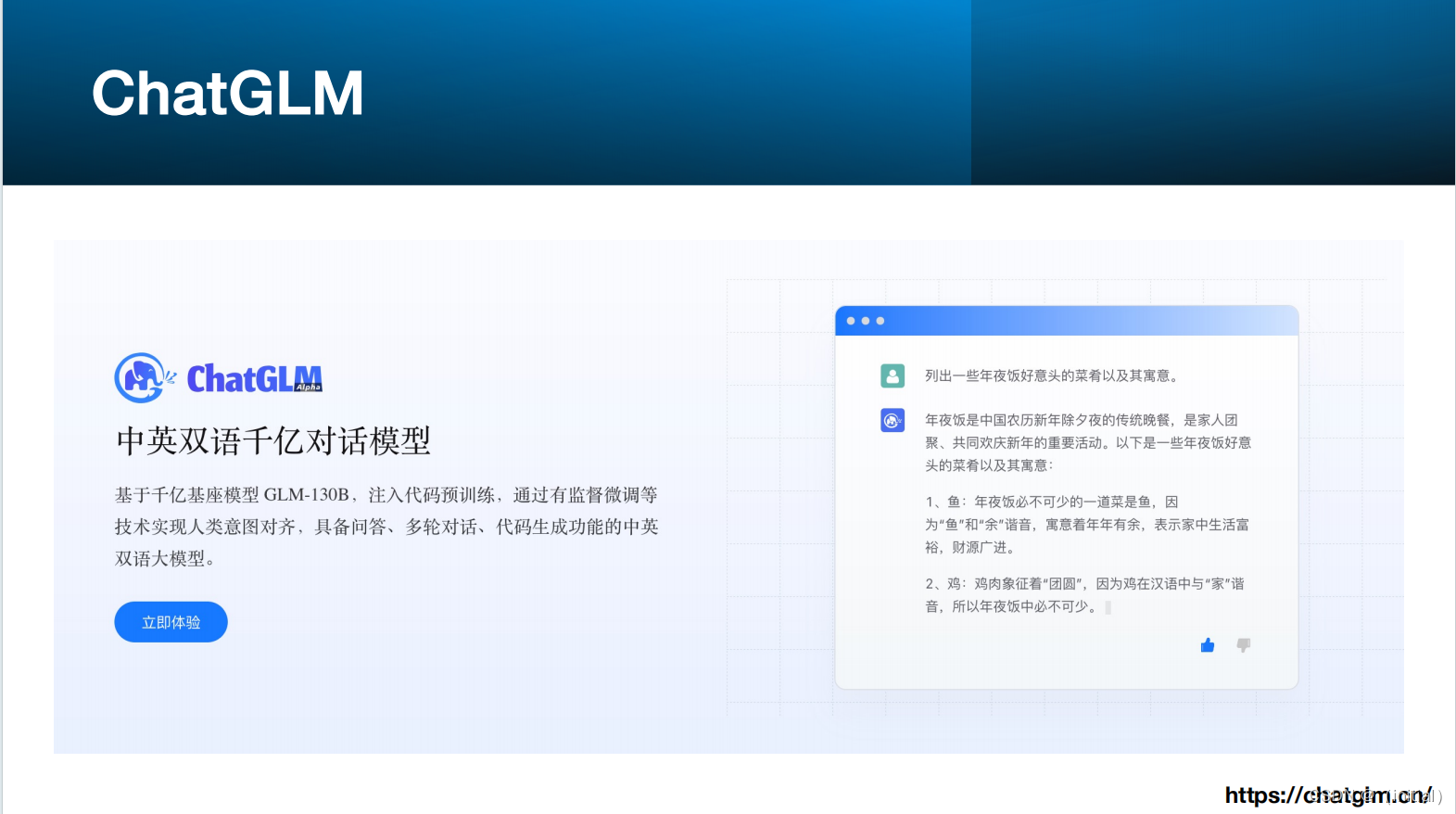
10.GLM
智谱AI GLM 大模型家族
最强基座模型 GLM-130B

GLM (General Language Model Pretraining with Autoregressive Blank Infilling)
基于自回归空白填充的通用语言模型(GLM)。GLM通过增加二维位置编码并允许以任意顺序预测跨度来改进空白填充预训练,这在NLU任务中实现了超越BERT和T5的性能提升。与此同时,GLM可以通过变化空白的数量和长度来预训练不同类型的任务。在跨NLU、有条件和无条件生成的广泛任务中,GLM在相同模型大小和数据条件下优于BERT、T5和GPT。
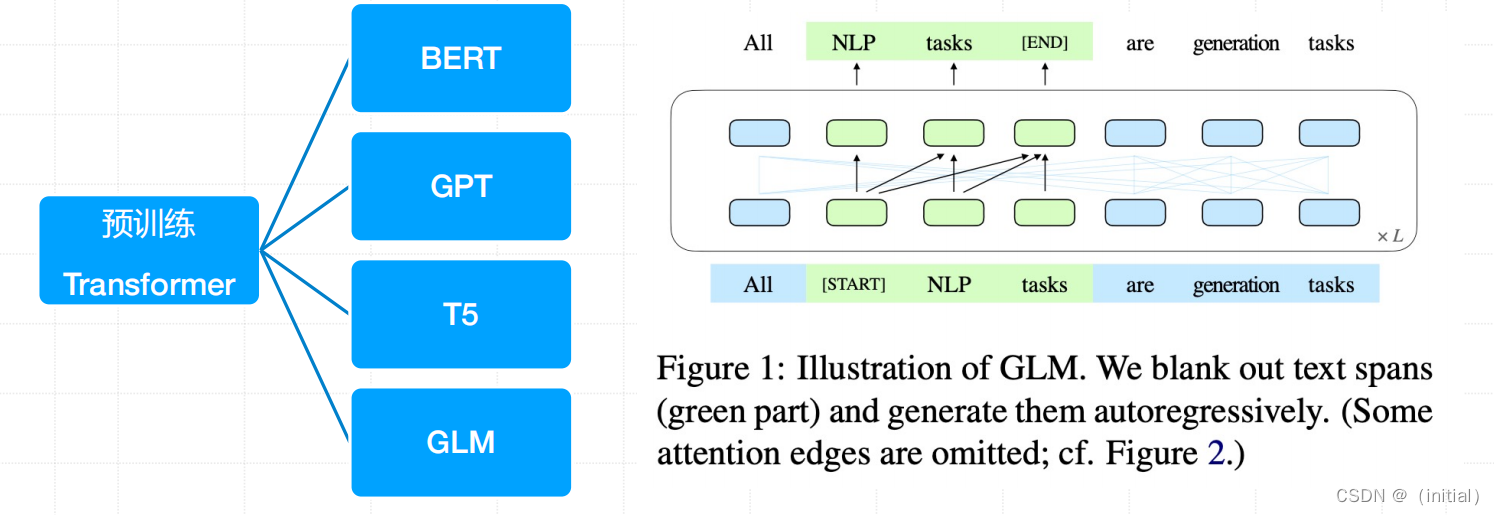
GLM 预训练原理解读 – 1
(a) 原始文本为[x1, x2, x3, x4, x5, x6]。随机采样了两个跨度(spans)[x3]和[x5, x6]。
(b) 在Part A中,用[MASK]标记[M]替换采样的跨度,并在Part B中对跨度进行洗牌(shuffle)。
© GLM 自回归地生成 Part B。每个跨度前添加[START]标记作为输入,并在后面附加[END]标记作为输出。二维位置编码表示跨度间和跨度内的位置。
(d) 自注意力掩码:灰色区域被遮蔽。Part A标记 (蓝色) 可以内部互相关注,有助于模型捕捉文本内部的上下文信息,但不能关注B。Part B标记(黄色和绿色)可以关注A和B中前文,这种设置允许模型以自回归的方式生成文本,同时考虑到已经生成的上下文。
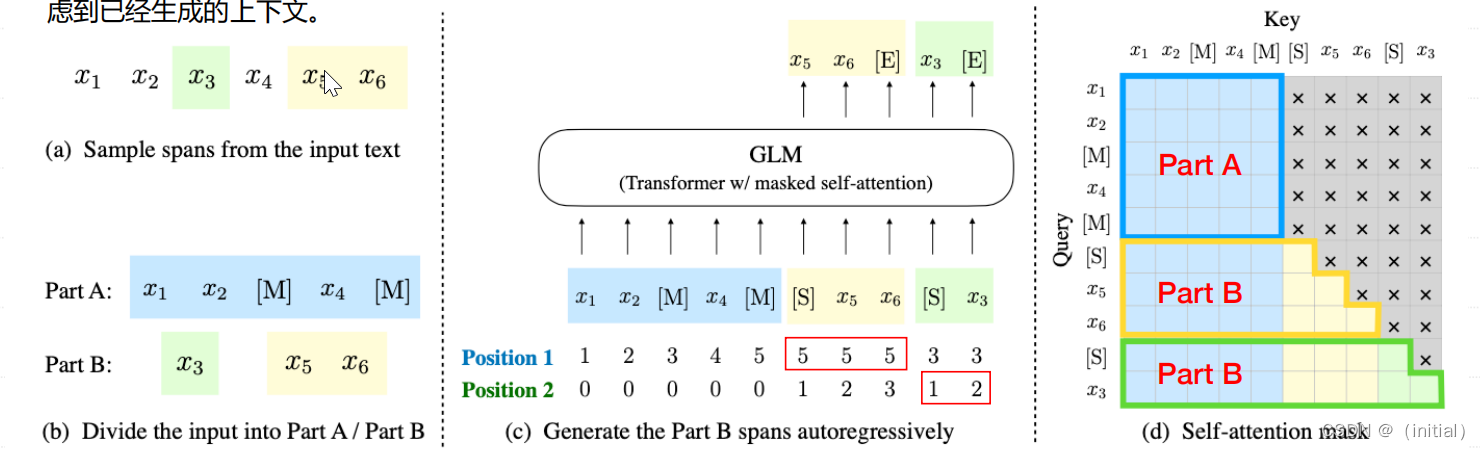
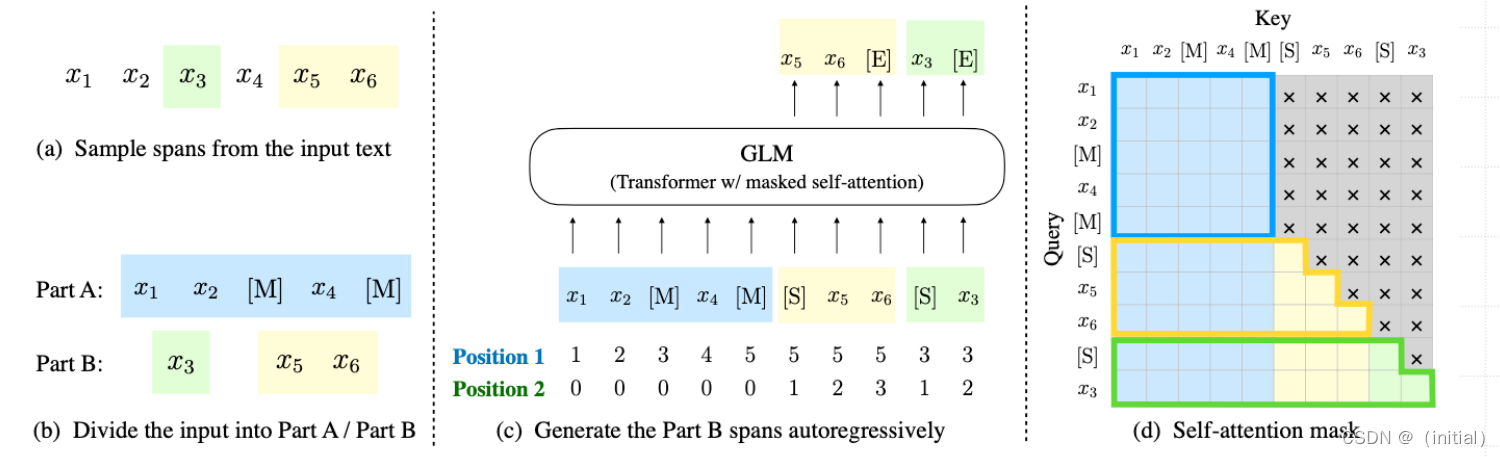
上图分为三部分,分别为:1. 输入的文本构成; 2. 模型的输入和模型输出; 3.模型的注意力mask掩码矩阵。
- 我们首先看第一部分,从上图可以看到,输入 � 被分为两部分:PartA是文本 x_corrupt,而PartB是被mask掩码片段原本的token。掩码片段的长度服从泊松分布。
- 接下来,我们再来看第二部分.在第二部分中PartA和PartB拼接在一起,并且PartB中的Mask片段使用[s] token 来与其他片段和PartA进行分开。然后,glm的位置编码为二维位置编码。在postion 1中,PartA的位置编码为从0递增,PartB的位置编码为掩码 s_i 在 x_corrupt 中原本的位置编码。在Postion 2中, x_corrupt 的位置全为0,PartB中的每个 s_i 片段内位置自增。假设 x=[x_1,x_2,x_3,x_4,x_5,x_6],其中 和x_3和x_5,x_6 为掩码片段,记为 和s_n和s_m 。因为 s_n 来自片段3, s_m 来自片段5,所以它们的potion 1的位置编码分别为3和5.而 s_n 的potion 2位置编码为[1], s_m的位置编码为[1,2].
- glm通过改变它的注意力掩码,从而实现encoder-decoder架构。在glm注意力掩码里, x_corrupt为全注意力掩码,既当前tokn既可以关注之前token,能关注到之后的token。所以, x_corrupt 之间是双向注意力,换个角度想, x_corrupt是输入到一个encoder里。而在掩码片段中,它们之间的注意力掩码为对角线,既掩码片段之间是单向注意力机制,所以掩码片段的部分输入到decoder里。总的来说,PartA中的词彼此可见;PartB中的词单向可见;PartB可见PartA;PartA不可见PartB.在预训练的时候,每个token生成的输入都是在它之前的文本。
假设 x=[x_1,x_2,x_3,x_4,x_5,x_6] ,其中 和x_3和x_5,x_6 为掩码片段。在预测 x_5 的时候,输入到模型中的是[x_1,x_2,S],其中 和x_1和x_2 是全注意力掩码,S为单向注意力掩码。接下来,要预测 x_6 的时候,即使模型上一个预测出来的token的不是 x_5 ,但是输入到模型中的还是 [x_1,x_2,S,x_5] ,实现了一种教师机制,从而保证预训练的时候,输入到模型的文本是正确的。
GLM 预训练原理解读 - 2
GLM 使用的短跨度(λ = 3)掩码的训练,适用于自然语言理解(NLU)任务。
为了在一个模型中同时支持文本生成,作者提出了一个多任务预训练方法(以第二目标共同优化文本生成任务):
- 文档级:从均匀分布中采样,其长度为原始标记的50%到100%。该目标针对长文本生成。
- 句子级:采样严格保证必须是完整的句子,总采样覆盖原始标记的15%。该目标针对seq2seq任务
- 这两个新目标与原始目标定义相同,唯一的区别是跨度的数量和长度。
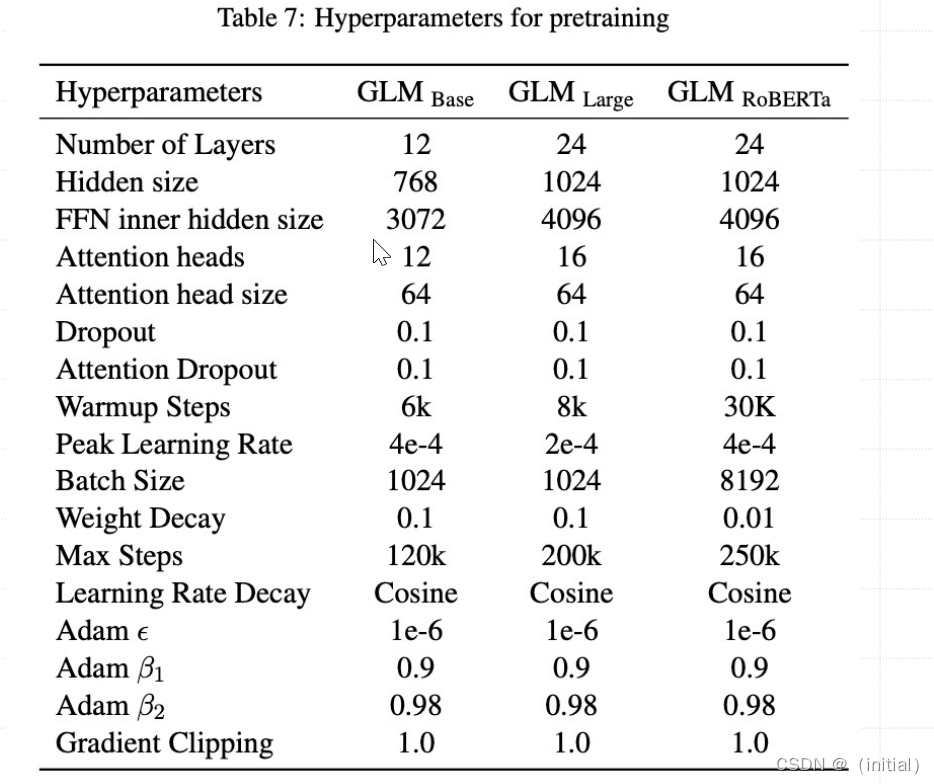
GLM 预训练超参数设置
GLM-130B**:开源双语大语言模型(ICLR 2023)**
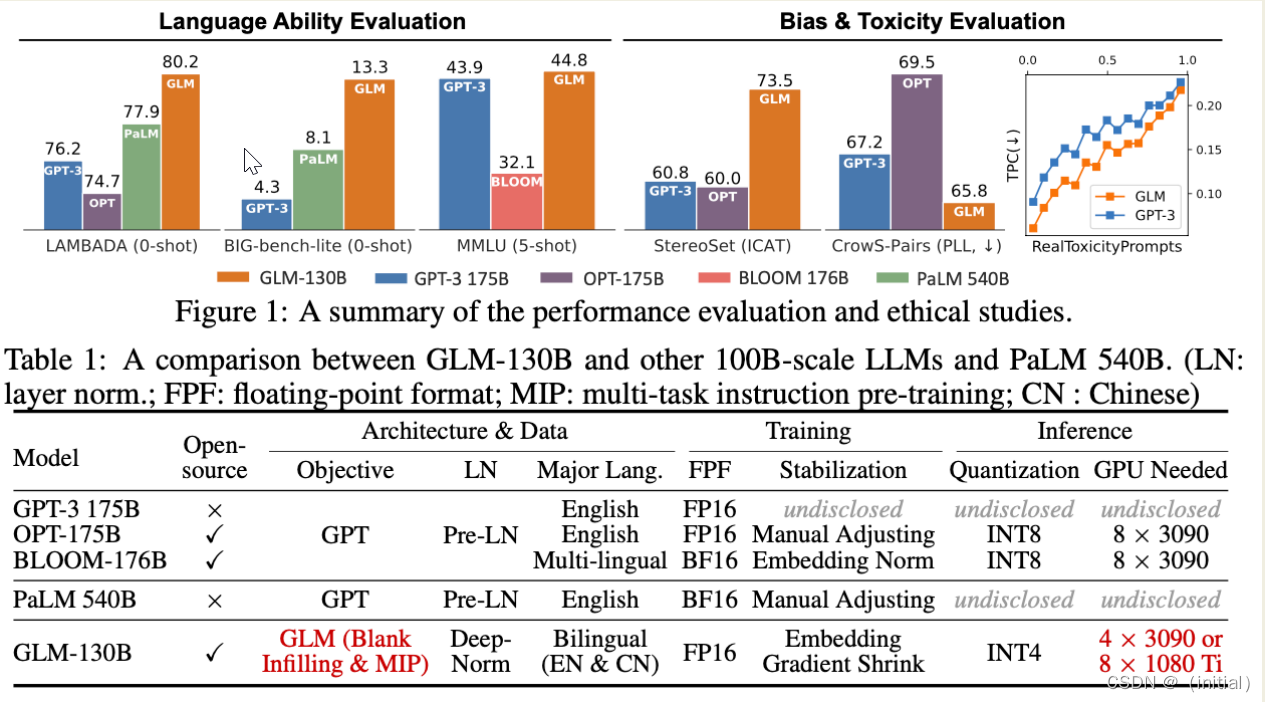
实验结果
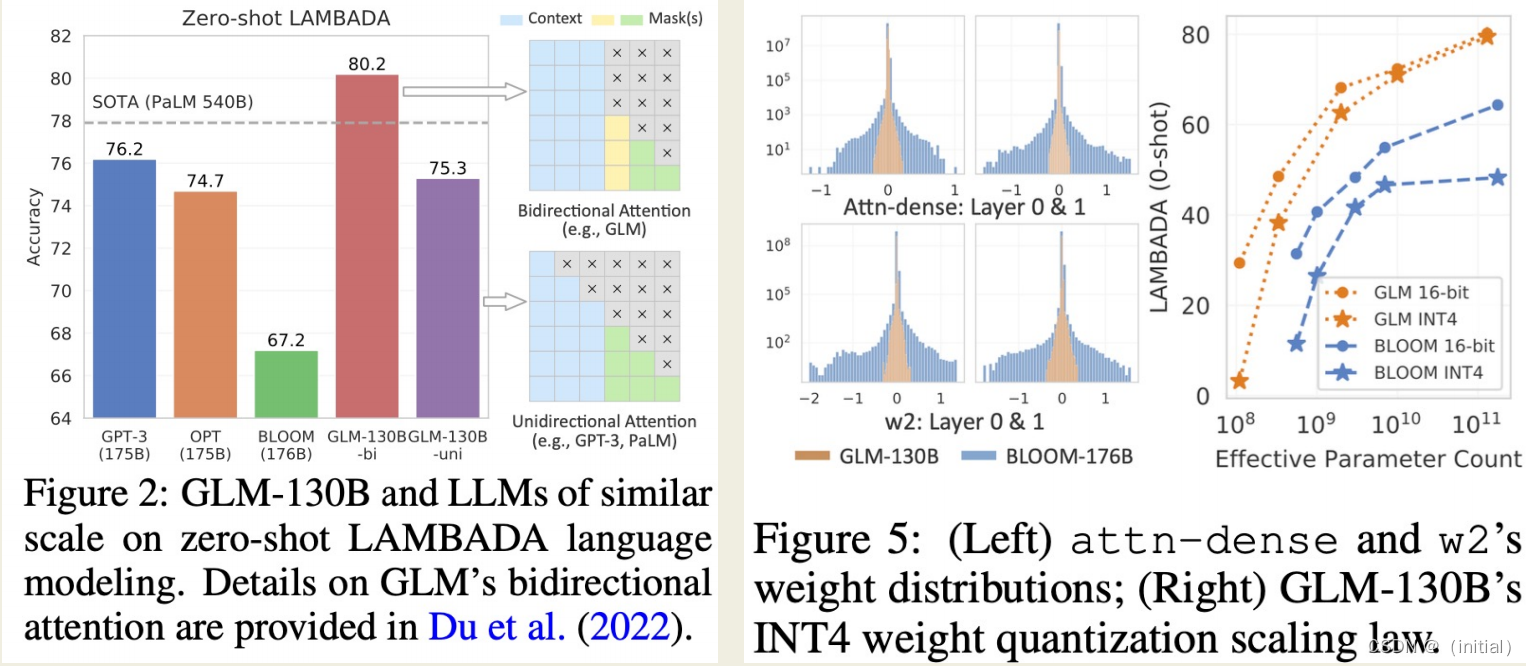
GLM-130B 预训练过程的挑战
训练崩溃和不稳定性包括以下几个方面:
- 损失尖峰:训练过程中可能出现损失函数突然大幅上升的情况,这可能是由于梯度爆炸、不恰当的学习率设置或模型架构问题导致的。
- 梯度不稳定:大型模型可能会遇到梯度不稳定的问题,导致训练过程波动性大,难以敛。
- 内存溢出:由于模型规模巨大,可能会出现内存溢出或其他资源限制问题,这会导致训练过程中断。
- 硬件限制:大型模型训练可能受到硬件资源的限制,如GPU内存不足,需要采用复杂的并行化策略。
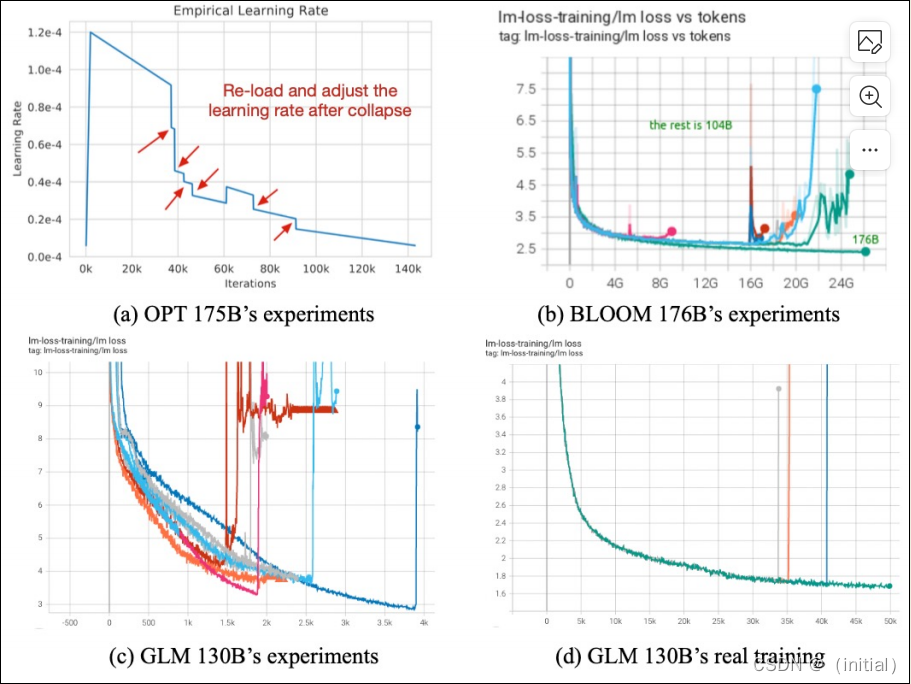
GLM-130B 量化后精度损失较少
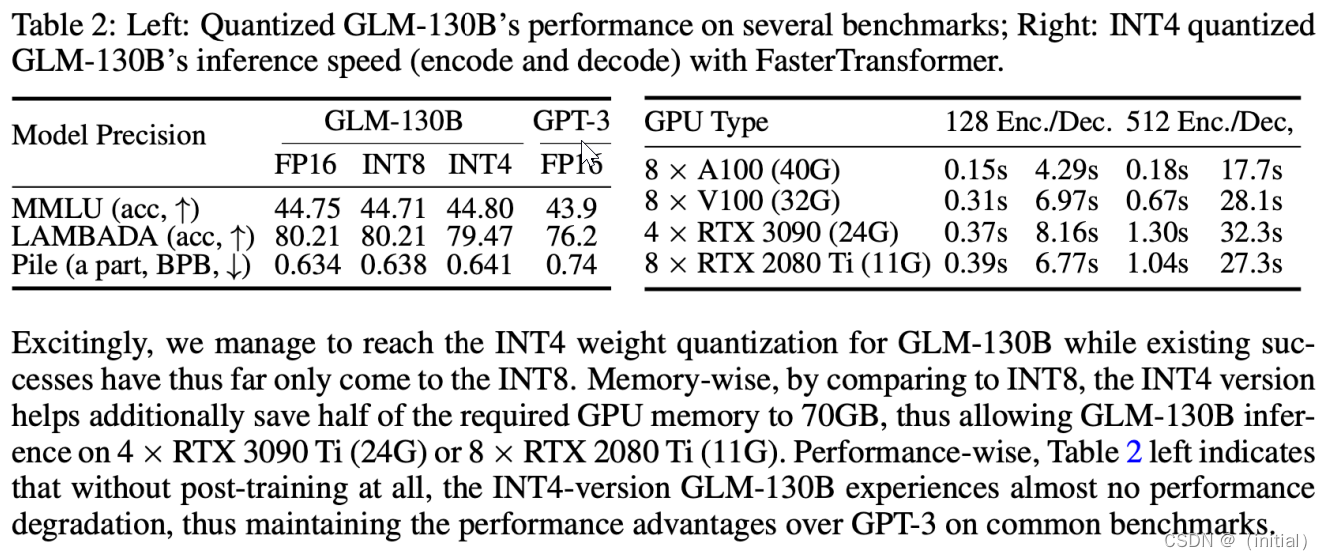
GLM-130B 部署硬件资源需求
- 建议使用A100(40G * 8)服务器
- 所有GLM-130B评估结果(约30个任务)可以在大约半天的时间内轻松地使用单个A100服务器进行复现。
- 通过INT8 / INT4量化,在具有4 * RTX3090(24G)的单个服务器上可以进行高效推理,详见GLM-130B的量化说明。
- 结合量化和权重卸载技术,甚至可以在GPU内存更小的服务器上进行GLM-130B推理,请参阅低资源推理以获取详细信息。
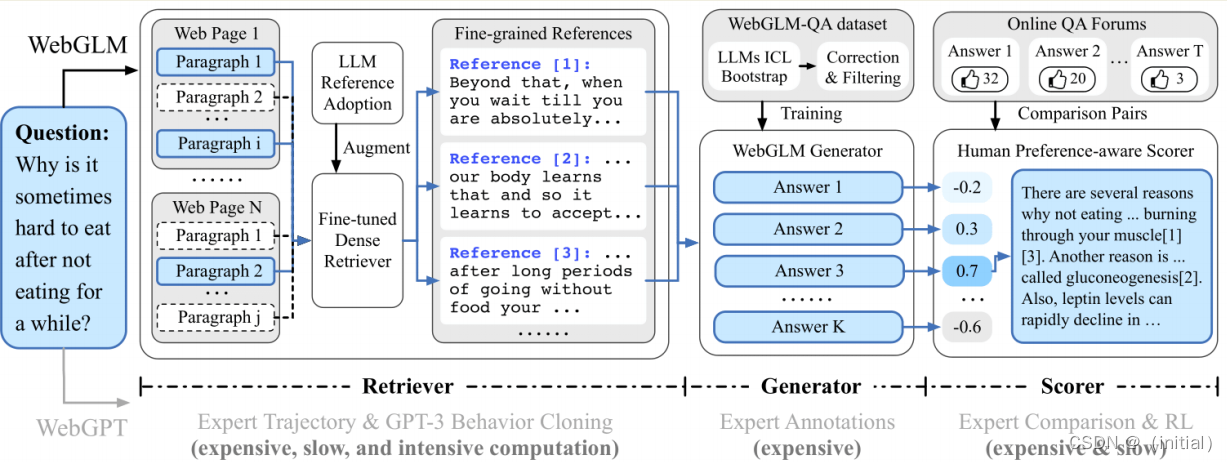
联网检索能力 WebGLM
WebGLM: An Efficient Web-enhanced Question Answering System (KDD 2023)
WebGLM旨在利用100亿参数的通用语言模型(GLM)提供高效且具有成本效益的网络增强问答系统。它旨在通过将网络搜索和检索功能整合到预训练的语言模型中,改善实际应用部署。
- LLM增强型检索器:提高相关网络内容的检索能力,以更准确地回答问题。
- 引导式生成器:利用GLM的能力生成类似人类的问题回答,提供精炼的答案。
- 人类偏好感知评分器:通过优先考虑人类偏好来评估生成回答的质量,确保系统产生有用吸引人的内容
初探多模态 VisualGLM-6B

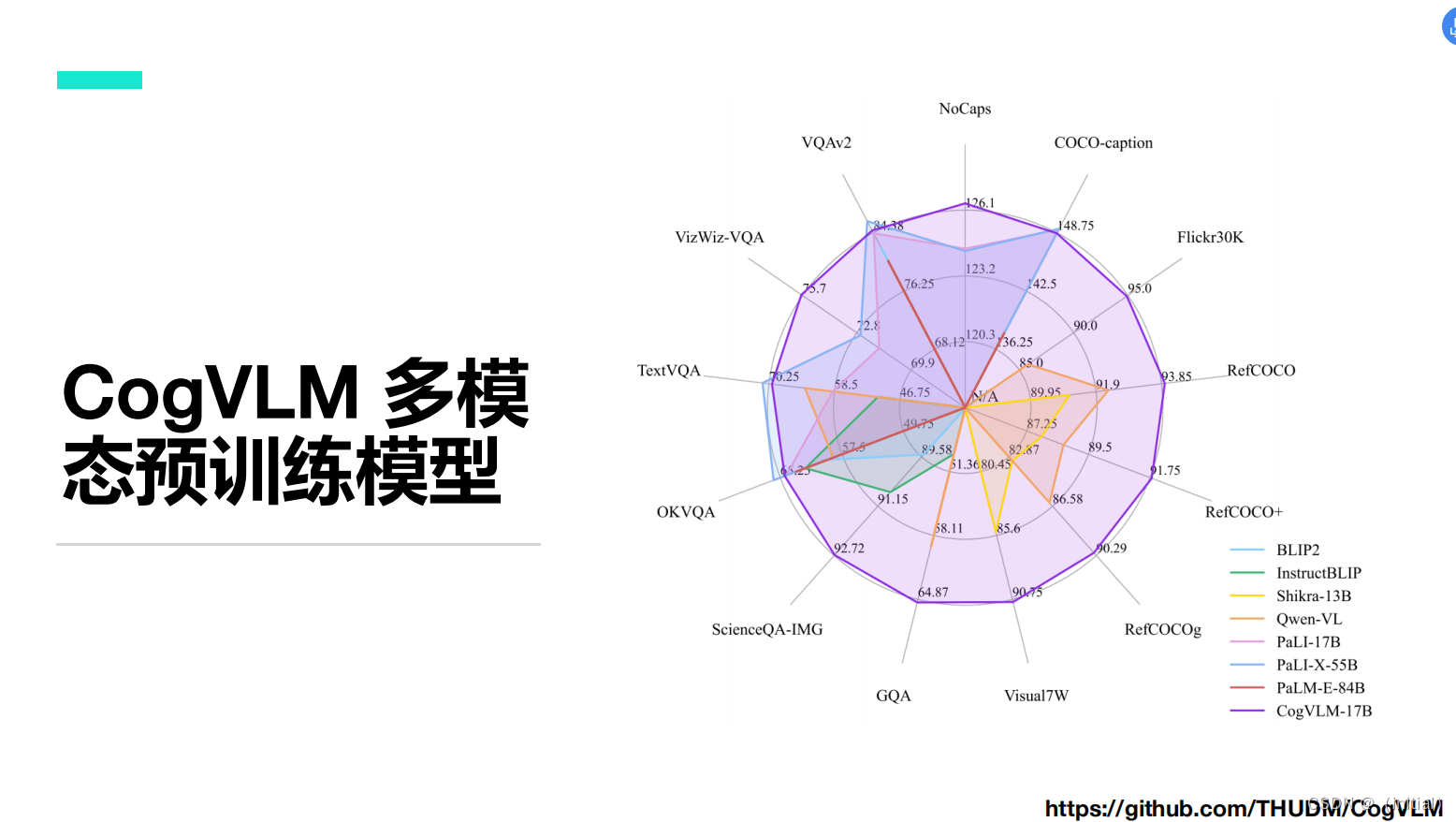
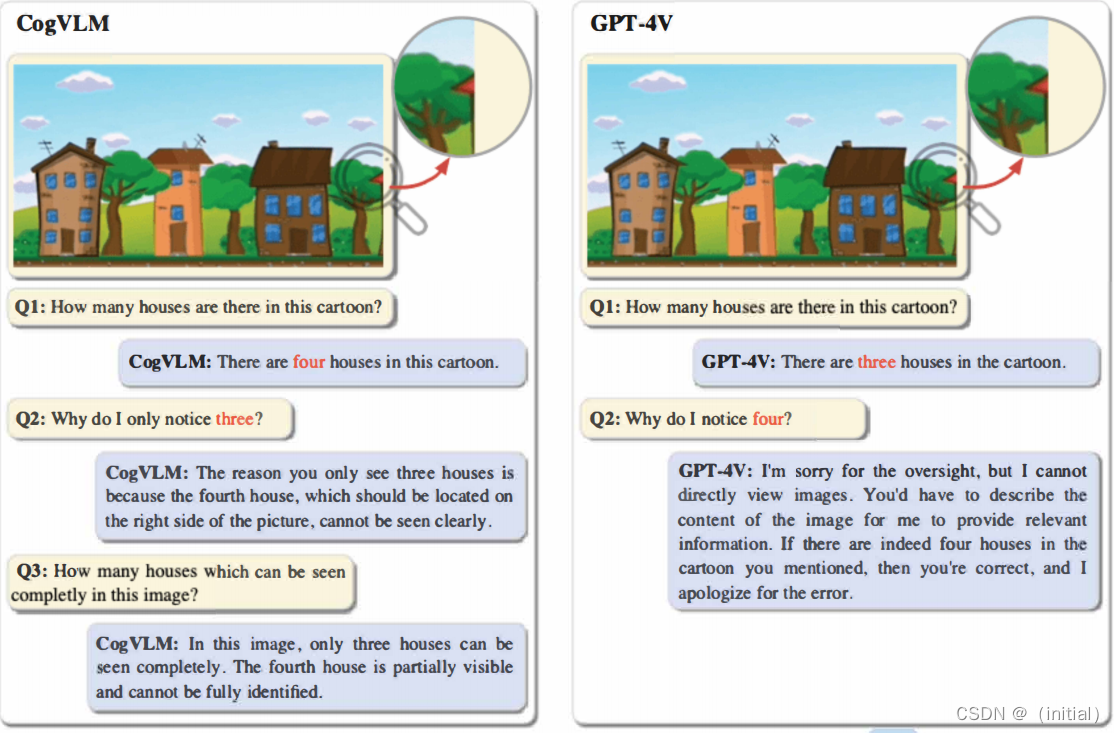
多模态预训练模型 CogVLM



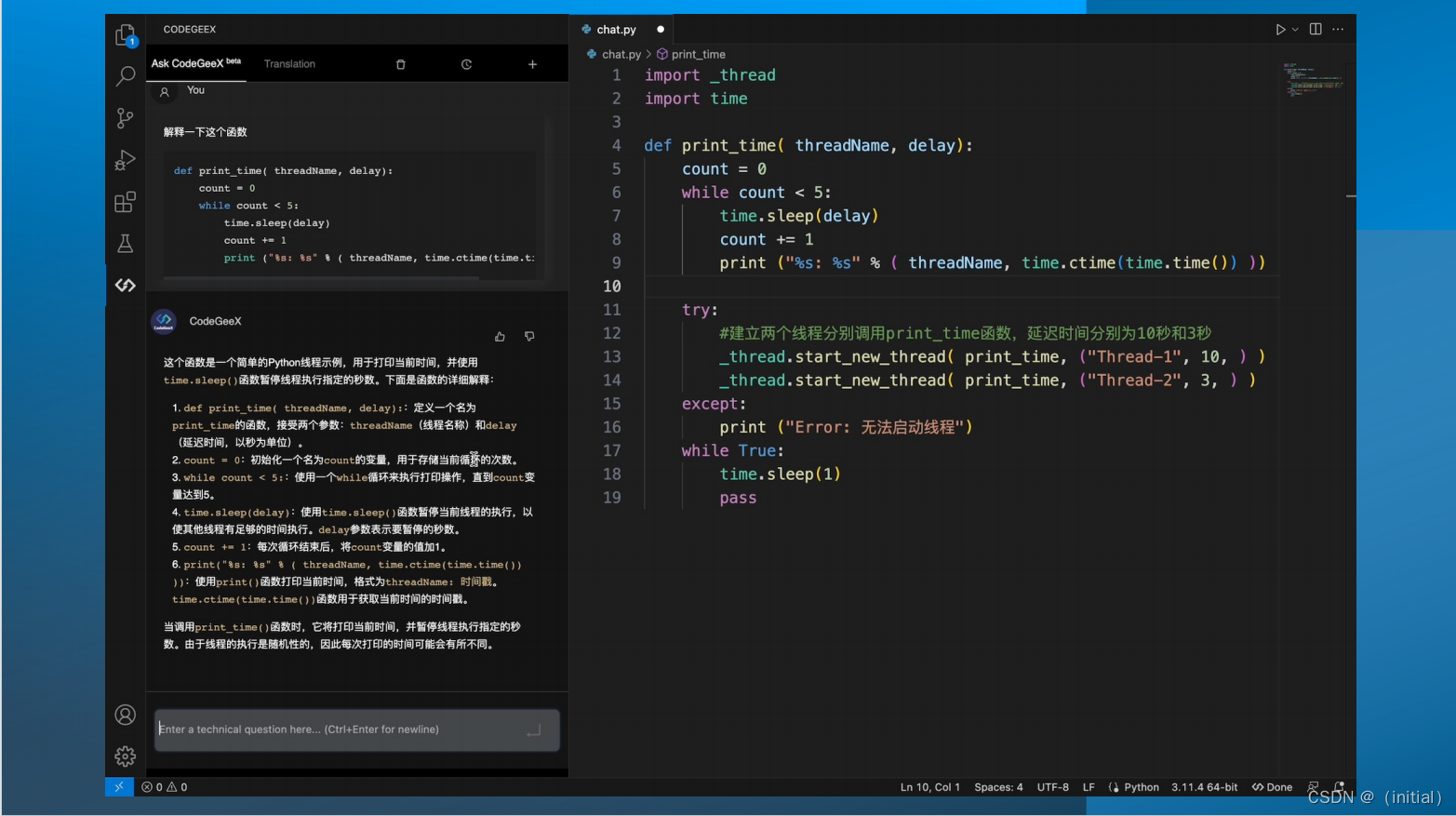
代码生成模型 CodeGeex2


增强对话能力 ChatGLM


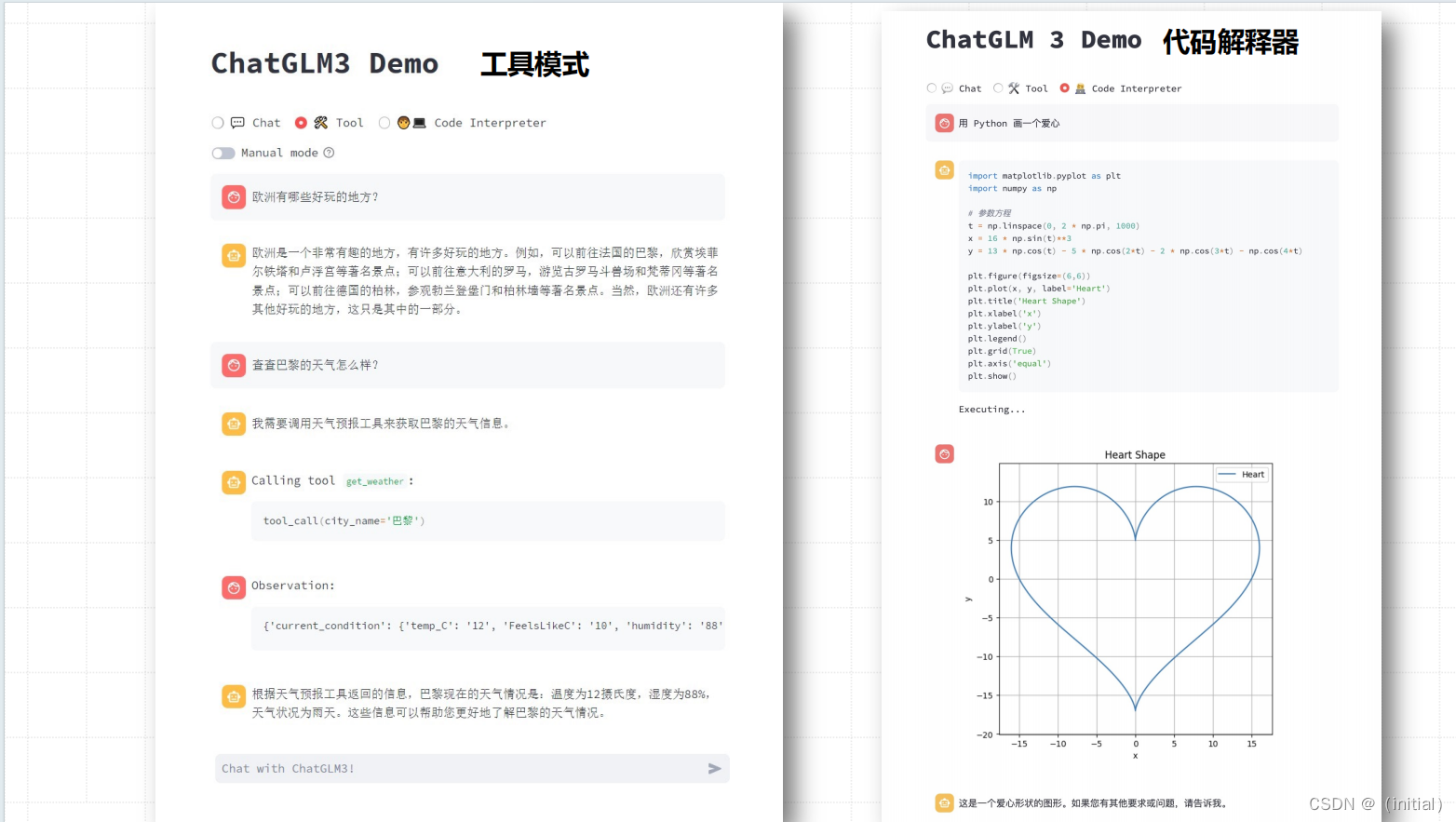
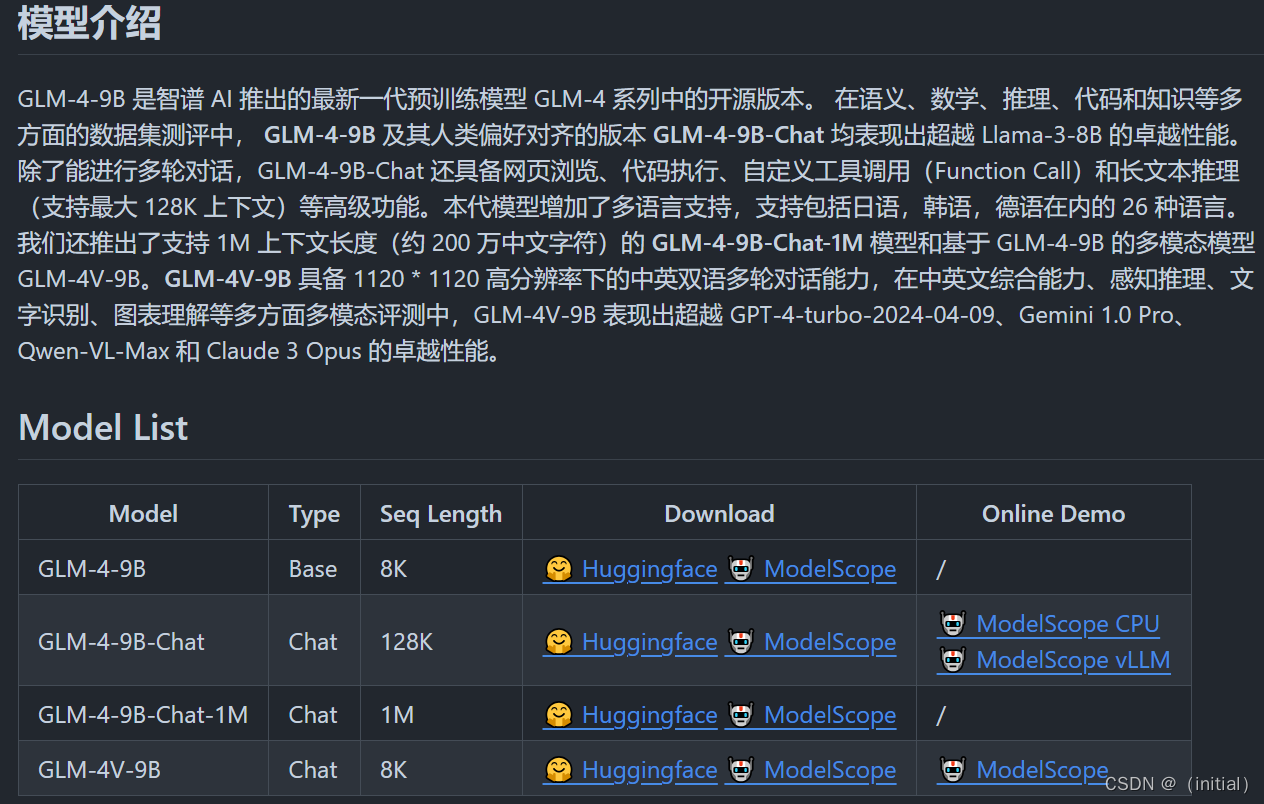
GLM4
相关文章:
10.GLM
智谱AI GLM 大模型家族 最强基座模型 GLM-130B GLM (General Language Model Pretraining with Autoregressive Blank Infilling) 基于自回归空白填充的通用语言模型(GLM)。GLM通过增加二维位置编码并允许以任意顺序预测跨度来改进空白填充预训练&…...

【深度学习】Transformer分类器,CICIDS2017,入侵检测,随机森林、RFE、全连接神经网络
文章目录 1 前言2 随机森林训练3 递归特征消除 RFE Recursive feature elimination4 DNN5 Transformer5.1. 输入嵌入层(Input Embedding Layer)5.2. 位置编码层(Positional Encoding Layer)5.3. Transformer编码器层(T…...
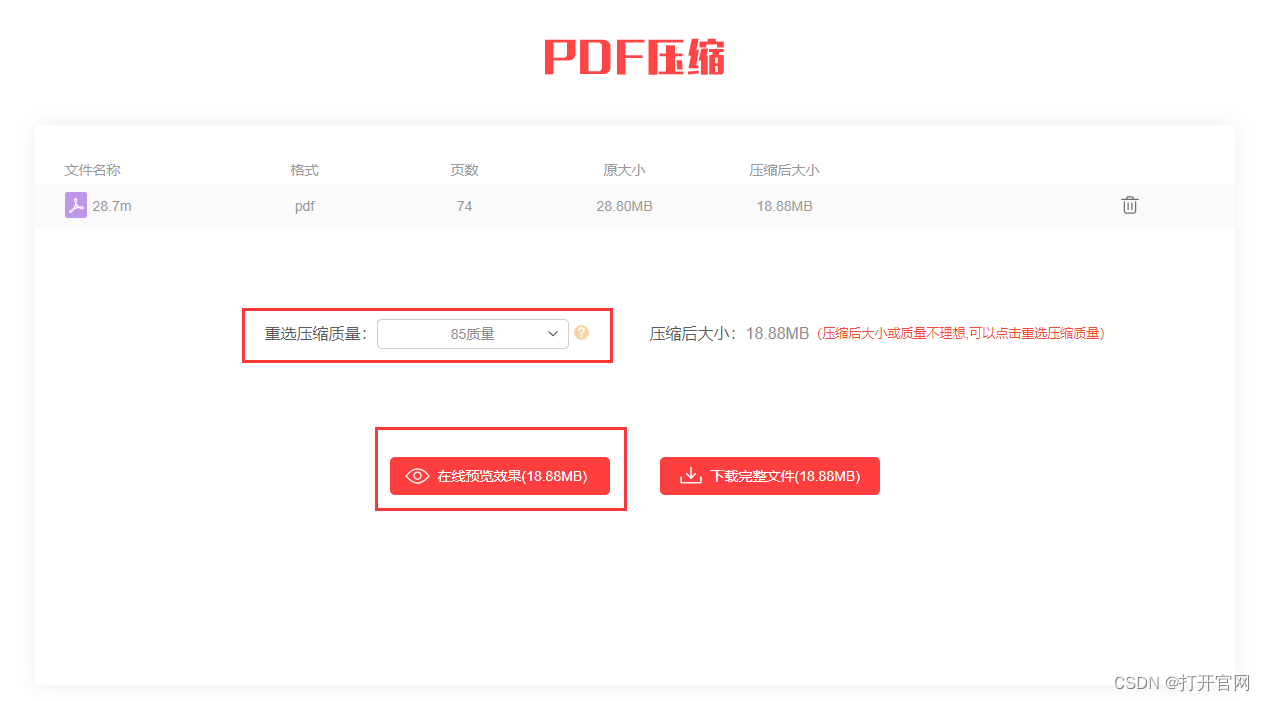
pdf压缩到指定大小的简单方法
压缩PDF文件是许多人在日常工作和学习中经常需要面对的问题。PDF文件因其跨平台、易阅读的特性而广受欢迎,但有时候文件体积过大,会给传输和存储带来不便。因此,学会如何有效地压缩PDF文件,就显得尤为重要。本文将详细介绍几种常见…...
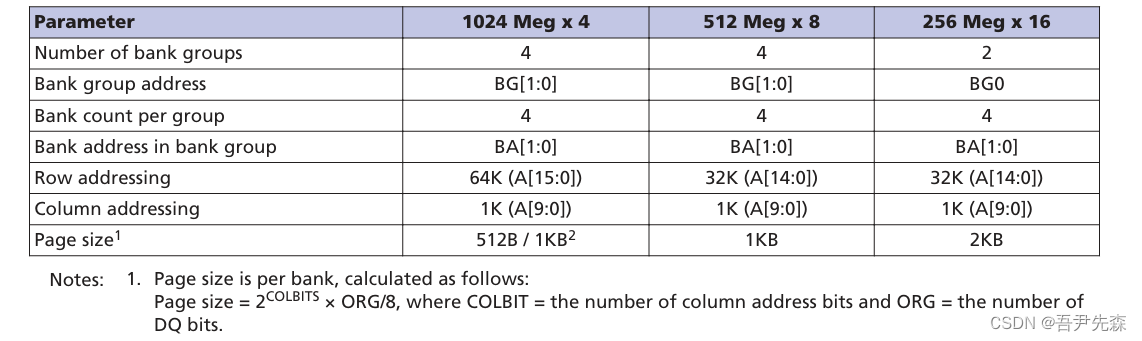
关于FPGA对 DDR4 (MT40A256M16)的读写控制 I
关于FPGA对 DDR4 (MT40A256M16)的读写控制 I 语言 :Verilg HDL EDA工具:ISE、Vivado 关于FPGA对 DDR4 (MT40A256M16)的读写控制 I一、引言二、DDR4的特性(MT40A256M16)(1…...
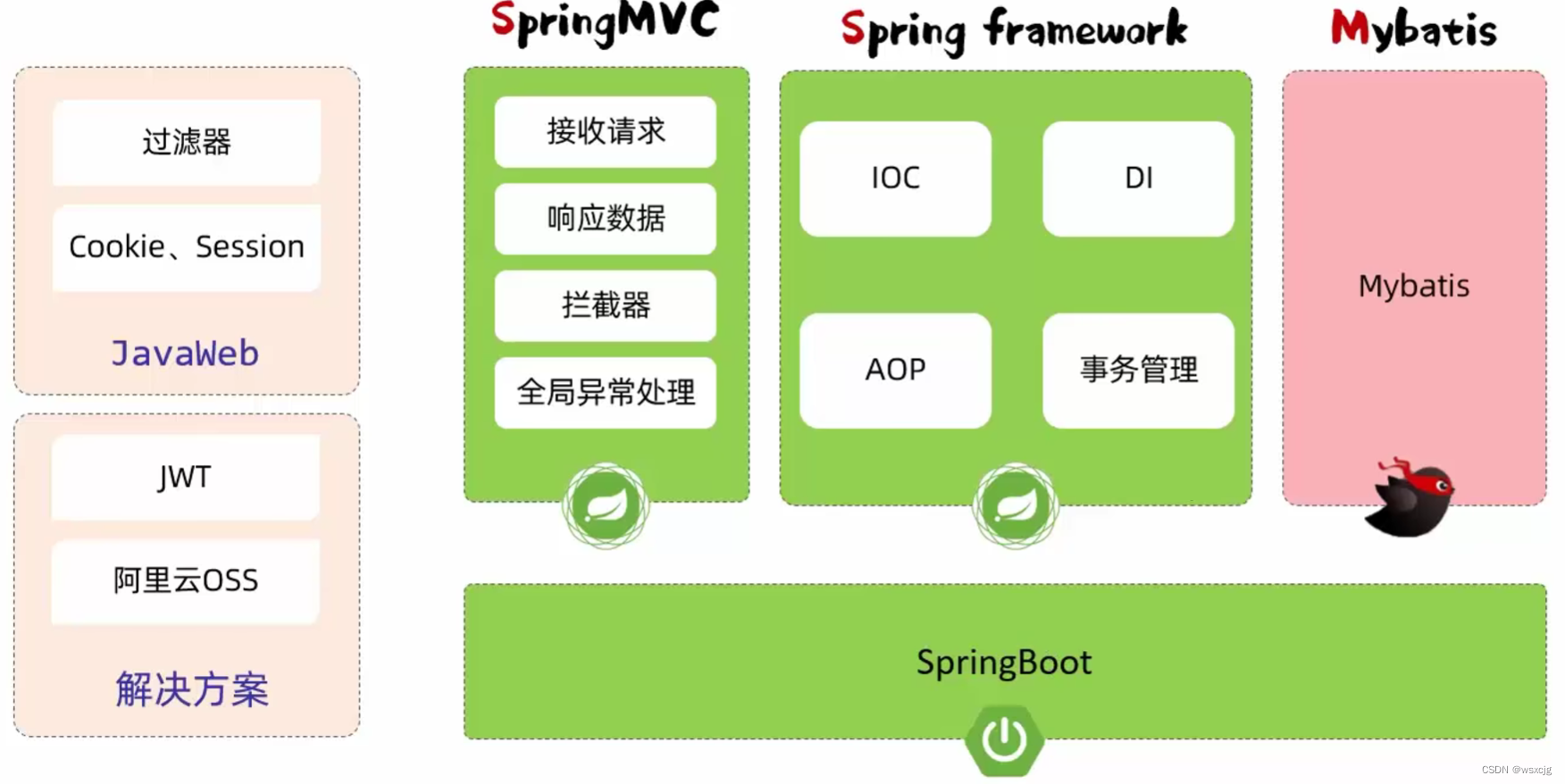
JavaWeb_SpringBootWeb案例
环境搭建: 开发规范 接口风格-Restful: 统一响应结果-Result: 开发流程: 第一步应该根据需求定义表结构和定义接口文档 注意: 本文代码从上往下一直添加功能,后面的模块下的代码包括前面的模块,…...

Linux中FTP安装
文章目录 一、FTP介绍1.1、FTP是什么1.2、FTP的工作原理1.3、FTP的传输模式1.4、FTP用户类别1.5、FTP的优点与缺点1.6、FTP数据传输格式 二、FTP客户端与服务端2.1、服务端2.2、客户端 三、FTP服务器软件介绍3.1、WU-FTPD3.2、ProFtpD3.3、vsftpd3.4、Pure-FTP3.5、FileZilla S…...

【Spring EL<二>✈️✈️ 】SL 表达式结合 AOP 注解实现鉴权
目录 🍻前言 🍸一、鉴权(Authorization) 🍺二、功能实现 2.1 环境准备 2.2 代码实现 2.3 测试接口 🍹三、测试功能 3.1 传递 admin 请求 3.2 传递普通 user 请求 🍻四、章末 &a…...
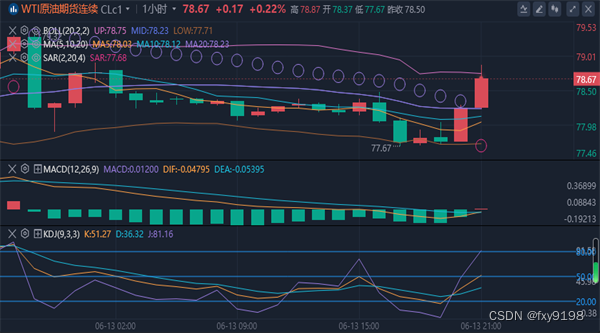
冯喜运:6.13美盘外汇黄金原油趋势分析及操作策略
【黄金消息面分析】:美国5月生产者价格指数(PPI)的意外下降,为市场带来了通胀可能见顶的积极信号。与此同时,初请失业金人数的上升,为劳动力市场的现状增添了一层不确定性。美国劳工统计局公布的数据显示&a…...
Lecture2——最优化问题建模
一,建模 1,重要性 实际上,我们并没有得到一个数学公式——通常问题是由某个领域的专家口头描述的。能够将问题转换成数学公式非常重要。建模并不是一件容易的事:有时,我们不仅想找到一个公式,还想找到一个…...
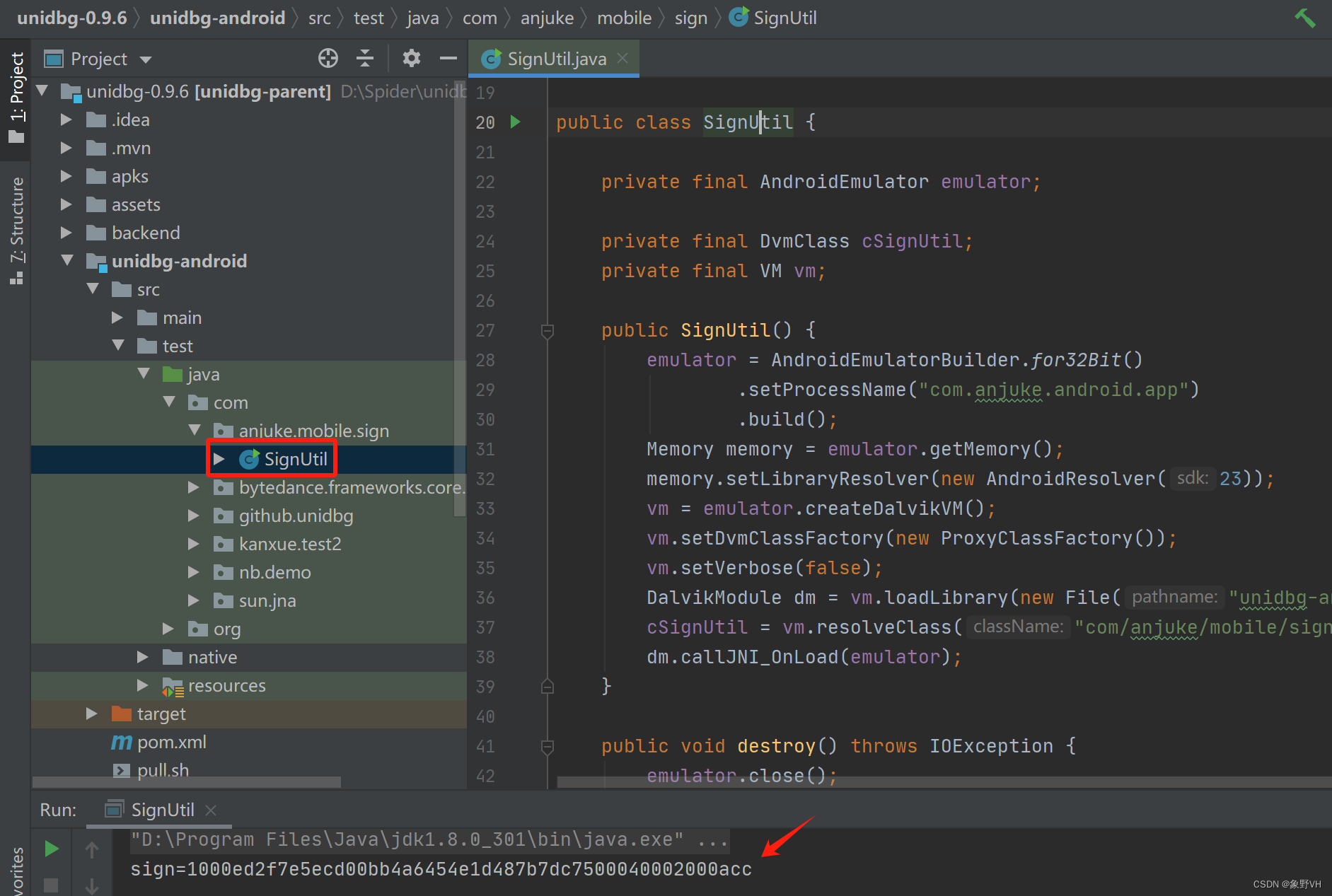
unidbg讲解V1
前言 unidbg是什么? unidbg是一个Java项目,可以帮助我们去模拟一个安卓或IOS设备,用于去执行so文件中的算法,从而不需要再去逆向他内部的算法。最终会产出一个jar包,可以被python进行调用。 如何使用unidbg? 下载github上开源的项目:https://github.com/zhkl0228/un…...

软设之敏捷方法
敏捷方法的总体目标是通过尽可能早地,持续地对有价值的软黏的交付,使客户满意 适用于:小步快跑的思想,适合小项目小团队 极限编程XP 4大价值观: 沟通 简单 反馈 勇气 5大原则 快速反馈 简单性假设 逐步修改…...

【设计模式深度剖析】【7】【行为型】【观察者模式】
👈️上一篇:中介者模式 设计模式-专栏👈️ 文章目录 观察者模式英文原文直译如何理解? 观察者模式的角色类图代码示例 观察者模式的应用观察者模式的优点观察者模式的缺点观察者模式的使用场景 观察者模式 观察者模式(Observer…...

列表的C++实
自动扩容 List item 扩容基数为2 可以设置扩容因子(这里我没有设置) 代码实现如下: // // Created by shaoxinHe on 2024/6/4. //#ifndef CPRIMER_MYLIST_H #define CPRIMER_MYLIST_H#include <stdexcept> #include <vector>namespace st…...

Chisel入门——在windows系统下部署Chisel环境并点亮FPGA小灯等实验
Chisel入门——在windows系统下部署Chisel环境并点亮FPGA小灯等实验 一、chisel简介二、vscode搭建scala开发环境2.1 安装Scala官方插件2.2 java版本(本人用的是jdk18)2.3 下载Scala Windows版本的二进制文件2.4 配置环境变量2.5 scala测试2.6 vscode运行…...

Python和C++赋值共享内存、Python函数传址传值、一些其他的遇到的bug
1、Numpy共享内存的情况: array1 np.array([1, 2, 3]) array2 array1 array2[0] 0 # array1也会跟着改变,就地操作 array2 array2 * 2 # array2不会跟着改变,属于非就地操作,会创建一个新的地址给array2array2 array1…...
深度解析ONLYOFFICE协作空间2.5版本新功能
深度解析ONLYOFFICE协作空间2.5版本新功能 上个月,4月份,ONLYOFFICE协作空间推出了V2.5版本,丰富了一些很实用的新功能,之前已经有文章介绍过了: ONLYOFFICE 协作空间 2.5 现已发布https://blog.csdn.net/m0_6827469…...
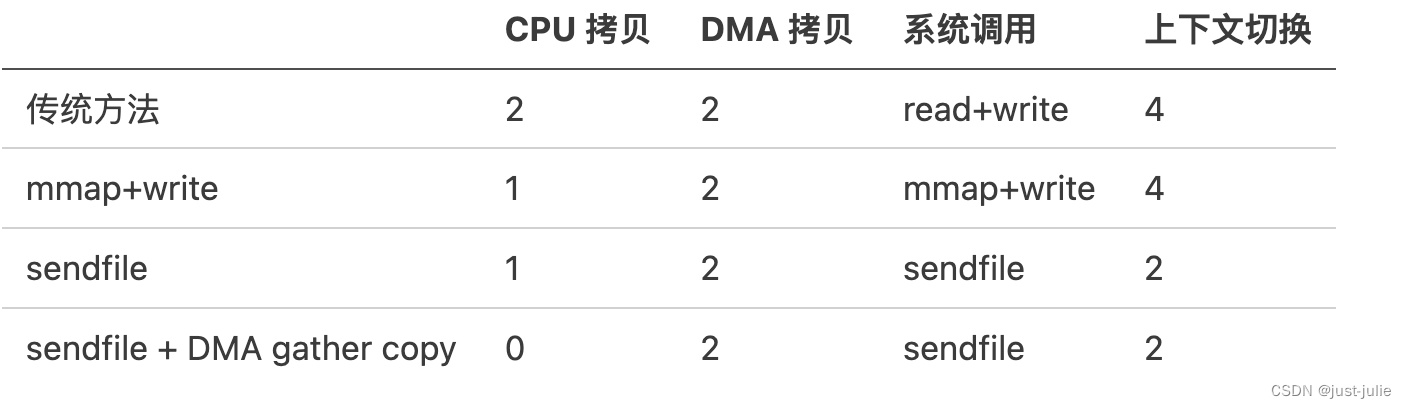
Java I/O模型
引言 根据冯.诺依曼结构,计算机结构分为5个部分:运算器、控制器、存储器、输入设备、输出设备。 输入设备和输出设备都属于外部设备。网卡、硬盘这种既可以属于输入设备,也可以属于输出设备。 从计算机结构的视角来看,I/O描述了…...

【简单介绍下Sass,什么是Sass?】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...

bat脚本—快速修改网络配置
一、bat编写前注意事项 windows桌面用文本文件打开把批命令输入在文本框中,保存采用ANSI编码,后缀用.bat 可参考博客——bat脚本简介学习原理以及具体创建方式 (文件扩展名位置) 语法准确性:严格遵循 BAT 脚本的语…...

node.js漏洞——
一.什么是node.js 简单的说 Node.js 就是运行在服务端的 JavaScript。 Node.js 是一个基于 Chrome JavaScript 运行时建立的一个平台。 Node.js 是一个事件驱动 I/O 服务端 JavaScript 环境,基于 Google 的 V8 引擎,V8 引擎执行 Javascript 的速度非常…...

9.5 点云采样——拓扑采样
图9-5-1 PointNet++中的邻域特征聚合的拓扑采样过程 拓扑/图结构采样的核心思想是“基于点云的局部拓扑关系(如K近邻、聚类)”进行采样,通过构建点云的拓扑图或聚类结构,选取每个局部区域的代表点,实现“局部保特征、全局均匀”的采样效果。 (1)出处 &n...

深夜“哔哔”声源排查指南:从原理到实战解决电子设备异响
1. 深夜“哔哔”声的普遍困扰与根源剖析你有没有在凌晨三点被一阵微弱但执着的“哔哔”声从睡梦中拽出来过?那种感觉,就像有个看不见的小精灵在你家天花板的某个角落,每隔一分钟就用气声对你进行一次精准的精神攻击。你猛地坐起,睡…...

模型运行记录
1753...

数据中台下半场比的是治理:六家主流厂商四维度横向测评
一、数据治理:决定数据中台价值兑现的关键变量2026年,一个行业的共识正在变得清晰:数据中台的上限由计算架构决定,但下限由数据治理决定。过去数年,大量企业投入资源搭建了数据中台的基础设施——数据湖、数仓、调度引…...

底特律汽车产业转型:从全球平台战略到创新生态重构
1. 从废墟中重生:底特律汽车产业的韧性复苏如果你在2010年前后关注过全球汽车产业,或者对美国的工业经济史稍有了解,那么“底特律”这个名字,在当时几乎就是“衰败”与“绝望”的同义词。这座曾经的“汽车之城”,在200…...

【无人机】基于动态反演和扩展状态观测器的无人机鲁棒姿态控制研究附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 完整代码获取 定制创新 论文复现点击:Matlab科研工作室🍊个人信条:格物致知,完整Matlab…...

抖音下载器终极指南:3分钟实现无水印批量下载的高效解决方案
抖音下载器终极指南:3分钟实现无水印批量下载的高效解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback…...
核心算法,搞定面试高频考点)
C++数据结构进阶|排序:吃透O(n log n)核心算法,搞定面试高频考点
文章目录 前言 一、希尔排序(Shell Sort)—— 插入排序的进阶优化版 二、快速排序(Quick Sort)—— C面试手写高频,实际开发首选 三、归并排序(Merge Sort)—— 稳定排序的核心选择 四、堆排…...
:框架、流程与量化基础)
信息安全工程师-网络安全风险评估(上篇):框架、流程与量化基础
一、引言 (一)核心定位与定义 网络安全风险评估是信息安全管理体系的核心方法论,在软考信息安全工程师考试中属于信息安全管理模块的高频考点,占比约 8-10 分。其标准定义为:依据 GB/T 20984-2007《信息安全技术 信息…...
核心原理、选型指南与EDA设计实战)
可编程逻辑器件(PLD/CPLD/FPGA)核心原理、选型指南与EDA设计实战
1. 项目概述:从怀旧到硬核,聊聊可编程逻辑的“前世今生”那天在网上闲逛,本想找点微马赛克艺术(Micromosaic)的制作视频,结果算法一个拐弯,把我带回了上世纪七八十年代的《大青蛙布偶秀》&#…...