2024 年最新 Python 调用 OpenAi 详细教程实现问答、图像合成、图像理解、语音合成、语音识别(详细教程)
OpenAi 环境安装
首先确保您的计算机上已经安装了 Python。您可以从 Python 官方网站下载并安装最新版本 Python。安装时,请确保勾选 “Add Python to PATH” (添加环境变量)选项,以便在 cmd 命令行中直接使用 Python。
安装 OpenAI Python 库
打开命令行或终端窗口安装 OpenAI Python 库
pip install openai
OpenAi Platform 教程
平台官网:https://platform.openai.com/
http API 调用方式文档:https://platform.openai.com/docs/api-reference/introduction
文本生成 GPT-4
GPT-4 模型概述
GPT-4是一个大型多模态模型(接受文本或图像输入和输出文本),由于其更广泛的一般知识和先进的推理能力,它可以比我们以前的任何模型都更准确地解决难题。付费客户可以在OpenAI API中使用GPT-4。与gpt-3.5 turbo一样,GPT-4针对聊天功能进行了优化,但在使用聊天完井API的传统完井任务中表现良好。在我们的文本生成指南中学习如何使用GPT-4。
测试案例
聊天模型将消息列表作为输入,并返回模型生成的消息作为输出。虽然聊天格式的设计是为了使多回合的对话变得容易,但它对于没有任何对话的单回合任务同样有用。
一个聊天完成API调用的例子如下:
from openai import OpenAI
client = OpenAI()response = client.chat.completions.create(model="gpt-4",messages=[{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Who won the world series in 2020?"},{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},{"role": "user", "content": "Where was it played?"}]
)print(response)
数据结构
{"choices": [{"finish_reason": "stop","index": 0,"message": {"content": "The 2020 World Series was played in Texas at Globe Life Field in Arlington.","role": "assistant"},"logprobs": null}],"created": 1677664795,"id": "chatcmpl-7QyqpwdfhqwajicIEznoc6Q47XAyW","model": "gpt-3.5-turbo-0613","object": "chat.completion","usage": {"completion_tokens": 17,"prompt_tokens": 57,"total_tokens": 74}
}
图像合成 DALL·E
DALL·E 模型概述
DALL·E是一个人工智能系统,可以通过自然语言的描述创造逼真的图像和艺术。DALL·e3目前支持在提示下创建具有特定大小的新映像的功能。DALL·e2还支持编辑现有映像,或创建用户提供的映像的变体。
测试案例
图像生成端点允许您在给定文本提示的情况下创建原始图像。当使用DALL·e3时,图像的大小可以是1024x1024、1024x1792或1792x1024像素。
默认情况下,图像以标准质量生成,但当使用DALL·e3时,您可以将质量设置为“hd”以增强细节。正方形的、标准质量的图像是最快生成的。您可以使用DALL·e3一次请求1个图像(通过并行请求请求更多),或者使用带n参数的DALL·e2一次至多请求10个图像。
from openai import OpenAIclient = OpenAI()response = client.images.generate(model="dall-e-3",prompt="a white siamese cat",size="1024x1024",quality="standard",n=1,
)image_url = response.data[0].url
语音合成 TTS
TTS 模型概述
TTS是一种人工智能模型,可以将文本转换为自然发音的口语文本。我们提供了两种不同的模型变量,ts-1针对实时文本到语音的用例进行了优化,而ts-1-hd针对质量进行了优化。这些模型可以与Audio API中的Speech端点一起使用。
测试案例
语音端点接受三个关键输入:模型、应该转换为音频的文本和用于音频生成的语音。简单的请求如下所示:
from pathlib import Path
from openai import OpenAIclient = OpenAI()speech_file_path = Path(__file__).parent / "speech.mp3"
response = client.audio.speech.create(model="tts-1",voice="alloy",input="Today is a wonderful day to build something people love!"
)response.stream_to_file(speech_file_path)
音色选择
尝试不同的声音(alloy, echo, fable, onyx, nova, and shimmer),找到一个符合你想要的语气和听众。当前的声音是针对英语优化的。
语音识别 Whisper
Whisper 概述
Whisper 是一个通用的语音识别模型。它是在不同音频的大型数据集上训练的,也是一个多任务模型,可以执行多语言语音识别以及语音翻译和语言识别。Whisper v2大型模型目前可通过我们的API使用Whisper -1模型名称。
目前,Whisper的开源版本和通过我们的API提供的版本之间没有区别。然而,通过我们的API,我们提供了一个优化的推理过程,这使得通过我们的API运行Whisper比执行它要快得多。
测试案例
语音识别 API 将要识别的音频文件和所需的音频转录输出文件格式作为输入。我们目前支持多种输入和输出文件格式。文件上传目前限制为 25mb,支持 mp3、mp4、mpeg、mpga、m4a、wav、webm 等文件类型的输入。
from openai import OpenAIclient = OpenAI()audio_file = open("/path/to/file/audio.mp3", "rb")
transcription = client.audio.transcriptions.create(model="whisper-1",file=audio_file
)
print(transcription.text)
数据结构
{"text": "Imagine the wildest idea that you've ever had, and you're curious about how it might scale to something that's a 100, a 1,000 times bigger.
....
}
配置 OPENAI_API_KEY
查看 class OpenAI(SyncAPIClient) 类实现的源码片段发现,关于 api_key 和 base_url 会读取本地环境变量中 OPENAI_API_KEY 和 OPENAI_BASE_URL 变量。
if api_key is None:api_key = os.environ.get("OPENAI_API_KEY")
if api_key is None:raise OpenAIError("The api_key client option must be set either by passing api_key to the client or by setting the OPENAI_API_KEY environment variable")
self.api_key = api_key
if base_url is None:base_url = os.environ.get("OPENAI_BASE_URL")
if base_url is None:base_url = f"https://api.openai.com/v1"
dotenv 加载 .env 环境变量
dotenv是一个Python库(虽然也适用于其他编程语言,如JavaScript),它的主要功能是从.env文件中读取环境变量,并将这些变量加载到操作系统的环境变量中,使得Python应用程序可以轻松地访问这些变量。.env文件是一个纯文本文件,其中包含键值对(key-value pairs),每个键值对占据一行,格式为KEY=VALUE。
pip install python-dotenv
将敏感信息(如API密钥、数据库密码等)存储在环境变量中,而不是硬编码在代码中,是一种良好的安全实践。这样可以减少敏感信息泄露的风险,因为这些值不会存储在代码库中,也不会在部署时暴露出来。
在 Python 代码中,使用 python-dotenv 库加载 .env 文件,并访问其中的环境变量。这通常通过 from dotenv import load_dotenv 和 load_dotenv() 函数实现。访问环境变量:加载.env文件后,可以使用 os.getenv('KEY') 的方式访问环境变量。
from dotenv import load_dotenv
load_dotenv()
图像理解 GPT-4o
gpt - 40和GPT-4 Turbo都具有视觉功能,这意味着这些模型可以接收图像并回答有关图像的问题。从历史上看,语言模型系统一直受到单一输入形式文本的限制。
模型可以通过两种主要方式使用图像:通过传递到图像的链接或在请求中直接传递base64编码的图像。图像可以在用户消息中传递。
from openai import OpenAIclient = OpenAI()response = client.chat.completions.create(model="gpt-4o",messages=[{"role": "user","content": [{"type": "text", "text": "What’s in this image?"},{"type": "image_url","image_url": {"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg",},},],}],max_tokens=300,
)print(response.choices[0])
上传base64编码的图像如果你在本地有一张或一组图像,你可以将它们以base64编码的格式传递给模型,下面是一个实际的例子
import base64
import requestsapi_key = "YOUR_OPENAI_API_KEY"def encode_image(image_path):with open(image_path, "rb") as image_file:return base64.b64encode(image_file.read()).decode('utf-8')image_path = "path_to_your_image.jpg"base64_image = encode_image(image_path)headers = {"Content-Type": "application/json","Authorization": f"Bearer {api_key}"
}payload = {"model": "gpt-4o","messages": [{"role": "user","content": [{"type": "text","text": "What’s in this image?"},{"type": "image_url","image_url": {"url": f"data:image/jpeg;base64,{base64_image}"}}]}],"max_tokens": 300
}response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)print(response.json())
相关文章:
2024 年最新 Python 调用 OpenAi 详细教程实现问答、图像合成、图像理解、语音合成、语音识别(详细教程)
OpenAi 环境安装 首先确保您的计算机上已经安装了 Python。您可以从 Python 官方网站下载并安装最新版本 Python。安装时,请确保勾选 “Add Python to PATH” (添加环境变量)选项,以便在 cmd 命令行中直接使用 Python。 安装 Op…...

git原理解释,windows 10 / ubuntu 24.04 安装使用 github
git的原理 git是赫赫有名的Linux之父Linus Torvalds从2005年起开发的文件版本管理系统,掌控Linux内核这样一个最为重量级的世界产品的Linus为什么要开发这个东西呢?因为Linux系统由全世界的程序员协作维护,对源代码文件的版本控制管理的需求…...
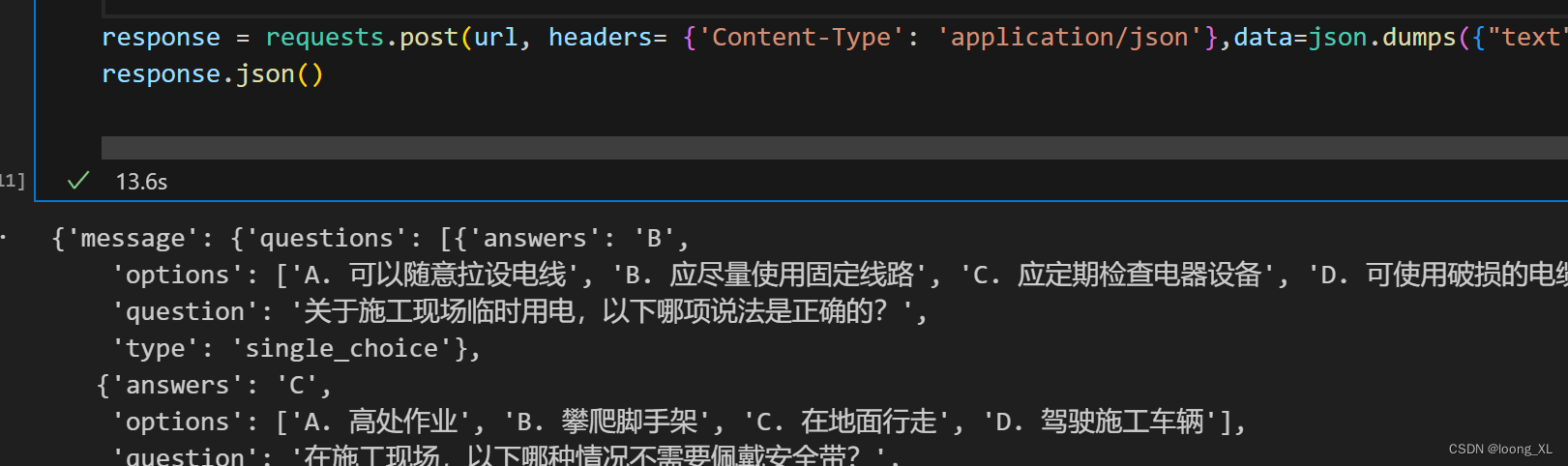
requests post json/data;requests response 接收不同数据
1、requests post json/data 在Python的requests库中,当你发送POST请求时,可以选择使用json参数或data参数来传递数据。这两者之间的主要区别在于它们如何被序列化和发送到服务器。 json参数: 当你使用json参数时,requests库会自…...
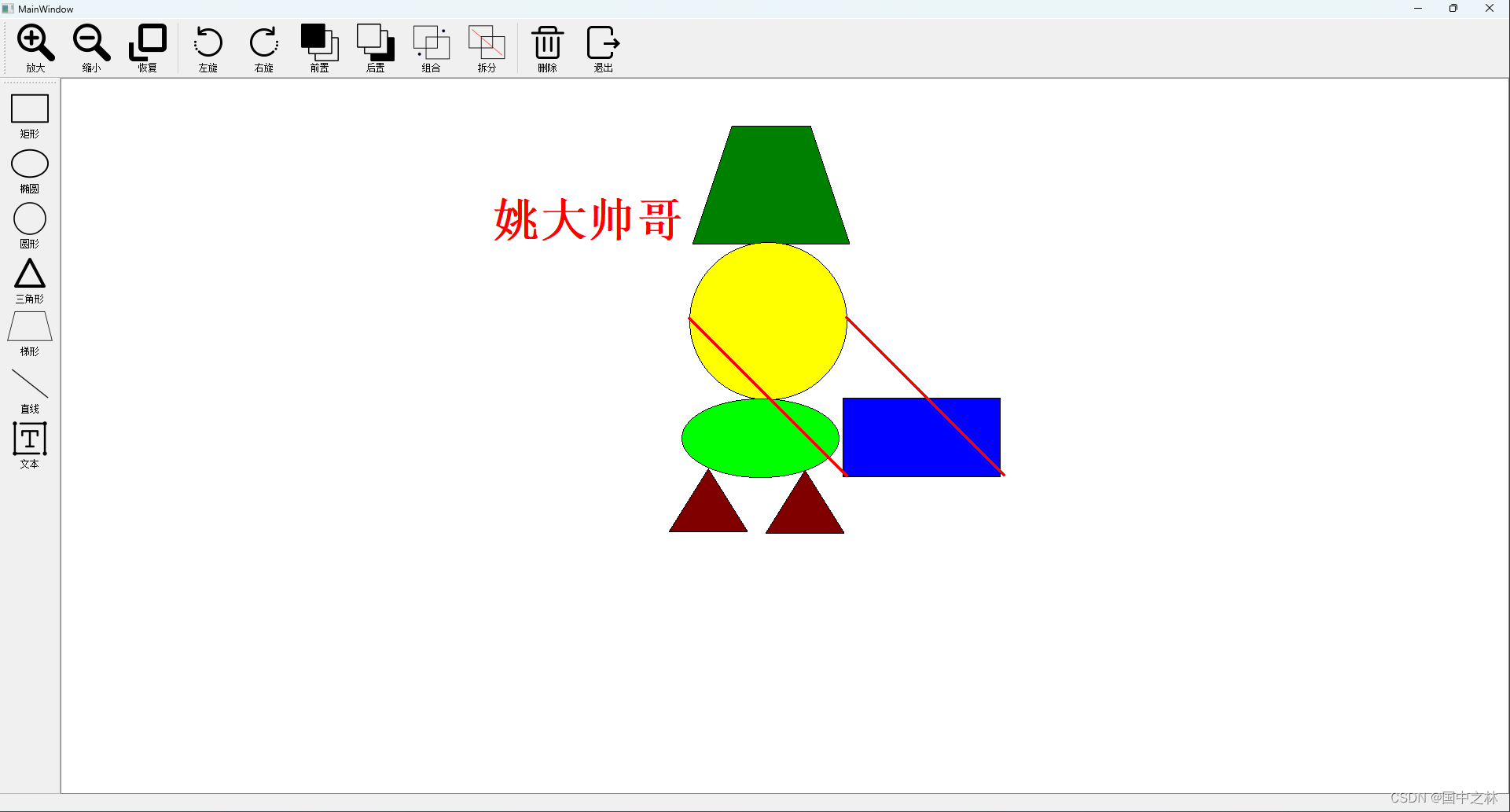
【qt】平面CAD(计算机辅助设计 )项目 上
CAD 一.前言二.界面设计三.提升类四.接受槽函数五.实现图形action1.矩形2.椭圆3.圆形4.三角形5.梯形6.直线7.文本 六.总结 一.前言 用我们上节课刚刚学过的GraphicsView架构来绘制一个可以交互的CAD项目! 效果图: 二.界面设计 添加2个工具栏 需要蔬菜的dd我! 添加action: …...

C++中bool类型的使用细节
C中bool类型的使用细节 ANSIISO C标准添加了一种名叫bool的新类型(对 C来说是新的)。它的名称来源于英国数学家 George Boole,是他开发了逻辑律的数学表示法。在计算中,布尔变量的值可以是true或false。过去,C和C一样,也没有布尔…...
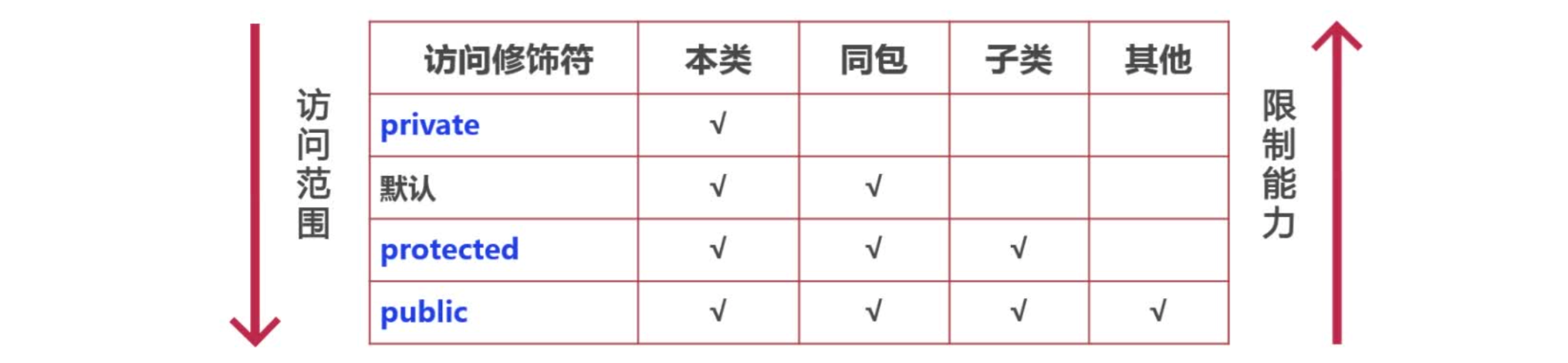
Java 面向对象 -- Java 语言的封装、继承、多态、内部类和 Object 类
大家好,我是栗筝i,这篇文章是我的 “栗筝i 的 Java 技术栈” 专栏的第 007 篇文章,在 “栗筝i 的 Java 技术栈” 这个专栏中我会持续为大家更新 Java 技术相关全套技术栈内容。专栏的主要目标是已经有一定 Java 开发经验,并希望进…...

【C++】和【预训练模型】实现【机器学习】【图像分类】的终极指南
目录 💗1. 准备工作和环境配置💕 💖安装OpenCV💕 💖安装Dlib💕 下载并编译TensorFlow C API💕 💗2. 下载和配置预训练模型💕 💖2.1 下载预训练的ResNet…...

HTML5 Web SQL数据库:浏览器中的轻量级数据库解决方案
在HTML5时代,Web开发迎来了一系列创新特性,其中之一便是Web SQL数据库。尽管Web SQL标准已被W3C废弃,转而推荐IndexedDB作为替代,但了解Web SQL对于学习Web存储技术的演进历程仍有其价值。本文将详细介绍Web SQL数据库的基本概念、…...

C++ const关键字有多种用法举例
C const关键字有多种用法 可以用来修饰变量、指针、函数参数、成员函数等。可以看到const在C中有多种用法,主要用于保证数据的不可变性,增强代码的安全性和可读性。在实际编程中,根据需要选择适当的const用法,可以有效避免意外修…...

Makefile-快速掌握
引用 本文完全参照大佬的文档写的,写这篇文章只是为了梳理一下知识 https://github.com/marmotedu/geekbang-go/blob/master/makefile/Makefile%E5%9F%BA%E7%A1%80%E7%9F%A5%E8%AF%86.md 介绍 Makefile是一个工程文件的编译规则,描述了整个工程的编译…...
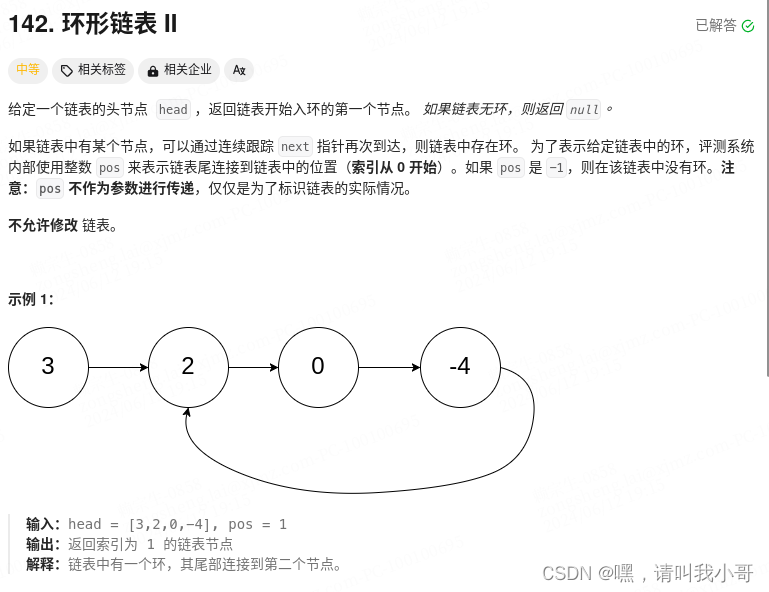
定个小目标之刷LeetCode热题(20)
这题与上一题有一点不同,上一题是判断链表是否存在环,这题是寻找入环的第一个节点,有一个规则是这样的,在存在环的情况下,运用快慢指针判断是否有环结束时,把快指针指向头结点,慢指针不变&#…...
短剧分销小程序:影视产业链中的新兴力量
一、引言 在数字化浪潮的推动下,影视产业正迎来一场深刻的变革。短剧分销小程序作为这场变革中的新兴力量,正以其独特的魅力和价值,逐渐在影视产业链中崭露头角。本文将探讨短剧分销小程序在影视产业链中的新兴地位、其带来的变革以及未来的…...

使用fvm切换flutter版本
切换flutter版本 下载fvm 1、dart pub global activate fvm dart下载fvm 2、warning中获取下载本地的地址 3、添加用户变量path: 下载地址 终端查看fvm版本 fvm --version 4、指定fvm文件缓存地址 fvm config --cache-path C:\src\fvm(自定义地址&…...
python通过selenium实现自动登录及轻松过滑块验证、点选验证码(2024-06-14)
一、chromedriver配置环境搭建 请确保下载的驱动程序与你的Chrome浏览器版本匹配,以确保正常运行。 1、Chrome版本号 chrome的地址栏输入chrome://version,自然就得到125.0.6422.142 版本 125.0.6422.142(正式版本) (…...

【C++】开源项目收集
C 是一种强大的、静态类型的通用编程语言,它的开源生态系统非常丰富,拥有众多高质量的项目。以下是一些知名的C开源项目: Boost: 这是一个庞大的库集合,提供了大量的实用工具和组件,如文件系统、网络编程、智能指针等&…...
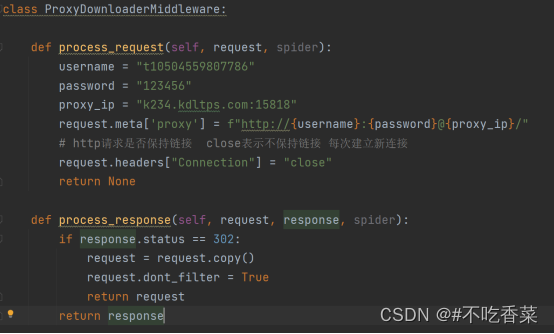
爬虫相关面试题
一,如何抓取一个网站? 1,去百度和谷歌搜一下这个网站有没有分享要爬取数据的API 2, 看看电脑网页有没有所需要的数据,写代码测试调查好不好拿,如果好拿直接开始爬取 3,看看有没有电脑能打开的手机网页&a…...

Spring Cloud Netflix 之 Ribbon
前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家:https://www.captainbed.cn/z ChatGPT体验地址 文章目录 前言前言1、负载均衡1.1、服务端负载均衡1.2、客户端负载均衡 2、Ribbon实现服务…...

C语言怎样记住那么多的颜⾊?
一、问题 ⾚、橙、⻩、绿、⻘、蓝、紫,如此之多的颜⾊,数字不好记,英⽂看程序还可以, 直接写也不好写。那么怎样记住那么多的颜⾊呢? 二、解答 颜⾊枚举值如下: enum COLORS {BLACK, /*O⿊*/BLUE, …...
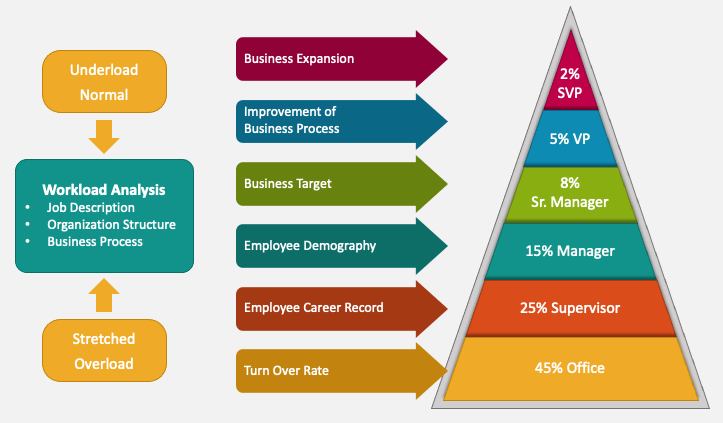
LabVIEW软件开发任务的工作量估算方法
在开发LabVIEW软件时,如何准确估算软件开发任务的工作量。通过需求分析、功能分解、复杂度评估和资源配置等步骤,结合常见的估算方法,如专家判断法、类比估算法和参数估算法,确保项目按时按质完成,提供项目管理和资源分…...

【已解决】引入 element 组件无法使用编译错误 ERROR Failed to compile with 1 error
如果大家使用这个vue 配合 element 框架不熟练,当你顺利按照文档安装好 vue 和 element 的时候想要使用element 的组件时候确无法展示出来,甚至报错。不妨看看是不是这个问题, 1.首先使用element 的时候,前提是把必须要的 elemen…...

6541616
56465651...

)
保姆级拆解:用代码和图示彻底搞懂YOLOv7的Backbone与Head(附ELAN模块详解)
保姆级拆解:用代码和图示彻底搞懂YOLOv7的Backbone与Head(附ELAN模块详解) 在计算机视觉领域,目标检测一直是热门研究方向。YOLO系列作为其中的佼佼者,以其高效和准确著称。YOLOv7作为该系列的最新成员,在速…...

101种美食-图像分类数据集
101种美食图像分类数据集 数据集(文章最后关注公众号获取数据集): 通过网盘分享的文件: 链接: https://pan.baidu.com/s/1MWasy2HPJSknwgA5IrrNSA?pwdzj6u 提取码: zj6u 数据集信息介绍 apple_pie(苹果派)…...

【NotebookLM经济学研究辅助终极指南】:20年量化研究员亲授5大高阶用法,90%学者还不知道的AI研报加速术
更多请点击: https://intelliparadigm.com 第一章:NotebookLM经济学研究辅助的底层逻辑与范式革命 NotebookLM 以语义理解为核心,将传统文献驱动的研究流程重构为“知识图谱—问题锚定—推理生成”三位一体的新范式。其底层并非依赖关键词匹…...

raylib终极指南:3天从零到一的游戏开发快速入门
raylib终极指南:3天从零到一的游戏开发快速入门 【免费下载链接】raylib A simple and easy-to-use library to enjoy videogames programming 项目地址: https://gitcode.com/GitHub_Trending/ra/raylib raylib是一款专为游戏开发设计的轻量级跨平台框架&am…...

TimerBlox:基于电流基准的硬件定时新方案,替代555与MCU
1. 项目概述:重新认识定时电路的设计范式在嵌入式系统、电源管理、电机控制乃至各类信号发生器的设计中,定时功能几乎无处不在。无论是生成一个精确的PWM波去调节LED亮度,还是产生一个可调的时钟信号驱动VCO,亦或是需要一个精准的…...

WechatSogou:基于搜狗微信搜索的公众号数据采集解决方案实战指南
WechatSogou:基于搜狗微信搜索的公众号数据采集解决方案实战指南 【免费下载链接】WechatSogou 基于搜狗微信搜索的微信公众号爬虫接口 项目地址: https://gitcode.com/gh_mirrors/we/WechatSogou 在微信公众号生态日益繁荣的今天,如何高效、稳定…...

科技晚报|2026年5月15日:AI 代理开始补协作、编排和护栏
科技晚报|2026年5月15日:AI 代理开始补协作、编排和护栏 一句话导读:今晚更值得看的,不是哪家模型榜单又变了,而是几家平台同时在补 AI 代理真正进生产前最缺的三块能力:跨 IDE 共享状态、团队级可观测&…...

软件测试从业者理财指南:别让辛苦钱在通胀中缩水
你的“缺陷”不止在代码里作为软件测试工程师,你每天都在和缺陷打交道——功能缺陷、性能缺陷、安全缺陷。你擅长用边界值分析挖出隐藏的bug,用等价类划分提升用例效率,用自动化脚本把重复劳动压缩到极致。但当你关掉Jira,看着工资…...