【Python/Pytorch - 网络模型】-- 手把手搭建E3D LSTM网络

文章目录
文章目录
- 00 写在前面
- 01 基于Pytorch版本的E3D LSTM代码
- 02 论文下载
00 写在前面
测试代码,比较重要,它可以大概判断tensor维度在网络传播过程中,各个维度的变化情况,方便改成适合自己的数据集。
需要github上的数据集以及可运行的代码,可以私聊!
01 基于Pytorch版本的E3D LSTM代码
# 库函数调用
from functools import reduce
from src.utils import nice_print, mem_report, cpu_stats
import copy
import operator
import torch
import torch.nn as nn
import torch.nn.functional as F# E3DLSTM模型代码
class E3DLSTM(nn.Module):def __init__(self, input_shape, hidden_size, num_layers, kernel_size, tau):super().__init__()self._tau = tauself._cells = []input_shape = list(input_shape)for i in range(num_layers):cell = E3DLSTMCell(input_shape, hidden_size, kernel_size)# NOTE hidden state becomes input to the next cellinput_shape[0] = hidden_sizeself._cells.append(cell)# Hook to register submodulesetattr(self, "cell{}".format(i), cell)def forward(self, input):# NOTE (seq_len, batch, input_shape)batch_size = input.size(1)c_history_states = []h_states = []outputs = []for step, x in enumerate(input):for cell_idx, cell in enumerate(self._cells):if step == 0:c_history, m, h = self._cells[cell_idx].init_hidden(batch_size, self._tau, input.device)c_history_states.append(c_history)h_states.append(h)# NOTE c_history and h are coming from the previous time stamp, but we iterate over cellsc_history, m, h = cell(x, c_history_states[cell_idx], m, h_states[cell_idx])c_history_states[cell_idx] = c_historyh_states[cell_idx] = h# NOTE hidden state of previous LSTM is passed as input to the next onex = houtputs.append(h)# NOTE Concat along the channelsreturn torch.cat(outputs, dim=1)class E3DLSTMCell(nn.Module):def __init__(self, input_shape, hidden_size, kernel_size):super().__init__()in_channels = input_shape[0]self._input_shape = input_shapeself._hidden_size = hidden_size# memory gates: input, cell(input modulation), forgetself.weight_xi = ConvDeconv3d(in_channels, hidden_size, kernel_size)self.weight_hi = ConvDeconv3d(hidden_size, hidden_size, kernel_size, bias=False)self.weight_xg = copy.deepcopy(self.weight_xi)self.weight_hg = copy.deepcopy(self.weight_hi)self.weight_xr = copy.deepcopy(self.weight_xi)self.weight_hr = copy.deepcopy(self.weight_hi)memory_shape = list(input_shape)memory_shape[0] = hidden_size# self.layer_norm = nn.LayerNorm(memory_shape)self.group_norm = nn.GroupNorm(1, hidden_size) # wzj# for spatiotemporal memoryself.weight_xi_prime = copy.deepcopy(self.weight_xi)self.weight_mi_prime = copy.deepcopy(self.weight_hi)self.weight_xg_prime = copy.deepcopy(self.weight_xi)self.weight_mg_prime = copy.deepcopy(self.weight_hi)self.weight_xf_prime = copy.deepcopy(self.weight_xi)self.weight_mf_prime = copy.deepcopy(self.weight_hi)self.weight_xo = copy.deepcopy(self.weight_xi)self.weight_ho = copy.deepcopy(self.weight_hi)self.weight_co = copy.deepcopy(self.weight_hi)self.weight_mo = copy.deepcopy(self.weight_hi)self.weight_111 = nn.Conv3d(hidden_size + hidden_size, hidden_size, 1)def self_attention(self, r, c_history):batch_size = r.size(0)channels = r.size(1)r_flatten = r.view(batch_size, -1, channels)# BxtaoTHWxCc_history_flatten = c_history.view(batch_size, -1, channels)# Attention mechanism# BxTHWxC x BxtaoTHWxC' = B x THW x taoTHWscores = torch.einsum("bxc,byc->bxy", r_flatten, c_history_flatten)attention = F.softmax(scores, dim=2)return torch.einsum("bxy,byc->bxc", attention, c_history_flatten).view(*r.shape)def self_attention_fast(self, r, c_history):# Scaled Dot-Product but for tensors# instead of dot-product we do matrix contraction on twh dimensionsscaling_factor = 1 / (reduce(operator.mul, r.shape[-3:], 1) ** 0.5)scores = torch.einsum("bctwh,lbctwh->bl", r, c_history) * scaling_factorattention = F.softmax(scores, dim=0)return torch.einsum("bl,lbctwh->bctwh", attention, c_history)def forward(self, x, c_history, m, h):# Normalized shape for LayerNorm is CxT×H×Wnormalized_shape = list(h.shape[-3:])def LR(input):# return F.layer_norm(input, normalized_shape)return self.group_norm(input, normalized_shape) # wzj# R is CxT×H×Wr = torch.sigmoid(LR(self.weight_xr(x) + self.weight_hr(h)))i = torch.sigmoid(LR(self.weight_xi(x) + self.weight_hi(h)))g = torch.tanh(LR(self.weight_xg(x) + self.weight_hg(h)))recall = self.self_attention_fast(r, c_history)# nice_print(**locals())# mem_report()# cpu_stats()c = i * g + self.group_norm(c_history[-1] + recall) # wzji_prime = torch.sigmoid(LR(self.weight_xi_prime(x) + self.weight_mi_prime(m)))g_prime = torch.tanh(LR(self.weight_xg_prime(x) + self.weight_mg_prime(m)))f_prime = torch.sigmoid(LR(self.weight_xf_prime(x) + self.weight_mf_prime(m)))m = i_prime * g_prime + f_prime * mo = torch.sigmoid(LR(self.weight_xo(x)+ self.weight_ho(h)+ self.weight_co(c)+ self.weight_mo(m)))h = o * torch.tanh(self.weight_111(torch.cat([c, m], dim=1)))# TODO is it correct FIFO?c_history = torch.cat([c_history[1:], c[None, :]], dim=0)# nice_print(**locals())return (c_history, m, h)def init_hidden(self, batch_size, tau, device=None):memory_shape = list(self._input_shape)memory_shape[0] = self._hidden_sizec_history = torch.zeros(tau, batch_size, *memory_shape, device=device)m = torch.zeros(batch_size, *memory_shape, device=device)h = torch.zeros(batch_size, *memory_shape, device=device)return (c_history, m, h)class ConvDeconv3d(nn.Module):def __init__(self, in_channels, out_channels, *vargs, **kwargs):super().__init__()self.conv3d = nn.Conv3d(in_channels, out_channels, *vargs, **kwargs)# self.conv_transpose3d = nn.ConvTranspose3d(out_channels, out_channels, *vargs, **kwargs)def forward(self, input):# print(self.conv3d(input).shape, input.shape)# return self.conv_transpose3d(self.conv3d(input))return F.interpolate(self.conv3d(input), size=input.shape[-3:], mode="nearest")class Out(nn.Module):def __init__(self, in_channels, out_channels):super().__init__()self.conv = nn.Conv3d(in_channels, out_channels, kernel_size = 3, stride=1, padding=1)def forward(self, x):return self.conv(x)class E3DLSTM_NET(nn.Module):def __init__(self, input_shape, hidden_size, num_layers, kernel_size, tau, time_steps, output_shape):super().__init__()self.input_shape = input_shapeself.hidden_size = hidden_sizeself.num_layers = num_layersself.kernel_size = kernel_sizeself.tau = tauself.time_steps = time_stepsself.output_shape = output_shapeself.dtype = torch.float32self.encoder = E3DLSTM(input_shape, hidden_size, num_layers, kernel_size, tau).type(self.dtype)self.decoder = nn.Conv3d(hidden_size * time_steps, output_shape[0], kernel_size, padding=(0, 2, 2)).type(self.dtype)self.out = Out(4, 1)def forward(self, input_seq):return self.out(self.decoder(self.encoder(input_seq)))# 测试代码
if __name__ == '__main__':input_shape = (16, 4, 16, 16)output_shape = (16, 1, 16, 16)tau = 2hidden_size = 64kernel = (3, 5, 5)lstm_layers = 4time_steps = 29x = torch.ones([29, 2, 16, 4, 16, 16])model = E3DLSTM_NET(input_shape, hidden_size, lstm_layers, kernel, tau, time_steps, output_shape)print('finished!')f = model(x)print(f)
02 论文下载
Eidetic 3D LSTM: A Model for Video Prediction and Beyond
Eidetic 3D LSTM: A Model for Video Prediction and Beyond
Github链接:e3d_lstm
相关文章:
【Python/Pytorch - 网络模型】-- 手把手搭建E3D LSTM网络
文章目录 文章目录 00 写在前面01 基于Pytorch版本的E3D LSTM代码02 论文下载 00 写在前面 测试代码,比较重要,它可以大概判断tensor维度在网络传播过程中,各个维度的变化情况,方便改成适合自己的数据集。 需要github上的数据集…...

C#面:Server.UrlEncode、HttpUtility.UrlDecode的区别
C#中的Server.UrlEncode和HttpUtility.UrlDecode都是用于处理URL编码和解码的方法,它们的区别如下: Server.UrlEncode: Server.UrlEncode是一个静态方法,属于System.Web命名空间。它用于将字符串进行URL编码,将特殊字…...
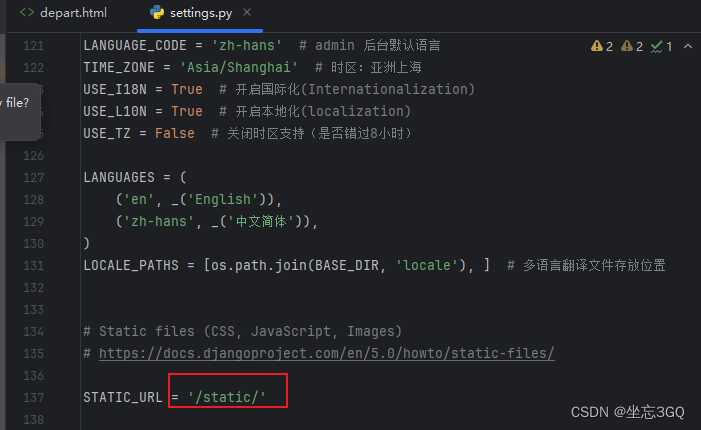
50.Python-web框架-Django中引入静态的bootstrap样式
目录 Bootstrap 官网 特性 下载 在线样例 Bootstrap 入门 Bootstrap v5 中文文档 v5.3 | Bootstrap 中文网 在django中使用bootstrap 新建static\bootstrap5目录,解压后的Bootstrap文件,拷贝项目里就好。 在template文件里引用css文…...

机器学习实验----支持向量机(SVM)实现二分类
目录 一、介绍 (1)解释算法 (2)数据集解释 二、算法实现和代码介绍 1.超平面 2.分类判别模型 3.点到超平面的距离 4.margin 间隔 5.拉格朗日乘数法KKT不等式 (1)介绍 (2)对偶问题 (3)惩罚参数 (4)求解 6.核函数解决非线性问题 7.SMO (1)更新w (2)更新b 三、代…...
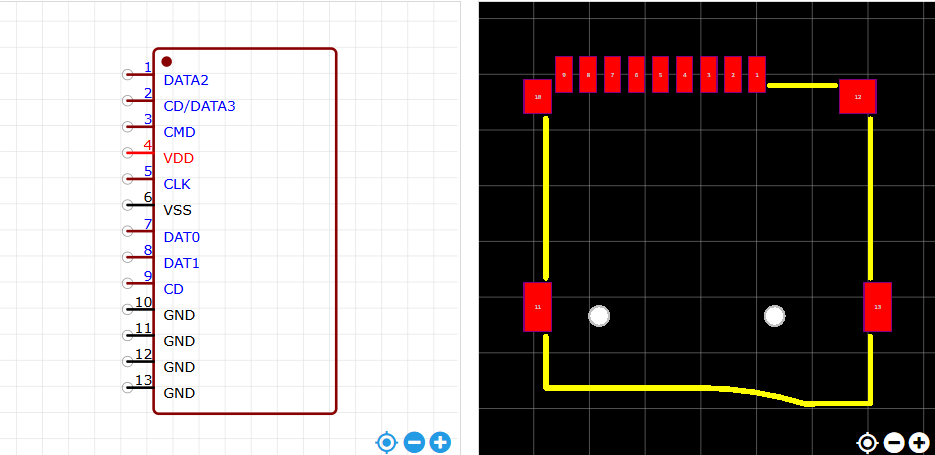
STM32自己从零开始实操05:接口电路原理图
一、TTL 转 USB 驱动电路设计 1.1指路 延续使用芯片 CH340E 。 实物图 实物图 原理图与封装图 1.2数据手册重要信息提炼 1.2.1概述 CH340 是一个 USB 总线的转接芯片,实现 USB 与串口之间的相互转化。 1.2.2特点 支持常用的 MODEM 联络信号 RTS(请…...

git子模块
1 子模块管理的关键文件和配置 在 Git 中使用子模块时,Git 会利用几个特殊的文件和配置来管理子模块。以下是涉及子模块管理的关键文件和配置: 1.1 .gitmodules 这是一个文本文件,位于 Git 仓库的根目录下。它记录了子模块的信息ÿ…...

stm32编写Modbus步骤
1. modbus协议简介: modbus协议基于rs485总线,采取一主多从的形式,主设备轮询各从设备信息,从设备不主动上报。 日常使用都是RTU模式,协议帧格式如下所示: 地址 功能码 寄存器地址 读取寄存器…...

基于 Transformer 的大语言模型
语言建模作为语言模型(LMs)的基本功能,涉及对单词序列的建模以及预测后续单词的分布。 近年来,研究人员发现,扩大语言模型的规模不仅增强了它们的语言建模能力,而且还产生了处理传统NLP任务之外更复杂任务…...

证照之星是一款很受欢迎的证件照制作软件
证照之星是一款很受欢迎的证件照制作软件,证照之星可以为用户提供“照片旋转、裁切、调色、背景处理”等功能,满足用户对证件照制作的基本需求。本站证照之星下载专题为大家提供了证照之星电脑版、安卓版、个人免费版等多个版本客户端资源,此…...
不定时更新 解决无法访问GitHub github.com 打不开 dns访问加速
1 修改hosts Windows 10为例,文件C:\Windows\System32\drivers\etc\hosts 管理员打开记事本来修改 文件-打开-“C:\Windows\System32\drivers\etc\hosts” 20.205.243.168 api.github.com 185.199.108.154 github.githubassets.com 185.199.108.133 raw.githubusercontent.…...

单向环形链表的创建与判断链表是否有环
单向环形链表的创建与单向链表的不同在于,最后一个节点的next需要指向头结点; 判断链表是否带环,只需要使用两个指针,一个步长为1,一个步长为2,环状链表这两个指针总会相遇。 如下示例代码: l…...
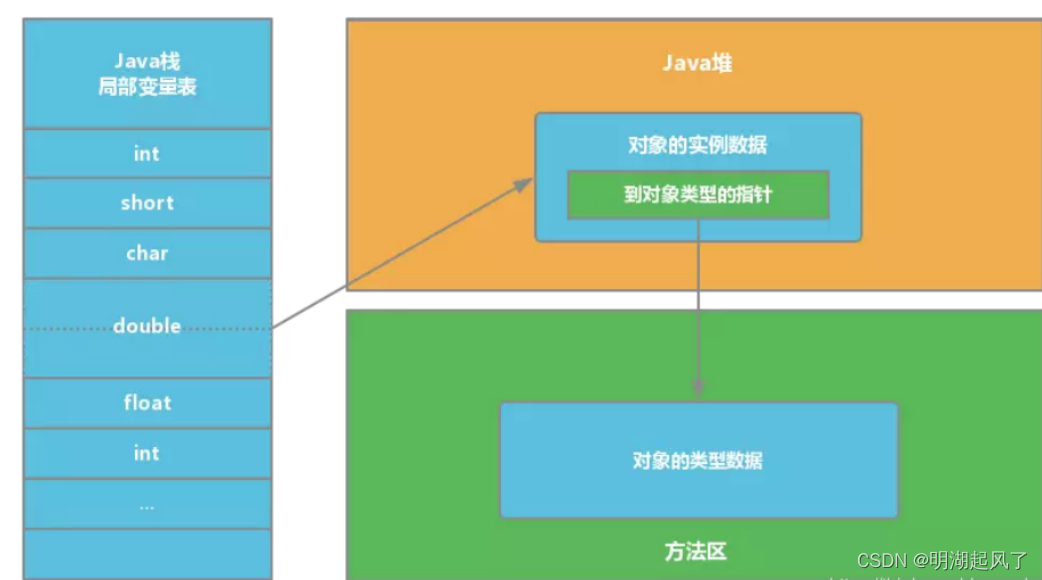
JVM堆栈的区别、分配内存与并发安全问题、对象定位
一、堆和栈的区别 堆(Heap)和栈(Stack)是两种基本的数据结构,它们在内存管理、程序执行流程控制等方面扮演着重要角色。在编程语言尤其是Java这样的高级语言环境中,堆和栈的概念被用来描述程序运行时的内存…...
)
Python教程:机器学习 - 百分位数(4)
什么是百分位数? 统计学中使用百分位数(Percentiles)为您提供一个数字,该数字描述了给定百分比值小于的值。 例如:假设我们有一个数组,包含住在一条街上的人的年龄。 ages [5,31,43,48,50,41,7,11,15,3…...
数据结构习题(快期末了)
一个数据结构是由一个逻辑结构和这个逻辑结构上的一个基本运算集构成的整体。 从逻辑关系上讲,数据结构主要分为线性结构和非线性结构两类。 数据的存储结构是数据的逻辑结构的存储映像。 数据的物理结构是指数据在计算机内实际的存储形式。 算法是对解题方法和…...

Http协议:Http缓存
文章目录 Cookie和Session缓存有效性检查整体流程总结Cookie和Session Cookie 客户端的缓存 Session 服务端的缓存,存储服务器与客户端一次会话的过程中的数据/资源 两者区别 是服务端与客户端的不同需求造成的 有效期 Cookie的有效期很长,Session的较短 原因:服务…...

idea插件开发之hello idea plugin
写在前面 最近一直想研究下自定义idea插件的内容,这样如果是想要什么插件,但又一时找不到合适的,就可以自己来搞啦!这不终于有时间来研究下,但过程可谓是一波三折,再一次切身体验了下万事开头难。那么&…...

Sm4【国密4加密解密】
当我们开发金融、国企、政府信息系统时,不仅要符合网络安全的等保二级、等保三级,还要求符合国密的安全要求,等保测评已经实行很久了,而国密测评近两年才刚开始。那什么是密码/国密?什么是密评?本文就关于密…...

git如果将多次提交压缩成一次
将N个提交压缩到单个提交中有两种方式: git reset git reset的本意是版本回退,回退时可以选择保留commit提交。我们基于git reset的作用,结合新建分支,可以实现多次commit提交的合并。这个不需要vim编辑,很少有冲突。…...

android用Retrofit进行网络请求和解析
Retrofit 的原理 Retrofit的核心原理包括动态代理与Service Method的构建、注解解析与请求配置、网络请求执行与响应处理等。它是一个类型安全的HTTP客户端,用于Android和Java平台,通过将HTTP API转化为Java接口的方式,简化了网络请求的编写…...

list容器的基本使用
目录 前言一,list的介绍二,list的基本使用2.1 list的构造2.2 list迭代器的使用2.3 list的头插,头删,尾插和尾删2.4 list的插入和删除2.5 list 的 resize/swap/clear 前言 list中的接口比较多,与string和vector类似&am…...

通义千问大模型+Flask:打造智能PDF批量解析与问答系统
1. 为什么需要智能PDF解析与问答系统 每天都有海量的PDF文档在各个行业流转,从合同协议到财务报表,从学术论文到产品手册。传统的人工阅读和提取方式效率低下,容易出错。我曾经帮一家律师事务所处理过上千份合同,光是找出所有涉及…...

5个核心特性让嵌入式设备实现高效安全加密:tiny-AES-c轻量级加密库深度解析
5个核心特性让嵌入式设备实现高效安全加密:tiny-AES-c轻量级加密库深度解析 【免费下载链接】tiny-AES-c Small portable AES128/192/256 in C 项目地址: https://gitcode.com/gh_mirrors/ti/tiny-AES-c 在物联网设备和嵌入式系统的资源受限环境中࿰…...
)
新手必看:腾讯SRC漏洞挖掘实战全记录(附详细步骤与避坑指南)
腾讯SRC漏洞挖掘实战:从零到一的完整攻防手册 第一次接触漏洞挖掘时,我盯着电脑屏幕发呆了半小时——那些专业术语像天书一样,而论坛里"轻松挖洞"的帖子更让我怀疑自己是不是选错了方向。直到在腾讯SRC提交第一个有效漏洞的那天&am…...

Paperless-ng多语言文档管理终极指南:如何实现国际化支持的完整解决方案
Paperless-ng多语言文档管理终极指南:如何实现国际化支持的完整解决方案 【免费下载链接】paperless-ng A supercharged version of paperless: scan, index and archive all your physical documents 项目地址: https://gitcode.com/gh_mirrors/pa/paperless-ng …...

FireRedASR-AED-L从零开始教程:无需Python环境,镜像开箱即用识别中英混合语音
FireRedASR-AED-L从零开始教程:无需Python环境,镜像开箱即用识别中英混合语音 你是不是经常遇到这样的场景?手头有一段重要的会议录音,里面既有中文讨论,又夹杂着几个英文专业术语,想把它转成文字却找不到…...

一骑红尘妃子笑,CodeBuddy 运荔枝
一骑红尘妃子笑,CodeBuddy 运荔枝故事背景:适逢荔枝盛产季节,圣人(唐玄宗)为博美人(杨贵妃)一笑,钦点"荔枝使",负责将荔枝从"岭南"(今广…...

EmbeddingGemma-300M效果实测:Ollama部署下的中文语义相似度
EmbeddingGemma-300M效果实测:Ollama部署下的中文语义相似度 1. 轻量级嵌入模型的实用价值 在当今信息爆炸的时代,文本数据的处理和分析变得愈发重要。无论是构建智能搜索系统、实现文档聚类,还是开发个性化推荐引擎,文本嵌入技…...

找不到msvcr120.dll解决方法:2026年有效的一键修复与手动安装步骤
正玩着游戏或做着设计图,屏幕突然弹出“找不到msvcr120.dll”的提示,相信很多Windows用户都遇到过这种令人抓狂的时刻。这个错误意味着你的电脑缺少了某个软件或游戏运行所必需的“零件”。别担心,这个零件就是Microsoft Visual C 2013运行库…...

4个维度解析YetAnotherKeyDisplayer:开源实时按键可视化工具全指南
4个维度解析YetAnotherKeyDisplayer:开源实时按键可视化工具全指南 【免费下载链接】YetAnotherKeyDisplayer The application for displaying pressed keys of the keyboard 项目地址: https://gitcode.com/gh_mirrors/ye/YetAnotherKeyDisplayer YetAnothe…...
)
三自由度机械手-工业机器人(说明书+CAD图纸)
三自由度机械手作为工业机器人领域的典型代表,其核心作用在于通过三个独立运动轴的协同控制,实现末端执行器在三维空间内的精准定位与灵活操作。这种结构通过旋转、俯仰与伸缩三个方向的复合运动,能够覆盖工作空间内的任意目标点,…...