十种排序方法
目录
1.冒泡排序(Bubble Sort)代码实现
2.选择排序(Selection Sort)代码实现
3.插入排序(Insertion Sort)
4.希尔排序(Shell Sort)代码实现
5.快速排序(Quick Sort)代码实现
6.归并排序(Merge Sort)代码实现
7.堆排序(Heap Sort)代码实现
8.计数排序(Counting Sort)代码实现
9.桶排序(Bucket Sort)代码实现
10.基数排序(Radix Sort)代码实现
在C语言中,有多种排序算法可供选择,每种都有其独特的特点和应用场景。以下是几种常见的排序算法及其在C语言中的总结:
1. 冒泡排序(Bubble Sort)
原理:通过重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
时间复杂度:O(n^2),其中n是待排序数组的长度。
空间复杂度:O(1),只需要常数个额外空间。
2. 选择排序(Selection Sort)
原理:首先在未排序序列中找到最小(或最大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(或最大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
时间复杂度:O(n^2),其中n是待排序数组的长度。
空间复杂度:O(1),只需要常数个额外空间。
3. 插入排序(Insertion Sort)
原理:通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
时间复杂度:O(n^2),最坏情况下;O(n),最好情况下(已排序数组)。
空间复杂度:O(1),只需要常数个额外空间。
4. 希尔排序(Shell Sort)
原理:是插入排序的一种更高效的改进版本,也称为缩小增量排序,是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。
时间复杂度:依赖于增量序列的选择,最坏情况下O(n^2),最好情况下O(n log n)。空间复杂度:O(1),只需要常数个额外空间。
5. 快速排序(Quick Sort)
原理:通过一次排序将待排序的数据分割成独立的两部分,其中一部分的所有数据都比另一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
时间复杂度:O(n log n),平均情况;O(n^2),最坏情况下(例如当输入数据已经排序或接近排序时)。
空间复杂度:O(log n),递归栈空间;但在最坏情况下需要O(n)的额外空间。
6. 归并排序(Merge Sort)
原理:将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
时间复杂度:O(n log n),其中n是待排序数组的长度。
空间复杂度:O(n),需要额外的空间来存储临时数组。
7. 堆排序(Heap Sort)
原理:是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子节点的键值或索引总是小于(或者大于)它的父节点。
时间复杂度:O(n log n),其中n是待排序数组的长度。
空间复杂度:O(1),只需要常数个额外空间。
8. 计数排序(Counting Sort)
原理:不是基于比较的排序算法,其核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
时间复杂度:O(n+k),其中k是整数的范围。
空间复杂度:O(n+k),需要额外的数组来存储计数。
9. 桶排序(Bucket Sort)
原理:是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。为了使桶排序更加高效,我们需要做到这两点:首先,要使得数据分散得尽可能均匀;其次,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。
时间复杂度:O(n+n^2/k+k),其中n是待排序数组的长度,k是桶的数量。当桶的数量接近或等于数组的长度时,退化为O(n^2)。
空间复杂度:O(n+k),需要额外的数组来存储桶。
10. 基数排序(Radix Sort)
原理:是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。
时间复杂度:O(nk),其中n是待排序数组的长度,k是数字的位数。
空间复杂度:O(n+k),需要额外的数组来存储临时数据。
1.冒泡排序(Bubble Sort)代码实现
是一种简单的排序算法,它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。以下是使用C语言实现的冒泡排序算法:
#include <stdio.h>// 冒泡排序函数
void bubbleSort(int arr[], int n) {int i, j, temp;for (i = 0; i < n-1; i++) { // 外层循环控制遍历的次数for (j = 0; j < n-i-1; j++) { // 内层循环控制每次遍历需要比较的次数if (arr[j] > arr[j+1]) { // 如果前一个元素大于后一个元素,则交换temp = arr[j];arr[j] = arr[j+1];arr[j+1] = temp;}}}
}// 打印数组
void printArray(int arr[], int size) {int i;for (i=0; i < size; i++)printf("%d ", arr[i]);printf("\n");
}int main() {int arr[] = {64, 34, 25, 12, 22, 11, 90};int n = sizeof(arr)/sizeof(arr[0]);bubbleSort(arr, n);printf("Sorted array: \n");printArray(arr, n);return 0;
}在这个示例中,bubbleSort 函数接受一个整数数组 arr 和数组的大小 n 作为参数。然后,它使用两个嵌套的循环来进行排序。外层循环控制遍历的次数,而内层循环则负责每次遍历时的元素比较和可能的交换。如果前一个元素大于后一个元素,则交换它们的位置。
这个算法的效率并不高,特别是当待排序的数组已经有序或者接近有序时,因为仍然会进行不必要的比较和交换。然而,冒泡排序的实现简单易懂,因此经常被用作教学示例。
冒泡排序的时间复杂度在最坏的情况下是 O(n^2),其中 n 是数组的大小。在最好的情况下(即数组已经有序),时间复杂度是 O(n)。然而,由于冒泡排序在实际应用中并不高效,因此它通常不被用于大数据集的排序。
2.选择排序(Selection Sort)代码实现
是一种简单直观的排序算法。它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
以下是使用C语言实现的选择排序算法:
#include <stdio.h>void selectionSort(int arr[], int n) {int i, j, minIndex, temp;for (i = 0; i < n - 1; i++) {// 找到未排序部分中的最小元素minIndex = i;for (j = i + 1; j < n; j++) {if (arr[j] < arr[minIndex]) {minIndex = j;}}// 将找到的最小元素与未排序部分的第一个元素交换temp = arr[minIndex];arr[minIndex] = arr[i];arr[i] = temp;}
}int main() {int arr[] = {64, 25, 12, 22, 11};int n = sizeof(arr) / sizeof(arr[0]);selectionSort(arr, n);printf("Sorted array: \n");for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}return 0;
}在这个示例中,selectionSort 函数接收一个整数数组和数组的大小作为参数。它使用了两层循环。外层循环控制已排序部分的末尾位置,内层循环用于从未排序部分中找到最小元素的位置。一旦找到最小元素的位置,就将其与未排序部分的第一个元素(即当前外循环的索引位置)交换。
选择排序是不稳定的排序算法,因为在交换过程中,相等元素的相对顺序可能会发生变化。
选择排序的时间复杂度为 O(n^2),其中 n 是待排序数组的大小。这是因为对于每一个元素,我们都需要遍历剩余的未排序部分来找到最小(或最大)的元素。因此,选择排序在大数据集上的效率不如一些更先进的排序算法,如快速排序、归并排序或堆排序。但是,由于选择排序的实现简单且易于理解,它在算法教学或小型数据集上仍然很受欢迎。
3.插入排序(Insertion Sort)
是一种简单直观的排序算法,它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
以下是使用C语言实现的插入排序算法:
#include <stdio.h>void insertionSort(int arr[], int n) {int i, key, j;for (i = 1; i < n; i++) {key = arr[i];j = i - 1;/* 将大于key的元素向后移动 */while (j >= 0 && arr[j] > key) {arr[j + 1] = arr[j];j = j - 1;}arr[j + 1] = key;}
}int main() {int arr[] = {12, 11, 13, 5, 6};int n = sizeof(arr) / sizeof(arr[0]);insertionSort(arr, n);printf("Sorted array: \n");for (int i = 0; i < n; i++)printf("%d ", arr[i]);return 0;
}在这个示例中,insertionSort 函数接收一个整数数组和数组的大小作为参数。它使用两层循环来实现插入排序。外层循环遍历数组中的每个元素(从第二个元素开始),内层循环则将当前元素(称为key)与其前面的元素进行比较,如果前面的元素比key大,则将它们向后移动一位,直到找到key的正确位置或者已经到达数组的开始。然后,将key插入到正确的位置上。
主函数 main 创建一个整数数组并调用 insertionSort 函数对其进行排序,然后打印排序后的数组。
4.希尔排序(Shell Sort)代码实现
是插入排序的一种更高效的改进版本,也称为缩小增量排序。它的基本思想是:先将整个待排序的记录序列分割成为若干子序列(由相隔某个“增量”的记录组成)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的记录“基本有序”时,再对全体记录进行一次直接插入排序。
希尔排序通过比较相距一定间隔的元素来工作,各趟比较所用的距离随着算法的进行而减小,直到只比较相邻元素的最后一趟排序为止。
以下是使用C语言实现的希尔排序算法:
#include <stdio.h>void shellSort(int arr[], int n) {int gap, i, j, temp;for (gap = n / 2; gap > 0; gap /= 2) { // 初始gap为数组长度的一半,然后逐渐缩小for (i = gap; i < n; i++) { // 从gap位置开始,对每个子序列进行插入排序temp = arr[i];for (j = i; j >= gap && arr[j - gap] > temp; j -= gap) {arr[j] = arr[j - gap]; // 将大于temp的元素后移}arr[j] = temp; // 找到temp的插入位置}}
}int main() {int arr[] = {12, 34, 54, 2, 3};int n = sizeof(arr) / sizeof(arr[0]);shellSort(arr, n);printf("Sorted array: \n");for (int i = 0; i < n; i++)printf("%d ", arr[i]);return 0;
}在这个示例中,shellSort 函数接收一个整数数组和数组的大小作为参数。它使用一个外部循环来逐渐减小增量(gap),内部循环则对每个由当前gap定义的子序列执行插入排序。初始时,gap通常设置为数组长度的一半,并在每次迭代中除以2(或者其他数)来逐渐减小,直到gap为1,此时算法就退化为普通的插入排序。
希尔排序的时间复杂度依赖于增量序列的选择,不同的增量序列会导致不同的执行效率。上述示例中使用的增量序列是最简单的递减序列,即每次减半。在实际应用中,可能会使用更复杂的增量序列来提高效率。
需要注意的是,希尔排序是不稳定的排序算法,即相等的元素在排序后可能会改变其相对顺序。
5.快速排序(Quick Sort)代码实现
是一种高效的排序算法,它采用了分治法的思想。快速排序的基本思想是:选择一个基准元素(pivot),通过一趟排序将待排序的数据分割成独立的两部分,其中一部分的所有数据都比另一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
以下是使用C语言实现的快速排序算法:
#include <stdio.h>// 快速排序的划分函数
int partition(int arr[], int low, int high) {int pivot = arr[high]; // 选择最右边的元素作为基准int i = (low - 1); // 指向小于基准的元素的最后一个位置for (int j = low; j <= high - 1; j++) {// 如果当前元素小于或等于基准if (arr[j] <= pivot) {i++; // 增加 i// 交换 arr[i] 和 arr[j]int temp = arr[i];arr[i] = arr[j];arr[j] = temp;}}// 将基准元素交换到它最终的位置 arr[i+1]int temp = arr[i + 1];arr[i + 1] = arr[high];arr[high] = temp;return (i + 1);
}// 快速排序函数
void quickSort(int arr[], int low, int high) {if (low < high) {/* pi 是分区点,arr[pi] 已经到位 */int pi = partition(arr, low, high);// 分别对基准元素左边的子序列和右边的子序列进行快速排序quickSort(arr, low, pi - 1);quickSort(arr, pi + 1, high);}
}// 打印数组
void printArray(int arr[], int size) {int i;for (i = 0; i < size; i++)printf("%d ", arr[i]);printf("\n");
}// 主函数
int main() {int arr[] = {10, 7, 8, 9, 1, 5};int n = sizeof(arr) / sizeof(arr[0]);quickSort(arr, 0, n - 1);printf("Sorted array: \n");printArray(arr, n);return 0;
}在这个示例中,quickSort 函数是递归的,它接受一个整数数组 arr 和要排序的数组段的起始 low 和结束 high 索引作为参数。函数首先检查基本情况(即 low 是否小于 high),然后调用 partition 函数来选择一个基准元素并将数组分成两部分。然后,它递归地对基准元素左右两侧的子数组进行快速排序。
partition 函数负责选择基准元素(在这个例子中是最右边的元素),然后将数组重新排列,使得所有小于基准的元素都在基准的左边,所有大于基准的元素都在基准的右边。函数最后返回基准元素的最终位置。
快速排序的平均时间复杂度是 O(n log n),但在最坏的情况下(即每次划分都极度不平衡),时间复杂度会退化为 O(n^2)。然而,通过随机化基准元素的选择或使用三数取中等技巧,可以大大降低最坏情况发生的概率。
6.归并排序(Merge Sort)代码实现
是一种典型的分治算法,它将一个大问题分解为两个或更多个小问题,然后递归地解决这些小问题,最后将解决的小问题合并起来,从而完成对整个数据的排序。
以下是使用C语言实现的归并排序算法:
#include <stdio.h>// 合并两个已排序的数组
void merge(int arr[], int left[], int leftSize, int right[], int rightSize) {int i = 0, j = 0, k = 0;while (i < leftSize && j < rightSize) {if (left[i] <= right[j]) {arr[k++] = left[i++];} else {arr[k++] = right[j++];}}// 拷贝剩余的元素while (i < leftSize) {arr[k++] = left[i++];}while (j < rightSize) {arr[k++] = right[j++];}
}// 归并排序函数
void mergeSort(int arr[], int left, int right) {if (left < right) {int mid = left + (right - left) / 2;int leftSize = mid - left + 1;int rightSize = right - mid;// 创建临时数组int leftArr[leftSize], rightArr[rightSize];// 拷贝数据到临时数组for (int i = 0; i < leftSize; i++) {leftArr[i] = arr[left + i];}for (int j = 0; j < rightSize; j++) {rightArr[j] = arr[mid + 1 + j];}// 递归地对左右子数组进行排序mergeSort(leftArr, 0, leftSize - 1);mergeSort(rightArr, 0, rightSize - 1);// 合并临时数组回原数组merge(arr, leftArr, leftSize, rightArr, rightSize);}
}// 打印数组
void printArray(int arr[], int size) {for (int i = 0; i < size; i++) {printf("%d ", arr[i]);}printf("\n");
}// 主函数
int main() {int arr[] = {12, 11, 13, 5, 6, 7};int arrSize = sizeof(arr) / sizeof(arr[0]);printf("Given array is \n");printArray(arr, arrSize);mergeSort(arr, 0, arrSize - 1);printf("\nSorted array is \n");printArray(arr, arrSize);return 0;
}在这个示例中,mergeSort 函数是递归的,它首先将数组分成两半,然后递归地对这两半进行排序。当递归调用返回时,merge 函数被用来合并两个已排序的子数组,生成一个完整的已排序数组。
归并排序的时间复杂度是 O(n log n),其中 n 是数组的大小。这个算法是稳定的,即具有相同值的元素在排序后的相对顺序保持不变。归并排序的空间复杂度取决于实现方式,如果使用了额外的数组来存储临时数据,则空间复杂度为 O(n)。然而,如果原地(in-place)归并排序的变种被实现,则空间复杂度可以降低到 O(log n)(忽略递归栈的额外空间)。但是,原地归并排序通常更加复杂且难以实现。
7.堆排序(Heap Sort)代码实现
是一种基于二叉堆这种数据结构所设计的排序算法。它是选择排序的一种有效改进版本,其基本思想是将待排序的序列构造成一个大顶堆(或小顶堆),此时,整个序列的最大值(或最小值)就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值(或最小值)。然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了。
以下是使用C语言实现的堆排序算法:
#include <stdio.h>// 交换两个元素
void swap(int* a, int* b) {int t = *a;*a = *b;*b = t;
}// 堆调整,从当前节点开始向下调整
void heapify(int arr[], int n, int i) {int largest = i; // 初始化largest为根int left = 2 * i + 1; // 左子节点int right = 2 * i + 2; // 右子节点// 如果左子节点大于根if (left < n && arr[left] > arr[largest])largest = left;// 如果右子节点大于目前已知的最大if (right < n && arr[right] > arr[largest])largest = right;// 如果最大不是根if (largest != i) {swap(&arr[i], &arr[largest]);// 递归地调整受影响的子堆heapify(arr, n, largest);}
}// 堆排序
void heapSort(int arr[], int n) {// 构建一个大顶堆for (int i = n / 2 - 1; i >= 0; i--)heapify(arr, n, i);// 一个个从堆顶取出元素for (int i = n - 1; i >= 0; i--) {// 将当前最大的元素arr[0]和arr[i]交换swap(&arr[0], &arr[i]);// 重新调整堆heapify(arr, i, 0);}
}int main() {int arr[] = {12, 11, 13, 5, 6, 7};int n = sizeof(arr) / sizeof(arr[0]);heapSort(arr, n);printf("Sorted array: \n");for (int i = 0; i < n; i++)printf("%d ", arr[i]);return 0;
}在这个示例中,heapSort 函数首先通过 heapify 函数将数组构造成一个大顶堆。然后,它将堆顶元素(即当前的最大值)与数组的最后一个元素交换,并将剩余的元素重新调整为大顶堆。这个过程重复进行,直到整个数组有序。
堆排序的时间复杂度是 O(n log n),其中 n 是待排序数组的大小。这是因为构建堆的时间复杂度是 O(n),并且调整堆和交换元素的操作在 n-1 次循环中发生,每次循环的复杂度是 O(log n)。因此,堆排序是一种非常高效的排序算法。同时,堆排序是一种原地排序算法,因为它只需要常数个额外的空间来存储临时数据。
8.计数排序(Counting Sort)代码实现
是一种非基于比较的排序算法,适用于一定范围内的整数排序。其核心思想是利用一个额外的数组(计数数组)来记录每个元素出现的次数,然后根据计数数组来将元素放到正确的位置上。
以下是计数排序在C语言中的实现总结:1. 计数排序的基本步骤
找出待排序的数组中最大和最小的元素:为了确定计数数组的长度和元素的映射范围。
统计数组中每个值为 i 的元素出现的次数:遍历输入数组,增加计数数组中对应索引的计数。
对计数数组进行累加操作:从计数数组的第二个元素开始,每个元素都加上前一个元素的值,得到一个新数组。新数组的第 i 个元素表示原数组中值小于等于 i 的元素个数。
根据计数数组得到排序后的数组:从后往前遍历输入数组,根据计数数组确定当前元素在排序后数组中的位置,并将元素放到该位置。
计数数组在排序后不再需要,可以释放(如果是在动态分配的内存中)。
2. C语言实现示例
#include <stdio.h>
#include <stdlib.h>void countingSort(int arr[], int n) {int max = arr[0];int min = arr[0];for (int i = 1; i < n; i++) {if (arr[i] > max) max = arr[i];if (arr[i] < min) min = arr[i];}int range = max - min + 1;int count[range];for (int i = 0; i < range; i++) {count[i] = 0;}for (int i = 0; i < n; i++) {count[arr[i] - min]++;}for (int i = 1; i < range; i++) {count[i] += count[i - 1];}int output[n];for (int i = n - 1; i >= 0; i--) {output[count[arr[i] - min] - 1] = arr[i];count[arr[i] - min]--;}// 将排序后的数组复制回原数组(如果需要)for (int i = 0; i < n; i++) {arr[i] = output[i];}
}int main() {int arr[] = {4, 2, 2, 8, 3, 3, 1};int n = sizeof(arr) / sizeof(arr[0]);countingSort(arr, n);for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}return 0;
}3. 计数排序的适用场景
数据范围小:计数排序的复杂度取决于数据范围的大小,而不是数据量的大小。如果数据范围很大,计数数组也会很大,会占用大量内存。
非负整数:计数排序通常用于非负整数排序,因为需要确定一个明确的范围来构建计数数组。如果包含负数或浮点数,需要进行额外的处理。
稳定排序:计数排序是稳定的排序算法,即相等的元素在排序后保持原有的顺序。
9.桶排序(Bucket Sort)代码实现
是一种分配式排序算法,它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。为了使桶排序更加高效,我们需要做到这两点:首先,要使得数据分散得尽可能均匀;其次,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。
以下是桶排序在C语言中的实现总结:
1. 桶排序的基本步骤
确定桶的数量和大小:根据待排序数组的范围确定桶的数量,以及每个桶所能容纳的范围。
初始化桶:创建一个空的桶数组(或者使用其他数据结构如链表、动态数组等),每个桶都初始化为空。
分配元素到桶中:遍历待排序数组,将每个元素分配到对应的桶中。
对每个桶中的元素进行排序:可以使用任何有效的排序算法对每个桶中的元素进行排序,如插入排序、快速排序等。
合并桶中的元素:按照桶的顺序,将桶中的元素依次取出,合并成一个有序数组。
2. C语言实现示例
这里假设我们处理的是非负整数,并且知道数据的最大值 maxValue。
#include <stdio.h>
#include <stdlib.h>void bucketSort(int arr[], int n, int maxValue) {// 桶的数量int bucketSize = maxValue / n + 1;int bucketCount = (maxValue / bucketSize) + 1;// 初始化桶int* buckets = (int*)calloc(bucketCount, sizeof(int*));for (int i = 0; i < bucketCount; i++) {buckets[i] = (int*)malloc(sizeof(int) * bucketSize);int j;for (j = 0; j < bucketSize; j++) {buckets[i][j] = -1; // 标记为未使用}}// 将元素分配到桶中for (int i = 0; i < n; i++) {int index = arr[i] / bucketSize;int offset = arr[i] % bucketSize;int j;for (j = 0; j < bucketSize; j++) {if (buckets[index][j] == -1) {buckets[index][j] = arr[i];break;}}}// 对每个桶进行排序(这里使用插入排序作为示例)for (int i = 0; i < bucketCount; i++) {int k = 0;while (buckets[i][k] != -1) {int j = k + 1;while (j < bucketSize && buckets[i][j] != -1) {if (buckets[i][j] < buckets[i][j - 1]) {int temp = buckets[i][j];buckets[i][j] = buckets[i][j - 1];buckets[i][j - 1] = temp;}j++;}k++;}}// 合并桶中的元素int index = 0;for (int i = 0; i < bucketCount; i++) {for (int j = 0; j < bucketSize; j++) {if (buckets[i][j] != -1) {arr[index++] = buckets[i][j];}}}// 释放桶的内存for (int i = 0; i < bucketCount; i++) {free(buckets[i]);}free(buckets);
}int main() {int arr[] = {4, 2, 2, 8, 3, 3, 1, 10};int n = sizeof(arr) / sizeof(arr[0]);int maxValue = 10; // 假设已知数据的最大值bucketSort(arr, n, maxValue);for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}return 0;
}3. 桶排序的适用场景
数据分布均匀:当待排序的数据分布比较均匀时,桶排序的效率会非常高。
数据范围大但数据量不大:桶排序适合处理数据范围大但数据量不大的情况。如果数据量非常大,桶的数量也会非常大,这可能会导致内存消耗过多。
非负整数:桶排序通常用于非负整数排序,如果包含负数或浮点数,需要进行额外的处理。
10.基数排序(Radix Sort)代码实现
是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。基数排序使用了计数排序(Counting Sort)作为子程序。
基数排序有两种常见的实现方式:最低位优先(Least Significant Digit first, LSD)和最高位优先(Most Significant Digit first, MSD)。通常,LSD 更常用,因为它可以从低位到高位依次排序,而不需要像 MSD 那样进行递归或栈操作。
以下是基数排序的 C 语言实现(使用 LSD 方法):
#include <stdio.h>
#include <stdlib.h>
#include <string.h>// 假设我们处理的是非负整数,并且知道最大的数的位数 maxDigit
void countingSort(int arr[], int n, int exp) {int output[n];int count[10] = {0};// 存储每个元素的出现次数for (int i = 0; i < n; i++) {count[(arr[i] / exp) % 10]++;}// 更改 count[i] 使得 count[i] 现在包含小于或等于 i 的数字的数量for (int i = 1; i < 10; i++) {count[i] += count[i - 1];}// 生成输出数组for (int i = n - 1; i >= 0; i--) {output[count[(arr[i] / exp) % 10] - 1] = arr[i];count[(arr[i] / exp) % 10]--;}// 复制回原数组for (int i = 0; i < n; i++) {arr[i] = output[i];}
}// 基数排序函数
void radixsort(int arr[], int n) {// 找到数组中最大的数int max = arr[0];for (int i = 1; i < n; i++) {if (arr[i] > max) {max = arr[i];}}// 计算最大数的位数int maxDigit = 0;while (max > 0) {max /= 10;maxDigit++;}// 对每一位进行计数排序for (int exp = 1; exp <= maxDigit; exp *= 10) {countingSort(arr, n, exp);}
}int main() {int arr[] = {170, 45, 75, 90, 802, 24, 2, 66};int n = sizeof(arr) / sizeof(arr[0]);radixsort(arr, n);printf("Sorted array: \n");for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}return 0;
}在这个示例中,我们首先通过 countingSort 函数对数组的每个位进行排序。然后,在 radixsort 函数中,我们确定最大数的位数,并对每一位调用 countingSort 函数。最后,在 main 函数中,我们测试基数排序并打印排序后的数组。
相关文章:

十种排序方法
目录 1.冒泡排序(Bubble Sort)代码实现 2.选择排序(Selection Sort)代码实现 3.插入排序(Insertion Sort) 4.希尔排序(Shell Sort)代码实现 5.快速排序(Quick Sort&…...
docker-compose启动oracle11、并使用navicat进行连接
一、docker-compose.yml version: 3.9 services:oracle:image: registry.cn-hangzhou.aliyuncs.com/helowin/oracle_11grestart: alwaysprivileged: truecontainer_name: oracle11gvolumes:- ./data:/u01/app/oracleports:- 1521:1521network_mode: "host"logging:d…...

使用ffmpeg进行音频处理
音频处理是数字媒体制作中不可或缺的一部分,而ffmpeg作为一款强大的多媒体处理工具,为我们提供了丰富的音频处理功能。 一、查看音频信息 在处理音频之前,了解音频的基本信息是非常重要的。FFmpeg的ffprobe工具可以帮助我们查看音频的详细信息,如采样率、位深等。 示例命…...

重装系统,以及设置 深度 学习环境
因为联想y7000在ubantu系统上连不到wifi,所以打算弄双系统 第一步:下载win10镜像,之后在系统用gparted新建个分区,格式化成ntfs,用来装win10系统 第二步,制作win10启动盘,这个需要先把u盘用disks格式化&a…...

深入理解渲染引擎:打造逼真图像的关键
在数字世界中,图像渲染是创造逼真视觉效果的核心技术。渲染引擎,作为这一过程中的关键组件,负责将二维或三维的模型、纹理、光照等数据转化为人们肉眼可见的二维图像。本文将深入探讨渲染引擎的工作原理及其在打造逼真图像中所起的关键作用。…...

【LeetCode最详尽解答】128_最长连续序列 Longest-Consecutive-Sequence
欢迎收藏Star我的Machine Learning Blog:https://github.com/purepisces/Wenqing-Machine_Learning_Blog。如果收藏star, 有问题可以随时与我交流, 谢谢大家! 链接: 128_最长连续序列 直觉 输入: nums [100, 4, 200, 1, 3, 2]输出: 4解释: 最长的连续元素序列是…...
盒马鲜生礼品卡如何使用?
盒马鲜生的礼品卡除了在门店用以外,还有什么用处啊 毕竟家附近的盒马距离都太远了,好多卡最后都闲置下来了,而且以前都不知道盒马卡还会过期,浪费了好多 还好最近发现了 盒马鲜生礼品卡现在也能在收卡云上兑现了,而且…...

有哪些常用ORM框架
ORM(Object-Relational Mapping,对象关系映射)是一种编程技术,它允许开发者使用面向对象的编程语言来操作关系型数据库。ORM的主要目的是将数据库中的数据表映射到编程语言中的对象,从而使得开发者可以使用对象的方式来…...

nodejs 中 axios 设置 burp 抓取 http 与 https
在使用 axios 库的时候,希望用 burp 抓包查看发包内容。但关于 axios 设置代理问题,网上提到的一些方法不是好用,摸索了一段时间后总结出设置 burp 代理抓包的方法。 nodejs 中 axios 设置 burp 抓包 根据请求的站点,分为 http …...
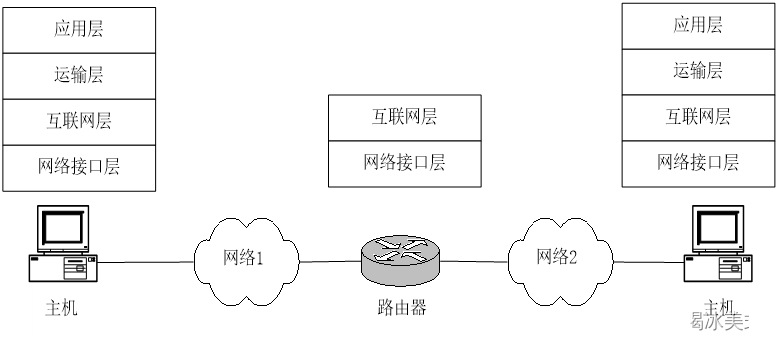
数据通信与网络(二)
如何构建网络协议 这些协议采用分层的结构,每层协议实现特定功能,同时也需要依靠低层协议所提供的服务。 网络协议可以理解为三部分组成: 1、语法:通信时双方交换数据和控制信息的格式,是对通信时采用的数据结构形式…...
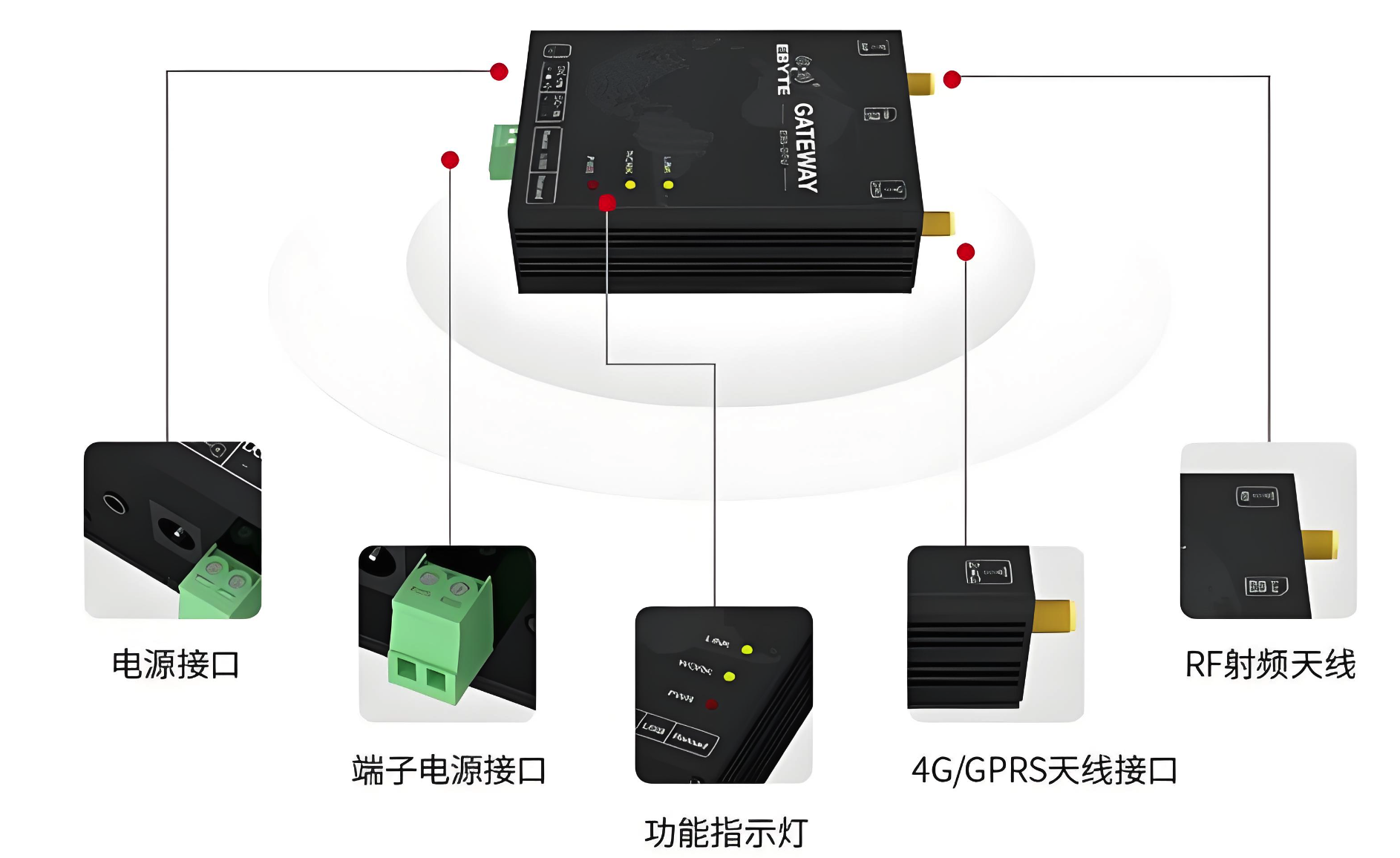
DTU为何应用如此广泛?
1.DTU是什么 DTU(数据传输单元)是一种无线终端设备,它的核心功能是将串口数据转换为IP数据或将IP数据转换为串口数据,并通过无线通信网络进行传送。DTU通常内置GPRS模块,能够实现远程数据的实时传输,广泛应用于工业自动化、远程监…...
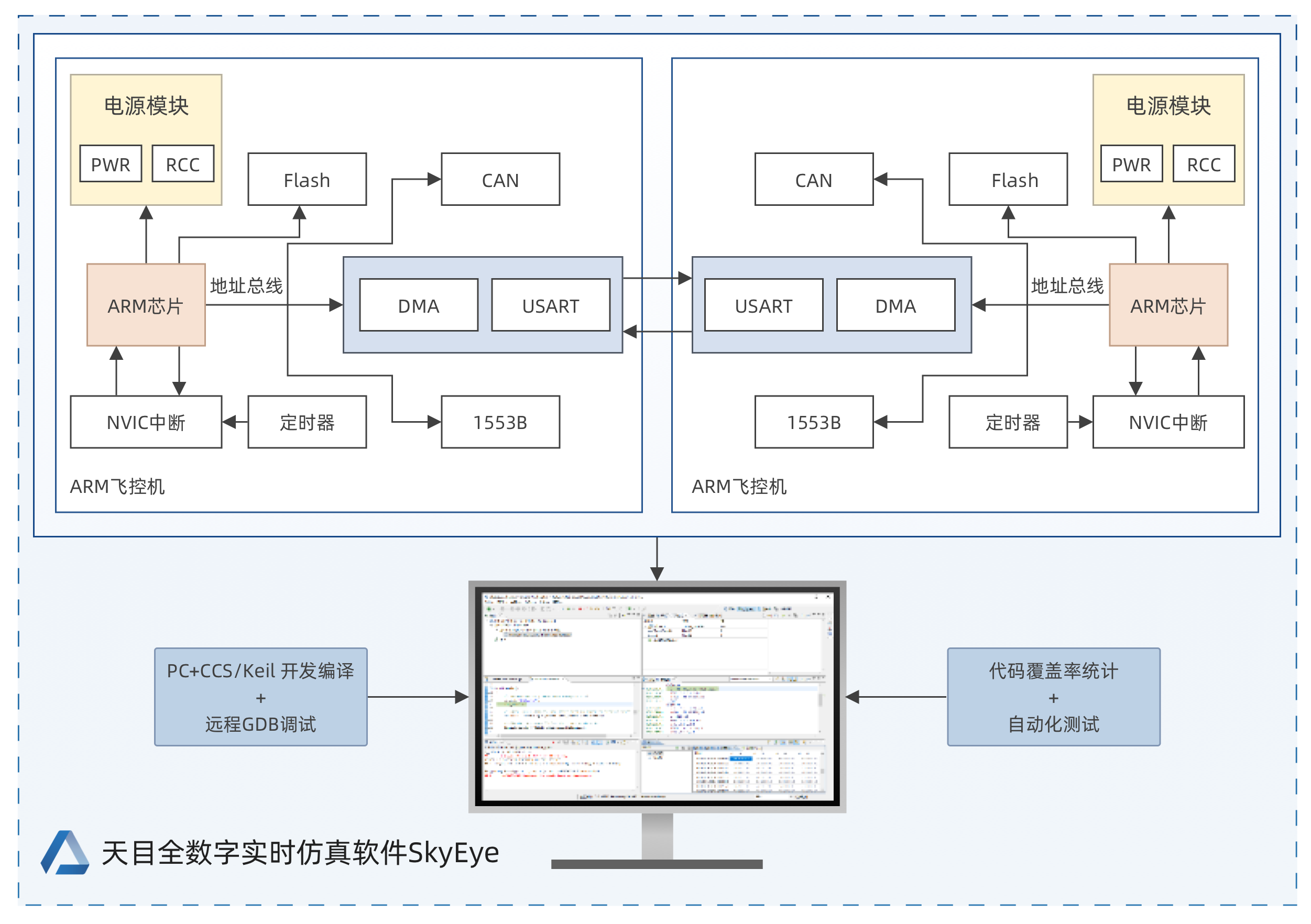
基于软件在环的飞控机建模仿真
安全关键系统(Safety-Critical System,SCS)是指由于某些行为或组合行为能够引发整体系统失效,继而导致财物损失、人员受伤等严重影响的系统,诸多安全关键领域如航空航天、核电系统、医疗设备、交通运输等领域的系统都属…...

github ssh key的SHA256是什么
github ssh key的SHA256是什么 怎么知道github上自己的公钥指纹和本地的公钥是否一致? 计算方法如下: cat .ssh/id_rsa.pub |awk { print $2 } | # Only the actual key data without prefix or commentsbase64 -d | # decode as base64s…...

HyperBDR新版本上线,自动化容灾兼容再升级!
本次HyperBDR v5.5.0版本新增完成HCS(Huawei Cloud Stack)8.3.x和HCSO(Huawei Cloud Stack Online)自动化对接,另外还突破性完成了Oracle云(块存储模式)的自动化对接。 HyperBDR,云原生业务级别容灾工具。支…...

python学习—合并多个Excel工作簿表格文件
系列文章目录 python学习—合并TXT文本文件 python学习—统计嵌套文件夹内的文件数量并建立索引表格 python学习—查找指定目录下的指定类型文件 python学习—年会不能停,游戏抽签抽奖 python学习—循环语句-控制流 文章目录 系列文章目录功能说明1 准备工作&#…...

如何把路由器设备的LAN口地址为三大私网地址
要将路由器的LAN口地址配置为三大私有IP地址范围之一(10.0.0.0/8、172.16.0.0/12 或 192.168.0.0/16),我们需要访问路由器的管理界面并进行相应的设置。 下面是步骤: 连接到路由器: 连接到路由器的管理界面…...

Java多线程-StampedLock(原子读写锁)
StampedLock 是读写锁的实现,对比 ReentrantReadWriteLock 主要不同是该锁不允许重入,多了乐观读的功能,使用上会更加复杂一些,但是具有更好的性能表现。StampedLock 的状态由版本和读写锁持有计数组成。 获取锁方法返回一个邮戳&…...
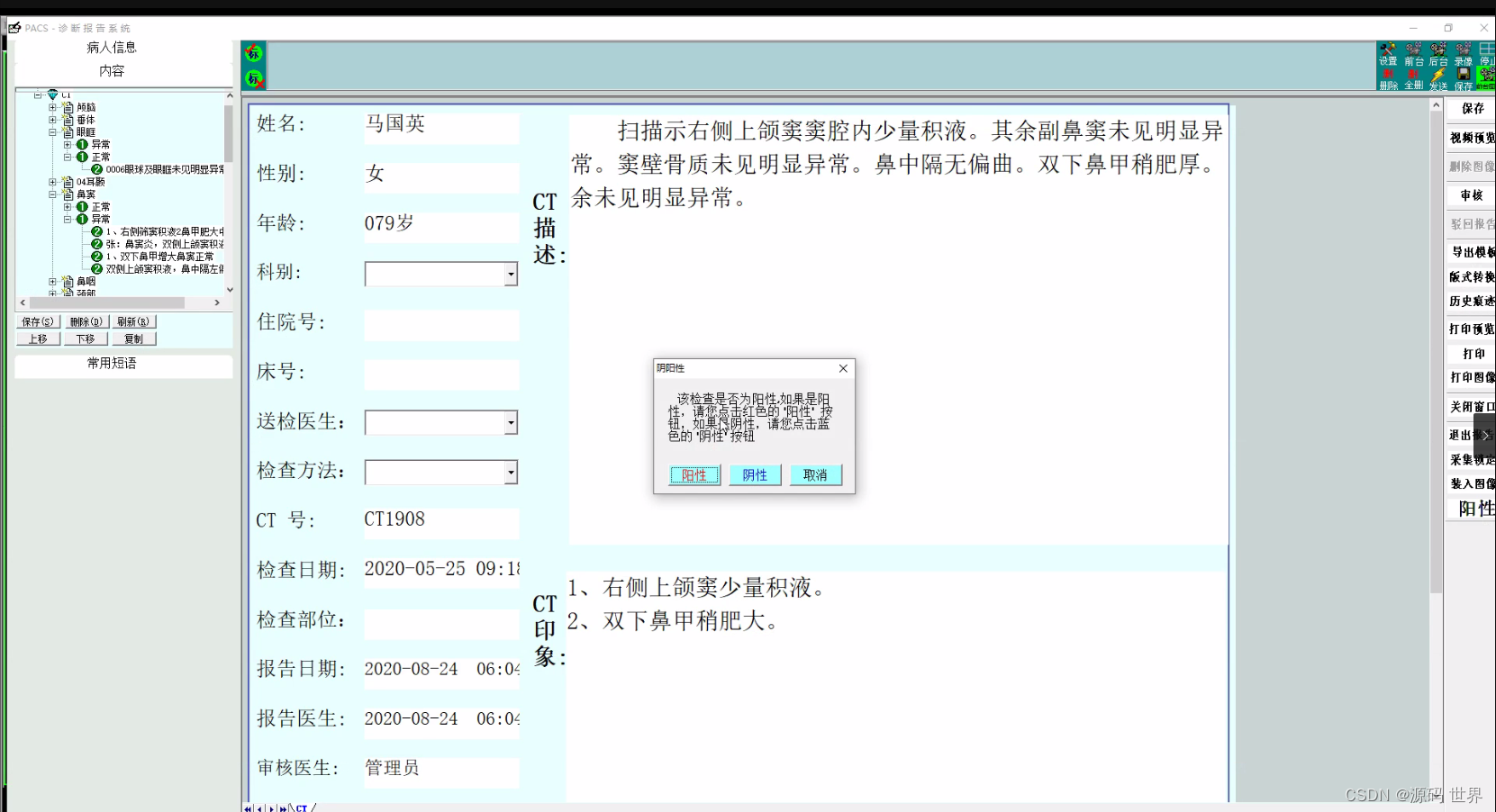
(源码)一套医学影像PACS系统源码 医院系统源码 提供数据接收、图像处理、测量、保存、管理、远程医疗和系统参数设置等功能
PACS系统还提供了数据接收、图像处理、测量、保存、管理、远程医疗和系统参数设置等功能。 PACS系统提高了医学影像的利用率和诊疗效率,为医生提供了更加准确和及时的诊断依据。它是医院信息化的必备系统之一,已经成为医学影像管理和传输的重要工具。 P…...

【Qt 学习笔记】Qt窗口 | 对话框 | 创建自定义对话框
博客主页:Duck Bro 博客主页系列专栏:Qt 专栏关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ Qt窗口 | 对话框 | 创建自定义对话框 文章编号:Qt 学习笔记…...
)
# RocketMQ 实战:模拟电商网站场景综合案例(五)
RocketMQ 实战:模拟电商网站场景综合案例(五) 一、mybatis 逆向工程使用 4、逆向工程 生成 的 .xml 配置文件。 4.1、生成的 TradeCouponMapper.xml 文件。 <?xml version"1.0" encoding"UTF-8" ?> <!DOC…...

3个颠覆性用法:B站字幕提取工具如何改变你的视频创作流程
3个颠覆性用法:B站字幕提取工具如何改变你的视频创作流程 【免费下载链接】BiliBiliCCSubtitle 一个用于下载B站(哔哩哔哩)CC字幕及转换的工具; 项目地址: https://gitcode.com/gh_mirrors/bi/BiliBiliCCSubtitle 你是否曾经为了获取B站视频的字幕而烦恼&…...

QuickBMS技术探索者指南:游戏资源解析与逆向工程实战
QuickBMS技术探索者指南:游戏资源解析与逆向工程实战 【免费下载链接】QuickBMS QuickBMS by aluigi - Github Mirror 项目地址: https://gitcode.com/gh_mirrors/qui/QuickBMS 在数字内容创作与逆向工程领域,文件格式的多样性与加密机制的复杂性…...

AugmentCode无限续杯插件:突破登录限制的自动化解决方案
AugmentCode无限续杯插件:突破登录限制的自动化解决方案 【免费下载链接】free-augment-code AugmentCode 无限续杯浏览器插件 项目地址: https://gitcode.com/gh_mirrors/fr/free-augment-code 痛点解析:开发者的账户管理困境 在软件开发与测试…...
)
从嵌入式到云原生:手把手教你根据项目规模选对MQTT Broker(EMQX vs Mosquitto实战避坑)
从嵌入式到云原生:手把手教你根据项目规模选对MQTT Broker(EMQX vs Mosquitto实战避坑) 当你在设计一个物联网系统时,选择正确的MQTT Broker就像为你的房子选择合适的地基。选得太轻量级,系统可能无法承载未来的增长&…...

给数学恐惧症患者的DDPM前向扩散公式拆解:从‘图像变糊’到一行代码生成任意噪声图
给数学恐惧症患者的DDPM前向扩散公式拆解:从‘图像变糊’到一行代码生成任意噪声图 想象一下,你正在搅拌一杯咖啡。最初,咖啡是纯黑色的,但随着你不断加入牛奶,颜色逐渐变浅,最终变成一杯乳白色的液体。这…...

手把手教你用AI搞定独立游戏美术:从DeepSeek写方案到Unity导入模型的完整流程
手把手教你用AI搞定独立游戏美术:从DeepSeek写方案到Unity导入模型的完整流程 独立游戏开发最令人头疼的环节之一就是美术资源。传统方式要么需要高昂的外包成本,要么耗费大量时间自学建模。但现在,AI工具链已经能帮我们实现从概念设计到3D模…...

从零开始:roLabelImg安装与OBB旋转框标注实战指南
1. 为什么需要roLabelImg和旋转框标注 在计算机视觉项目中,我们经常需要标注图像中的目标物体。对于常规的矩形框标注,LabelImg这类工具已经足够好用。但遇到倾斜物体时,比如遥感图像中的飞机、自然场景中的交通标志、医学图像中的器官&#…...

SketchUp STL插件:5个简单步骤实现3D打印工作流革命
SketchUp STL插件:5个简单步骤实现3D打印工作流革命 【免费下载链接】sketchup-stl A SketchUp Ruby Extension that adds STL (STereoLithography) file format import and export. 项目地址: https://gitcode.com/gh_mirrors/sk/sketchup-stl 你是否曾为Sk…...

LockSupport深度解析:线程阻塞与唤醒的底层实现原理
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

3大创新突破:CoreCycler单核心稳定性测试全攻略
3大创新突破:CoreCycler单核心稳定性测试全攻略 【免费下载链接】corecycler Script to test single core stability, e.g. for PBO & Curve Optimizer on AMD Ryzen or overclocking/undervolting on Intel processors 项目地址: https://gitcode.com/gh_mir…...