【CS.SE】使用 docker pull confluentinc/cp-kafka 的全面指南
文章目录
- 1 引言
- 2 准备工作
- 2.1 安装 Docker
- 2.1.1 在 Linux 上安装 Docker
- 2.1.2 在 macOS 上安装 Docker
- 2.1.3 在 Windows 上安装 Docker
- 2.2 验证 Docker 安装
- 3 拉取 confluentinc/cp-kafka Docker 镜像
- 3.1 拉取镜像
- 3.2 验证镜像
- 4 运行 Kafka 容器
- 4.1 启动 ZooKeeper
- 4.2 启动 Kafka
- 4.3 验证 Kafka 启动
- 5 配置 Kafka
- 5.1 配置文件
- 5.2 环境变量
- 6 常见问题解决
- 6.1 无法连接 ZooKeeper
- 6.1.1 问题描述
- 6.1.2 解决方法
- 6.2 Kafka 端口冲突
- 6.2.1 问题描述
- 6.2.2 解决方法
- 6.3 内存不足
- 6.3.1 问题描述
- 6.3.2 解决方法
- 7 总结
- References
1 引言

Apache Kafka 是一种分布式流处理平台,由于其高吞吐量、可扩展性和容错性,广泛应用于实时数据处理和数据管道。Confluent 是 Kafka 的主要贡献者之一,并提供了一个包含 Kafka 及其生态系统的 Docker 镜像 confluentinc/cp-kafka。本文将全面介绍如何使用 Docker 拉取并运行 confluentinc/cp-kafka 镜像,包括准备工作、实际操作、配置及常见问题解决。
Docker 是一个开源的平台,允许开发者自动化部署应用程序在容器中。容器是一种轻量级、可移植、自包含的环境,可以在任何地方运行。
Kafka 是一个分布式流处理平台,最初由 LinkedIn 开发,后捐赠给 Apache 软件基金会。Kafka 用于构建实时数据管道和流应用,提供发布和订阅记录流、存储记录流及处理记录流的功能。
2 准备工作
在拉取并运行 Kafka Docker 镜像之前,需要确保系统中已安装 Docker。如果尚未安装 Docker,请按照以下步骤进行安装。
2.1 安装 Docker
2.1.1 在 Linux 上安装 Docker
sudo apt-get update
sudo apt-get install -y apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt-get update
sudo apt-get install -y docker-ce
2.1.2 在 macOS 上安装 Docker
macOS 用户可以通过 Docker Desktop for Mac 进行安装。
2.1.3 在 Windows 上安装 Docker
Windows 用户可以通过 Docker Desktop for Windows 进行安装。
2.2 验证 Docker 安装
安装完成后,运行以下命令验证 Docker 是否成功安装:
$ docker --version
Docker version 24.0.5, build ced0996
3 拉取 confluentinc/cp-kafka Docker 镜像
3.1 拉取镜像
使用以下命令从 Docker Hub 拉取 confluentinc/cp-kafka 镜像:
docker pull confluentinc/cp-kafka
3.2 验证镜像
拉取完成后,使用以下命令验证镜像是否成功拉取:
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
confluentinc/cp-kafka latest abc12345def 2 days ago 1.29GB4 运行 Kafka 容器
4.1 启动 ZooKeeper
Kafka 依赖于 ZooKeeper 进行分布式协调。首先需要启动一个 ZooKeeper 实例:
docker run -d --name zookeeper -p 2181:2181 confluentinc/cp-zookeeper
4.2 启动 Kafka
使用以下命令启动 Kafka 实例:
docker run -d --name kafka -p 9092:9092 --link zookeeper:zookeeper \-e KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 \-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092 \confluentinc/cp-kafka
4.3 验证 Kafka 启动
使用以下命令检查 Kafka 容器的日志,确保 Kafka 成功启动:
$ docker logs kafka
[2022-01-01 00:00:00,000] INFO [KafkaServer id=1] started (kafka.server.KafkaServer)
5 配置 Kafka
5.1 配置文件
Kafka 的配置文件位于 /etc/kafka 目录中,可以通过挂载配置文件对其进行自定义。例如:
docker run -d --name kafka -p 9092:9092 --link zookeeper:zookeeper \-v /path/to/your/config/server.properties:/etc/kafka/server.properties \confluentinc/cp-kafka
5.2 环境变量
Kafka 也可以通过环境变量进行配置,常见的配置项包括:
KAFKA_ZOOKEEPER_CONNECT:指定 ZooKeeper 的连接地址。KAFKA_ADVERTISED_LISTENERS:指定 Kafka 的监听地址。
更多配置项可以参考 Confluent Kafka Docker 文档。
6 常见问题解决
6.1 无法连接 ZooKeeper
6.1.1 问题描述
Kafka 启动时无法连接到 ZooKeeper,可能导致 Kafka 启动失败。
6.1.2 解决方法
- 确认 ZooKeeper 容器是否正常启动,并且在正确的端口上监听。
- 检查
KAFKA_ZOOKEEPER_CONNECT环境变量是否配置正确。
6.2 Kafka 端口冲突
6.2.1 问题描述
Kafka 使用的默认端口 9092 被其他进程占用,导致 Kafka 启动失败。
6.2.2 解决方法
- 确认 9092 端口没有被其他进程占用。
- 如果被占用,可以修改 Kafka 的监听端口:
docker run -d --name kafka -p 9093:9092 --link zookeeper:zookeeper \-e KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 \-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9093 \confluentinc/cp-kafka
6.3 内存不足
6.3.1 问题描述
如果系统内存不足,可能导致 Kafka 容器启动失败或性能下降。
6.3.2 解决方法
- 确认系统有足够的可用内存。
- 可以通过 Docker 的
--memory参数限制容器的内存使用:
docker run -d --name kafka -p 9092:9092 --link zookeeper:zookeeper \-e KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 \-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092 \--memory 4g \confluentinc/cp-kafka
7 总结
本文详细介绍了使用 Docker 拉取并运行 confluentinc/cp-kafka 镜像的步骤,包括准备工作、实际操作、配置及常见问题解决。通过这些步骤,可在本地快速搭建一个 Kafka 环境,用于开发和测试。
References
1000.07.CS.SE.2-软件开发流程-容器化与Docker-案例-Kafka容器-Created: 2024-06-08.Saturday18:54
相关文章:
【CS.SE】使用 docker pull confluentinc/cp-kafka 的全面指南
文章目录 1 引言2 准备工作2.1 安装 Docker2.1.1 在 Linux 上安装 Docker2.1.2 在 macOS 上安装 Docker2.1.3 在 Windows 上安装 Docker 2.2 验证 Docker 安装 3 拉取 confluentinc/cp-kafka Docker 镜像3.1 拉取镜像3.2 验证镜像 4 运行 Kafka 容器4.1 启动 ZooKeeper4.2 启动…...

STM32快速入门(ADC数模转换)
STM32快速入门(ADC数模转换) 前言 ADC数模转换存在的意义就是将一些温度传感器、各自数据传感器产生的模拟信号转换成方便识别和计算的数字信号。 导航 图24 通用定时器框图: 图片截取自STM32 F1XX中文参考手册。还是以框图为中心&#x…...
Linux环境在非root用户中搭建(java-tomcat-redis)
注: 本文在内网(离线)环境,堡垒机中搭建,服务器不同可能有所差异,仅供参考 本文安装JDK-20.0.1版本,apache-tomcat-10.1.10版本,redis-6.2.15版本 本文服务器IP假设:192.168.88.133 root用户创建子用户并…...
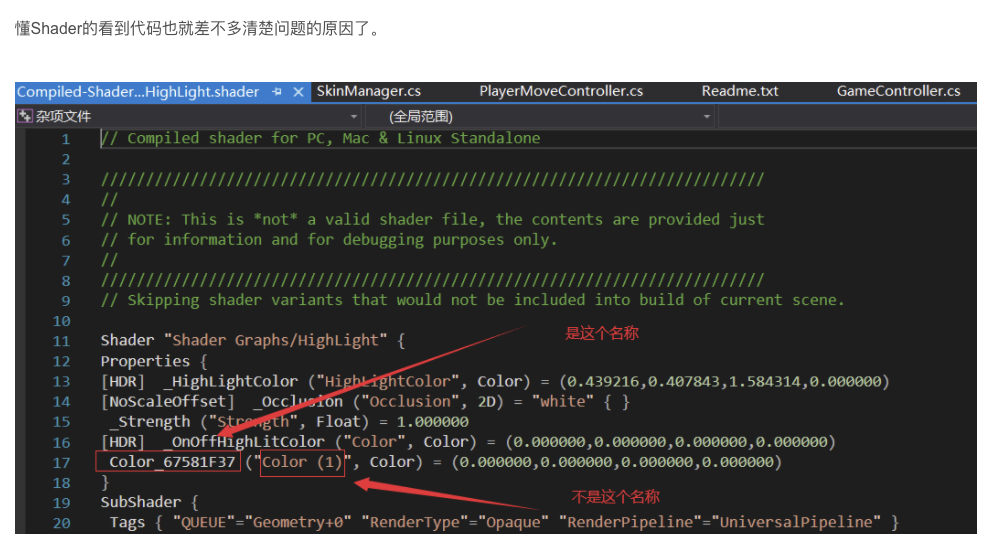
Unity 之 代码修改材质球贴图
Unity 之 代码修改材质球贴图 代码修改Shader:ShaderGraph:材质球包含属性 代码修改 meshRenderer.material.SetTexture("_Emission", texture);Shader: ShaderGraph: 材质球包含属性 materials[k].HasProperty("…...
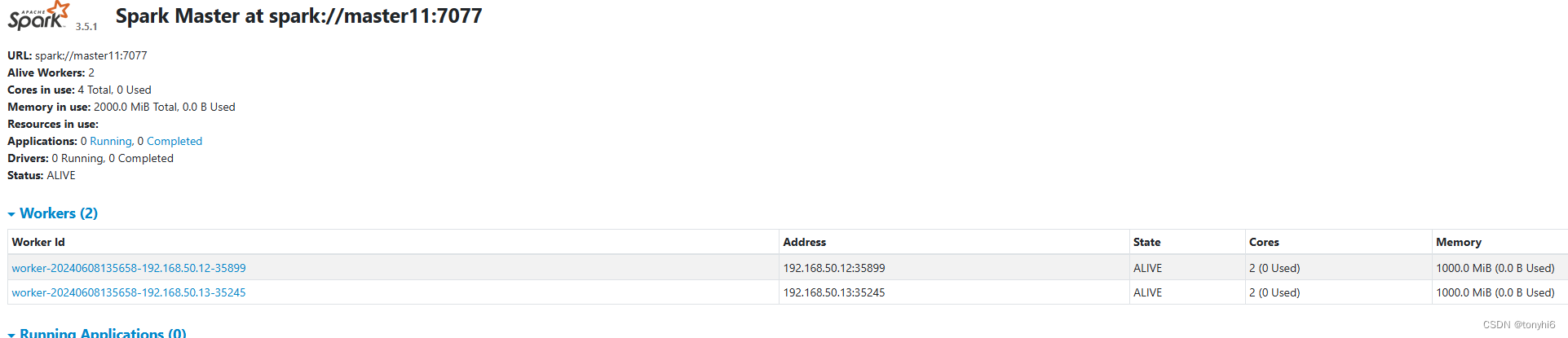
spark-3.5.1+Hadoop 3.4.0+Hive4.0 分布式集群 安装配置
Hadoop安装参考: Hadoop 3.4.0HBase2.5.8ZooKeeper3.8.4Hive4.0Sqoop 分布式高可用集群部署安装 大数据系列二-CSDN博客 一 下载:Downloads | Apache Spark 1 下载Maven – Welcome to Apache Maven # maven安装及配置教程 wget https://dlcdn.apache.org/maven/maven-3/3.8…...

Matlab实现GWO-CNN-LSTM-Mutilhead-Att灰狼算法卷积长短期记忆神经网络融合多头注意力机制预测 SCI顶级优化
数据预处理:准备和清理数据,包括数据的加载、特征提取、归一化等。 GWO (灰狼算法) 的实现:根据灰狼算法的原理和公式,编写 MATLAB 代码来初始化灰狼群体、计算适应度函数、更新位置等。 CNN (卷积神经网络) 的构建:使…...

RTKLIB之RTKPLOT画图工具
开源工具RTKLIB在业内如雷贯耳,其中的RTKPLOT最近正在学习,发现其功能之强大,前所未见,打开了新的思路。 使用思博伦GSS7000卫星导航模拟器,PosApp软件仿真一个载具位置 1,RTKPLOT支持DUT 串口直接输出的NMEA数据并…...

本地部署 RAGFlow
本地部署 RAGFlow 0. RAGFlow 是什么?1. 安装 wsl-ubuntu2. (可选)配置清华大学软件源3. 系统更新和安装构建工具4. 安装 Miniconda35. 安装 CUDA Toolkit6. 安装 git lfs7. 配置 Hugging Face 的缓存路径8. 配置 vm.max_map_count9. 安装 Docker Engine10. 安装 nginx11. 本地…...

php常用数据库操作
文章目录 PHP操作1. mysqli_connect() 连接数据库2. mysqli_close() 关闭数据库3. mysqli_num_rows 查询结果集中的行数4. mysqli_select_db 选择数据库的函数5. mysqli_query 常规的插入查找等6. header( )7.防止 sql 注入 PHP操作 1. mysqli_connect() 连接数据库 2. mysql…...
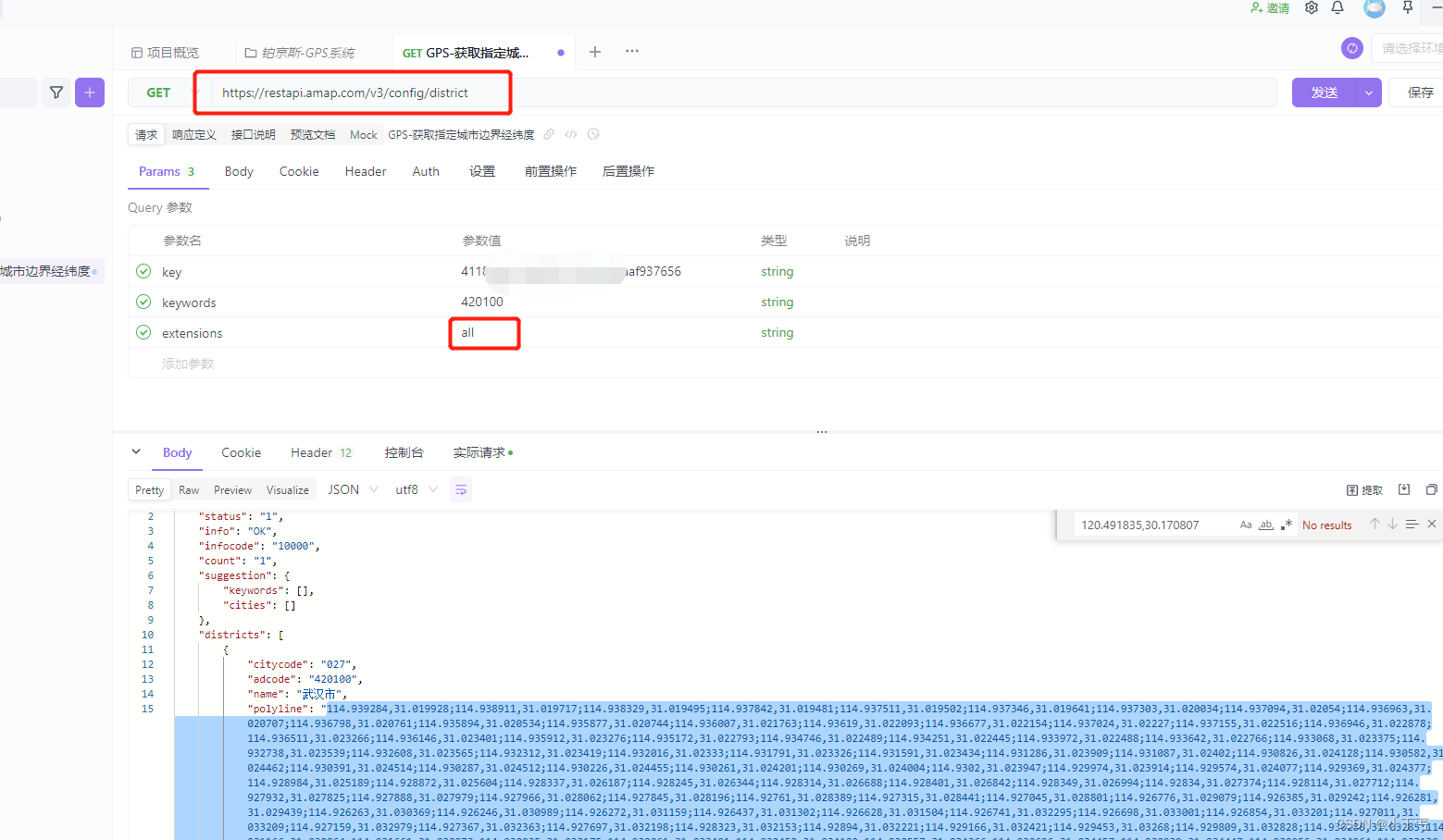
判断经纬度是否在某个城市内
一、从高德获取指定城市边界经纬度信息 通过apifox操作: 二、引入第三方jar包: maven地址:https://mvnrepository.com/ maven依赖: <dependency><groupId>org.locationtech.jts</groupId><artifactId>…...
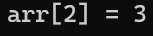
Java——数组排序和查找
一、排序介绍 1、排序的概念 排序是将多个数据按照指定的顺序进行排列的过程。 2、排序的种类 排序可以分为两大类:内部排序和外部排序。 3、内部排序和外部排序 1)内部排序 内部排序是指数据在内存中进行排序,适用于数据量较小的情况…...

Flutter中防抖动和节流策略
什么是防抖和节流? 函数节流(throttle)与 函数防抖(debounce)都是为了限制函数的执行频次,以优化函数触发频率过高导致的响应速度跟不上触发频率,出现延迟,假死或卡顿的现象 是应对频…...

设计模式-中介者(调停者)模式(行为型)
中介者模式 中介者模式是一种行为型模式,又叫调停者模式,它是为了解决多个对象之间,多个类之间通信的复杂性,定义一个中介者对象来封装一些列对象之间的交互,使各个对象之间不同持有对方的引用就可以实现交互…...

HC-05蓝牙模块配置连接和使用
文章目录 1. 前期准备 2. 进入AT模式 3. 电脑串口配置 4. 配置过程 5. 主从机蓝牙连接 6. 蓝牙模块HC-05和电脑连接 1. 前期准备 首先需要准备一个USB转TTL连接器,电脑安装一个串口助手,然后按照下面的连接方式将其相连。 VCCVCCGNDGNDRXDTXDTXD…...

云上小知识:企业选择云服务的小Tips
企业在选择云服务模式时,应综合考虑以下几个关键因素: 1. 业务需求与场景 企业需要根据自身的业务特点和需求来选择合适的云服务模式。例如,如果企业的用户分布广泛,需要跨地域提供服务,那么公有云可能是更好的选择。…...

生成式人工智能 - Stable Diffusion 都使用了哪些技术?
一、Stable Diffusion简述 1、简述 Stable Diffusion在2022年8月开源,是由慕尼黑大学的CompVis研究团队开发的生成式人工神经网络。该项目由初创公司StabilityAI、CompVis和Runway合作开发,并得到了EleutherAI和LAION的支持。截至2022年10月,StabilityAI已筹集了1.01亿美元…...

React的useState的基础使用
import {useState} from react // 1.调用useState添加状态变量 // count 是新增的状态变量 // setCount 修改状态变量的方法 // 2.添加点击事件回调 // userState实现计数实例import {useState} from react// 使用组件 function App() {// 1.调用useState添加状态变量// coun…...
接口自动化Requests+Pytest基础实现
目录 1. 数据库以及数据库操作1.1 概念1.2 分类1.3 作用 2 python操作数据库的相关实现2.1 背景2.2 相关实现 3. pymysql基础3.1 整个流程3.2 案例3.3 Pymysql工具类封装 4 事务4.1 案例4.2 事务概念4.3 事务特征 5. requests库5.1 概念5.2 角色定位5.3 安装5.4 校验5.5 reques…...

深入解析Kafka消息传递的可靠性保证机制
深入解析Kafka消息传递的可靠性保证机制 Kafka在设计上提供了不同层次的消息传递保证,包括at most once(至多一次)、at least once(至少一次)和exactly once(精确一次)。每种保证通过不同的机制…...

jEasyUI 设置排序
jEasyUI 设置排序 jEasyUI 是一个基于 jQuery 的框架,用于轻松构建交互式的 Web 应用程序。它提供了一系列的 UI 组件,如表格(datagrid)、树(tree)、下拉列表(combobox)等,这些组件可以帮助开发者快速实现复杂的界面功能。在本文中,我们将重点讨论如何在 jEasyUI 中…...

Moveit2 automaticaddison mycobot_ros2 代码讲解
github地址 https://github.com/automaticaddison/mycobot_ros2/tree/jazzy 一.mycobot_moveit_config 1.moveit2基本控制 在mycobot_moveit_config下面创建config/mycobot_280 initial_positions.yaml 定义了机械臂所有关节的初始位置 joint_limits.yaml 定义每个关节的…...

AI智能体集成Active Directory:统一身份管理与安全沙箱实践
1. 项目概述:在Active Directory中为AI智能体安家最近在折腾一个挺有意思的项目,叫agent-directory。简单来说,它能让你的AI智能体(Agent)像公司里的员工一样,在Windows Active Directory(AD&am…...

凌扬微优势代理 LY3508 4.2V/1A充电/1.6A驱动 全桥马达驱动控制芯片 ESOP8 技术解析
在电动牙刷、智能垃圾桶等单节锂电池供电的马达类产品中,需要一款集成锂电池充电管理和全桥马达驱动的芯片,以实现电机正反转、刹车控制,并简化外围电路设计。LY3508是一款集成了锂电池充电管理模块、全桥马达驱动模块、续流二极管和逻辑控制…...

IP第一次作业
...

如何高效解决Unity游戏插件框架BepInEx启动失败:完整指南与最佳实践
如何高效解决Unity游戏插件框架BepInEx启动失败:完整指南与最佳实践 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx作为Unity游戏最强大的插件框架之一&#x…...

AwesomeQRCode源码阅读笔记:深入理解二维码渲染核心技术
AwesomeQRCode源码阅读笔记:深入理解二维码渲染核心技术 【免费下载链接】AwesomeQRCode An awesome QR code generator for Android. 项目地址: https://gitcode.com/gh_mirrors/aw/AwesomeQRCode 想要为你的Android应用添加炫酷的二维码生成功能吗…...

Ascend NPU高效无损压缩技术解析与优化
1. 项目概述:Ascend NPU上的高效无损压缩技术在AI模型规模爆炸式增长的今天,模型权重的存储与传输已成为系统瓶颈。以Qwen3-32B模型为例,其65.6GB的权重文件在分布式训练中会产生显著的通信开销。传统CPU/GPU压缩方案如ZipNN(1.5GB/s)和NV-Bi…...
Translumo:游戏与视频实时屏幕翻译的终极解决方案
Translumo:游戏与视频实时屏幕翻译的终极解决方案 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否曾因语…...

CANN/ops-math Signbit算子文档
aclnnSignbit 【免费下载链接】ops-math 本项目是CANN提供的数学类基础计算算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-math 📄 查看源码 产品支持情况 产品是否支持Ascend 950PR/Ascend 950DT√Atlas A3 训练系…...

Paris注解处理器深度解析:从@Style到@StyleableChild的完整实现原理
Paris注解处理器深度解析:从Style到StyleableChild的完整实现原理 【免费下载链接】paris Define and apply styles to Android views programmatically 项目地址: https://gitcode.com/gh_mirrors/pa/paris Paris是一款专为Android开发者设计的样式注解处理…...