C/C++内存管理
C/C++内存管理
- C/C++内存分布
- C语言中内存管理的方式:malloc/calloc/realloc/free
- C++内存管理方式
- 内置类型
- 自定义类型
- operator new 与operator delete
- new和delete的实现原理
- 内置类型
- 自定义类型
- 定位new表达式(placement-new)
- new/delete与malloc/free的区别
C/C++内存分布
我们先来看一段代码:
int globalVar = 1;
static int staticGlobalVar = 1;
void Test()
{
static int staticVar = 1;
int localVar = 1;
int num1[10] = { 1, 2, 3, 4 };
char char2[] = "abcd";
const char* pChar3 = "abcd";
int* ptr1 = (int*)malloc(sizeof(int) * 4);
int* ptr2 = (int*)calloc(4, sizeof(int));
int* ptr3 = (int*)realloc(ptr2, sizeof(int) * 4);
free(ptr1);
free(ptr3);
}
1. 选择题:选项: A.栈 B.堆 C.数据段(静态区) D.代码段(常量区)globalVar在哪里?____ staticGlobalVar在哪里?____staticVar在哪里?____ localVar在哪里?____num1 在哪里?____char2在哪里?____ *char2在哪里?___pChar3在哪里?____ *pChar3在哪里?____ptr1在哪里?____ *ptr1在哪里?____
2. 填空题:sizeof(num1) = ____;sizeof(char2) = ____; strlen(char2) = ____;sizeof(pChar3) = ____; strlen(pChar3) = ____;sizeof(ptr1) = ____;
3. sizeof 和 strlen 区别?
首先我们来回答第一题:
globalVar属于全局变量,全局变量存储与全局区或静态区,所以答案选C;
staticGlobalVar,static修饰的全局变量,存储与静态区,所以答案选C;
staticVar,static修饰的局部变量,也属于静态变量,也存储与静态区,所以答案选C;
localVar,属于main函数内部的局部变量,存储在main函数的栈帧中,所以答案选A;
num1 ,数组名,num1整个数组是开辟在main函数的栈帧上的,属于局部变量,也是存储与栈上,所以答案选A;
char2,在main函数栈帧上开辟,随着main函数栈帧的销毁而销毁,属于局部变量,存储在栈上,所以选A;
*char2,char2没有与&结合,也没有单独放在sizeof内部,char2表述数组首元素地址,对其解引用访问到的是数组首元素,整个数组都是开辟在栈上的,首元素当然也不例外,故答案选A;
pChar3,在栈上开辟,选A;
*pChar3,“"abcd"是存储与常量区的,故pChar3存储的是常量区的地址,对其解引用访问到的就是首元素,整个字符串都是存储与常量区的,首元素也不例外,故选D;
ptr1,局部变量,存储与栈上,故答案选A;
*ptr1,是用malloc开辟的空间,malloc是从堆区申请空间,ptr1是堆区的地址,对其解引用就是堆区的空间,故选B;
第二题:
num1是数组名,数组名单独放在sizeof内部,表示整个数组,故求得大小为40字节;
char2是数组名,数组名单独放在sizeof内部,表示整个数组,故求得大小是5字节(不要忘了’\0’);
strlen(char2),strlen遇到’\0’停止,故求得大小为4;
sizeof(pChar3),pChar3是指针,大小为4/8字节;
strlen(pChar3),strlen遇到’\0’停止,故求得大小为4;
sizeof(ptr1),ptr1是指针,故求得大小为4/8字节;
第三题:
sizeof是求数据所占内存空间大小的关键字,strlen是求字符串长度的函数;

总结:
- 栈又叫堆栈–非静态局部变量/函数参数/返回值等等,栈是向下增长的。
- 内存映射段是高效的I/O映射方式,用于装载一个共享的动态内存库。用户可使用系统接口
创建共享共享内存,做进程间通信。(Linux课程如果没学到这块,现在只需要了解一下)- 堆用于程序运行时动态内存分配,堆是可以上增长的。
- 数据段–存储全局数据和静态数据。
- 代码段–可执行的代码/只读常量。
C语言中内存管理的方式:malloc/calloc/realloc/free
void test()
{int* tmp = (int*)malloc(sizeof(int) * 10);//利用malloc向堆区申请10个int类型的空间,这些空间不会被初始化;if (tmp == nullptr){perror("malloc");exit(EXIT_FAILURE);}int* tmp2 = (int*)calloc(sizeof(int), 10);//利用calloc向堆区申请10个int类型的空间,编译器会自动以0初始化这些空间;if (tmp2 == nullptr){perror("calloc");exit(EXIT_FAILURE);}int* p = nullptr;int* tmp4 = (int*)realloc(p,sizeof(int)*20);//对空间进行扩容,当tmp==nullptr时,realloc相当于malloc;if (tmp4 == nullptr){perror("calloc");exit(EXIT_FAILURE);}free(tmp4);free(tmp2);free(tmp);
}
我们可以发现,C语言实现内存管理的方式是通过4个函数,这些函数在使用起来似乎并不是那么方便,比如不管我们用那种方式(malloc、calloc、realloc)开辟空间,我们在使用这些空间之前都必须对其进行判空处理,避免后续对空指针解引用的处理,如果我们需要频繁的申请空间,那么这些判空代码就会被我们大量的使用,会增加重复的代码,要是每次返回的都是经过malloc等函数验证过的指针该多好,用起来也方便!还有就是malloc、calloc、realloc参数设计的不太同一,使用起来比较复杂;
最后一点就是对于所开空间的大小我们都需要手动计算,容易计算错误!等等,简而言之,在C语言中实现内存的管理并不是一件易事!那么C++作为C的扩展,在内存管理方面会不会有优化呢?
C++内存管理方式
内置类型
在C++中通过new和delete两个操作符来实现内存管理;
比如:
void test2()
{//开一个int空间int* p1 = new int;//开辟10个连续 int空间int* parr = new int[10];//释放空间delete p1;//释放连续空间delete[]parr;
}
通过对比C语言的内存管理方式我们可以发现,在C++实现内存管理的方式非常简洁,同时也没有了繁琐的判空的步骤!
在C语言中,我们从堆上开辟的空间是不能初始化的,如果能的话那也就是calloc,但是它是只能初始化为0,在某些场景下与没初始化没什么区别;
在C++中我们可以指定值来初始化我们从堆区开辟的空间;
比如:

调试结果:

总结:
1、开辟单块空间: new type (初始值);
开辟连续空间: new type[大小] {初始值1,初始值2,……};
释放单个空间:delete 指针;
释放连续空间:delete [ ] 指针;
千万要注意,new和delete配套使用;new [] 与delete [ ]配套使用,如果乱使用的话,可能会引发一些不可预料的后果!
2、new出来的空间不需要进行强转和判空;
自定义类型
上面是对于内置类型的内存管理,那么对于自定义类型呢?
其基本用法与内置类下的用法大致一样,但是还是有一点区别:
class A
{
public:A() :_a(0){cout << "A()" << endl;}A(int a) :_a(a){cout << "A(int a)" << endl;}A(const A& a) :_a(a._a){cout << "A(const A& a)" << endl;}~A(){cout << "~A()" << endl;}void test(){cout << "void test()" << endl;}A& operator=(const A& a){cout << "A& operator=(const A& a)" << endl;_a = a._a;return *this;}
private:int _a;
};
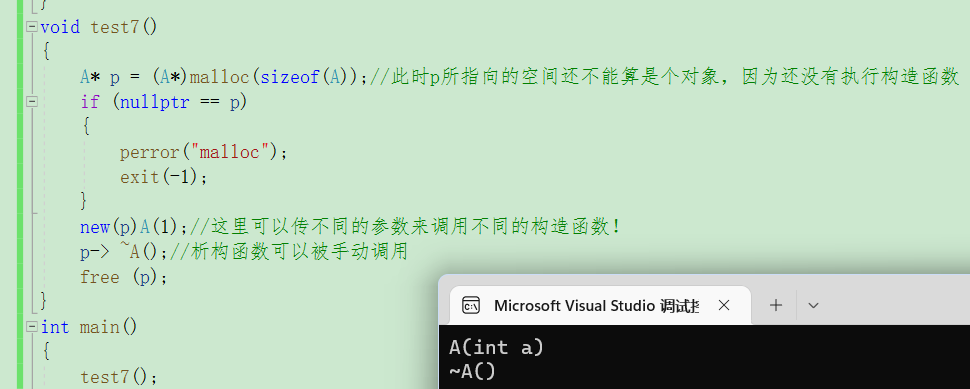
void test3()
{//向堆区开辟一块空间A* p = new A;//向堆区开辟一块连续的空间A* parr =new A[5];delete p;delete[] parr;
}
运行结果:

我们可以发现,自定义类型在利用new向堆区申请空间时,会自动调用构造函数来初始化空间,在利用delete释放空间的时候,会自动调用析构函数!
通过实验结论可以看出,当我们不指定特定值来初始化时,编译器默认调用默认构造函数来初始化!
那么我们如何让对象,按照我们指定的构造函数来初始化空间呢?
用法如下:

总结:
1、利用new给自定义类型开辟空间时,如果不指定构造函数,则编译器会使用默认构造函数来初始化;delete空间时,编译器会调用先调用析构函数;而对于malloc/free函数来说并不会调用构造函数和析构函数;
2、对于自定义类型我们也可以指定构造方式来初始化;
operator new 与operator delete
new与delete是用户在C++中进行内存管理的操作符,其底层是用operator new和operator delete这两个全局函数来实现的,是的!你没听错,operator new和operator delete是全局函数,不是运算符重载!operator new和operator delete就是函数名与Add、Show、test等一样的函数名!这个名字很有误导性!我们需要注意;
既然new和delete底层是用operator new 与operator delete两个全局函数实现的,那么我们来看看这两个函数的具体实现:
operator new:
//operator new:该函数实际通过malloc来申请空间,当malloc申请空间成功时直接返回;申请空间
失败,尝试执行空间不足应对措施,如果改应对措施用户设置了,则继续申请,否则抛异常。
void *__CRTDECL operator new(size_t size) _THROW1(_STD bad_alloc)
{
// try to allocate size bytes
void *p;
while ((p = malloc(size)) == 0)
if (_callnewh(size) == 0){// report no memory// 如果申请内存失败了,这里会抛出bad_alloc 类型异常static const std::bad_alloc nomem;_RAISE(nomem);}
return (p);
}
operator new参数和返回值与malloc一致;
我们可以发现operator new函数内部也是调用malloc来实现的,只不过operator new对malloc进行了封装;就是说operator new函数对于malloc 开辟空间失败 的做法进行了优化,不再是返回空指针,而是直接抛出异常!而对于开辟成功的空间,则是直接返回所开空间的首地址!这对于我们使用者来说,方便了不少,我们无需在每次对从堆区申请的空间进行判空了,可以大胆放心的使用!但是operator new函数的返值是void*,也就是说我们还得需要对指针进行强转!
operator delete:
//operator delete: 该函数最终是通过free来释放空间的
void operator delete(void *pUserData)
{_CrtMemBlockHeader * pHead;RTCCALLBACK(_RTC_Free_hook, (pUserData, 0));if (pUserData == NULL)return;_mlock(_HEAP_LOCK); // block other threads __TRY// get a pointer to memory block header pHead = pHdr(pUserData);// verify block type _ASSERTE(_BLOCK_TYPE_IS_VALID(pHead->nBlockUse));_free_dbg( pUserData, pHead->nBlockUse );__FINALLY_munlock(_HEAP_LOCK); // release other threads __END_TRY_FINALLYreturn;
}
//free的实现
#define free(p) _free_dbg(p, _NORMAL_BLOCK)
既然operator new都有了,那么自然的作为“开辟”的伴随者,“释放”自然也就少不了,operator delete 就是对free的封装,用法也与free一样!
我们可以在我们的程序中,直接使用这些函数:

new和delete的实现原理
内置类型
对于内置类型来说,new、delete与malloc、free基本类似;
不同的是:接受new出来的空间不需要进行强制类型转换!malloc的返回值需要进行强制类型转换!
还有就是new开辟空间失败会抛出异常,不会返回空指针,而malloc开辟空间失败是会返回空指针的;
new出来的空间可以放心使用,malloc出来的空间在使用前,需要判断是否是合法空间(判空!)
自定义类型
new原理:
1、调用operator new函数开辟空间;
2、调用构造函数初始化空间;
delete原理:
1、调用析构函数进行资源清理;
2、调用operator delete函数进行对象本身的释放;
new [N]
1、调用operator new[](也就是对于operator new的封装,目的是为了对应new [ ]),operator new[]实际通过调用operator new来完成的函数开辟N个连续空间的对象;
2、调用N次构造函数,分别对每个对象进行初始化;
delete [ ]
1、调用N次析构函数,分别对每个对象进行资源清理;
2、调用operator delete[](也就是对于operator delete的封装,目的是为了和operator new配对),实际是通过调用operator delete来完成对N个连续对象本身的释放;
在这里我再次强调一下:
malloc与free匹配使用!
new与delete匹配使用!
new[]与delete[]匹配使用!
千万不要混用不然会出现不可预知的后果!
比如:

我们new出来的空间利用free来释放,调用free来释放的话,编译器是不会调用对象的析构函数的!对于本例来说并没有多大影响!因为A类没有额外申请资源,不需要对资源进行手动释放;但是如果是栈类呢?

虽然我们完成了Stack栈类对象本身空间的释放,但是我们造成了内存泄漏!_a所指向的空间也是我们从堆上开辟的,我们利用free释放,就不会调用析构函数,也就无法完成_a所指向的空间的释放!
当我们使用delete时,编译器才会调用析构函数完成_a所指空间的释放!

这就是乱用的后果,内存泄漏是个很严重的问题,在C/C++语言中,编译器是不会检查内存泄漏的!
还有一个例子也是乱使用delete、free、delete[]造成的程序崩溃:
我们可以看到使用free和delete释放new[]开辟的空间时,程序直接崩溃了;
这是为什么?
我们刚才说了,delete []释放空间的时候是需要调用N次析构函数的,对于new[N]需要调用N次构造函数,new很容易知道,但是delete怎么知道他要调用N次析构函数呢?主要是因为为,new[]在开辟空间的时候,在所开空间的前面多开了几块空间,这多开的空间就是专门用来存储delete[]该调用几次析构函数的:
为此我们在使用delete[]的时候,operator delete[]会先将指针往前偏一点,拿到调用析构函数的次数,然后调用N次析构函数,最后在从多开出的空间开始释放!而不是从new[]返回的地址开始释放!当我们使用free、delete的时候都是从new[]返回的地址处开始释放的,会造成红色部分空间没有得到释放!系统就会崩溃!
当然,如果我们将析构函数注释掉,那么free、delete、delete[]三种方式释放空间,编译器都不会报错了,这是为什么?
编译器也是很聪明,当编译器发现你是使用的默认析构函数,也就是编译器自动生成的时候,他就会认为此时对new[]出来的空间析不构析构好像没多大意义了,那么在new[]的时候也就不会多开辟空间出来存储需要delete[]需要调用析构函数的次数,那么自然delete、free就不会造成空间的少释放!



总而言之,上面的例子都在告诉我们要匹配malloc/free、new/delete、new[]/delete[]使用!!!!!
定位new表达式(placement-new)
定位new表达式是在已分配的原始内存空间中调用构造函数初始化一个对象。
使用格式:
new (place_address) type或者new (place_address) type(initializer-list)
place_address必须是一个指针,initializer-list是类型的初始化列表
使用场景:
定位new表达式在实际中一般是配合内存池使用。因为内存池分配出的内存没有初始化,所以如果是自定义类型的对象,需要使用new的定义表达式进行显示调构造函数进行初始化。
这里简单介绍一下内存池:内存池故名思意就是一个池子,里面装的都是内存块,我们在使用new、malloc等操作符或函数申请空间的时候,都是直接去os管理的堆上开辟的空间,所有需要申请空间的程序都是从这里申请的,在这里申请空间就避免不了与os的交互,交互是需要花费时间的,如果一个程序中需要频繁的开辟空间,那么程序会在申请空间的路上花费大量时间,时间效率有点低,因为这需要频繁的与os交互,为此大佬们提出了内存池的技术,就是预先从os管理的堆上开辟一部分空间出来,程序想要申请空间的时候就不需要向os申请了,直接去内存池拿,减少了os的交互时间,提高了程序运行效率!如果当内存池的空间不足时,再由内存池向os申请一块更大的空间过来;
new/delete与malloc/free的区别
共同点:
无论是new还是malloc都是从堆上申请空间,都需要用户自己手动对这些空间进行手动释放!
不同点:
1、new的返回值是不需要进行强制转换的,malloc需要对返回类型进行强转;
2、对于new开辟的空间,我们不需要进行判空,new如果开辟失败的话,或抛出异常;malloc开辟失败会返回空指针,因此我们在使用malloc开辟空间时,需要自己手动判断空间是否开辟成功;
3、new空间的时候只需要告诉我们想要开辟空间的个数,malloc开辟空间的时候需要我们手动计算所开空间的大小;
4、new可以用指定值初始化开辟出来的空间,malloc不能对开辟出来的空间进行初始化;
5、对于自定义类型来说,new在开辟好空间后会调用其构造函数来初始化这块空间,delete释放这块空间的时候会先调用该对象的析构函数来清理该对象的资源,然后才完成对象本身的释放;malloc只会开辟空间,不会调用构造函数;free也只是释放空间,不会调用析构函数;
6、new/delete是操作符malloc/free是函数;
相关文章:
C/C++内存管理
C/C内存管理C/C内存分布C语言中内存管理的方式:malloc/calloc/realloc/freeC内存管理方式内置类型自定义类型operator new 与operator deletenew和delete的实现原理内置类型自定义类型定位new表达式(placement-new)new/delete与malloc/free的区别C/C内存分布 我们先…...
【大数据hive】hive 函数使用详解
一、前言 在任何一种编程语言中,函数可以说是必不可少的,像mysql、oracle中,提供了很多内置函数,或者通过自定义函数的方式进行定制化使用,而hive作为一门数据分析软件,随着版本的不断更新迭代,…...
彻底搞懂分布式系统服务注册与发现原理
目录 引入服务注册与发现组件的原因 单体架构 应用与数据分离...

安卓Camera2用ImageReader获取NV21源码分析
以前如何得到Camera预览流回调 可以通过如下方法,得到一路预览回调流 Camera#setPreviewCallbackWithBuffer(Camera.PreviewCallback),可以通过如下方法,设置回调数据的格式,比如 ImageFormat.NV21 Camera.Parameters#setPreview…...

24. 两两交换链表中的节点
文章目录题目描述迭代法递归法参考文献题目描述 给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。 示例 1: 输入&a…...

linux006之帮助命令
linux帮助命令简介: linux的命令是非常多的,光靠人是记不住的,在工作中一般都会去网上查,这是有外网的情况下,如果项目中不允许访问外网,那么linux的帮助命令就可以派上用场了, linux帮助命令是…...

【C++初阶】十三、模板进阶(总)|非类型模板参数|模板的特化|模板分离编译|模板总结(优缺点)
目录 一、非类型模板参数 二、模板的特化 2.1 模板特化概念 2.2 函数模板特化 2.3 类模板特化 2.3.1 全特化 2.3.2 偏特化 三、模板分离编译 四、模板总结(优缺点) 前言:之前模板初阶并没有把 C模板讲完,因为当时没有接触…...
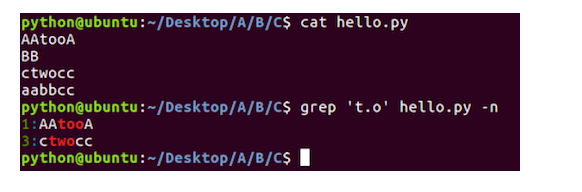
Linux之文本搜索命令
文本搜索命令学习目标能够知道文本搜索使用的命令1. grep命令的使用命令说明grep文本搜索grep命令效果图:2. grep命令选项的使用命令选项说明-i忽略大小写-n显示匹配行号-v显示不包含匹配文本的所有行-i命令选项效果图:-n命令选项效果图:-v命令选项效果图:3. grep命令结合正则表…...

微信小程序Springboot 校园拼车自助服务系统java
系统管理员: 管理员账户管理:在线对管理员的账户信息进行管理,包括对管理员信息的增加修改以及密码的修改等。 站内新闻管理:在后台对站内新闻信息进行发布,并能够对站内新闻信息进行删除修改等。 论坛版块管理&#x…...

【Unity3D 常用插件】Haste插件
一,Haste介绍 Haste插件是一款针对 Unity 3D 的 Everthing软件,可以实现基于名称快速定位对象的功能。Unity 3D 编辑器也自带了搜索功能,但是在 project视图 和 Hierarchy视图 中的对象需要分别查找,不支持模糊匹配。Haste插件就…...

【c++面试问答】全局变量和局部变量的区别
问题 C中的全局变量和局部变量有什么区别? 注:内容全部参考自文末的参考资料 全局变量和局部变量的区别 可以从以下4个角度来区分: 区别全局变量局部变量作用域全局作用域局部作用域内存分配全局变量在静态数据区静态局部变量在静态数据区…...

Java List集合
6 List集合 List系列集合:添加的元素是有序,可重复,有索引 ArrayList: 添加的元素是有序,可重复,有索引LinkedList: 添加的元素是有序,可重复,有索引Vector :是线程安全的ÿ…...

linux服务器挂载硬盘/磁盘
1. 查看机器所挂硬盘个数及分区情况:fdisk -l可以看出来目前/dev/vda 目前有300G可用.内部有两个分区(/dev/vda1,/dev/vda2)。2. 格式化磁盘格式化磁盘命令为【mkfs.磁盘类型格式 目录路径组成】查看磁盘文件格式:df -T格式化磁盘…...

Java 抽象类
文章目录1、抽象方法和抽象类2、抽象类的作用当编写一个类时,常常会为该类定义一些方法,用于描述该类的行为方式,这些方法都有具体的方法体。但在某些情况下,某个基类只是知道其子类应该包含那些方法,但不知道子类是如…...
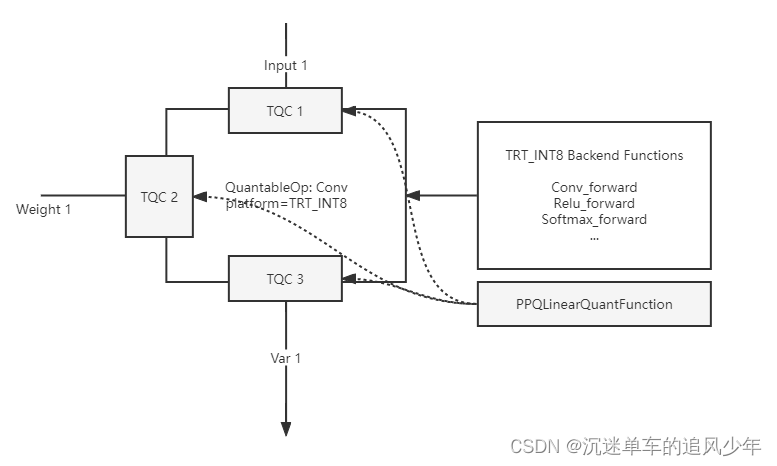
OpenPPL PPQ量化(5):执行引擎 源码剖析
目录 PPQ Graph Executor(PPQ 执行引擎) PPQ Backend Functions(PPQ 算子库) PPQ Executor(PPQ 执行引擎) Quantize Delegate (量化代理函数) Usage (用法示例) Hook (执行钩子函数) 前面四篇博客其实就讲了下面两行代码: ppq_ir load_onnx_graph(onnx_impor…...
【脚本开发】运维人员必备技能图谱
脚本(Script)语言是一种动态的、解释性的语言,依据一定的格式编写的可执行文件,又称作宏或批处理文件。脚本语言具有小巧便捷、快速开发的特点;常见的脚本语言有Windows批处理脚本bat、Linux脚本语言shell以及python、…...
N字形变换-力扣6-java
一、题目描述将一个给定字符串 s 根据给定的行数 numRows ,以从上往下、从左到右进行 Z 字形排列。比如输入字符串为 "PAYPALISHIRING" 行数为 3 时,排列如下:P A H NA P L S I I GY I R之后,你的输出需要从左往右逐行读…...
)
概论_第5章_中心极限定理1__定理2(棣莫弗-拉普拉斯中心极限定理)
在概率论中, 把有关论证随机变量和的极限分布为正态分布的一类定理称为中心极限定理称为中心极限定理称为中心极限定理。 本文介绍独立同分布序列的中心极限定理。 一 独立同分布序列的中心极限定理 定理1 设X1,X2,...Xn,...X_1, X_2, ...X_n,...X1,X2,...Xn…...
详细解读503服务不可用的错误以及如何解决503服务不可用
文章目录1. 问题引言2. 什么是503服务不可用错误3 尝试解决问题3.1 重新加载页面3.2 检查该站点是否为其他人关闭3.3 重新启动设备3.3 联系网站4. 其他解决问的方法1. 问题引言 你以前遇到过错误503吗? 例如,您可能会收到消息,如503服务不可…...

【前端vue2面试题】2023前端最新版vue模块,高频17问(上)
🥳博 主:初映CY的前说(前端领域) 🌞个人信条:想要变成得到,中间还有做到! 🤘本文核心:博主收集的关于vue2面试题(上) 目录 vue2面试题 1、$route 和 $router的区别 2、一个…...

告别TwinCAT:手把手教你用LinuxCNC+IGH搭建开源EtherCAT运动控制平台
告别商业软件束缚:LinuxCNCIGH开源运动控制平台实战指南 在工业自动化和运动控制领域,商业软件长期占据主导地位,但高昂的授权费用和封闭的生态系统让许多工程师和创客望而却步。开源运动控制平台的出现打破了这一局面,为追求灵活…...

从电机控制到呼吸灯:用STM32CubeMX玩转TIM高级定时器的互补PWM与死区时间配置
从电机控制到呼吸灯:用STM32CubeMX玩转TIM高级定时器的互补PWM与死区时间配置 在嵌入式开发中,定时器是最基础也最强大的外设之一。对于STM32开发者来说,掌握高级定时器的互补PWM输出和死区时间配置,意味着可以解锁从电机控制到LE…...

CoverM如何革新宏基因组覆盖率分析:从短读长到PacBio HiFi的完整解决方案
CoverM如何革新宏基因组覆盖率分析:从短读长到PacBio HiFi的完整解决方案 【免费下载链接】CoverM Read alignment statistics for metagenomics 项目地址: https://gitcode.com/gh_mirrors/co/CoverM 宏基因组研究正经历着从短读长测序到长读长技术的深刻变…...

三维动画课程期末复盘:从零搭建我的马卡龙童话游乐场✨
当我按下 3ds Max 的渲染按钮,看着浅蓝的摩天轮缓缓转动、粉白的旋转木马跟着节奏起舞、淡紫色热气球轻轻飘动时,我才真正意识到:为期一学期的三维动画课程,就这样在我的指尖落下了帷幕。从刚打开软件连工具栏都认不全的 “小白”…...

【AI面试临阵磨枪-54】如何监控 AI 系统:成功率、延迟、Token 消耗、幻觉率、调用量
一、 面试题目面试官提问: “在大规模 Agent 系统中,你是如何建立监控体系的?请针对 成功率、延迟、Token 消耗、幻觉率、调用量 这五个核心指标,详细谈谈你的采集、分析与预警方案。”二、 知识储备1. 核心背景:AI 监…...

如何解决QQ音乐下载的歌曲在其他设备上无法播放的问题
如何解决QQ音乐下载的歌曲在其他设备上无法播放的问题 【免费下载链接】qmcflac2mp3 直接将qmcflac文件转换成mp3文件,突破QQ音乐的格式限制 项目地址: https://gitcode.com/gh_mirrors/qm/qmcflac2mp3 你是否曾经在QQ音乐下载了喜欢的歌曲,却发现…...

【限时公开】谷歌内部未文档化Gemini JavaScript SDK隐藏能力:流式响应中断控制、上下文压缩率提升63%实测数据
更多请点击: https://intelliparadigm.com 第一章:Gemini JavaScript SDK核心能力概览 Gemini JavaScript SDK 是 Google 官方提供的轻量级客户端库,专为在浏览器和 Node.js 环境中无缝集成 Gemini 模型能力而设计。它抽象了底层 HTTP 请求、…...

从布朗运动到伊藤公式:金融随机世界的建模基石
1. 从花粉运动到股票价格:布朗运动的金融启示 1827年,英国植物学家罗伯特布朗在显微镜下观察到花粉颗粒在水中的不规则舞动,这个看似简单的物理现象却在80年后被爱因斯坦用数学语言精确描述。有趣的是,当我们将显微镜换成股票行情…...

Go-sniffer高级用法指南:自定义过滤规则和协议扩展开发终极教程
Go-sniffer高级用法指南:自定义过滤规则和协议扩展开发终极教程 【免费下载链接】go-sniffer 项目地址: https://gitcode.com/gh_mirrors/go/go-sniffer Go-sniffer是一款功能强大的网络嗅探工具,专为开发者和运维人员设计,能够实时抓…...

AI推广的核心原理是什么?
理解AI推广的原理,你才能知道该做什么、不该做什么,而不是盲目操作。一句话概括AI推广的核心原理:让AI在回答用户问题时,选择引用你的内容。就这么简单。但要做到这件事,你需要理解AI是怎么"选择"的。AI回答…...