TF-IDF算法
TF-IDF算法详解
一、TF-IDF算法概述
TF-IDF(Term Frequency-Inverse Document Frequency)算法是一种常用于信息检索和文本挖掘的加权技术。其基本思想是通过评估一个词在文档中的重要性,来确定这个词在文档集合或语料库中的权重。TF-IDF算法由两部分组成:词频(Term Frequency, TF)和逆文档频率(Inverse Document Frequency, IDF)。词频指的是一个词在文档中出现的次数与文档总词数的比例,而逆文档频率则是用来衡量一个词在整个文档集合中的重要程度。
二、TF-IDF算法原理
1.词频(TF)
词频(TF)指的是一个词在文档中出现的次数与文档总词数的比例。计算公式为:
[ \text{TF}(t, d) = \frac{n_{t,d}}{N_d} ]
其中,( t ) 是词,( d ) 是文档,( n_{t,d} ) 是词 ( t ) 在文档 ( d ) 中出现的次数,( N_d ) 是文档 ( d ) 的总词数。词频越高,说明该词在文档中的重要性越大。
2.逆文档频率(IDF)
逆文档频率(IDF)用于衡量一个词在整个文档集合中的重要程度。计算公式为:
[ \text{IDF}(t) = \log\frac{D}{d_t + 1} ]
其中,( D ) 是文档集合中的文档总数,( d_t ) 是包含词 ( t ) 的文档数。逆文档频率越高,说明该词在文档集合中的重要性越大。注意,分母加1是为了防止分母为0的情况。
3.TF-IDF值
TF-IDF值是词频和逆文档频率的乘积,计算公式为:
[ \text{TF-IDF}(t, d) = \text{TF}(t, d) \times \text{IDF}(t) ]
TF-IDF值越高,说明该词在文档中的重要性越大。
三、TF-IDF算法的优点
1.可解释性好
TF-IDF算法的结果直观易懂,可以清晰地看到关键词及其在文档中的重要性。这使得TF-IDF算法在文本分析和处理领域具有广泛的应用前景。
2.计算速度快
TF-IDF算法的实现相对简单,计算速度快,特别是对于大规模文档集合的处理。这使得TF-IDF算法在处理大规模文本数据时具有较高的效率。
3.对标注数据依赖小
TF-IDF算法可以使用无标注语料完成一部分工作,对标注数据的依赖较小。这使得TF-IDF算法在缺乏标注数据的情况下仍然能够进行有效的文本分析和处理。
4.可以与其他算法组合使用
TF-IDF算法可以作为词权重使用,与其他算法(如分类器、聚类算法等)结合使用。这种组合使用可以进一步提高文本分析和处理的准确性和效率。
四、TF-IDF算法的缺点
1.受分词效果影响大
分词效果的好坏会直接影响TF-IDF的计算结果。如果分词不准确,可能会导致一些重要的词被忽略,从而影响TF-IDF算法的性能。
2.没有考虑语义信息
TF-IDF算法只考虑了词频和文档频率,没有考虑词语的语义信息。这可能导致一些语义上相似但字面不同的词在TF-IDF值上存在差异,从而影响文本分析和处理的准确性。
3.没有语序信息
TF-IDF算法基于词袋模型,不考虑词语在文档中的顺序。这可能导致一些具有不同语序但语义相同的文档在TF-IDF值上存在差异,从而影响文本分析和处理的准确性。
4.能力范围有限
TF-IDF算法对于复杂任务,如机器翻译和实体挖掘等,可能无法胜任。这是因为这些任务需要更深入的语义理解和分析,而TF-IDF算法只能提供基于词频和文档频率的简单权重评估。
5.样本不均衡会有影响
在样本不均衡的情况下,TF-IDF算法的结果可能会受到影响。例如,在某些类别中某个词的出现频率远高于其他类别,这可能导致该词在该类别的TF-IDF值过高,从而影响分类或聚类的准确性。
五、TF-IDF算法的应用场景
1. 搜索引擎
搜索引擎是TF-IDF算法最典型的应用场景之一。搜索引擎通过计算查询词与文档集中每个文档的TF-IDF值,来评估查询词与文档之间的相关性。这样,当用户输入查询词时,搜索引擎可以快速、准确地返回与查询词最相关的文档。具体来说,搜索引擎会将查询词分词,并计算每个词在文档中的TF值和在整个文档集中的IDF值,然后将它们相乘得到TF-IDF值。最后,搜索引擎会按照TF-IDF值的大小对文档进行排序,将相关性高的文档优先展示给用户。
2. 自然语言处理
在自然语言处理领域,TF-IDF算法也有广泛的应用。例如,在文本分类任务中,可以使用TF-IDF算法来计算文本中每个词语的权重,并将文本表示为向量形式。然后,可以利用这些向量进行文本分类。在文本聚类任务中,同样可以使用TF-IDF算法来计算文本之间的相似度,并将相似的文本聚为一类。此外,TF-IDF算法还可以用于关键词提取、情感分析、文本摘要等任务中。
3. 信息检索
在信息检索领域,TF-IDF算法被用来比较文档之间的相似度,并根据查询词的重要性确定搜索结果的排序。与传统的基于关键词的检索方法相比,TF-IDF算法可以更好地反映词语在文档中的重要性,从而提高检索的准确性和效率。例如,在学术文献检索中,TF-IDF算法可以帮助用户快速找到与自己研究主题相关的文献。
4. 推荐系统
在推荐系统中,TF-IDF算法可以用于表示用户历史行为或兴趣中的物品(如商品、视频、音乐等)。具体来说,可以将用户历史浏览、购买或评价过的物品作为文档,将每个物品的特征(如标题、描述、标签等)作为词语,然后计算每个词语的TF-IDF值来表示该物品的特征权重。这样,当用户需要推荐时,可以根据用户的历史行为和物品的TF-IDF值来计算用户与候选物品之间的相似度,并为用户推荐与其兴趣最匹配的物品。
5. 社交媒体分析
在社交媒体分析中,TF-IDF算法可以用于分析用户的文本内容,以了解用户的兴趣、观点和情感等。例如,可以将用户在社交媒体上发布的帖子或评论作为文档,将帖子或评论中的词语作为特征,然后计算每个词语的TF-IDF值来表示该词语在帖子或评论中的重要性。通过分析不同用户的TF-IDF值分布,可以了解用户的兴趣差异和社交媒体上的热门话题等。
综上所述,TF-IDF算法在信息检索、自然语言处理、推荐系统、社交媒体分析等领域都有广泛的应用。虽然TF-IDF算法存在一些缺点和局限性(如受分词效果影响大、没有考虑语义信息等),但其在文本分析和处理方面的优势仍然使其成为一种重要的文本表示方法。
后续会持续更新分享相关内容,记得关注哦!
相关文章:

TF-IDF算法
TF-IDF算法详解 一、TF-IDF算法概述 TF-IDF(Term Frequency-Inverse Document Frequency)算法是一种常用于信息检索和文本挖掘的加权技术。其基本思想是通过评估一个词在文档中的重要性,来确定这个词在文档集合或语料库中的权重。TF-IDF算法…...
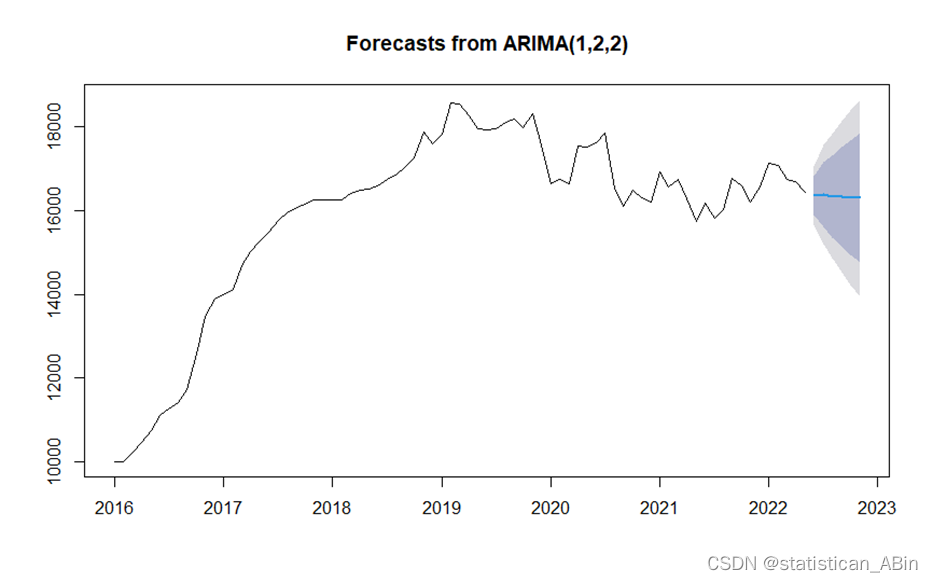
R语言数据分析案例29-基于ARIMA模型的武汉市房价趋势与预测研究
一、选题背景 房地产行业对于国民经济和社会及居民的发展和生活具有很大的影响,而房价能够体现经济运转的好坏,因而房价的波动牵动着开发商和购房者的关注,城市房价预测是一个研究的热点问题,研究房价对民生问题具有重要意义。 …...

面试-NLP八股文
机器学习 交叉熵损失: L − ( y l o g ( y ^ ) ( 1 − y ) l o g ( 1 − ( y ^ ) ) L-(ylog(\hat{y}) (1-y)log(1-(\hat{y})) L−(ylog(y^)(1−y)log(1−(y^))均方误差: L 1 n ∑ i 1 n ( y i − y ^ i ) 2 L \frac{1}{n}\sum\limits_{i1}^{n}…...

数据仓库之离线数仓
离线数据仓库(Offline Data Warehouse)是一种以批处理方式为主的数据仓库系统,旨在收集、存储和分析大量历史数据。离线数据仓库通常用于定期(如每日、每周、每月)更新数据,以支持各种业务分析、报表生成和…...

Mybatis源码解析
MybatisAutoConfiguration或者MybatisPlusAutoConfiguration核心作用是初始化工厂类SqlSessionFactory,其中包含属性interceptors、MapperLocations、TypeAliasesPackage、TypeEnumsPackage、TypeHandlers等。 MybatisAutoConfiguration自动装配类是由依赖…...

前端学习CSS之神奇的块浮动
在盒子模型的基础上就可以对网页进行设计 不知道盒子模型的可以看前面关于盒子模型的内容 而普通的网页设计具有一定的原始规律,这个原始规律就是文档流 文档流 标签在网页二维平面内默认的一种排序方式,块级标签不管怎么设置都会占一行,而同一行不能放置两个块级标签 行级…...

【Java】内部类、枚举、泛型
目录 1.内部类1.1概述1.2分类1.3匿名内部类(重点) 2.枚举2.1一般枚举2.2抽象枚举2.3应用1:用枚举写单例2.4应用2:标识常量 3.泛型3.1泛型认识3.2泛型原理3.3泛型的定义泛型类泛型接口泛型方法 3.4泛型的注意事项 1.内部类 1.1概述 内部类:指…...
LabVIEW电子类实验虚拟仿真系统
开发了基于LabVIEW开发的电子类实验虚拟仿真实验系统。该系统通过图形化编程方式,实现了复杂电子实验操作的虚拟化,不仅提高了学生的操作熟练度和学习兴趣,而且通过智能评价模块提供即时反馈,促进教学和学习的互动。 项目背景 在…...

SVM支持向量机
SVM的由来和概念 间隔最大化是找最近的那个点的距离’ 之前我们学习的都是线性超平面,现在我们要将超平面变成圈 对于非线性问题升维来解决 对于下图很难处理,我们可以将棍子立起来,然后说不定red跑到左边了,green跑到右边了(可能增加了某种筛选条件导致两个豆子分离)(只是一种…...
【Unity】RPG2D龙城纷争(二)关卡、地块
更新日期:2024年6月12日。 项目源码:后续章节发布 索引 简介地块(Block)一、定义地块类二、地块类型三、地块渲染四、地块索引 关卡(Level)一、定义关卡类二、关卡基础属性三、地块集合四、关卡初始化五、关…...
mediamtx流媒体服务器测试
MediaMTX简介 在web页面中直接播放rtsp视频流,重点推荐:mediamtx,不仅仅是rtsp-CSDN博客 mediamtx github MediaMTX(以前的rtsp-simple-server)是一个现成的和零依赖的实时媒体服务器和媒体代理,允许发布,读取&…...

C# 循环
C# 循环 在编程中,循环是一种控制结构,它允许我们重复执行一段代码多次。C# 提供了几种循环机制,以适应不同的编程需求。本文将详细介绍 C# 中常用的几种循环类型,包括 for 循环、while 循环、do-while 循环和 foreach 循环&…...

PHP杂货铺家庭在线记账理财管理系统源码
家庭在线记帐理财系统,让你对自己的开支了如指掌,图形化界面操作更简单,非常适合家庭理财、记账,系统界面简洁优美,操作直观简单,非常容易上手。 安装说明: 1、上传到网站根目录 2、用phpMyad…...
)
机器学习中的神经网络重难点!纯干货(上篇)
. . . . . . . . .纯干货 . . . . . . 目录 前馈神经网络 基本原理 公式解释 一个示例 卷积神经网络 基本原理 公式解释 一个示例 循环神经网络 基本原理 公式解释 一个案例 长短时记忆网络 基本原理 公式解释 一个示例 自注意力模型 基本原理…...

[DDR4] DDR1 ~ DDR4 发展史导论
依公知及经验整理,原创保护,禁止转载。 专栏 《深入理解DDR4》 内存和硬盘是电脑的左膀右臂, 挑起存储的大梁。因为内存的存取速度超凡地快, 但内存上的数据掉电又会丢失,一直其中缓存的作用,就像是我们的工…...
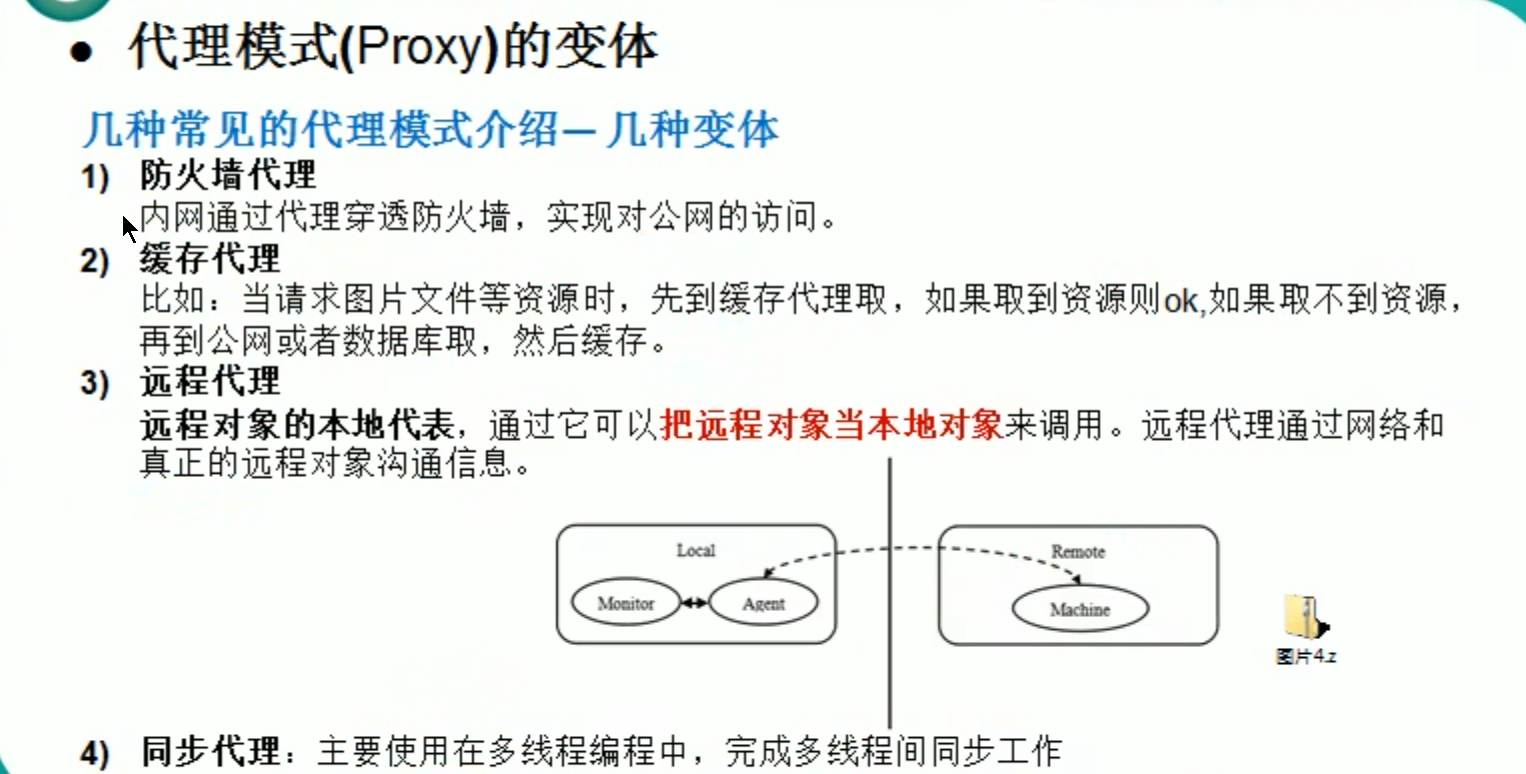
享元和代理模式
文章目录 享元模式1.引出享元模式1.展示网站项目需求2.传统方案解决3.问题分析 2.享元模式1.基本介绍2.原理类图3.外部状态和内部状态4.类图5.代码实现1.AbsWebSite.java 抽象的网站2.ConcreteWebSite.java 具体的网站,type属性是内部状态3.WebSiteFactory.java 网站…...

[英语单词] ellipsize,动词化后缀 -ize
openvswitch manual里的一句话:里面有使用ellipsize,但是查字典是没有这个单词,这就是创造出来的动词。将单词ellipsis,加动词化后缀,-ize。 Often we ellipsize arguments not important to the discussion, e.g.: &…...

自然资源-测绘地信专业术语,值得收藏!
自然资源-测绘地信专业术语,值得收藏! 1、1954年北京坐标系 1954年我国决定采用的国家大地坐标系,实质上是由原苏联普尔科沃为原点的1942年坐标系的延伸。 2、1956年黄海高程系统 根据青岛验潮站1950年一1956年的验潮资料计算确定的平均海面…...

如何在小程序中实现页面之间的返回
在小程序中实现页面之间的返回,通常有以下几种方法,这些方法各有特点,适用于不同的场景: 1. 使用wx.navigateBack方法 描述:wx.navigateBack是微信小程序中用于关闭当前页面,返回上一页面或多级页面的API…...

深入解析数据结构之B树:平衡树中的王者
在计算机科学中,数据结构是算法和程序设计的基础。而在众多数据结构中,B树作为一种平衡树,在数据库和文件系统中有着广泛应用。本文将详细介绍B树的概念、特点、操作、优缺点及其应用场景,帮助读者深入理解这一重要的数据结构。 …...

基于React+TypeScript+Tailwind的ChatGPT应用UI模板开发指南
1. 项目概述:一个为ChatGPT应用量身定制的UI模板如果你正在开发一个基于ChatGPT或类似大语言模型的Web应用,无论是客服机器人、智能写作助手,还是企业内部的知识问答工具,那么你大概率会遇到一个绕不开的难题:如何快速…...

基于GPT-4与Neo4j构建智能推荐聊天机器人:从原理到实践
1. 项目概述:一个能“读懂”并“修改”数据库的智能聊天机器人 最近在捣鼓一个挺有意思的开源项目,叫 NeoGPT-Recommender 。简单来说,它不是一个普通的聊天机器人,而是一个能真正理解你、并基于你的喜好动态更新知识库的智能助…...

UAssetGUI终极指南:深度解析虚幻引擎资源文件转换技术
UAssetGUI终极指南:深度解析虚幻引擎资源文件转换技术 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAssetGUI是…...

Agent-Layer:构建多智能体协作系统的中间层框架设计与实践
1. 项目概述:Agent-Layer 是什么,以及它想解决什么问题最近在开源社区里,一个名为lopushok9/Agent-Layer的项目引起了我的注意。乍一看这个标题,你可能会想,这又是一个关于“智能体”或“代理”的框架吧?确…...

高性能事件存储引擎Chronicle:原理、部署与生产实践指南
1. 项目概述与核心价值最近在折腾日志和事件数据的管理,发现一个挺有意思的开源项目,叫tensakulabs/chronicle。这名字起得挺贴切,“编年史”,一听就知道是跟记录、存储历史事件相关的。简单来说,Chronicle 是一个高性…...

GPU资源利用率监测与优化实战指南
1. GPU资源利用率监测基础解析在超算中心和AI训练集群中,GPU资源利用率(GPU_UTIL)是衡量计算效率的核心指标。这个看似简单的百分比背后,实际上反映了GPU内部多个执行单元的综合活跃状态。通过NVIDIA的DCGM(Data Cente…...

联邦学习与RAG融合:构建隐私保护的分布式智能问答系统
1. 项目概述:当联邦学习遇上检索增强生成最近在折腾一个挺有意思的开源项目,叫fed-rag,来自 Vector Institute。光看名字,老司机们大概就能猜出个七七八八了:这玩意儿是把联邦学习和检索增强生成给揉到一块儿去了。我花…...

DeepSeek Serverless冷启动优化实录:从1200ms到47ms的7次迭代,附Go/Rust双语言Runtime调优参数表
更多请点击: https://intelliparadigm.com 第一章:DeepSeek Serverless冷启动优化全景概览 DeepSeek Serverless 平台在 AI 模型推理场景中面临显著的冷启动延迟挑战,尤其当模型权重加载、CUDA 上下文初始化与 Python 运行时预热叠加时&…...

iOS模拟器效率革命:Alfred工作流实现键盘流式开发
1. 项目概述与核心价值如果你是一名iOS开发者,或者正在学习Swift或React Native,那么你一定对Xcode自带的iOS模拟器又爱又恨。爱的是它让我们在没有实体设备的情况下也能快速测试应用;恨的是每次想启动模拟器、安装应用、截图或录屏ÿ…...

知识付费浪潮下的技术学习:是捷径,还是新的信息茧房?
当“知识”成为一种商品打开手机,各类技术公众号、知识星球、极客时间专栏、慕课网实战课、B站充电视频……铺天盖地的“测试开发进阶”“性能测试大师班”“自动化测试框架实战”正以9.9元、199元、3999元的价格被明码标价。作为一名软件测试工程师,我们…...