神经网络 torch.nn---Convolution Layers
torch.nn — PyTorch 2.3 documentation
torch.nn - PyTorch中文文档 (pytorch-cn.readthedocs.io)
torch.nn和torch.nn.functional的区别
-
torch.nn是对torch.nn.functional的一个封装,让使用torch.nn.functional里面的包的时候更加方便
-
torch.nn包含了torch.nn.functional,打个比方,torch.nn.functional相当于开车的时候齿轮的运转,torch.nn相当于把车里的齿轮都封装好了,为我们提供一个方向盘
-
如果只是简单应用,会torch.nn就好了。但要细致了解卷积操作,需要深入了解torch.nn.functional
-
打开torch.nn.functional的官方文档,可以看到许多跟卷积相关的操作:torch.nn.functional — PyTorch 2.3 documentation
torch.nn中Convolution Layers 卷积层
- 一维卷积层 torch.nn.Conv1d
- 二维卷积层 torch.nn.Conv2d
-
三维卷积层 torch.nn.Conv3d
一维卷积层 torch.nn.Conv1d
class torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
一维卷积层,输入的尺度是(N, C_in,L),输出尺度( N,C_out,L_out)的计算方式:
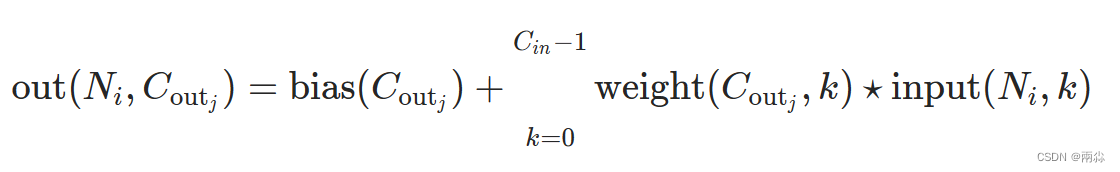
说明
bigotimes: 表示相关系数计算stride: 控制相关系数的计算步长dilation: 用于控制内核点之间的距离,详细描述在这里groups: 控制输入和输出之间的连接,group=1,输出是所有的输入的卷积;group=2,此时相当于有并排的两个卷积层,每个卷积层计算输入通道的一半,并且产生的输出是输出通道的一半,随后将这两个输出连接起来。
Parameters:
- in_channels(
int) – 输入信号的通道 - out_channels(
int) – 卷积产生的通道 - kerner_size(
intortuple) - 卷积核的尺寸 - stride(
intortuple,optional) - 卷积步长 - padding (
intortuple,optional)- 输入的每一条边补充0的层数 - dilation(
intortuple, `optional``) – 卷积核元素之间的间距 - groups(
int,optional) – 从输入通道到输出通道的阻塞连接数 - bias(
bool,optional) - 如果bias=True,添加偏置
shape:
输入: (N,C_in,L_in)
输出: (N,C_out,L_out)
输入输出的计算方式:

变量:
weight(tensor) - 卷积的权重,大小是(out_channels, in_channels, kernel_size)
bias(tensor) - 卷积的偏置系数,大小是(out_channel)
二维卷积层
1、torch.nn.functional.conv2d
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)
对几个输入平面组成的输入信号应用2D卷积。
参数:
-
input: 输入,数据类型为tensor,形状尺寸规定为:(minibatch, 几个通道(in_channels), 高, 宽)
-
weight: 权重。更专业地来说可以叫卷积核,形状尺寸规定为:(输出的通道(out_channel), in_channels/groups(groups一般取1), 高kH, 宽kW)
-
bias: 偏置。可选偏置张量 (out_channels)
-
strids: 步幅。卷积核的步长,可以是单个数字或一个元组 (sh x sw)
-
padding: 填充。默认为1 - padding – 输入上隐含零填充。可以是单个数字或元组。
-
默认值:0 - groups – 将输入分成组,in_channels应该被组数除尽
举例讲解参数strids
输入一个5×5的图像,其中的数字代表在每个像素中的颜色显示。卷积核设置为3×3的大小。
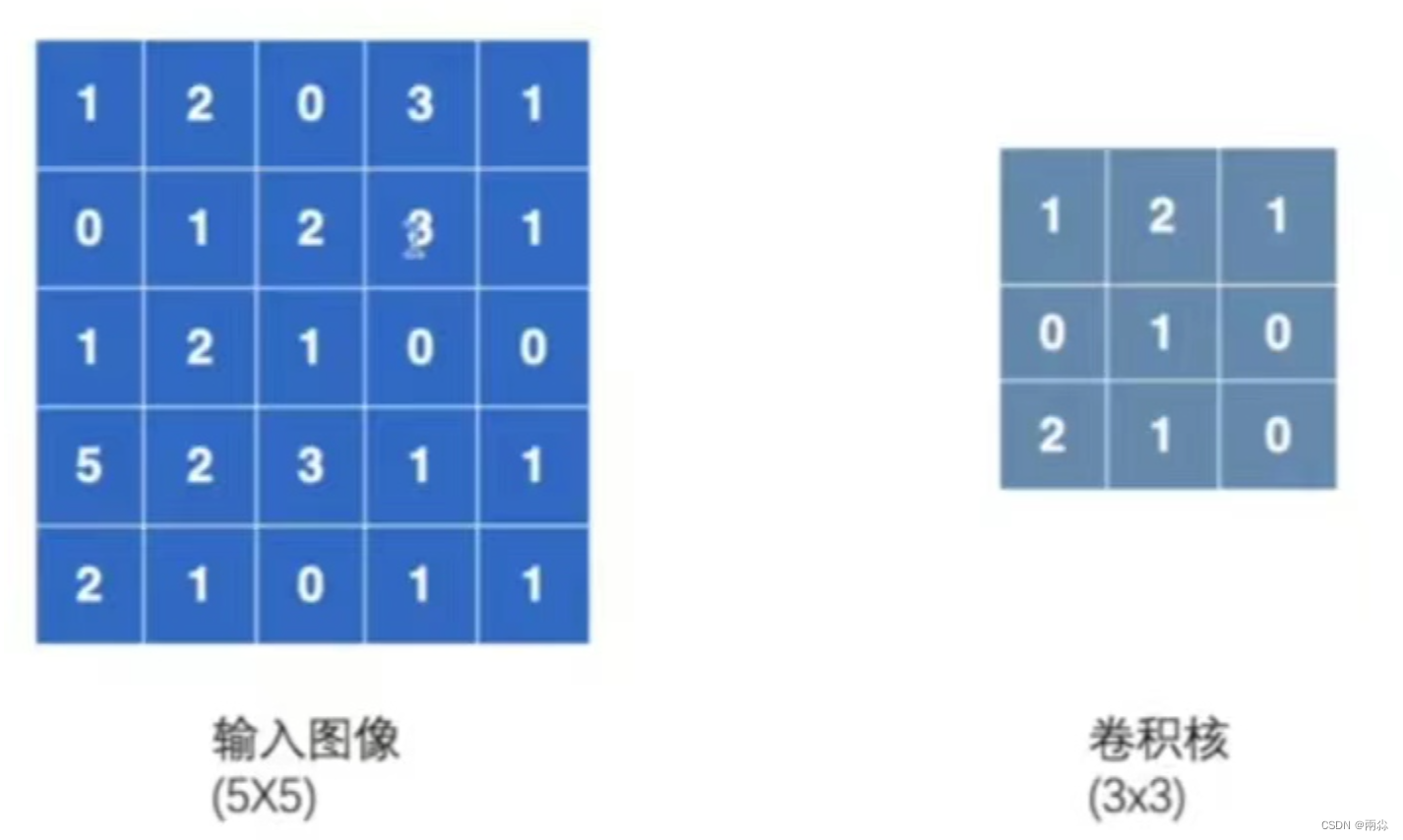
- strids参数的输入格式是单个数或者形式为 (sH,sW) 的元组,可以理解成:比如输入单个数:strids=1,每次卷积核在图像中向上下或左右移1位;如果输入strids=(2,3),那么每次卷积核在图像中左右移动(横向移动)时,是移动2位,在图像中上下移动(纵向移动)时,是移动3位。
-
本例设置strids=1
第一次移位:
-
基于上述的假设,在做卷积的过程中,需要将卷积核将图像的前三行和前三列进行匹配:
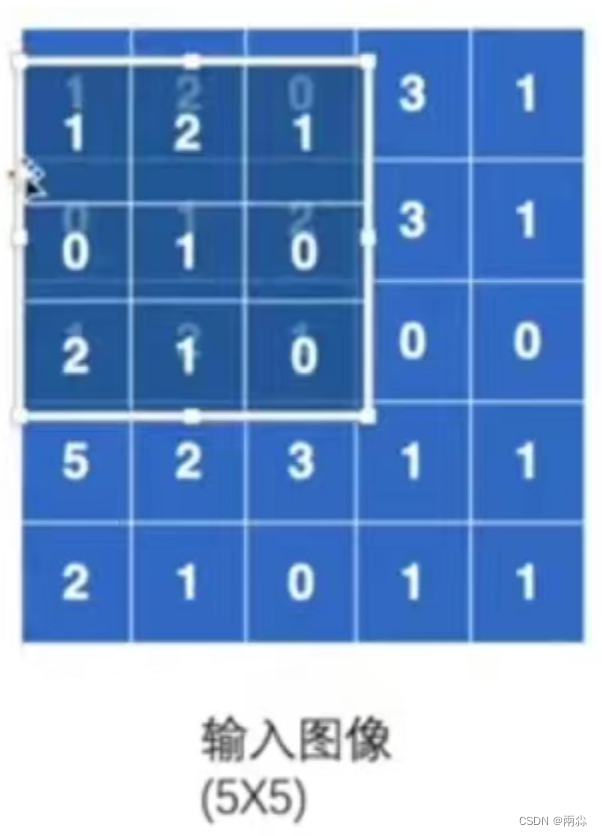
- 在匹配过后,进行卷积计算:对应位相乘然后相加,即
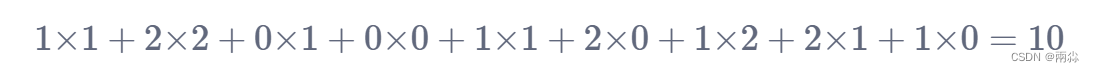
- 上面的得出的10可以赋值给矩阵,然后作为一个输出

之后卷积核可以在图像中进行一个移位,可以向旁边走1位或2位,如下图(向右走2位)。具体走多少位由strids参数决定,比如strids=2,那就是走2位。本例设置stride=1。
第二次移位:
-
向右移动一位,进行卷积计算:
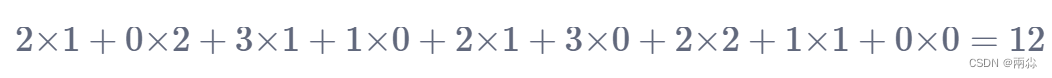
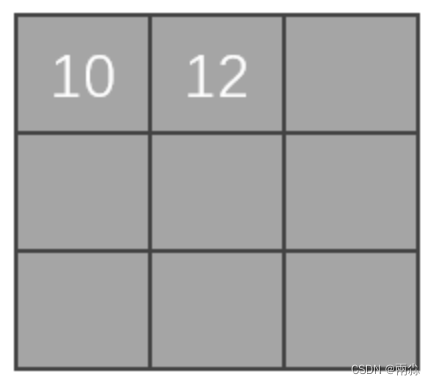
以此类推,走完整个图像,最后输出的矩阵如下图。这个矩阵是卷积后的输出。

举例讲解参数padding
padding的作用是在输入图像的左右两边进行填充,padding的值决定填充的大小有多大,它的输入形式为一个整数或者一个元组 ( padH, padW ),其中,padH=高,padW=宽。默认padding=0,即不进行填充。
- 仍输入上述的5×5的图像,并设置padding=1,那么输入图像将会变成下图,即图像的上下左右都会拓展一个像素,然后这些空的地方像素(里面填充的数据)都默认为0。
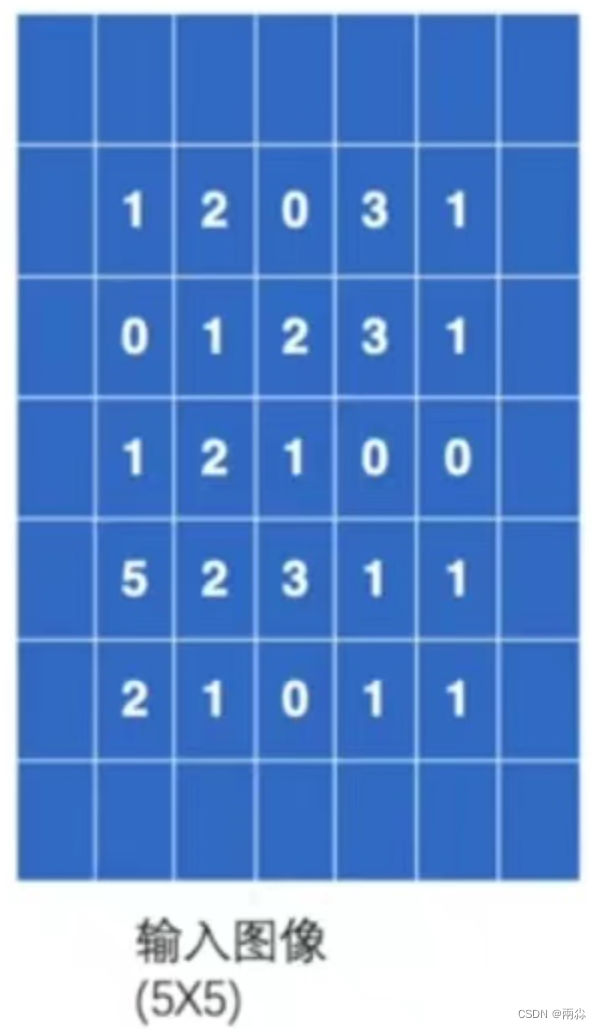
- 按上面的顺序进行卷积计算,第一次移位时在左上角3×3的位置,卷积计算公式变为:
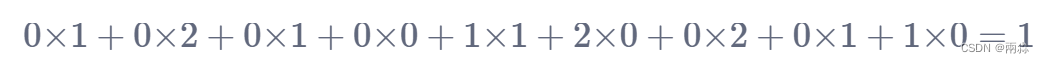
-
以此类推,完成后面的卷积计算,并输出矩阵
程序代码
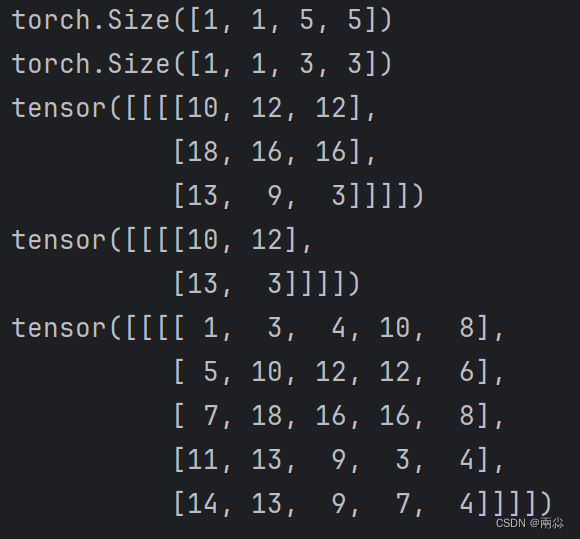
import torch
import torch.nn.functional as Finput = torch.tensor([[1, 2, 0, 3, 1],[0, 1, 2, 3, 1],[1, 2, 1, 0, 0],[5, 2, 3, 1, 1],[2, 1, 0, 1, 1]])kernel = torch.tensor([[1, 2, 1],[0, 1, 0],[2, 1, 0]])input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))print(input.shape)
print(kernel.shape)output = F.conv2d(input, kernel, stride=1)
print(output)# Stride=2
output2 = F.conv2d(input, kernel, stride=2)
print(output2)# padding=1
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)运行结果
2、torch.nn.Conv2d
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
Parameters:
- in_channels(
int) – 输入信号的通道。输入图像的通道数,彩色图像一般为3(RGB三通道) - out_channels(
int) – 卷积产生的通道。产生的输出的通道数 - kerner_size(
intortuple) - 卷积核的尺寸。一个数或者元组,定义卷积大小。如kernel_size=3,即定义了一个大小为3×3的卷积核;kernel_size=(1,2),即定义了一个大小为1×2的卷积核。 - stride(
intortuple,optional) - 卷积步长。 默认为1,卷积核横向、纵向的步幅大小 - padding(
intortuple,optional) - 默认为0,对图像边缘进行填充的范围 - dilation(
intortuple,optional) – 卷积核元素之间的间距。默认为1,定义在卷积过程中,它的核之间的距离。这个我们称之为空洞卷积,但不常用。 - groups(
int,optional) – 从输入通道到输出通道的阻塞连接数。默认为1。分组卷积,一般都设置为1,很少有改动 - bias(
bool,optional) - 默认为True。偏置,常年设置为True。代表卷积后的结果是否加减一个常数。
二维卷积层, 输入的尺度是(N, C_in,H,W),输出尺度(N,C_out,H_out,W_out)
关于卷积操作,官方文档的解释如下:

图像输入输出尺寸转化计算公式
参数说明:
-
N: 图像的batch_size
-
C: 图像的通道数
-
H: 图像的高
-
W: 图像的宽
计算过程
shape:
input: (N,C_in,H_in,W_in)
output: (N,C_out,H_out,W_out)or(C_out,H_out,W_out)
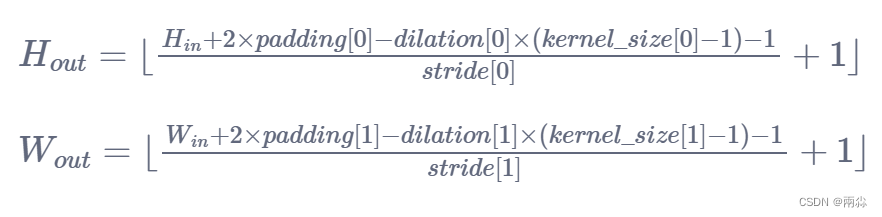
看论文的时候,有些比如像padding这样的参数不知道,就可以用这条公式去进行推导
变量:
weight(tensor) - 卷积的权重,大小是(out_channels, in_channels,kernel_size)
bias(tensor) - 卷积的偏置系数,大小是(out_channel)
参数kernel_size的说明
-
kernel_size主要是用来设置卷积核大小尺寸的,给定模型一个kernel_size,模型就可以据此生成相应尺寸的卷积核。
-
卷积核中的参数从图像数据分布中采样计算得到的。
-
卷积核中的参数会通过训练不断进行调整。
参数out_channel的说明
- 如果输入图像in_channel=1,并且只有一个卷积核,那么对于卷积后产生的输出,其out_channel也为1
- 如果输入图像in_channel=2,此时有两个卷积核,那么在卷积后将会输出两个矩阵,把这两个矩阵当作一个输出,此时out_channel=2
程序代码
使用CIFAR中的图像数据,对Conv2d进行讲解
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import Dataset, DataLoader
from torch.utils.tensorboard import SummaryWriterdataset = torchvision.datasets.CIFAR10(root='./dataset', train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)class Tudui(nn.Module):def __init__(self):super(Tudui, self).__init__()self.conv1 = nn.Conv2d(3, 6, 3, stride=1, padding=0)def forward(self, x):x = self.conv1(x)return xtudui = Tudui()
print(tudui)writer = SummaryWriter('./logs')
step = 0
for data in dataloader:imgs, targets = dataoutputs = tudui(imgs)print(imgs.shape) # torch.Size([64, 3, 32, 32])print(outputs.shape) # torch.Size([64, 6, 30, 30])writer.add_images("input", imgs, step)# torch.Size([64, 6, 30, 30]) ->> [64, 3, 32, 32]output = torch.reshape(outputs, [-1, 3, 30, 30])#由于第一个值不知道是多少,所以写-1,它会根据后面的值去计算writer.add_images("output", output, step)step += 1writer.close()
相关文章:
神经网络 torch.nn---Convolution Layers
torch.nn — PyTorch 2.3 documentation torch.nn - PyTorch中文文档 (pytorch-cn.readthedocs.io) torch.nn和torch.nn.functional的区别 torch.nn是对torch.nn.functional的一个封装,让使用torch.nn.functional里面的包的时候更加方便 torch.nn包含了torch.nn.…...
Linux常用基本命令-操作
目录 一、shell 1、什么是shell 二、Linux基本的命令分类 1、内部命令和外部命令 2、查看内部命令 2.1、help命令 2.2、enable 命令 2.3、type命令 2.4、whereis命令 2.5、which 命令 2.6、hash缓存 编辑 三、Linux常用命令 1、Linux命令格式 2、编辑Linux命…...
搭建全文搜索引擎)
从零开始使用 Elasticsearch(8.14.0)搭建全文搜索引擎
Elasticsearch 是目前最常用的全文搜索引擎。它可以快速地存储、搜索和分析海量数据,广泛应用于维基百科、Stack Overflow、Github 等网站。 Elasticsearch 的底层是开源库 Lucene。直接使用 Lucene 需要写大量代码,而 Elasticsearch 对其进行了封装&am…...
流程与IT双驱动:锐捷网络如何构建持续领先的服务竞争力?
AI大模型及相关应用进入“竞赛时代”,算力作为关键要素备受关注,由于算力行业对网络设备和性能有较大需求,其发展也在推动ICT解决方案提供商加速升级,提升服务响应速度和服务质量。 锐捷网络是行业领先的ICT基础设施及行业解决方…...

CopyOnWriteArrayList 详细讲解以及示范
CopyOnWriteArrayList是Java集合框架中的一种线程安全的列表实现,特别适用于读多写少的并发场景。 它是通过“写时复制”(Copy-On-Write)策略来保证线程安全的,这意味着当有线程尝试修改列表时,它会先复制原列表到一个…...
01-Java和Android环境配置
appium是做app自动化测试最火的一个框架,它的主要优势是支持android和ios,同时也支持Java和Python脚本语言。而学习appium最大的难处在于环境的安装配置,本文主要介绍Java和Android环境配置,在后续文章中将会介绍appium的安装和具…...
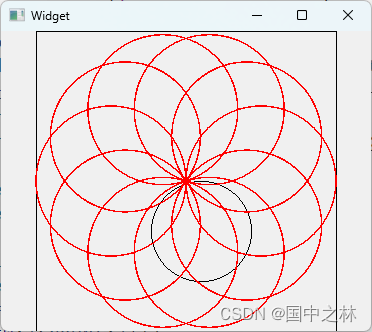
【qt】视口和窗口坐标
视口和窗口坐标 一.视口和窗口坐标的原理二.视口和窗口坐标的好处三.演示好处四.总结 一.视口和窗口坐标的原理 在绘图事件中进行绘图 void Widget::paintEvent(QPaintEvent *event) {QPainter painter(this);QRect rect(200,0,200,200);painter.drawRect(rect);//设置视口的…...

优化SQL查询的策略和技巧 - AI提供
优化SQL查询以提高处理大型数据集的数据库性能是一个重要课题。 以下是一些关键策略和技巧,可以帮助您提升查询效率: 1、创建合适索引: 针对频繁出现在WHERE、JOIN、ORDER BY和GROUP BY子句中的列创建索引。索引能够显著加速数据检索过程。…...

平安科技智能运维案例
平安科技智能运维案例 在信息技术迅速发展的背景下,平安科技面临着运维规模庞大、内容复杂和交付要求高等挑战。通过探索智能运维,平安科技建立了集中配置管理、完善的运营管理体系和全生命周期运维平台,实施了全链路监控,显著提…...

基于深度学习的向量图预测
基于深度学习的向量图预测 向量图预测(Vector Graphics Prediction)是计算机视觉和图形学中的一个新兴任务,旨在从像素图像(栅格图像)生成相应的向量图像。向量图像由几何图形(如线条、曲线、多边形等&…...
与$rawfile(““)的区别)
鸿蒙HarmonyOS $r(““)与$rawfile(““)的区别
在鸿蒙(HarmonyOS)开发中,$r(“”) 和 $rawfile(“”) 是两种不同的资源引用方式,它们分别用于引用不同的资源类型。 1、$r(“”) $r 函数通常用于引用字符串、颜色、尺寸、样式等定义在资源文件(如 strings.json, c…...

简单了解java中的Collection集合
集合 1、Collection-了解 1.1、集合概述 集合就是一种能够存储多个数据的容器,常见的容器有集合和数组 那么集合和数组有什么区别嘞? 1、集合长度可变,数组的长度不可变 2、集合只能存储引用数据类型(如果要存储基本数据类型…...
java 实现导出word 自定义word 使用aspose教程包含图片 for 循环 自定义参数等功能
java 实现导出word 主要有一下几个知识点 1,aspose导入 jar包 和 java编写基础代码下载使用 aspose-words jar包导入 aspose jar 包 使用 maven导入java代码编写 2,if判断 是否显示2,显示指定值3,循环显示List 集合列表 使用 fore…...
)
CSS动画(炫酷表单)
1.整体效果 https://mmbiz.qpic.cn/sz_mmbiz_gif/EGZdlrTDJa6yORMSqiaEKgpwibBgfcTQZNV0pI3M8t8HQm5XliaicSO42eBiboEUC3jxQOL1bRe0xlsd8bv04xXoKwg/640?wx_fmtgif&fromappmsg&wxfrom13 表单,也需要具有吸引力和实用性。HTML源码酷炫表单不仅能够提供给用户…...

Stream
Stream 也叫Stream流,是Jdk8开始新增的一套API (java.util.stream.*),可以用于操作集合或者数组的数据。 优势: Stream流大量的结合了Lambda的语法风格来编程,提供了一种更加强大,更加简单的方式操作集合或者数组中的…...

鸿蒙轻内核A核源码分析系列五 虚实映射(5)虚实映射解除
虚实映射解除函数LOS_ArchMmuUnmap解除进程空间虚拟地址区间与物理地址区间的映射关系,其中参数包含MMU结构体、解除映射的虚拟地址和解除映射的数量count,数量的单位是内存页数。 ⑴处函数OsGetPte1用于获取指定虚拟地址对应的L1页表项数据。⑵处计算需要解除的无效…...

编程初学者用什么软件电脑:全方位指南及深度解析
编程初学者用什么软件电脑:全方位指南及深度解析 在数字化浪潮席卷而来的今天,编程技能逐渐成为了一项必备的基本素养。对于初学者来说,选择一款合适的编程软件电脑至关重要。本文将从四个方面、五个方面、六个方面和七个方面,深…...

代理IP池功能组件
1.IP池管理器:用于管理IP池,包括IP地址的添加、删除、查询和更新等操作。 2.代理IP获取器:用于从外部资源中获取代理IP,例如从公开代理IP网站上爬取代理IP、从代理服务商订购代理IP等。 3.IP质量检测器:用于检测代理…...

Sqlite3入门和c/c++下使用
1. SQLite3基本介绍 1.1 数据库的数据类型 1.2 基本语法 1. 创建数据表格 create table 表名(字段名 数据类型, 字段名 数据类型); create table student(id int, name varchar(256), address text, QQ char(32)); 2. 插入数据 insert into 表名 valu…...
pyinstaller打包exe多种失败原因解决方法
pyinstaller打包exe多种失败原因解决方法 目录 pyinstaller打包exe多种失败原因解决方法1、pyinstaller安装有问题1.1 安装pyinstaller1.2 采用anconda的环境启动 2、pyqt5与pyside6冲突2.1 打包生成.spec文件2.2 编辑spec文件 3、打包成功后打不开exe,exe闪退3.1 s…...

ChatGPT Plus值不值得买?——从服务器响应延迟、上下文长度、并发请求上限到插件可用性,11维硬指标逐项打分
更多请点击: https://intelliparadigm.com 第一章:ChatGPT Plus值不值得买? ChatGPT Plus 以 $20/月的订阅费提供 GPT-4 级别响应、优先访问高峰时段、更长上下文窗口(最高 32K tokens)及图像/文件解析能力。但是否值…...

BilibiliVideoDownload故障排查指南:从登录失败到下载中断的全面解决方案
BilibiliVideoDownload故障排查指南:从登录失败到下载中断的全面解决方案 【免费下载链接】BilibiliVideoDownload Cross-platform download bilibili video desktop software, support windows, macOS, Linux 项目地址: https://gitcode.com/gh_mirrors/bi/Bilib…...
)
从键盘到5G模组:深入浅出聊聊USB那些五花八门的‘设备类’(HID/CDC/MSC)
从键盘到5G模组:深入浅出聊聊USB那些五花八门的‘设备类’(HID/CDC/MSC) 当你在键盘上敲下字符、用U盘拷贝文件,或是通过4G模块联网时,背后都有一群看不见的"协议翻译官"在忙碌——它们就是USB设备类&#x…...

从零移植Debian到红米2:解锁MSM8916上的主线Linux手机体验
1. 为什么选择红米2作为Linux移植平台 红米2作为2015年发布的入门级智能手机,搭载高通骁龙410(MSM8916)平台,1GB内存8GB存储的配置在今天看来已经相当落伍。但正是这种"过时硬件"反而成为了极客们眼中的宝藏开发板。我选…...

OpenClaw Gateway智能守护者:双触发自愈与AI诊断实践
1. 项目概述:一个为OpenClaw Gateway设计的智能守护者如果你在运维一个基于OpenClaw Gateway的服务,大概率经历过这样的深夜惊魂:手机突然收到告警,提示网关服务挂了,然后你不得不从床上爬起来,摸黑打开电脑…...

30分钟从零到精通:Czkawka Windows文件清理完全手册
30分钟从零到精通:Czkawka Windows文件清理完全手册 【免费下载链接】czkawka Multi functional app to find duplicates, empty folders, similar images etc. 项目地址: https://gitcode.com/GitHub_Trending/cz/czkawka Czkawka是一款功能强大的开源文件清…...

怎样高效使用DeepSeekMath:7B开源数学推理AI的完整实践指南
怎样高效使用DeepSeekMath:7B开源数学推理AI的完整实践指南 【免费下载链接】DeepSeek-Math DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models 项目地址: https://gitcode.com/GitHub_Trending/de/DeepSeek-Math 还在为…...

从零构建:深入理解自治系统与BGP协议的核心机制
1. 自治系统与BGP协议的前世今生 第一次听说"自治系统"这个词时,我脑海中浮现的是科幻电影里的智能机器人。实际上,它指的是互联网中由单一组织管理的网络区域。想象一下,每个自治系统就像城市里的一个独立社区,有自己的…...

Cortex-R52性能监控与调试架构深度解析
1. Cortex-R52性能监控单元架构解析在嵌入式实时系统中,性能监控单元(PMU)如同汽车的仪表盘,为开发者提供处理器内部运行状态的实时数据。Cortex-R52的PMU模块采用三级监控架构:1.1 事件采集层处理器内部部署了45个专用硬件计数器,…...

工程师创意竞赛全流程策划:从社区激活到公平投票的实战指南
1. 项目概述:一场别开生面的工程师创意竞赛又到了二月底,这意味着我们年初启动的那个“独轮车”图片配文竞赛,终于要进入最激动人心的投票环节了。我记得很清楚,那是2012年2月初,编辑部觉得冬天太沉闷,想找…...