【scikit-learn入门指南】:机器学习从零开始
1. 简介

scikit-learn是一款用于数据挖掘和数据分析的简单高效的工具,基于NumPy、SciPy和Matplotlib构建。它能够进行各种机器学习任务,如分类、回归和聚类。
2. 安装scikit-learn
在开始使用scikit-learn之前,需要确保已经安装了scikit-learn库。可以使用以下命令安装:
pip install scikit-learn
3. 数据预处理
数据预处理是机器学习中的一个重要步骤。在这一部分,我们将讨论如何处理缺失值、标准化数据以及编码类别变量。
缺失值处理
在实际数据集中,经常会遇到缺失值。我们可以使用scikit-learn的SimpleImputer类来填补缺失值。
import numpy as np
from sklearn.impute import SimpleImputer# 创建一个包含缺失值的数据集
data = np.array([[1, 2, np.nan], [3, np.nan, 6], [7, 8, 9]])# 使用均值填补缺失值
imputer = SimpleImputer(strategy='mean')
data_imputed = imputer.fit_transform(data)print("填补后的数据:\n", data_imputed)
结果分析:以上代码用列的均值填补了缺失值,输出的填补后数据如下:
填补后的数据:
[[1. 2. 7.5][3. 5. 6.][7. 8. 9.]]
数据标准化
不同特征的数值范围可能差异很大,为了提高模型的性能,通常需要对数据进行标准化处理。
from sklearn.preprocessing import StandardScaler# 标准化数据
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data_imputed)print("标准化后的数据:\n", data_scaled)
结果分析:数据标准化后,各特征的均值为0,标准差为1。
类别变量编码
对于分类变量,需要将其转换为数值型。可以使用OneHotEncoder来进行独热编码。
from sklearn.preprocessing import OneHotEncoder# 创建一个包含类别变量的数据集
data = np.array([['Male', 1], ['Female', 3], ['Female', 2]])# 独热编码
encoder = OneHotEncoder(sparse=False)
data_encoded = encoder.fit_transform(data)print("编码后的数据:\n", data_encoded)
结果分析:独热编码将类别变量转换为二进制特征。
4. 数据集划分
在训练模型前,需要将数据集划分为训练集和测试集。train_test_split函数可以轻松实现这一点。
from sklearn.model_selection import train_test_split# 创建一个示例数据集
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]])
y = np.array([0, 1, 0, 1, 0])# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)print("训练集特征:\n", X_train)
print("测试集特征:\n", X_test)
结果分析:数据集按照80%的比例划分为训练集和测试集。
5. 模型选择与训练
在这部分,我们将介绍几种常用的机器学习模型,并展示如何使用scikit-learn进行训练和预测。
线性回归
线性回归是最简单的回归模型之一。
from sklearn.linear_model import LinearRegression# 创建线性回归模型
model = LinearRegression()# 训练模型
model.fit(X_train, y_train)# 预测
predictions = model.predict(X_test)print("线性回归预测结果:", predictions)
结果分析:线性回归模型对测试集进行了预测,输出预测值。
逻辑回归
逻辑回归常用于二分类问题。
from sklearn.linear_model import LogisticRegression# 创建逻辑回归模型
model = LogisticRegression()# 训练模型
model.fit(X_train, y_train)# 预测
predictions = model.predict(X_test)print("逻辑回归预测结果:", predictions)
结果分析:逻辑回归模型对测试集进行了预测,输出预测类别。
K近邻算法
K近邻算法是一种基于实例的学习方法。
from sklearn.neighbors import KNeighborsClassifier# 创建K近邻模型
model = KNeighborsClassifier(n_neighbors=3)# 训练模型
model.fit(X_train, y_train)# 预测
predictions = model.predict(X_test)print("K近邻预测结果:", predictions)
结果分析:K近邻模型对测试集进行了预测,输出预测类别。
决策树
决策树是一种常见的分类和回归方法。
from sklearn.tree import DecisionTreeClassifier# 创建决策树模型
model = DecisionTreeClassifier()# 训练模型
model.fit(X_train, y_train)# 预测
predictions = model.predict(X_test)print("决策树预测结果:", predictions)
结果分析:决策树模型对测试集进行了预测,输出预测类别。
6. 模型评估
在这一部分,我们将讨论如何使用交叉验证、混淆矩阵和ROC曲线来评估模型性能。
交叉验证
交叉验证可以帮助我们更稳定地评估模型性能。
from sklearn.model_selection import cross_val_score# 使用交叉验证评估模型
scores = cross_val_score(model, X, y, cv=5)print("交叉验证得分:", scores)
结果分析:交叉验证得分展示了模型在不同折中的性能。
混淆矩阵
混淆矩阵用于评估分类模型的性能。
from sklearn.metrics import confusion_matrix# 计算混淆矩阵
cm = confusion_matrix(y_test, predictions)print("混淆矩阵:\n", cm)
结果分析:混淆矩阵展示了模型的分类情况,包括正确和错误的分类数量。
ROC曲线
ROC曲线用于评估二分类模型的性能。
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt# 计算ROC曲线
fpr, tpr, thresholds = roc_curve(y_test, model.predict_proba(X_test)[:,1])
roc_auc = auc(fpr, tpr)# 绘制ROC曲线
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()
结果分析:ROC曲线展示了模型在不同阈值下的性能,AUC值越接近1表示模型性能越好。
7. 结论
本教程详细介绍了如何使用scikit-learn进行数据预处理、模型训练与评估。scikit-learn提供了丰富的工具和方法,可以方便地进行机器学习任务。希望通过本教程,读者能对scikit-learn有一个全面的了解,并能够在实际项目中应用这些知识。
通过对各个模型的详细解释和代码实现,相信你已经掌握了scikit-learn的基础操作。尝试用你自己的数据集进行练习,进一步提升你的机器学习技能吧!
相关文章:
【scikit-learn入门指南】:机器学习从零开始
1. 简介 scikit-learn是一款用于数据挖掘和数据分析的简单高效的工具,基于NumPy、SciPy和Matplotlib构建。它能够进行各种机器学习任务,如分类、回归和聚类。 2. 安装scikit-learn 在开始使用scikit-learn之前,需要确保已经安装了scikit-le…...

MEMS:Lecture 17 Noise MDS
讲义 Minimum Detectable Signal (MDS) Minimum Detectable Signal(最小可检测信号)是指当信号-噪声比(Signal-to-Noise Ratio, SNR)等于1时的输入信号水平。简单来说,MDS 是一个系统能够分辨出信号存在的最低输入信号…...

Windows运维:找到指定端口的服务
运维过windows的或多或少都遇到过需要找到一个端口对应的服务,或者是因为端口占用,或者是想看下对应的服务是哪个,那么如何操作呢?看看本文吧。 1、按照端口找到进程ID 例如想找8000端口的进程ID netstat -ano | findstr :8000 2…...

Linux文件系统讲解!
一、Linux文件系统历史 1、在早期的时候Linux各种不同发行版拥有自己各自自定义的文件系统层级结构。 2、当我用Red hat转向玩Debian时,我进入/etc我都是懵的。 3、后来Linux社区做了一个标准、FHS(文件系统标准层次结构)。来帮助Linux系统的…...

mysql集群,两主两从,使用mysql-proxy实现读写分离
主从复制 一、IP规划 服务器IP备注master1192.168.100.131master2的从master2192.168.100.132master1的从slave1192.168.100.134slave1的从slave2192.168.100.135slave2的从mysql-proxy192.168.100.137 二、具体配置 1.master1 配置ip:192.168.100.131 …...
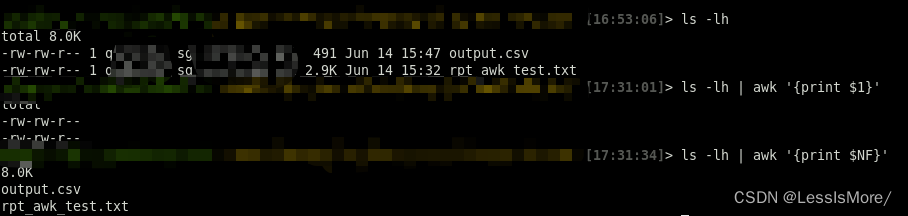
Linux文本处理三剑客+正则表达式
Linux文本处理常用的3个命令,脚本或者文本处理任务中会用到。这里做个整理。 三者的功能都是处理文本,但侧重点各不相同,grep更适合单纯的查找或匹配文本,sed更适合编辑匹配到的文本,awk更适合格式化文本,对…...
Linux启动KKfileview文件在线浏览时报错:启动office组件失败,请检查office组件是否可用
目录 1、导论 2、报错信息 3、问题分析 4、解决方法 4.1、下载 4.2、安装步骤 1、导论 今天进行项目部署时,遇到了一个问题。在启动kkfileview时,出现了报错异常: 2024-06-09 06:36:44.765 ERROR 1 --- [ main] cn.keking.service.Of…...

React <> </>的用法
React <> </>的用法 介绍为什么使用 <>?例子解释 关于顶级元素总结 介绍 在 React 中,使用 <> 表示一个空标签或片段(Fragment),这是一个简洁的方式来包裹一…...
is not null 、StringUtils.isNotEmpty和StringUtils.isNotBlank之间的区别?
这三者主要是针对对象是否为空、是否为空串和是否为空白字符串有不同的功能。 is not null 只是说明该对象不为空,没有考虑是否为空串和空白字符串。 StringUtils.isNotEmpty检查字符串是否不为 null且长度大于零,不考虑字符串中的空白字符。 StringU…...

Git使用-gitlab上面的项目如何整到本地的idea中
场景 一般我们在开发项目或者接手某个项目时,基本都要接触Git,比如上传项目代码,下载同事给你的交接代码等等。 这是一个基本功,小小整理一下日常操作中的使用。 第一步:在 GitLab 上找到你要克隆的项目,复…...

活体检验API在Java、Python、PHP中的使用教程
活体检验API是一种基于生物特征的身份验证技术,通过分析和识别用户的生物信息来确认其身份。这种技术广泛应用于各种领域,如金融、安全、社交媒体等,以提高身份验证的安全性和准确性。以下是描述”活体检验API”背景的一些关键点:…...

智能计算系统-概述
1、人工智能技术分层 2、人工智能方向人才培养 3、课程体系的建议 4、智能系统课程对学生的价值 5、智能计算系统对老师的价值 6、什么是智能计算系统 7、智能计算系统的形态 8、智能计算系统具有重大价值 9、智能计算系统的三大困难 10、开创深度学习处理器方向 11、寒武纪的国…...

SM5101 SOP-8 充电+触摸+发执丝控制多合一IC触摸打火机专用IC
SM5101 SOP-8 2.7V 涓流充电 具电池过充过放 触摸控制 发热丝电流控制多功能为一体专用芯片 昱灿-海川 SM5101 SOP-8 充电触摸发执丝控制多合一IC触摸打火机方案 !!! 简介: SM5101是一款针对电子点烟器的专用芯片,具…...

Mysql-题目02
下面列出的( DBMS )是数据库管理系统的简称。 A、DB(数据库) B、DBA C、DBMS(数据库管理系统) D、DBS(数据库系统) 以下选项中,( 概念模式 )面向数据库设计人员&…...

Swift开发——循环执行方式
本文将介绍 Swift 语言的循环执行方式 01、循环执行方式 在Swift语言中,主要有两种循环执行控制方式: for-in结构和while结构。while结构又细分为当型while结构和直到型while结构,后者称为repeat-while结构。下面首先介绍for-in结构。 循环控制方式for-in结构可用于区间中的…...
Navicat和SQLynx产品功能比较一(整体比较)
Navicat和SQLynx都是数据库管理工具,在过去的二十年中,国内用户主要是使用Navicat偏多,一般是个人简单开发需要,数据量一般不大,开发相对简单。SQLynx是最近几年的数据库管理工具,Web开发,桌面版…...

pip 配置缓存路径
在windows操作平台,默认情况,pip下使用的系统目录 C:\Users\用名名称\AppData\Local\pip C盘是系统盘,如果常常使用pip安装会占用大量的空间很快就满,这时候就有必要变更一下缓存保存路径了。 pip 配置缓存路径: Win…...
 - Scala入门)
大数据开发语言Scala(一) - Scala入门
引言 在当今的大数据时代,数据量和数据处理的复杂性不断增加,传统的编程语言已经难以满足需求。Scala作为一门新兴的编程语言,以其简洁、强大和高效的特性,迅速成为大数据开发的热门选择。本文将详细介绍Scala语言的基础知识&…...
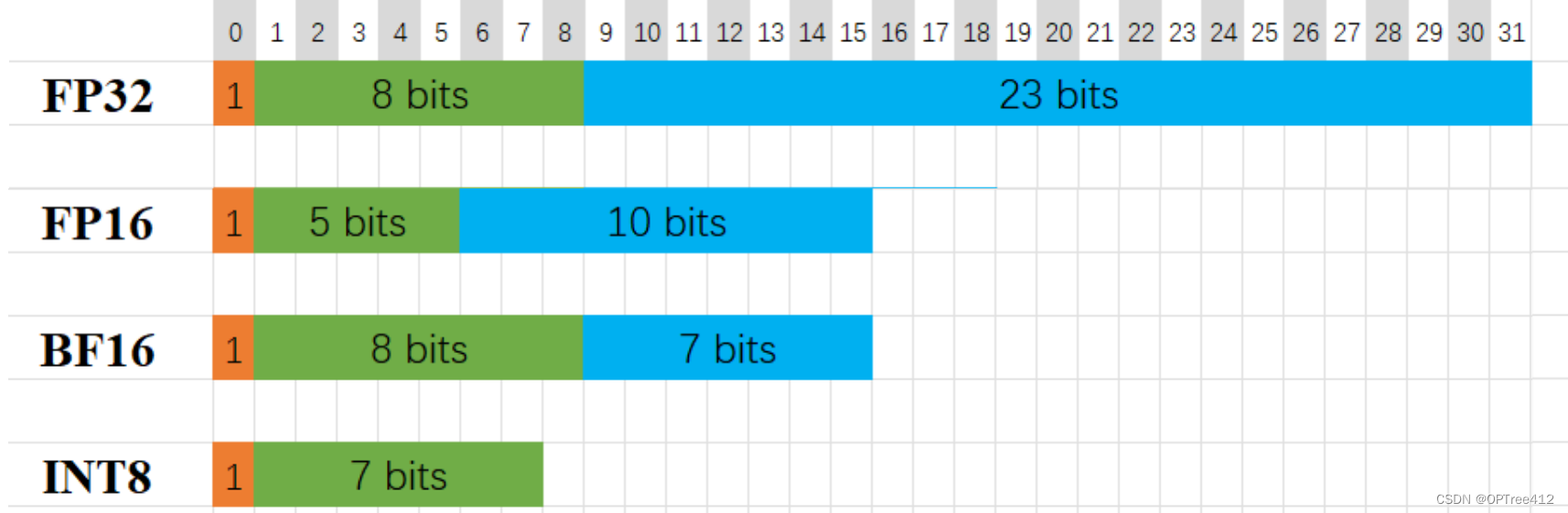
大模型中的计算精度——FP32, FP16, bfp16之类的都是什么???
大模型中的计算精度——FP32, FP16, bfp16之类的都是什么??? 这些精度是用来干嘛的??混合精度 mixed precision training什么是混合精度?怎么转换呢? 为什么大语言模型通常使用FP32精度训练量化…...
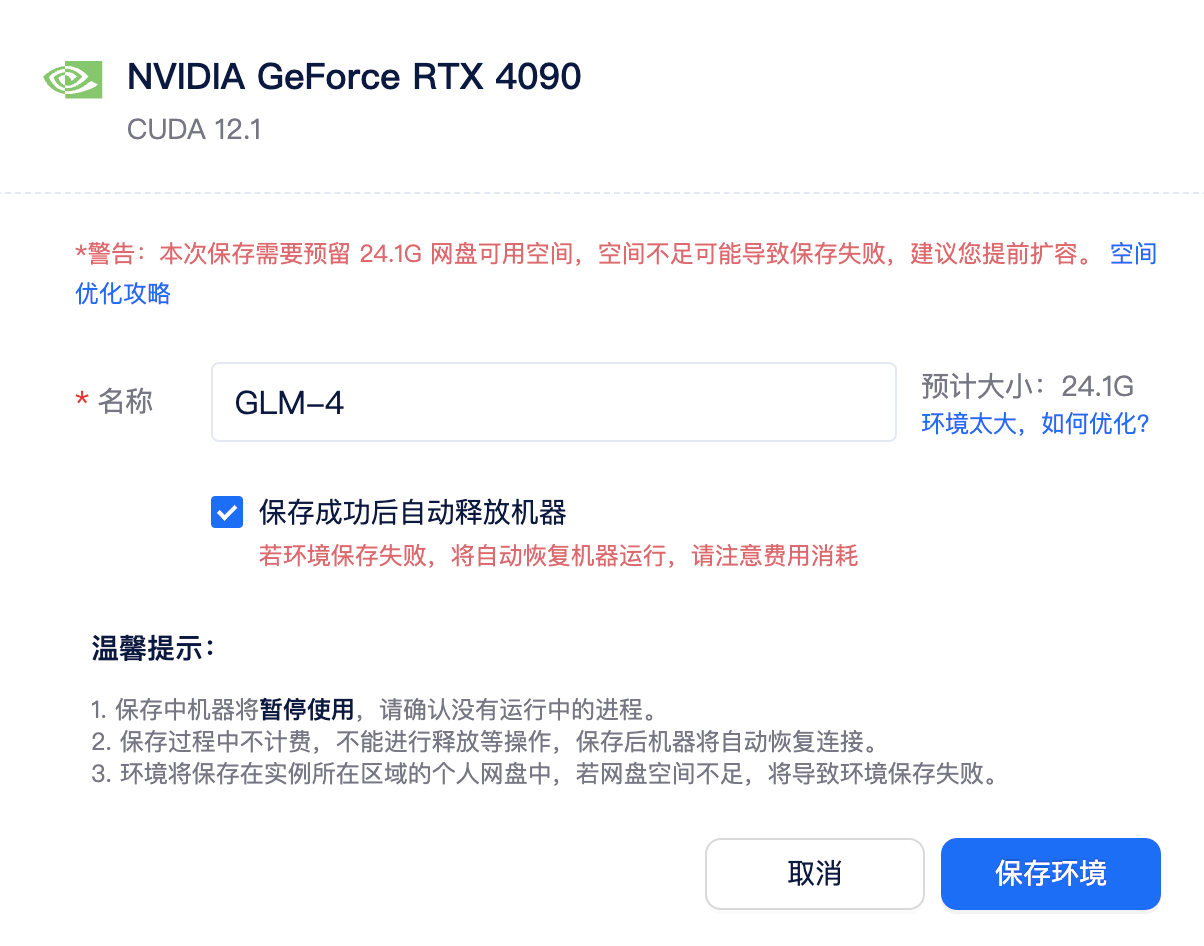
在矩池云使用GLM-4的详细指南(无感连GitHubHuggingFace)
GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本,在多项测试中表现出超越已有同等规模开源模型的性能,它能兼顾多轮对话、网页浏览、代码执行、多语言、长文本推理等多种功能,性能更加强大。其多模态语言模型GLM-4V-9B在…...

黄仁勋CMU演讲:取代你的是会AI的人,所有人同一起跑线,奔跑吧
老黄又当博士了。这是他的第7个荣誉博士学位,而且英特尔CEO陈立武亲自为其授袍。卡内基梅隆大学(CMU)最新一届毕业典礼上,黄仁勋向5800多名毕业生发表演讲。面对AI浪潮的冲击,所有人都在焦虑、都在担心会不会被AI取代&…...

学术合规性危机预警:Perplexity生成内容如何精准适配Chicago第17版?,一文锁定98.7%高校期刊投稿要求
更多请点击: https://intelliparadigm.com 第一章:学术合规性危机预警:Perplexity生成内容如何精准适配Chicago第17版? 随着AI辅助写作工具在人文社科领域的深度渗透,Perplexity等生成式平台输出的引文、脚注与参考文…...
)
紧急预警:Midjourney即将下架Nihonga相关风格标签?(内部消息+已存档的5类不可再生提示词组合,仅限今日开放获取)
更多请点击: https://intelliparadigm.com 第一章:Nihonga风格在Midjourney中的历史定位与美学内核 Nihonga(日本画)作为明治维新后确立的现代民族绘画体系,以天然矿物颜料、金箔银箔、胶质媒介及传统和纸为物质基础&…...

从一次内部渗透测试说起:我是如何利用SSRF漏洞,通过Gopher协议拿下Redis的
渗透测试实战:SSRF漏洞到Redis未授权访问的完整攻击链剖析 在一次常规的企业内部渗透测试中,我发现了一个看似普通的SSRF漏洞,却意外打开了通往内网核心系统的大门。这个故事不是教科书式的漏洞复现,而是一个真实攻击者视角下的完…...
)
Codex入门09-Git工作流(小白入门:不会写commit信息?AI帮你自动生成规范提交)
🎯 本文目标 学会用 Codex 自动化 Git 操作:提交、冲突解决、PR 描述生成。 😰 Git 新手的典型痛点 你的提交记录是不是这样的: git log --oneline a3f4b2c fix 9d1e8c4 update 4c7b91f 修改了一些东西 f0a2d3e 。。。 b5c8e7a 又改了这就是"屎山提交记录"—…...

【DeepSeek开发者垂直搜索实战指南】:3大行业落地案例+5个避坑要点,限时公开内部调优参数
更多请点击: https://intelliparadigm.com 第一章:DeepSeek开发者垂直搜索应用案例全景概览 DeepSeek系列大模型凭借其开源、高性能与强推理能力,正被广泛集成至开发者垂直搜索场景中——从代码片段检索、API文档语义查找,到私有…...
)
别再只会点灯了!用51单片机和继电器模块,做个智能插座控制台灯(附完整代码)
从点灯到智能家居:51单片机与继电器模块的实战进阶指南 当你已经能够熟练地用51单片机点亮LED灯时,是否想过将这些基础技能转化为实际生活中的实用工具?本文将带你跨越实验板与真实世界的鸿沟,用最常见的51单片机和继电器模块&…...

模函数激活:挑战ReLU的极致简洁方案,为CV与TinyML带来性能突破
1. 项目概述:为什么我们需要重新审视激活函数?在深度学习的工具箱里,激活函数可能是最不起眼,却又最不可或缺的部件。它就像神经网络中的“开关”或“阀门”,决定了每个神经元是否被激活,以及激活的程度。长…...

免费在线PPT制作工具PPTist:浏览器中的专业演示文稿创作平台
免费在线PPT制作工具PPTist:浏览器中的专业演示文稿创作平台 【免费下载链接】PPTist PowerPoint-ist(/pauəpɔintist/), An online presentation application that replicates most of the commonly used features of MS PowerPoint, allow…...

Taotoken 官方价折扣与活动价助力个人开发者降低创新门槛
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken 官方价折扣与活动价助力个人开发者降低创新门槛 对于个人开发者和学生而言,探索大模型应用的最大挑战之一往往…...