保姆级使用PyTorch训练与评估自己的EfficientNetV2网络教程

文章目录
- 前言
- 0. 环境搭建&快速开始
- 1. 数据集制作
- 1.1 标签文件制作
- 1.2 数据集划分
- 1.3 数据集信息文件制作
- 2. 修改参数文件
- 3. 训练
- 4. 评估
- 5. 其他教程
前言
项目地址:https://github.com/Fafa-DL/Awesome-Backbones
操作教程:https://www.bilibili.com/video/BV1SY411P7Nd
EfficientNetV2原论文:点我跳转
如果你以为该仓库仅支持训练一个模型那就大错特错了,我在项目地址放了目前支持的42种模型(LeNet5、AlexNet、VGG、DenseNet、ResNet、Wide-ResNet、ResNeXt、SEResNet、SEResNeXt、RegNet、MobileNetV2、MobileNetV3、ShuffleNetV1、ShuffleNetV2、EfficientNet、RepVGG、Res2Net、ConvNeXt、HRNet、ConvMixer、CSPNet、Swin-Transformer、Vision-Transformer、Transformer-in-Transformer、MLP-Mixer、DeiT、Conformer、T2T-ViT、Twins、PoolFormer、VAN、HorNet、EfficientFormer、Swin Transformer V2、MViT V2、MobileViT、DaViT、RepLKNet、BEiT、EVA、MixMIM、EfficientNetV2),使用方式一模一样。且目前满足了大部分图像分类需求,进度快的同学甚至论文已经在审了
0. 环境搭建&快速开始
- 这一步我也在最近录制了视频
最新Windows配置VSCode与Anaconda环境
『图像分类』从零环境搭建&快速开始
- 不想看视频也将文字版放在此处。建议使用Anaconda进行环境管理,创建环境命令如下
conda create -n [name] python=3.6 其中[name]改成自己的环境名,如[name]->torch,conda create -n torch python=3.6
- 我的测试环境如下
torch==1.7.1
torchvision==0.8.2
scipy==1.4.1
numpy==1.19.2
matplotlib==3.2.1
opencv_python==3.4.1.15
tqdm==4.62.3
Pillow==8.4.0
h5py==3.1.0
terminaltables==3.1.0
packaging==21.3
- 首先安装Pytorch。建议版本和我一致,进入Pytorch官网,点击
install previous versions of PyTorch,以1.7.1为例,官网给出的安装如下,选择合适的cuda版本
# CUDA 11.0
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html# CUDA 10.2
pip install torch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2# CUDA 10.1
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html# CUDA 9.2
pip install torch==1.7.1+cu92 torchvision==0.8.2+cu92 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html# CPU only
pip install torch==1.7.1+cpu torchvision==0.8.2+cpu torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
- 安装完Pytorch后,再运行
pip install -r requirements.txt
- 下载MobileNetV3-Small权重至datas下
- Awesome-Backbones文件夹下终端输入
python tools/single_test.py datas/cat-dog.png models/mobilenet/mobilenet_v3_small.py --classes-map datas/imageNet1kAnnotation.txt
1. 数据集制作
1.1 标签文件制作
-
将项目代码下载到本地
-
本次演示以花卉数据集为例,目录结构如下:
├─flower_photos
│ ├─daisy
│ │ 100080576_f52e8ee070_n.jpg
│ │ 10140303196_b88d3d6cec.jpg
│ │ ...
│ ├─dandelion
│ │ 10043234166_e6dd915111_n.jpg
│ │ 10200780773_c6051a7d71_n.jpg
│ │ ...
│ ├─roses
│ │ 10090824183_d02c613f10_m.jpg
│ │ 102501987_3cdb8e5394_n.jpg
│ │ ...
│ ├─sunflowers
│ │ 1008566138_6927679c8a.jpg
│ │ 1022552002_2b93faf9e7_n.jpg
│ │ ...
│ └─tulips
│ │ 100930342_92e8746431_n.jpg
│ │ 10094729603_eeca3f2cb6.jpg
│ │ ...
- 在
Awesome-Backbones/datas/中创建标签文件annotations.txt,按行将类别名 索引写入文件;
daisy 0
dandelion 1
roses 2
sunflowers 3
tulips 4

1.2 数据集划分
- 打开
Awesome-Backbones/tools/split_data.py - 修改
原始数据集路径以及划分后的保存路径,强烈建议划分后的保存路径datasets不要改动,在下一步都是默认基于文件夹进行操作
init_dataset = 'A:/flower_photos' # 改为你自己的数据路径
new_dataset = 'A:/Awesome-Backbones/datasets'
- 在
Awesome-Backbones/下打开终端输入命令:
python tools/split_data.py
- 得到划分后的数据集格式如下:
├─...
├─datasets
│ ├─test
│ │ ├─daisy
│ │ ├─dandelion
│ │ ├─roses
│ │ ├─sunflowers
│ │ └─tulips
│ └─train
│ ├─daisy
│ ├─dandelion
│ ├─roses
│ ├─sunflowers
│ └─tulips
├─...
1.3 数据集信息文件制作
- 确保划分后的数据集是在
Awesome-Backbones/datasets下,若不在则在get_annotation.py下修改数据集路径;
datasets_path = '你的数据集路径'
- 在
Awesome-Backbones/下打开终端输入命令:
python tools/get_annotation.py
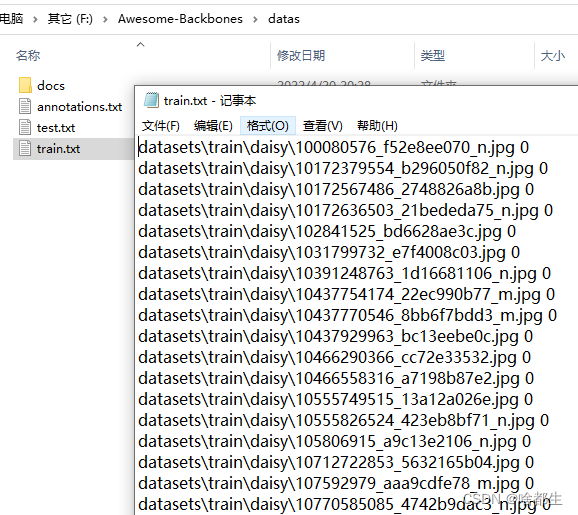
- 在
Awesome-Backbones/datas下得到生成的数据集信息文件train.txt与test.txt
2. 修改参数文件
-
每个模型均对应有各自的配置文件,保存在
Awesome-Backbones/models下 -
由
backbone、neck、head、head.loss构成一个完整模型 -
找到EfficientNetV2参数配置文件,可以看到
所有支持的类型都在这,且每个模型均提供预训练权重

-
在
model_cfg中修改num_classes为自己数据集类别大小 -
按照自己电脑性能在
data_cfg中修改batch_size与num_workers -
若有预训练权重则可以将
pretrained_weights设置为True并将预训练权重的路径赋值给pretrained_weights -
若需要冻结训练则
freeze_flag设置为True,可选冻结的有backbone, neck, head -
在
optimizer_cfg中修改初始学习率,根据自己batch size调试,若使用了预训练权重,建议学习率调小 -
学习率更新详见
core/optimizers/lr_update.py,同样准备了视频『图像分类』学习率更新策略|优化器 -
更具体配置文件修改可参考配置文件解释,同样准备了视频『图像分类』配置文件补充说明
3. 训练
- 确认
Awesome-Backbones/datas/annotations.txt标签准备完毕 - 确认
Awesome-Backbones/datas/下train.txt与test.txt与annotations.txt对应 - 选择想要训练的模型,在
Awesome-Backbones/models/下找到对应配置文件,以efficientnetv2_b0为例 - 按照
配置文件解释修改参数 - 在
Awesome-Backbones路径下打开终端运行
python tools/train.py models/efficientnetv2/efficientnetv2_b0.py

4. 评估
- 确认
Awesome-Backbones/datas/annotations.txt标签准备完毕 - 确认
Awesome-Backbones/datas/下test.txt与annotations.txt对应 - 在
Awesome-Backbones/models/下找到对应配置文件 - 在参数配置文件中
修改权重路径,其余不变
ckpt = '你的训练权重路径'
- 在
Awesome-Backbones路径下打开终端运行
python tools/evaluation.py models/efficientnetv2/efficientnetv2_b0.py

- 单张图像测试,在
Awesome-Backbones打开终端运行
python tools/single_test.py datasets/test/dandelion/14283011_3e7452c5b2_n.jpg models/efficientnetv2/efficientnetv2_b0.py

至此完毕,实在没运行起来就去B站看我手把手带大家运行的视频教学吧~
5. 其他教程
除开上述,我还为大家准备了其他一定用到的操作教程,均放在了GitHub项目首页,为了你们方便为也粘贴过来
- 环境搭建
- 数据集准备
- 配置文件解释
- 训练
- 模型评估&批量检测/视频检测
- 计算Flops&Params
- 添加新的模型组件
- 类别激活图可视化
- 学习率策略可视化
有任何更新均会在Github与B站进行通知,记得Star与三连关注噢~
相关文章:
保姆级使用PyTorch训练与评估自己的EfficientNetV2网络教程
文章目录前言0. 环境搭建&快速开始1. 数据集制作1.1 标签文件制作1.2 数据集划分1.3 数据集信息文件制作2. 修改参数文件3. 训练4. 评估5. 其他教程前言 项目地址:https://github.com/Fafa-DL/Awesome-Backbones 操作教程:https://www.bilibili.co…...

【9】基础语法篇 - VL9 使用子模块实现三输入数的大小比较
VL9 使用子模块实现三输入数的大小比较 【报错】官方平台得背锅 官方平台是真的会搞事情,总是出一些平台上的莫名其妙的错误。 当然如果官方平台是故意考察我们的细心程度,那就当我没有说!! 在这个程序里,仿真时一直在报错 错误:无法在“test”中绑定wire/reg/memory“t…...

成功的项目管理策略:减少成本,提高质量
项目管理是一项具有挑战性的任务,项目团队需要合理的规划和策略,以确保项目的成功和达成预期。为了实现项目的成功,项目经理必须采用正确的策略,才能以最大限度地减少成本并提高项目质量。本文将探讨成功的项目管理策略࿰…...

centos 7下JDK8安装
下载安装包https://www.oracle.com/java/technologies/downloads/#java8-linux上传路径 /usr/local(替换为自己需要安装的路径)解压tar -zxvf jdk-8u131-linux-x64.tar.gz配置环境变量[rootlocalhost java]# vi /etc/profile添加如下配置在配置文件最后&…...

datatables.js中文项目使用案例
官方下载地址https://datatables.net/download/中文官网:http://datatables.club/资源引用<link href"~/datatables/datatables.min.css" rel"stylesheet" /> <script src"~/jquery.min.js" type"text/javascript"…...

Hadoop小结
Hadoop是什么Hadoop是一 个由Apache基金 会所开发的分布式系统基础架构。主要解决,海量数据的存储和海量数据的分析计算问题。广义上来说,Hadoop通 常是指一个更广泛的概念一Hadoop 生态圈。Hadoop优势Hadoop组成HDFS架构Hadoop Distributed File System,…...
)
经典卷积模型回顾14—vgg16实现图像分类(tensorflow)
VGG16是由牛津大学计算机视觉小组(Visual Geometry Group)开发的深度卷积神经网络模型。其结构由16层组成,其中13层是卷积层,3层是全连接层。 VGG16被广泛应用于各种计算机视觉任务,如图像分类、目标检测和人脸识别等。…...

#Vue2篇:keep-alive的属性和方法
定义 keep-alive 组件是 Vue.js 内置的一个高阶组件,用于缓存其子组件,以提高组件的性能和响应速度。 除了基本用法之外,它还提供了一些属性和方法,以便更好地控制缓存的组件。 属性 include属性用于指定哪些组件应该被缓存&a…...
webpack指南(项目篇)——webpack在项目中的运用
系列文章目录 webpack指南(基础篇)——手把手教你配置webpack webpack指南(优化篇)——webpack项目优化 文章目录系列文章目录前言一、配置拆分二、修改启动命令三、定义环境变量四、配置路径别名总结前言 前面我们对webpack的基…...
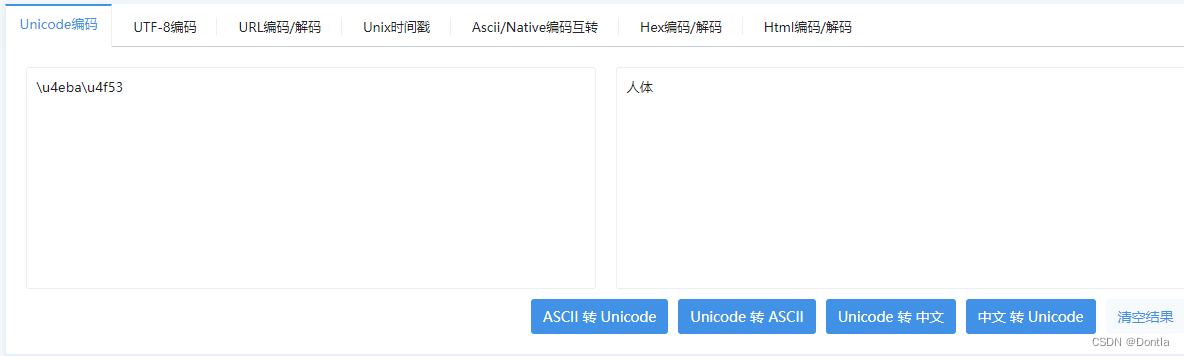
unicode字符集与utf-8编码的区别,unicode转中文工具、中文转unicode工具(汉字)
在cw上报的报警信息中,有一个name字段的值是\u4eba\u4f53 不知道是啥,查了一下,是unicode编码,用下面工具转换成汉字就是“人体” 参考文章:https://tool.chinaz.com/tools/unicode.aspx 那么我很好奇,uni…...

3D数学系列之——再谈特卡洛积分和重要性采样
目录一、前篇文章回顾二、积分的黎曼和形式三、积分的概率形式(蒙特卡洛积分)四、误差五、蒙特卡洛积分计算与收敛速度六、重要性采样七、重要性采样方法和过程八、重要性采样的优缺点一、前篇文章回顾 在前一篇文章3D数学系列之——从“蒙的挺准”到“蒙…...

Python错误 TypeError: ‘NoneType‘ object is not subscriptable解决方案汇总
目录前言一、引发错误来源二、解决方案2-1、解决方案一(检查变量)2-2、解决方案二(使用 [] 而不是 None)2-3、解决方案三(设置默认值)2-4、解决方案四(使用异常处理)2-5、解决方案五…...

VMware空间不足又无法删除快照的解决办法
如果因为快照删除半路取消或者失败,快照管理器就不再显示这个快照,但是其占用的空间还在,最终导致硬盘不足。 可以百度到解决方案,就是在快照管理器,先新建一个,再点删除,等待删除完成就可以将…...
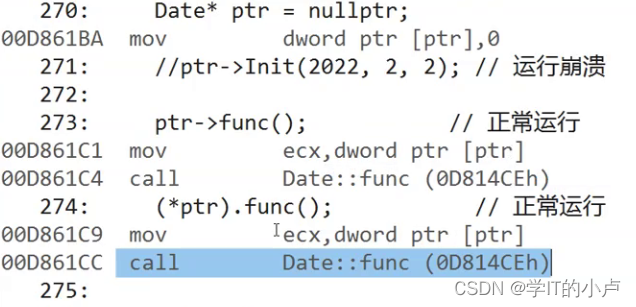
类和对象(一)
类和对象(一) C并不是纯面向对象语言 C是面向过程和面向对象语言的! 面向过程和面向对象初步认识: C语言是面向过程的,关注的是过程,分析出求解问题的步骤,通过函数调用逐步解决问题。 C是基…...
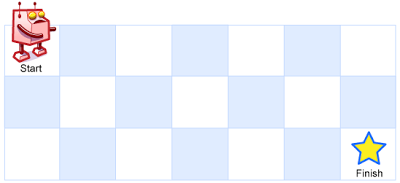
Java 不同路径
不同路径中等一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。问总共有多少条不同的路径?…...

【SAP PO】X-DOC:SAP PO 接口配置 REST 服务对接填坑记
X-DOC:SAP PO 接口配置 REST 服务对接填坑记1、背景2、PO SLD配置3、PO https证书导入1、背景 (1)需求背景: SAP中BOM频繁变更,技术人员在对BOM进行变更后,希望及时通知到相关使用人员 (2&…...
最新研究!美国爱荷华州立大学利用量子计算模拟原子核
爱荷华州立大学物理学和天文学教授James Vary(图片来源:网络)美国爱荷华州立大学物理学和天文学教授James Vary和来自爱荷华州立大学、马萨诸塞州塔夫茨大学,以及美国能源部加利福尼亚州劳伦斯伯克利国家实验室的研究人员…...

零入门kubernetes网络实战-22->基于tun设备实现在用户空间可以ping通外部节点(golang版本)
《零入门kubernetes网络实战》视频专栏地址 https://www.ixigua.com/7193641905282875942 本篇文章视频地址(稍后上传) 本篇文章主要是想做一个测试: 实现的目的是 希望在宿主机-1上,在用户空间里使用ping命令发起ping请求,产生的icmp类型的…...

web安全——Mybatis防止SQL注入 ssrf漏洞利用 DNS污染同源策略
目录 0x01 Mybatis防止SQL注入 0x02 sqlmap中报错注入判断 0x03 ssrf漏洞利用 0x04 SSRF重绑定 0x05 DNS污染...
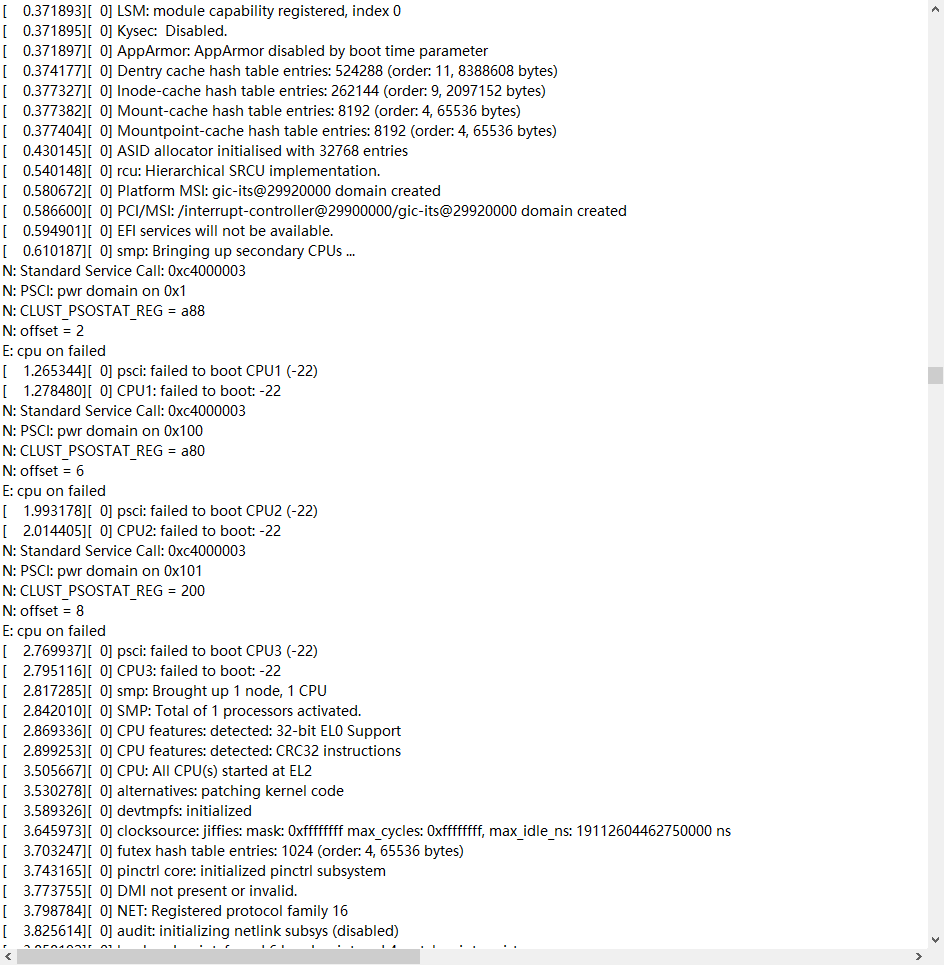
smp_init过程解析
当你看到这样的log,会不会很慌张?竟然由CPU没有启动成功,除了什么故障?本文将结合我遇到的一个问题,将启动过程中bringup secondary cpu的过程分析一下。smp_init代码如下:602 void __init smp_init(void) …...

DDSP与神经音频合成:AI如何复刻经典合成器音色
1. 项目概述:当AI遇见经典合成器如果你和我一样,是个对复古合成器声音着迷,同时又对现代AI技术充满好奇的音乐制作人或开发者,那么最近在GitHub上出现的martinic/DrMixAISynth项目,绝对值得你花上一个下午的时间好好研…...

终极指南:用WarcraftHelper彻底解决魔兽争霸III现代系统兼容性问题
终极指南:用WarcraftHelper彻底解决魔兽争霸III现代系统兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸III在Wi…...
)
STM32CubeMX呼吸灯实战:用TIM3的PWM模式驱动LED(附完整代码与重映射避坑指南)
STM32CubeMX呼吸灯实战:用TIM3的PWM模式驱动LED(附完整代码与重映射避坑指南) 呼吸灯效果是嵌入式开发中经典的PWM应用场景,不仅能直观展示定时器功能,还能为产品增添交互美感。对于STM32开发者而言,利用Cu…...

凌晨还在改论文?这些降重黑科技帮你一键通关
凌晨对着电脑屏幕改论文,那种既疲惫又焦虑的感觉,经历过的人都懂。好在现在的降重工具已经不只是“替换同义词”那么简单了,像 毕业之家 和 PaperRed 这两款主流工具,各自走了完全不同的技术路线,可以根据你的痛点来选…...

别再手动调阈值了!OpenCV实战:用Otsu和自适应阈值搞定光照不均的图片分割
智能图像分割实战:Otsu与自适应阈值技术解决光照不均难题 在工业质检、医疗影像分析、自动驾驶等场景中,图像分割的准确性直接影响最终结果。但现实世界的光照条件往往复杂多变——同一张图片可能同时存在过曝和欠曝区域,传统全局阈值方法在…...
)
避坑指南:在CentOS 7.5上成功安装Ansys 19.2的完整流程(附字体问题终极解决方案)
CentOS 7.5与Ansys 19.2黄金组合:工业仿真环境搭建实战手册 在工程仿真领域,Ansys作为行业标准工具链的核心组件,其Linux环境部署一直是技术人员的痛点。经过长达三个月的多版本交叉测试,我们意外发现CentOS 7.5与Ansys 19.2的组合…...

技术债务的职场政治:谁该为历史遗留问题买单
在软件测试从业者的日常工作中,技术债务是一个绕不开的话题。它像一颗隐藏在代码深处的定时炸弹,随时可能在项目推进的某个节点爆发,引发一系列连锁反应。而当技术债务问题浮出水面时,一场关于“谁该为历史遗留问题买单”的职场政…...

优化ESP32 ADF 音频问题
可以,现在已经进入音质调试阶段了,不是“能不能播放”的阶段。 你现在的问题大概率不是一个单点问题,而是下面几类之一: 1. 音量 / 增益太大,导致 ES8388 或 MD8002A 功放削顶失真 2. I2S 时钟不准,导致声音…...

VCSA 7.0 报 vAPI Endpoint 黄灯告警?别慌,这份保姆级排查与修复指南帮你搞定
VCSA 7.0 vAPI Endpoint黄灯告警全流程诊断手册 凌晨三点,监控系统突然弹出一条告警——vCenter Server的vAPI Endpoint服务状态由绿转黄。作为运维负责人,你需要在最短时间内判断这是需要立即处理的严重故障,还是可以暂缓的偶发异常。本文将…...

保姆级教程:在Google Colab上用TensorFlow 2.0快速搭建你的第一个ACGAN图像生成器
零门槛实战:用ColabTensorFlow打造你的首个ACGAN数字生成器 想象一下,只需点击几次就能让AI学会生成逼真的手写数字——这不再是实验室里的黑科技。我们将利用Google Colab的免费GPU资源,带你用TensorFlow 2.0快速搭建一个能按需求生成特定数…...