KafkaQ - 好用的 Kafka Linux 命令行可视化工具
软件效果前瞻 ~
鉴于并没有在网上找到比较好的linux平台的kafka可视化工具,今天为大家介绍一下自己开发的在 Linux 平台上使用的可视化工具KafkaQ
虽然简陋,主要可以实现下面的这些功能:
1)查看当前topic的分片数量和副本数量
2)查看当前topic下面每个分片的最大offset
3)查看当前topic某个分片下面指定offset范围的数据
4)搜索当前topic指定关键词的message
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++

KafkaQ分为普通版本和搜索版本:
* 普通版本支持上述3种查询
* 搜索版本支持上述3种查询之外,增加关键词搜索,即在分片中搜索指定关键词的message
一、普通版 KafkaQ.sh

使用方法:
Usage: KafkaQ.sh --topic<topic> [--partition<partition>] [--offset<offset>] [--limit<limit>]--topic 话题名称
--partition 分片索引(可选)
--offset 从第k个offset开始检索(可选)
--limit 从第k个offset开始检索X条结果(可选)显示的效果如下,十分简洁,分片数据里面左边一列是消息入库的时间,右边是message内容:

KafkaQ 源码如下:
#!/bin/bash# 默认值
PARTITION=${2:-0}
OFFSET=${3:-0}
LIMIT=${4:-0}# 检查参数
if [ -z "$1" ]; thenecho "Usage: $0 --topic<topic> [--partition<partition>] [--offset<offset>] [--limit<limit>]"exit 1
fiTOPIC="$1"# 检查Kafka命令是否存在
if ! command -v /usr/local/kafka/bin/kafka-topics.sh >/dev/null 2>&1; thenecho "Kafka not found at /usr/local/kafka/bin/"exit 1
fi# 获取Topic信息
echo -e "\033[0;31m* 话题: $TOPIC\033[0m"# 获取分区数和副本数
PARTITION_INFO=$(/usr/local/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic "$TOPIC")
PARTITION_COUNT=$(echo "$PARTITION_INFO" | awk '/Partition:/ {print $2}' | wc -l)
REPLICA_COUNT=$(echo "$PARTITION_INFO" | grep -oP 'ReplicationFactor: \K\d+')echo "* 分片: $PARTITION_COUNT, 副本: $REPLICA_COUNT"# 获取分片a和分片b的最大偏移量
MAX_OFFSET=$(/usr/local/kafka/bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic "$TOPIC" | awk -F: '{ printf " 分片: %s,MaxOffset: %s\n", $2, $3 }')
echo "$MAX_OFFSET"# 获取分片数据
if [ "$LIMIT" -gt 0 ]; thenecho -e "\033[0;33mFetching messages from partition $PARTITION with offset $OFFSET and limit $LIMIT ...\033[0m"MESSAGES=$(/usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic "$TOPIC" --partition "$PARTITION" --offset "$OFFSET" --max-messages "$LIMIT" --property print.key=true --property print.value=true --property print.timestamp=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.StringDeserializer)# 格式化输出消息echo "$MESSAGES" | awk -F'\t' 'BEGIN {print "* 分片数据:"}{if ($3 != "null") {timestamp = substr($1, 12) / 1000 # 从第10个字符开始提取时间戳,并除以1000以转换为秒级时间戳value = $3printf "\033[0;33m%s\033[0m %s\n", strftime("%Y-%m-%d %H:%M:%S", timestamp), value}}'
fi
二、搜索版 KafkaQ-Search.sh
使用方法:
Usage: KafkaQ-Search.sh --topic<topic> [--partition<partition>] [--offset<offset>] [--limit<limit>] [--search<keyword>]--topic 话题名称
--partition 分片索引(可选)
--offset 从第k个offset开始检索(可选)
--limit 从第k个offset开始检索X条结果(可选)
--search 搜索字符串示例(所有参数是必选的哦):
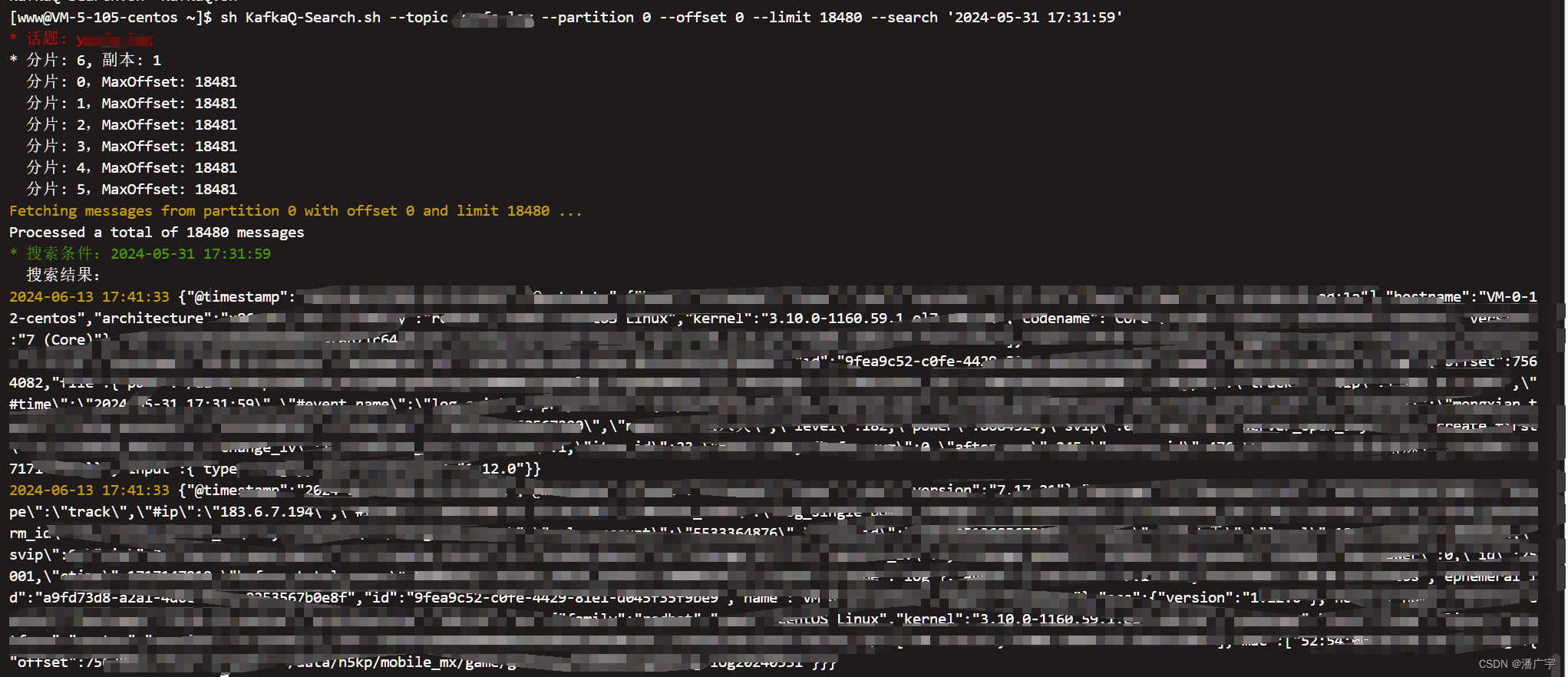
sh KafkaQ-Search.sh --topic log --partition 0 --offset 0 --limit 18480 --search '9fea9c52-c0fe-4429-81e1-d045f35f9be9'显示效果如下:

KafkaQ-Search.sh 源码如下:
#!/bin/bash# 默认值
PARTITION=${2:-0}
OFFSET=${3:-0}
LIMIT=${4:-0}
SEARCH=${5:-""}# 检查参数
if [ -z "$1" ]; thenecho "Usage: $0 --topic<topic> [--partition<partition>] [--offset<offset>] [--limit<limit>] [--search<keyword>]"exit 1
fiwhile [[ $# -gt 0 ]]; docase "$1" in--topic)TOPIC="$2"shift 2;;--partition)PARTITION="$2"shift 2;;--offset)OFFSET="$2"shift 2;;--limit)LIMIT="$2"shift 2;;--search)SEARCH="$2"shift 2;;*)echo "Unknown parameter: $1"exit 1;;esac
done# 检查Kafka命令是否存在
if ! command -v /usr/local/kafka/bin/kafka-topics.sh >/dev/null 2>&1; thenecho "Kafka not found at /usr/local/kafka/bin/"exit 1
fi# 获取Topic信息
echo -e "\033[0;31m* 话题: $TOPIC\033[0m"# 获取分区数和副本数
PARTITION_INFO=$(/usr/local/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic "$TOPIC")
PARTITION_COUNT=$(echo "$PARTITION_INFO" | awk '/Partition:/ {print $2}' | wc -l)
REPLICA_COUNT=$(echo "$PARTITION_INFO" | grep -oP 'ReplicationFactor: \K\d+')echo "* 分片: $PARTITION_COUNT, 副本: $REPLICA_COUNT"# 获取分片a和分片b的最大偏移量
MAX_OFFSET=$(/usr/local/kafka/bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic "$TOPIC" | awk -F: '{ printf " 分片: %s,MaxOffset: %s\n", $2, $3 }')
echo "$MAX_OFFSET"# 获取分片数据
if [ "$LIMIT" -gt 0 ]; thenecho -e "\033[0;33mFetching messages from partition $PARTITION with offset $OFFSET and limit $LIMIT ...\033[0m"MESSAGES=$(/usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic "$TOPIC" --partition "$PARTITION" --offset "$OFFSET" --max-messages "$LIMIT" --property print.key=true --property print.value=true --property print.timestamp=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.StringDeserializer)# 搜索关键词并输出结果if [[ ! -z $SEARCH ]]; thenecho -e "\033[0;32m* 搜索条件:$SEARCH\033[0m"echo " 搜索结果:"echo "$MESSAGES" | grep --color=never "$SEARCH" | awk -F'\t' '{timestamp = substr($1, 12) / 1000 # 从第12个字符开始提取时间戳,并除以1000以转换为秒级时间戳value = $3printf "\033[0;33m%s\033[0m %s\n", strftime("%Y-%m-%d %H:%M:%S", timestamp), value}'fi
fi
* (附注)参考的shell如下
1、获取kafka的topic 分区数量
/usr/local/kafka/bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic <topic>2、获取kafka每个分片最大的offset
/usr/local/kafka/bin/kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list localhost:9092 --topic <topic>3、获取kafka分片指定offset范围的具体信息
/usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic <topic> --partition <partition> --offset <offset> --max-messages <max-message> --property print.key=true --property print.value=true --property print.timestamp=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.StringDeserializer相关文章:
KafkaQ - 好用的 Kafka Linux 命令行可视化工具
软件效果前瞻 ~ 鉴于并没有在网上找到比较好的linux平台的kafka可视化工具,今天为大家介绍一下自己开发的在 Linux 平台上使用的可视化工具KafkaQ 虽然简陋,主要可以实现下面的这些功能: 1)查看当前topic的分片数量和副本数量 …...

不愧是字节,图像算法面试真细致
这本面试宝典是一份专为大四、研三春招和研二暑假实习生准备的珍贵资料。 涵盖了图像算法领域的核心知识和常见面试题,包括卷积神经网络、实例分割算法、目标检测、图像处理等多个方面。不论你是初学者还是有经验的老手,都能从中找到实用的内容。 通过…...

14、C++中代码重用
1、C模板的主要作用是允许编写通用代码,即能够在不同数据类型或数据结构上工作而无需重复编写代码。通过模板,可以实现代码的复用性和灵活性,从而提高开发效率和程序的可维护性。 typename关键字: 在C中,typename关键…...
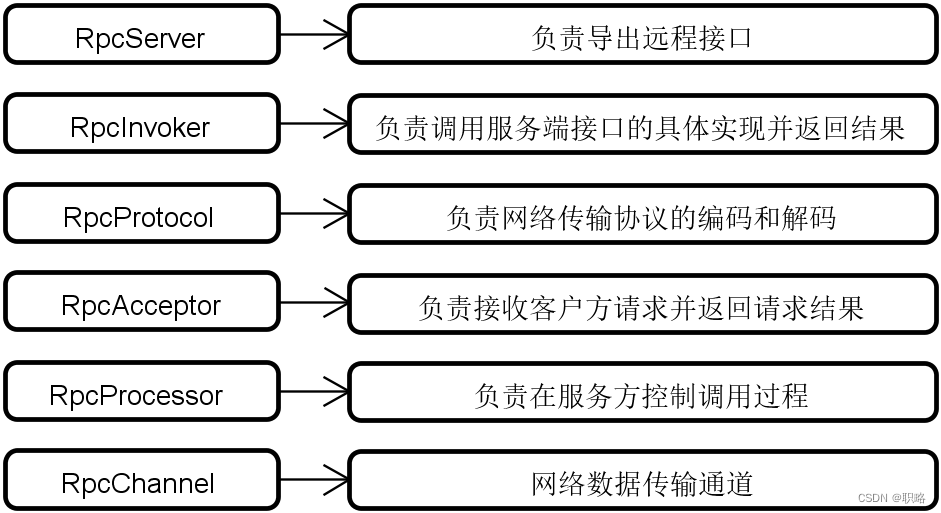
剖析框架代码结构的系统方法(下)
当面对Dubbo、Spring Cloud、Mybatis等开源框架时,我们可以采用一定的系统性的方法来快速把握它们的代码结构。这些系统方法包括对架构演进过程、核心执行流程、基础架构组成和可扩展性设计等维度的讨论。 在上一讲中,我们已经讨论了架构演进过程和核心执行流程这两个系统方法…...
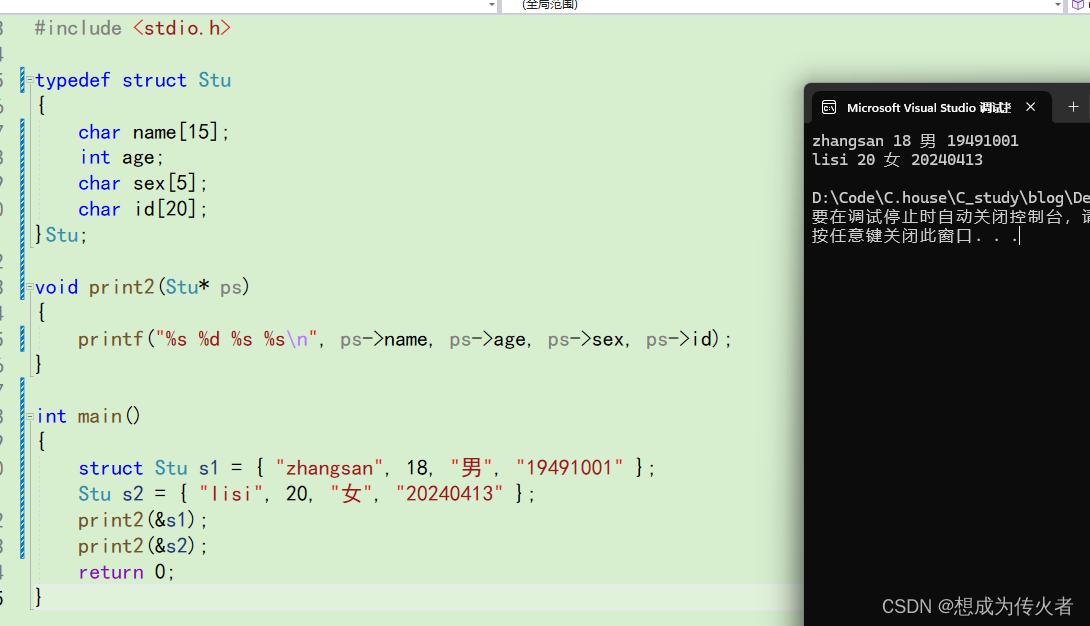
C语言学习笔记之结构体(一)
目录 什么是结构体? 结构体的声明 结构体变量的定义和初始化 结构体成员的访问 结构体传参 什么是结构体? 在现实生活中的很多事物无法用单一类型的变量就能描述清楚,如:描述一个学生,需要姓名,年龄&a…...

MATLAB入门知识
目录 原教程链接:数学建模清风老师《MATLAB教程新手入门篇》https://www.bilibili.com/video/BV1dN4y1Q7Kt/ 前言 历史记录 脚本文件(.m) Matlab帮助系统 注释 ans pi inf无穷大 -inf负无穷大 i j虚数单位 eps浮点相对精度 0/&a…...
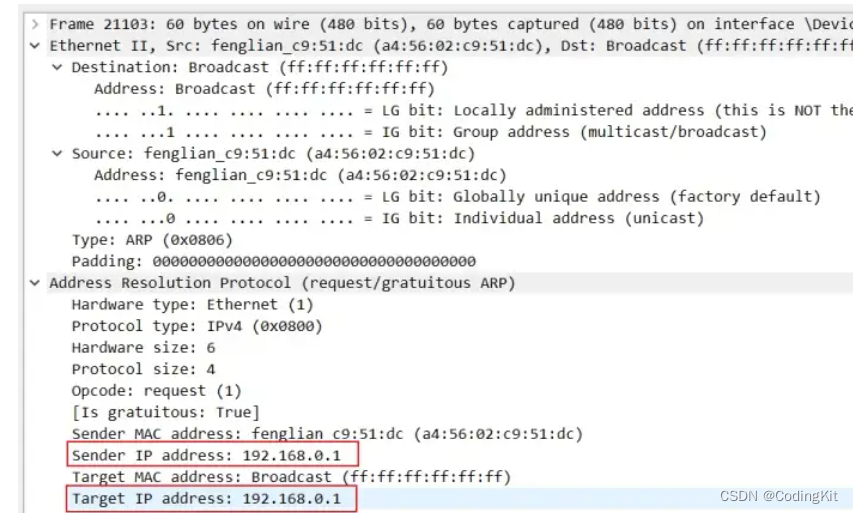
计算机网络(5) ARP协议
什么是ARP 地址解析协议,即ARP(Address Resolution Protocol),是根据IP地址获取物理地址的一个TCP/IP协议。主机发送信息时将包含目标IP地址的ARP请求广播到局域网络上的所有主机,并接收返回消息,以此确定…...

美团的 AI 面试有点简单
刷到一个美团的 AI 实习生的面试帖子,帖子虽然不长,但是把美团 AI 评测算法实习生面试的问题都po出来了。 单纯的看帖子中面试官提出的问题,并不是很难,大部分集中在考察AI项目和对AI模型的理解上,并没有过多的考察AI算…...

编程软件怎么给机器人编程:深入探索编程与机器人技术的融合
编程软件怎么给机器人编程:深入探索编程与机器人技术的融合 随着科技的飞速发展,机器人技术已经深入到我们生活的方方面面。而要让机器人按照我们的意愿执行任务,就需要借助编程软件对机器人进行编程。那么,编程软件究竟是如何给…...

unity2d Ugui--Image城市道路汽车行驶
目录 1.车辆生成与回收 2.路径点控制 3.车辆控制 1.车辆生成与回收 using System.Collections.Generic; using UnityEngine;public class RoadContr : MonoBehaviour {public WayPoint[] wayPoints; //出生点public Transform pare;[SerializeField]private Car[] fabCar;pu…...

【深度学习】【Prompt】使用GPT的一些提示词
f翻译论文用这个提示词: # 翻译规则## 翻译规则1 请在翻译这篇学术论文时,严格保留所有专业术语的原始英文表述,不要尝试将它们翻译成中文,而不是专业术语的部分,需要翻译为中文。保持所有文章引用格式和内容的完整无…...

如何在centos中和windows server中找到挖矿木马和消灭挖矿木马
在 CentOS 和 Windows Server 中查找和消灭挖矿木马涉及多个步骤,包括检测、清理和预防。以下是具体的步骤和命令。 在 CentOS 中查找和消灭挖矿木马 步骤 1:检测木马 检查异常进程: ps aux | grep -E miner|cryptonight|xmrig查找进程列表…...

Slice用法举例Python
Slice用法举例Python 在Python中,slice(切片)是一个强大的工具,用于处理序列类型的数据,如列表、元组、字符串等。slice提供了一种简洁而高效的方式来获取序列的子集或修改序列的某些部分。下面,我们将从四…...

响应式网页开发方法与实践
随着移动设备的普及和多样化,响应式网页开发已成为现代网页设计的主流趋势。响应式网页(Responsive Web Design, RWD)是一种网页设计技术,其核心思想是通过灵活的布局和媒体查询,使网页能够适应不同设备和屏幕尺寸&…...

feedparser - Python 解析Atom和RSSfeed
文章目录 一、关于 feedparser二、安装三、关于文档及构建四、测试五、常见RSS元素访问常见 Channel 元素访问常用项目元素 六、常见Atom元素访问常用feed元素访问公共入口元素 七、获取Atom元素的详细信息Feed元素的详细信息 八、测试元素是否存在九、其他功能 & 文档高级…...

ARM32开发--IIC时钟案例
知不足而奋进 望远山而前行 目录 文章目录 前言 目标 内容 需求 开发流程 移植驱动 修改I2C实现 测试功能 总结 前言 在现代嵌入式系统开发中,移植外设驱动并测试其功能是一项常见的任务。本次学习的目标是掌握移植方法和测试方法,以实现对开…...
[深度学习]基于C++和onnxruntime部署yolov10的onnx模型
基于C和ONNX Runtime部署YOLOv10的ONNX模型,可以遵循以下步骤: 准备环境:首先,确保已经下载后指定版本opencv和onnruntime的C库。 模型转换:按照官方源码:https://github.com/THU-MIG/yolov10 安装好yolov…...
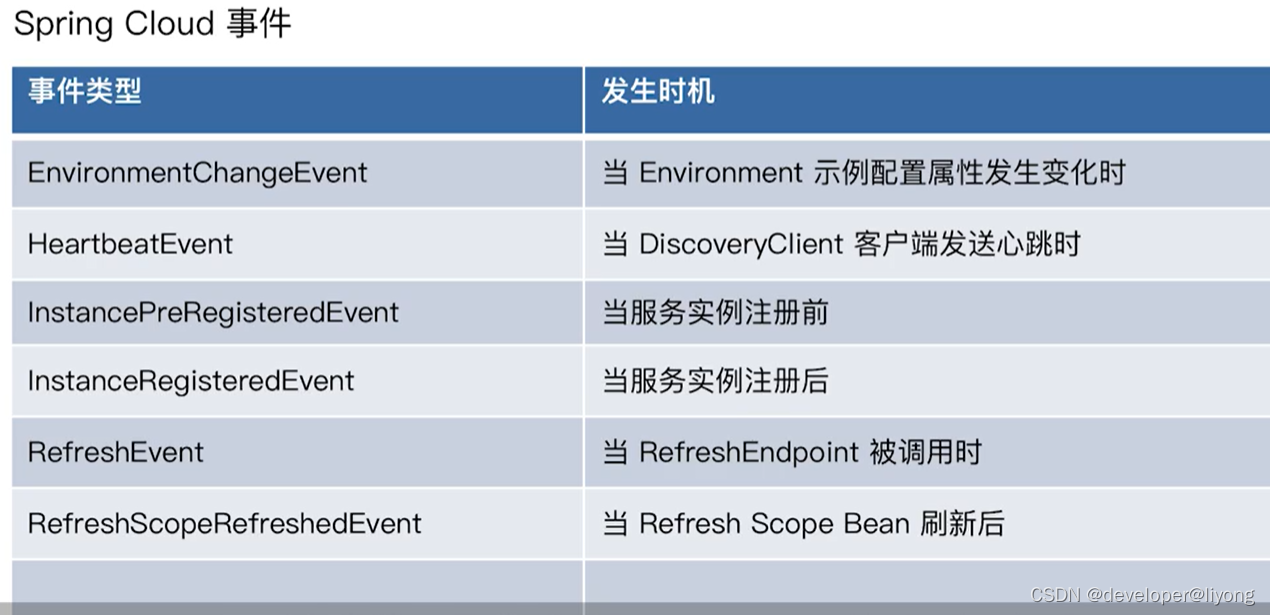
Spring-事件
Java 事件/监听器编程模型 设计模式-观察者模式的拓展 可观察者对象(消息发送者) Java.util.Observalbe观察者 java.util.Observer 标准化接口(标记接口) 事件对象 java.util.EventObject事件监听器 java.util.EventListener public class ObserverDemo {public static vo…...
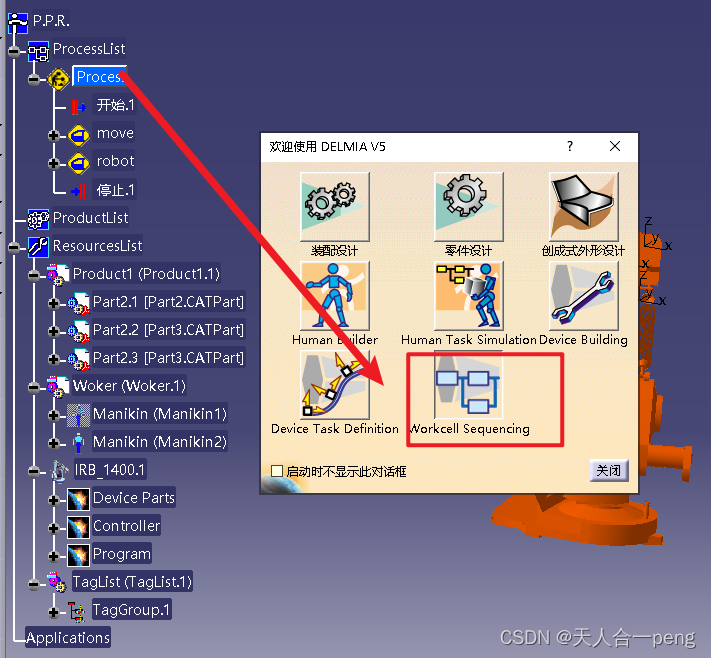
delmia的工序设置
process的设置需要在workcell sequuencing里面去设置...

【JavaEE精炼宝库】多线程(5)单例模式 | 指令重排序 | 阻塞队列
目录 一、单例模式: 1.1 饿汉模式: 1.2 懒汉模式: 1.2.1 线程安全的懒汉模式: 1.2.2 线程安全的懒汉模式的优化: 二、指令重排序 三、阻塞队列 3.1 阻塞队列的概念: 3.2 生产者消费者模型…...

Qwen3-ASR-0.6B方言识别效果展示:粤语、四川话实测
Qwen3-ASR-0.6B方言识别效果展示:粤语、四川话实测 1. 引言 语音识别技术发展至今,已经能够很好地处理普通话和英语等主流语言,但方言识别一直是技术难点。不同地区的方言在发音、语调、词汇上都有很大差异,让机器准确识别并非易…...

Phi-4-mini-reasoning一文详解:专为多步推理设计的开源大模型实战
Phi-4-mini-reasoning一文详解:专为多步推理设计的开源大模型实战 1. 模型概述 Phi-4-mini-reasoning是一款专注于推理任务的文本生成模型,特别擅长处理需要多步分析的复杂问题。与通用聊天模型不同,它被设计用来解决数学题、逻辑题等需要逐…...

避坑指南:在K210上跑人脸68关键点,这些细节让你的疲劳检测更准
K210人脸疲劳检测实战:68关键点调优与工程化避坑指南 当你在车载监控或工业安全场景部署基于K210的疲劳检测系统时,是否遇到过这些情况?明明按照开源代码跑通了68关键点检测,但实际场景中闭眼判断总是不准;白天阳光直射…...

如何选择高转化率的关键词_如何优化SEO关键词
<h2>如何选择高转化率的关键词</h2> <p>在现代数字营销中,选择高转化率的关键词是提升网站流量和销售额的关键。一个成功的SEO策略,需要在关键词选择上下足功夫,因为这直接影响到网站的整体效果。本文将从问题分析、原因说…...

终极Windows系统清理指南:免费工具让电脑重获新生
终极Windows系统清理指南:免费工具让电脑重获新生 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 您的Windows电脑是否变得越来越慢?C盘空…...

Windows记事本CVE-2026-20841漏洞分析:从命令注入根因、全链路攻击链到企业级纵深防御的全维度深度复盘
在Windows系统的生态里,从来没有一款工具能像记事本一样,拥有长达40年的“绝对安全”共识。 从1985年Windows 1.0首次预装,到如今Windows 11的全版本覆盖,这个仅数百KB的纯文本编辑器,始终是全球用户记录备忘、清理格…...
Pixel Epic效果展示:支持Markdown+LaTeX混合输出的学术论文初稿生成案例
Pixel Epic效果展示:支持MarkdownLaTeX混合输出的学术论文初稿生成案例 1. 像素史诗:科研写作的新范式 在传统学术写作工具普遍沉闷单调的背景下,Pixel Epic带来了一场视觉与功能双重革新的科研体验。这款基于AgentCPM-Report大模型的智能终…...

从七鳃鳗到潜水器:手把手教你用Python生态学模型搞定2024美赛A、B题
从七鳃鳗到潜水器:Python生态学建模实战指南 数学建模竞赛中,生态学问题往往让参赛者望而生畏——复杂的生物系统、多变的环境参数、非线性相互作用,这些要素叠加起来容易让人陷入理论推导的泥潭。但换个角度看,这正是Python科学计…...

Java POI读取大文件慢如何优化
用java poi处理大型excel文件时,往往会遇到阅读速度慢的问题,严重影响程序性能。本文将针对“java poi打开大文件的慢优化方法?”这个问题讨论了几个可行的解决方案,以帮助开发者提高程序效率。问题在于java poi 默认情况下&#…...

Kurento Media Server与OpenVidu集成:打造企业级视频会议系统
Kurento Media Server与OpenVidu集成:打造企业级视频会议系统 【免费下载链接】kurento-media-server [ARCHIVED] Contents migrated to monorepo: https://github.com/Kurento/kurento 项目地址: https://gitcode.com/gh_mirrors/ku/kurento-media-server K…...