理解Es的DSL语法(二):聚合
前一篇已经系统介绍过查询语法,详细可直接看上一篇文章(理解DSL语法(一)),本篇主要介绍DSL中的另一部分:聚合
理解Es中的聚合
虽然Elasticsearch 是一个基于 Lucene 的搜索引擎,但也提供了聚合(aggregations)的功能,允许用户对数据进行统计和分析。聚合可以按照不同的维度对数据进行分组和汇总,从而得到有意义的统计信息。这也是Es很多场景下被当作分析工具使用的原因。
聚合语法
使用上来讲,es的聚合就相当于SQL中的group by,在DSL中主要使用aggs关键字和size关键字来控制:
{"size":0,"aggs":{"TestName":{ //自定义的聚合名称"term":{ //聚合类型关键字,根据聚合类型来"field":"title" //需要聚合的字段}}}
}这里着重说一下size关键字,如果单纯进行聚合,而不需要实际数据,最好这里size设置为0,设置size为0在进行聚合时,会默认触发Es的缓存机制,能够很有效的提升性能。
当然聚合也可以搭配查询query使用,即对查询的数据进行聚合,例如我们对最近一天的文章,聚合一下标题:
{"query":{"bool":{"filter":[{"range":{ "create_time":{"gte":"now - 1d","lte":"now"}}}]}}"size":0,"aggs":{"TestName":{ //自定义的聚合名称"term":{ //聚合类型关键字,根据聚合类型来"field":"title" //需要聚合的字段}}}
}这里Es收到请求后,会先根据query中的条件去检索满足创建时间在近一天内的所有文档,然后对这些文档进行桶聚合,以title字段为桶,将title内容一致的文档放入桶内。
聚合的种类
总的来看,Es的聚合可以分为四类,即Bucketing Aggregations、Metric Aggregations、Matrix Aggregations、Pipeline Aggregations。

Bucketing Aggregations
将数据分桶,类似于 SQL 中的 GROUP BY。例如,可以根据某个字段的不同值将数据分组,然后对每个分组进行统计,对于字段和内容都有一定的限制。
常用的聚合关键字有:
| 关键字 | 描述 | 适用字段类型 |
| Terms | Terms 聚合根据指定字段的确切值将文档分组。它类似于 SQL 中的 GROUP BY 语句。 | keyword |
| Histogram | 直方图聚合将数值字段划分为指定间隔的桶,并计算每个桶中的文档数量。 | 数值类型(
|
| Date Histogram | 日期直方图聚合类似于直方图聚合,但它专门用于日期字段,允许你根据时间间隔(如天、周、月等)来分组数据 | date |
| Range | 范围聚合允许你根据指定的范围将数据分组,每个范围定义了上界和下界。 | 数值类型 (
|
| IP Range | IP 范围聚合允许你根据 IP 地址的范围将数据分组。 | ip |
| Date Range | 日期范围聚合是范围聚合的日期版本,专门用于日期字段。 | date |
| Filter/Filters | 过滤器聚合根据一个或多个过滤器条件将数据分组,每个过滤器条件定义了一个桶。 | 可以应用于任何类型的字段,但通常与布尔查询结合使用来定义过滤器条件。 |
| Nested | 嵌套聚合应用于嵌套字段,它允许你根据嵌套对象中的字段值对嵌套文档进行分组。 | object或nested |
详细的可查阅ElasticSearch的官网,这里仅列出常用的,我们假设Es中存在以下一个数据集合:
[{"name": "Book A", "category": "Fiction", "price": 9.99, "publish_date": "2020-01-01"},{"name": "Book B", "category": "Science", "price": 15.00, "publish_date": "2021-06-15"},{"name": "Book C", "category": "Fiction", "price": 12.50, "publish_date": "2022-03-10"},{"name": "Book D", "category": "Education", "price": 8.50, "publish_date": "2019-09-20"},{"name": "Book E", "category": "Science", "price": 20.00, "publish_date": "2023-01-05"}
]并针对该数据集,进行相关的聚合样例:
Terms Aggregation聚合
查看有多少种category以及每种的文档数量。
示例:
{"size":0,"aggs": {"genres": {"terms": {"field": "category" // genre必须为keyword类型"size":3 //根据文档数量倒叙展示条数,默认不填写则仅展示10个}}}
}//输出:
{"category": {"buckets": [{"key": "Fiction", "doc_count": 2},{"key": "Science", "doc_count": 2},{"key": "Education", "doc_count": 1}]}
}Histogram Aggregation 聚合
按价格区间聚合书籍
{"size":0,"aggs": {"price_distribution": {"histogram": {"field": "price","interval": 5 //以5元为一个段}}}
}//输出:
{"aggregations": {"price_distribution": {"buckets": [{ "key": 5, "doc_count": 1 },{ "key": 10, "doc_count": 2 },{ "key": 15, "doc_count": 2 }]}}
}Date Histogram Aggregation 聚合
按年份查看出版书籍的数量
{"size":0,"aggs": {"books_over_time": {"date_histogram": {"field": "publish_date","calendar_interval": "year" //查询区间可以指定单位}}}
}//输出{"aggregations": {"books_over_time": {"buckets": [{ "key_as_string": "2019", "doc_count": 1 },{ "key_as_string": "2020", "doc_count": 1 },{ "key_as_string": "2021", "doc_count": 1 },{ "key_as_string": "2022", "doc_count": 1 },{ "key_as_string": "2023", "doc_count": 1 }]}}
}其中对于date_histogram使用较多,这里单独列一下关于date_histogram的相关参数
-
calendar_interval:按照日历时间间隔(如年、季度、月、周、日等)来创建桶。
-
fixed_interval:按照固定时间间隔(如1小时、5分钟等)来创建桶,不考虑日历界限。
-
min_doc_count:设置为 0 或更大的值,以忽略那些文档计数小于该值的桶。
-
extended_bounds:允许聚合查询返回超出正常查询范围之外的桶,例如在直方图的开始或结束之前添加额外的桶。
-
order:指定桶的排序方式,可以是
asc(升序)或desc(降序)。 -
format:自定义日期格式,用于指定桶的 key 值的日期格式。
-
time_zone:指定时区来应用到聚合上,特别是对于固定间隔的聚合。
-
pre_zone 和 post_zone:与
extended_bounds结合使用,指定额外桶的时区。
{"size": 0,"aggs": {"publish_monthly": {"date_histogram": {"field": "publish_date","calendar_interval": "month", // 每月一个桶"min_doc_count": 1, // 只包括至少有一个文档的桶"extended_bounds": {"min": "2019-01-01","max": "2023-12-31"}, // 设置聚合的最小和最大界限"order": "desc", // 桶按降序排序"format": "yyyy-MM", // 桶 key 的格式"time_zone": "Europe/Berlin" // 使用柏林时区}}}
}Range Aggregation聚合
查看价格区间内书籍的数量
{"size":0,"aggs": {"price_ranges": {"range": {"field": "price","ranges": [{ "from": 0, "to": 10 },{ "from": 10, "to": 20 }]}}}
}//输出
{"aggregations": {"price_ranges": {"buckets": [{ "from": 0, "to": 10, "doc_count": 2 },{ "from": 10, "to": 20, "doc_count": 3 }]}}
}Filters Aggregation聚合
同时筛选 Fiction 和 Science 类别的书籍,并分别计算数量。
{"size":0,"aggs": {"category_filters": {"filters": {"filters": {"Fiction": {"term": {"category.keyword": "Fiction"}},"Science": {"term": {"category.keyword": "Science"}}}}}}
}
//输出
{"aggregations": {"category_filters": {"buckets": {"Fiction": { "doc_count": 2 },"Science": { "doc_count": 2 }}}}
}这里特殊说明一下,针对以上场景,也可以使用:
{"query": {"bool": {"filter": [{"terms": {"category": ["Fiction", "Science"]}}]}},"size": 0,"aggs": {"category": {"terms": {"field": "category"}}}
}不同的是,使用这种聚合,Es的需要进行两次操作,即:先根据query条件,进行数据查询,再对查询结果进行聚合,而Filters聚合则只有一次操作。在相同场景下,考虑性能的话,使用 filters 聚合可能在某些情况下更有效率,因为它可以利用 Elasticsearch 的缓存机制,特别是当这些特定的过滤条件经常被查询时。
Composite Aggregation聚合
按 category 和 publish_date 的每个月份组合聚合书籍。
{"size": 0,"aggs": {"category_date_composite": {"composite": {"sources": [{ "category": { "terms": { "field": "category.keyword" } } },{ "date": { "date_histogram": { "field": "publish_date", "calendar_interval": "month" } } }],"size": 10}}}
}
//输出
{"composite_of_category_and_date": {"buckets": [{"key": {"category": "Fiction", "date": "2020-01"}, "doc_count": 1},{"key": {"category": "Fiction", "date": "2022-03"}, "doc_count": 1},{"key": {"category": "Science", "date": "2021-06"}, "doc_count": 1},{"key": {"category": "Science", "date": "2023-01"}, "doc_count": 1}]}
}Metric Aggregations
对数据进行数学运算,如计算平均值、总和、最小值、最大值等。此类大多对数字类型的字段进行聚合。
| 关键字 | 描述 |
| Sum Aggregation | 计算数值字段的总和 |
| Avg Aggregation | 计算数值字段的平均值 |
| Min Aggregation | 找出数值字段中的最小值 |
| Max Aggregation | 找出数值字段中的最大值 |
| Stats Aggregation | 返回字段的多个统计度量,包括最小值、最大值、平均值和总和。 |
| Cardinality Aggregation | 计算字段中唯一值的近似数量,对于大数据集非常有用,因为它比value_count更高效。 |
一般配合桶查询使用,对标的是SQL中的SUM、MAX等数学函数
Cardinality Aggregation
查看一共有多少文档:
{"size":0,"aggs": {"countALl": {"cardinality": {"field": "_id"}}}
}//输出
{"aggregations": {"countALl": {"value": 3}}
}Min/Max Aggregation
//查看书籍最贵的价格
{"size":0,"aggs": {"maximum_price": {"max": {"field": "price"}}}
}
//输出:
{"aggregations": {"maximum_price": {"value": 20.0}}
}//查看书籍最便宜的价格
{"size":0,"aggs": {"min_price": {"min": {"field": "price"}}}
}
//输出
//输出:
{"aggregations": {"min_price": {"value": 5.0}}
}
Sum/Avg Aggregation
//对库内书籍价格求和
{"aggs": {"all_price": {"sum": {"field": "price"}}}
}//输出:
{"aggregations": {"all_price": {"value": 13.398}}
}//对库内书籍价格求均值
{"aggs": {"average_price": {"avg": {"field": "price"}}}
}//输出
{"aggregations": {"average_price": {"value": 13.398}}
}Stats Aggregation
查看价格的综合统计
{"size":0,"aggs": {"price_stats": {"stats": {"field": "price"}}}
}//输出:
{"aggregations": {"price_stats": {"count": 5,"min": 8.5,"max": 20.0,"avg": 13.398,"sum": 66.99}}
}聚合嵌套
语法格式为:
{"size":0,"aggs":{"One":{ // 一层桶名称"terms":{"field":"fielda"},"aggs":{ //一层桶下二层聚合} }}
}以书籍书籍为例,查看每类书籍的平均价格,则可以先对书籍类型进行terms聚合,再在terms桶内,获取桶内书籍的平均价格:
//DSL
{"size": 0,"aggs": {"categories": {"terms": {"field": "keyword"},"aggs": {"average_price": {"avg": {"field": "price"}}}}}
}//输出结果
{"aggregations": {"categories": {"buckets": [{"key": "Fiction","doc_count": 2,"average_price": {"value": 11.245}},{"key": "Science","doc_count": 2,"average_price": {"value": 17.5}},{"key": "Education","doc_count": 1,"average_price": {"value": 8.5}}]}}
}也可以查看发布年限,每年里发布书籍的总价格:
{"size": 0,"aggs": {"publish_years": {"date_histogram": {"field": "publish_date","calendar_interval": "year"},"aggs": {"total_price": {"sum": {"field": "price"}}}}}
}//输出
{"aggregations": {"publish_years": {"buckets": [{"key_as_string": "2019","key": 1577836800000,"doc_count": 1,"total_price": {"value": 8.5}},{"key_as_string": "2020","key": 1609459200000,"doc_count": 1,"total_price": {"value": 9.99}},{"key_as_string": "2021","key": 1609459200000,"doc_count": 1,"total_price": {"value": 15.0}},{"key_as_string": "2022","key": 1640995200000,"doc_count": 1,"total_price": {"value": 12.5}},{"key_as_string": "2023","key": 1672531200000,"doc_count": 1,"total_price": {"value": 20.0}}]}}
}相关文章:
理解Es的DSL语法(二):聚合
前一篇已经系统介绍过查询语法,详细可直接看上一篇文章(理解DSL语法(一)),本篇主要介绍DSL中的另一部分:聚合 理解Es中的聚合 虽然Elasticsearch 是一个基于 Lucene 的搜索引擎,但…...
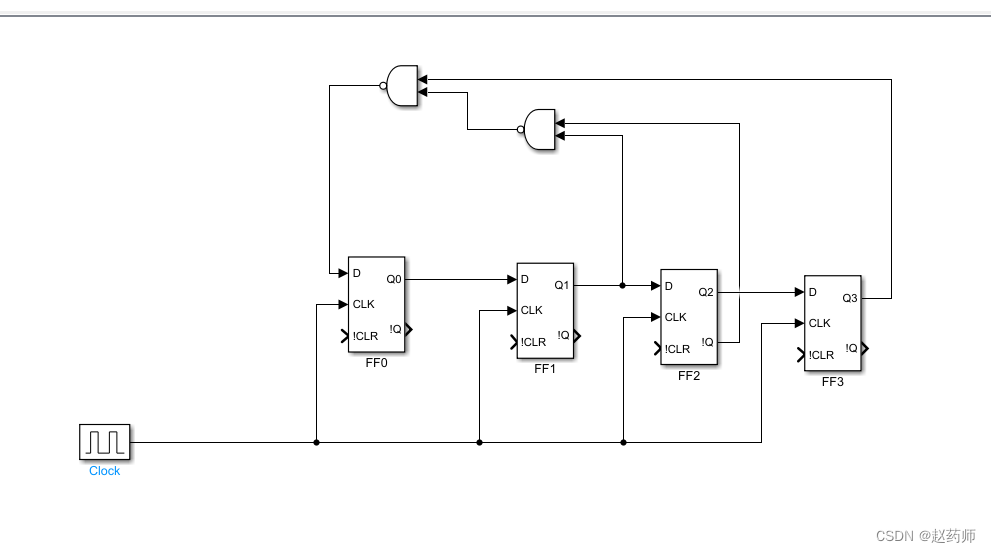
matlab-2-simulink-小白教程-如何绘制电路图进行电路仿真
以上述电路图为例:包含D触发器,时钟CLK,与非门 一、启动simulink的三种方式 方式1 在MATLAB的命令行窗口输入“Simulink”命令。 方式2 在MATLAB主窗口的“主页”选项卡中,单击“SIMULINK”命令组中的Simulink命令按钮。 方式3 从MATLAB…...

CSS从入门到精通——背景样式
目录 背景颜色 任务描述 相关知识 背景色 编程要求 背景图片 任务描述 相关知识 背景图片 设置背景图片 平铺背景图像 任务要求 背景定位与背景关联 任务描述 相关知识 背景定位 背景关联 简写背景 编程要求 背景颜色 任务描述 本关任务:在本关…...
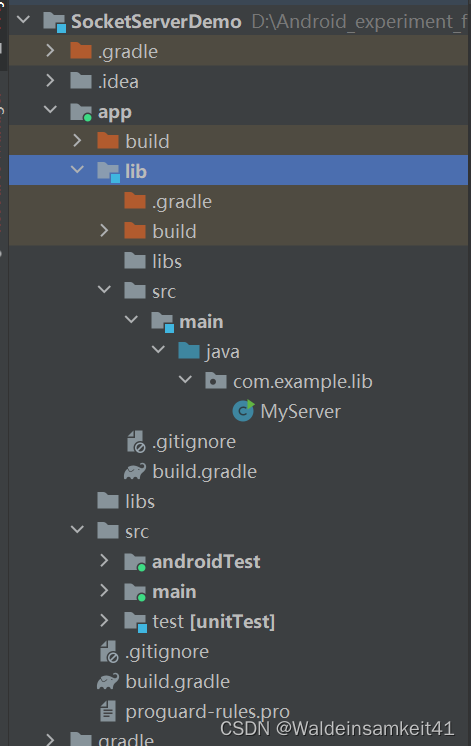
网络编程---Java飞机大战联机
解析服务器端代码 代码是放在app/lib下的src下的main/java,而与之前放在app/src/main下路径不同 Main函数 Main函数里只放着创建MyServer类的一行 public static void main(String args[]){new MyServer();} MyServer构造函数 1.获取本机IP地址 //获取本机IP地…...

一个简单的Oracle函数
CREATE OR REPLACE FUNCTION getyj_zhibiao_value(p_name IN varchar2, p_index IN varchar2) RETURN NUMBER IS -- 定义返回的指标值变量 v_result NUMBER; -- 定义临时变量来存储查询到的指标值 v_index1 VARCHAR2(50); v_index2 VARCHAR2(50); …...
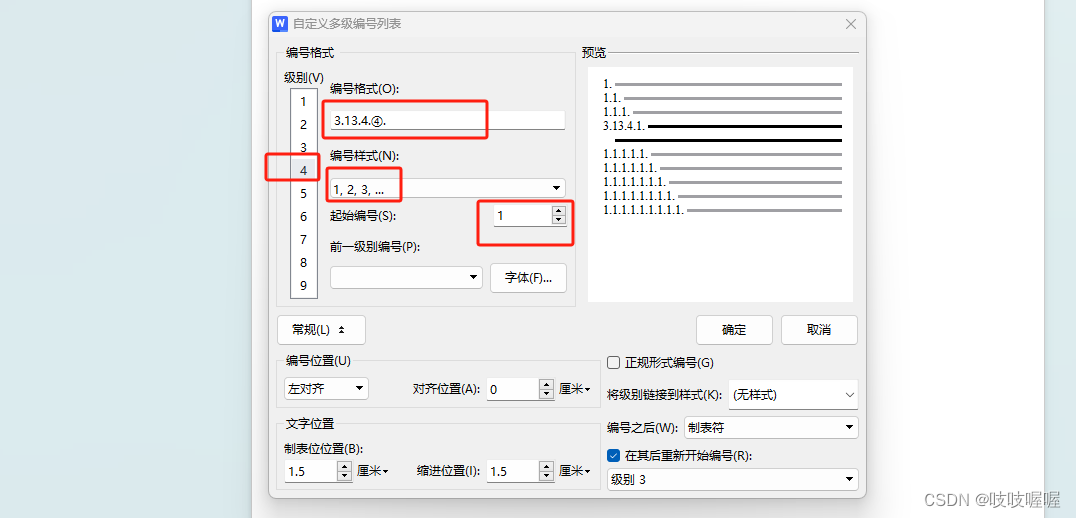
word中根据上级设置下级编号
如上级是3.13.4,如下图 现在想设置下级编码跟随上级逐级显示成3.13.4.1 则在标题功能说明这点击顶部菜单栏的编号按钮,如下图 然后,选择自定义编号-自定义列表-自定义按钮 然后重点是编号格式这一栏,需要手动填写下前三级的编号&…...

【康复学习--LeetCode每日一题】2786. 访问数组中的位置使分数最大
题目描述: 给你一个下标从 0 开始的整数数组 nums 和一个正整数 x 。 你一开始 在数组的位置 0 处,你可以按照下述规则访问数组中的其他位置: 如果你当前在位置 i ,那么你可以移动到满足 i < j 的 任意 位置 j 。 对于你访问的…...

bash和sh区别
bash 和 sh 是两种常用的 Unix Shell,它们有一些区别,特别是在功能和兼容性方面。以下是一些主要的区别: 1. **历史与实现**: - sh(Bourne Shell)是第一个 Unix Shell,最初由 Stephen Bourn…...
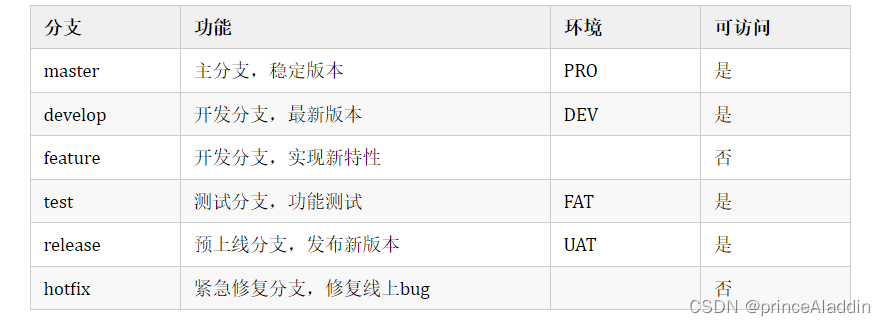
Git 代码管理规范 !
分支命名 master 分支 master 为主分支,也是用于部署生产环境的分支,需要确保master分支稳定性。master 分支一般由 release 以及 hotfix 分支合并,任何时间都不能直接修改代码。 develop 分支 develop 为开发环境分支,始终保持最…...

MGRS坐标
一 概述 MGRS坐标系统,即军事格网参考系统,是北约(NATO)军事组织使用的标准坐标系统。它基于UTM(通用横向墨卡托)系统,并将每个UTM区域进一步划分为100km100km的小方块。这些方块通过两个相连的字母标识,其…...

FreeRTOS简单内核实现4 临界段
文章目录 0、思考与回答0.1、思考一0.2、思考二0.3、思考三 1、关中断1.1、带返回值1.2、不带返回值 2、开中断3、临界段4、应用 0、思考与回答 0.1、思考一 为什么需要临界段? 有时候我们需要部分代码一旦这开始执行,则不允许任何中断打断࿰…...

Scala的字符串插值
Scala的字符串插值 期待您的关注 ☀Scala学习笔记 目录 Scala的字符串插值 1. s插值器: 2. f插值器: 3. raw插值器: 在Scala中,字符串插值是一种方便的方式,可以在字符串中插入变量或表达式的值。Scala支持三种类型…...
EasyGBS服务器和终端配置
服务器配置 修改easygbs.ini sip/host为本机IP,否则终端能登录,无法视频。 [sip] host192.168.3.190 终端用于登录的用户名和密码 default_usertest default_passwordtest1234 default_guest_userguest default_guest_passwordtest1234终端配置 关…...

git配置2-不同的代码托管平台配置不同的ssh key
1. 配置单个ssh key 1.1. 原理1.2. 生成 ssh key1.3. 代码托管平台配置公钥 2. 配置多个ssh key 2.1. 应用场景2.2. 生成两个不同的key2.3. 修改config文件2.4. 配置代码托管平台2.5. 测试是否成功 1. 配置单个ssh key 1.1. 原理 使用ssh命令行工具(git安装成功…...

【CT】LeetCode手撕—102. 二叉树的层序遍历
目录 题目1-思路2- 实现⭐102. 二叉树的层序遍历——题解思路 3- ACM实现3-1 二叉树构造3-2 整体实现 题目 原题连接:102. 二叉树的层序遍历 1-思路 1.借助队列 Queue ,每次利用 ①while 循环遍历当前层结点,②将当前层结点的下层结点放入 …...

Flink 命令行提交、展示和取消作业
Apache Flink 是一个流处理和批处理的开源框架,用于在分布式环境中执行无边界和有边界的数据流。你可以使用 Flink 的命令行界面(CLI)来提交、展示和取消作业。 提交作业 使用 Flink CLI 提交作业的命令格式通常如下: ./bin/fl…...

STM32单片机选型方法
一.STM32单片机选型方法 1.首先要确定需求: 性能需求:根据应用的复杂度和性能要求,选择合适的CPU性能和主频。 内存需求:确定所需的内存大小,包括RAM和Flash存储空间。 外设需求:根据应用所需的功能&…...

gsap动画库的实践
先看效果: gsap动画库 安装插件:npm install gsap <template><div><h1 style"text-align: left">gsap的用法</h1><h1 style"text-align: left">https://gsap.com/resources/get-started</h1>&…...
LeetCode | 387.字符串中的第一个唯一字符
这道题可以用字典解决,只需要2次遍历字符串,第一次遍历字符串,记录每个字符出现的次数,第二次返回第一个出现次数为1的字符的下标,若找不到则返回-1 class Solution(object):def firstUniqChar(self, s):""…...

textarea 中的内容在word中显示换行不起作用
js文本换行在word显示 在JavaScript中,处理文本换行以确保它在Word中正确显示,通常需要将文本中的换行符转换为Word可识别的格式。在HTML中,换行通常是通过<br>标签来实现的,而在Word中,换行通常由段落标签<…...

Anthropic 百万行代码库的官方最佳实践
随着AI 编程智能体的越来越深入到日常工作,相信你也遇到了大型项目和和小型代码库完全不同的场景。正好最近也是在做大型项目的重构开发,刷到这篇来自 Anthropic 官方的文章。系统梳理了 Claude Code 在大规模代码库中的运作机制、Harness 架构的七个扩展…...

抖音无水印视频下载神器:3分钟快速上手,轻松保存高清无水印视频
抖音无水印视频下载神器:3分钟快速上手,轻松保存高清无水印视频 【免费下载链接】douyin_downloader 抖音短视频无水印下载 win编译版本下载:https://www.lanzous.com/i9za5od 项目地址: https://gitcode.com/gh_mirrors/dou/douyin_downlo…...
)
告别手动抢红包!用Kotlin写一个Android微信红包监听助手(附完整代码)
用Kotlin构建Android微信红包自动化工具:从原理到避坑指南 春节聚会时,你是否曾因低头抢红包错过亲友的精彩对话?工作群里的手气红包总在分神时一闪而过?作为一名Android开发者,其实可以用技术优雅解决这些烦恼。本文…...

基于Slack与AI的IDE智能助手:架构设计与实战部署
1. 项目概述:当你的IDE拥有了“光标智能体” 如果你是一名开发者,每天在IDE(集成开发环境)里敲代码的时间超过8小时,那你一定对这样的场景不陌生:光标在代码行间跳跃,你正试图理解一个复杂的函…...

WarcraftHelper终极指南:魔兽争霸3优化工具完整教程
WarcraftHelper终极指南:魔兽争霸3优化工具完整教程 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸III》的陈旧限制而烦…...

MPLAB® Harmony嵌入式框架实战:从架构解析到项目开发避坑指南
1. 项目概述:从零到一,理解MPLAB Harmony的价值如果你是一位嵌入式开发者,尤其是长期与Microchip的PIC或SAM系列MCU打交道的朋友,那么“MPLAB Harmony”这个名字你一定不陌生。它可能出现在官方文档的角落里,在论坛的讨…...

GitHub仓库自动化同步工具xpull:原理、配置与实战应用
1. 项目概述:一个被低估的GitHub数据同步利器 如果你经常在GitHub上管理多个仓库,或者需要将某个仓库的特定分支、标签甚至整个提交历史同步到另一个仓库,那么你很可能经历过手动操作的繁琐。无论是为了备份、镜像、还是将上游的更新合并到自…...

微软UFO项目:基于视觉大模型的GUI自动化智能体实战解析
1. 项目概述:当“全能”AI助手遇见复杂任务编排 最近在AI应用开发圈里,一个来自微软研究院的项目“UFO”引起了我的注意。这名字听起来挺科幻,全称是“UI-Focused Agent”,直译过来是“专注于用户界面的智能体”。但别被这个直白的…...

基于ESP32-S3与CircuitPython的NASA小行星追踪器项目实践
1. 项目概述:一个会“说话”的太空瞭望台如果你对头顶那片星空既充满好奇又带有一丝敬畏,想知道是否有“天外来客”正悄无声息地接近我们,那么这个项目就是为你准备的。这不是一个简单的数据看板,而是一个亲手搭建的、能实时“对话…...

【NotebookLM移动端避坑白皮书】:上线首月超12万用户踩中的3类权限陷阱与2种文档同步丢失根因分析
更多请点击: https://intelliparadigm.com 第一章:NotebookLM移动端避坑白皮书导论 NotebookLM 是 Google 推出的基于用户上传文档构建个性化 AI 助手的实验性工具,其移动端(iOS/Android)虽提供便捷访问入口ÿ…...