Segment Anything CSharp| 在 C# 中通过 OpenVINO™ 部署 SAM 模型实现万物分割
OpenVINO™ C# API 是一个 OpenVINO™ 的 .Net wrapper,应用最新的 OpenVINO™ 库开发,通过 OpenVINO™ C API 实现 .Net 对 OpenVINO™ Runtime 调用.Segment Anything Model(SAM)是一个基于Transformer的深度学习模型,主要应用于图像分割领域。在本文中,我们将演示如何在C#中使用OpenVINO™部署 Segment Anything Model 实现任意目标分割。
OpenVINO™ C# API项目链接:
https://github.com/guojin-yan/OpenVINO-CSharp-API.git使用 OpenVINO™ C# API 部署 Segment Anything Model 全部源码:
https://github.com/guojin-yan/segment-anything-csharp/blob/master/src/segment_anything_openvino/Program.cs
文章目录
- 1. 前言
- 1.1 OpenVINO™ C# API
- 1.2 Segment Anything Model (SAM)
- 2. 模型下载与转换
- 2.1 安装环境
- 2.2 下载模型
- 2.3 模型转换
- 3. 模型部署代码
- 3.1 编码器模型部署代码
- 3.2 解码器模型部署代码
- 4. 模型部署测试代码
- 5. 预测效果
- 6. 总结
1. 前言
1.1 OpenVINO™ C# API
英特尔发行版 OpenVINO™ 工具套件基于 oneAPI 而开发,可以加快高性能计算机视觉和深度学习视觉应用开发速度工具套件,适用于从边缘到云的各种英特尔平台上,帮助用户更快地将更准确的真实世界结果部署到生产系统中。通过简化的开发工作流程,OpenVINO™ 可赋能开发者在现实世界中部署高性能应用程序和算法。

2024年4月25日,英特尔发布了开源 OpenVINO™ 2024.1 工具包,用于在各种硬件上优化和部署人工智能推理。更新了更多的 Gen AI 覆盖范围和框架集成,以最大限度地减少代码更改。同时提供了更广泛的 LLM 模型支持和更多的模型压缩技术。通过压缩嵌入的额外优化减少了 LLM 编译时间,改进了采用英特尔®高级矩阵扩展 (Intel® AMX) 的第 4 代和第 5 代英特尔®至强®处理器上 LLM 的第 1 令牌性能。通过对英特尔®锐炫™ GPU 的 oneDNN、INT4 和 INT8 支持,实现更好的 LLM 压缩和改进的性能。最后实现了更高的可移植性和性能,可在边缘、云端或本地运行 AI。
OpenVINO™ C# API 是一个 OpenVINO™ 的 .Net wrapper,应用最新的 OpenVINO™ 库开发,通过 OpenVINO™ C API 实现 .Net 对 OpenVINO™ Runtime 调用,使用习惯与 OpenVINO™ C++ API 一致。OpenVINO™ C# API 由于是基于 OpenVINO™ 开发,所支持的平台与 OpenVINO™ 完全一致,具体信息可以参考 OpenVINO™。通过使用 OpenVINO™ C# API,可以在 .NET、.NET Framework等框架下使用 C# 语言实现深度学习模型在指定平台推理加速。
1.2 Segment Anything Model (SAM)
Segment Anything Model(SAM)是一个基于Transformer的深度学习模型,主要应用于图像分割领域。SAM采用了Transformer架构,主要由编码器和解码器组成,编码器负责将输入的图像信息编码成上下文向量,而解码器则将上下文向量转化为具体的分割输出。

SAM的核心思想是“自适应分割”,即能够根据不同图像或视频中的对象,自动学习如何对其进行精确分割;并且具有零样本迁移到其他任务中的能力,这意味着它可以对训练过程中未曾遇到过的物体和图像类型进行分割;SAM被视为视觉领域的通用大模型,其泛化能力强,可以涵盖广泛的用例,并且可以在新的图像领域上即时应用,无需额外的训练。

总的来说,Segment Anything Model(SAM)是一个先进的图像分割模型,以其强大的自适应分割能力、零样本迁移能力和通用性而著称。然而,在实际应用中仍需注意其泛化能力和域适应方面的挑战。
2. 模型下载与转换
2.1 安装环境
该代码要求“python>=3.8”,以及“pytorch>=1.7”和“torchvision>=0.8”。请按照此处的说明操作(https://pytorch.org/get-started/locally/)以安装PyTorch和TorchVision依赖项。
pip install git+https://github.com/facebookresearch/segment-anything.git
然后安装一些其他的依赖项:
pip install opencv-python pycocotools matplotlib onnxruntime onnx
2.2 下载模型
此处直接下载官方训练好的模型:
wget https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth
2.3 模型转换
此处模型转换使用Python实现,上面我们已经安装好了模型转换环境,下面首先导入所需要的程序包,如下所示:
import torch
from segment_anything import sam_model_registry
from segment_anything.utils.onnx import SamOnnxModel
然后导出编码器模型,编码器负责将输入的图像信息编码成上下文向量,因此其模型输入输出结构相对较为简单,转换代码如下所示:
torch.onnx.export(f="vit_b_encoder.onnx",model=sam.image_encoder,args=torch.randn(1, 3, 1024, 1024),input_names=["images"],output_names=["embeddings"],export_params=True)
接下来转换解码器模型,解码器则将上下文向量转化为具体的分割输出,因此在输入时需要指定分割的位置信息,所以其输入比较多,,分别为:
-
**image_embeddings:**编码器模型对图片编码后的输出内容,在使用时直接将编码器模型运行后的输出加载到该模型输入节点即可。
-
**point_coords:**输入的提示坐标或位置,对应点输入和框输入。方框使用两个点进行编码,一个用于左上角,另一个用于右下角。坐标必须已转换为长边1024。具有长度为1的批索引。
-
**point_labels:**稀疏输入提示的标签,0是负输入点,1是正输入点,2是输入框左上角,3是输入框右下角,-1是填充点。如果没有框输入,则应连接标签为-1且坐标为(0.0,0.0)的单个填充点。
-
**mask_input:**形状为1x1x256x256的模型的掩码输入,如果没有掩码输入,也必须提供全为0的输入。
-
**has_mask_input:**掩码输入的指示符。1表示掩码输入,0表示没有掩码输入。
-
**orig_im_size:**表示原始图片形状大小,输入格式(H,W)。
模型转换代码如下所示:
checkpoint = "sam_vit_h_4b8939.pth"
model_type = "vit_h"
sam = sam_model_registry[model_type](checkpoint=checkpoint)
onnx_model = SamOnnxModel(sam, return_single_mask=True)
embed_dim = sam.prompt_encoder.embed_dim
embed_size = sam.prompt_encoder.image_embedding_size
mask_input_size = [4 * x for x in embed_size]
dummy_inputs = {"image_embeddings": torch.randn(1, embed_dim, *embed_size, dtype=torch.float),"point_coords": torch.randint(low=0, high=1024, size=(1, 5, 2), dtype=torch.float),"point_labels": torch.randint(low=0, high=4, size=(1, 5), dtype=torch.float),"mask_input": torch.randn(1, 1, *mask_input_size, dtype=torch.float),"has_mask_input": torch.tensor([1], dtype=torch.float),"orig_im_size": torch.tensor([1500, 2250], dtype=torch.float),
}
output_names = ["masks", "iou_predictions", "low_res_masks"]
torch.onnx.export(f="vit_b_decoder.onnx",model=onnx_model,args=tuple(dummy_inputs.values()),input_names=list(dummy_inputs.keys()),output_names=output_names,dynamic_axes={"point_coords": {1: "num_points"},"point_labels": {1: "num_points"}},export_params=True,opset_version=17,do_constant_folding=True
)
3. 模型部署代码
3.1 编码器模型部署代码
static float[] ImageEmbeddings(Mat img, string model_path)
{Core core = new Core();Model model = core.read_model(model_path); OvExtensions.printf_model_info(model);CompiledModel compiled = core.compile_model(model, "CPU");Console.WriteLine("Compile Model Sucessfully!");InferRequest request = compiled.create_infer_request();Mat mat = new Mat();Cv2.CvtColor(img, mat, ColorConversionCodes.BGR2RGB);float factor = 0;mat = Resize.letterbox_img(mat, 1024, out factor);mat = Normalize.run(mat, new float[] { 123.675f, 116.28f, 103.53f }, new float[] { 1.0f / 58.395f, 1.0f / 57.12f, 1.0f / 57.375f }, false);Tensor input_tensor = request.get_input_tensor();float[] input_data = Permute.run(mat);input_tensor.set_data(input_data);Stopwatch sw = new Stopwatch();sw.Start();request.infer();sw.Stop();Console.WriteLine("Inference time: " + sw.ElapsedMilliseconds);Tensor output_tensor = request.get_output_tensor();Console.WriteLine(output_tensor.get_shape().to_string());return output_tensor.get_data<float>((int)output_tensor.get_size());
}
3.2 解码器模型部署代码
static byte[] ImageDecodings(string model_path, float[] image_embeddings, float[] onnx_coord, float[] onnx_label, float[] onnx_mask_input, float[] onnx_has_mask_input, float[] img_size)
{Core core = new Core();Model model = core.read_model(model_path);OvExtensions.printf_model_info(model);CompiledModel compiled = core.compile_model(model, "CPU");Console.WriteLine("Compile Model Sucessfully!");InferRequest request = compiled.create_infer_request();Tensor tensor1 = request.get_tensor("image_embeddings");tensor1.set_data(image_embeddings);Tensor tensor2 = request.get_tensor("point_coords");tensor2.set_shape(new Shape(1, 3, 2));tensor2.set_data(onnx_coord);Tensor tensor3 = request.get_tensor("point_labels");tensor3.set_shape(new Shape(1, 3));tensor3.set_data(onnx_label);Tensor tensor4 = request.get_tensor("mask_input");tensor4.set_data(onnx_mask_input);Tensor tensor5 = request.get_tensor("has_mask_input");tensor5.set_data(onnx_has_mask_input);Tensor tensor6 = request.get_tensor("orig_im_size");tensor6.set_data(img_size);Stopwatch sw = new Stopwatch();sw.Start();request.infer();sw.Stop();Console.WriteLine("Inference time: " + sw.ElapsedMilliseconds);Tensor output_tensor = request.get_tensor("masks");float[] mask_data = output_tensor.get_data<float>((int)output_tensor.get_size());byte[] mask_data_byte = new byte[mask_data.Length];for (int i = 0; i < mask_data.Length; i++){mask_data_byte[i] = (byte)(mask_data[i] > 0 ? 255 : 0);}return mask_data_byte;
}
4. 模型部署测试代码
下面时模型部署案例测试代码,通过调用
static void Main(string[] args)
{string embedding_model = "./../../../../../model/vit_b_encoder/vit_b_encoder.onnx";string decoding_model = "./../../../../../model/vit_b_decoder.onnx";string image_path = "./../../../../../images/dog.jpg";string image_embedding_path = "./../../../../../images/dog.bin";Mat img = Cv2.ImRead(image_path);float factor = 0;Resize.letterbox_img(img, 1024, out factor);if (!File.Exists(image_embedding_path)) {float[] data = ImageEmbeddings(img, embedding_model);SaveToFile(data, image_embedding_path);}float[] image_embedding_data = LoadFromFile(image_embedding_path);float[] onnx_coord = new float[6] { 600f / factor, 200f / factor, 480 / factor, 130 / factor, (480 + 190)/factor, (130 + 140)/factor };float[] onnx_label = new float[3] { 1f, 2f, 3f };float[] onnx_mask_input = new float[256 * 256];float[] onnx_has_mask_input = new float[1] { 0 };float[] img_size = new float[2] { img.Height, img.Width };byte[] result = ImageDecodings(decoding_model, image_embedding_data, onnx_coord, onnx_label, onnx_mask_input, onnx_has_mask_input, img_size);Cv2.Rectangle(img, new Rect(600, 200, 20, 20), new Scalar(0, 0, 255), -1);Cv2.Rectangle(img, new Rect(480, 130, 190, 140), new Scalar(0, 255, 255), 2);Mat mask = new Mat(img.Rows, img.Cols, MatType.CV_8UC1, result);Mat rgb_mask = Mat.Zeros(new Size(img.Cols, img.Rows), MatType.CV_8UC3);Cv2.Add(rgb_mask, new Scalar(255.0, 144.0, 37.0, 0.6), rgb_mask, mask);Mat new_mat = new Mat();Cv2.AddWeighted(img, 0.5, rgb_mask, 0.5, 0.0, new_mat);Cv2.ImShow("mask", new_mat);Cv2.WaitKey(0);
}
5. 预测效果
下面展示了几个预测效果情况:

该图在输入时指定了两个标记点,同时标注在了车身和车窗上,那么就会根据所标记的点提取,两个点都是在车上,因此最后分割出来的结果是车身。

与上一张图片不同的时,在这张图片中我们只标记了车窗位置,因此分割结果只分割了车窗位置。

同样地在这张图片中我们标记了狗狗,因此他最终分割出来了狗狗的位置。
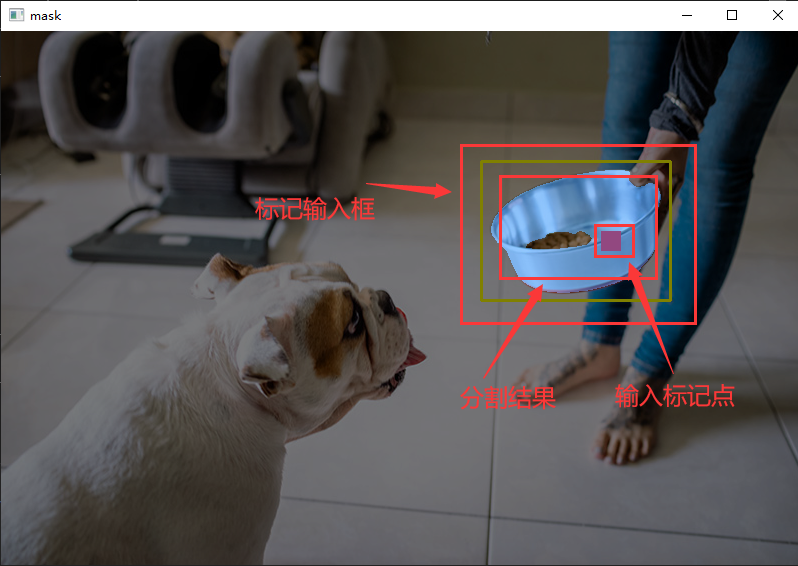
下面我们对图片中的饭盆进行分割,我们标记了饭盆,并输入了一个范围框,这样模型在这个范围里分割出了饭盆。
6. 总结
在该项目中,我们演示了如何在C#中使用OpenVINO™部署 Segment Anything Model 实现任意目标分割。最后如果各位开发者在使用中有任何问题,以及对该接口开发有任何建议,欢迎大家与我联系。

相关文章:
Segment Anything CSharp| 在 C# 中通过 OpenVINO™ 部署 SAM 模型实现万物分割
OpenVINO™ C# API 是一个 OpenVINO™ 的 .Net wrapper,应用最新的 OpenVINO™ 库开发,通过 OpenVINO™ C API 实现 .Net 对 OpenVINO™ Runtime 调用.Segment Anything Model(SAM)是一个基于Transformer的深度学习模型&#x…...

企业应如何选择安全合规的内外网文件摆渡系统?
网络隔离是一种安全措施,旨在将网络划分为不同的部分,以减少安全风险并保护敏感信息。常见的隔离方式像物理隔离、逻辑隔离、防火墙隔离、虚拟隔离、DMZ区隔离等,将网络隔离成内网和外网。内外网文件摆渡通常指在内部网络(内网&am…...

一分钟有60秒,这个有趣的原因你知道吗?
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
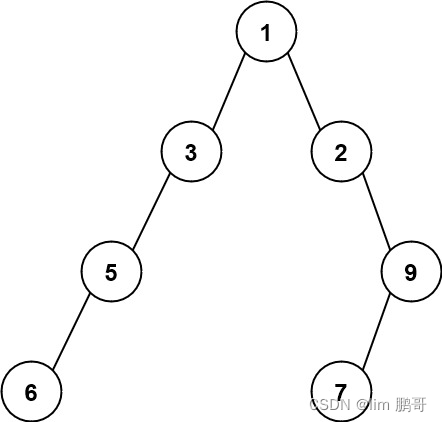
二叉树最大宽度
文章目录 前言二叉树最大宽度1.题目解析2.算法原理3.代码编写 总结 前言 二叉树最大宽度 1.题目解析 给你一棵二叉树的根节点 root ,返回树的 最大宽度 。 树的 最大宽度 是所有层中最大的 宽度 。 每一层的 宽度 被定义为该层最左和最右的非空节点(即…...
自定义HOOK)
React@16.x(24)自定义HOOK
目录 1,介绍2,简单举例2.1,获取数据1.2,计时器 2,自定义 HOOK 相比类组件 1,介绍 将一些常用的,跨组件的函数抽离,做成公共函数也就是 HOOK。自定义HOOK需要按照HOOK的规则来实现&a…...

群体优化算法----树蛙优化算法介绍以及应用于资源分配示例
介绍 树蛙优化算法(Tree Frog Optimization Algorithm, TFO)是一种基于群体智能的优化算法,模拟了树蛙在自然环境中的跳跃和觅食行为。该算法通过模拟树蛙在树枝间的跳跃来寻找最优解,属于近年来发展起来的自然启发式算法的一种 …...

常见汇编指令
下面是一些包含汇编指令 MOV、PUSH、POP、LEA、LDS、ADD、ADC、INC、SUB、SBB、DEC、CMP、MUL、DIV、AND、OR、XOR、NOT、TEST、SHL、SAL、SHR、SAR、ROL、ROR、RCL、RCR、LODS、MOVS 的例题。这些例题展示了每条指令的用法及其作用。 1. MOV 指令 MOV AX, BX ; 将寄存器 B…...

Mysql学习(七)——约束
文章目录 四、约束4.1 概述4.2 约束演示4.3 外键约束 总结 四、约束 4.1 概述 概念:约束是作用于表中字段上的规则,用于限制存储在表中的数据。目的:保证数据库中数据的正确、有效性和完整性。分类: 4.2 约束演示 根据需求&…...

Redis实战篇02
1.分布式锁Redisson 简单介绍: 使用setnx可能会出现的极端问题: Redisson的简介: 简单的使用: 业务代码的改造: private void handleVoucherOrder(VoucherOrder voucherOrder) {Long userId voucherOrder.getUserI…...
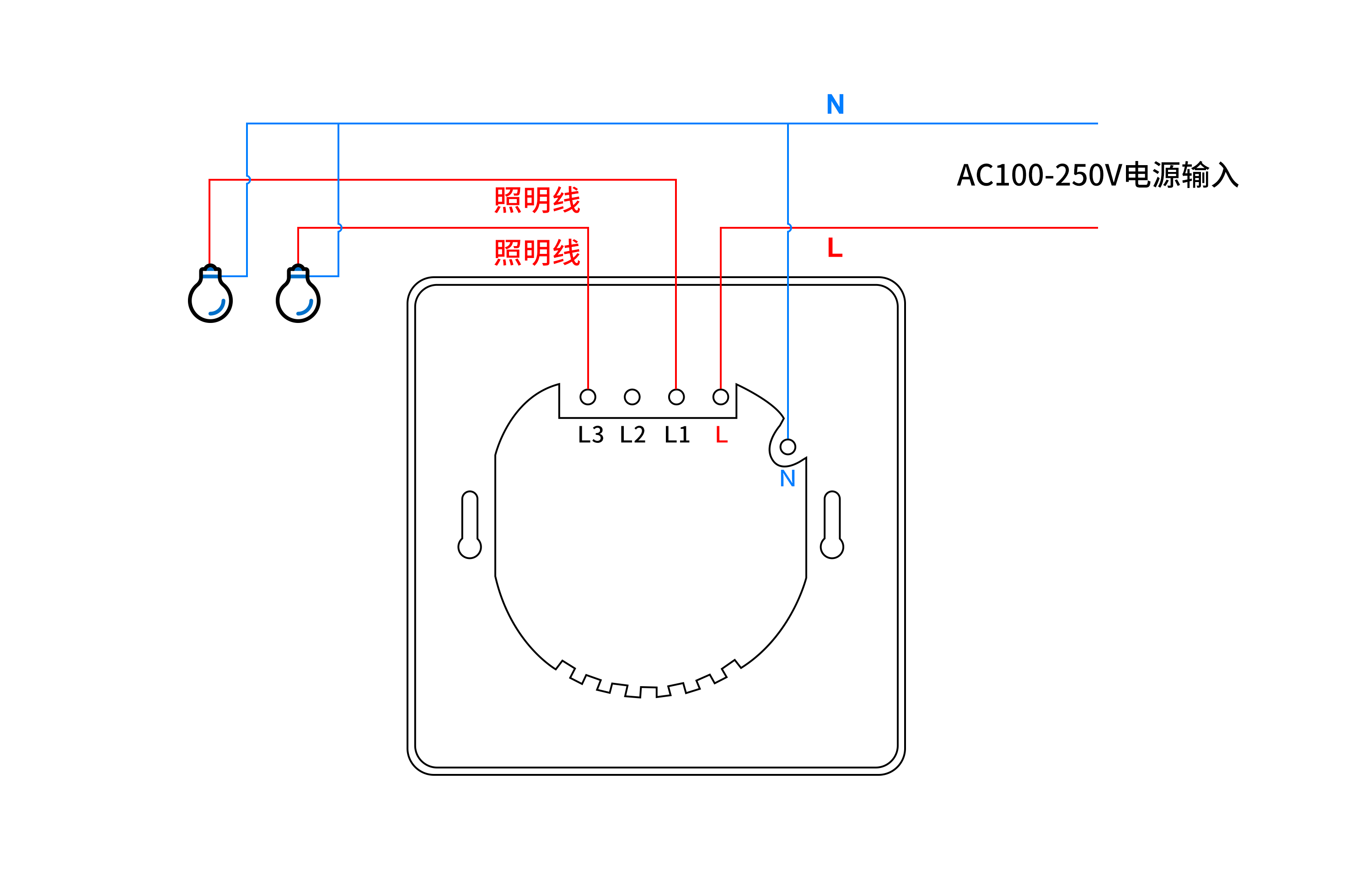
怎么用PHP语言实现远程控制两路照明开关
怎么用PHP语言实现远程控制两路开关呢? 本文描述了使用PHP语言调用HTTP接口,实现控制两路开关,两路开关可控制两路照明、排风扇等电器。 可选用产品:可根据实际场景需求,选择对应的规格 序号设备名称厂商1智能WiFi墙…...

Docker面试整理-什么是多阶段构建?它的好处是什么?
多阶段构建是 Docker 在 Dockerfile 中引入的一个功能,允许你在单个 Dockerfile 中使用多个构建阶段,但最终只生成一个轻量级的镜像。这是通过在一个 Dockerfile 中定义多个 FROM 指令来实现的,每个 FROM 指令都可以使用不同的基础镜像,并开始一个新的构建阶段。 多阶段构建…...
ENSP校园网设计实验
前言 哈喽,我是ICT大龙。本次更新了使用ENSP仿真软件设计校园网实验。时间比较着急,可能会有错误,欢迎大家指出。 获取本次工程文件方式在文章结束部分。 拓扑设计 拓扑介绍---A校区 如图,XYZ大学校园网设计分为3部分࿰…...
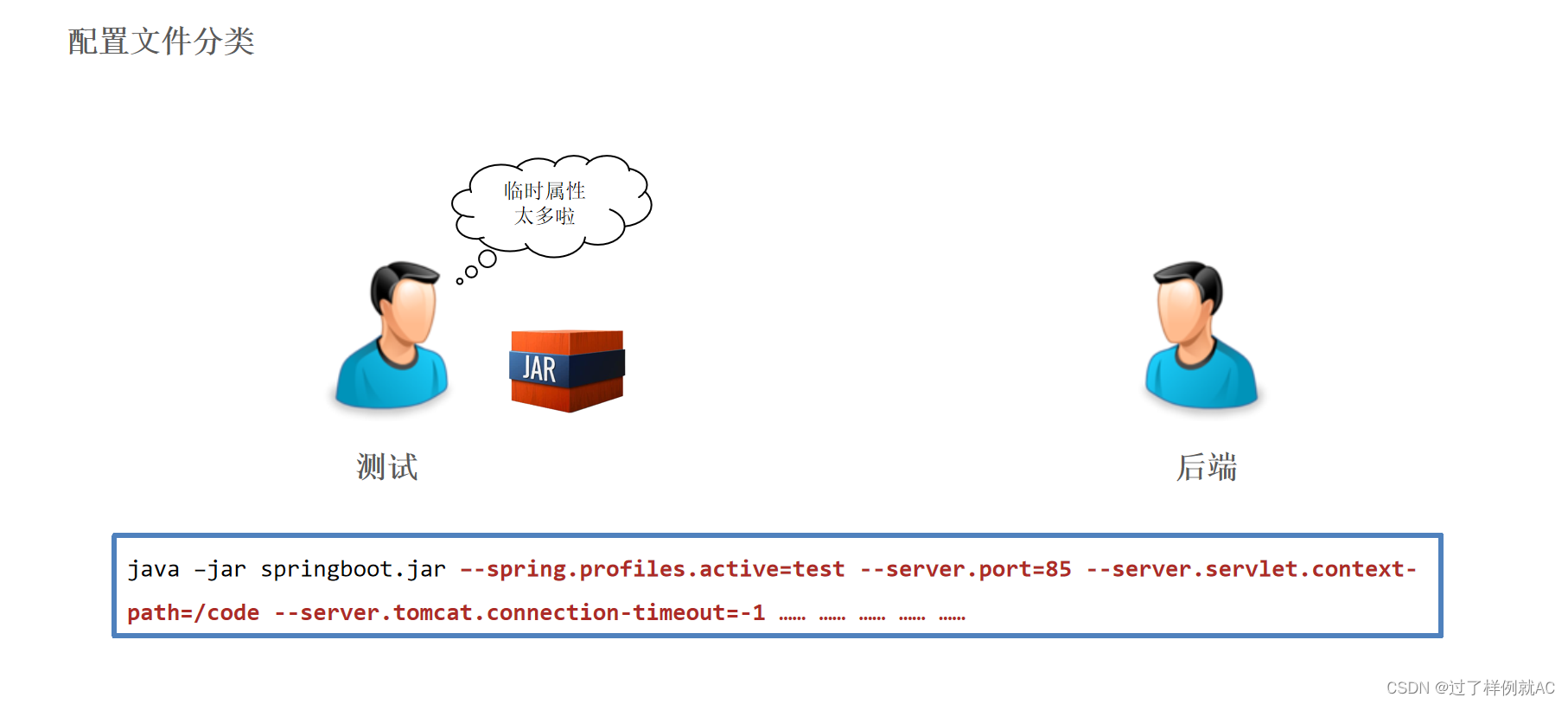
【Spring框架全系列】SpringBoot_3种配置文件_yml语法_多环境开发配置_配置文件分类(详细)
文章目录 1.三种配置文件2. yaml语法2.1 yaml语法规则2.2 yaml数组数据2.3 yaml数据读取 3. 多环境开发配置3.1 多环境启动配置3.2 多环境启动命令格式3.3 多环境开发控制 4. 配置文件分类 1.三种配置文件 问题导入 框架常见的配置文件有哪几种形式? 比如…...

华为坤灵路由器初始化的几个坑,含NAT配置
1、aaa密码复杂度修改: #使能设备对密码进行四选三复杂度检查功能。 <HUAWEI>system-view [HUAWEI]aaa [HUAWEI-aaa]local-aaa-user password policy administrator [HUAWEI-aaa-lupp-admin]password complexity three-of-kinds 2、本地用户名长度必须大…...

【RAG入门教程04】Langchian的文档切分
在 Langchain 中,文档转换器是一种在将文档提供给其他 Langchain 组件之前对其进行处理的工具。通过清理、处理和转换文档,这些工具可确保 LLM 和其他 Langchain 组件以优化其性能的格式接收数据。 上一章我们了解了文档加载器,加载完文档之…...
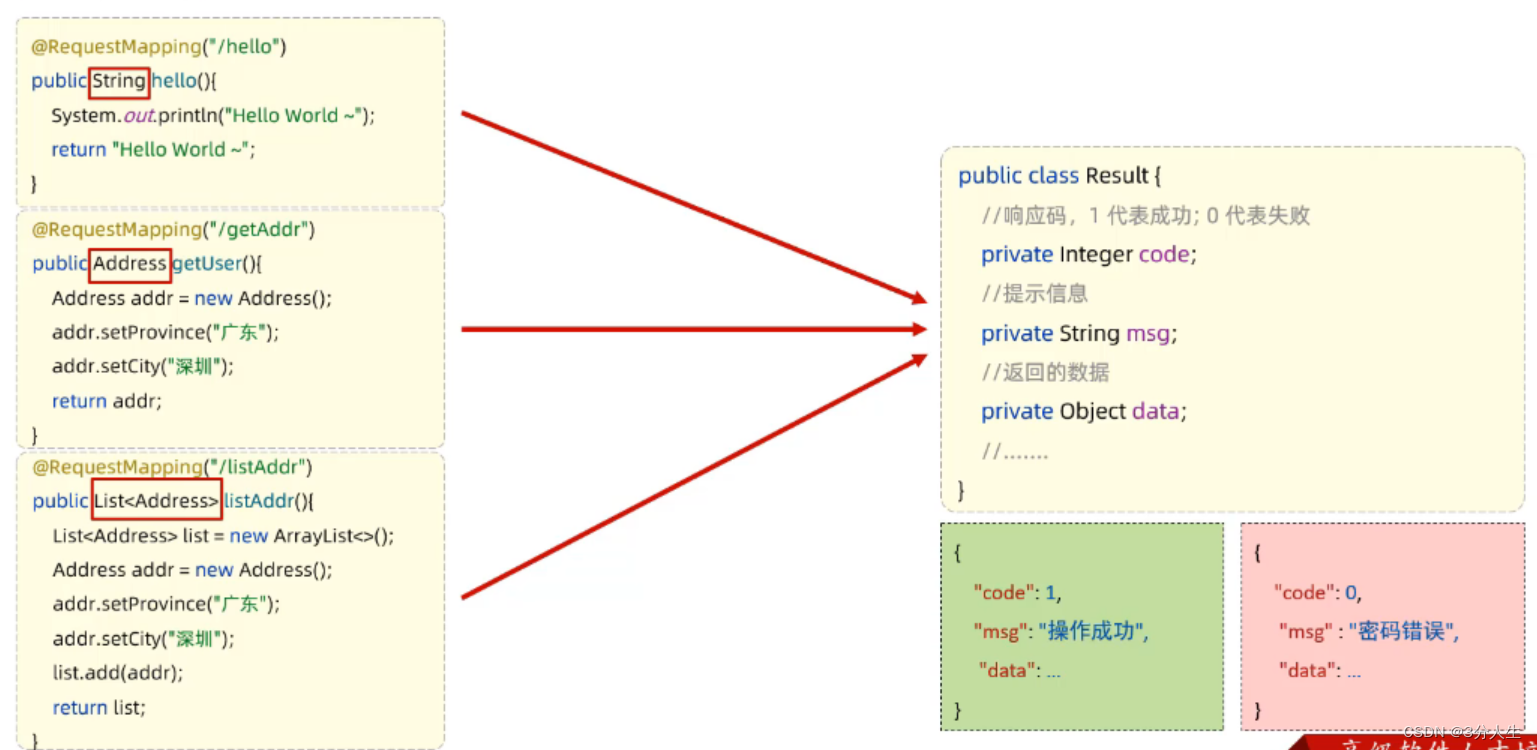
请求 响应
在web的前后端分离开发过程中,前端发送请求给后端,后端接收请求,响应数据给前端 请求 前端发送数据进行请求 简单参数 原始方式 在原始的web程序中,获取请求参数,需要通过HttpServletRequest 对象手动获取。 代码…...
)
技术周总结2024.06.03~06.09(K8S HikariCP数据库连接池)
文章目录 一、06.05 周三1.1) 问题01: 容器领域,Docker与 K8S的区别和联系Docker主要功能和特点:使用场景: Kubernetes (K8S)主要功能和特点:使用场景: 联系和区别联系:区别: 结合使用总结 二、…...

【JavaScript】了解 Sass:现代 CSS 的强大预处理器
我已经从你的 全世界路过 像一颗流星 划过命运 的天空 很多话忍住了 不能说出口 珍藏在 我的心中 只留下一些回忆 🎵 牛奶咖啡《从你的全世界路过》 在前端开发领域,CSS 是必不可少的样式表语言。然而,随着项目复杂度的…...

下载安装Thonny并烧录MicroPython固件至ESP32
Thonny介绍 一、Thonny的基本特点 面向初学者:Thonny的设计初衷是为了帮助Python初学者更轻松、更快速地入门编程。它提供了直观易懂的用户界面和丰富的功能,降低了编程的门槛。轻量级:作为一款轻量级的IDE,Thonny不会占用过多的…...
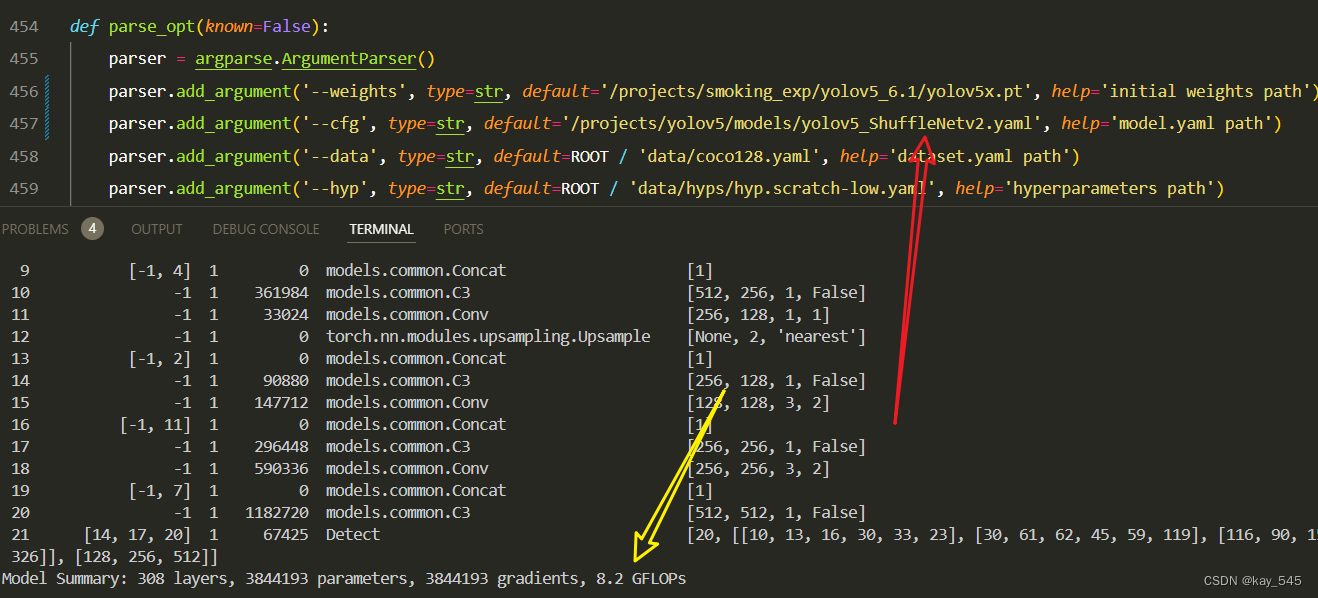
YOLOv5改进 | 主干网络 | 将主干网络替换为轻量化的ShuffleNetv2【原理 + 完整代码】
💡💡💡本专栏所有程序均经过测试,可成功执行💡💡💡 目标检测是计算机视觉中一个重要的下游任务。对于边缘盒子的计算平台来说,一个大型模型很难实现实时检测的要求。基于一系列消融…...

AI决策公平性:司法审查下的技术实践与算法治理
1. 项目概述:当算法成为“法官”,公平如何被审查?最近几年,我参与和观察了不少涉及算法决策的项目,从信贷审批到招聘筛选,再到内容推荐。一个越来越无法回避的问题是:当AI系统代替人类做出影响个…...

Gemma 4大模型实战:从架构解析到生产部署与微调
1. 项目概述:为什么我们需要深入理解Gemma 4?如果你最近在关注开源大模型领域,一定绕不开“Gemma”这个名字。从年初Gemma 2B/7B的惊艳亮相,到如今关于下一代架构的种种猜测,Google的Gemma系列正以一种稳健而有力的姿态…...

终极指南:Python通达信数据接口MOOTDX完整使用教程
终极指南:Python通达信数据接口MOOTDX完整使用教程 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx MOOTDX是一款基于Python的高效通达信数据接口封装,专为量化投资和金融数…...

基于Node.js与Telegraf构建支持双历法的Telegram天气机器人
1. 项目概述:一个功能完备的Telegram天气机器人 最近在做一个需要集成天气信息的小项目,顺手就把之前写的一个Telegram天气机器人翻新重构了一遍。这个机器人不只是简单地查询温度,它融合了实时天气、24小时预报,并且特别加入了波…...

ThunderAI:开源本地AI助手桌面应用部署与核心架构解析
1. 项目概述:一个开源的AI助手桌面应用 最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“ThunderAI”。这名字听起来就挺带劲,对吧?点进去一看,是个用Python写的桌面应用程序,核心功能是把几个…...

Java——Character
Character1、Unicode基础2、检查code point和char3、code point与char的转换4、按code point处理char数组或序列5、字符属性6、字符转换1、Unicode基础 Unicode给世界上每个字符分配了一个编号,编号范围为0x000000~0x10FFFF。编号范围在0x0000ÿ…...

FPGA LVDS输入作为模拟比较器的原理、设计与工程实践
1. 项目概述:当LVDS输入遇上模拟电压 最近几年,各大FPGA厂商都在力推自家的“模拟-数字转换器(ADC)IP核”,宣传其如何集成便利、性能优越。这让我这个老工程师不禁琢磨,这些IP核的底层原理究竟是什么&#…...

数说故事解读AI品牌心智:让品牌被AI看见、推荐与信任
当AI全面进入商业决策、智能体成为企业标配,品牌增长逻辑正在发生底层重构:品牌不再只是面对消费者,更需要被AI识别、理解、推荐与信任。数说故事在2026 D3智慧增长大会上提出全新观点——AI品牌心智,将成为AI共生时代品牌最重要的…...

PLC编程入门学习路径
PLC编程入门学习路径基础概念理解PLC(可编程逻辑控制器)是一种工业自动化控制设备。需要理解其工作原理、硬件组成(CPU、I/O模块、电源等)以及常见的品牌(如西门子、三菱、欧姆龙)。编程语言学习PLC常用编程…...
函数参数详解与常见错误排查)
R语言数据清洗避坑指南:melt()函数参数详解与常见错误排查
R语言数据清洗避坑指南:melt()函数参数详解与常见错误排查 数据清洗是数据分析过程中最关键的环节之一,而R语言中的melt()函数作为数据重塑的利器,在实际应用中却常常让用户陷入各种"坑"。本文将深入剖析melt()函数的参数设置与常见…...