数据仓库相关概念的解释
数据仓库相关概念的解释
文章目录
- 数据仓库相关概念的解释
- 1 ETL是什么?
- ETL体系结构
- 2 数据流向
- 何为数仓DW
- 3 ODS 是什么?
- 4 数据仓库层DW
- DWD 明细层
- DWD 轻度汇总层(MID或DWB,data warehouse basis)
- DWS 主题层(DM,data market 或DWS,data warehouse service)
- 5 数据产品层/应用层 APP
- 6 数据的来源
- 7 ODS、DW -> App 层
- 8 维度表 DIM
1 ETL是什么?
ETL 是英文 Extract-Transform-Load 的缩写,用来描述将数据从源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程,它能够对各种分布的、异构的元数据(如关系数据)进行抽取,按照预先设计的规则将不完整数据、重复数据以及错误数据等“脏”数据内容进行清晰,得到符合要求的“干净”数据,并加载到数据仓库中进行存储,这些“干净”数据久成为了数据分析、数据挖掘的基石。
ETL 就是抽取、转换、加载这三个单词的缩写,所以顾名思义主要的工作就是把数据从那块儿抽过来,然后进行一个清洗、加工,最后再存到哪块儿。
抽取:这个环节可能主要是比如说Sqoop、Flume、Kafka、还有Kettle、Datax、Maxwell这些狗屎抽取工作。离线可能主要是用的Sqoop或者DataX去进行离线数据的抽取,像实时可能会采用比如说Flume或者是kafka、Maxwell,还有Kettle去进行抽取。
转换:转换包括清洗、合并、拆分、加工等等,可以用Hadoop生态的东西,MapReduce、Spark、Flink、Hive等进行数据方面的清洗。
加载:抽取转换之后,就是将数据加载到目标数据库。可能会用到Hbase去存储一些大数据方面的东西,或者HDFS等等这些工具。
**ETL是实现商务智能(Business Intelligence,BI)的核心** 。一般情况下,ETL 会花费整个BI项目三分之一的时间,因此ETL设计得好坏直接影响BI项目的成败。
企业中常用的ETL实现有多种方式,常见的方式如下。
(1)借助ETL工具(如Pentaho Kettle、Infomatic 等)。
(2)编写SQL语句。
(3)将ETL工具和SQL语句结合起来使用。
上述3种实现方式各有利弊,其中第1种方式可以快速建立ETL工程,屏蔽复杂的编码任务、加快速度和降低难度,但是缺少灵活性:第二种方式使用编写SQL语句的方式优点是灵活,可以提高ETL的运行效率,但是编码复杂,对技术要求比较稿;第三种方式综合了前面两种方法的优点,可以极大地提高ETL的开发速度和效率。
ETL体系结构
ETL主要是用来实现异构数据源数据集成的。多种数据源的所有原始数据大部分未作修改就被载入ETL,因此,无论数据源再关系型数据库、非关系型数据库,还是在外部文件,集成后的数据都将被置于数据库的数据表或数据仓库的维度表中,以便在数据库内或数据仓库种做进一步转换(因此,一般会将最终的数据存储到数据库或者数据仓库中)。ETL的体系结构如图下所示。

如图,若数据源1和数据源2均为功能较强大的DBMS(数据库管理系统),则可以使用SQL语句完成一部分数据清洗工作。但是,如果数据源为外部文件,就无法使用SQL语句进行数据清洗工作了,只能直接从数据源中抽取出来,然后在数据转换的时候进行数据清洗的工作。因此,数据仓库中的数据清洗工作主要还是在数据转换的时候进行。清洗好的数据将保存到目标数据库中,用于后续的数据分析、数据挖掘以及商业智能。
2 数据流向

何为数仓DW
Data warehouse(可简写为DW 或者 DWH) 数据仓库,是在数据库已经大量存在的情况下,它是一整套包括了 etl、调度、建模在内的完整的理论体系。
数据仓库的方案建设的目的,是为前端查询和分析作为基础,主要应用于 OLAP(on-line Analytical Processing),支持复杂的分析操作,侧重决策支持,并且提供只管移动的查询结果。目前行业比较流行的有:AWS Redshift,Greenplum,Hive等。
数据仓库并不是数据的最终目的地,而是为数据最终的目的地做好准备,这些准备包含:清洗、转义、分类、重组、合并、拆分、统计等
主要特点
面向主题
操作型数据库组织面向事务处理任务,而数据仓库中的数据是按照一定的主题域进行组织。
主题是指用户使用数据仓库进行决策时所关系的重点方面,一个主题通过与多个操作型信息系统相关。
集成
需要对元数据进行加工与融合,统一与综合
在加工的过程中必须消除源数据的不一致性,以保证数据仓库内的信息是关于整个企业的一致的全局信息。(关联关系)
不可修改
DW中的数据并不是最新的,而是来源于其他数据源
数据仓库主要是为决策分析提供数据,涉及的操作主要是数据的查询
与时间相关
处于决策的需要数据仓库中的数据都需要表明时间属性
与数据库对比
DW:专门为数据分析设计的,设计读取大量数据以了解数据之间的关系和趋势
数据库:用于捕获和存储数据
| 特性 | 数据仓库 | 事务数据库 |
|---|---|---|
| 适合的工作负载 | 分析、报告、大数据 | 事务处理 |
| 数据源 | 从多个来源手机和标准话的数据 | 从单个来源(例如事务系统)捕获的数据 |
| 数据捕获 | 批量写入操作通过按照预定的批处理计划执行 | 针对连续写入操作进行了优化,因为新数据能够最大程度地提供事务吞吐量 |
| 数据标准化 | 非标准化schema,例如星型schema或雪花行schema | 高度标准化的静态schema |
| 数据存储 | 使用列式存储进行了优化,可实现轻松访问和高速查询性能 | 针对在单行型物理块中执行高吞吐量写入操作进行了优化 |
| 数据访问 | 为最小化I/O并最大化数据吞吐量进行了优化 | 大量小型读取操作 |
3 ODS 是什么?
- ODS层最好理解,基本上就是数据从源表拉过来,进行etl,比如mysql 映射到hive,那么到了hive里面就是ods层。
- ODS 全称是 Operational Data Store,是、操作数据存储“面向主题的”,数据运营层,也叫ODS层,是最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,即传说中的ETL之后,装入本层。本层的数据,总体上大多是按照源头业务系统的分类方式而分类的。但是,这一层面的数据却不等同于原始数据。在元数据装入这一层时,要进行诸如去噪(例如有一条数据中人的年龄是300岁,这种属于异常数据,就与要提前做一些处理)、去重(例如在个人资料表中,同一ID 却有两条重复数据,在接入的时候需要做进一步去重)、字段命名规范等一系列操作。
4 数据仓库层DW
数据仓库层(DW),是数据仓库的主题,在这里,从ODS 层中获得的数据按照主题 建立各种数据模型。这一层和维度建模会有比较深的联系。
细分:
- 数据明细层:DWD(Data Warehouse Detail)
- 数据中间层:DWM(Data Warehouse Middle)
- 数据服务层:DWS(Data Warehouse Service)
DWD 明细层
明细层(ODS,Operational Data Store,DWD:data warehouse detail)
- 概念:是数据仓库的细节数据层,是对STAGE 层数据进行沉淀,减少了抽取的复杂性,同时ODS/DWD的信息模型组织主要遵循企业业务事务处理的形式,将各个专业数据进行集中,明细曾跟stage层的粒度一致,属于分析的公共资源
- 数据生产方式:部分数据直接来自kafka,部分数据为接口层数据与历史数据合成。
- 这个stage层不是很清晰
DWD 轻度汇总层(MID或DWB,data warehouse basis)
- 概念:轻度汇总层数据仓库中DWD 层和DM层之间的一个过渡层次,是对DWD层的生产数据进行轻度综合和汇总统计(可以把复杂的清晰,处理包含,如根据PV日志生成的会话数据)。轻度综合层与DWD的主要区别在于二者的应用领域不同,DWD的数据来源于生产型系统,并未满意一些不可预见的需求而进行沉淀;轻度综合层则面向分析型应用进行细粒度的统计和沉淀
- 数据生成方式:由明细层按照一定的业务需求生成轻度汇总表。明细层需要复杂清晰的数据和需要MR处理的数据也经过处理后接入到轻度汇总层。
- 日志存储方式:内表,parquet文件格式。
- 日志删除方式:长久存储。
- 表schema:一般按天创建分区,没有时间概念的按具体业务选择分区字段。
- 库与表命名。库名:dwd.表名:初步考虑格式为:dwd日期业务表名,待定。
- 旧数据更新方式:直接覆盖
DWS 主题层(DM,data market 或DWS,data warehouse service)
- 概念:又称数据集市或宽表。按照业务划分,如流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
- 数据生成方式:由轻度汇总层和明细层数据计算生成。
- 日志存储方式:使用impala内表,parquet文件格式。
- 日志删除方式:长久存储。
- 表schema:一般按天创建分区,没有时间概念的按具体业务选择分区字段。
- 库与表命名。库名:dm.表名:初步考虑格式为:dm日期业务表名,待定。
- 旧数据更新方式:直接覆盖
5 数据产品层/应用层 APP
数据产品层(APP),这一层是提供为数据产品使用的结果数据。
主要是提供给数据产品和数据分析使用的数据,一般会存放在 ES、Mysql 等系统中供线上系统使用,也可能会存在 Hive 或者 Druid 中供数据分析和数据挖掘使用。
如我们经常说的报表数据,或者说那种打款表,一般就放在这里。
应用层(App)
- 概念:应用层是根据业务需要,由前面三层数据统计而出的结果,可以直接提供查询占星,或导入至MySql中使用。
- 数据生成方式:由明细层、轻度汇总层,数据集市层生成,一般要求数据主要来源于集市层。
- 日志存储方式:使用 impala 内表,parquet 文件格式。
- 日志删除方式:长久存储。
- 表schema:一般按天创建分区,没有事件概念的按具体业务选择分区字段。
- 库与表命名。库名:暂定 apl,另外根据业务不同,不限定一定要一个库。
- 旧数据更新方式:直接覆盖。

6 数据的来源
数据主要会有两个大的来源:
业务库,这里经常会使用 Sqoop 来抽取
在实时方面,可以考虑用 Canal 监听 Mysql 的 Binlog,实时接入即可。
埋点日志,线上系统会打入各种日志,这些日志一般以文件的形式保存,我们可以选择用 Flume 定时抽取,也可以用用 Spark Streaming 或者 Storm 来实时接入,当然,Kafka 也会是一个关键的角色。
还有使用 filebeat 收集日志,打到kafka ,然后处理日志
注意:在这层,理应不是简单的数据接入,而是要考虑一定的数据清洗,比如异常字段的处理、字段命名规范化、时间字段的统一等,一般这些很容易会被忽略,但是却至关重要。特别是后期我们做各种特征自动生成的时候,会十分有用。
7 ODS、DW -> App 层
这里也主要分两种类型:
- 每日定时任务型:比如典型的日计算任务,每天凌晨算前一天的数据,早上起来看报表。这种任务经常使用 Hive、Spark 或者生撸 MR 程序来计算,最终结果写入 Hive、Hbase、Mysql、Es 或者 Redis 中。
- 实时数据:这部分主要是各种实时的系统使用,比如我们的实时推荐、实时用户画像,一般我们会用 Spark Streaming、Storm 或者 Flink 来计算,最后会落入 Es、Hbase 或者 Redis 中。
8 维度表 DIM
维度表(Dimension)
为表层主要包含两部分数据:
- 高基数维度数据:一般是用户资料表、商品资料表类似的资料表。数据量可能是千万级或者上亿级别。
- 低基数维度数据:一般是配置表,比如枚举值对应的中文含义,或者日期维表。数据量可能是个位数或者几千万。
相关文章:
数据仓库相关概念的解释
数据仓库相关概念的解释 文章目录数据仓库相关概念的解释1 ETL是什么?ETL体系结构2 数据流向何为数仓DW3 ODS 是什么?4 数据仓库层DWDWD 明细层DWD 轻度汇总层(MID或DWB,data warehouse basis)DWS 主题层(D…...
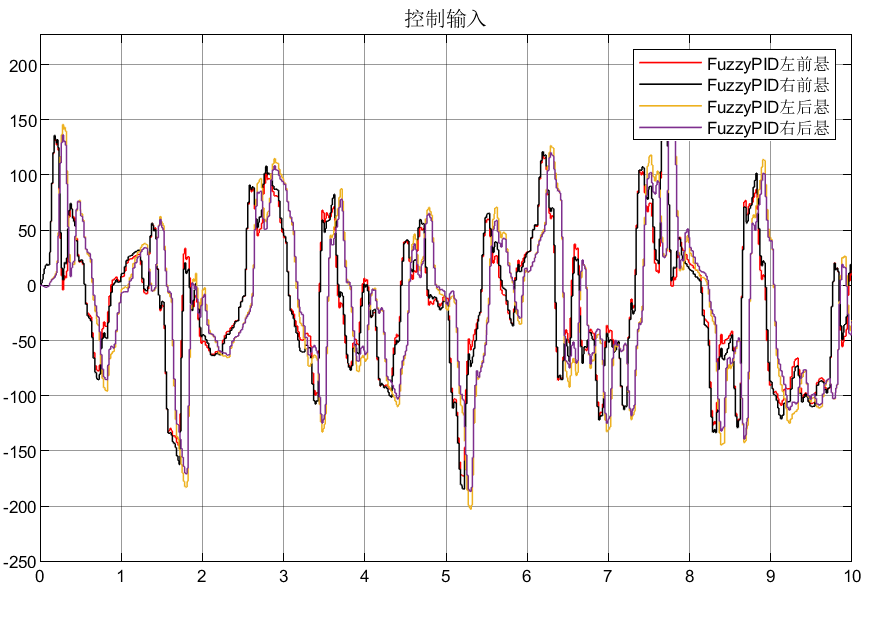
1/4车、1/2车、整车悬架模糊PID控制仿真合集
目录 前言 1. 1/4悬架系统 1.1数学模型 1.2仿真分析 2. 1/2悬架系统 2.1数学模型 2.2仿真模型 2.3仿真分析 3. 整车悬架系统 3.1数学模型 3.2仿真分析 4.总结 前言 前面几篇文章介绍了LQR、SkyHook、H2/H∞、PID控制,接下来会继续介绍滑模、反步法、M…...

Linux性能补丁升级,避免不必要的跨核Wake-Up
导读一个由英特尔发起的、旨在改进Linux内核公平调度程序代码的补丁系列,也看到了来自AMD工程师和其他利益相关者的测试/反馈,并继续进行改进。这个补丁系列的重点是避免在不必要的情况下发生过多的跨核唤醒(Cross-CPU Wake-up)。这样一来,这…...

Spring Cloud Alibaba全家桶(六)——微服务组件Sentinel介绍与使用
前言 本文小新为大家带来 微服务组件Sentinel介绍与使用 相关知识,具体内容包括分布式系统存在的问题,分布式系统问题的解决方案,Sentinel介绍,Sentinel快速开始(包括:API实现Sentinel资源保护,…...

拼多多2021笔试真题集 -- 3. 多多的求和计算
多多的求和计算 多多路上从左到右有N棵树(编号1~N),其中第i个颗树有和谐值Ai。 多多鸡认为,如果一段连续的树,它们的和谐值之和可以被M整除,那么这个区间整体看起来就是和谐的。 现在多多鸡想请…...

DP算法:动态规划算法
步骤(1)确定初始状态(2)确定转移矩阵,得到每个阶段的状态,由上一阶段推到出来(3)确定边界条件。例题蓝桥杯——印章(python实现)使用dp记录状态,d…...
一三四——一六七
一三四、JavaScript——_DOM简介 MDNq前端参考文档:DOM 概述 - Web API 接口参考 | MDN (mozilla.org) 一三五、JavaScript——HelloWorld <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><meta h…...

day29_JS
今日内容 上课同步视频:CuteN饕餮的个人空间_哔哩哔哩_bilibili 同步笔记沐沐霸的博客_CSDN博客-Java2301 零、 复习昨日 一、事件 二、DOM操作 三、案例 零、 复习昨日 js 脚本语言,弱类型 引入方案: 3种 js的内容: 语法dombom 语法 变量 var 数据类型 引用类型 - 对象,J…...
【HTTP协议与Web服务器】
HTTP协议与Web服务器浏览器与服务器通信过程HTTP的请求报头HTTP请求报头结构HTTP的请求方法HTTP应答报头HTTP应答报头结构应答状态web服务器的c语言实现浏览器与服务器通信过程 浏览器与Web服务器再应用层通信使用的是HTTP协议,而HTTP协议在传输层使用的是TCP协议。…...
Idea+maven+spring-cloud项目搭建系列--12 整合grpc
前言: grpc 是geogle 开源的rpc 通信框架,通过定义proto生成通信存根,像本地调用服务一样,进行远程服务的调用; 1 消费端服务提供: 1.1 引入grpc 和 protobuf <!-- RPC --> <!-- RPC 服务调用 …...
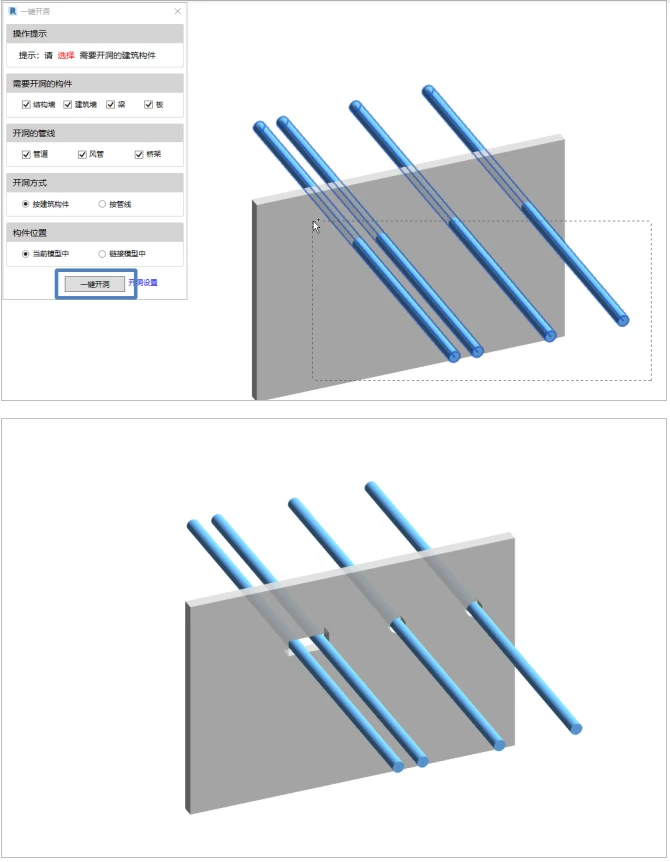
Revit开洞问题:结构专业开洞口剖面显示及一键开洞
一、Revit中关于结构专业开洞口剖面显示问题 Revit作业的时候,我们不仅只为了一个最后的三维立体模型,我们需要的是一个符合国家以及本院制图标准的一个出图样式,这时候就会出现各种各样的显示问题,本期就一个结构专业开洞显示问题,跟大家一起…...
)
0107连通分量-无向图-数据结构和算法(Java)
文章目录1 API2 代码实现和分析测试后记1 API 深度优先搜索下一个直接应用就是找出一幅图中的连通分量,定义如下API。 public class CCCC(Graph g)预处理构造函数booleanconnected(int v, int w)v和w连通吗intcount()连通分量数intid(int v)v所在的连通分量标识符(0~count()-…...
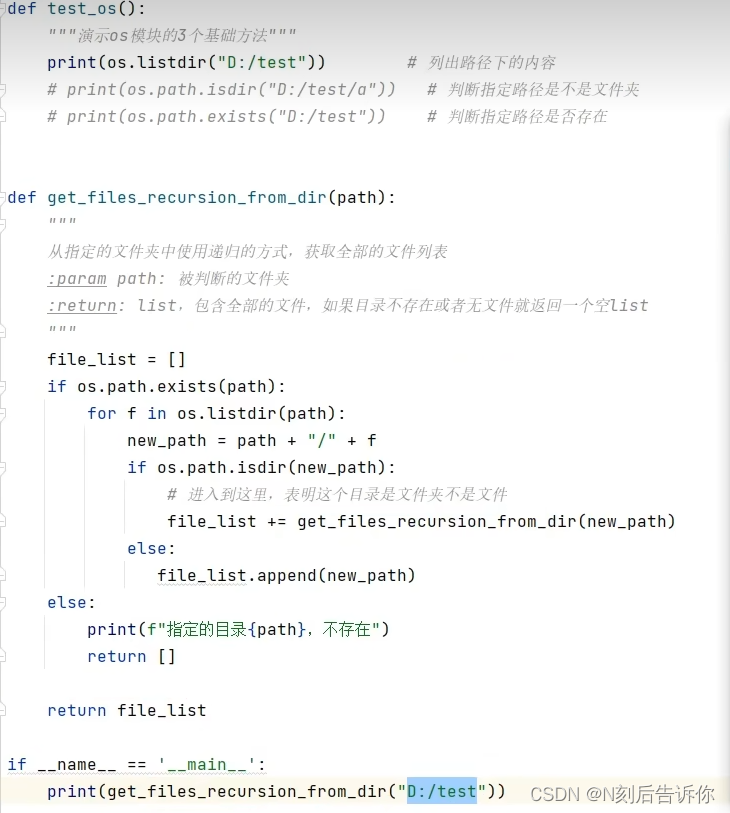
[学习笔记]黑马程序员python教程
文章目录思维导图Python基础知识图谱面向对象SQL入门和实战Python高阶技巧第一阶段第九章:Python异常、模块与包1.9.1异常的捕获1.9.1.1 为什么要捕获异常1.9.1.2 捕获常规的异常1.9.1.3 捕获指定的异常1.9.1.4 捕获多个异常1.9.1.5 捕获全部异常1.9.1.6 异常的else…...

如何配置用于构建 FastReport Online Designer 的 API ?
FastReport Online Designer 是一个跨平台的报表设计器,允许通过任何平台的移动设备创建和编辑报表。今天我们就一起来看看在2023版中新增和改进的功能有哪些,点击下方可以获取最新版免费试用哦! FastReport Onlin Designe最新版试用https:/…...
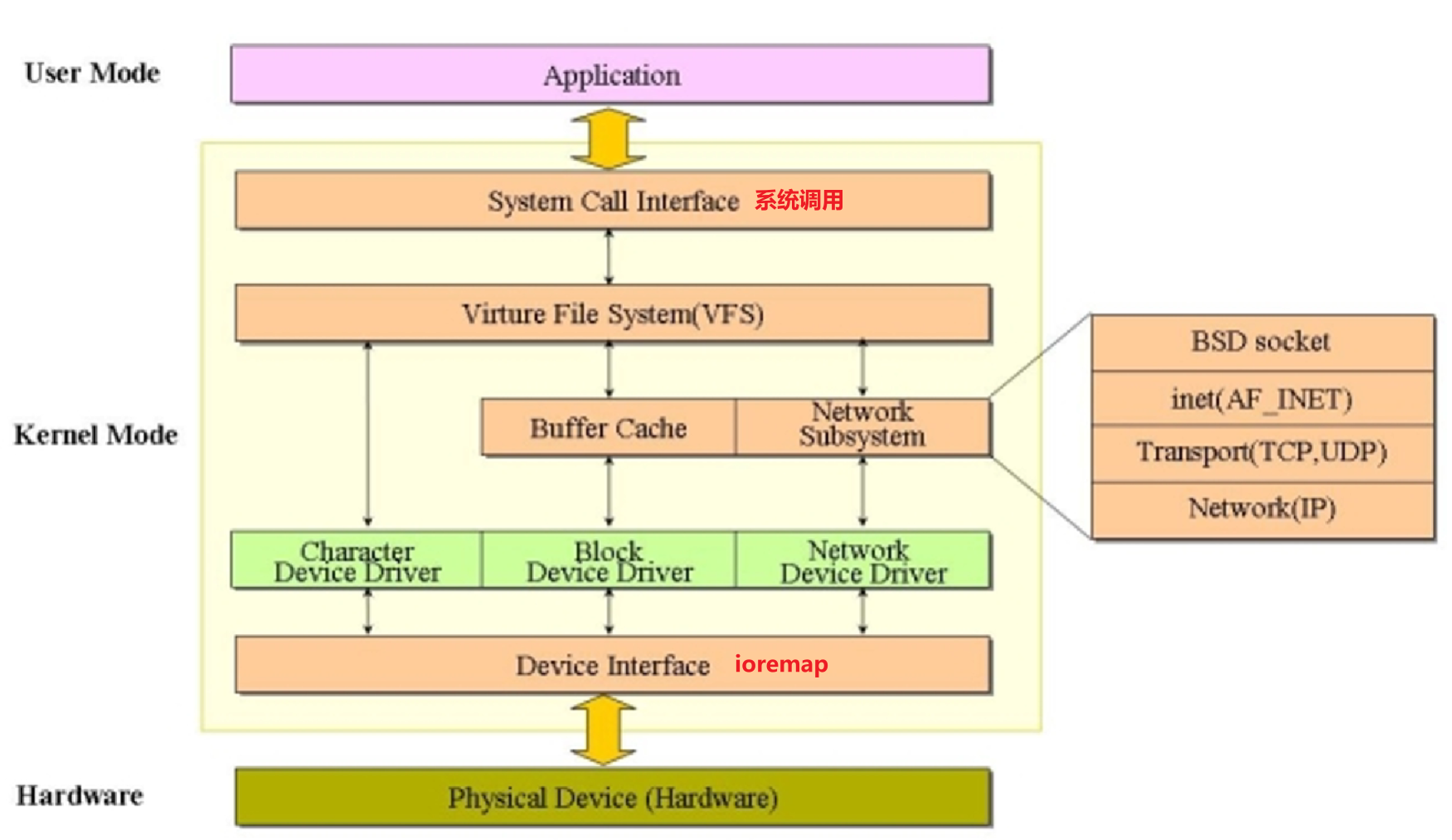
【嵌入式Linux内核驱动】02_字符设备驱动
字符设备驱动 〇、基本知识 设备驱动分类 (按共性分类方便管理) 1.字符设备驱动 字符设备指那些必须按字节流传输,以串行顺序依次进行访问的设备。它们是我们日常最常见的驱动了,像鼠标、键盘、打印机、触摸屏,还有…...

【零散整理】
1-1 git查看代码的项目总行数 git log --prettytformat: --numstat | awk ‘{ add $1; subs $2; loc $1 - $2 } END { printf “added lines: %s, removed lines: %s, total lines: %s\n”, add, subs, loc }’ - 1-2 cookie const cookies document.cookie.split(; )for…...
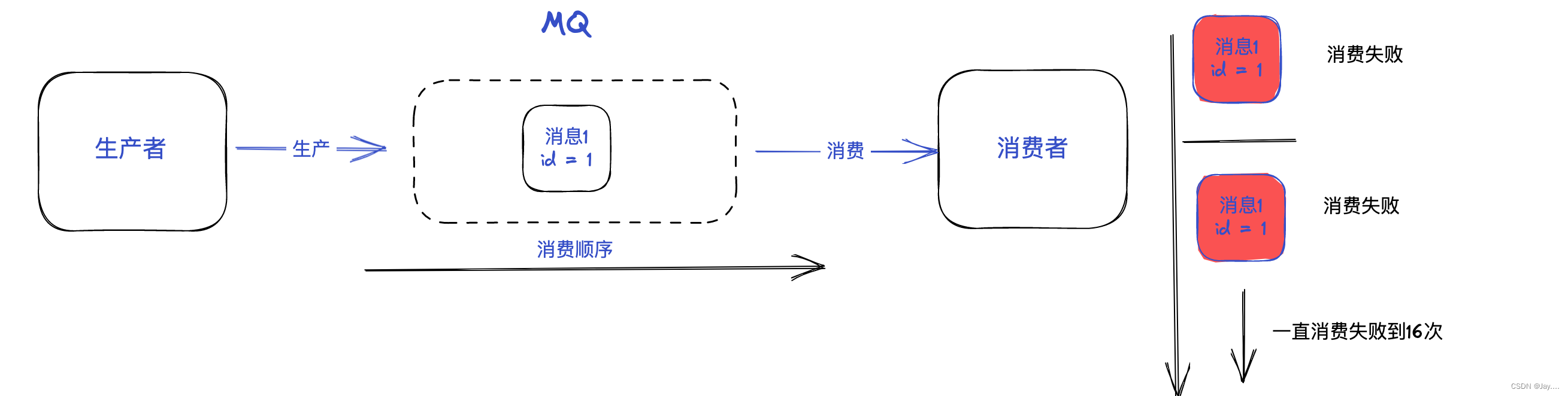
RocketMQ重复消费的症状以及解决方案
RocketMQ重复消费的症状以及解决方案 生产消息时重复 症状 当一条消息已被成功发送到 消费者 并完成持久化,此时出现了网络闪断或者客户端宕机,导致服务端对客户端应答失败。 如果此时 生产者 意识到消息发送失败并尝试再次发送消息,消费者…...
数字化时代,企业的商业模式建设
随着新一代信息化、数字化技术的应用,众多领域通过科技革命和产业革命实现了深度化的数字改造,进入到以数据为核心驱动力的,全新的数据处理时代,并通过业务系统、商业智能BI等数字化技术和应用实现了数据价值,从数字经…...
项目实战典型案例23——-注册上nacos上的部分服务总是出现频繁掉线的情况
注册上nacos上的部分服务总是出现频繁掉线的情况一:背景介绍二:思路&方案解决问题过程涉及到的知识nacos服务注册和服务发现一:背景介绍 spring cloud项目通过nacos作为服务中心和配置中心,出现的问题是其中几个服务总是出现…...
玩转金山文档 3分钟让你的文档智能化
在上个月底,我们给大家推荐了金山轻维表的几个使用场景,社群中不少用户反响很好,对其中一些场景的解决方案十分感兴趣。但也有一些人表示,有些场景不知道如何实现,希望我们能提供模版/教程。这次我们将做一期热门模板盘…...
)
Win10下CUDA 11.7和PyTorch保姆级安装避坑指南(含Anaconda换源与驱动检查)
Win10深度学习环境配置全攻略:从CUDA到PyTorch的零失败实践 刚接触深度学习的新手往往在第一步——环境配置上就遭遇重重阻碍。驱动版本混乱、下载速度缓慢、环境变量缺失、版本兼容性问题……这些看似简单的步骤背后隐藏着无数可能让初学者崩溃的"坑"。本…...

开发AI Agent时如何通过Taotoken灵活调度不同模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发AI Agent时如何通过Taotoken灵活调度不同模型 在构建复杂的AI Agent系统时,一个常见的需求是根据不同的任务类型&a…...

如何快速掌握AMD处理器调试工具:从新手到专家的完整指南
如何快速掌握AMD处理器调试工具:从新手到专家的完整指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://…...

开源AI代码助手Codetie:本地部署、模型自选与实战调优指南
1. 项目概述:一个面向开发者的AI代码伴侣最近在GitHub上看到一个挺有意思的项目,叫codetie-ai/codetie。乍一看名字,可能以为是某个新的编程语言或者框架,但深入了解后,发现它的定位非常精准:一个开源的、本…...

2026 电钢琴选购核心:三踏板 + 全配重,3 个价位段精准推荐
很多新手选琴总陷入两难:同价位,选大牌溢价还是高配置实用款?同配置,选便携易收纳还是立式强共鸣?其实选琴逻辑很简单:同价比配置、同配看价格,核心锁定三踏板、全配重、高复音数三大刚需&#…...

03-eMMC性能实战解析:速率模式、引脚配置与上电时序的协同设计
1. eMMC高速模式实战:HS400与HS200的带宽对决 在嵌入式系统设计中,eMMC存储的性能直接影响设备响应速度和用户体验。实测数据显示,三星KLMCG2KETM-B041芯片在HS400模式下能达到269.4MB/s的读取速度,而东芝THGBMDG5D1LBAIL同模式下…...

2026营销策划岗位怎么提升个人能力水平:从创意执行到策略操盘
流量碎片化、用户圈层化、渠道多元化,靠灵感和经验吃饭的时代正在过去。那些只会讲创意、不懂数据验证的策划人,正在逐渐失去话语权;而能用数据驱动策略、用效果证明价值的营销策划专家,却成为各大品牌争抢的对象。今天这篇文章&a…...

基于meta-kb构建智能知识库:从文档向量化到RAG应用实战
1. 项目概述与核心价值最近在折腾个人知识库和AI应用落地的朋友,应该都绕不开一个核心问题:如何把散落在各处的文档、笔记、网页内容,高效地组织成一个能被大语言模型(LLM)理解和利用的“知识大脑”?这不仅…...

算法札记——5.14
今天记录一道有难度的链表题——148. 排序链表 - 力扣(LeetCode) 题目要求是让我们对一个链表进行排序,首先可以想到的最简单的思路就是,将所有的节点存储到一个数组,然后数组以node->val排序,最后遍历数…...

开源集成利器OpenClaw:深度连接Bitrix24与外部系统的PHP解决方案
1. 项目概述:一个为Bitrix24量身定制的开源集成利器如果你正在使用Bitrix24,并且对它的某些功能限制感到束手束脚,或者你厌倦了在不同系统间手动搬运数据的繁琐,那么你很可能已经意识到,一个强大的集成工具是多么必要。…...