Spark安装、解压、配置环境变量、WordCount
Spark
小白的spark学习笔记 2024/5/30 10:14
文章目录
- Spark
- 安装
- 解压
- 改名
- 配置spark-env.sh
- 重命名,配置slaves
- 启动
- 查看
- 配置环境变量
- 工作流程
- maven
- 创建maven项目
- 配置maven
- 更改pom.xml
- WordCount
- 按照用户求消费额
- 上传到spark集群上运行
安装
上传,直接拖拽
解压
tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /usr/local/
改名
cd /usr/local
mv spark-2.1.1-bin-hadoop2.7/ sparkcd spark/conf
mv spark-env.sh.template spark-env.sh
配置spark-env.sh
vi spark-env.sh
在该配置文件中添加如下配置
export JAVA_HOME=/usr/local/jdk
export SPARK_MASTER_IP=centos1
export SPARK_MASTER_PORT=7077 master work通信用
保存退出

上面三条分别是
jdk的位置
主机名(查询主机名hostname)
端口
重命名,配置slaves
mv slaves.template slaves
vi slaves
在该文件中添加子节点所在的位置(Worker节点)
将配置好的Spark拷贝到其他节点上
启动
命令也是start-all.sh,跟Hadoop的启动命令冲突,所以改一下名
在/usr/local/spark/sbin下
mv start-all.sh start_all.sh
mv stop-all.sh stop_all.sh
查看
启动后执行jps命令,主节点上有Master进程,其他子节点上有Work进行,登录Spark管理界面查看集群状态(主节点):http://centos1:8080/
配置环境变量
vim /etc/profile
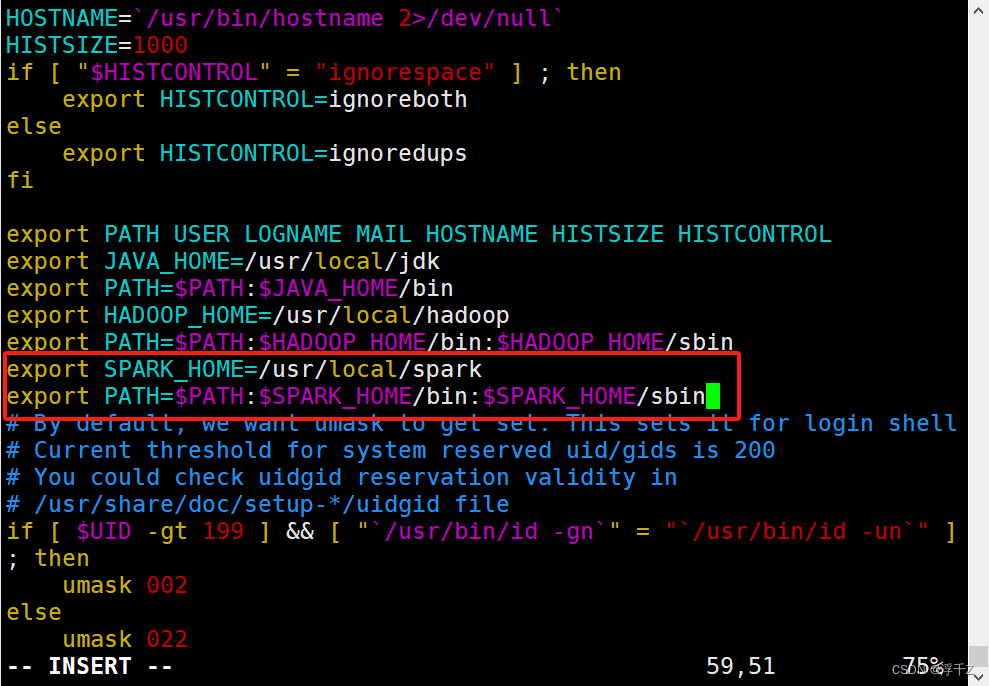
source /etc/profile
工作流程
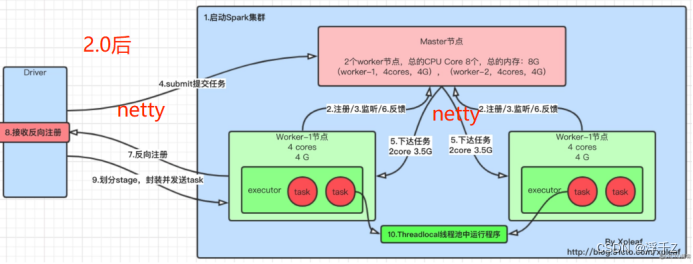
maven
下载jar,根据groupid,artifactld,version
创建maven项目
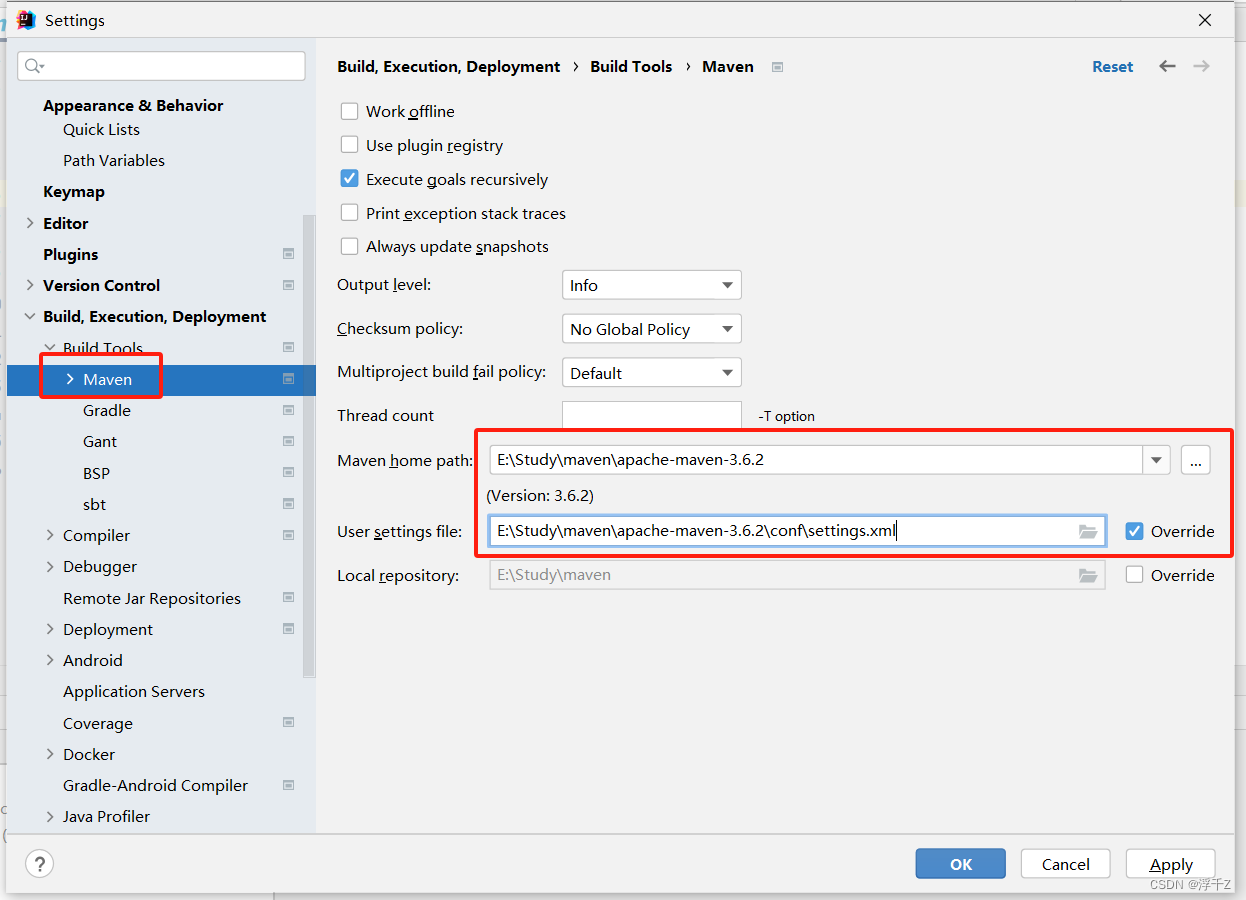
配置maven
更改pom.xml
WordCount
求单词出现次数
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSessionobject HelloWorld {def main(args: Array[String]): Unit = {val config=new SparkConf()//是用来创建spark上下文driverval spark=SparkSession.builder().master("local[*]").config(config).appName("hello").getOrCreate()val rddLine: RDD[String] = spark.sparkContext.textFile("D:\\Study\\Hadoop\\input\\word.txt")//求单词出现的次数//1.
// rddLine.flatMap(x=>x.split(" ")).map(x=>(x,1)).groupByKey().map(x=>(x._1,x._2.sum)).foreach(x=>println(x))
// rddLine.flatMap(x=>x.split(" ")).map(x=>(x,1)).groupByKey().foreach(x=>println(x+"-----bkbk"))
// //这个groupByKey方法直接按照key来分组,后面的集合是key对应的值的集合
// //(ss,CompactBuffer(1, 1))-----bkbk//2.用reduce直接做rddLine.flatMap(x=>x.split(" ")).map(x=>(x,1)).reduceByKey((x,y)=>x+y).foreach(x=>println(x))}
}
按照用户求消费额
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
//数据如下
//1,2020-12-12,10
//1,2020-12-13,16
//2,2020-12-12,89
//2,2020-12-13,22
object SumByUser {def main(args: Array[String]): Unit = {val conf=new SparkConf()val spark=SparkSession.builder().master("local[*]").config(conf).appName("hello").getOrCreate()//创建spark上下文driverval rddLine: RDD[String] = spark.sparkContext.textFile("D:\\Study\\Hadoop\\input\\sumbyuser.txt")//文件读入地址//按","分割,取第一列和第三列,reducebykeyrddLine.map(x=>x.split(",")).map(x=>(x(0),x(2).toInt)).reduceByKey((x,y)=>x+y).foreach(x=>println(x))}
}上传到spark集群上运行
代码中去掉master,改一下文件读入路径
打包
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
//数据如下
//1,2020-12-12,10
//1,2020-12-13,16
//2,2020-12-12,89
//2,2020-12-13,22
object SumByUser {def main(args: Array[String]): Unit = {val conf=new SparkConf()//如果提交到spark集群上运行,就不需要master,文件地址也要改val spark=SparkSession.builder().config(conf).appName("hello").getOrCreate()//创建spark上下文driverval rddLine: RDD[String] = spark.sparkContext.textFile(args(0))//文件读入地址//按","分割,取第一列和第三列,reducebykeyrddLine.map(x=>x.split(",")).map(x=>(x(0),x(2).toInt)).reduceByKey((x,y)=>x+y).foreach(x=>println(x))}
}
把jar和数据传到虚拟机上
执行
类名、master、内存大小、核的个数、jar的名、数据的名
spark-submit --class com.oracle.spark.SumByUser --master spark://centos1:7077 --executor-memory 500M --total-executor-cores 2 jt_sparkz-1.0-SNAPSHOT-jar-with-dependencies.jar sumbyuser.txt
类名
相关文章:
Spark安装、解压、配置环境变量、WordCount
Spark 小白的spark学习笔记 2024/5/30 10:14 文章目录 Spark安装解压改名配置spark-env.sh重命名,配置slaves启动查看配置环境变量 工作流程maven创建maven项目配置maven更改pom.xml WordCount按照用户求消费额上传到spark集群上运行 安装 上传,直接拖拽…...
)
DeepSeek-V2-Chat多卡推理(不考虑性能)
TOC 本文演示了如何使用accelerate推理DeepSeek-V2-Chat(裁剪以后的模型,仅演示如何将权值拆到多卡) 代码 import torch from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig from accelerate import init_empty_weights import sys from acce…...
)
算法题day42(补5.28日卡:动态规划02)
今天的动态规划都是二维的,与昨日不同。 一、刷题: 1.leetcode题目 62. 不同路径 - 力扣(LeetCode)(medium,) 解决: class Solution:def uniquePaths(self, m: int, n: int) -> int:dp …...

分治与递归
实验一:分治与递归 【实验目的】 深入理解分治法的算法思想,应用分治法解决实际的算法问题。 【实验性质】 验证性实验(学时数:2H) 【实验内容与要求】 1、设有n2k个运动员要进行网球循环赛。现要设计一个满足以…...

Spring中IOC容器
IoC IOC容器 IoC是一种设计思想,面向对象编程 Spring通过IoC管理所有Java对象的实例化和初始化,控制对象之间依赖关系 将IoC容器管理的Java对象称为Spring Bean,与new创建的对象没有区别 控制反转(IoC Inversion of Controle&a…...

php redis分布式锁
一,概念 在PHP中实现分布式锁通常可以使用数据库、缓存系统(如Redis)或者其他中央存储系统来保证在分布式系统中的数据一致性与同步。秒杀下单、抢红包等等业务场景,都需要用到分布式锁。 常规方案大概有七中 方案一:…...

kotlin 中的布尔
1、kotlin中内置的Boolean类型,可以有true与false两个值的布尔对象。 布尔值的内置运算有(跟很多语言如java、js一摸一样): ||——逻辑或&&——逻辑与!——逻辑非 fun main() {val a: Boolean trueval b: Boolean fa…...

有哪些ai聊天推荐?简单分享三款
有哪些ai聊天推荐?在当今数字化时代,人工智能(AI)聊天软件已经成为我们日常生活中不可或缺的一部分。无论是与朋友、家人还是同事交流,这些智能聊天软件都能为我们提供极大的便利。那么,市面上有哪些值得推…...
Python第二语言(十、Python面向对象(上))
目录 1. 标记变量的基础类型 2. 初识对象 2.1 使用对象组织数据 3. 成员变量 3.1 类和类成员的定义 3.2 成员变量和成员方法使用 3.3 成员方法的定义语句 4. 类和对象class Clock: def ring(self): 4.1 创建类对象的语法:对象名 类名称() 4.2 用生活中的…...
SolidWorks 2016 SP5安装教程
软件介绍 Solidworks软件功能强大,组件繁多。 Solidworks有功能强大、易学易用和技术创新三大特点,这使得SolidWorks 成为领先的、主流的三维CAD解决方案。 SolidWorks 能够提供不同的设计方案、减少设计过程中的错误以及提高产品质量。SolidWorks 不仅…...

为什么高考志愿只选计算机专业?
刚刚高考结束,不知道各位学弟学妹考的怎么样啊? 高考毕竟是对十二年寒窗苦读的评判,也是很多人改变命运的机会。很多同学每天等待出分的过程很煎熬,既吃不好也玩不好(os:这种同学还挺多的)。 但…...

GPT大模型微调-提高垂直领域回答质量
微调一个大模型并测试微调后的效果是一个很好的学习实践。下面是一个逐步指导,帮助你使用一个较小的预训练大模型进行微调,并测试其效果。我们将使用 Hugging Face 的 Transformers 库和一个较小的预训练模型,如 DistilBERT。这个库非常流行且易于使用。 实现步骤 步骤 1:…...

全网首发-Docker被封后的代理设置教程
最近上交、科大以及阿里的一些docker镜像,好像都因为不可控力导致无法访问。 所以,之前好多正常的一些镜像的打包都会报错: 比如: #1 [internall load build definition from Dockerfile#1transferring dockerfile:972B done#1 D…...

代码随想录算法训练营第五十七天|1143.最长公共子序列、1035.不相交的线、53. 最大子序和、392.判断子序列
代码随想录算法训练营第五十七天 1143.最长公共子序列 题目链接:1143.最长公共子序列 确定dp数组以及下标的含义:dp[i][j] :以下标i - 1为结尾的text1,和以下标j - 1为结尾的text2,最长重复子数组长度为dp[i][j]确…...
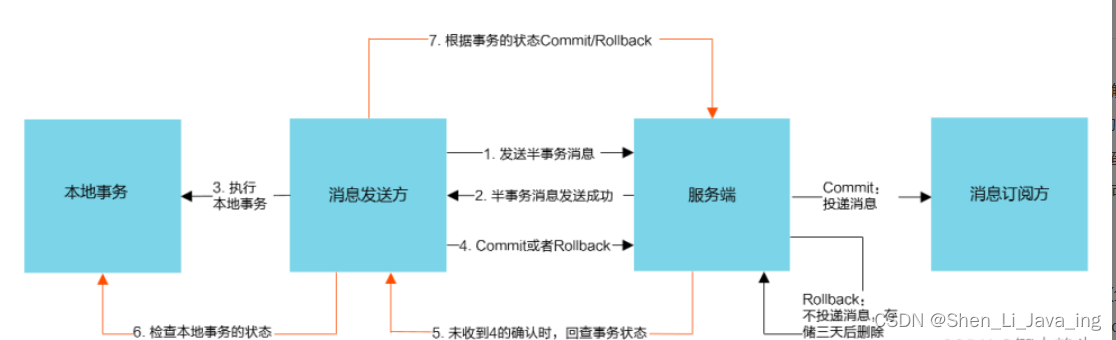
RocketMQ事务性消息
RocketMQ事务性消息是一定能保证消息发送成功的 事务消息发送步骤: (1)发送方将半事务消息发送至RocketMQ服务端。 (2)RocketMQ服务端将消息持久化之后,向发送方返回ack确认消息已经发送成功。由于消息为…...

mysql (事物)
一.什么是事物 事物是一组操作的集合,不可分割的工作单位,事物会把所有的操作当作一个整体一起向系统提交或撤销操作请求,就是这些操作要么一起成功要么一起失败。 二.事物操作 (这个就是一个理解) 1.事务特性 原子性…...
kotlin 中的字符串
一、字符类访问 1、字符串的访问跟js一样,可以使用索引来访问或者直接循环。 fun main() {val a: String "2024"// 方式一:for (item in a) {println(item) // 输出每一个字符}// 方式二:println("${a[0]}, ${a[1]}, ${a[2…...
网站线上模板建设的优缺点
优点: 1.搭建的时间短,在线建站,只需要登录注册然后选择网站模板创建网站即可管理自己的网站后台,就几步操作就可以实现。 2.网站出错率少,因为有很多用户在使用,前期所报出来的问题就已经一一…...

哲学家进餐问题
1.最多允许四个哲学家同时进餐,保证有一个筷子是空闲的,从而保证能有有一个哲学家成功进餐,而不导致死锁 semaphore chopstick[5] {1, 1, 1, 1, 1}, mutex4; Pi(){do{think...P(mutex);P(chopstick[i]);P(chopstick[(i1)%5);eat...V(mutex)…...

无人机遥感在农林信息提取中的实现方法与GIS融合应用
在新一轮互联网信息技术大发展的现今,无人机、大数据、人工智能、物联网等新兴技术在各行各业都处于大爆发的前夜。为了将人工智能方法引入农业生产领域。首先在种植、养护等生产作业环节,逐步摆脱人力依赖;在施肥灌溉环节构建智慧节能系统&a…...

知网AI率80%降到15%教程,比话降AI知网算法专精+售后保障!
知网AI率80%降到15%教程,比话降AI知网算法专精售后保障! 如果你是硕博毕业生、学校送知网检测、答辩前查出 AI 率 80%——这篇文章直接给你完整操作教程。从「拿到 80% 报告」到「学校送审通过」的完整路径,每一步该做什么、花多少时间、花多…...
)
保姆级教程:手把手教你下载、解压与解析ILSVRC2015 VID数据集(附Python脚本)
计算机视觉实战:ILSVRC2015 VID数据集处理全流程指南 当你第一次打开ILSVRC2015 VID数据集时,可能会被它的规模吓到——超过100万张图像、数千个视频序列和复杂的XML标注结构。这份指南将带你从零开始,像处理日常项目一样轻松驾驭这个庞然大…...

必知必会:大模型位置编码RoPE与ALiBi位置编码详解
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供从完整学习路径。 github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass gitee地址:AI-Compass👈:https://gitee…...

从信息学奥赛真题到项目实战:C++浮点数精度那些坑,你的double真的够用吗?
从信息学奥赛真题到项目实战:C浮点数精度那些坑,你的double真的够用吗? 在信息学奥赛的赛场上,一个看似简单的多项式计算题可能让许多选手栽跟头——不是算法思路不对,而是浮点数精度处理不当导致答案偏差。这种问题在…...
)
告别臃肿!用Debootstrap从零打造一个极简Debian系统(保姆级分区+配置指南)
告别臃肿!用Debootstrap从零打造一个极简Debian系统(保姆级分区配置指南) 在资源有限的环境中,一个臃肿的操作系统往往会成为性能瓶颈。无论是老旧电脑、嵌入式设备还是轻量级服务器,系统冗余不仅占用宝贵的存储空间&a…...

不止于校验:用HashMyFiles命令行玩转文件批量管理与VirusTotal联动
从本地到云端:HashMyFiles命令行与VirusTotal联动的安全自动化实践 在数字化时代,文件完整性校验和安全检测已成为IT运维、安全分析乃至日常开发中不可或缺的环节。传统图形界面工具虽然直观,但在处理大批量文件或需要自动化集成的场景下显得…...

如何在5分钟内完成BepInEx安装:游戏插件框架终极指南
如何在5分钟内完成BepInEx安装:游戏插件框架终极指南 【免费下载链接】BepInEx Unity / XNA game patcher and plugin framework 项目地址: https://gitcode.com/GitHub_Trending/be/BepInEx BepInEx是一款功能强大的游戏插件框架,专为Unity Mono…...

企业级网络模拟:用eNSP搭建USG6000v双机热备+NAT的完整实验环境
企业级网络高可用实战:基于eNSP的USG6000v双机热备与NAT深度解析 当企业核心业务对网络连续性要求达到99.99%时,单台防火墙的部署就像走钢丝——任何硬件故障或链路中断都可能导致服务瘫痪。这正是我在为某电商平台设计灾备方案时遇到的痛点:…...

UNet3+全解析:从结构创新到医学图像分割实战
1. UNet3为什么能成为医学图像分割的新标杆? 第一次看到UNet3的论文时,我正被一个肝脏CT分割项目折磨得焦头烂额。当时试过UNet、UNet、Attention UNet等各种变体,但总在一些微小病灶的边界分割上差强人意。直到把UNet3的代码跑起来ÿ…...

面试题:模型评价指标全解析——准确率、精确率、召回率、F1、ROC、AUC、MAE、MSE、RMSE、R² 一文讲透
把“分类指标怎么看、回归指标怎么选、ROC/AUC 怎么判断模型好坏”一次讲清楚很多人在面试里被问到“模型评价指标有哪些”时,第一反应往往是背一串名词:准确率、精确率、召回率、F1、AUC、MAE、MSE、R。看似都答到了,实际上却很容易被继续追…...