分批次训练和评估神经网络模型
【背景】
训练神经网络模型的时候,特征组合太多,电脑的资源会不足,所以采用分批逐步进行。已经处理过的批次保存下来,在下一次跳过,只做新加入的批次训练。
选择最优模型组合在中间结果的范围内选择,这样能保证所有的特征都能得到组合,所有的组合都能得到训练和评估。
【流程】
+-------------------------------------+
| 开始 (Start) |
+-------------------------------------+|v
+-------------------------------------+
| 读取中间结果 (loss_records) |
+-------------------------------------+|v
+-------------------------------------+
| 计算总的特征组合数量 |
| (total_combinations) |
+-------------------------------------+|v
+-------------------------------------+
| 计算批次数量 (num_batches) |
+-------------------------------------+|v
+-------------------------------------+
| 初始化进度条 |
+-------------------------------------+|v
+-------------------------------------+
| 清理多余记录 |
| (Clean extra records) |
+-------------------------------------+|v
+-------------------------------------+
| 遍历每个批次 (for each batch) |
+-------------------------------------+|v
+-------------------------------------+
| 获取当前批次特征组合和数据 |
+-------------------------------------+|v
+-------------------------------------+
| 检查当前批次是否已处理 |
| (if batch in loss_records) |
+-------------------+-----------------+
| 否 | 是 |
| | |
v | |
+-------------------------------------+|
| 调用 train_and_evaluate_torch |
+-------------------------------------+|| |v |
+-------------------------------------+|
| 更新所有评估结果 | |
+-------------------------------------+ || | vv +-------------------------------------+
+-------------------------------------+| 跳过已处理的批次,更新评估结果 |
| 保存中间结果 |+-------------------------------------+
| (save intermediate results) |
+-------------------------------------+|v
+-------------------------------------+
| 更新进度条 |
+-------------------------------------+|v
+-------------------------------------+
| 所有批次处理完成 |
| (All batches processed) |
+-------------------------------------+|v
+-------------------------------------+
| 保存最佳模型和特征组合到Excel |
| (save_result_to_excel) |
+-------------------------------------+|v
+-------------------------------------+
| 结束 (End) |
+-------------------------------------+
【需求】
读取中间结果
执行特征工程
遍历传入的特征组合
对比中间结果和新传入的特征组合,
找出和新传入的特征组合的差异,包括新增的和不再用的
执行训练和评估,针对新增的,同步中间数据,中间结果中也包括预测值和模型参数(因为我希望从中选出最优模型,并记录,其中也包括参数信息和预测值)
从最新的评估数据(包括新的和中间结果中的), 选出最优的特征组合,保存到excel
【代码】
import os
import json
import pandas as pd
from tqdm import tqdm
import logging# 读取中间结果以防程序中途停止
loss_records = {}
if os.path.exists(loss_records_file):try:with open(loss_records_file, "r") as f:loss_records = json.load(f)print('~~~~~~~~从中间文件中读取到的loss_records:', loss_records)# 确保键是字符串,并转换回元组形式loss_records = {deserialize_features(k): v for k, v in loss_records.items()}print('~~~~~~~~转换回元组形式的loss_records:', loss_records)print("成功加载 loss_records.json")except json.JSONDecodeError as e:print(f"JSONDecodeError: {e}. 重置 loss_records.json 文件内容。")loss_records = {}with open(loss_records_file, "w") as f:json.dump(loss_records, f)# 获取所有特征组合的总数
total_combinations = len(feature_combinations)# 计算批次数量
num_batches = (total_combinations + combination_batch_size - 1) // combination_batch_size# 进度条初始化
pbar = tqdm(total=total_combinations, desc='特征组合训练进度', position=0, leave=True)
all_evaluation_results = []
new_feature_set = set(feature_combinations)# 删除 loss_records 中多余的记录
loss_records = {k: v for k, v in loss_records.items() if deserialize_features(k) in new_feature_set}
print('Cleaned loss_records:', loss_records)for batch_index in range(num_batches):start = batch_index * combination_batch_sizeend = min(start + combination_batch_size, total_combinations)current_batch = feature_combinations[start:end]current_normalized_data = normalized_data[start:end]print('current_batch: ', current_batch)print('loss_records: ', loss_records)# 检查当前批次是否已处理过if all(features in loss_records for features in current_batch):# 更新进度条pbar.update(len(current_batch))print('跳过已经处理过的批次')# 将已处理过的结果添加到所有评估结果中for features in current_batch:serialized_features = serialize_features(features)if serialized_features in loss_records:results = loss_records[serialized_features]all_evaluation_results.append({'features': features,'mse': results['MSE'],'mae': results['MAE'],'r2': results['R2']})continueprint('----没有跳过----已经处理过的批次')# 调用 train_and_evaluate_torch 函数处理当前批次的特征组合evaluation_results = train_and_evaluate_torch(current_batch, current_normalized_data, param_model, scaler_close, evaluation_results, n, data_obj, parameter_period, loss_records)all_evaluation_results.extend(evaluation_results)# 保存中间结果for features in current_batch:serialized_features = serialize_features(features)print(f'Serializing features: {features} -> {serialized_features}')# 提取结果并保存results = next(item for item in evaluation_results if item['features'] == features)if 'best_metrics' in results:best_metrics = results['best_metrics']loss_records[serialized_features] = {'MSE': convert_numpy_types(best_metrics['mse']),'MAE': convert_numpy_types(best_metrics['mae']),'R2': convert_numpy_types(best_metrics['r2'])}else:loss_records[serialized_features] = {'MSE': convert_numpy_types(results['mse']),'MAE': convert_numpy_types(results['mae']),'R2': convert_numpy_types(results['r2'])}# 输出当前的 loss_records 以进行调试print('Current loss_records before saving: ', loss_records)with open(loss_records_file, "w") as f:json.dump(loss_records, f)# 再次读取并检查文件内容,确保保存正确with open(loss_records_file, "r") as f:loaded_loss_records = json.load(f)print('Loaded loss_records after saving: ', loaded_loss_records)# 更新进度条pbar.update(len(current_batch))print("所有批次处理完成。")
pbar.close()# 最佳模型和每个特征组合的最佳模型保存到excel
save_result_to_excel(strategy_name, all_evaluation_results, OUTPUT_FILE_NEURAL_NETWORK_PATH, weights)def save_result_to_excel(strategy_name, evaluation_results, file_path, weights=None):"""数据保存到excel.Parameters:- evaluation_results 评估数据- file_path excel文件名称,用来保存测试报告Returns:None"""# print('评估数据evaluation_results:', evaluation_results)strategy_func = strategy_mapping.get(strategy_name)if strategy_func:num_params = len(inspect.signature(strategy_func).parameters)if weights and num_params > 1:best_result = strategy_func(evaluation_results, weights)print("best_result assigned successfully:", best_result)else:best_result = strategy_func(evaluation_results)print("best_result assigned successfully:", best_result)print('>>>>>>>>>>保存best_result>>>>>>>>>', best_result)print() try: # 创建一个空列表来存储评估过程的结果evaluation_process_data = []# 添加评估过程中的结果for result in evaluation_results:evaluation_process_data.append({'Features': result['features'],'Best Parameters': result['best_params'],'Best Metrics': result['best_metrics']})# 创建DataFrame来存储评估过程的结果df_evaluation_process = pd.DataFrame(evaluation_process_data)print('训练过程的数据:df_evaluation_process', df_evaluation_process)# 创建一个空的DataFrame来存储最佳模型的结果df_best_model_results = pd.DataFrame(columns=['Features', 'Best Predictions'])if best_result is not None:df_best_model_results.loc[0] = {'Features': best_result['features'], # 使用best_result中的特征信息'Best Predictions': best_result['predictions']}# 倒置最佳模型结果DataFrame的行列df_best_model_results_transposed = df_best_model_results.transpose()# 创建一个新的 DataFrame,用于存储转置后的数据以及其含义df_with_labels = pd.DataFrame(columns=['Label', 'Value'])# 将原始表头作为索引,添加到新 DataFrame 中for feature in df_best_model_results_transposed.index:# 获取转置后数据的值,而不包括索引和数据类型信息value = df_best_model_results_transposed.loc[feature].values[0]df_with_labels = pd.concat([df_with_labels, pd.DataFrame({'Label': [feature], 'Value': [value]})], ignore_index=True)# 保存最佳模型的结果到Excel文件with pd.ExcelWriter(file_path, engine='xlsxwriter') as writer:df_with_labels.to_excel(writer, sheet_name='Best Model Results', index=False)print('执行了保存数据到excel,路径是:') print(file_path) else:print("best_result is None, cannot save to excel")logging.error("best_result is None, cannot save to excel")except Exception as e:print(f"保存测试结果到excel: {e}")logging.error(f"save result to excel: {e}") else:print('Invalid strategy name:', strategy_name)
要点
- 清理多余记录:在处理批次之前,根据新的特征组合清理
loss_records中多余的记录。 - 更新所有评估结果:即使跳过已处理的批次,也将其评估结果添加到
all_evaluation_results中,以确保最终的最佳模型选择是基于所有特征组合。 - 保存最佳结果到Excel:保持
save_result_to_excel函数逻辑不变,确保从所有评估结果中选出最优模型并保存。
这样可以确保即使跳过了一些已处理的批次,最终的最优模型仍然是从所有特征组合中选出的,并且中间结果不会包含多余的记录。
相关文章:

分批次训练和评估神经网络模型
【背景】 训练神经网络模型的时候,特征组合太多,电脑的资源会不足,所以采用分批逐步进行。已经处理过的批次保存下来,在下一次跳过,只做新加入的批次训练。 选择最优模型组合在中间结果的范围内选择,这样…...

【CS.AL】算法核心之分治算法:从入门到进阶
文章目录 1. 概述2. 适用场景3. 设计步骤4. 优缺点5. 典型应用6. 题目和代码示例6.1 简单题目:归并排序6.2 中等题目:最近点对问题6.3 困难题目:分数背包问题 7. 题目和思路表格8. 总结References 1000.01.CS.AL.1.4-核心-DivedeToConquerAlg…...

leetcode刷题记录:hot100强化训练2:二叉树+图论
二叉树 36. 二叉树的中序遍历 递归就不写了,写一下迭代法 class Solution(object):def inorderTraversal(self, root):""":type root: TreeNode:rtype: List[int]"""if not root:return res []cur rootstack []while cur or st…...
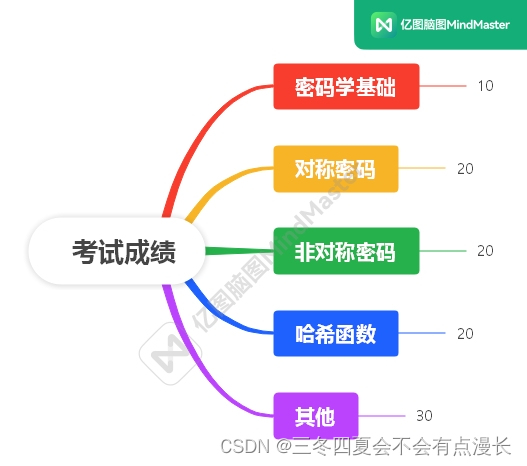
湘潭大学信息与网络安全复习笔记2(总览)
前面的实验和作业反正已经结束了,现在就是集中火力把剩下的内容复习一遍,这一篇博客的内容主要是参考教学大纲和教学日历 文章目录 教学日历教学大纲 教学日历 总共 12 次课,第一次课是概述,第二次和第三次课是密码学基础&#x…...

C语言:头歌使用函数找出数组中的最大值
任务描述 本关任务:本题要求实现一个找出整型数组中最大值的函数。 函数接口定义: int FindArrayMax( int a[], int n ); 其中a是用户传入的数组,n是数组a中元素的个数。函数返回数组a中的最大值。 主程序样例: #include <stdio.h>#…...

【技巧】Leetcode 191. 位1的个数【简单】
位1的个数 编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中 设置位 的个数(也被称为汉明重量)。 示例 1: 输入:n 11 输出:3 解释&#x…...

【Pandas驯化-02】pd.read_csv读取中文出现error解决方法
【Pandas】驯化-02pd.read_csv读取中文出现error解决方法 本次修炼方法请往下查看 🌈 欢迎莅临我的个人主页 👈这里是我工作、学习、实践 IT领域、真诚分享 踩坑集合,智慧小天地! 🎇 相关内容文档获取 微信公众号 &…...
)
linux下C语言如何操作文件(三)
我们继续介绍file_util.c中的函数: bool create_dir(const char* path):创建目录,根据给定的path创建目录,成功返回true,否则返回false。如果有父目录不存在,该函数不会创建。 /*** 创建目录* @param path 目录路径* @return true 创建成功,false 创建失败*/ bool cre…...
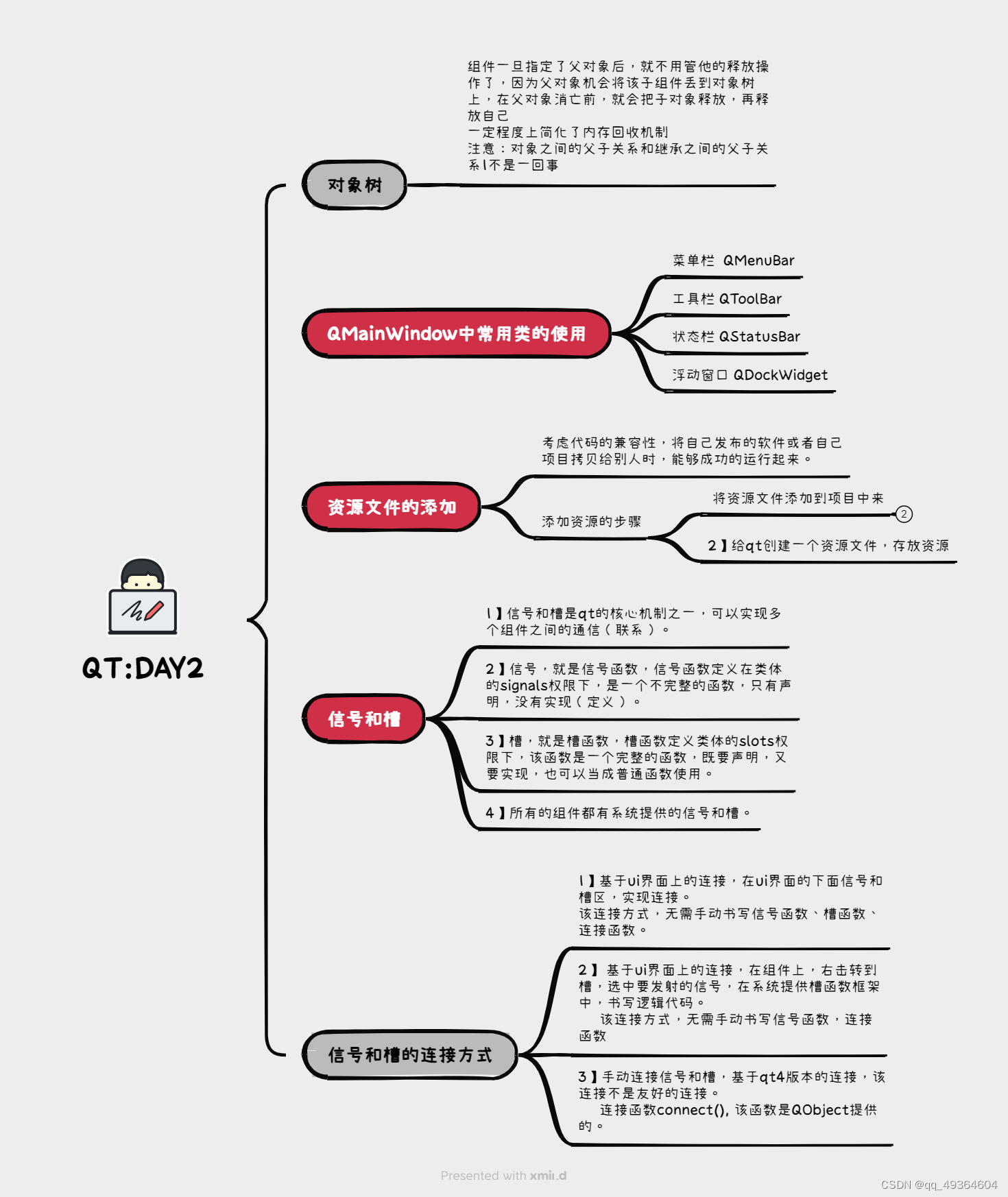
6.14作业
使用手动连接,将登录框中的取消按钮使用第二中连接方式,右击转到槽,在该槽函数中,调用关闭函数 将登录按钮使用qt4版本的连接到自定义的槽函数中,在槽函数中判断ui界面上输入的账号是否为"admin"࿰…...
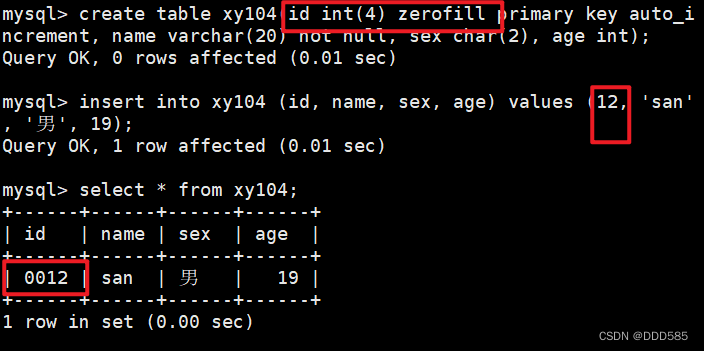
MySQL数据库管理(一)
目录 1.MySQL数据库管理 1.1 常用的数据类型编辑 1.2 char和varchar区别 2. 增删改查命令操作 2.1 查看数据库结构 2.2 SQL语言 2.3 创建及删除数据库和表 2.4 管理表中的数据记录 2.5 修改表名和表结构 3.MySQL的6大约束属性 1.MySQL数据库管理 1.1 常用的数据类…...

Kafka使用教程和案例详解
Kafka 使用教程和案例详解 Kafka 使用教程和案例详解1. Kafka 基本概念1.1 Kafka 是什么?1.2 核心组件2. Kafka 安装与配置2.1 安装 Kafka使用包管理器(如 yum)安装使用 Docker 安装2.2 配置 Kafka2.3 启动 Kafka3. Kafka 使用教程3.1 创建主题3.2 生产消息3.3 消费消息3.4 …...

TGI模型- 同期群-评论文本
用户偏好分析 TGI 1.1 用户偏好分析介绍 要分析的目标,在目标群体中的均值 和 全部群体里的均值进行比较, 差的越多说明 目标群体偏好越明显 TGI(Target Group Index,目标群体指数)用于反映目标群体在特定研究范围内…...
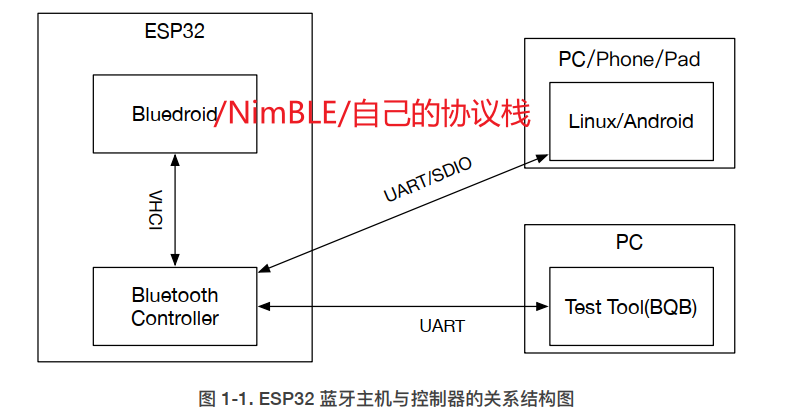
ESP32 BLE学习(0) — 基础架构
前言 (1)学习本文之前,需要先了解一下蓝牙的基本概念:BLE学习笔记(0.0) —— 基础概念(0) (2) 学习一款芯片的蓝牙肯定需要先简单了解一下该芯片的体系结构&a…...

【JAVA】Java中Spring Boot如何设置全局的BusinessException
文章目录 前言一、函数解释二、代码实现三、总结 前言 在Java应用开发中,我们常常需要读取配置文件。Spring Boot提供了一种方便的方式来读取配置。在本文中,我们将探讨如何在Spring Boot中使用Value和ConfigurationProperties注解来读取配置。 一、函数…...
)
pdf.js实现web h5预览pdf文件(兼容低版本浏览器)
注意 使用的是pdf.js 版本为 v2.16.105。因为新版本 兼容性不太好,部分手机预览不了,所以采用v2版本。 相关依赖 "canvas": "^2.11.2", "pdfjs-dist": "^2.16.105", "core-js-pure": "^3.37.…...

SSID简介
一、 SSID 概念定义 SSID(Service Set Identifier)即服务集标识符。它是无线网络中的一个重要标识,用于区分不同的无线网络。 相当于无线网络的名称,用于区分不同的无线网络。用户在众多可用网络中识别和选择特定网络的依据。通…...
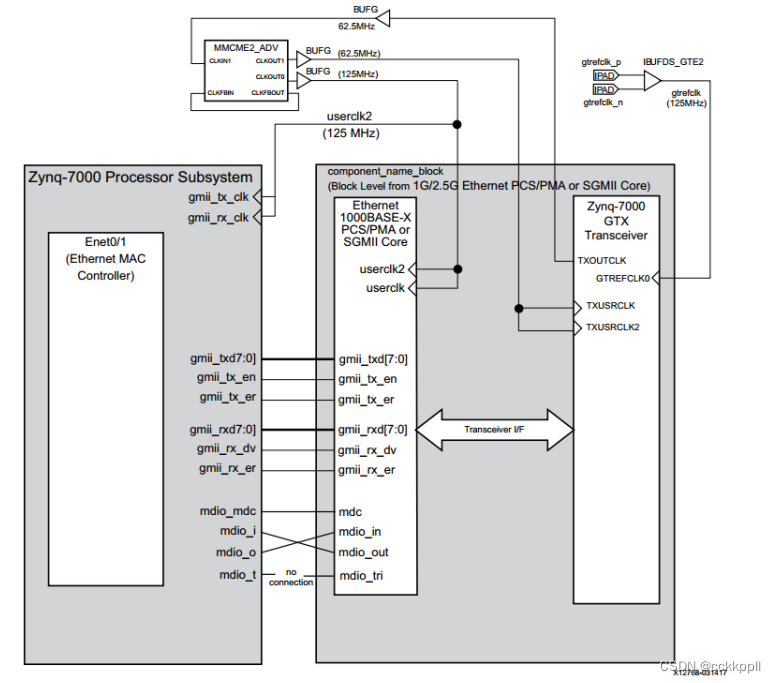
PS通过GTX实现SFP网络通信1
将 PS ENET1 的 GMII 接口和 MDIO 接口 通过 EMIO 方 式引出。在 PL 端将引出的 GMII 接口和 MDIO 接口与 IP 核 1G/2.5G Ethernet PCS/PMA or SGMII 连接, 1G/2.5G Ethernet PCS/PMA or SGMII 通过高速串行收发器 GTX 与 MIZ7035/7100 开发…...
前端面试项目细节重难点(已工作|做分享)(九)
面试官:请你讲讲你在工作中如何开发一个新需求,你的整个开发过程是什么样的? 答:仔细想想,我开发新需求的过程如下: (1)第一步:理解需求文档: 首先&#x…...
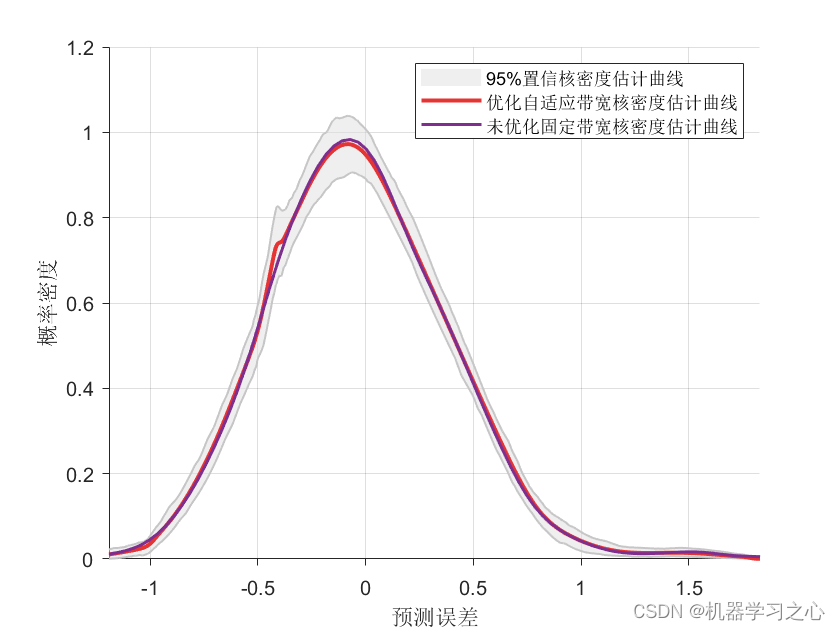
区间预测 | Matlab实现BP-ABKDE的BP神经网络自适应带宽核密度估计多变量回归区间预测
区间预测 | Matlab实现BP-ABKDE的BP神经网络自适应带宽核密度估计多变量回归区间预测 目录 区间预测 | Matlab实现BP-ABKDE的BP神经网络自适应带宽核密度估计多变量回归区间预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现BP-ABKDE的BP神经网络自适应带…...

抢占人工智能行业红利,前阿里巴巴产品专家带你15天入门AI产品经理
前言 当互联网行业巨头纷纷布局人工智能,国家将人工智能上升为国家战略,藤校核心课程涉足人工智能…人工智能领域蕴含着巨大潜力,早已成为业内共识。 面对极大的行业空缺,不少人都希望能抢占行业红利期,进入AI领域。…...

从泊松比到广义胡克定律:物理仿真中的材料形变建模指南
1. 泊松比:材料形变的"性格密码" 第一次接触泊松比这个概念时,我正对着橡胶减震器的仿真结果发愁——明明设置了正确的杨氏模量,为什么变形效果总是不对劲?直到导师指着屏幕问:"你考虑过这个橡胶材料的…...

DeepSeek Jaeger性能压测实录:单日240亿Span写入下,存储层崩溃前的4.7秒黄金抢救窗口
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Jaeger链路追踪 DeepSeek Jaeger 是 DeepSeek 系列可观测性工具中专为分布式系统设计的轻量级链路追踪实现,深度兼容 OpenTracing 与 OpenTelemetry 协议,并针对大模型…...

怎样高效使用DeepSeekMath:7B开源数学推理AI的完整实践指南
怎样高效使用DeepSeekMath:7B开源数学推理AI的完整实践指南 【免费下载链接】DeepSeek-Math DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models 项目地址: https://gitcode.com/GitHub_Trending/de/DeepSeek-Math 还在为…...

OAI 5G核心网搭建后,如何用Docker命令进行日常运维和故障排查?
OAI 5G核心网Docker运维实战:从日志分析到故障排查 当OAI 5G核心网完成基础部署后,真正的挑战才刚刚开始。面对由多个容器组成的复杂系统,如何快速定位AMF拒绝注册的原因?SMF的PDU会话建立失败该如何排查?本文将分享一…...

别再复制粘贴了!手把手教你从零配置一个生产可用的log4j2.xml文件
从零构建生产级Log4j2配置:告别复制粘贴的五个关键设计 每次接手新项目时,看到团队直接从GitHub或博客复制过来的log4j2.xml文件,我都会暗自叹气。这些配置往往带着各种隐患:有的在高峰期突然打满磁盘,有的关键错误日志…...

反PUA30天 Day15:“你格局小“——当这句话出现时,通常意味着对方已经没有别的论据了 |乐想屋
“本文来自「乐想屋」公众号,系列更新[职场反PUA30天觉醒计][职场生存暗规则],每天一篇清醒认知,拒绝内耗,少踩坑,快速成长。”绩效沟通那天,leader跟我说了一句话:「你不要老盯着自己那一亩三分…...

TIA Portal 多版本下载与安装全攻略
1. TIA Portal版本选择与下载准备 第一次接触西门子TIA Portal的工程师,面对从V15.1到V18多个版本时,往往会陷入选择困难。我刚开始用TIA Portal时也踩过不少坑,后来发现版本选择主要取决于两个因素:项目需求和硬件兼容性。如果是…...

通过MCP协议用AI助手管理OVH云资源:ovh-api-mcp项目实战
1. 项目概述:一个连接MCP与OVH云的桥梁 最近在折腾一些自动化运维和云资源管理的活儿,发现了一个挺有意思的开源项目: davidlandais/ovh-api-mcp 。简单来说,这是一个 Model Context Protocol (MCP) 服务器 ,专门…...

如何用Obsidian主页插件打造你的专属数字工作台?
如何用Obsidian主页插件打造你的专属数字工作台? 【免费下载链接】obsidian-homepage Obsidian homepage - Minimal and aesthetic template (with my unique features) 项目地址: https://gitcode.com/gh_mirrors/obs/obsidian-homepage 你是否厌倦了每次打…...

【Midjourney Holga风格权威调参手册】:基于1,843组实测Prompt的色偏校准模型与动态暗角衰减公式
更多请点击: https://intelliparadigm.com 第一章:Holga风格的视觉基因解码与Midjourney适配原理 Holga相机以其塑料镜头、不可控漏光、边缘暗角与柔和色散著称,构成了一套独特的“模拟故障美学”语言。将这种物理成像缺陷转化为AI生成语义&…...