Python数据分析I
目录
注:简单起见,下文中"df"均写为"表名","函数"均写为"HS","属性"均写为"SX","范围"均写为"FW"。
1.数据分析常用开源库
注释:
2.Pandas 数据结构
Series的创建
Series属性
3.DataFrame创建
4.文件加载
5.HS与SX
6.HS-初始化表格
7.HS-获取最值索引
8.SX-显示行列
9.HS/SX-索引
10.HS-计数
11.HS-最值中位数平均值标准差求和
12.HS-排序
13.HS-去重
14.应用
15.数据的保存和读取
16.HS-query查询
17.HS-isin
18.DF增列
19.DF删除
20.DF修改
21.Series/apply自定义函数
22.DataF/apply自定义函数
23.pandas/Mysql
注:简单起见,下文中"df"均写为"表名","函数"均写为"HS","属性"均写为"SX","范围"均写为"FW"。
1.数据分析常用开源库
Pandas
基于Numpy,特点高效的科学计算库,核心的数据对象是ndarray(n维数组)
Series 一列数据
DataFrame 二维表
绘图的库最基础的 Matplotlib
Pandas 有绘图的API,基于Matplotlib
Seaborn 基于Matplotlib
注释:
简单起见,下文中"df"均写为"表名","函数"均写为"HS","属性"均写为"SX","范围"均写为"FW"
2.Pandas 数据结构
Series的创建
pd.Series()
S大写
传入一个、两个参数
第一个参数就是数据, 也可以通过index = 指定行索引
如果不指定行索引, 会默认添加从0开始的索引
传入的数据可以是以下类型
numpy的ndarray
python 列表,元组,字典
传入的如果是字典,字典的key作为索引,Value就是数据
一列Series数据类型必须一致的
如果既有字符串,又有数字,会默认是字符串类型 Object
Series属性
s.shape # 形状 描述Series有几行 返回一个元组 s.values # Series的值 默认ndarray类型 s.index # Series的索引, 如果手动指定, 就是一个ndarray类型, 如果是自动生成 rangeIndex()
3.DataFrame创建
# 定义一个字典
dict_data ={'id':[1,2,3],'name':['张三','李四','王五'],'age':[18,20,22]
}
# 储存在df中
df = pd.DataFrame(dict_data)
df4.文件加载
# 不创建也可以加载文件 df = pd.read_csv('D:/Yuanman/day01/02_代码/data/scientists.csv') df = pd.read_csv('D:/Yuanman/day01/02_代码/data/scientists.csv',encoding='gbk') df
5.HS与SX
红色m:HS,用()
紫色p:SX,乄||[]

6.HS-初始化表格
加载数据之后,做具体的业务处理之前,一般固定的套路
head() info() describe()
从脑袋上取前5条,也可指定条数
表名.head()
从尾巴上取后5条,也可指定条数
表名.tail()
字段有哪些,有没有空值
表名.info()
看数据的分布情况
表名.describe()
查看所有数据分布情况
表名.describe(include='all')
查看有几个唯一值
表名.unique()
7.HS-获取最值索引
# 返回最大值的下标
表名['列名'].argmax()
# 返回最小值的下标
表名['列名'].argmin()
# 返回最大值的索引值
表名['列名'].idxmax()
# 返回最小值的索引值
表名['列名'].idxmin()8.SX-显示行列
# 显示几行几列
表名.shape
# 仅显示行
表名.shape[0]
# 仅显示列
表名.shape[1]
# 显示所有值
表名.values9.HS/SX-索引
# 行索引FW及步长
表名.index
# 显示列索引及类型
表名.columns
# 把某一列数据作为索引,加inplace=True替换原索引
表名.set_index('列名',inplace=True)
# 重置所有为从0开始的整数
表名.reset_index()
# 将其行索引修改为对应的列值
表名.index = df2['列名']
# 将其列索引(字段)修改为对应值
表名.columns =['列1','列2']
# 单独修改某行某列的索引,注意rename和replace类似,如果旧值没有找到,不会报错
表名.rename(index={0:'行索引名'},columns={'旧列名':'新列名'})10.HS-计数
# 计算所有列的数据数,也可以单独计算某列
表名.count()
# 分组计数,查看每个分组的数量并降序,也可以单独计算某列
表名.value_counts(ascending=False)11.HS-最值中位数平均值标准差求和
# 计算所有列的最大值,也可以单独计算某列
表名.max()
# 计算所有列的最小值,也可以单独计算某列
表名.min()
# 计算所有列的平均值,也可以单独计算某列
表名.mean()
# 计算所有列的中位数,也可以单独计算某列
表名.median()
# 标准差(方差开根号,反映了数据的离散程度,也可以单独计算某列)
s1.std()
# 对文件某一列或某多列进行求和,0是对列求和,默认是0
表名['字段'].sum()
# 1是对行求和,此时列字段至少两个
表名[['字段1','字段2']].sum()12.HS-排序
# 按照某列排序,True升/False降,不指定显示列则为全部
表名['显示列名'].sort_values(by='筛选字段名',ascending=False)
# 根据某字段排序后显示其他字段
名称 = 表名[['字段1','字段2']].sort_values(by='字段2',ascending=False)13.HS-去重
# 去重,假删
表名.drop_duplicates()
# 去重,真删(False假True真)
表名.drop_duplicates(inplace=True)subset 传入列名的列表,用来做重复判断的条件
keep = 默认是first 满足重复条件的数据,保留第一次出现的,还可以选last 保留最后一次出现的
ignore_index = 默认是False 去重后会保留原来的索引,改成True之后,会重新给从0开始的索引
inplace 替换
表名.drop_duplicates(subset=['字段1','字段2'])
表名.drop_duplicates(subset=['字段1','字段2'],keep='last',inplace=True)
表名.drop_duplicates(subset=['字段1','字段2'],keep='last',ignore_index=True)14.应用
# select * 表名[直接就条件] # 获取数据的一列或多列 表名['列名'] 表名[['列1,列2']]# 通过下标切片方式获取部分行,[初始索引:终止索引:步长],不包括终止索引(左闭右开) 表名[a:b:c]# 相当于sql中的where筛选,多个条件需要用()括起来,位运算连接(and:&,or:|) 表名['显示列'][表名['列名']=='数值']# 根据条件增新列 表名['新列名']=表名['数据列1']-表名['数据列2']# 拿出行数据,用列展示,[]内是行列名,不是编号 表名.loc[0] # 所有行加一列 表名.loc[:,'列名'] # 0到3(左闭右闭) 表名.loc[:3] # 列名也可以加:指定列FW 表名.loc[:3,:'列名'] 表名.loc[:3,['列1','列2']] # 逗号前也可以作条件筛选 表名.loc[df['区域']=='望京租房',:'价格']# 输出指定索引值的数据,[]内是编号,不是行列名,其他同上 新表名 = 带索引的表.iloc[0]['输出列名']
15.数据的保存和读取
# 创建数据文件
import pandas as pd
data =[
[1,'张三','1999-3-10',18],
[2,'李四','2002-3-10',15],
[3,'王五','1990-3-10',33],
[4,'隔璇老王','1983-3-10',40]
]
df = pd.DataFrame(data,columns=['id','name','birthday','age'])
# 将数据存储为表格文件
df.to_excel('test2.xlsx',sheet_name='student',index=False)
# 读取该文件
pd.read_excel('test2.xlsx',sheet_name='student')
# 将数据存储为csv文件
df.to_csv('test2.csv',index=False)
# 指定分隔符
df.to_csv('test3.csv',index=False,sep='\t')
# 读取该文件
pd.read_csv('test2.csv')16.HS-query查询
# 引号外单内双
表名.query('区域=="望京租房"').head()
表名.query('区域 in ["望京租房","回龙观租房"]')['单独取该列']
# 层层递进
新表名 = 表名.query('区域 in ["望京租房","回龙观租房"]')
新新表名 = 新表名.query('朝向 in [“东”,"南”]')['单独取该列']
# 层层递进合成(类似于子查询)
表名.query('区域 in ["望京租房","回龙观租房"]').query('朝向 in ["东","南"]')['单独取该列']
# 上式也能这么写
表名.query('区域 in ["望京租房","回龙观租房"] and 朝向 in ["东","南"]')['单独取该列']17.HS-isin
# 筛选是否为指定数据,输出True和False
表名['区域'].isin(['望京租房','回尨观租房'])
# 再传给df,输出所有字段
表名[表名['区域'].isin(['望京租房','回尨观租房'])]
# 多条件筛选(&或|)
表名[(表名['区域'].isin(['望京租房','回尨观租房'])) & (表名['朝向'].isin(['西南 东北','南 北']))]18.DF增列
# 添加新列,只能在最后一列
表名['新列名']=['','',...]
# insert新增列,可指定位置
表名.insert(列索引,column='字段名',value='字段内容')
# 在某列后插入一列
所有列名 = 表.columns.tolist() # 首先获取现有列名
某列的索引 = 所有列名.index('某列') # 找到budget列的索引位置
所有列名.insert(某列的索引 + 1, '新列名') # 在budget列之后插入利润列,更新所有列名
表名 = 表名[columns] # 重置列顺序来更新表19.DF删除
# 通过 df.drop(labels=,axis=,inplace=)方法删除行列数据
# labels: 行索引值或列名
# axis: 删除行->0或index,删除列->1或columns,默认0
# inplace: True或False,是否在原数据上删除,默认 False
表名.drop(0)
表名.drop('列名',axis=1,inplace=True)20.DF修改
# 直接改
表名.loc[0,'列名']= 数据
# 改多个
表名['列名']=[数据1,数据2,数据3,数据4,数据5]
# 修改指定数
表名.replace(to_replace='旧值',value='新值')
# 将某列更改后替换旧列并select* (将新列赋值给原列)
名称 = 表名['列名'].mean()
表名['列名']=表名['列名'].fillna(名称)21.Series/apply自定义函数
def func(x):print(x)if x=='天通苑租房':return '昌平区'else:return x
# 遍历区域这一列,每遍历一条数据就会调用一次func把每个值传递给func函数,func函数的返回值作为apply的结果, 返回的还是Series
s = df['区域'].apply(func)# apply 可以传递出了series值其它参数,但是传参必须从第二个参数开始
df_head3 = df.head().copy()
def func(x,arg1,arg2):print(x)if x=='天通苑租房':return arg1else:return arg2
df_head3['区域'].apply(func,args=['昌平区','其它区'])22.DataF/apply自定义函数
df.apply(func,axis=默认值0)
默认会传入每一列的series对象,如果数据有5列,func就会被调用5次,每次传入一列series对象
axis=1会传入每一行的Series对象,如果数据有10行,func就会被调用10次,每次传入一行的series对象
# 返回每一行它的价格/它的面积,但用列展示
def func1(x):return x['价格']/x['面积']
df_head3 = df.head().copy()
df_head3.apply(func1,axis=1)df.apply() 传入自定义函数的时候,函数也可以接受额外的参数,传参args一定是列表
# 返回每一行如果区域为‘天通···’则给价格加个数,但用列展示
def func2(x,arg1):# print(x)# print("============") 分隔一下if x['区域']=='天通苑租房':x['价格']=x['价格']+arg1return x
df_head3.apply(func2,axis=1,args=[2000])23.pandas/Mysql
(1)导包创建连接
from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://root:root@localhost:3306/tabledata?charset=utf8') # 'mysql+pymysql://用户名:密码@mysql服务IP地址:3306/数据库名字?charset=utf8'(2)写入数据到Mysql
student.to_sql('student', con=engine, if_exists='append', index=False)(3)从Mysql读取数据
pd.read_sql(sql='student', con=engine.connect(),columns=['id','name','age'])
相关文章:
Python数据分析I
目录 注:简单起见,下文中"df"均写为"表名","函数"均写为"HS","属性"均写为"SX","范围"均写为"FW"。 1.数据分析常用开源库 注释…...
Qt5/6使用SqlServer用户连接操作SqlServer数据库
网上下载SQLServer2022express版数据库,这里没啥可说的,随你喜欢,也可以下载Develop版本。安装完后,我们可以直接连接尝试, 不过一般来说,还是下载SQLServer管理工具来连接数据更加方便。 所以直接下载ssms, 我在用的时候,一开始只能用Windows身份登录。 所以首先,我…...

[经验] 场效应管是如何发挥作用的 #知识分享#学习方法#职场发展
场效应管是如何发挥作用的 在现代电子技术领域,场效应管(MOSFET)是一种重要的半导体元器件。它的作用非常广泛,例如在集成电路中扮演着关键的角色。在本文中,我们将详细探讨场效应管的作用及其在实际应用中的意义。 简…...
数据挖掘--分类
数据挖掘--引论 数据挖掘--认识数据 数据挖掘--数据预处理 数据挖掘--数据仓库与联机分析处理 数据挖掘--挖掘频繁模式、关联和相关性:基本概念和方法 数据挖掘--分类 数据挖掘--聚类分析:基本概念和方法 基本概念 决策树归纳 决策树:决策树是一…...

数据结构篇其六-串
数据结构—串 前置说明 由于学习Java面向对象语言走火入魔,试图在C语言中模拟实现面向对象设计。里面加入了大量的函数指针配合结构体来模拟类中的成员方法 故此篇,亦可称: 面向对象的C语言程序设计 用C语言实现串这种数据结构,并将它应用到…...

队列和栈的实现
本节讲解的队列与栈,如果你对之前的线性和链式结构顺利掌握了,那么下边的队列和栈就小菜一碟了。因为我们会用前两节讲到的东西来实现队列和栈。 之所以放到一起讲是因为这两个东西很类似,队列是先进先出结构(FIFO, first in first out)&…...

lua vm 五: upvalue
前言 在 lua vm 中,upvalue 是一个重要的数据结构。upvalue 以一种高效的方式实现了词法作用域,使得函数能成为 lua 中的第一类值,也因其高效的设计,导致在实现上有点复杂。 函数 (proto) upvalue 构成了闭包(closu…...

React Native中集成ArcGIS以显示地图、渲染自定义图层和获取地理信息数据
在您的数据采集上传的应用中集成ArcGIS以显示地图、渲染自定义图层和获取地理信息数据是一项常见需求。下面是如何实现这些功能的详细指南,包括具体步骤和示例代码。 1. 显示地图 原生开发 Android: 使用ArcGIS Android SDK。您需要在AndroidManifest…...

java中的异常-异常处理(try、catch、finally、throw、throws)+自定义异常
一、概述 1、java程序员在编写程序时提前编写好对异常的处理程序,在程序发生异常时就可以执行预先设定好的处理程序,处理程序执行完之后,可以继续向后执行后面的程序 2、异常处理程序是在程序执行出现异常时才执行的 二、5个关键字 1、tr…...
深入了解反射
newInstance 可访问性限制: newInstance()方法只能调用无参的公共构造函数。如果类没有无参公共构造函数,那么newInstance()方法将无法使用。 异常处理: newInstance()方法在创建对象时会抛出受检异常InstantiationException和IllegalAcces…...
5、搭建前端项目
5.1 使用vite vue搭建 win r 打开终端 切换到你想要搭建的盘 npm init vitelatest跟着以下步骤取名即可 cd fullStackBlognpm installnpm run dev默认在 http://localhost:5173/ 下启动了 5.2 用vscode打开项目并安装需要的插件 1、删除多余的 HelloWorld.vue 文件 2、安装…...

LLM之Agent初探
Agent是什么? Agent一词起源于拉丁语中的Agere,意思是“to do”。在LLM语境下,Agent可以理解为在某种能自主理解、规划决策、执行复杂任务的智能体。 Agent并非ChatGPT升级版,它不仅告诉你“如何做”,更会帮你去做。…...

目录穿越漏洞CVE-2018-7171复现 又学到一招小技巧!!!!
还是半夜睡不着,打开靶机开始操作。今天看了文件下载和目录穿越漏洞想结合以及防御方法。半夜来进行操作一波。复现一下漏洞,这个网上的文章页比较的少!!! 开始操作起来!!! 进入到页…...
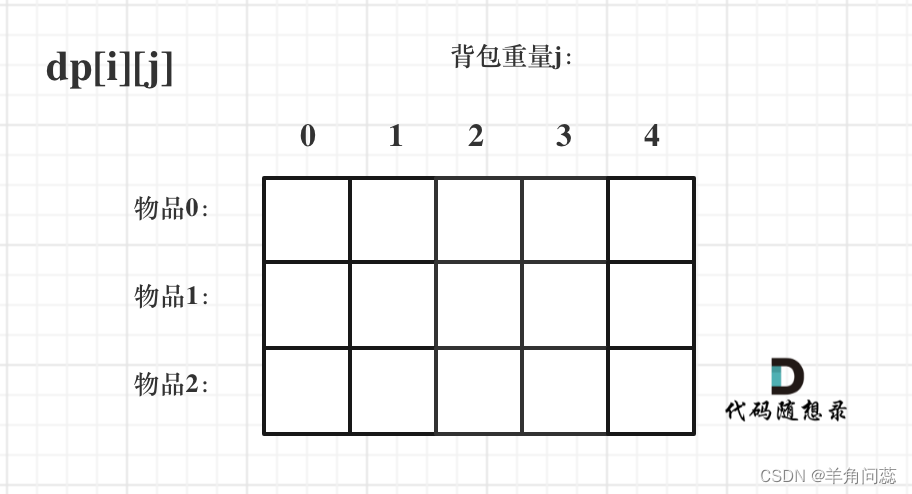
代码随想录算法训练营day41
题目:01背包理论基础、416. 分割等和子集 参考链接:代码随想录 动态规划:01背包理论基础 思路:01背包是所有背包问题的基础,第一次看到比较懵,完全不知道dp数据怎么设置。具体分析还是dp五部曲ÿ…...

从0~1开发财务软件
1.获取图形验证码接口 功能要求 1、随机生成6位字符 2、将字符生成base64位格式的图片,返回给前端 3、将生成的字符存储到redis中,用匿名身份id(clientId)作为key,验证码作为value。 clientId通过/login/getClien…...
Python实现连连看9
(2)标识选中的图片 在判断出玩家选中的是哪一张图片之后,接下来就可以标识选中的图片了,即在该选中的图片外围画矩形。代码如下所示。 FIRSTCLICK True #FIRSTCLICK是全局变量 if(click_col>0 and click_row>0) and \(no…...

项目验收总体计划书(实际项目验收原件参考Word)
测试目标:确保项目的需求分析说明书中的所有功能需求都已实现,且能正常运行;确保项目的业务流程符合用户和产品设计要求;确保项目的界面美观、风格一致、易学习、易操作、易理解。 软件全套文档过去进主页。 一、 前言 ࿰…...

C++基础与深度解析 | 异常处理 | 枚举与联合 | 嵌套类与局部类 | 嵌套名字空间与匿名名字空间 | 位域与volatile关键字
文章目录 一、异常处理二、枚举与联合三、嵌套类与局部类四、嵌套名字空间与匿名名字空间五、位域与volatile关键字 一、异常处理 异常处理用于处理程序在调用过程中的非正常行为。 传统的处理方法:传返回值表示函数调用是否正常结束。 例如,返回 0 表示…...

番外篇 | 利用华为2023最新Gold-YOLO中的Gatherand-Distribute对特征融合模块进行改进
前言:Hello大家好,我是小哥谈。论文提出一种改进的信息融合机制Gather-and-Distribute (GD) ,通过全局融合多层特征并将全局信息注入高层,以提高YOLO系列模型的信息融合能力和检测性能。通过引入MAE-style预训练方法,进一步提高模型的准确性。🌈 目录 🚀1.论文解…...

python记录之字符串
在Python中,字符串是一种非常常见且重要的数据类型,用于存储文本信息。下面,我们将对Python字符串进行深入的讲解,包括其基本操作、常见方法、格式化以及高级特性。 1. 字符串的创建 在Python中,字符串可以通过单引号…...

别再手动填Token了!用Knife4j的OAuth2配置,一键搞定接口文档自动化认证
告别手动Token时代:Knife4j与OAuth2的自动化认证实战 每次调试API都要复制粘贴Token的日子该结束了。作为后端开发者,我们花了大量时间在接口文档和认证流程之间来回切换——这不仅是效率问题,更是一种思维中断。想象一下,当你的微…...

Wan2.2-I2V-A14B极限测试:高分辨率与长视频生成的稳定性挑战
Wan2.2-I2V-A14B极限测试:高分辨率与长视频生成的稳定性挑战 1. 开场白:当AI视频生成遇上极限挑战 最近在测试Wan2.2-I2V-A14B模型时,我突发奇想:这个在常规场景下表现优秀的视频生成模型,如果被推到极限会怎样&…...

全网资源嗅探下载神器:轻松获取视频音频资源的终极指南
全网资源嗅探下载神器:轻松获取视频音频资源的终极指南 【免费下载链接】res-downloader 资源下载器、网络资源嗅探,支持微信视频号下载、网页抖音无水印下载、网页快手无水印视频下载、酷狗音乐下载等网络资源拦截下载! 项目地址: https://gitcode.co…...

跨平台网络资源嗅探下载工具:一站式解决多媒体内容获取难题
跨平台网络资源嗅探下载工具:一站式解决多媒体内容获取难题 【免费下载链接】res-downloader 资源下载器、网络资源嗅探,支持微信视频号下载、网页抖音无水印下载、网页快手无水印视频下载、酷狗音乐下载等网络资源拦截下载! 项目地址: https://gitcod…...
)
手把手教你用STM32实现BLDC电机的SPWM控制(附代码调试心得)
STM32实战:无刷直流电机SPWM控制全解析与代码优化指南 从理论到实践:BLDC电机控制的核心逻辑 第一次接触无刷直流电机(BLDC)控制时,我被它优雅的工作原理所吸引——没有电刷的火花和磨损,却能实现高效的能量转换。在工业自动化、无…...

RTX 4090D专属镜像应用场景:短视频MCN机构批量生成口播视频生产系统
RTX 4090D专属镜像应用场景:短视频MCN机构批量生成口播视频生产系统 1. 短视频行业的痛点与解决方案 短视频MCN机构每天面临的最大挑战之一,就是如何高效生产大量高质量的口播视频内容。传统制作流程通常需要: 租用专业摄影棚聘请主播录制…...

三层架构破解小红书数据采集难题:Appium+MitmProxy双引擎实战
三层架构破解小红书数据采集难题:AppiumMitmProxy双引擎实战 【免费下载链接】XiaohongshuSpider 小红书爬取 项目地址: https://gitcode.com/gh_mirrors/xia/XiaohongshuSpider 在小红书内容生态快速发展的今天,数据工程师和产品分析师面临着内容…...

告别“人工智障”!OpenClaw + 大模型:打造真正能“看懂、想通、干成”的机械臂智能体
写在前面 在机器人圈子里,有个心照不宣的痛点:机械臂越来越便宜,但让它“听话”却越来越难。 传统的示教编程(Teaching Pendant)太慢,改个产品就得重教一遍;视觉定位(Vision Guided&…...

建行江门市分行:量身定制金融策 陈皮产业绽新姿
“前期承包土地、购买柑苗已投入大量资金,后续还要设法购买化肥。”眼看资金接续不上,前期投入面临打水漂,流动资金短缺让江门新会某陈皮庄园负责人老李一筹莫展。 获悉老李困境后,建行广东江门分行网点客户经理驱车前往果园实地走…...

别再死记硬背了!用Python手把手教你实现数据库闭包自动计算器
用Python实现数据库闭包计算器:从理论到实战的自动化工具 闭包计算是数据库原理中的核心算法,但传统教材往往停留在抽象描述和手工演算阶段。作为曾经被各种箭头符号和递归推导折磨过的开发者,我决定用Python打造一个能自动计算闭包并可视化步…...