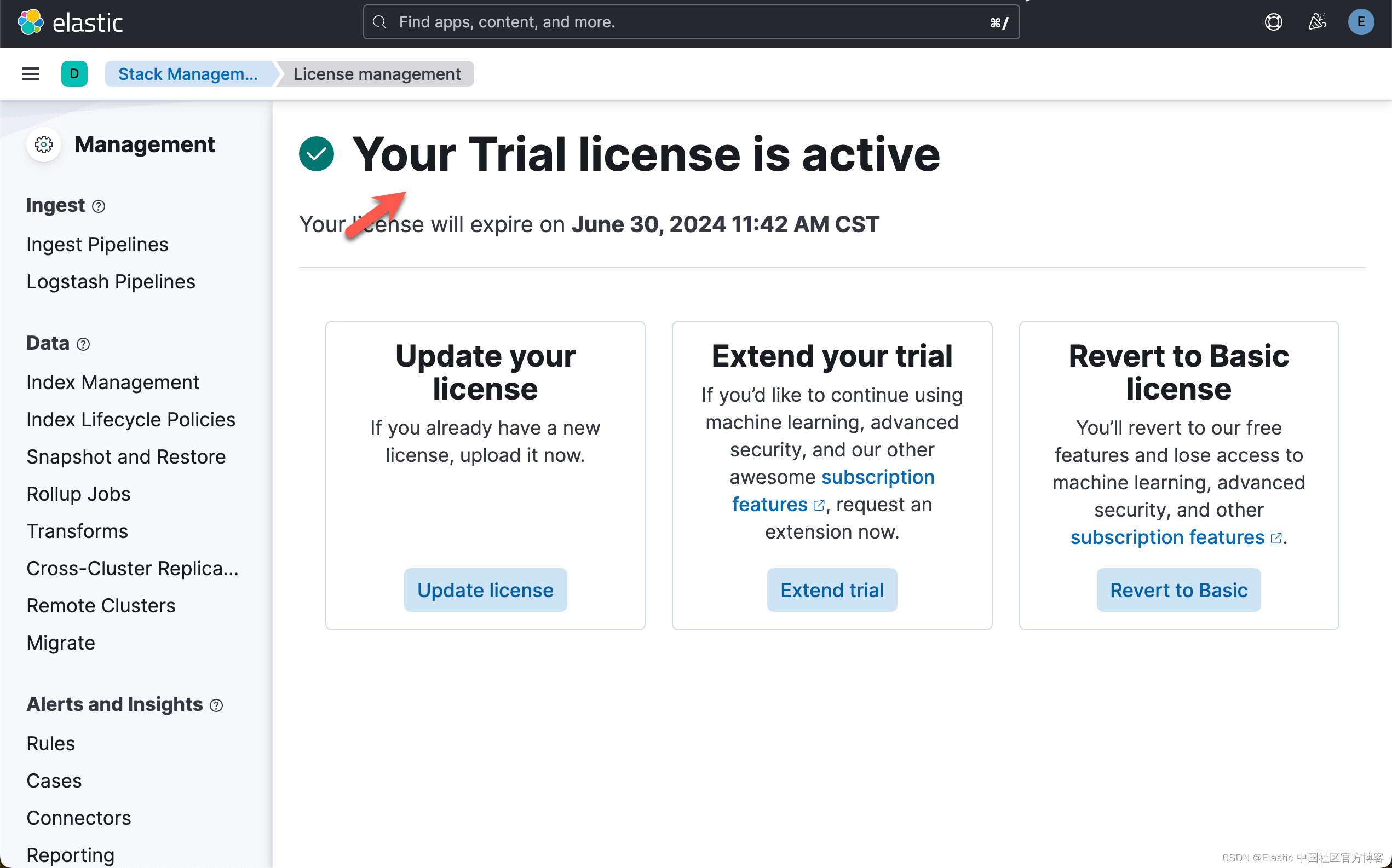
这样我们就完成了白金试用功能。
创建环境变量
为了能够使得下面的应用顺利执行,我们在当前的项目根目录下创建一个叫做 .env 的文件。它的内容如下:
.env
ES_USER="elastic"
ES_PASSWORD="=VnaMJck+DbYXpHR1Fch"
ES_ENDPOINT="localhost"
OPENAI_API_KEY="YourOpenAIkey"你需要根据自己的 Elasticsearch 的配置来修改上面的配置。你需要申请自己的 OpenAI key 来完成上面的配置。你可以在地址 https://platform.openai.com/api-keys 进行申请。

创建完上面的文件后,我们可以看到:
$ pwd
/Users/liuxg/python/elasticsearch-labs/supporting-blog-content/geospatial-llm
$ ls -al
total 176
drwxr-xr-x 5 liuxg staff 160 May 31 11:10 .
drwxr-xr-x 16 liuxg staff 512 May 31 09:55 ..
-rw-r--r-- 1 liuxg staff 146 May 31 11:10 .env
-rw-r--r-- 1 liuxg staff 78674 May 31 09:48 09-geospatial-search.ipynb
-rw-r----- 1 liuxg staff 1915 May 31 10:55 http_ca.crt演示
我们在项目的根目录下,我们使用如下的命令来打开 notebook:
$ pwd
/Users/liuxg/python/elasticsearch-labs/supporting-blog-content/geospatial-llm
$ jupyter notebook 09-geospatial-search.ipynb 安装及连接
首先,我们需要使用 Python 客户端连接到 Elastic 部署。
!pip install -qU elasticsearch requests openai python-dotenv接下来,我们导入所需要的包:
from dotenv import load_dotenv
import os
from elasticsearch import Elasticsearch, helpers, exceptions
from elasticsearch.helpers import BulkIndexError
import time
import json as JSON现在我们可以实例化 Python Elasticsearch 客户端。然后我们创建一个客户端对象来实例化 Elasticsearch 类的实例
load_dotenv()ES_USER = os.getenv("ES_USER")
ES_PASSWORD = os.getenv("ES_PASSWORD")
ES_ENDPOINT = os.getenv("ES_ENDPOINT")
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")url = f"https://{ES_USER}:{ES_PASSWORD}@{ES_ENDPOINT}:9200"
print(url)client = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)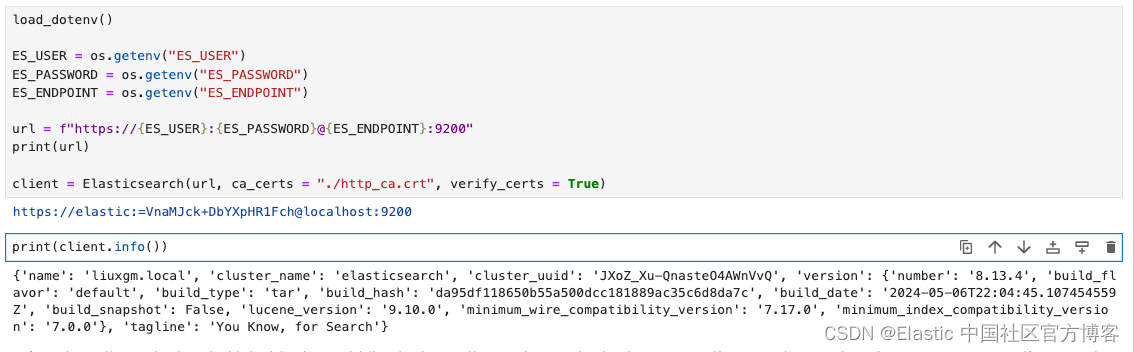
下载并部署 ELSER 模型
在此示例中,我们将下载 ELSER 模型并将其部署到 ML 节点中。确保你有一个 ML 节点才能运行 ELSER 模型。
# delete model if already downloaded and deployed
try:client.ml.delete_trained_model(model_id=".elser_model_2", force=True)print("Model deleted successfully, We will proceed with creating one")
except exceptions.NotFoundError:print("Model doesn't exist, but We will proceed with creating one")# Creates the ELSER model configuration. Automatically downloads the model if it doesn't exist.
client.ml.put_trained_model(model_id=".elser_model_2", input={"field_names": ["text_field"]}
)注意:针对 x86 架构,我们可以使用模型 .elser_model_2_linux-x86_64 来代替 .elser_model_2 以获取更好的性能。在下面的代码中,我们也需要相应的更换。
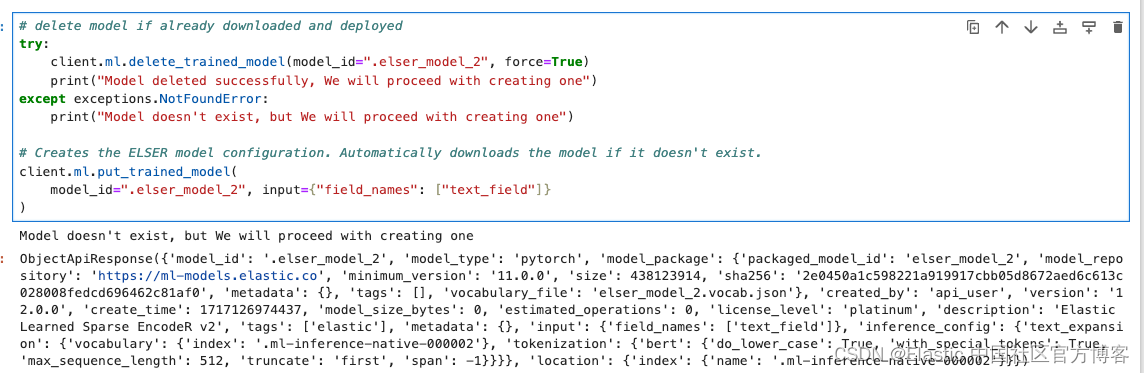
上面的命令下载需要一点时间。我们使用如下的代码来等待模型的下载:
while True:status = client.ml.get_trained_models(model_id=".elser_model_2", include="definition_status")if status["trained_model_configs"][0]["fully_defined"]:print("ELSER Model is downloaded and ready to be deployed.")breakelse:print("ELSER Model is downloaded but not ready to be deployed.")time.sleep(5)
运行完上面的代码后,我们可以在 Kibana 中进行查看:
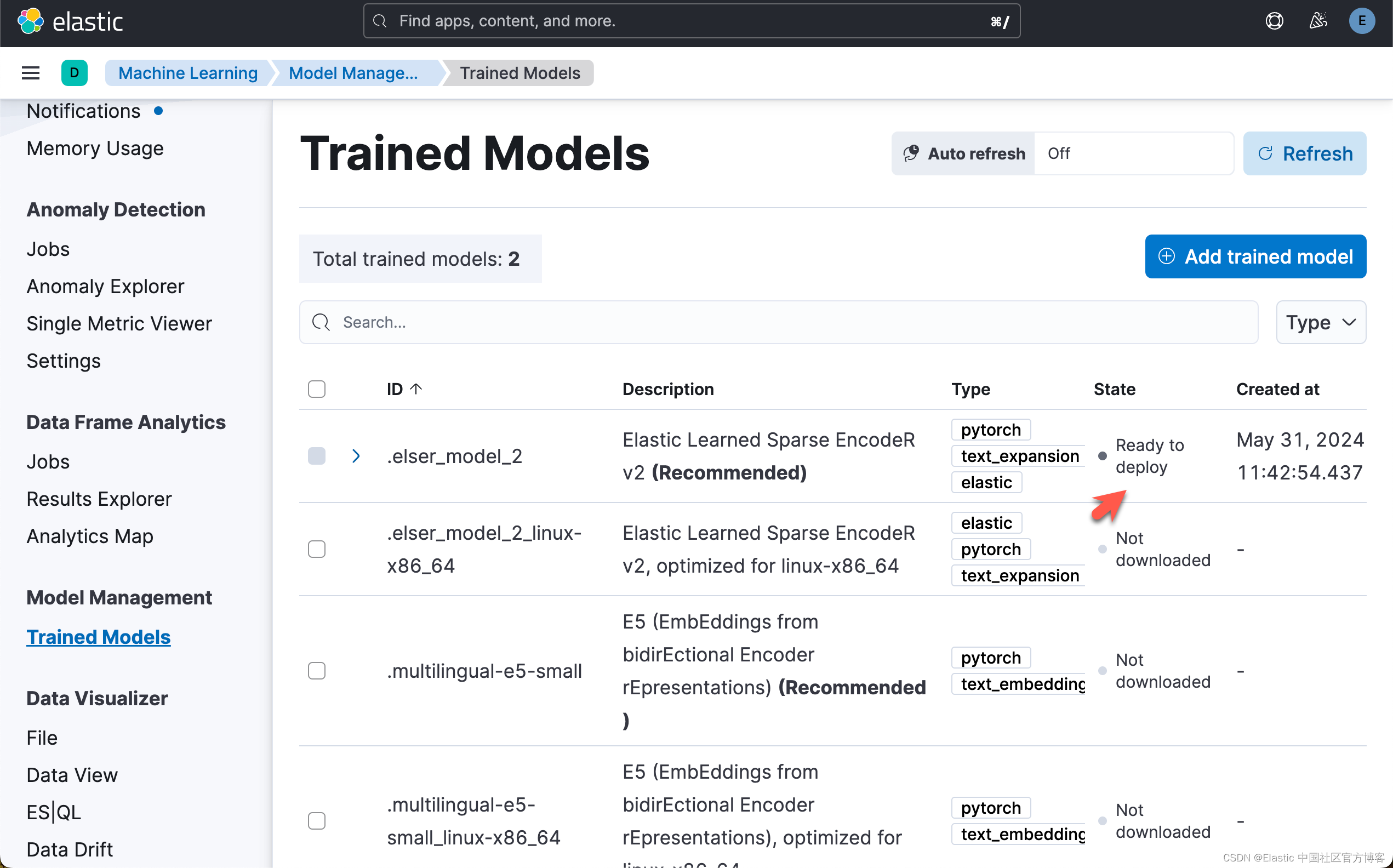
下载模型后,我们可以将模型部署到 ML 节点中。使用以下命令来部署模型。
# Start trained model deployment if not already deployed
client.ml.start_trained_model_deployment(model_id=".elser_model_2", number_of_allocations=1, wait_for="starting"
)while True:status = client.ml.get_trained_models_stats(model_id=".elser_model_2",)if status["trained_model_stats"][0]["deployment_stats"]["state"] == "started":print("ELSER Model has been successfully deployed.")breakelse:print("ELSER Model is currently being deployed.")time.sleep(5)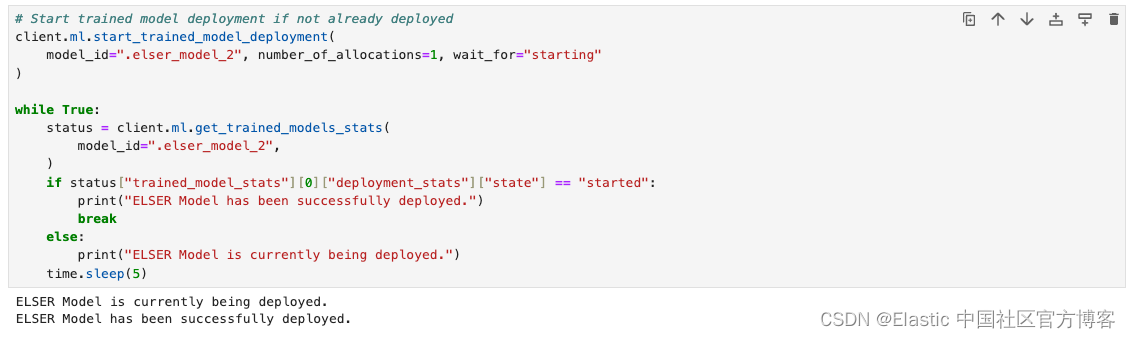
运行完上面的代码后,我们可以在 Kibana 再次进行查看:
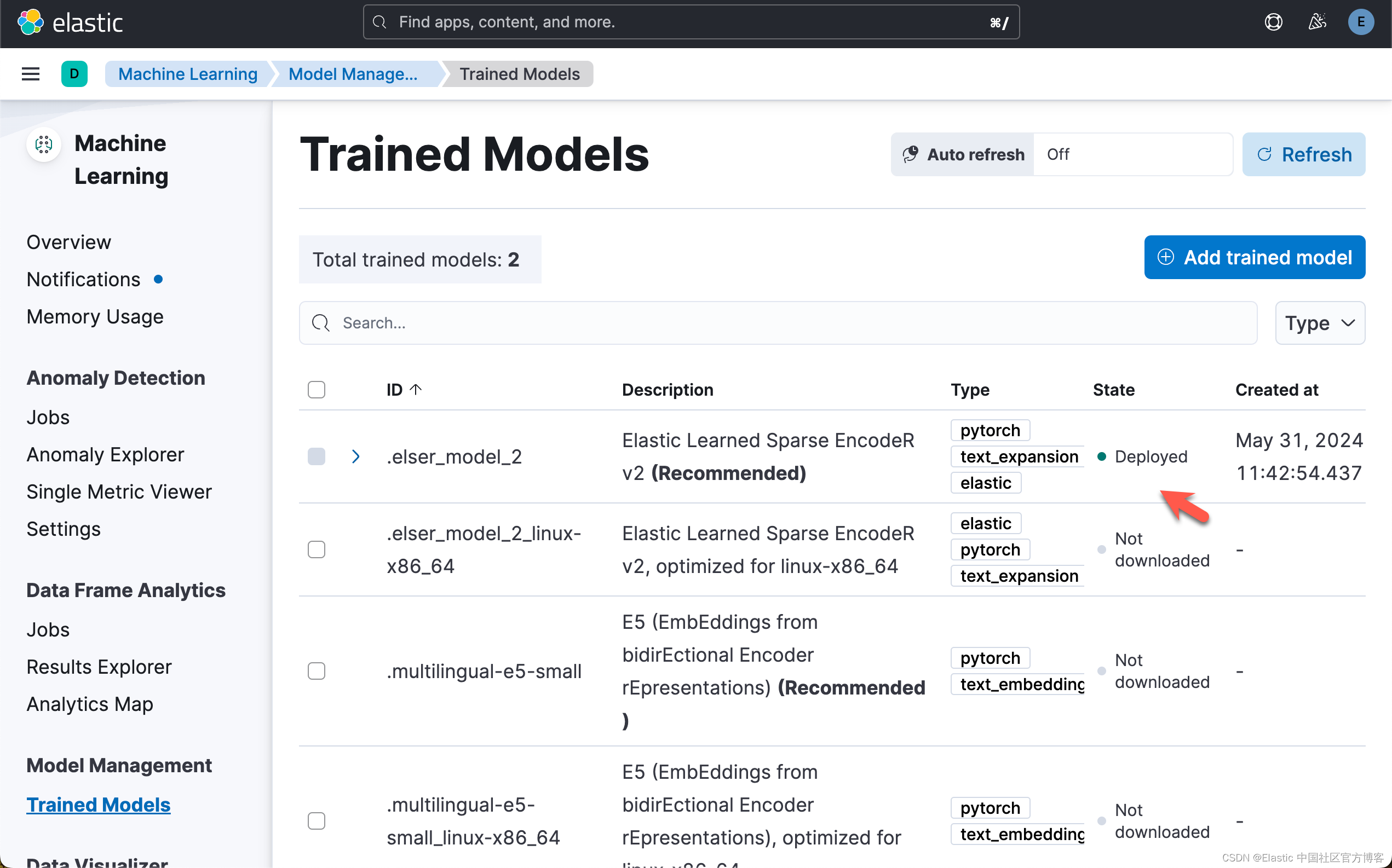
我们也可以从 Kibana 中来部署 ELSER。请详细阅读之前的文章 “Elasticsearch:部署 ELSER - Elastic Learned Sparse EncoderR”。
使用 ELSER 索引文档
为了在我们的 Elasticsearch 部署上使用 ELSER,我们需要创建一个包含运行 ELSER 模型的推理处理器的摄取管道。让我们使用 put_pipeline 方法添加该管道。
client.ingest.put_pipeline(id="elser-ingest-pipeline",description="Ingest pipeline for ELSER",processors=[{"html_strip": {"field": "name", "ignore_failure": True}},{"html_strip": {"field": "description", "ignore_failure": True}},{"html_strip": {"field": "amenities", "ignore_failure": True}},{"html_strip": {"field": "host_about", "ignore_failure": True}},{"inference": {"model_id": ".elser_model_2","input_output": [{"input_field": "name", "output_field": "name_embedding"}],"ignore_failure": True,}},{"inference": {"model_id": ".elser_model_2","input_output": [{"input_field": "description","output_field": "description_embedding",}],"ignore_failure": True,}},{"inference": {"model_id": ".elser_model_2","input_output": [{"input_field": "amenities", "output_field": "amenities_embedding"}],"ignore_failure": True,}},{"inference": {"model_id": ".elser_model_2","input_output": [{"input_field": "host_about","output_field": "host_about_embedding",}],"ignore_failure": True,}},],
)ObjectApiResponse({'acknowledged': True})准备 AirBnB 列表
接下来我们需要准备索引。除非另有说明,我们会将所有内容映射为关键字。我们还将使用 ELSER 将列表的 name 和 decription 映射为 sparse_vectors 。
client.indices.delete(index="airbnb-listings", ignore_unavailable=True)
client.indices.create(index="airbnb-listings",settings={"index": {"default_pipeline": "elser-ingest-pipeline"}},mappings={"dynamic_templates": [{"stringsaskeywords": {"match": "*","match_mapping_type": "string","mapping": {"type": "keyword"},}}],"properties": {"host_about_embedding": {"type": "sparse_vector"},"amenities_embedding": {"type": "sparse_vector"},"description_embedding": {"type": "sparse_vector"},"name_embedding": {"type": "sparse_vector"},"location": {"type": "geo_point"},},},
)ObjectApiResponse({'acknowledged': True, 'shards_acknowledged': True, 'index': 'airbnb-listings'})运行完上面的代码后,我们可以在 Kibana 中找到已经创建的 airbnb-listings 索引:
下载 airbnb 数据
接下来,我们将下载 AirBnB 列表 csv 并将其上传到 Elasticsearch。这可能需要几分钟! AirBnB 列表包含大约 80mb 的 CSV 扩展文件和大约 40,000 个文档。在下面的代码中,我们添加了一个 if 条件以仅处理前 5,000 个文档。
为了能够使得下面的代码能够正常运行,我们使用如下的命令来活动 airbnb 数据:
wget https://data.insideairbnb.com/united-states/ny/new-york-city/2024-03-07/data/listings.csv.gz$ pwd
/Users/liuxg/tmp/elasticsearch-labs/supporting-blog-content/geospatial-llm
$ wget https://data.insideairbnb.com/united-states/ny/new-york-city/2024-03-07/data/listings.csv.gz
--2024-05-31 12:59:59-- https://data.insideairbnb.com/united-states/ny/new-york-city/2024-03-07/data/listings.csv.gz
Resolving data.insideairbnb.com (data.insideairbnb.com)... 13.226.210.37, 13.226.210.3, 13.226.210.22, ...
Connecting to data.insideairbnb.com (data.insideairbnb.com)|13.226.210.37|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 21315678 (20M) [application/x-gzip]
Saving to: ‘listings.csv.gz’listings.csv.gz 100%[=============================>] 20.33M 12.2MB/s in 1.7s 2024-05-31 13:00:01 (12.2 MB/s) - ‘listings.csv.gz’ saved [21315678/21315678]$ ls
09-geospatial-search.ipynb listings.csv.gz$ pwd
/Users/liuxg/tmp/elasticsearch-labs/supporting-blog-content/geospatial-llm
$ ls
09-geospatial-search.ipynb listings.csv.gz
$ gunzip listings.csv.gz
$ ls
09-geospatial-search.ipynb listings.csvimport requests
import gzip
import shutil
import csv# Download the CSV file
# url = "https://data.insideairbnb.com/united-states/ny/new-york-city/2024-03-07/data/listings.csv.gz"
# response = requests.get(url, stream=True)# Save the downloaded file
#with open("listings.csv.gz", "wb") as file:
# shutil.copyfileobj(response.raw, file)# Unpack the CSV file
#with gzip.open("./listings.csv.gz", "rb") as file_in:
# with open("listings.csv", "wb") as file_out:
# shutil.copyfileobj(file_in, file_out)def remove_empty_fields(data):empty_fields = []# Iterate over the dictionary itemsfor key, value in data.items():# Check if the value is empty (None, empty string, empty list, etc.)if not value:empty_fields.append(key)# Remove empty fields from the dictionaryfor key in empty_fields:del data[key]return datadef prepare_documents():with open("./listings.csv", "r", encoding="utf-8") as file:reader = csv.DictReader(file, delimiter=",")# we are going to only add the first 5.000 listings.limit = 5000for index, row in enumerate(reader):if index >= limit:breakif index % 250 == 0:print(f"Processing document {index}")row["location"] = {"lat": float(row["latitude"]),"lon": float(row["longitude"]),}row = remove_empty_fields(row)yield {"_index": "airbnb-listings","_source": dict(row),}# Note: A bigger chunk_size might cause "connection timeout error"
helpers.bulk(client, prepare_documents(), chunk_size=10)在上面,我们有意识地把 chunk_size 设置为较小的一个数字。如果这个数字较大,那么很有可能会造成 “Connection timeout” 错误信息。这个依赖于我们的 Elasticsearch 的配置及计算机运行的速度。现在每次写入都需要调动 ingest pipeline 来进行向量化。如果这个数字值太大,那么向量化的时间需要的越长,那么极有可能会使得这个 helper.bulk 代码的执行出现 Connection timeout 错误,因为这个执行是需要在规定的时间范围里返回结果的。另外一种解决办法是使用一般操作来完成。
在执行上面的代码后,我们可以看到如下的信息:
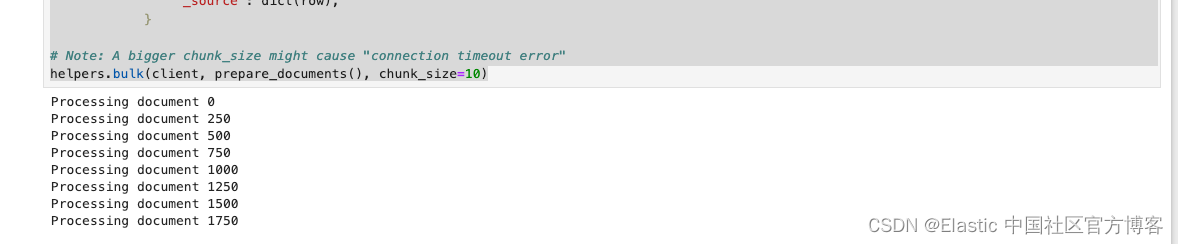
整个写入的时间可能会持续一段时间。这个依赖于自己的电脑的配置。
我们可以在 Kibana 中进行查看:

最终,我们把所需要的 5000 个文档写入到 Elasticsearch 中:
准备 MTA 地铁站索引
我们需要准备索引并确保我们将地理位置视为 geo_point 类型。
client.indices.delete(index="mta-stations", ignore_unavailable=True)
client.indices.create(index="mta-stations",mappings={"dynamic_templates": [{"stringsaskeywords": {"match": "*","match_mapping_type": "string","mapping": {"type": "keyword"},}}],"properties": {"location": {"type": "geo_point"}},},
)索引 MTA 数据
我们现在需要为 MTA 的数据建立索引。
import csv# Download the CSV file
url = "https://data.ny.gov/api/views/39hk-dx4f/rows.csv?accessType=DOWNLOAD"
response = requests.get(url)# Parse and index the CSV data
def prepare_documents():reader = csv.DictReader(response.text.splitlines())for row in reader:row["location"] = {"lat": float(row["GTFS Latitude"]),"lon": float(row["GTFS Longitude"]),}yield {"_index": "mta-stations","_source": dict(row),}# Index the documents
helpers.bulk(client, prepare_documents())准备兴趣点
和之前一样。我们想要索引兴趣点并使用 ELSER 来确保任何语义搜索都有效。例如。搜索 "sights with gardens" 应该返回 "Central Park",即使它的名称中不包含 garden。
client.indices.delete(index="points-of-interest", ignore_unavailable=True)
client.indices.create(index="points-of-interest",settings={"index": {"default_pipeline": "elser-ingest-pipeline"}},mappings={"dynamic_templates": [{"stringsaskeywords": {"match": "*","match_mapping_type": "string","mapping": {"type": "keyword"},}}],"properties": {"NAME": {"type": "text"},"location": {"type": "geo_point"},"name_embedding": {"type": "sparse_vector"},},},
)下载兴趣点
the_geom 看起来像这样: POINT (-74.00701717096757 40.724634757833414) 其格式为众所周知的文本点格式,我们正式支持这一点。我个人总是喜欢将经纬度坐标存储为对象,以确保不会造成混淆。
import csv# Download the CSV file
url = "https://data.cityofnewyork.us/api/views/t95h-5fsr/rows.csv?accessType=DOWNLOAD"
response = requests.get(url)# Parse and index the CSV data
def prepare_documents():reader = csv.DictReader(response.text.splitlines())for row in reader:row["location"] = {"lat": float(row["the_geom"].split(" ")[2].replace(")", "")),"lon": float(row["the_geom"].split(" ")[1].replace("(", "")),}row["name"] = row["NAME"].lower()yield {"_index": "points-of-interest","_source": dict(row),}# Index the documents
helpers.bulk(client, prepare_documents(),chunk_size=10)上面的代码执行需要一段时间。需要耐心等候。
现在我们已经万事俱备了
首先让我们看看 ELSER 在 “geo” 查询方面的表现如何。我们就以 Central Park 和 Empire State 旁边的爱彼迎 (AirBnB) 为例。此外,我们现在只查看 description,而不是 name 或作者简介。让我们保持简单。
response = client.search(index="airbnb-*",size=10,query={"text_expansion": {"description_embedding": {"model_id": ".elser_model_2","model_text": "Next to Central Park and Empire State Building",}}},
)for hit in response["hits"]["hits"]:doc_id = hit["_id"]score = hit["_score"]name = hit["_source"]["name"]location = hit["_source"]["location"]print(f"Score: {score}\nTitle: {name}\nLocation: {location}\nDocument ID: {doc_id}\n")
分析响应
我们对所有 AirBnB 进行了索引,因此可能与你仅索引前 5,000 个时获得的结果略有不同。
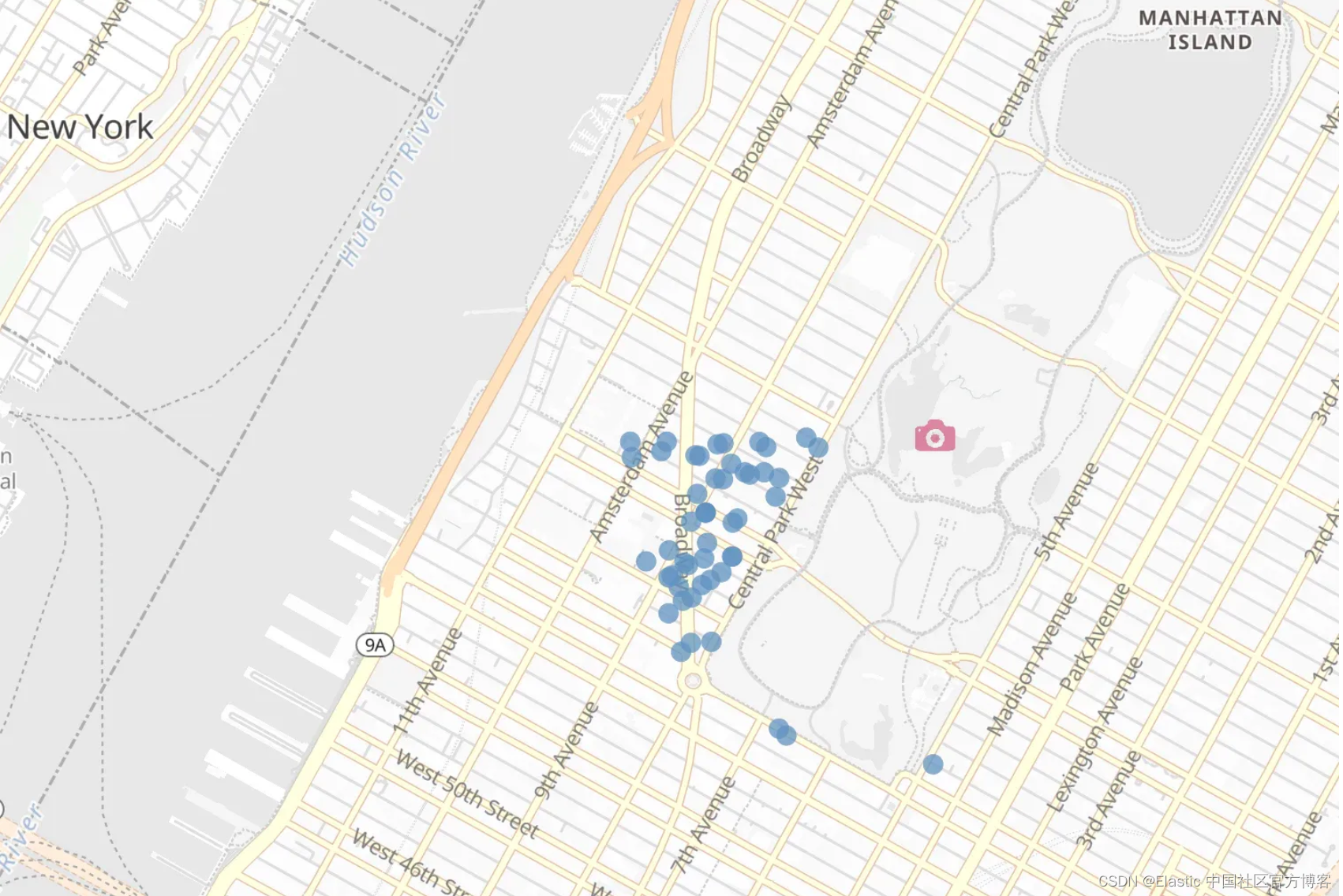
下一步是在 Elasticsearch 中运行 geo_distance 查询。首先来分析一下中央公园(Central Park)和帝国大厦(Empire State Building)相距多远。由于中央公园相当大并且包含许多景点,因此我们将使用 Bow Bridge 作为标志性景点。
我们将使用一个简单的术语查询来获取中央公园弓桥的地理位置,然后使用 _geo_distance 排序运行 geo_distance 查询来获取准确的距离。目前,geo_distance 查询始终需要距离参数。我们添加了一个术语来搜索帝国大厦,因为我们只对此感兴趣。
response = client.search(index="points-of-interest",size=1,query={"term": {"name": "central park bow bridge"}},
)for hit in response["hits"]["hits"]:# this should now be the central park bow bridge.print(f"Name: {hit['_source']['name']}\nLocation: {hit['_source']['location']}\n")response = client.search(index="points-of-interest",size=1,query={"bool": {"must": {"term": {"name": "empire state building"}},"filter": {"geo_distance": {"distance": "200km","location": {"lat": hit["_source"]["location"]["lat"],"lon": hit["_source"]["location"]["lon"],},}},}},sort=[{"_geo_distance": {"location": {"lat": hit["_source"]["location"]["lat"],"lon": hit["_source"]["location"]["lon"],},"unit": "km","distance_type": "plane","order": "asc",}}],)print(f"Distance to Empire State Building: {response['hits']['hits'][0]['sort'][0]} km")Name: central park bow bridge
Location: {'lon': -73.97178440451849, 'lat': 40.77577539823907}Distance to Empire State Building: 3.247504472145157 km与 ELSER 相比
现在我们得分最高的文档:
Score: 20.003891
Title: Gorgeous 1 Bedroom - Upper East Side Manhattan -
Location: {'lon': -73.95856, 'lat': 40.76701}
Document ID: AkgfEI8BHToGwgcUA6-7让我们使用 geo_distance 运行上面的计算。
response = client.search(index="points-of-interest",size=10,query={"bool": {"must": {"terms": {"name": ["central park bow bridge", "empire state building"]}},"filter": {"geo_distance": {"distance": "200km","location": {"lat": "40.76701", "lon": "-73.95856"},}},}},sort=[{"_geo_distance": {"location": {"lat": "40.76701", "lon": "-73.95856"},"unit": "km","distance_type": "plane","order": "asc",}}],
)for hit in response["hits"]["hits"]:print("Distance between AirBnB and", hit["_source"]["name"], hit["sort"][0], "km")Distance between AirBnB and central park bow bridge 1.4799179352060348 km
Distance between AirBnB and empire state building 3.0577584374128617 km分析
距离两个景点仅1.4公里和 3 公里。没有那么糟糕。让我们看看当我们创建一个包含帝国大厦和中央公园 Bow Bridge 的地理边界框时我们能发现什么。此外,我们将按照到中央公园 Bow Bridge 的距离对结果进行排序,然后按照到帝国大厦的距离进行排序。
response = client.search(index="points-of-interest",size=2,query={"terms": {"name": ["central park bow bridge", "empire state building"]}},
)# for easier access we store the locations in two variables
central = {}
empire = {}
for hit in response["hits"]["hits"]:hit = hit["_source"]if "central park bow bridge" in hit["name"]:central = hit["location"]elif "empire state building" in hit["name"]:empire = hit["location"]# Now we can run the geo_bounding_box query and sort it by the
# distance first to Central Park Bow Bridge
# and then to the Empire State Building.
response = client.search(index="airbnb-*",size=50,query={"geo_bounding_box": {"location": {"top_left": {"lat": central["lat"], "lon": empire["lon"]},"bottom_right": {"lat": empire["lat"], "lon": central["lon"]},}}},sort=[{"_geo_distance": {"location": {"lat": central["lat"], "lon": central["lon"]},"unit": "km","distance_type": "plane","order": "asc",}},{"_geo_distance": {"location": {"lat": empire["lat"], "lon": empire["lon"]},"unit": "km","distance_type": "plane","order": "asc",}},],
)for hit in response["hits"]["hits"]:print(f"Distance to Central Park Bow Bridge: {hit['sort'][0]} km")print(f"Distance to Empire State Building: {hit['sort'][1]} km")print(f"Title: {hit['_source']['name']}\nDocument ID: {hit['_id']}\n")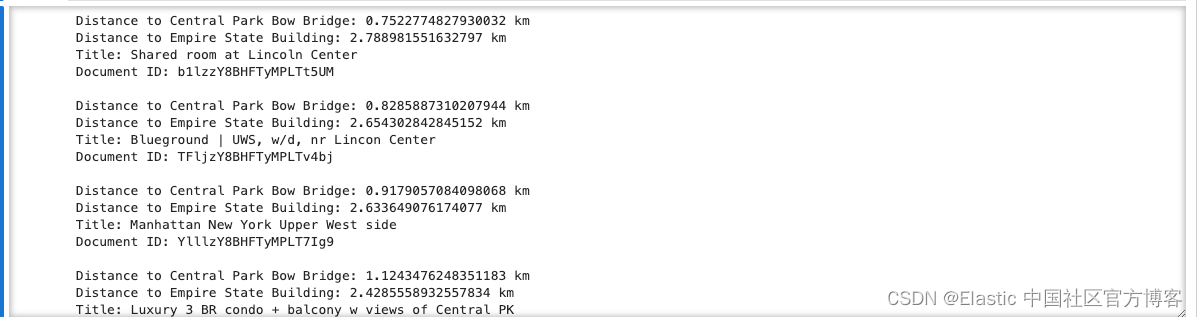
人工智能
现在让我们终于进入 AI 部分。所有这些都是设置和理解地理空间搜索的作用及其工作原理。还有很多东西有待发现。让我们将其连接到我们的 OpenAI 实例。在这里我们使用 OpenAI 资源。
from openai import OpenAIOPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
client = OpenAI(# This is the default and can be omittedapi_key=os.environ.get("OPENAI_API_KEY"),
)# Set API key
openai = OpenAI()# Let's do a test:
question = "What is the capital of France? Answer with just the capital city."answer = openai.chat.completions.create(messages=[{"role": "user","content": question,}],model="gpt-3.5-turbo",
)print(answer.choices[0].message.content)Paris上面显示出来正确的答案。它表明我们的 OpenAI 是工作正常的。
既然这可行了,我们确信我们是在正确的地方开始我们的问题。我们正在编写一个提示,强制 ChatGPT 创建 JSON 响应并从问题中提取信息。
question = """
As an expert in named entity recognition machine learning models, I will give you a sentence from which I would like you to extract what needs to be found (location, apartment, airbnb, sight, etc) near which location and the distance between them. The distance needs to be a number expressed in kilometers. I would like the result to be expressed in JSON with the following fields: "what", "near", "distance_in_km". Only return the JSON.
Here is the sentence: "Get me the closest AirBnB between 1 miles distance from the Empire State Building"
"""answer = openai.chat.completions.create(messages=[{"role": "user","content": question,}],model="gpt-3.5-turbo",
)
print(answer.choices[0].message.content)上面代码的输出为:
{"what": "AirBnB","near": "Empire State Building","distance_in_km": 1.6
}我们案例的答案如下
这是所需的输出:
{"what": "AirBnB","near": "Empire State Building","distance_in_km": 1610
}- 提取距离 - 完成(1 英里)
- 将距离转换为公里 - 完成 (1.6 公里)
- 提取位置 - 这应该是 “Empire State Building”,但从更一般的角度来说,我们应该认识到这是一个位置,因此我们制作一个称为单独的标签
json = answer.choices[0].message.content
# This now should contain just the json.
json = JSON.loads(json)# first let's grab the location of the `near` field
# it could be multiple locations, so we will search for all of them.
near = client.search(index="points-of-interest",size=100,query={"bool": {"must": {"terms": {"name": [json["near"].lower()]}}}},
)# we store just all of the geo-locations of the near locations.
near_location = []
sort = []for hit in near["hits"]["hits"]:near_location.append(hit["_source"]["location"])sort.append({"_geo_distance": {"location": {"lat": hit["_source"]["location"]["lat"],"lon": hit["_source"]["location"]["lon"],},"unit": "km","distance_type": "plane","order": "asc",}})query = {"geo_distance": {"distance": str(json["distance_in_km"]) + "km","location": {"lat": near_location[0]["lat"], "lon": near_location[0]["lon"]},}
}
# Now let's get all the AirBnBs `what` near the `near` location.
# We always use the first location as our primary reference.
airbnbs = client.search(index="airbnb-*", size=100, query=query, sort=sort)for hit in airbnbs["hits"]["hits"]:print(f"Distance to {json['near']}: {hit['sort'][0]} km")print(f"Title: {hit['_source']['name']}\nDocument ID: {hit['_id']}\n")上述命令运行的结果为:

现在,我们将地理空间搜索与 LLMs 结合起来。
所有的源码可以在地址:elasticsearch-labs/supporting-blog-content/geospatial-llm/09-geospatial-search.ipynb at main · liu-xiao-guo/elasticsearch-labs · GitHub 进行下载。
相关文章:
城市之旅:使用 LLM 和 Elasticsearch 简化地理空间搜索(二)
我们在之前的文章 “城市之旅:使用 LLM 和 Elasticsearch 简化地理空间搜索(一)”,在今天的练习中,我将使用本地部署来做那里面的 Jupyter notebook。 安装 Elasticsearch 及 Kibana 如果你还没有安装好自己的 Elasti…...

【知识点】 C++ 构造函数 参数类型为右值引用的模板函数
C 构造函数是一种特殊的成员函数,用于初始化类对象。C 中的构造函数主要分为以下几种类型: 默认构造函数(Default Constructor)参数化构造函数(Parameterized Constructor)拷贝构造函数(Copy C…...
华为云服务器-云容器引擎 CCE环境构建及项目部署
1、切换地区 2、搜索云容器引擎 CCE 3、购买集群 4、创建容器节点 通过漫长的等待(五分钟左右),由创建中变为运行中,则表明容器已经搭建成功 购买成功后,返回容器控制台界面 5、节点容器管理 6、创建redis工作负载 7、创建mysql工作负载 8、…...
Linux shell编程学习笔记57:lshw命令 获取cpu设备信息
0 前言 在Linux中,获取cpu信息的命令很多,除了我们已经研究的 cat /proc/cpuinfo、lscpu、nproc、hwinfo --cpu 命令,还有 lshw命令。 1 lshw命令的功能 lshw命令源自英文list hardware,即列出系统的硬件信息,这些硬…...

连山露【诗词】
连山露 雾隐黄山路,十步一松树。 树上惊松鼠,松子衔木屋。 松子青嫩芽,尖尖头探出。 卷挂白露珠,装映黄山雾。...

【Qt】Frame和Widget的区别
1. 这两个伙计有啥区别? 2. 区别 2.1 Frame继承自Widget,多了一些专有的功能 Frame Widget 2.2 Frame可以设置边框...

Python爬虫实战:从入门到精通
网络爬虫,又称为网络蜘蛛或爬虫,是一种自动浏览网页的程序,用于从互联网上收集信息。Python由于其简洁的语法和强大的库支持,成为开发网络爬虫的首选语言。 环境准备 Python安装 必要的库:requests, BeautifulSoup, Sc…...

堆算法详解
目录 堆 二叉堆的实现 二叉堆的插入 二叉堆取出堆顶 (extract/delete max) 优先对列 (priority queue) 堆的实现 语言中堆的实现 leadcode 题目堆应用 堆 堆是一种高效维护集合中最大或最小元素的数据结构。 大根堆:根节点最大的堆…...

6.6SSH的运用
ssh远程管理 ssh是一种安全通道协议,用来实现字符界面的远程登录。远程复制,远程文本传输。 ssh对通信双方的数据进行了加密 用户名和密码登录 密钥对认证方式(可以实现免密登录) ssh 22 网络层 传输层 数据传输的过程中是加密的 …...
MySQL-备份(三)
备份作用:保证数据的安全和完整。 一 备份类别 类别物理备份 xtrabackup逻辑备份mysqldump对象数据库物理文件数据库对象(如用户、表、存储过程等)可移植性差,不能恢复到不同版本mysql对象级备份,可移植性强占用空间占…...

结构体(1)<C语言>
导言 结构体是C语言中的一种自定义类型,它的值(成员变量)可以是多个,且这些值可以为不同类型,这也是和数组的主要区别,下面将介绍它的一些基本用法,包括:结构体的创建、结构体变量的…...

HW面试应急响应之场景题
(1)dns 报警就一定是感染了吗?怎么处理? 不一定。 引起dns报警的情况有:恶意软件感染,域名劫持,DNS欺骗,DDoS攻击等。 处理方法: 1、分析报警,查看报警类型、源IP地址、目标域名等…...
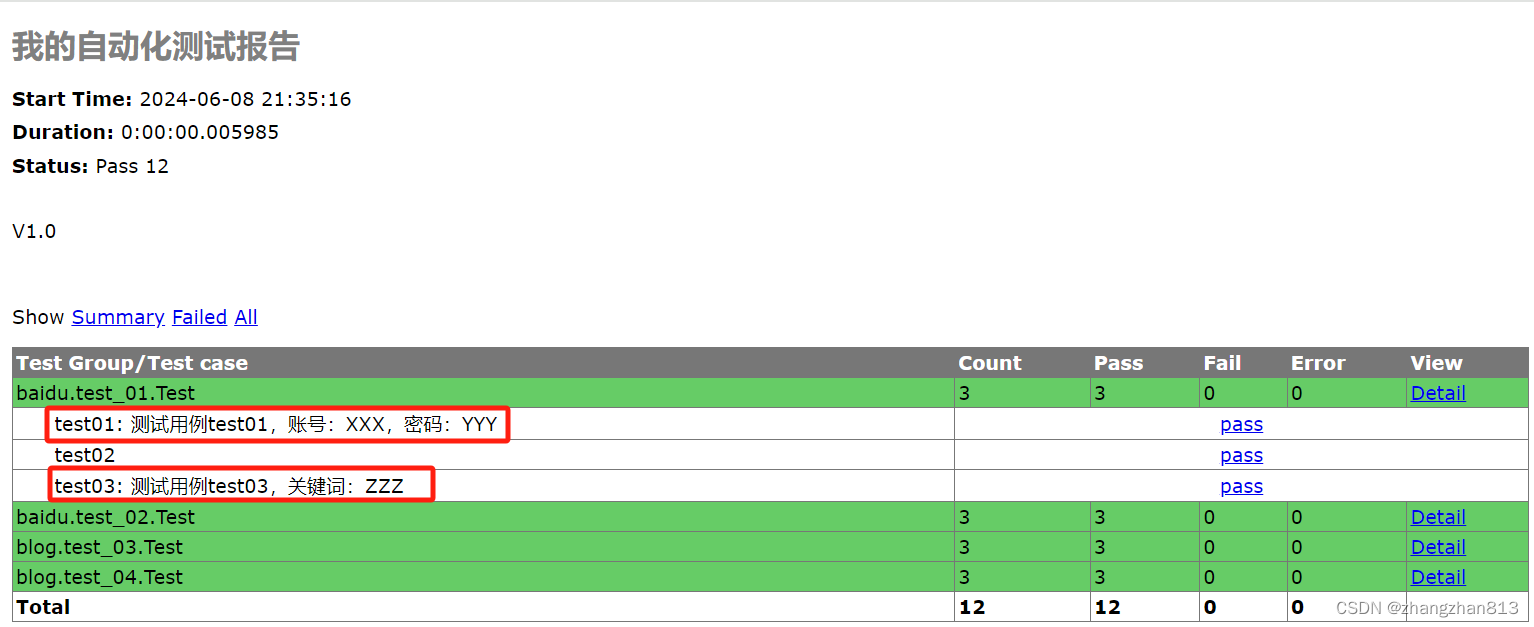
30-unittest生成测试报告(HTMLTestRunner插件)
批量执行完测试用例后,为了更好的展示测试报告,最好是生成HTML格式的。本文使用第三方HTMLTestRunner插件生成测试报告。 一、导入HTMLTestRunner模块 这个模块下载不能通过pip安装,只能下载后手动导入,下载地址是:ht…...
鸿蒙北向开发 IDE DevEco Studio 3.1 傻瓜式安装闭坑指南
首先下载 安装IDE 本体程序 DevEco Studio 下载链接 当前最新版本是3.1.1,下载windows版本的 下载下来后是一个压缩包, 解压解锁包后会出现一个exe安装程序 双击运行安装程序 一路 next ( 这里涉及安装文件目录,我因为C盘够大所以全部默认了,各位根据自己情况选择自己的文件…...

Oracle数据库面试题-9
81. 请解释Oracle数据库中的林业数据处理方法。 Oracle数据库中的林业数据处理 在Oracle数据库中处理林业数据涉及到存储、管理、分析和可视化与林业相关的数据。以下是林业数据处理的一些关键方面以及如何使用Oracle数据库进行示例性的SQL说明: 数据库设计&#…...
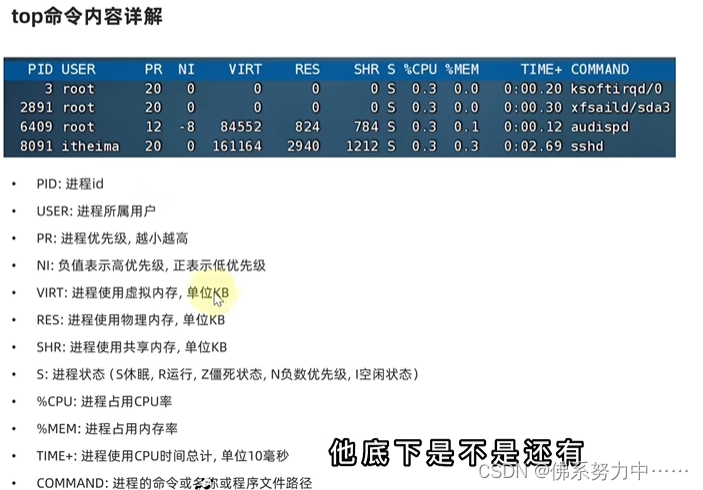
跟着小白学linux的基础命令
小白学习记录: 前情提要:Linux命令基础格式!查看 lsLinux 的7种文件类型及各颜色代表含义 进入指定目录 cd查看当前工作目录 pwd创建一个新的目录(文件夹) mkdir创建文件 touch查看文件内容 cat、more操作文件、文件夹- 复制 cp- 移动 mv- 删…...

2024-06-08 Unity 编辑器开发之编辑器拓展9 —— EditorUtility
文章目录 1 准备工作2 提示窗口2.1 双键窗口2.2 三键窗口2.3 进度条窗口 3 文件面板3.1 存储文件3.2 选择文件夹3.3 打开文件3.4 打开文件夹 4 其他内容4.1 压缩纹理4.2 查找对象依赖项 1 准备工作 创建脚本 “Lesson38Window.cs” 脚本,并将其放在 Editor 文件…...
Mac下删除系统自带输入法ABC,正解!
一、背景说明 MacOS 在 14.2 以下的系统存在中文输入法 BUG,会造成系统卡顿,出现彩虹圆圈。如果为了解决这个问题,有两种方法: 升级到最新的 14.5 系统使用第三方输入法 在使用第三方输入法的时候,会发现系统自带的 …...
redis学习路线
待更新… 一、nosql讲解 1. 为什么要用nosql? 用户的个人信息,社交网络,地理位置,自己产生的数据,日志等等爆发式增长!传统的关系型数据库已无法满足这些数据处理的要求,这时我们就需要使用N…...

数据库练习题
1行程和用户 表:Trips ----------------------- | Column Name | Type | ----------------------- | id | int | | client_id | int | | driver_id | int | | city_id | int | | status | enum | | request_at…...

Firefly开源中文大模型:指令微调、部署与领域适配实战
1. 项目概述:一个专为中文优化的开源大语言模型最近在开源社区里,Firefly(流萤)这个项目引起了我的注意。它不是一个通用框架,而是一个经过精心指令微调的大语言模型系列。简单来说,你可以把它理解为一个“…...

Super IO插件终极指南:5分钟掌握Blender文件处理革命
Super IO插件终极指南:5分钟掌握Blender文件处理革命 【免费下载链接】super_io blender addon for copy paste import / export 项目地址: https://gitcode.com/gh_mirrors/su/super_io Super IO是一款彻底改变Blender工作流程的革命性插件,它通…...

大模型评测实战指南:从基准测试到技术选型的全流程解析
1. 项目概述:为什么我们需要一个“大模型评测”清单?如果你在过去一年里深度参与过大语言模型(LLM)的应用开发、技术选型或者仅仅是技术追踪,你大概率会和我有同样的感受:“评测”这件事,变得越…...

FPGA生成SPWM的另一种思路:抛弃ROM,用DDS IP核与CORDIC算法实时生成正弦波
FPGA实时生成SPWM:基于DDS IP核与CORDIC算法的高效实现方案 在电力电子和电机控制领域,SPWM(正弦脉宽调制)技术因其优异的谐波特性和高效率而广受青睐。传统FPGA实现方案通常采用预存波形数据的ROM方法,虽然实现简单&a…...

小熊猫Dev-C++:5分钟搞定C++开发环境的终极解决方案 [特殊字符]
小熊猫Dev-C:5分钟搞定C开发环境的终极解决方案 🚀 【免费下载链接】Dev-CPP A greatly improved Dev-Cpp 项目地址: https://gitcode.com/gh_mirrors/dev/Dev-CPP 你是否曾为复杂的C开发环境配置而头疼?是否厌倦了臃肿的IDE占用大量系…...

别再只会拖模块了!手把手教你用Simulink封装打造自己的‘智能积木’
从零构建你的Simulink智能积木库:封装技术实战指南 在工程建模领域,Simulink就像数字世界的乐高积木箱,但大多数用户只停留在拖拽现成模块的初级阶段。真正的高手都掌握了一项核心技能——模块封装。这就像把一堆散乱的乐高零件组装成功能完整…...

PDF顺手编辑器工具
版式文件编辑器是一款支持PDF和OFD 文件处理工具,可在任何网络下使用。软件完全免费,无广告零弹窗,而且资源占用极小。软件广泛应用在党、政、军及企事业单位中,适合电子公文、证照、票据等领域,应用范围非常广。为啥用…...

Arm Development Studio 2023.1入门:构建Hello World项目
1. Arm Development Studio 2023.1入门指南:从零开始构建Hello World项目作为一名嵌入式开发工程师,我深知选择正确的开发工具对于项目成功的重要性。Arm Development Studio(简称Arm DS)作为Arm官方推出的集成开发环境࿰…...

Fooocus终极指南:零门槛AI图像生成神器,5分钟从安装到创作
Fooocus终极指南:零门槛AI图像生成神器,5分钟从安装到创作 【免费下载链接】Fooocus Focus on prompting and generating 项目地址: https://gitcode.com/GitHub_Trending/fo/Fooocus 在AI图像生成领域,复杂的技术参数和繁琐的调整过程…...
完全指南)
【LangChain】 输出解析器(Output Parsers)完全指南
LangChain 输出解析器(Output Parsers)完全指南2026 年最新版 | 覆盖所有内置解析器 完整代码示例一、什么是输出解析器 输出解析器是 LangChain 中连接"自由文本 LLM"与"结构化程序"的桥梁。LLM 天生输出自然语言,但应…...