AI-知识库搭建(一)腾讯云向量数据库使用
一、AI知识库
将已知的问答知识,问题和答案转变成向量存储在向量数据库,在查找答案时,输入问题,将问题向量化,匹配向量库的问题,将向量相似度最高的问题筛选出来,将答案提交。
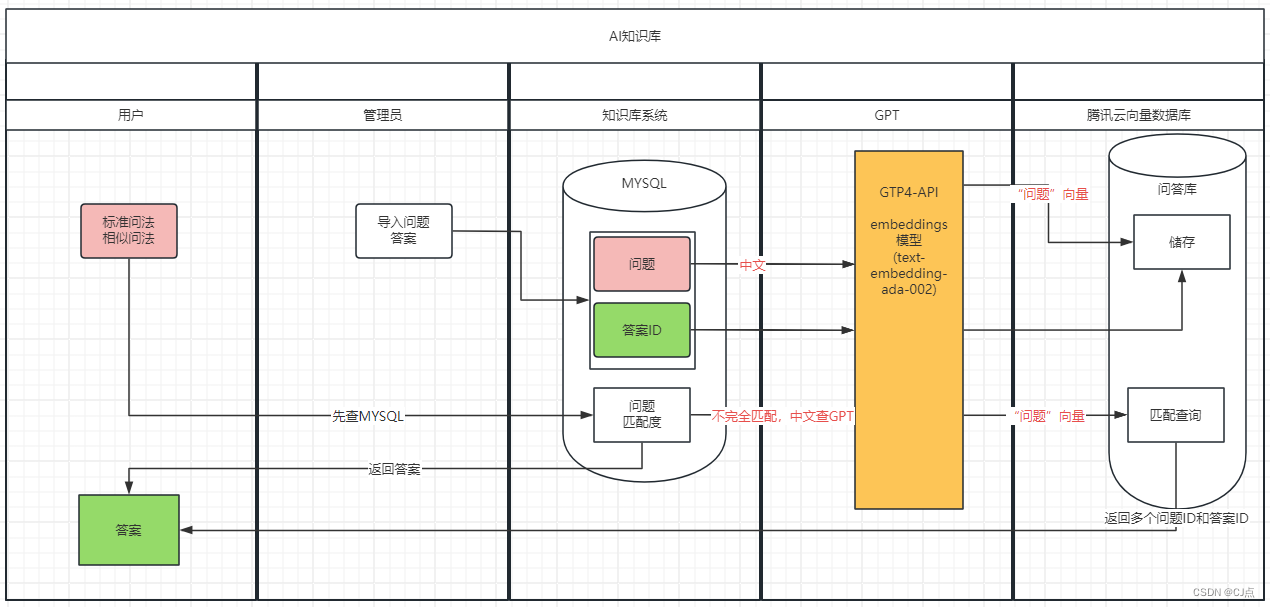
二、腾讯云向量数据库
向量数据库_大模型知识库_向量数据存储_向量数据检索- 腾讯云
腾讯云向量数据库(Tencent Cloud VectorDB)是一款全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据。该数据库支持多种索引类型和相似度计算方法,单索引支持千亿级向量规模,可支持百万级 QPS 及毫秒级查询延迟。腾讯云向量数据库不仅能为大模型提供外部知识库,提高大模型回答的准确性,还可广泛应用于推荐系统、自然语言处理等 AI 领域。
三、使用教程(java)
1、项目引用依赖
<!--腾讯云向量数据库使用--><dependency><groupId>com.tencent.tcvectordb</groupId><artifactId>vectordatabase-sdk-java</artifactId><version>1.2.0</version></dependency>2、application.properties 配置
#向量数据库地址-购买服务器后,获取到外网访问域名,账号密码
vectordb.url=${VECTORDB_URL:http://xxxxxxxxx.com:10000}
vectordb.user=${VECTORDB_USER:root}
vectordb.key=${VECTORDB_KEY:123456}3、初始化客户端
import com.tencent.tcvectordb.client.VectorDBClient;
import com.tencent.tcvectordb.model.param.database.ConnectParam;
import com.tencent.tcvectordb.model.param.enums.ReadConsistencyEnum;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;@Component
public class InitVectorClient {@Value("${vectordb.url:}")private String vdbUrl;@Value("${vectordb.user:}")private String vdbUser;@Value("${vectordb.key:}")private String vdbKey;@Beanpublic VectorDBClient vdbClient(){ConnectParam connectParam = ConnectParam.newBuilder().withUrl(vdbUrl).withUsername(vdbUser).withKey(vdbKey).withTimeout(30).build();VectorDBClient client = new VectorDBClient(connectParam, ReadConsistencyEnum.EVENTUAL_CONSISTENCY);return client;}}
4、创建表结构
这里使用HTTP的方式
curl --location --request POST 'xxxxx.com:10000/database/create' \
--header 'Authorization: Bearer account=root&api_key=123456' \
--header 'Content-Type: application/json' \
--data-raw '{"database": "db_xiaosi"
}'curl --location --request POST 'xxxxx.com:10000/collection/create' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer account=root&api_key=123456' \
--data-raw '{"database": "db_xiaosi","collection": "t_bug","replicaNum": 0,"shardNum": 1,"description": "BUG表关键字向量","indexes": [{"fieldName": "id","fieldType": "string","indexType": "primaryKey"},{"fieldName": "bug_name","fieldType": "string","indexType": "filter"},{"fieldName": "is_deleted","fieldType": "uint64","indexType": "filter"},{"fieldName": "vector","fieldType": "vector","indexType": "HNSW","dimension": 1536,"metricType": "COSINE","params": {"M": 16,"efConstruction": 200}}]
}'5、封装http请求类
package com.ikscrm.platform.api.manager.bug;import cn.hutool.core.date.DateUtil;
import com.ikscrm.platform.api.dao.vector.BugVector;
import com.tencent.tcvectordb.client.VectorDBClient;
import com.tencent.tcvectordb.model.Collection;
import com.tencent.tcvectordb.model.Database;
import com.tencent.tcvectordb.model.DocField;
import com.tencent.tcvectordb.model.Document;
import com.tencent.tcvectordb.model.param.dml.*;
import com.tencent.tcvectordb.model.param.entity.AffectRes;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;/*** 向量数据库能力* 接口文档 https://cloud.tencent.com/document/product/1709/97768* 错误码 https://cloud.tencent.com/document/product/1709/104047* @Date 2024/3/6 13:49*/
@Component
@Slf4j
public class VectorManager {@Resourceprivate VectorDBClient vdbClient;/*** 根据向量查询相似数据。** @param dbName 数据库名称* @param tableName 表名称* @param vector 向量* @return 返回更新操作影响的记录数* @throws RuntimeException 如果更新过程中发生业务异常*/public List<BugVector> findBugList(String dbName, String tableName, List<Double> vector) {List<BugVector> resultList = new ArrayList<>();Database database = vdbClient.database(dbName);Collection collection = database.describeCollection(tableName);Filter filter = new Filter("is_deleted=0");//这部分的算法需要深入了解SearchByVectorParam searchByVectorParam = SearchByVectorParam.newBuilder().addVector(vector)// 若使用 HNSW 索引,则需要指定参数ef,ef越大,召回率越高,但也会影响检索速度.withParams(new HNSWSearchParams(15))// 指定 Top K 的 K 值.withLimit(20)// 过滤获取到结果.withFilter(filter).build();// 输出相似性检索结果,检索结果为二维数组,每一位为一组返回结果,分别对应 search 时指定的多个向量List<List<Document>> svDocs = collection.search(searchByVectorParam);for (List<Document> docs : svDocs) {for (Document doc : docs) {BugVector build = new BugVector();build.setId(doc.getId());build.setScore(doc.getScore());build.setVector(doc.getVector());for (DocField field : doc.getDocFields()) {if (field.getName().equals("bug_name")) {build.setBugName(field.getStringValue());}if (field.getName().equals("bug_title")) {build.setBugTitle(field.getStringValue());}if (field.getName().equals("is_deleted")) {build.setIsDeleted(Integer.valueOf(field.getStringValue()));}if (field.getName().equals("create_time")) {build.setCreateTime(field.getStringValue());}if (field.getName().equals("update_time")) {build.setUpdateTime(field.getStringValue());}}resultList.add(build);}}return resultList;}/*** 将问题向量列表插入到指定的数据库和集合中。** @param dbName 数据库名称,指定要操作的数据库。* @param tableName 集合名称,即数据表名称,指定要插入数据的表。* @param list 要插入的数据列表,列表中的每个元素都是TaskVector类型,包含了问题的向量信息及其他相关字段。*/public Long insertBugList(String dbName, String tableName, List<BugVector> list) {try {Database database = vdbClient.database(dbName);Collection collection = database.describeCollection(tableName);List<Document> documentList = new ArrayList<>();list.forEach(item -> {documentList.add(Document.newBuilder().withId(item.getId()).withVector(item.getVector()).addDocField(new DocField("bug_name", item.getBugName())).addDocField(new DocField("bug_title", item.getBugTitle())).addDocField(new DocField("is_deleted", item.getIsDeleted())).addDocField(new DocField("create_time", DateUtil.now())).addDocField(new DocField("update_time", DateUtil.now())).build());});InsertParam insertParam = InsertParam.newBuilder().addAllDocument(documentList).build();
// upsert 实际数据会有延迟AffectRes upsert = collection.upsert(insertParam);log.info("向量列表插入数量:{},完成:{}", list.size(), upsert.getAffectedCount());return upsert.getAffectedCount();} catch (Exception ex) {log.error("向量列表插入异常", ex);throw new RuntimeException("向量列表插入异常" + ex.getMessage());}}
}
腾讯云的向量库使用方式基本就是这样着,在这里简单的使用到了他的插入和向量查询功能。下一篇讲解GPT的如何与向量数据库结合使用
AI-知识库搭建(二)GPT-Embedding模式使用-CSDN博客
相关文章:
AI-知识库搭建(一)腾讯云向量数据库使用
一、AI知识库 将已知的问答知识,问题和答案转变成向量存储在向量数据库,在查找答案时,输入问题,将问题向量化,匹配向量库的问题,将向量相似度最高的问题筛选出来,将答案提交。 二、腾讯云向量数…...

AI数据分析:根据Excel表格数据绘制柱形图
工作任务:将Excel文件中2013年至2019年间线上图书的销售额,以条形图的形式呈现,每个条形的高度代表相应年份的销售额,同时在每个条形上方标注具体的销售额数值 在deepseek中输入提示词: 你是一个Python编程专家&#…...
基于协调过滤算法商品推荐系统的设计
管理员账户功能包括:系统首页,个人中心,商品管理,论坛管理,商品资讯管理 前台账户功能包括:系统首页,个人中心,论坛,商品资讯,商家,商品 开发系统…...

CS1061 “HtmlHelper”未包含“Partial”的定义,并且找不到可接受第一个“HtmlHelper”类型参数的可访问扩展方法“Partial”
严重性 代码 说明 项目 文件 行 禁止显示状态 错误 CS1061 “HtmlHelper”未包含“Partial”的定义,并且找不到可接受第一个“HtmlHelper”类型参数的可访问扩展方法“Partial”(是否缺少 using 指令或程序集引用?) 14_Views_Message_E…...


在知识的海洋中航行:问题的演变与智慧的追求
在信息技术迅猛发展的今天,互联网和人工智能已成为我们生活中不可或缺的一部分。它们像是一座座灯塔,照亮了知识的海洋,使得曾经难以触及的知识变得触手可及。随着这些技术的普及,越来越多的问题能够迅速得到答案。然而࿰…...
、slice()、split()三种方法的区别)
splice()、slice()、split()三种方法的区别
slice slice() 方法返回一个新的数组对象,这一对象是一个由 start 和 end 决定的原数组的浅拷贝(包括 start,不包括 end),其中 start 和 end 代表了数组元素的索引。原始数组不会被改变。 const animals [ant, bison…...
iOS 之homebrew ruby cocoapods 安装
cocoapods安装需要ruby,更新ruby需要rvm,下载rvm需要gpg,下载gpg需要homebrew,所以安装顺序是homebrew->gpg->rvm->ruby-cocoapods Rvm 官网: RVM: Ruby Version Manager - RVM Ruby Version Manager - Docum…...

【栈】2751. 机器人碰撞
本文涉及知识点 栈 LeetCode2751. 机器人碰撞 现有 n 个机器人,编号从 1 开始,每个机器人包含在路线上的位置、健康度和移动方向。 给你下标从 0 开始的两个整数数组 positions、healths 和一个字符串 directions(directions[i] 为 ‘L’ …...

贪心算法06(leetcode738,968)
参考资料: https://programmercarl.com/0738.%E5%8D%95%E8%B0%83%E9%80%92%E5%A2%9E%E7%9A%84%E6%95%B0%E5%AD%97.html 738. 单调递增的数字 题目描述: 当且仅当每个相邻位数上的数字 x 和 y 满足 x < y 时,我们称这个整数是单调递增的。…...

cve_2022_0543-redis沙盒漏洞复现 vulfocus
1. 原理 该漏洞的存在是因为Debian/Ubuntu中的Lua库是作为动态库提供的。自动填充了一个package变量,该变量又允许访问任意 Lua 功能。 2.复现 我们可以尝试payload: eval local io_l package.loadlib("/usr/lib/x86_64-linux-gnu/liblua5.1.so…...
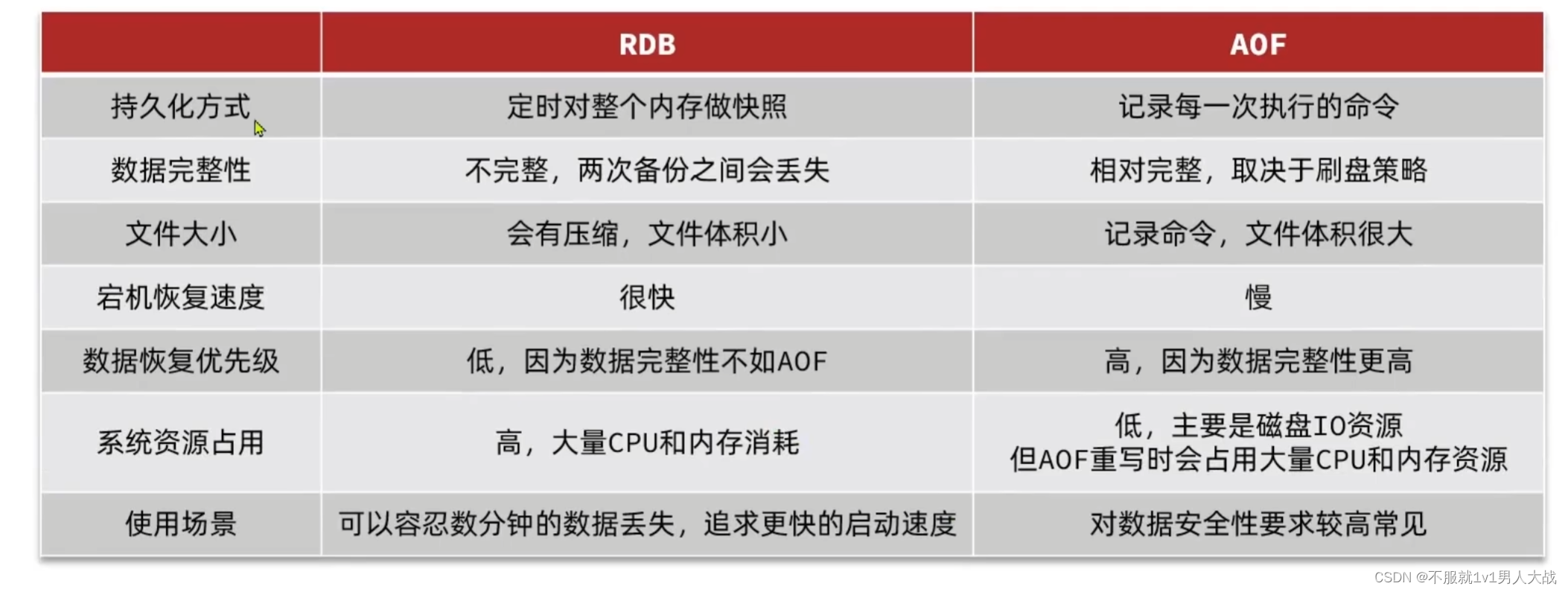
浅解Reids持久化
Reids持久化 RDB redis的存储方式: rdb文件都是二进制,很小,里面存的是数据 实现方式 redis-cli链接到redis服务端 使用save命令 注:不推荐 因为save命令是直接写到磁盘里面,速度特别慢,一般都是redis…...
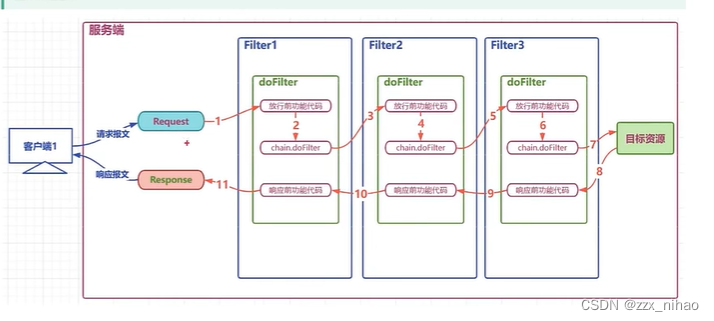
Java24:会话管理 过滤器 监听器
一 会话管理 1.cookie 是一种客户端会话技术,cookie由服务端产生,它是服务器存放在浏览器的一小份数据,浏览器 以后每次访问服务器的时候都会将这小份的数据带到服务器去。 //创建cookie对象 Cookie cookie1new Cookie("…...

web前端电影简介标签:深度解析与创意应用
web前端电影简介标签:深度解析与创意应用 在web前端开发中,电影简介标签的设计与实现是一项既具挑战性又充满创意的任务。这些标签不仅需要准确传达电影的核心信息,还要通过精美的设计和交互效果吸引用户的眼球。本文将从四个方面、五个方面…...

Java面向对象-方法的重写、super
Java面向对象-方法的重写、super 一、方法的重写二、super关键字1、super可以省略2、super不可以省略3、super修饰构造器4、继承条件下构造方法的执行过程 一、方法的重写 1、发生在子类和父类中,当子类对父类提供的方法不满意的时候,要对父类的方法进行…...

解锁ChatGPT:从GPT-2实践入手解密ChatGPT
⭐️我叫忆_恒心,一名喜欢书写博客的研究生👨🎓。 如果觉得本文能帮到您,麻烦点个赞👍呗! 近期会不断在专栏里进行更新讲解博客~~~ 有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三连支…...
20240605解决飞凌的OK3588-C的核心板刷机原厂buildroot不能连接ADB的问题
20240605解决飞凌的OK3588-C的核心板刷机原厂buildroot不能连接ADB的问题 2024/6/5 13:53 rootrootrootroot-ThinkBook-16-G5-IRH:~/repo_RK3588_Buildroot20240508$ ./build.sh --help rootrootrootroot-ThinkBook-16-G5-IRH:~/repo_RK3588_Buildroot20240508$ ./build.sh lun…...

c++手写的bitset
支持stl bitset 类似的api #include <iostream> #include <vector> #include <climits> #include <utility> #include <stdexcept> #include <iterator>using namespace std;const int W 64;class Bitset { private:vector<unsigned …...
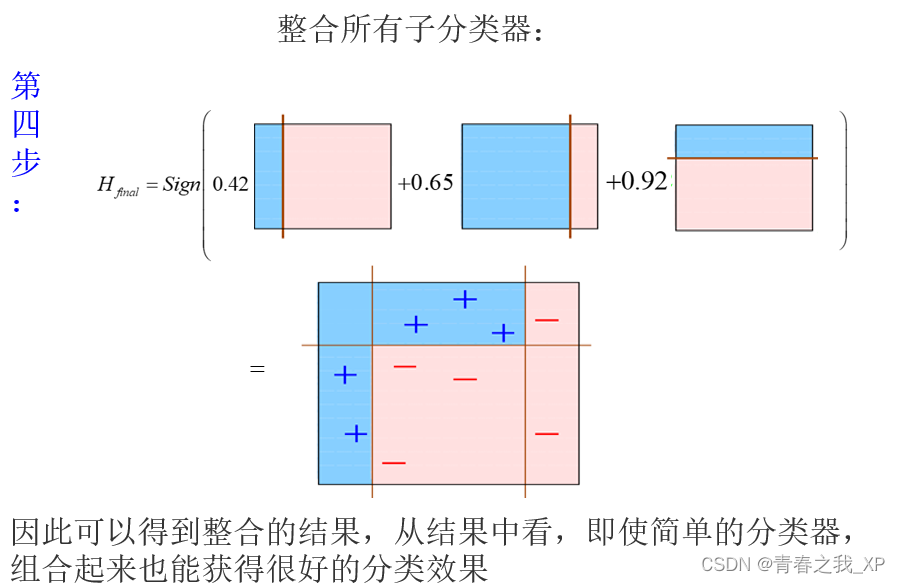
【机器学习系列】深入理解集成学习:从Bagging到Boosting
目录 一、集成方法的一般思想 二、集成方法的基本原理 三、构建集成分类器的方法 常见的有装袋(Bagging)和提升(Boosting)两种方法 方法1 :装袋(Bagging) Bagging原理如下图: …...

用FFMPEG对YUV序列进行编辑的笔记
还是单独开一个吧 每次找挺烦的 播放YUV序列 ffmpeg -f rawvideo -pix_fmt yuv420p -s 3840x2160 -i "Wood.yuv" -vf "scale1280x720" -c:v rawvideo -pix_fmt yuv420p -f sdl "Wood"4K序列转720P ffmpeg -f rawvideo -pix_fmt yuv420p -s 38…...

Filecoin挖矿硬件怎么选?用Lotus-bench实测RTX 2080 Ti到GTX 1060的密封性能
Filecoin挖矿硬件实战指南:从GPU选型到Lotus-bench深度优化 在Filecoin挖矿生态中,GPU性能直接决定了密封效率和区块奖励获取能力。面对市场上从高端RTX 2080 Ti到入门级GTX 1060的各类显卡,矿工往往陷入选择困境——官方推荐列表中的参数是否…...

基于CCS811与CircuitPython的可穿戴呼吸监测面具制作全解析
1. 项目概述与核心价值 几年前,当我第一次接触到可穿戴健康设备时,就被其潜力深深吸引。但市面上的产品要么是封闭的“黑盒”,数据不透明;要么价格高昂,难以进行个性化定制。我一直想,能不能自己动手做一个…...

为什么Delorean是Python时间处理的最佳选择?
为什么Delorean是Python时间处理的最佳选择? 【免费下载链接】delorean Delorean: Time Travel Made Easy 项目地址: https://gitcode.com/gh_mirrors/de/delorean 在Python开发中,时间处理常常是一个令人头疼的问题,尤其是涉及到时区…...

5分钟搞定Windows和Office永久激活:智能KMS工具完全指南
5分钟搞定Windows和Office永久激活:智能KMS工具完全指南 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office文档突然变成…...

突破性ARM架构兼容方案:Box86揭秘x86程序在ARM设备上的运行奥秘
突破性ARM架构兼容方案:Box86揭秘x86程序在ARM设备上的运行奥秘 【免费下载链接】box86 Box86 - Linux Userspace x86 Emulator with a twist, targeted at ARM Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box86 你是否曾想过,在…...

构建智能增量更新插件:Softer-Delta算法与工程实践
1. 项目概述与核心价值最近在折腾一些自动化工作流,发现很多场景下,我们都需要一个能“聪明”地处理文件差异、生成补丁,并且能无缝集成到现有工具链里的插件。这让我想起了之前用过的一个叫pear-plugin的工具,它挂在Softer-delta…...

无电池RF无线供电电子货架标签系统设计
1. 项目概述在零售和物流行业中,电子货架标签(ESL)正逐步取代传统的纸质标签。传统ESL通常依赖纽扣电池供电,但电池更换带来的维护成本和环境影响日益凸显。我们团队基于商用现成组件(COTS)设计了一套完全无…...

别再只跑Demo了!用Mask R-CNN和Balloon数据集实战,手把手教你从训练到可视化调参
从Demo到实战:用Mask R-CNN深入掌握目标分割全流程 当你第一次运行Mask R-CNN的官方示例时,那种"成功运行"的喜悦往往伴随着隐约的不安——代码虽然跑通了,但你真的理解模型是如何训练的吗?Balloon数据集作为经典的入门…...

当机器人遇见城市:江南北如何重塑武汉的智能生活图景
城市,是人类文明的结晶,也是科技创新的试验场。在武汉这座英雄的城市,一场由江南北(武汉)信息技术有限公司(简称“江南北机器人”)引领的智能革命,正悄然改变着市民的日常生活与城市…...

D2RML:暗黑破坏神2重制版多开终极指南,告别繁琐登录流程
D2RML:暗黑破坏神2重制版多开终极指南,告别繁琐登录流程 【免费下载链接】D2RML Diablo 2 Resurrected Multilauncher 项目地址: https://gitcode.com/gh_mirrors/d2/D2RML 还在为暗黑破坏神2重制版的多账户切换而烦恼吗?每次登录战网…...