【机器学习】集成学习方法:Bagging与Boosting的应用与优势


文章目录
- 引言
- 一、集成学习的定义
- 二、Bagging方法
- 1. 随机森林(Random Forest)
- 2. 其他Bagging方法
- 二、Boosting方法
- 1. 梯度提升树(Gradient Boosting Machine, GBM)
- 解释GBM的基本原理和训练过程
- 讨论GBM在逐步改进模型预测性能方面的优势
- 2. XGBoost
- 介绍XGBoost作为GBM的一种高效实现
- XGBoost的特性和在各类比赛中的优异表现
- 3. LightGBM和CatBoost
- 概述LightGBM和CatBoost的特点及应用场景
- 三、总结

引言
机器学习作为人工智能的一个重要分支,旨在通过数据驱动的方式让计算机自动从经验中学习,并进行预测或决策。机器学习技术在诸多领域,如图像识别、自然语言处理、推荐系统和金融预测等,取得了广泛应用和显著成果。然而,尽管机器学习模型在特定任务中表现优异,但单一模型在泛化能力上的局限性也逐渐显现出来。
单一模型往往容易受到训练数据的影响,可能会过拟合训练集,即在训练数据上表现很好,但在未见过的测试数据上表现较差。过拟合的问题严重影响了模型的泛化能力,即模型在处理新数据时的表现。因此,提高模型的泛化能力成为了机器学习研究中的一个重要课题。
为了克服单一模型在泛化能力上的不足,集成学习(Ensemble Learning)作为一种有效的方法被提出并得到了广泛应用。集成学习通过构建和组合多个基学习器(Base Learners),可以显著提升模型的预测性能和稳定性。集成学习方法在理论和实践中都证明了其在提高模型泛化能力方面的优势。
一、集成学习的定义

集成学习是一种通过训练多个基学习器并将它们的预测结果进行组合,从而获得更优模型性能的方法。基学习器可以是同质的(如多个决策树)或异质的(如决策树、支持向量机和神经网络的组合)。集成学习的核心思想是通过多模型的集成来减小单个模型的误差,最终获得更稳健和准确的预测结果。
集成学习方法主要分为两大类:Bagging和Boosting。Bagging(Bootstrap Aggregating)通过对训练数据进行重采样来构建多个基学习器,并对它们的预测结果进行平均或投票;Boosting则通过逐步调整基学习器的权重,使后续的基学习器更关注之前模型中难以预测的样本。这两种方法虽然在实现上有所不同,但都通过模型集成有效地提高了泛化能力和预测精度。
通过对集成学习的深入研究和应用,可以发现其在各种实际问题中的显著优势,使得它成为现代机器学习中不可或缺的重要方法之一。
二、Bagging方法
1. 随机森林(Random Forest)
随机森林(Random Forest)是一种基于Bagging(Bootstrap Aggregating)思想的集成学习方法。它由Leo Breiman在2001年提出,是对决策树算法的改进。随机森林通过构建多棵决策树来进行分类或回归,并通过这些树的集合投票(分类)或平均(回归)来获得最终的预测结果。
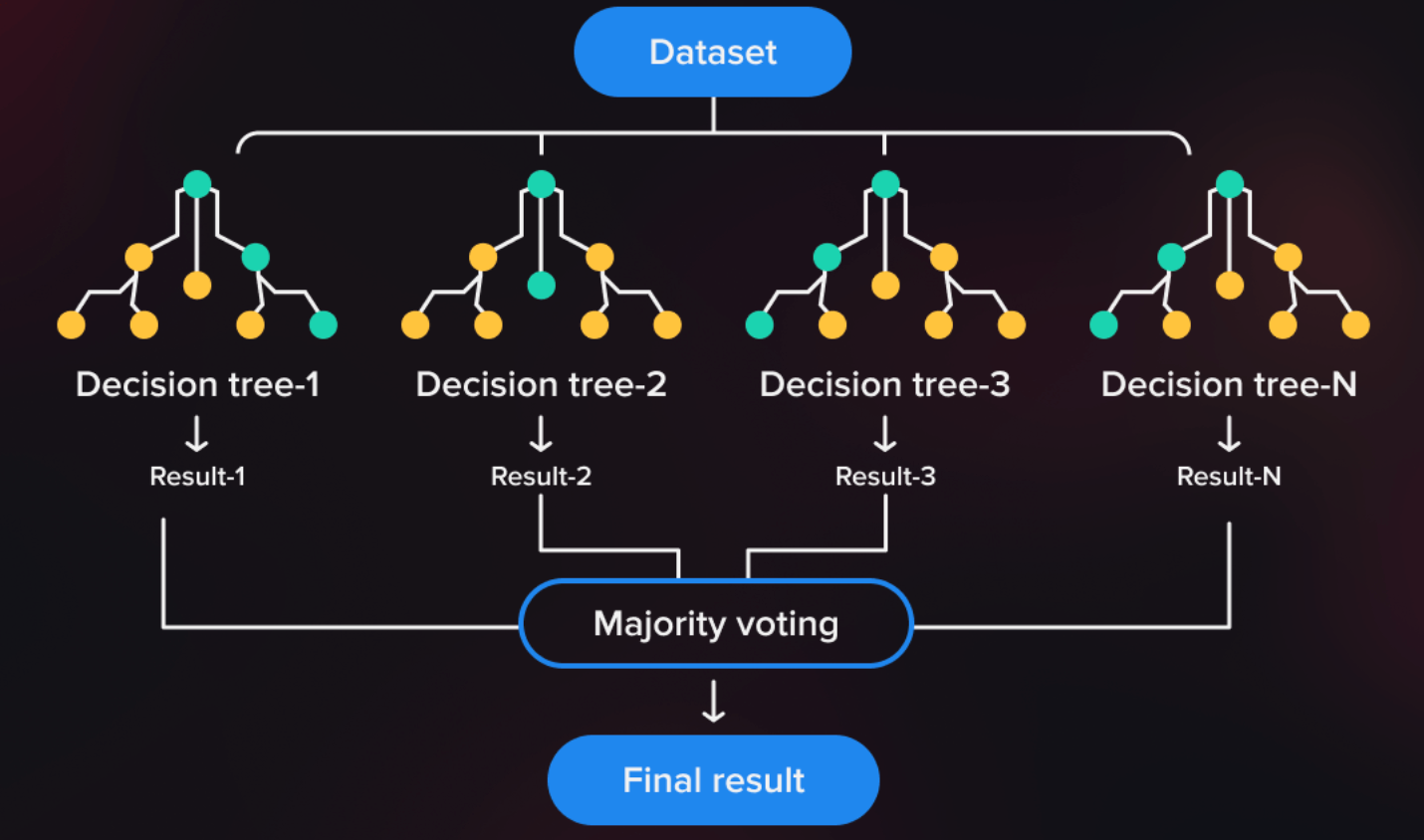
随机森林的核心在于其随机性和多样性。构建随机森林的步骤如下:
- 数据子集随机抽样:对于每一棵决策树,从原始训练数据集中随机抽取一个子集(有放回抽样,即Bootstrap抽样),这些子集之间可以有重叠。
- 特征子集随机选择:在构建每棵树的过程中,对每个节点的划分,随机选择特征的一个子集进行最佳分裂。这一过程增加了树之间的差异性。
这种随机性在一定程度上减少了每棵树的相关性,使得最终的模型更为稳健和准确。
通过Python代码可以更好地理解随机森林的构建过程。下面是一个使用Scikit-learn库构建随机森林的示例:
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据集
data = load_iris()
X = data.data
y = data.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建随机森林分类器
rf_clf = RandomForestClassifier(n_estimators=100, random_state=42)# 训练模型
rf_clf.fit(X_train, y_train)# 预测
y_pred = rf_clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Random Forest Accuracy: {accuracy:.2f}")
随机森林通过集成多棵决策树,显著提高了模型的稳定性和泛化能力:
- 降低过拟合:单棵决策树容易过拟合训练数据,而随机森林通过对多个决策树的结果进行平均或投票,可以减少单棵树的过拟合风险,增强对新数据的泛化能力。
- 提高稳定性:由于随机森林是由多棵独立决策树组成的,个别树的异常预测不会对整体结果产生重大影响,从而提高了模型的稳定性和鲁棒性。
2. 其他Bagging方法
除了随机森林,Bagging还应用于其他多种模型中,以进一步提高模型性能。常见的Bagging方法包括:
- Bagged Decision Trees:这是最原始的Bagging方法,直接对决策树进行Bootstrap抽样和集成。与随机森林不同,Bagged Decision Trees并不进行特征子集的随机选择,只是对数据进行抽样。
- Bagged K-Nearest Neighbors (KNN):在KNN中,Bagging通过对不同的Bootstrap样本集构建多个KNN模型,并将这些模型的结果进行平均或投票,从而提高预测性能。
- Bagged Neural Networks:将Bagging应用于神经网络,通过多个神经网络的集成来减少单个网络的过拟合和提高泛化能力。
这些Bagging方法都利用了Bootstrap抽样和集成的思想,通过多个模型的组合来增强整体预测能力和稳健性。
以下是一个使用Bagged Decision Trees的示例代码:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据集
data = load_iris()
X = data.data
y = data.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建基学习器
base_clf = DecisionTreeClassifier(random_state=42)# 创建Bagging分类器
bagging_clf = BaggingClassifier(base_estimator=base_clf, n_estimators=50, random_state=42)# 训练模型
bagging_clf.fit(X_train, y_train)# 预测
y_pred = bagging_clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Bagged Decision Trees Accuracy: {accuracy:.2f}")
通过这些示例代码,展示了如何使用Bagging方法构建集成模型,并说明了这些方法在提高模型性能和稳定性方面的效果。
二、Boosting方法
1. 梯度提升树(Gradient Boosting Machine, GBM)
解释GBM的基本原理和训练过程
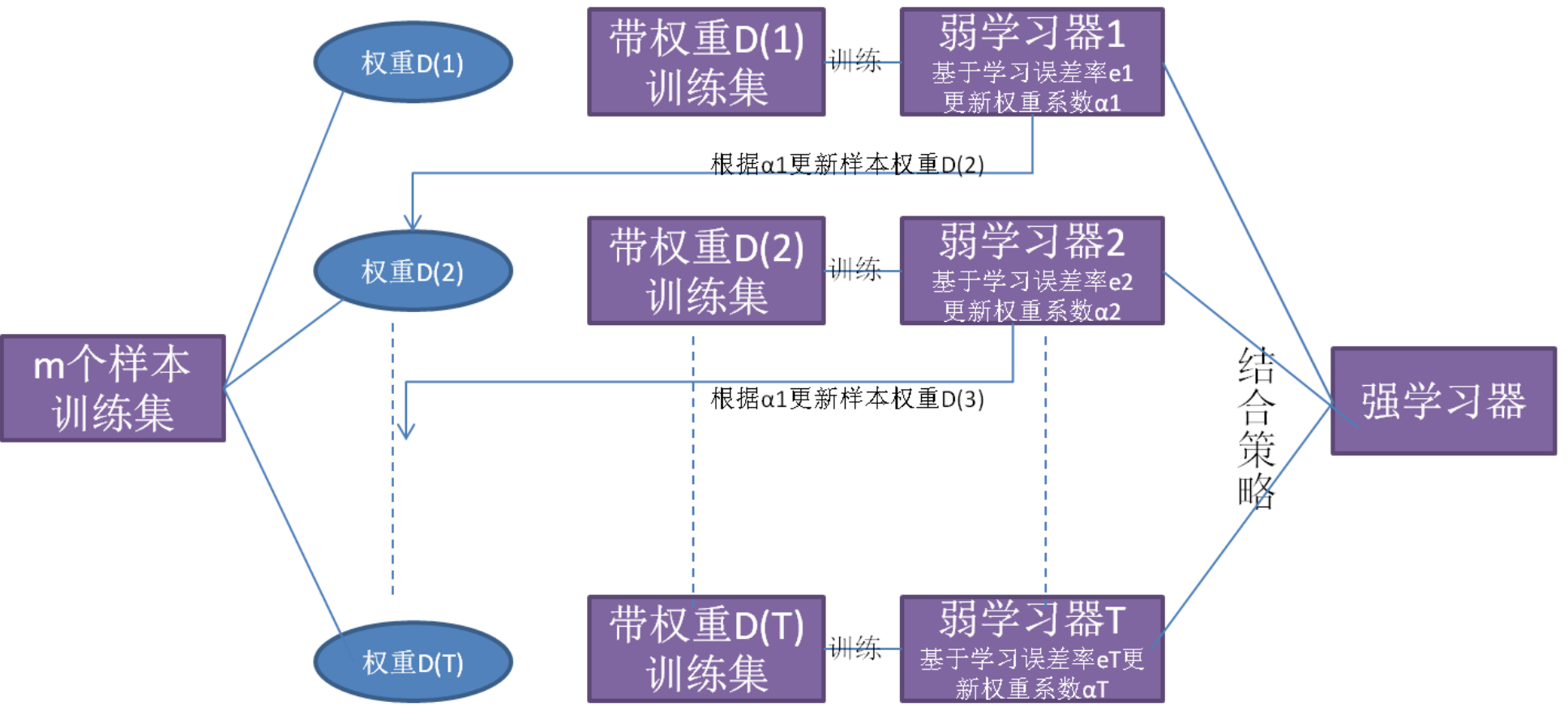
梯度提升树(Gradient Boosting Machine, GBM)是一种迭代的集成学习方法,通过组合多个弱学习器(通常是决策树)来提高模型的预测性能。GBM的基本思想是通过逐步减小前一个模型的误差来构建新的模型,每一步都试图纠正前一步的错误。其训练过程可以分为以下几个步骤:
- 初始化模型:首先,用一个简单的模型(通常是一个常数模型)来预测目标值。这个模型的输出是所有样本的平均值。
- 计算残差:计算当前模型的残差,即真实值与预测值之间的差异。
- 训练弱学习器:用这些残差作为目标值,训练一个新的弱学习器(如决策树)。
- 更新模型:将弱学习器的预测结果乘以一个学习率,然后加到当前模型上,更新模型的预测值。
- 重复迭代:重复步骤2-4,直到达到预定的迭代次数或模型误差不再显著下降。
以下是GBM的示例代码,使用Scikit-learn库实现:
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据集
data = load_iris()
X = data.data
y = data.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建GBM分类器
gbm_clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, random_state=42)# 训练模型
gbm_clf.fit(X_train, y_train)# 预测
y_pred = gbm_clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"GBM Accuracy: {accuracy:.2f}")
讨论GBM在逐步改进模型预测性能方面的优势
GBM在逐步改进模型预测性能方面具有显著优势:
- 逐步优化:GBM通过迭代的方式,每一步都在前一步的基础上进行改进,逐步减小误差。这种方法使得GBM可以有效地捕捉数据中的复杂模式。
- 灵活性高:GBM可以处理各种类型的数据,包括数值型、分类型和文本数据。它在处理非线性关系和复杂数据结构方面表现尤为出色。
- 可调参数:GBM提供了多个超参数(如树的数量、深度和学习率)供调节,用户可以根据具体问题调整这些参数,以优化模型性能。
2. XGBoost
介绍XGBoost作为GBM的一种高效实现
XGBoost(eXtreme Gradient Boosting)是GBM的一种高效实现,它在GBM的基础上进行了多项改进,使其在速度和性能上都有显著提升。XGBoost的关键特性包括:
- 正则化:XGBoost通过引入L1和L2正则化,控制模型复杂度,防止过拟合。
- 并行计算:XGBoost利用并行计算技术,加快了模型训练速度。
- 树的分裂算法:XGBoost采用了更高效的分裂算法,能够更快速地找到最佳分裂点。
- 处理缺失值:XGBoost能够自动处理数据中的缺失值,提升了模型的鲁棒性。
以下是使用XGBoost的示例代码:
import xgboost as xgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据集
data = load_iris()
X = data.data
y = data.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建XGBoost分类器
xgb_clf = xgb.XGBClassifier(n_estimators=100, learning_rate=0.1, random_state=42)# 训练模型
xgb_clf.fit(X_train, y_train)# 预测
y_pred = xgb_clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"XGBoost Accuracy: {accuracy:.2f}")
XGBoost的特性和在各类比赛中的优异表现
XGBoost由于其高效的实现和出色的性能,广泛应用于各种机器学习比赛中,并且在许多比赛中表现优异。其特性包括:
- 高效性:XGBoost在处理大规模数据时表现出色,训练速度快且内存占用低。
- 灵活性:XGBoost支持多种目标函数和评估指标,用户可以根据具体问题自定义损失函数和评估标准。
- 鲁棒性:XGBoost具有强大的鲁棒性,能够处理噪声数据和缺失值,提升模型的稳定性和泛化能力。
3. LightGBM和CatBoost
概述LightGBM和CatBoost的特点及应用场景
LightGBM
LightGBM(Light Gradient Boosting Machine)是由微软开发的一种高效的GBM实现,具有以下特点:
- 基于直方图的决策树算法:LightGBM使用直方图算法构建决策树,提高了训练速度和内存效率。
- 支持大规模数据:LightGBM在处理大规模数据时表现优异,适用于高维度数据和大数据场景。
- 高效的并行训练:LightGBM支持数据并行和特征并行,进一步加快了模型训练速度。
应用场景:LightGBM适用于需要处理大规模数据集的场景,如推荐系统、点击率预测和金融风控等。
以下是使用LightGBM的示例代码:
import lightgbm as lgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据集
data = load_iris()
X = data.data
y = data.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建LightGBM分类器
lgb_clf = lgb.LGBMClassifier(n_estimators=100, learning_rate=0.1, random_state=42)# 训练模型
lgb_clf.fit(X_train, y_train)# 预测
y_pred = lgb_clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"LightGBM Accuracy: {accuracy:.2f}")
CatBoost
CatBoost(Categorical Boosting)是由Yandex开发的一种GBM实现,专门优化了对类别特征的处理。其特点包括:
- 高效处理类别特征:CatBoost无需对类别特征进行独热编码,直接处理类别数据,简化了数据预处理过程。
- 减少过拟合:CatBoost通过对梯度计算进行改进,减小了梯度偏差,从而减少了过拟合现象。
- 自动化处理:CatBoost内置了许多自动化处理功能,如自动调整超参数和处理缺失值,提高了模型的易用性。
应用场景:CatBoost特别适用于含有大量类别特征的数据集,如广告点击率预测、推荐系统和金融预测等。
以下是使用CatBoost的示例代码:
from catboost import CatBoostClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据集
data = load_iris()
X = data.data
y = data.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 创建CatBoost分类器
cat_clf = CatBoostClassifier(n_estimators=100, learning_rate=0.1, random_state=42, verbose=0)# 训练模型
cat_clf.fit(X_train, y_train)# 预测
y_pred = cat_clf.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"CatBoost Accuracy: {accuracy:.2f}")
三、总结
集成学习方法通过结合多个基学习器的优势,显著提高了机器学习模型的泛化能力和预测性能。Bagging方法,如随机森林,通过对数据和特征进行重采样构建多个模型,减少了过拟合风险,提升了模型的稳定性和准确性。而Boosting方法,通过迭代地改进模型的误差,如梯度提升树(GBM)、XGBoost、LightGBM和CatBoost等,在处理复杂数据和提高预测性能方面表现尤为出色。
这些方法各具特色,在不同应用场景中发挥了重要作用。随机森林适用于需要高稳定性的任务,XGBoost由于其高效性和灵活性在比赛中表现优异,LightGBM则在大数据处理方面优势明显,而CatBoost专注于类别特征的处理,简化了预处理过程并提升了模型性能。
通过合理选择和应用这些集成学习方法,能够有效提升机器学习模型的表现,解决实际问题中的复杂挑战。
相关文章:
【机器学习】集成学习方法:Bagging与Boosting的应用与优势
🔥 个人主页:空白诗 文章目录 引言一、集成学习的定义二、Bagging方法1. 随机森林(Random Forest)2. 其他Bagging方法 二、Boosting方法1. 梯度提升树(Gradient Boosting Machine, GBM)解释GBM的基本原理和…...
工业 web4.0 的 UI 卓越非凡
工业 web4.0 的 UI 卓越非凡...
C语言 | Leetcode C语言题解之第145题二叉树的后序遍历
题目: 题解: void addPath(int *vec, int *vecSize, struct TreeNode *node) {int count 0;while (node ! NULL) {count;vec[(*vecSize)] node->val;node node->right;}for (int i (*vecSize) - count, j (*vecSize) - 1; i < j; i, --j)…...
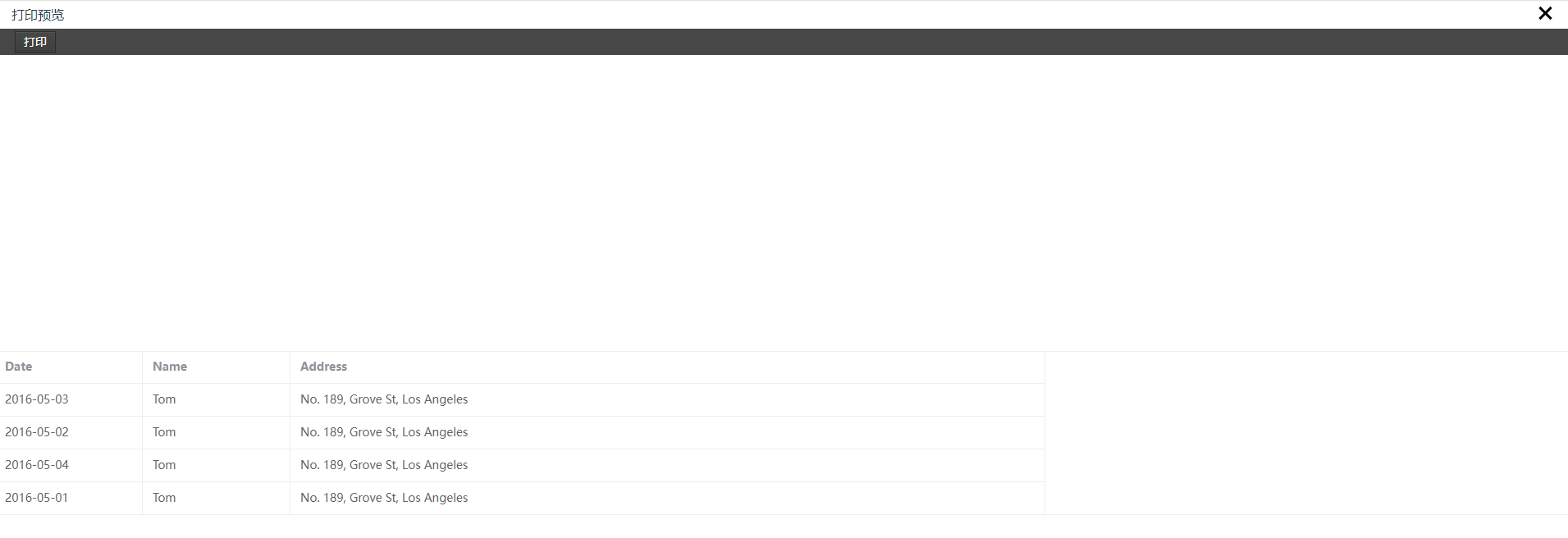
如何在 Vue 3 中使用 vue3-print-nb 实现灵活的前端打印
你好,我是小白Coding日志,一个热爱技术的程序员。在这里,我分享自己在编程和技术世界中的学习心得和体会。希望我的文章能够给你带来一些灵感和帮助。欢迎来到我的博客,一起在技术的世界里探索前行吧! 前言 在前端开…...

Go Module详解
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「stormsha的主页」…...

基于51单片机的智能水表
一.硬件方案 本设计主要以51单片机作为主控处理器的智能水表,该水表能够记录总的用水量和单次用水量,当用水量超出设定值时系统发出声光报警提醒,水量报警值能够通过按键进行自行设置,并且存储于AT24C02中,并且可以测…...
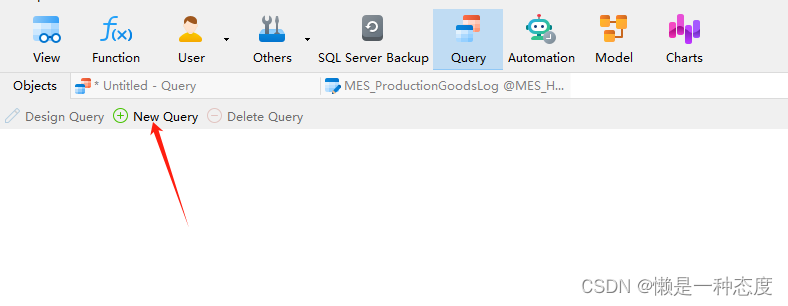
SQLServer 借助Navcate做定时备份的脚本
首先创建SQLServer链接,然后在Query标签种创建一个查询 查询内容如下 use ChengYuMES declare ls_time varchar(1000) declare ls_dbname varchar(1000) set ls_time convert(varchar, getdate(), 112) _ replace(convert(varchar, getdate(), 108), :, )-- 需…...

MBD_入门篇_21_SimulinkSignalAttributes
21.SignalAttributes 21.1 概述 Signal Attributes,信号属性,信号特性。 21.2 回顾常用模块 21.2.1 DataTypeConversion 数据类型转换模块,可以对信号的数据类型进行强制转换。无符号数据与有符号数据相加,我们可以将无符号数据转…...

Web前端高级课程:深入探索与技能飞跃
Web前端高级课程:深入探索与技能飞跃 在数字化时代的浪潮中,Web前端技术日新月异,对前端开发者的技能要求也日益提高。为了满足这一需求,我们精心打造了一款Web前端高级课程,旨在帮助学员掌握最前沿的前端技术&#x…...

螺丝工厂vtk ThreadFactory(1)
螺丝工厂vtkThreadFactory (1) 缘起 几年前的探索在Python里应用Openscad实现3D建模之3D螺纹建模初探3 新的参考: generating nice threads in openscadvtkRotationalExtrusionFilter 辅助AI: coze 笔记📒: openscad 代码分析 // 半径缩放函数,用…...

Android13 蓝牙协议属性配置详解
Android13 蓝牙协议属性配置详解 文章目录 Android13 蓝牙协议属性配置详解一、前言二、Android13 蓝牙协议属性配置1、Profile 属性和暴露接口的定义2、蓝牙协议属性定义3、系统代码中判断蓝牙协议是否使能的代码 三、其他1、adb 窗口中查看蓝牙协议属性2、动态设置蓝牙prop协…...

南通国际高中有哪些?南通惠立学校高中部校长见面日重磅来袭
惠灵顿(中国)自2011年成立以来,一直坚持深耕国际与双语教育,拥有丰厚的办学经验。依托于集团化的深厚经验南通惠立学校于2024-2025学年开设9-11年级,这所南通国际高中为高中学生搭建一个集卓越升学成果、强大师资、纯正…...

Al智能图像处理APP,安卓手机专用一键优化工具资源合集下载
### 标题:Al智能图像处理APP,安卓手机专用一键优化工具资源合集下载 随着科技的进步,图像处理技术也在不断提升。为了满足用户对图像处理日益增长的需求,我们隆重推出了一款功能强大的图像处理工具——Al智能图像处理APP。这款安…...
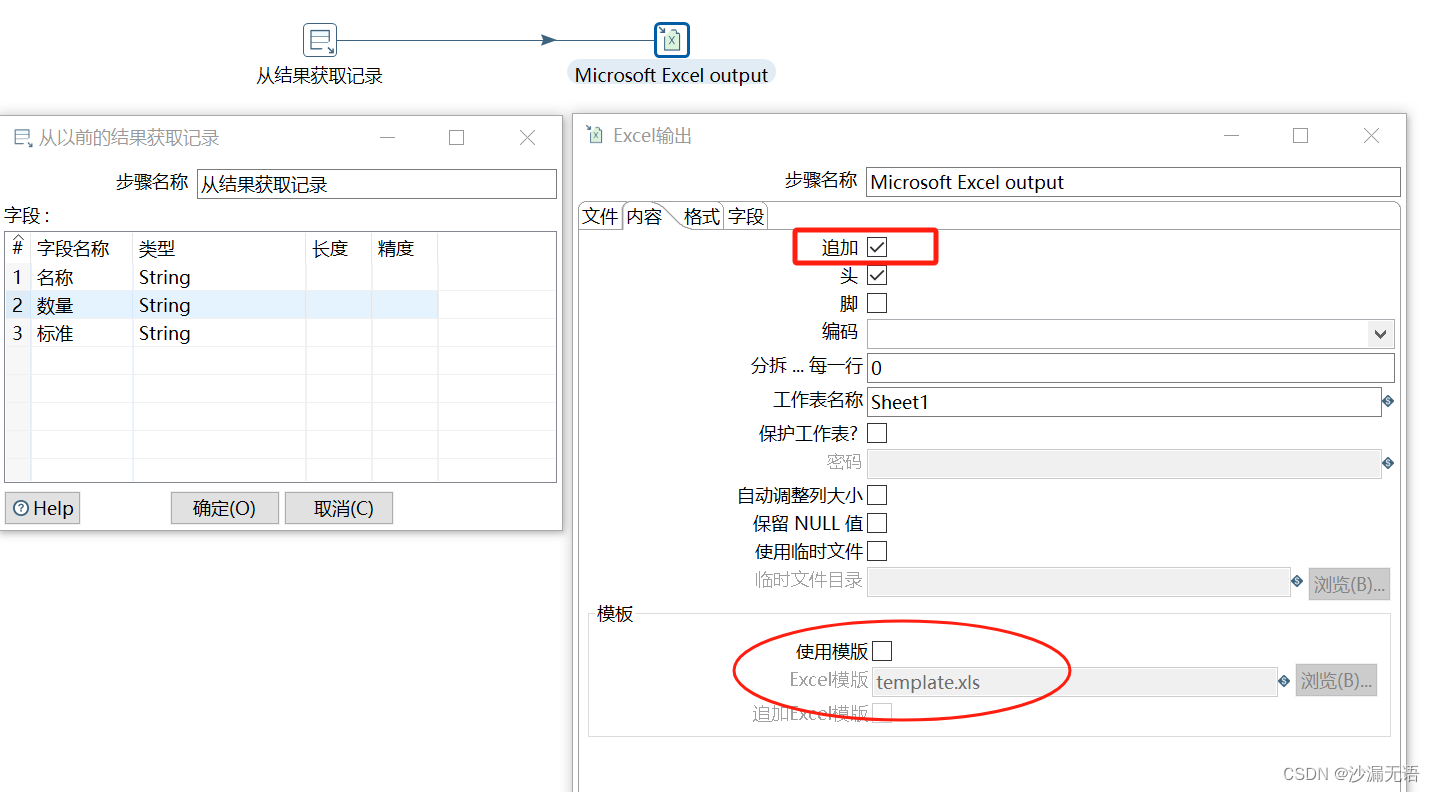
Kettle根据分类实现Excel文件拆分——kettle开发31
将整理好的一份供应商付款明细Excel文件,按供应商拆分成多个Excel文件。 实现思路 本文我们首先将供应商付款明细表,按照“名称”拆分成多份Excel文件。拆分Excel文件打算用两个转换实现,一个用来将Excel数据读取到参数中,另外一…...

merkle tree中文
Merkle tree merkle tree中文文档英文文档 #include <cstdlib> #include <string> #include <bitcoin/bitcoin.hpp>BC_USE_LIBBITCOIN_MAINusing namespace bc;bc::hash_digest calculate_merkle_root(bc::hash_list &merkle);int bc::main(int argc, …...

制作自己的 @OnClick、@OnLongClick(告别 setOnClickListener,使用注解、反射和动态代理)
前言 前面我们说过 ButterKnife 这个库,这个库实现不仅实现了 View 的绑定,而且还提供了大量的注解如 BindView、OnClick、OnLongClick 等来简化开发过程中事件绑定。而这些功能的实现是通过 APT 也就是注解处理器,在编译期间生成 Java 代码…...

Android基础-RecyclerView的优点
一、引言 在Android开发中,RecyclerView是一个强大而灵活的控件,用于展示大量数据集合的视图。相比于传统的ListView和GridView,RecyclerView提供了更高的性能、更多的布局选择和更丰富的交互体验。本文将详细阐述RecyclerView的功能作用以及…...
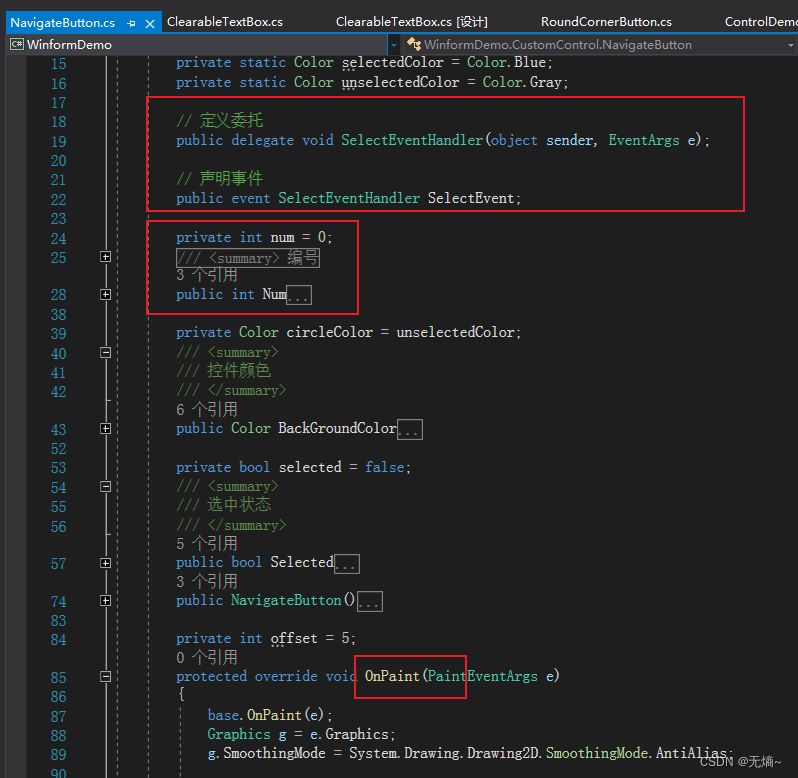
C# Winform 用户控件,扩展控件,自定义控件综合实例
Control类是Windows窗体控件的基类,它提供了在 Windows 窗体应用程序中进行可视显示所需的基础结构,可以通过继承来扩展熟悉的用户控件和现有控件的功能。本列介绍三种不同自定义控件以及怎么创建他们。 自定义控件分类 用户控件:基本控件的…...

经济学和金融学有什么区别?
中文版 金融学和经济学是两个密切相关但有所不同的学科,它们各自侧重于不同的研究领域和方法。 经济学 (Economics) 经济学是研究如何配置有限资源以满足人类无限需求的学科。它可以分为两个主要分支: 宏观经济学 (Macroeconomics): 研究经济整体的行…...
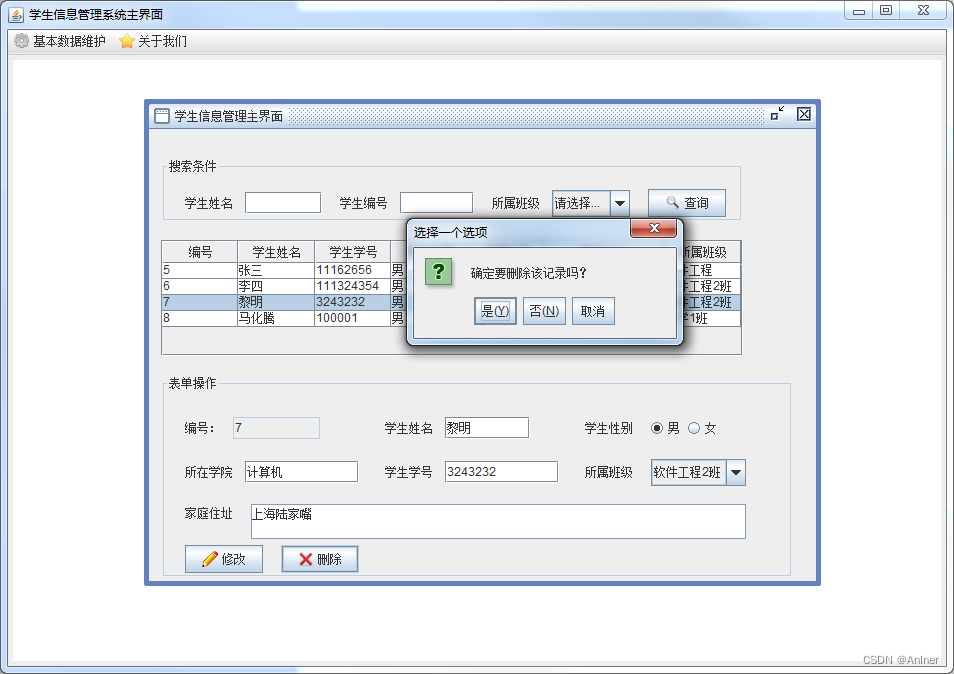
Java课程设计:基于swing的学生信息管理系统
文章目录 一、项目介绍二、项目展示三、源码展示四、源码获取 一、项目介绍 这款Java swing实现的学生信息管理系统和jsp版本的功能很相似,简单的实现了班级信息的增删改查,学生信息的增删改查,数据库采用的是mysql,jdk版本不限&…...

AI读脸术如何对接API?Flask服务封装部署教程
AI读脸术如何对接API?Flask服务封装部署教程 1. 为什么需要把“读脸术”变成API? 你可能已经试过这个AI读脸术镜像:上传一张照片,几秒内就能看到人脸框、性别和年龄段标签,效果干净利落。但如果你正开发一个用户管理…...
)
UCI心脏病数据集实战:用XGBoost构建预测模型的全流程指南(附特征重要性分析)
UCI心脏病数据集实战:用XGBoost构建预测模型的全流程指南(附特征重要性分析) 医疗数据科学正在重塑现代医学诊断方式。当我在克利夫兰诊所实习期间,亲眼见证了机器学习模型如何辅助医生识别高风险心脏病患者。本文将带您完整复现这…...
数据导入模板:Excel模板设计与导出)
cool-admin(midway版)数据导入模板:Excel模板设计与导出
cool-admin(midway版)数据导入模板:Excel模板设计与导出 【免费下载链接】cool-admin-midway 🔥 cool-admin(midway版)一个很酷的后台权限管理框架,模块化、插件化、CRUD极速开发,永久开源免费,基于midway.js 3.x、typ…...

COMSOL相场法/水平集方法多孔介质两相驱替模型案例 附随机孔隙度几何程序 助力学习两相流驱替模拟
COMSOL相场法(/水平集方法)多孔介质驱替模型案例,可以提供随机孔隙度几何程序。 提供基于COMSOL中相场方法模拟多孔介质两相驱替(水气、油水等等)的算例(也可以定做水平集驱替的算例)࿰…...

解决Python ssl模块与系统OpenSSL版本不一致的编译指南
1. 为什么Python的ssl模块会与系统OpenSSL版本不一致? 很多开发者都遇到过这样的困惑:明明系统已经升级了OpenSSL,为什么Python的ssl模块还在使用旧版本?这个问题其实源于Python的编译机制。Python在编译安装时,会将当…...

解决Canal 连接数据库超时问题
根本原因:DNS 反向解析导致超时Caused by: java.net.SocketTimeoutException: Timeout occurred, failed to read total 4 bytes in 5000 milliseconds, actual read only 0 bytesat com.alibaba.otter.canal.parse.driver.mysql.socket.BioSocketChannel.read(BioS…...

AnythingtoRealCharacters2511镜像免配置部署教程:Docker+ComfyUI开箱即用方案
AnythingtoRealCharacters2511镜像免配置部署教程:DockerComfyUI开箱即用方案 想快速将动漫人物变成真实照片?这个教程教你10分钟搞定专业级动漫转真人效果,无需任何技术背景! 1. 为什么选择这个镜像? 如果你曾经尝试…...

问道1.6夏日清风单机虚拟机版|200+礼包加持·最强方官1.6完整体验
温馨提示:文末有联系方式【全新封装|问道1.6夏日清风单机虚拟机版】 本版本基于稳定虚拟机环境深度优化,完美集成‘夏日清风’主内容与当前最成熟的‘最强方官1.6’核心框架,运行零冲突、免配置,开箱即玩。【超值&…...

从MATLAB/Python代码实现反推Newmark-β法:理解线性加速度假设如何变成迭代算法
从代码实现反推Newmark-β法:线性加速度假设的工程实践指南 在结构动力学分析中,地震响应、风荷载等时程分析问题常需要求解二阶微分方程。Newmark-β法作为经典数值解法,通过线性加速度假设将连续问题离散化。但教科书往往止步于公式推导&am…...

【测试之道】第四篇:分层测试论 —— 金字塔、奖杯与蜂巢:构建你的质量防御阵型
专栏进度:04 / 10 (测试理论专题) 在不同的架构(单体、微服务、前端驱动)下,测试资源的分配比例是完全不同的。盲目套用模板是测试经理最容易犯的错误。 一、 经典模型:测试金字塔 (Testing Pyramid) 由 Mike Cohn 提出…...