python学习—合并多个Excel工作簿表格文件
系列文章目录
python学习—合并TXT文本文件
python学习—统计嵌套文件夹内的文件数量并建立索引表格
python学习—查找指定目录下的指定类型文件
python学习—年会不能停,游戏抽签抽奖
python学习—循环语句-控制流
文章目录
- 系列文章目录
- 功能说明
- 1 准备工作
- ==(知识点)== 关于 Pandas 库
- 2 第一版代码
- (1) 指定目录
- (2) 获取目录下所有.xlsx文件的列表
- (3) 初始化一个空的DataFrame用于存储所有数据
- (4) 遍历所有Excel文件并逐个读取,然后追加到all_data中
- (5) 将合并后的数据写入指定文件中
- (6) 第一版完整代码
- 3 第二版代码
- (1) 遍历工作簿中的sheet表
- (2) 填写工作簿 和 内部 sheet表名称
- (3) 使用绝对路径,增强代码兼容性
- (4) 完整代码
- 4 后记
功能说明
同事有个需求:手里有很多人编辑的Excel工作簿,差不多有20多个,现在想把这些分开的工作簿合并为一整个工作簿,方便数据查询和使用。
我看了一下,这边表格的字段都是相同的,不同的是每行的数据有多有少,笨方法当然可以新建一个空表格,然后再依次打开每个工作簿,将内容复制粘贴到新建表格中,实现合并的效果。
既然是重复性工作,当然是使用python编程了。
本代码目标为:
- 1 将文件夹内的所有表格(包括.xls格式 和 .xlsx格式)合并为一个表格;
- 2 每个工作簿中可能有多个分sheet表;
- 3 合并表格的第一列填写每个工作簿文件名称,第二列填写工作簿内的分表sheet名称。
1 准备工作
首先在D盘根目录下建立文件夹“测试”,在该文件夹内存放多个Excel表格文件,内容随意。
我新建了2个工作簿,”测试表1.xlsx“ 和 “样例表2.xlsx”,工作簿中都有分表,内容如下图:

数据分析需要用到强大的 Pandas 库,创建Excel表格需要用到 openpyxl库,查看自己的电脑是否安装了这2个库,可以在python终端中输入:
pip list
运行后会列出你的python环境中安装的所有库文件。
如果没有安装上述两个库,可以在python终端中使用如下代码进行安装:
pip install pandas openpyxl
我使用的python版本为3.9.0,Pandas版本 1.5.2 ,openpyxl版本 3.1.2.
(知识点) 关于 Pandas 库
——Pandas: Pandas 是一个开源的 Python 数据分析和处理库,提供了大量功能使数据分析工作更加高效便捷。以下是对 Pandas 主要特点和功能的概述:
- 数据结构:Pandas 两大核心数据结构是 Series(一维数组,类似于带标签的数组)和 DataFrame(二维表格型数据结构,每列可以是不同类型的值)。这两种数据结构非常适合于处理和分析表格化的数据。
- 数据读写:Pandas 支持多种文件格式的数据读写操作,如 CSV、Excel、SQL 数据库、JSON、HDF5 等,使得数据导入导出变得简单快捷。
- 数据清洗:提供强大功能用于数据清洗,包括缺失值处理、数据类型转换、数据重塑、行列选择、过滤、排序等,有助于准备数据进行进一步分析。
- 数据操作:支持类似 SQL 的数据操作方法,如合并(merge)、连接(join)、分组(groupby)、聚合(aggregate)、透视表(pivot table)等,便于对数据进行复杂操作。
- 时间序列分析:Pandas 对时间序列数据有很好的支持,可以方便地进行重采样、移位、日期时间格式转换等操作,是金融、经济等领域数据分析的理想工具。
- 统计分析:内置了丰富的统计功能,如计算描述性统计量(均值、中位数、标准差等)、相关性分析、协方差、线性回归等,帮助用户快速理解数据。
- 可视化:虽然 Pandas 本身不直接提供复杂的可视化功能,但它与 Matplotlib、Seaborn 等图形库集成紧密,可以轻松地对数据进行可视化展示。
总的来说,Pandas 是进行数据预处理、数据分析和探索性数据分析的 强大工具,广泛应用于数据科学、金融、统计学、社会科学等多个领域。
2 第一版代码
第一版本的代码,主要实现一个合并的操作,最简单的情况:工作簿中只有1个表格。
(1) 指定目录
directory = 'D:/测试'
(2) 获取目录下所有.xlsx文件的列表
Excel表格有两种后缀名, .xls 和 .xlsx,使用后缀名判定。
excel_files = [file for file in os.listdir(directory) if file.endswith('.xlsx') or file.endswith('.xls')]
(3) 初始化一个空的DataFrame用于存储所有数据
all_data = pd.DataFrame()
(4) 遍历所有Excel文件并逐个读取,然后追加到all_data中
使用pandas读取Excel文件,假设每份Excel只包含一个工作表,并且想要合并所有工作表的数据。
for file in excel_files:file_path = os.path.join(directory, file) data = pd.read_excel(file_path)all_data = pd.concat([all_data, data], ignore_index=True)
知识点: pandas.concat() 方法
该函数使用pd.concat()方法将file_data数据框合并到merged_data数据框中。
ignore_index=True 参数表示合并后重新索引,保持索引的连续性。
ignore_index=False 表示保留原始的索引。
(5) 将合并后的数据写入指定文件中
//指定合并后的工作簿保存路径和名称
output_file = 'D:/测试/all_hebing.xlsx'//将合并后的数据写入新的Excel工作簿
all_data.to_excel(output_file, index=False)
(6) 第一版完整代码
import os
import pandas as pddirectory = 'D:/测试'
excel_files = [file for file in os.listdir(directory) if file.endswith('.xlsx') or file.endswith('.xls')]
all_data = pd.DataFrame()# 遍历所有Excel文件并逐个读取,然后追加到all_data中
for file in excel_files:file_path = os.path.join(directory, file)data = pd.read_excel(file_path)all_data = pd.concat([all_data, data], ignore_index=True)output_file = 'D:/测试/all_hebing.xlsx'
all_data.to_excel(output_file, index=False)print(f'合并完成,结果已保存至:{output_file}')
结果如下图:

可以看到,代码实现了基本的Excel工作表合并功能,sheet4是 "样例表2.xlsx"中的第一个表格,sheet1是”测试表1.xlsx“ 中的第一个表格。
3 第二版代码
在第一版代码的基础上,实现含有多个表格的工作簿合并,合并表格的第一列填写工作簿名称,第二列填写内部sheet名称。
在代码中添加一些数据读写的判定功能,将步骤拆分包装为函数提高运行效率。重点环节代码如下:
(1) 遍历工作簿中的sheet表
遍历工作簿,首先需要获取这个工作簿的名称,然后获取内部的sheet表名称,最后按照两级名称读取表格内容。
// 存储表格内容的空列表
sheets_data = []// 获取工作簿的名称
xls = pd.ExcelFile(file_path)// 获取 工作簿 内的 sheet表的名称,并读取表格内容。
for sheet_name in xls.sheet_names:sheet_data = xls.parse(sheet_name)
这段代码的作用是遍历 Excel文件中的所有工作表,并解析每个工作表的数据。
xls.sheet_names 返回一个包含所有工作表名称的列表。
xls.parse(sheet_name) 根据给定的工作表名称,解析该工作表的数据并返回。
(2) 填写工作簿 和 内部 sheet表名称
excel表格属于二维表格型数据结构,定义列的位置、名称、内容。
sheet_data.insert(0, '文件名称', file_path.name)sheet_data.insert(1, '内部表名称', sheet_name)// 将 insert 的内容,append 添加入 保存表格内容的 列表中。sheets_data.append(sheet_data)
该函数用于在名为sheet_data的表格的第0列,列名为’文件名称’,并将其赋值为file_path.name,即文件路径中的工作簿文件名部分;
表格的第1列,列名为’内部表名称’,并将其赋值为sheet_name,即工作簿文件名部分;
(3) 使用绝对路径,增强代码兼容性
在代码的路径设置中,使用 .resolve() 方法将该路径解析为一个绝对路径.
file_path = Path(file_path).resolve()
具体来说,它首先使用Path(file_path)创建一个Path对象,然后使用 .resolve() 方法将该路径解析为一个绝对路径。如果该路径是一个符号链接,则会解析为符号链接所指向的目标路径。如果路径不存在,则会抛出 FileNotFoundError 异常。
该函数的作用是确保后续操作使用的路径是绝对路径,避免了相对路径带来的问题,如路径解析错误、文件访问错误等。
(4) 完整代码
完整代码如下:
import os
import pandas as pd
from pathlib import Path# 读取Excel文件的所有工作表,并为每个工作表的数据添加文件名及工作表名称作为前两列
def read_excel_sheets(file_path):try:# 使用pathlib的绝对路径确保兼容性file_path = Path(file_path).resolve()xls = pd.ExcelFile(file_path)sheets_data = []for sheet_name in xls.sheet_names:sheet_data = xls.parse(sheet_name)# 添加文件名和工作表名sheet_data.insert(0, '文件名称', file_path.name)sheet_data.insert(1, '内部表名称', sheet_name)sheets_data.append(sheet_data)return pd.concat(sheets_data, ignore_index=True)except FileNotFoundError:print(f"文件 {file_path} 不存在。")return pd.DataFrame()except PermissionError:print(f"没有权限读取文件 {file_path}。")return pd.DataFrame()except Exception as e:print(f"读取文件 {file_path} 时发生未知错误: {e}")return pd.DataFrame()# 合并Excel文件,将每个文件的所有工作表合并为一个DataFrame,并保存到输出文件中。
def merge_excel_files_with_filenames(directory, output_file):directory_path = Path(directory).resolve()if not directory_path.exists() or not os.access(directory_path, os.R_OK):print(f"无法访问目录 {directory_path},请检查权限和路径。")returnexcel_files = list(directory_path.glob('*.xls*'))if not excel_files:print(f"在目录 {directory_path} 中未找到任何 .xls 或 .xlsx 文件。")returnmerged_data = pd.DataFrame()for file_path in excel_files:file_data = read_excel_sheets(file_path)merged_data = pd.concat([merged_data, file_data], ignore_index=True)output_dir = Path(output_file).parent.resolve()if not output_dir.exists() or not os.access(output_dir, os.W_OK):print(f"无法写入输出文件 {output_file} 的目录,请检查权限和路径。")returnmerged_data.to_excel(output_file, index=False)print(f"合并完成,结果已保存至:{output_file}。")# 调用合并函数,使用pathlib.path对象以增强代码的清晰度和跨平台能力
if __name__ == '__main__':path = Path(r'D:\测试').resolve()over_name = 'all_合并总表.xlsx'over_path = Path(os.path.join(path, over_name)).resolve()merge_excel_files_with_filenames(path, over_path)
再次看一下合并后的Excel工作簿,如下图:

4 后记
通过以上代码,可以实现多个Excel工作簿的合并工作,支持中文 。
案例中每个工作簿的结构和字段名称都是一致的,当遇到字段结构不一致的时刻,代码同样可以实现合并功能。
区别在于:
相同字段的内容会存储在相同字段这一列下,而不同的字段名在合并时会增加列数,用于存放不同字段下面的内容,即合并的结果是保留了每个工作簿中的字段名称,保证所有数据的完整性。
合并后的工作表,不存在 “合并单元格”,即源工作簿中的 那些 合并单元格,将被拆分。
相关文章:
python学习—合并多个Excel工作簿表格文件
系列文章目录 python学习—合并TXT文本文件 python学习—统计嵌套文件夹内的文件数量并建立索引表格 python学习—查找指定目录下的指定类型文件 python学习—年会不能停,游戏抽签抽奖 python学习—循环语句-控制流 文章目录 系列文章目录功能说明1 准备工作&#…...

如何把路由器设备的LAN口地址为三大私网地址
要将路由器的LAN口地址配置为三大私有IP地址范围之一(10.0.0.0/8、172.16.0.0/12 或 192.168.0.0/16),我们需要访问路由器的管理界面并进行相应的设置。 下面是步骤: 连接到路由器: 连接到路由器的管理界面…...

Java多线程-StampedLock(原子读写锁)
StampedLock 是读写锁的实现,对比 ReentrantReadWriteLock 主要不同是该锁不允许重入,多了乐观读的功能,使用上会更加复杂一些,但是具有更好的性能表现。StampedLock 的状态由版本和读写锁持有计数组成。 获取锁方法返回一个邮戳&…...
(源码)一套医学影像PACS系统源码 医院系统源码 提供数据接收、图像处理、测量、保存、管理、远程医疗和系统参数设置等功能
PACS系统还提供了数据接收、图像处理、测量、保存、管理、远程医疗和系统参数设置等功能。 PACS系统提高了医学影像的利用率和诊疗效率,为医生提供了更加准确和及时的诊断依据。它是医院信息化的必备系统之一,已经成为医学影像管理和传输的重要工具。 P…...

【Qt 学习笔记】Qt窗口 | 对话框 | 创建自定义对话框
博客主页:Duck Bro 博客主页系列专栏:Qt 专栏关注博主,后期持续更新系列文章如果有错误感谢请大家批评指出,及时修改感谢大家点赞👍收藏⭐评论✍ Qt窗口 | 对话框 | 创建自定义对话框 文章编号:Qt 学习笔记…...
)
# RocketMQ 实战:模拟电商网站场景综合案例(五)
RocketMQ 实战:模拟电商网站场景综合案例(五) 一、mybatis 逆向工程使用 4、逆向工程 生成 的 .xml 配置文件。 4.1、生成的 TradeCouponMapper.xml 文件。 <?xml version"1.0" encoding"UTF-8" ?> <!DOC…...

Cesium4Unreal - # 009 直接加载显示shapefile
文章目录 直接加载显示shapefile1 思路2 步骤2.1 下载shapelib2.2 添加依赖模块2.3 创建Actor2.3.1 MyShapeLoaderActor.h2.3.2 MyShapeLoaderActor.cpp2.3 蓝图代码直接加载显示shapefile 1 思路 在Unreal Engine中加载显示shapefile无非就是从shapefile中读取几何数据,并且…...

Release和Debug的区别?Release有什么好处?【面试】
Release和Debug的区别: 优化:Debug版本通常不进行优化,以便更容易调试;Release版本则经过高度优化,以提高性能。调试信息:Debug版本包含详尽的调试信息,如符号信息和源代码映射;Rel…...
DevExpress 控件和库
UI控件和组件 DevExpress WinForms包括以下Windows窗体库和控件: Grids and Editors Data Grid Tree List Vertical Grid Property Grid Gantt Control Data Editors and Simple Controls Office-inspired Ribbon, Bars and Menu Rich Text Editor Scheduler S…...
车载以太网测试
一、车载以太网的发展 IEEE: 电气与电子工程师协会,其中IEEE802.3工作小组致力于推进以太网相关标准的制定与完善,其发展主要经过一下三个阶段: 1.诊断/程序更新 2.智驾座舱 3.主干网 二、车载以太网协议(OSI七层模型&#x…...

181.二叉树:验证二叉树(力扣)
代码解决 /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(nullptr) {}* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}* Tre…...
陪诊小程序开发,陪诊师在线接单
近几年,陪诊师成为了一个新兴行业,在科技时代中,陪诊小程序作为互联网下的产物,为陪诊市场带来了更多的便利。 当下生活压力大,老龄化逐渐严重,年轻人很难做到陪同家属看病。此外,就诊中出现了…...

【全开源】Java无人共享棋牌室茶室台球室系统JAVA版本支持微信小程序+微信公众号
无人共享棋牌室系统——棋牌娱乐新体验 🎲引言 随着科技的不断发展,传统棋牌室正逐渐迈向智能化、无人化。今天,我要为大家介绍的就是这款引领潮流的“无人共享棋牌室系统”。它不仅为棋牌爱好者提供了全新的娱乐体验,更在便捷性…...

2024-6-10-zero shot,few shot以及无监督学习之间的关系是什么
Zero-shot learning、few-shot learning和无监督学习都是机器学习中的方法,它们共同的特点是在有限或没有标签数据的情况下进行学习。下面是这三种方法之间的关系和区别: Zero-shot Learning (零样本学习): 零样本学习是在模型训练过程中完全…...
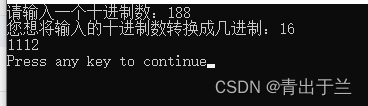
C语言|十进制数转换任意进制数
将十进制数转换成任意进制数。 思路分析: 先举一个具体的例子:十进制转换为二进制数 1 定义一个数组a[100],先归0,再存放运算过程中的余数 2 定义变量m, 先存放键盘上输入的十进制数 3 定义变量R 表示几进制数,循环变量…...
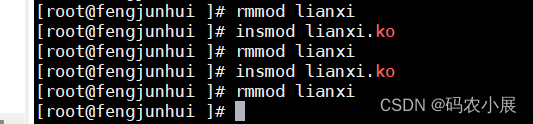
驱动开发(二):创建字符设备驱动
往期文章: 驱动开发(一):驱动代码的基本框架 驱动开发(二):创建字符设备驱动 ←本文 目录 字符驱动设备的作用 函数 字符驱动设备注册和注销 注册 注销 自动创建设备节点 创建class类…...

Golang:使用时会遇到的错误及解决方法详解
Go语言使用时常常会遇到的一些错误及解决方法,文中的示例代码讲解详细,感兴趣的小伙伴可以了解一下 1、go: go.mod file not found in current directory or any parent directory go mod init name 2、Failed to build the application: main.go:4:2:…...
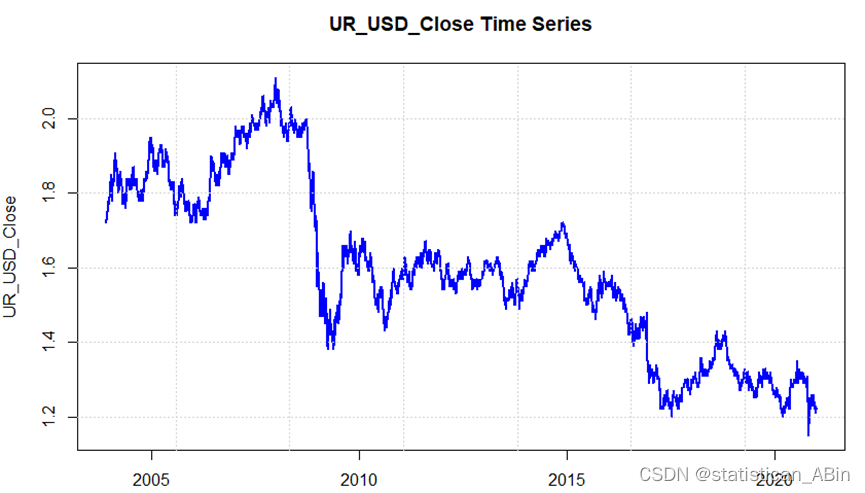
r语言数据分析案例25-基于向量自回归模型的标准普尔 500 指数长期预测与机制分析
一、背景介绍 2007 年的全球经济危机深刻改变了世界经济格局,引发了一系列连锁反应,波及各大洲。经济增长停滞不前,甚至在某些情况下出现负增长,给出口导向型发展中国家带来了不确定性。实体经济受到的冲击尤为严重,生…...
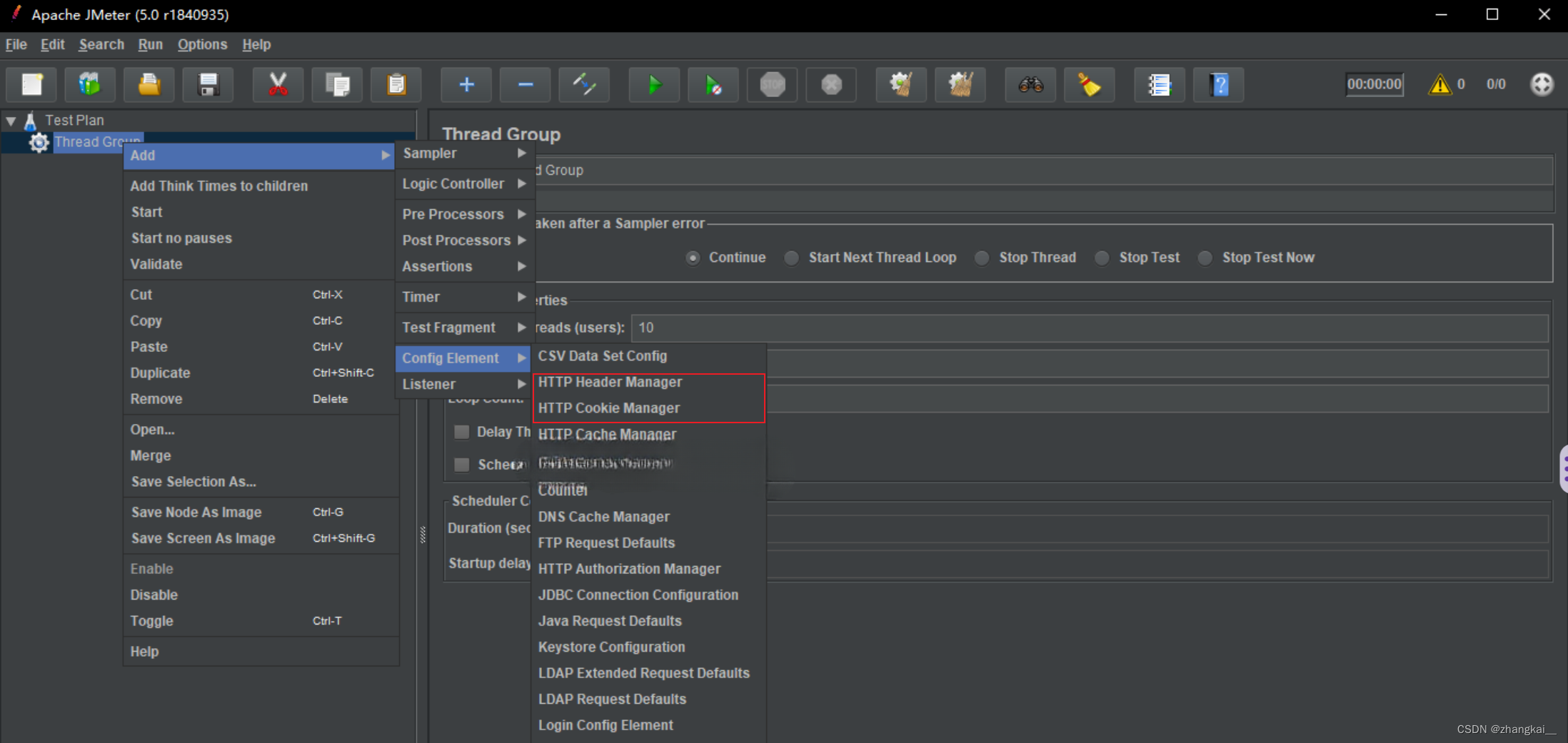
解决使用Jmeter进行测试时出现“302“,‘‘401“等用户未登录的问题
使用 JMeter 压力测试时解决登录问题的两种方法 在使用 JMeter 进行压力测试时,可能会遇程序存在安全验证,必须登录后才能对里面的具体方法进行测试: 如果遇到登录问题,通常是因为 JMeter 无法模拟用户的登录状态,导…...

MySql通过 Procedure 循环删除数据
一、问题描述 在日常使用运维中,一些特殊情况需要批量删除陈旧或异常数据。 如果通过 delete from 【表名】 where 【条件】 直接删除,可能会由于数据量过大,事务执行时间过长,造成死锁。 二、解决方案 通过 Procedure 使用循环…...

华为HMS Scan Kit Customized View Mode:打造品牌专属扫码界面的实战指南
1. 为什么选择Customized View Mode? 扫码功能已经成为现代App的标配,但很多开发者面临一个两难选择:要么用系统默认的扫码界面显得千篇一律,要么完全自己开发一套又耗时耗力。华为HMS Scan Kit的Customized View Mode正好解决了这…...

PyTorch 2.8深度学习镜像入门必看:RTX 4090D环境验证与快速上手步骤
PyTorch 2.8深度学习镜像入门必看:RTX 4090D环境验证与快速上手步骤 1. 镜像概述与核心优势 PyTorch 2.8深度学习镜像专为RTX 4090D显卡优化设计,提供开箱即用的深度学习开发环境。这个镜像最显著的特点是免去了复杂的环境配置过程,让开发者…...

07-打造个性化 AI 助手
OpenClaw 第七篇:记忆系统进阶——打造个性化 AI 助手 “Memory is the treasury and guardian of all things.” — Cicero 在人工智能领域,有一个永恒的挑战:如何让 AI 记住「我是谁」、「你是谁」,以及「我们之前聊过什么」。OpenClaw 作为新一代 AI 自动化平台,构建了…...
)
超导电路阵列实验方案 V1.0桌面量子引力实验(自指动力学与类时空关联涌现)
超导电路阵列实验方案 V1.0 桌面量子引力实验(自指动力学与类时空关联涌现) 方案编号:SR-EXP-QG-001 版本:V1.0 一、核心科学目标 1. 科学目标 在一维/二维超导量子比特阵列中,引入全局量子态测量 实时反馈构建强自指…...

QT图形界面开发集成Phi-4-mini-reasoning:打造智能桌面应用
QT图形界面开发集成Phi-4-mini-reasoning:打造智能桌面应用 1. 智能桌面应用的新可能 传统桌面应用开发正在经历一场智能化变革。想象一下,你的QT应用不仅能响应用户操作,还能理解用户意图、自动生成内容、提供智能建议——这就是集成Phi-4…...

OpenCore技术方案:老旧设备系统兼容性深度解析与性能优化评估
OpenCore技术方案:老旧设备系统兼容性深度解析与性能优化评估 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 1. 问题剖析:为何老旧Ma…...

如何轻松备份微信聊天记录:WeChatMsg完整指南让数据掌控权回归你手
如何轻松备份微信聊天记录:WeChatMsg完整指南让数据掌控权回归你手 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trend…...

终极Redis可视化工具:Another Redis Desktop Manager完全使用指南
终极Redis可视化工具:Another Redis Desktop Manager完全使用指南 【免费下载链接】AnotherRedisDesktopManager 🚀🚀🚀A faster, better and more stable Redis desktop manager [GUI client], compatible with Linux, Windows, …...

数据库索引原理:B+树与哈希索引的深度对决
数据库索引原理:B树与哈希索引的深度对决在数据库的世界里,索引是提升查询性能的“核武器”。如果把数据库表比作一本厚厚的书,那么索引就是书中的目录。没有目录,想要找到特定的知识点只能一页页翻找(全表扫描&#x…...

周末高质量遛娃,你真的找对地方了吗?
“周末想高质量遛娃,却不知找对地方了没?” 周末对于家长来说,是陪伴孩子的黄金时间,都希望能给孩子一段既有趣又有意义的时光。但究竟哪里才是高质量遛娃的好去处呢?下面就为您详细解答。遛娃地点基础认知类Q…...