R语言数据探索和分析23-公共物品问卷分析
第一次实验使用最基本的公共物品游戏,不外加其他的treatment。班里的学生4人一组,一共44/4=11组。一共玩20个回合的公共物品游戏。每回合给15秒做决定的时间。第十回合后,给大家放一个几分钟的“爱心”视频(链接如下),然后继续完成剩下的10回合。
修改列名
把“来源”,“来源详情”,“来自IP” 这几个无关变量删除。重新命名前面几个变量,新变量对应名称为:'序号','提交答卷时间','所用时间','性别'。把代表组号的那一个变量的名字重新命名为“team_num”。把后面所有回合的变量名重新命名为“round1”, round2,....round20。以及最后两个测算风险偏好和模糊偏好的变量分别重新命名为risk_atti 和 ambiguity_atti。
数据和完整代码
# 读取数据
data <- read.csv("datar.csv", header = TRUE, stringsAsFactors = FALSE, fileEncoding = "GBK")
datahead(data,5)# 删除无关变量
data <- data[, !names(data) %in% c("来源", "来源详情", "来自IP")]# 重新命名变量
colnames(data) <- c("序号", "提交答卷时间", "所用时间", "性别", "team_num", paste0("round", 1:20), "risk_atti", "ambiguity_atti")names(data)
head(data,5)
变量赋值
data$gender <- ifelse(data$性别 == "男", 1, 0)
head(data,5)看“爱心”视频前,大家前10回合的平均贡献值是多少?看“爱心”视频后,大家后10回合的平均贡献值是多少?
# 提取前10回合和后10回合的数据
before_video <- data[, 7:16]
after_video <- data[, 17:26]# 计算平均贡献值
avg_contribution_before <- rowMeans(before_video, na.rm = TRUE)
avg_contribution_after <- rowMeans(after_video, na.rm = TRUE)# 输出结果
avg_contribution_before <- mean(avg_contribution_before, na.rm = TRUE)
avg_contribution_after <- mean(avg_contribution_after, na.rm = TRUE)cat("看“爱心”视频前,大家前10回合的平均贡献值是:", avg_contribution_before, "\n")
cat("看“爱心”视频后,大家后10回合的平均贡献值是:", avg_contribution_after, "\n")
# 导入绘图库
library(ggplot2)# 创建数据框
contribution <- data.frame(Time_Period = c("Before Video", "After Video"),Average_Contribution = c(avg_contribution_before, avg_contribution_after)
)# 绘制柱状图,并标上数据值
ggplot(contribution, aes(x = Time_Period, y = Average_Contribution, fill = Time_Period)) +geom_bar(stat = "identity") +geom_text(aes(label = round(Average_Contribution, 2)), vjust = -0.5) + # 标上数据值labs(title = "Average Contribution Before and After Watching 'Love' Video",x = "Time Period",y = "Average Contribution") +theme_minimal() +theme(legend.position = "none")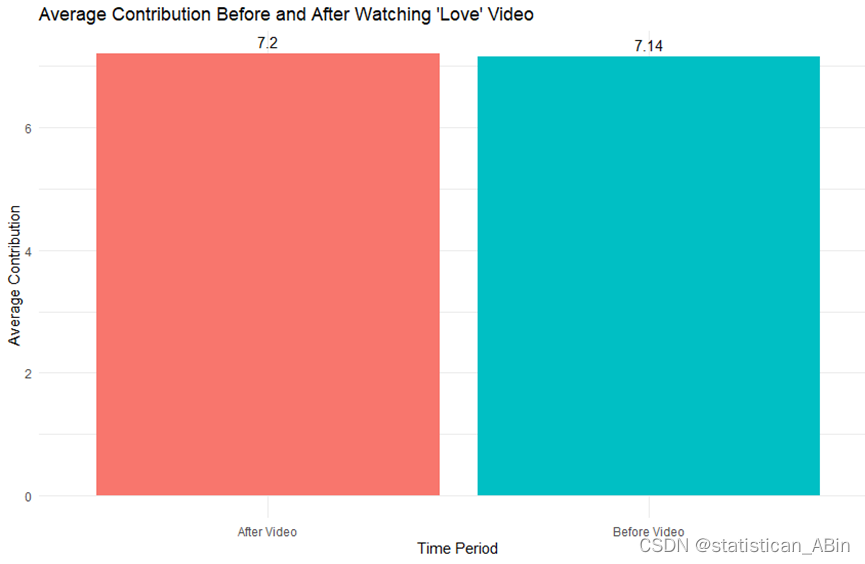
从结果和可视化都可以看出,看“爱心”视频前,大家前10回合的平均贡献值是7.138889,看“爱心”视频后,大家后10回合的平均贡献值是7.2
异常值检测
# 找出所用时间超过800秒的同学
outliers_800 <- data[data$'所用时间' == '808秒', ]
outliers_800
# 找出所用时间为314秒的同学
outliers_314 <- data[data$'所用时间' == '314秒', ]
# 找出所用时间为74秒的同学
outliers_74 <- data[data$'所用时间' == '74秒', ]
# 将outliers合并
outliers <- rbind(outliers_800, outliers_314, outliers_74)
outliers
# 从数据中删除outliers
data <- data[!(rownames(data) %in% rownames(outliers)), ]# 重新计算Part 1
before_video <- data[, 7:16]
after_video <- data[, 17:26]avg_contribution_before <- rowMeans(before_video, na.rm = TRUE)
avg_contribution_after <- rowMeans(after_video, na.rm = TRUE)avg_contribution_before <- mean(avg_contribution_before, na.rm = TRUE)
avg_contribution_after <- mean(avg_contribution_after, na.rm = TRUE)删除了异常值之后,看“爱心”视频前,大家前10回合的平均贡献值是6.751515,看“爱心”视频后,大家后10回合的平均贡献值是7.490909
女同学的前十和后十回合的平均贡献值是多少?男生呢?
# 按性别分组
female_data <- subset(data, 性别 == "女")
male_data <- subset(data, 性别 == "男")# 提取前十回合和后十回合的数据
before_video_female <- female_data[, 7:16]
before_video_female
after_video_female <- female_data[, 17:26]
before_video_male <- male_data[, 7:16]
after_video_male <- male_data[, 17:26]# 计算平均贡献值
avg_contribution_before_female <- rowMeans(before_video_female, na.rm = TRUE)
avg_contribution_after_female <- rowMeans(after_video_female, na.rm = TRUE)
avg_contribution_before_male <- rowMeans(before_video_male, na.rm = TRUE)
avg_contribution_after_male <- rowMeans(after_video_male, na.rm = TRUE)# 计算平均贡献值的平均值
avg_contribution_before_female <- mean(avg_contribution_before_female, na.rm = TRUE)
avg_contribution_after_female <- mean(avg_contribution_after_female, na.rm = TRUE)
avg_contribution_before_male <- mean(avg_contribution_before_male, na.rm = TRUE)
avg_contribution_after_male <- mean(avg_contribution_after_male, na.rm = TRUE)女同学的前十回合的平均贡献值是5.266667,女同学的后十回合的平均贡献值是6.3,男同学的前十回合的平均贡献值是7.308333,男同学的后十回合的平均贡献值是7.9375
为了探索不同风险偏好的同学在观看“爱心”视频前后的平均贡献值,我们可以按照之前的步骤进行数据处理和分析。首先,我们需要将风险偏好转换为风险偏好等级,然后按照这些等级将数据分组,分别计算他们在观看视频前后的平均贡献值。
# 根据映射关系将风险偏好转换为相应的风险偏好等级
risk_attitude_levels <- c("highly risk loving", "very risk loving", "risk loving", "risk neutral", "slightly risk averse", "risk averse", "very risk averse", "highly risk averse", "stay in bed", "stay in bed")data$risk_attitude_level <- risk_attitude_levels[data$risk_atti]# 按风险偏好等级分组
risk_attitude_groups <- split(data, data$risk_attitude_level)# 计算每个组在观看视频前后的平均贡献值
avg_contribution_before <- sapply(risk_attitude_groups, function(group) {avg_before <- mean(rowMeans(group[, 7:16], na.rm = TRUE), na.rm = TRUE)return(avg_before)
})avg_contribution_after <- sapply(risk_attitude_groups, function(group) {avg_after <- mean(rowMeans(group[, 17:26], na.rm = TRUE), na.rm = TRUE)return(avg_after)
})# 合并结果为数据框
avg_contribution <- data.frame(Risk_Attitude = names(avg_contribution_before),Avg_Contribution_Before = avg_contribution_before,Avg_Contribution_After = avg_contribution_after)# 输出结果
print(avg_contribution)
高风险偏好者(highly risk loving)在观看视频前的平均贡献值较高,但在观看视频后降低到较低水平,这可能表明他们更倾向于冒险和自我利益,并且对于公共物品的贡献程度受到外部因素影响较大。风险厌恶者(risk averse)在观看视频前后的平均贡献值有所增加,这可能表明他们更加稳健和谨慎,但在观看视频后表现出更多的愿意参与公共物品的贡献。风险中性者(risk neutral)在观看视频前后的平均贡献值保持相对稳定,这可能表明他们的决策相对稳定,不受外部因素的影响较大。风险略微厌恶者(slightly risk averse)和非常风险厌恶者(very risk averse)在观看视频前后的平均贡献值变化较小,这可能表明他们的行为相对稳定,不受外部因素的影响较大。保持在床上者(stay in bed)在观看视频前后的平均贡献值有所增加,这可能表明他们对于外部因素的反应较弱,但在观看视频后表现出更多的愿意参与公共物品的贡献。
综上所述,不同风险偏好等级的同学在观看视频前后的行为表现有所不同,这可能受到个体风险态度和外部环境的影响。针对这些不同特点,我们可以制定更具针对性的鼓励措施,以促进更多人为公共物品做出贡献。
创作不易,希望大家多点赞关注评论!!!
相关文章:
R语言数据探索和分析23-公共物品问卷分析
第一次实验使用最基本的公共物品游戏,不外加其他的treatment。班里的学生4人一组,一共44/411组。一共玩20个回合的公共物品游戏。每回合给15秒做决定的时间。第十回合后,给大家放一个几分钟的“爱心”视频(链接如下)&a…...

Webix前端界面框架:深度解析与应用实践
Webix前端界面框架:深度解析与应用实践 Webix,作为一款功能强大的前端界面框架,近年来在开发社区中逐渐崭露头角。本文将从四个方面、五个方面、六个方面和七个方面,深入剖析Webix的特性、优势、应用实践以及面临的挑战ÿ…...

Qt基于SQLite数据库的增删查改demo
一、效果展示 在Qt创建如图UI界面,主要包括“查询”、“添加”、“删除”、“更新”,四个功能模块。 查询:从数据库中查找所有数据的所有内容,并显示在左边的QListWidget控件上。 添加:在右边的QLineEdit标签上输入需…...

新书推荐:2.2.4 第11练:消息循环
/*------------------------------------------------------------------------ 011 编程达人win32 API每日一练 第11个例子GetMessage.c:消息循环 MSG结构 GetMessage函数 TranslateMessage函数:将虚拟键消息转换为字符消息 DispatchMessage函数…...

MASA:匹配一切、分割一切、跟踪一切
文章目录 摘要1、引言2、相关工作2.1、学习实例级关联2.2、Segment and Track Anything 模型 3、方法3.1、预备知识:SAM3.2、通过分割任何事物来匹配任何事物3.2.1、MASA流程3.2.2、MASA适配器3.2.3、推理 4、实验4.1、实验设置4.2、与最先进技术的比较4.3、消融研究…...

Websocket前端传参:深度解析与实战应用
Websocket前端传参:深度解析与实战应用 在现代Web开发中,Websocket作为一种双向通信协议,已经广泛应用于实时数据传输场景。前端传参作为Websocket通信的重要组成部分,其正确性和高效性直接影响到应用的性能和用户体验。本文将深…...

造假高手——faker
在测试写好的代码时通常需要用到一些测试数据,大量的真实数据有时候很难获取,如果手动制造测试数据又过于繁重无聊,显得不够优雅,今天我们介绍的faker这个轮子可以完美的解决这个问题。faker是一个用于生成各种类型假数据的库&…...
—— PostCSS(v8.4.38):CSS 转换工具)
前端工程化工具系列(十二)—— PostCSS(v8.4.38):CSS 转换工具
PostCSS 是转换 CSS 语法的工具。它提供 API 来对 CSS 文件进行分析和修改它的规则。 PostCSS 本身并不能直接使用,主要是使用基于 PostCSS 编写的插件。 1 安装 pnpm add -D postcss-import postcss-nested postcss-preset-env cssnano2 配置 在项目根目录下创…...

Scanpy(3)单细胞数据分析常规流程
单细胞数据分析常规流程 面对高效快速的要求上,使用R分析数据越来越困难,转战Python分析,我们通过scanpy官网去学习如何分析单细胞下游常规分析。 数据3k PBMC来自健康的志愿者,可从10x Genomics免费获得。在linux系统上,可以取消注释并运行以下操作来下载和解压缩数据。…...

【Stable Diffusion】(基础篇二)—— Stable Diffusion图形界面介绍和基本使用流程
本系列笔记主要参考B站nenly同学的视频教程,传送门:B站第一套系统的AI绘画课!零基础学会Stable Diffusion,这绝对是你看过的最容易上手的AI绘画教程 | SD WebUI 保姆级攻略_哔哩哔哩_bilibili 在上一篇博客中,我们成功…...
OpenCv之简单的人脸识别项目(动态处理页面)
人脸识别 准备九、动态处理页面1.导入所需的包2.设置窗口2.1定义窗口外观和大小2.2设置窗口背景2.2.1设置背景图片2.2.2创建label控件 3.定义视频处理脚本4.定义相机抓取脚本5.定义关闭窗口的函数6.按钮设计6.1视频处理按钮6.2相机抓取按钮6.3返回按钮 7.定义关键函数8.动态处理…...
【Linux】进程间通信
目录 一、进程间通信概念 二、进程间通信的发展 三、进程间通信的分类 四、管道 4.1 什么是管道 4.2 匿名管道 4.2 基于匿名管道设计进程池 4.3 命名管道 4.4 用命名管道实现server&client通信 五、system V共享内存 5.1 system V共享内存的引入 5.2 共享内存的…...

UI与前端:揭秘两者的微妙差异
UI与前端:揭秘两者的微妙差异 在数字化时代的浪潮中,UI设计和前端开发已成为塑造用户体验的两大核心力量。然而,这两者之间究竟有何区别?本文将深入剖析UI设计与前端开发的四个方面、五个方面、六个方面和七个方面的差异…...
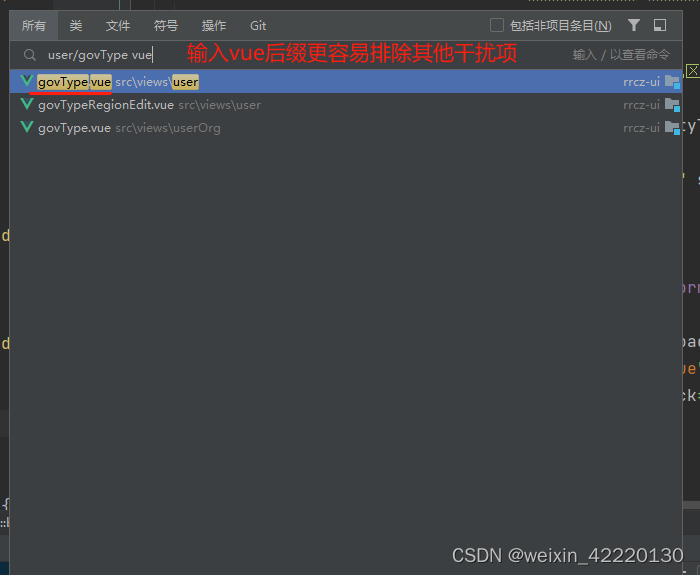
idea如何根据路径快速在项目中快速打卡该页面
在idea项目中使用快捷键shift根据路径快速找到该文件并打卡 双击shift(连续按两下shift) -粘贴文件路径-鼠标左键点击选中跳转的路径 自动进入该路径页面 例如:我的实例路径为src/views/user/govType.vue 输入src/views/user/govType或加vue后缀src/views/user/go…...

探索成功者的特质——俞敏洪的观点启示
在人生的舞台上,我们常常对成功者充满好奇与敬仰,试图探寻他们成功的奥秘。俞敏洪指出,成功者都具备七个特质,而这些特质与家庭背景和大学的好坏并无直接关系。让我们深入剖析这七个特质,或许能从中获得对我们自身成长…...

MCU的环形FIFO
fifo.h #ifndef __FIFO_H #define __FIFO_H#include "main.h"#define RINGBUFF_LEN (500) //定义最大接收字节数 500typedef struct {uint16_t Head; // 头指针 指向可读起始地址 每读一个,数字1uint16_t Tail; // 尾指针 指…...
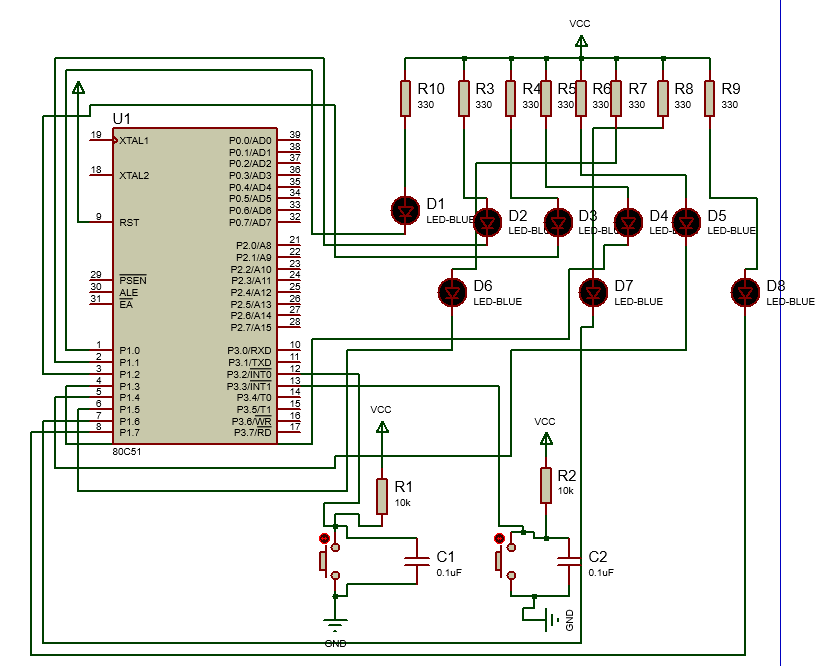
使用proteus仿真51单片机的流水灯实现
proteus介绍: proteus是一个十分便捷的用于电路仿真的软件,可以用于实现电路的设计、仿真、调试等。并且可以在对应的代码编辑区域,使用代码实现电路功能的仿真。 汇编语言介绍: 百度百科介绍如下: 汇编语言是培养…...

【漏洞复现】Apache OFBiz 路径遍历导致RCE漏洞(CVE-2024-36104)
0x01 产品简介 Apache OFBiz是一个电子商务平台,用于构建大中型企业级、跨平台、跨数据库、跨应用服务器的多层、分布式电子商务类应用系统。是美国阿帕奇(Apache)基金会的一套企业资源计划(ERP)系统。该系统提供了一整套基于Java的Web应用程序组件和工具。 0x02 …...

数据库表中创建字段查询出来却为NULL?
起因: 今天新创建了一张表,其中一个字段命名为"word_num"带下划线,我在前端页面怎么也查询不出来word_num的值,后来在后端接口处打印了一下数据库查询出来的数据,发现这个字段一直为NULL,然后我就想到是不是…...

缓存方法返回值
1. 业务需求 前端用户查询数据时,数据查询缓慢耗费时间; 基于缓存中间件实现缓存方法返回值:实现流程用户第一次查询时在数据库查询,并将查询的返回值存储在缓存中间件中,在缓存有效期内前端用户再次查询时,从缓存中间件缓存获取 2. 基于Redis实现 参考1 2.1 简单实现 引入…...

开源技能管理工具rei-skills:从零构建个人技术能力图谱
1. 项目概述与核心价值 最近在折腾个人知识库和技能树管理,发现了一个挺有意思的开源项目 rootcastleco/rei-skills 。这项目名字乍一看有点神秘, rei 在日语里是“零”或“灵”的意思,结合 skills ,我理解它想表达的是一种…...

从SolarWinds事件看供应链攻击与网络防御责任重构
1. 从SolarWinds事件看现代网络防御的“责任困境”2020年底曝光的SolarWinds供应链攻击,无疑给全球网络安全界投下了一颗震撼弹。攻击者通过入侵IT监控软件巨头SolarWinds的软件构建系统,在其Orion平台软件更新包中植入后门,导致全球超过1800…...

为什么92%的用户调不出正宗120胶片感?揭秘Midjourney底层色彩映射矩阵与胶片光谱响应偏差
更多请点击: https://intelliparadigm.com 第一章:胶片感的视觉本质与数字复现困境 胶片感并非单一参数可定义的视觉效果,而是由卤化银晶体随机分布、显影化学反应非线性响应、颗粒噪点的空间相关性以及动态范围压缩特性共同构成的模拟物理现…...

CMU开源localPlanner避坑指南:从仿真到实车,ROS小车部署的5个关键步骤
CMU开源localPlanner避坑指南:从仿真到实车,ROS小车部署的5个关键步骤 当学术论文中的算法终于有了开源实现,那种跃跃欲试的心情每个机器人开发者都懂。但真正把代码下载到本地,准备部署到自己的ROS小车上时,才发现从理…...

Fillinger智能填充算法深度解析:从三角剖分到工程化实现
Fillinger智能填充算法深度解析:从三角剖分到工程化实现 【免费下载链接】illustrator-scripts Adobe Illustrator scripts 项目地址: https://gitcode.com/gh_mirrors/il/illustrator-scripts 在矢量图形设计领域,复杂形状内的元素填充是一个常见…...

深度解析:PC端即时通讯防撤回功能的技术实现
深度解析:PC端即时通讯防撤回功能的技术实现 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcode.com/GitHub_…...

别再死记硬背了!用Wireshark抓包实战,5分钟搞懂IP报文每个字段
用Wireshark解密IP协议:从抓包实战到网络诊断的完全指南 当你第一次打开网络教材看到IP报文那密密麻麻的字段时,是否感觉像在解读外星密码?传统的学习方法让我们死记硬背"版本号4位、首部长度4位、服务类型8位...",但今…...

终极指南:如何快速筛选高质量免费股票资源的5大核心标准
终极指南:如何快速筛选高质量免费股票资源的5大核心标准 【免费下载链接】awesome-stock-resources :city_sunrise: A collection of links for free stock photography, video and Illustration websites 项目地址: https://gitcode.com/gh_mirrors/aw/awesome-s…...

高项通关秘籍:十大管理ITTO核心逻辑与实战速记
1. 十大管理ITTO的本质与学习误区 第一次接触高项考试的朋友,看到十大管理47个过程域的ITTO(输入、工具与技术、输出)时,往往会被密密麻麻的表格吓到。我当年备考时,整整三天都在和这些缩写词较劲,直到发现…...

像素即坐标,跨镜即连续:镜像视界空间级全域跟踪引擎技术解析方案
像素即坐标,跨镜即连续:镜像视界空间级全域跟踪引擎技术解析方案 一、方案前言 在全域视频感知、智慧城市、智慧园区、安防管控、跨境物流等场景中,传统跨摄像机(跨镜)跟踪技术长期面临目标ID断裂、轨迹碎片化、外观特…...