全面解析AdaBoost:多分类、逻辑回归与混合分类器的实现
1. 使用 AdaBoost 完成多分类和逻辑回归问题
多分类
AdaBoost 原本是为二分类问题设计的,但可以扩展到多分类问题。常用的方法包括 One-vs-All (OVA), AdaBoost.MH (Multiclass, Multi-Label) 和 AdaBoost.MR (Multiclass Ranking)。下面对每种方法进行详细介绍。
One-vs-All (OVA)
数学原理:
-
训练过程:
- 对于每个类别 k k k ,训练一个二分类器 G k G_k Gk ,将该类别视为正类,其他类别视为负类。
- 使用二分类 AdaBoost 方法训练每个 G k G_k Gk,并获得分类器的权重 α m \alpha_m αm 。
-
预测过程:
- 对于新样本 x x x ,通过所有分类器 G k G_k Gk 进行预测,选择得分最高的分类器 G k G_k Gk 的类别作为最终预测结果:
y ^ = arg max k G k ( x ) \hat{y} = \arg\max_k G_k(x) y^=argkmaxGk(x)
- 对于新样本 x x x ,通过所有分类器 G k G_k Gk 进行预测,选择得分最高的分类器 G k G_k Gk 的类别作为最终预测结果:
通俗解释:
对于每个类别,训练一个分类器来区分该类别和其他类别。最后,通过比较所有分类器的预测得分,选择得分最高的类别作为最终分类结果。
AdaBoost.MH (Multiclass, Multi-Label)
数学原理:
-
初始化权重:
- 对于每个样本 i i i 和每个类别 k k k ,初始化权重 w ˉ i , k = 1 \bar{w}_{i,k} = 1 wˉi,k=1 。
-
迭代过程:
- 对于每一轮 m m m ,针对每个类别 k k k 和每个样本 i i i,定义权重:
w ˉ i , k = exp [ − y i , k f m − 1 ( x i , k ) ] \bar{w}_{i,k} = \exp\left[-y_{i,k} f_{m-1}(x_i, k)\right] wˉi,k=exp[−yi,kfm−1(xi,k)] - 更新分类器 G m G_m Gm 使得加权误差最小:
G m = arg min G ∑ i = 1 N ∑ k = 1 K w ˉ i , k I ( y i , k ≠ G ( x i , k ) ) G_m = \arg\min_G \sum_{i=1}^{N} \sum_{k=1}^{K} \bar{w}_{i,k} I(y_{i,k} \ne G(x_i, k)) Gm=argGmini=1∑Nk=1∑Kwˉi,kI(yi,k=G(xi,k)) - 计算误差率 ϵ m \epsilon_m ϵm 和分类器权重 α m \alpha_m αm ,更新样本权重,归一化权重,类似二分类 AdaBoost。
- 对于每一轮 m m m ,针对每个类别 k k k 和每个样本 i i i,定义权重:
-
最终分类器:
- 最终分类器 F ( x ) F(x) F(x) 是所有弱分类器的加权和:
F ( x ) = ∑ m = 1 M α m G m ( x ) F(x) = \sum_{m=1}^{M} \alpha_m G_m(x) F(x)=m=1∑MαmGm(x)
- 最终分类器 F ( x ) F(x) F(x) 是所有弱分类器的加权和:
通俗解释:
将多分类问题视为多个二分类问题,并通过调整样本权重来增强分类效果。每个类别都有独立的权重,最终通过加权求和得到最终分类结果。
AdaBoost.MR (Multiclass Ranking)
数学原理:
-
初始化权重:
- 对于每个样本 i i i 和每个类别 k k k ,初始化权重 w ˉ i , k = 1 \bar{w}_{i,k} = 1 wˉi,k=1 。
-
迭代过程:
- 在每轮迭代中,更新分类器 G m G_m Gm 使得加权误差最小,并基于对样本排序的思想选择最佳分类器:
G m = arg min G ∑ i = 1 N ∑ k = 1 K w ˉ i , k I ( y i , k ≠ G ( x i , k ) ) G_m = \arg\min_G \sum_{i=1}^{N} \sum_{k=1}^{K} \bar{w}_{i,k} I(y_{i,k} \ne G(x_i, k)) Gm=argGmini=1∑Nk=1∑Kwˉi,kI(yi,k=G(xi,k)) - 计算误差率 ϵ m \epsilon_m ϵm 和分类器权重 α m \alpha_m αm ,更新样本权重,归一化权重,类似二分类 AdaBoost。
- 在每轮迭代中,更新分类器 G m G_m Gm 使得加权误差最小,并基于对样本排序的思想选择最佳分类器:
-
最终分类器:
- 最终分类器 F ( x ) F(x) F(x) 是所有弱分类器的加权和:
F ( x ) = ∑ m = 1 M α m G m ( x ) F(x) = \sum_{m=1}^{M} \alpha_m G_m(x) F(x)=m=1∑MαmGm(x)
- 最终分类器 F ( x ) F(x) F(x) 是所有弱分类器的加权和:
通俗解释:
基于对样本的排序,将多个分类器的输出进行排序,选择得分最高的类别作为最终预测结果。
逻辑回归
将 AdaBoost 与逻辑回归结合,可以通过每轮迭代增加一个逻辑回归分类器来增强模型的能力。
数学原理:
- 初始化: 给定训练数据 ( x i , y i ) (x_i, y_i) (xi,yi),初始权重 w i = 1 N w_i = \frac{1}{N} wi=N1。
- 迭代过程:
- 对于每一轮 m m m ,训练逻辑回归模型 G m G_m Gm:
G m ( x ) = 1 1 + exp ( − β m h m ( x ) ) G_m(x) = \frac{1}{1 + \exp(-\beta_m h_m(x))} Gm(x)=1+exp(−βmhm(x))1 - 更新权重:
w ˉ i = w i exp [ − y i G m ( x i ) ] \bar{w}_{i} = w_i \exp\left[-y_i G_m(x_i)\right] wˉi=wiexp[−yiGm(xi)] - 归一化权重:
w i = w ˉ i ∑ j = 1 N w ˉ j w_i = \frac{\bar{w}_i}{\sum_{j=1}^{N} \bar{w}_j} wi=∑j=1Nwˉjwˉi
- 对于每一轮 m m m ,训练逻辑回归模型 G m G_m Gm:
通俗解释:
逻辑回归是一种用来预测二分类问题的模型。将逻辑回归与 AdaBoost 结合,可以通过逐步增加多个逻辑回归模型来提高整体的预测性能。在每轮迭代中,增加一个新的逻辑回归模型,并根据上一个模型的预测结果调整样本的权重,使得模型更关注那些被错误分类的样本。
2. 训练中选择不同的分类器
AdaBoost 是一种增强学习算法,通过组合多个弱分类器来提高分类性能。这里我们详细描述如何在 AdaBoost 中应用决策树桩、朴素贝叶斯和支持向量机(SVM)作为基础分类器,并解释其数学原理和实现方法。
1. 决策树桩
数学原理:
决策树桩是非常简单的决策树,通常只包含一个决策节点和两个叶节点。它是 AdaBoost 中常用的基础分类器。
步骤:
-
初始化权重:
- 初始化每个样本的权重为 w i = 1 N w_i = \frac{1}{N} wi=N1,其中 N N N 是样本数。
-
迭代过程:
- 对于每一轮 m m m,训练一个新的决策树桩 G m G_m Gm:
G m ( x ) = arg min G ∑ i = 1 N w i I ( y i ≠ G ( x i ) ) G_m(x) = \arg\min_{G} \sum_{i=1}^{N} w_i I(y_i \ne G(x_i)) Gm(x)=argGmini=1∑NwiI(yi=G(xi)) - 计算误差率 ϵ m \epsilon_m ϵm:
ϵ m = ∑ i = 1 N w i I ( y i ≠ G m ( x i ) ) \epsilon_m = \sum_{i=1}^{N} w_i I(y_i \ne G_m(x_i)) ϵm=i=1∑NwiI(yi=Gm(xi)) - 计算分类器的权重 α m \alpha_m αm:
α m = 1 2 ln ( 1 − ϵ m ϵ m ) \alpha_m = \frac{1}{2} \ln\left(\frac{1 - \epsilon_m}{\epsilon_m}\right) αm=21ln(ϵm1−ϵm) - 更新样本权重:
w i ← w i exp ( − α m y i G m ( x i ) ) w_i \leftarrow w_i \exp\left(-\alpha_m y_i G_m(x_i)\right) wi←wiexp(−αmyiGm(xi)) - 归一化权重:
w i ← w i ∑ j = 1 N w j w_i \leftarrow \frac{w_i}{\sum_{j=1}^{N} w_j} wi←∑j=1Nwjwi
- 对于每一轮 m m m,训练一个新的决策树桩 G m G_m Gm:
-
最终分类器:
- 最终分类器 F ( x ) F(x) F(x) 是所有弱分类器的加权和:
F ( x ) = ∑ m = 1 M α m G m ( x ) F(x) = \sum_{m=1}^{M} \alpha_m G_m(x) F(x)=m=1∑MαmGm(x)
- 最终分类器 F ( x ) F(x) F(x) 是所有弱分类器的加权和:
通俗解释:
在每一轮迭代中,选择一个简单的决策树桩作为弱分类器,然后根据该分类器的表现来调整样本的权重,使得分类错误的样本权重增加。在下一轮迭代中,新的分类器将更关注这些错误分类的样本。最终,将所有弱分类器的结果加权求和得到最终分类结果。
2. 朴素贝叶斯
数学原理:
朴素贝叶斯假设特征之间相互独立,使用贝叶斯定理计算类别的后验概率。
步骤:
-
初始化权重:
- 初始化每个样本的权重为 w i = 1 N w_i = \frac{1}{N} wi=N1,其中 N N N 是样本数。
-
迭代过程:
- 对于每一轮 m m m,训练一个新的朴素贝叶斯分类器 G m G_m Gm:
G m ( x ) = arg max y P ( y ∣ x ) = arg max y P ( x ∣ y ) P ( y ) P ( x ) G_m(x) = \arg\max_{y} P(y | x) = \arg\max_{y} \frac{P(x | y) P(y)}{P(x)} Gm(x)=argymaxP(y∣x)=argymaxP(x)P(x∣y)P(y) - 计算误差率 ϵ m \epsilon_m ϵm 和分类器权重 α m \alpha_m αm,更新样本权重,归一化权重,类似决策树桩。
- 对于每一轮 m m m,训练一个新的朴素贝叶斯分类器 G m G_m Gm:
-
最终分类器:
- 最终分类器 F ( x ) F(x) F(x) 是所有弱分类器的加权和:
F ( x ) = ∑ m = 1 M α m G m ( x ) F(x) = \sum_{m=1}^{M} \alpha_m G_m(x) F(x)=m=1∑MαmGm(x)
- 最终分类器 F ( x ) F(x) F(x) 是所有弱分类器的加权和:
通俗解释:
朴素贝叶斯假设所有特征独立,并根据训练数据计算每个类别的概率。在每一轮迭代中,使用新的朴素贝叶斯分类器进行分类,并调整样本权重,使得错误分类的样本在下一轮中更加重要。最终将所有分类器的结果加权求和得到最终分类结果。
3. 支持向量机 (SVM)
数学原理:
SVM 通过找到一个超平面来最大化类间间隔,从而实现分类。
步骤:
-
初始化权重:
- 初始化每个样本的权重为 w i = 1 N w_i = \frac{1}{N} wi=N1,其中 N N N 是样本数。
-
迭代过程:
- 对于每一轮 m m m,训练一个新的 SVM 分类器 G m G_m Gm,目标是最大化类间间隔:
min w 1 2 ∥ w ∥ 2 subject to y i ( w ⋅ x i + b ) ≥ 1 \min_w \frac{1}{2} \|w\|^2 \quad \text{subject to} \quad y_i (w \cdot x_i + b) \ge 1 wmin21∥w∥2subject toyi(w⋅xi+b)≥1 - 使用样本权重 w i w_i wi 进行加权训练,使得 SVM 更关注权重较大的样本。
- 计算误差率 ϵ m \epsilon_m ϵm 和分类器权重 α m \alpha_m αm,更新样本权重,归一化权重,类似决策树桩。
- 对于每一轮 m m m,训练一个新的 SVM 分类器 G m G_m Gm,目标是最大化类间间隔:
-
最终分类器:
- 最终分类器 F ( x ) F(x) F(x) 是所有弱分类器的加权和:
F ( x ) = ∑ m = 1 M α m G m ( x ) F(x) = \sum_{m=1}^{M} \alpha_m G_m(x) F(x)=m=1∑MαmGm(x)
- 最终分类器 F ( x ) F(x) F(x) 是所有弱分类器的加权和:
通俗解释:
SVM 寻找一个能够最大化类间间隔的超平面来进行分类。在每一轮迭代中,使用加权的样本训练新的 SVM 分类器,使得错误分类的样本在下一轮中更加重要。最终将所有分类器的结果加权求和得到最终分类结果。
结论
在 AdaBoost 中,可以选择不同的基础分类器,如决策树桩、朴素贝叶斯和 SVM。每种分类器有其独特的训练方式和优势。通过逐轮训练新的基础分类器,并根据误分类调整样本权重,AdaBoost 能够逐步增强分类性能,最终得到一个强分类器。
好的,让我们更深入地探讨在同一个训练中使用不同分类器的过程,并结合具体实例进行详细分析。
3. 在同一个训练中使用不同的分类器
在 AdaBoost 中使用不同类型的分类器,称为 混合增强学习(Hybrid Boosting) 。这种方法在某些情况下可以提高分类性能。
应用场景和必要性
-
复杂数据集:
- 对于复杂的数据集,不同的分类器可能在不同的数据子集上表现优异。混合使用不同的分类器可以综合利用各分类器的优势。
-
提高泛化能力:
- 混合分类器可以减少单一分类器的偏差和方差,从而提高模型的泛化能力。
-
适应性:
- 不同的分类器可能对不同的特征类型更敏感。通过混合分类器,可以更好地捕捉数据的不同特征。
数学原理和实现
以一个具体实例进行详细分析,假设我们要分类一个包含三类的复杂数据集,其中特征类型多样。
初始化权重
- 初始化权重:
- 对于每个样本 i i i ,初始化权重 w i = 1 N w_i = \frac{1}{N} wi=N1 ,其中 N N N 是样本总数。
迭代过程
假设我们有三个基础分类器:决策树桩(Tree Stump),朴素贝叶斯(Naive Bayes),支持向量机(SVM)。在每轮迭代中,我们选择不同的分类器来训练模型。
-
第一轮:决策树桩
- 训练决策树桩 G 1 G_1 G1 ,计算误差率 ϵ 1 \epsilon_1 ϵ1:
ϵ 1 = ∑ i = 1 N w i I ( y i ≠ G 1 ( x i ) ) \epsilon_1 = \sum_{i=1}^{N} w_i I(y_i \ne G_1(x_i)) ϵ1=i=1∑NwiI(yi=G1(xi)) - 计算分类器权重 α 1 \alpha_1 α1:
α 1 = 1 2 ln ( 1 − ϵ 1 ϵ 1 ) \alpha_1 = \frac{1}{2} \ln\left(\frac{1 - \epsilon_1}{\epsilon_1}\right) α1=21ln(ϵ11−ϵ1) - 更新样本权重:
w i ← w i exp ( − α 1 y i G 1 ( x i ) ) w_i \leftarrow w_i \exp\left(-\alpha_1 y_i G_1(x_i)\right) wi←wiexp(−α1yiG1(xi)) - 归一化权重:
w i ← w i ∑ j = 1 N w j w_i \leftarrow \frac{w_i}{\sum_{j=1}^{N} w_j} wi←∑j=1Nwjwi
- 训练决策树桩 G 1 G_1 G1 ,计算误差率 ϵ 1 \epsilon_1 ϵ1:
-
第二轮:朴素贝叶斯
- 使用更新后的样本权重,训练朴素贝叶斯分类器 G 2 G_2 G2,计算误差率 ϵ 2 \epsilon_2 ϵ2 :
ϵ 2 = ∑ i = 1 N w i I ( y i ≠ G 2 ( x i ) ) \epsilon_2 = \sum_{i=1}^{N} w_i I(y_i \ne G_2(x_i)) ϵ2=i=1∑NwiI(yi=G2(xi)) - 计算分类器权重 α 2 \alpha_2 α2:
α 2 = 1 2 ln ( 1 − ϵ 2 ϵ 2 ) \alpha_2 = \frac{1}{2} \ln\left(\frac{1 - \epsilon_2}{\epsilon_2}\right) α2=21ln(ϵ21−ϵ2) - 更新样本权重:
w i ← w i exp ( − α 2 y i G 2 ( x i ) ) w_i \leftarrow w_i \exp\left(-\alpha_2 y_i G_2(x_i)\right) wi←wiexp(−α2yiG2(xi)) - 归一化权重:
w i ← w i ∑ j = 1 N w j w_i \leftarrow \frac{w_i}{\sum_{j=1}^{N} w_j} wi←∑j=1Nwjwi
- 使用更新后的样本权重,训练朴素贝叶斯分类器 G 2 G_2 G2,计算误差率 ϵ 2 \epsilon_2 ϵ2 :
-
第三轮:支持向量机
- 使用更新后的样本权重,训练支持向量机 G 3 G_3 G3 ,计算误差率 ϵ 3 \epsilon_3 ϵ3 :
ϵ 3 = ∑ i = 1 N w i I ( y i ≠ G 3 ( x i ) ) \epsilon_3 = \sum_{i=1}^{N} w_i I(y_i \ne G_3(x_i)) ϵ3=i=1∑NwiI(yi=G3(xi)) - 计算分类器权重 α 3 \alpha_3 α3 :
α 3 = 1 2 ln ( 1 − ϵ 3 ϵ 3 ) \alpha_3 = \frac{1}{2} \ln\left(\frac{1 - \epsilon_3}{\epsilon_3}\right) α3=21ln(ϵ31−ϵ3) - 更新样本权重:
w i ← w i exp ( − α 3 y i G 3 ( x i ) ) w_i \leftarrow w_i \exp\left(-\alpha_3 y_i G_3(x_i)\right) wi←wiexp(−α3yiG3(xi)) - 归一化权重:
w i ← w i ∑ j = 1 N w j w_i \leftarrow \frac{w_i}{\sum_{j=1}^{N} w_j} wi←∑j=1Nwjwi
- 使用更新后的样本权重,训练支持向量机 G 3 G_3 G3 ,计算误差率 ϵ 3 \epsilon_3 ϵ3 :
最终分类器
最终分类器 F ( x ) F(x) F(x) 是所有弱分类器的加权和:
F ( x ) = ∑ m = 1 M α m G m ( x ) F(x) = \sum_{m=1}^{M} \alpha_m G_m(x) F(x)=m=1∑MαmGm(x)
示例分析
假设我们有一个包含 10 个样本的数据集(简化为演示),每个样本具有两个特征,目标是将这些样本分类为三类(1, 2, 3)。
初始化权重
初始化所有样本的权重 w i = 1 10 = 0.1 w_i = \frac{1}{10} = 0.1 wi=101=0.1 。
第一轮迭代:决策树桩
- 训练一个简单的决策树桩,得到分类器 G 1 G_1 G1。
- 计算分类误差率 ϵ 1 \epsilon_1 ϵ1,假设 ϵ 1 = 0.3 \epsilon_1 = 0.3 ϵ1=0.3 。
- 计算分类器权重 α 1 \alpha_1 α1:
α 1 = 1 2 ln ( 1 − 0.3 0.3 ) ≈ 0.4236 \alpha_1 = \frac{1}{2} \ln\left(\frac{1 - 0.3}{0.3}\right) \approx 0.4236 α1=21ln(0.31−0.3)≈0.4236 - 更新样本权重 w i w_i wi 并归一化。
第二轮迭代:朴素贝叶斯
- 使用更新后的样本权重,训练朴素贝叶斯分类器 G 2 G_2 G2。
- 计算分类误差率 ϵ 2 \epsilon_2 ϵ2,假设 ϵ 2 = 0.25 \epsilon_2 = 0.25 ϵ2=0.25 。
- 计算分类器权重 α 2 \alpha_2 α2 :
α 2 = 1 2 ln ( 1 − 0.25 0.25 ) ≈ 0.5493 \alpha_2 = \frac{1}{2} \ln\left(\frac{1 - 0.25}{0.25}\right) \approx 0.5493 α2=21ln(0.251−0.25)≈0.5493 - 更新样本权重 w i w_i wi 并归一化。
第三轮迭代:支持向量机
- 使用更新后的样本权重,训练支持向量机 G 3 G_3 G3。
- 计算分类误差率 ϵ 3 \epsilon_3 ϵ3,假设 ϵ 3 = 0.2 \epsilon_3 = 0.2 ϵ3=0.2 。
- 计算分类器权重 α 3 \alpha_3 α3:
α 3 = 1 2 ln ( 1 − 0.2 0.2 ) ≈ 0.6931 \alpha_3 = \frac{1}{2} \ln\left(\frac{1 - 0.2}{0.2}\right) \approx 0.6931 α3=21ln(0.21−0.2)≈0.6931 - 更新样本权重 w i w_i wi 并归一化。
最终分类器
最终分类器 F ( x ) F(x) F(x) 是所有弱分类器的加权和:
F ( x ) = 0.4236 G 1 ( x ) + 0.5493 G 2 ( x ) + 0.6931 G 3 ( x ) F(x) = 0.4236 G_1(x) + 0.5493 G_2(x) + 0.6931 G_3(x) F(x)=0.4236G1(x)+0.5493G2(x)+0.6931G3(x)
通过这种方法,我们可以综合利用不同分类器的优势,提升模型的整体性能。在每轮迭代中,选择最适合当前数据的分类器,通过加权方式得到更准确的最终分类结果。
通俗解释
在每一轮迭代中,选择一个不同的分类器来训练模型。每个分类器在其擅长的数据子集上表现良好。根据每个分类器的表现,调整样本权重,使得分类错误的样本在下一轮中更加重要。最终,将所有分类器的结果加权求和得到最终分类结果。通过混合使用不同的分类器,可以充分利用各分类器的优势,提升整体模型的性能。
结论
通过使用混合增强学习,我们可以在同一个训练中使用不同的分类器(如决策树桩、朴素贝叶斯、SVM 等),提高模型的分类性能。通过具体实例分析,我们可以看到在每一轮迭代中,选择不同的分类器并调整样本权重,从而优化最终模型。这种方法在复杂数据集和不同特征类型的情况下特别有效。
相关文章:

全面解析AdaBoost:多分类、逻辑回归与混合分类器的实现
1. 使用 AdaBoost 完成多分类和逻辑回归问题 多分类 AdaBoost 原本是为二分类问题设计的,但可以扩展到多分类问题。常用的方法包括 One-vs-All (OVA), AdaBoost.MH (Multiclass, Multi-Label) 和 AdaBoost.MR (Multiclass Ranking)。下面对每种方法进行详细介绍。…...
:导语)
UE5实战篇二(对话系统1):导语
实现一款商业游戏中使用的对话系统插件。 虚幻商店链接: https://www.unrealengine.com/marketplace/zh-CN/product/0b84eaa9343543f58138bc4956a2fa8f 1. 内容可配置 2. 多分支对话、旁白对话、对话序列动画、文字显示及各种特效 3. 可配置文字、音效、呈现位…...

无人机的发展
朋友们,你们知道吗?无人机的发展之路可谓是科技界的一股清流,风头正劲啊!从最初简单的遥控飞机到现在各种智能功能的加持,无人机真是越来越神奇了! 首先,无人机在航拍领域大放异彩!无…...

MySQL和MariaDB的对比和选型
目录 1 基本介绍 2 功能对比 3 性能对比 4 兼容性 5 社区支持和发展 6 安全性 7 选择建议 8 结论 除去功能本身的对比,相应各位看官不一定能看出太大所以然,而且对于大部分同学来说,使用起来感觉应该差不多。 所以综合来说࿰…...

Android11 后台启动Activity
在 Android 10 (API 29) 及更高版本(包括 Android 11),系统对后台启动 Activity 施加了严格的限制。默认情况下,应用程序在后台无法启动 Activity,以提高用户体验并减少不必要的干扰。以下为解决方法。 From 7d554af386150edec1cd68f6eaf700538af4e373 Mon Sep 17 00:00:0…...
这4款国产软件,因为太良心好用,甚至被误认为是外国人开发的
说起国产软件,大家总是容易给它们打上“流氓、要钱、广告满天飞”的标签,其实,有些小众的软件超级好用,功能强大又不耍流氓,真心不该被一棍子打死。 1、sunlight studio Sunlight Studio是一个开源、免费、无广告的硬…...

【C++进阶学习】第一弹——继承(上)——探索代码复用的乐趣
前言: 在前面,我们已经将C的初阶部分全部讲完了,包括类与对象、STL、栈和队列等众多内容,今天我们就进入C进阶部分的学习,今天先来学习第一弹——继承 目录 一、什么是继承?为什么会有继承? 二…...

OpenCV单词轮廓检测
OpenCV单词轮廓检测 0. 前言1. 策略分析2. 检测字符轮廓3. 检测单词轮廓相关链接 0. 前言 在根据文档图像执行单词转录时,通常第一步是识别图像中单词的位置。我们可以使用两种不同的方法识别图像中的单词: 使用 CRAFT、EAST 等深度学习技术使用基于 O…...

主流后端开发语言对比
软件开发领域,语言本身在各自领域都有适用场景,有许多流行的编程语言可供选择,每种语言都有其独特的特点和适用场景。 Java、C、C、Go 、Python、C#、Ruby、PHP 等主流编程语言,从底层实现、效率、原理、国内外市场占有率、社区活…...

Linux排查问题常用命令
查看运行内存使用情况命令: free -g(单位GB)free -m(单位MB) 查看磁盘空间使用情况命令: df -h lsof命令: 诊断网络问题和分析系统资源利用情况非常有用 - lsof -n:查看已经删除的…...

【Python/Pytorch - 网络模型】-- 手把手搭建E3D LSTM网络
文章目录 文章目录 00 写在前面01 基于Pytorch版本的E3D LSTM代码02 论文下载 00 写在前面 测试代码,比较重要,它可以大概判断tensor维度在网络传播过程中,各个维度的变化情况,方便改成适合自己的数据集。 需要github上的数据集…...

C#面:Server.UrlEncode、HttpUtility.UrlDecode的区别
C#中的Server.UrlEncode和HttpUtility.UrlDecode都是用于处理URL编码和解码的方法,它们的区别如下: Server.UrlEncode: Server.UrlEncode是一个静态方法,属于System.Web命名空间。它用于将字符串进行URL编码,将特殊字…...
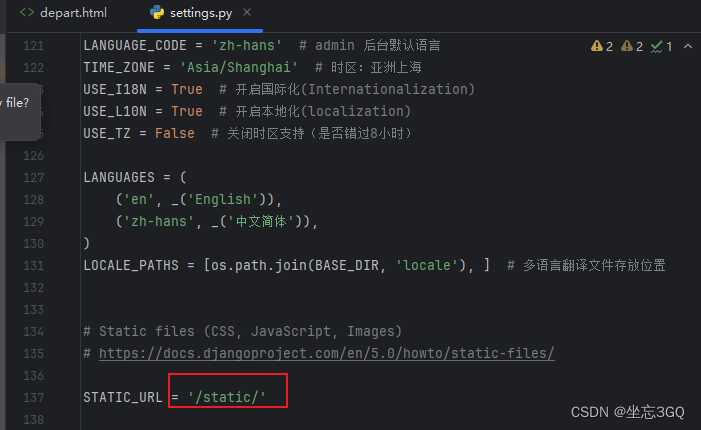
50.Python-web框架-Django中引入静态的bootstrap样式
目录 Bootstrap 官网 特性 下载 在线样例 Bootstrap 入门 Bootstrap v5 中文文档 v5.3 | Bootstrap 中文网 在django中使用bootstrap 新建static\bootstrap5目录,解压后的Bootstrap文件,拷贝项目里就好。 在template文件里引用css文…...

机器学习实验----支持向量机(SVM)实现二分类
目录 一、介绍 (1)解释算法 (2)数据集解释 二、算法实现和代码介绍 1.超平面 2.分类判别模型 3.点到超平面的距离 4.margin 间隔 5.拉格朗日乘数法KKT不等式 (1)介绍 (2)对偶问题 (3)惩罚参数 (4)求解 6.核函数解决非线性问题 7.SMO (1)更新w (2)更新b 三、代…...
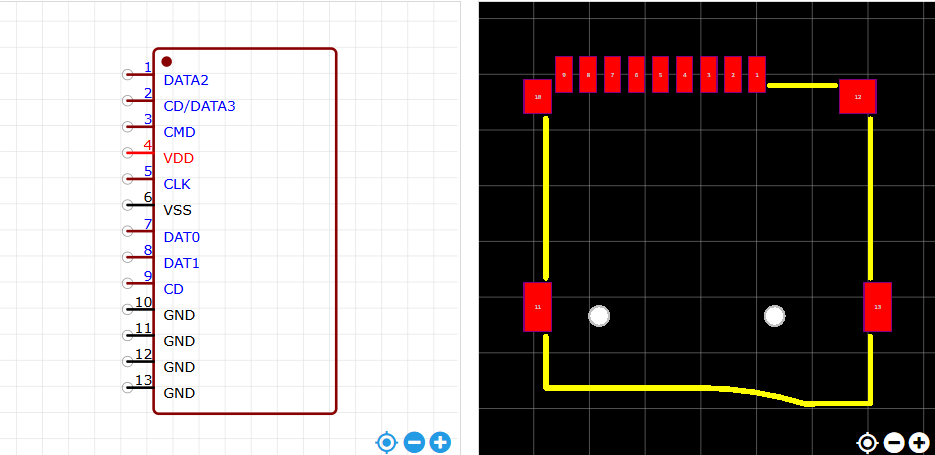
STM32自己从零开始实操05:接口电路原理图
一、TTL 转 USB 驱动电路设计 1.1指路 延续使用芯片 CH340E 。 实物图 实物图 原理图与封装图 1.2数据手册重要信息提炼 1.2.1概述 CH340 是一个 USB 总线的转接芯片,实现 USB 与串口之间的相互转化。 1.2.2特点 支持常用的 MODEM 联络信号 RTS(请…...

git子模块
1 子模块管理的关键文件和配置 在 Git 中使用子模块时,Git 会利用几个特殊的文件和配置来管理子模块。以下是涉及子模块管理的关键文件和配置: 1.1 .gitmodules 这是一个文本文件,位于 Git 仓库的根目录下。它记录了子模块的信息ÿ…...

stm32编写Modbus步骤
1. modbus协议简介: modbus协议基于rs485总线,采取一主多从的形式,主设备轮询各从设备信息,从设备不主动上报。 日常使用都是RTU模式,协议帧格式如下所示: 地址 功能码 寄存器地址 读取寄存器…...

基于 Transformer 的大语言模型
语言建模作为语言模型(LMs)的基本功能,涉及对单词序列的建模以及预测后续单词的分布。 近年来,研究人员发现,扩大语言模型的规模不仅增强了它们的语言建模能力,而且还产生了处理传统NLP任务之外更复杂任务…...

证照之星是一款很受欢迎的证件照制作软件
证照之星是一款很受欢迎的证件照制作软件,证照之星可以为用户提供“照片旋转、裁切、调色、背景处理”等功能,满足用户对证件照制作的基本需求。本站证照之星下载专题为大家提供了证照之星电脑版、安卓版、个人免费版等多个版本客户端资源,此…...
不定时更新 解决无法访问GitHub github.com 打不开 dns访问加速
1 修改hosts Windows 10为例,文件C:\Windows\System32\drivers\etc\hosts 管理员打开记事本来修改 文件-打开-“C:\Windows\System32\drivers\etc\hosts” 20.205.243.168 api.github.com 185.199.108.154 github.githubassets.com 185.199.108.133 raw.githubusercontent.…...

GB28181国标协议实战:用WVP+ZLMediaKit搭建一个支持级联的轻量级视频中台
GB28181国标协议实战:构建轻量级视频中台的架构设计与实现 在安防监控与视频管理领域,GB28181协议已经成为设备互联互通的事实标准。对于需要整合多品牌设备、实现统一管理的技术团队而言,如何快速搭建一个稳定可靠的视频中台是项目落地的关键…...

ComfyUI-WanVideoWrapper:5个技巧快速上手14B参数AI视频生成插件
ComfyUI-WanVideoWrapper:5个技巧快速上手14B参数AI视频生成插件 【免费下载链接】ComfyUI-WanVideoWrapper 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI-WanVideoWrapper 在AI视频生成领域,ComfyUI-WanVideoWrapper作为一款强大…...

解放双手!用Python自动化Adobe Premiere Pro视频编辑的终极指南 [特殊字符]
解放双手!用Python自动化Adobe Premiere Pro视频编辑的终极指南 🎬 【免费下载链接】pymiere Python for Premiere pro 项目地址: https://gitcode.com/gh_mirrors/py/pymiere 还在为重复的视频编辑任务而烦恼吗?PyMiere项目让你用Pyt…...

3步安全卸载:EdgeRemover的非强制解决方案
3步安全卸载:EdgeRemover的非强制解决方案 【免费下载链接】EdgeRemover PowerShell script to remove Microsoft Edge in a non-forceful manner. 项目地址: https://gitcode.com/gh_mirrors/ed/EdgeRemover Windows Edge卸载过程中如何确保系统安全&#x…...

基于YOLOv5和swin-Unet的带钢缺陷智能识别系统
十一、基于YOLOv5和swin-Unet的带钢缺陷智能识别系统 1.带标签数据集,包括检测和分割数据集,其中检测数据共计6类,1800张图片。 2.含模型训练权重。 3.pyqt5设计的界面,带登录界面,注册界面和运行界面。 4.提供详细的环…...

告别重复劳动:用快马平台生成你的专属工作流自动化agent
今天想和大家分享一个提升工作效率的小技巧——用自动化agent框架处理那些重复又繁琐的工作流程。作为一个经常要组织会议的程序员,我发现自己每天要花大量时间做同样的事情:从聊天记录里提取会议信息、手动创建日历事件、再给参会人发邮件通知。直到发现…...

炉石传说自动化工具:从效率提升到策略优化的全栈解决方案
炉石传说自动化工具:从效率提升到策略优化的全栈解决方案 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 问题引入:重构游戏体验…...

Python到Android的终极桥梁:如何用python-for-android将Python应用无缝转换为原生APK
Python到Android的终极桥梁:如何用python-for-android将Python应用无缝转换为原生APK 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android 在移动应用开…...

javaweb农家乐民宿客房美食预订活动管理系统
目录 同行可拿货,招校园代理 ,本人源头供货商系统功能模块划分核心业务流程设计数据分析功能技术实现要点 项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作 同行可拿货,招校园代理 ,本人源头供货商 系统功能模块划分 用户管理…...

Lingbot-Depth-Pretrain-ViTL-14 模型压缩与加速:面向边缘设备的部署优化教程
Lingbot-Depth-Pretrain-ViTL-14 模型压缩与加速:面向边缘设备的部署优化教程 想让一个像 Lingbot-Depth-Pretrain-ViTL-14 这样的大模型在树莓派、Jetson 这类小设备上跑起来,是不是感觉像让一头大象挤进小轿车?直接部署,设备可…...