【爬虫】requests 结合 BeautifulSoup抓取网页数据
一、BeautifulSoup使用步骤
BeautifulSoup 是一个用于从 HTML 或 XML 文件中提取数据的 Python 库。以下是如何使用 BeautifulSoup 来解析 HTML 并提取信息的基本步骤:
1、安装:
如果你还没有安装 BeautifulSoup,你可以使用 pip 来安装它。BeautifulSoup 通常与 lxml 或 html.parser 这样的解析器一起使用,但 lxml 通常提供更快的解析和更全面的功能。
pip install beautifulsoup4 lxml
2、导入库:
在你的 Python 脚本中,你需要导入 BeautifulSoup 和一个解析器。
from bs4 import BeautifulSoup
import requests
注意:这里我也导入了 requests 库,它用于从网络获取 HTML 内容。如果你已经有了 HTML 内容,你可以直接用它来创建 BeautifulSoup 对象。
3、获取 HTML 内容:
使用 requests 库从网页获取 HTML 内容。
url = 'http://example.com'
response = requests.get(url)
response.raise_for_status() # 如果请求失败,这会抛出一个异常
html_content = response.text
4、解析 HTML:
使用 BeautifulSoup 和解析器来解析 HTML 内容。
soup = BeautifulSoup(html_content, 'lxml')
5、提取数据:
使用 BeautifulSoup 的各种方法和选择器来提取你感兴趣的数据。例如,使用 .find() 或 .find_all() 方法来查找标签,并使用 .get_text() 方法来获取标签内的文本。
# 查找所有的段落标签 <p>
paragraphs = soup.find_all('p')# 打印每个段落的文本内容
for paragraph in paragraphs:print(paragraph.get_text())# 查找具有特定类名的标签
divs_with_class = soup.find_all('div', class_='some-class')# 使用 CSS 选择器查找元素
links = soup.select('a[href]') # 查找所有带有 href 属性的 <a> 标签
6、处理属性:
你也可以获取和处理 HTML 标签的属性。例如,要获取一个链接的 href 属性,你可以这样做:
for link in soup.find_all('a'):print(link.get('href'))
7、清理和关闭:
在处理完 HTML 后,你可能想要关闭任何打开的文件或连接(尽管在使用 requests 和 BeautifulSoup 时通常不需要手动关闭它们)。但是,如果你的脚本涉及其他资源,请确保正确关闭它们。
8、注意事项:
- 尊重网站的
robots.txt文件和版权规定。 - 不要过度请求网站,以免对其造成负担。
- 考虑使用异步请求或线程/进程池来加速多个请求的处理。
- 使用错误处理和重试逻辑来处理网络请求中的常见问题。
二、示例1:抓取百度百科数据
1)抓取百度百科《青春有你第三季》数据
抓取链接是:https://baike.baidu.com/item/青春有你第三季?fromModule=lemma_search-box#4-3
import json
from bs4 import BeautifulSoup
import requestsheaders = {"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6","cache-control": "max-age=0"
}def getAllUsers():url = "https://baike.baidu.com/item/%E9%9D%92%E6%98%A5%E6%9C%89%E4%BD%A0%E7%AC%AC%E4%B8%89%E5%AD%A3?fromModule=lemma_search-box#4-3"response = requests.get(url, headers=headers)response.raise_for_status() # 如果请求失败,这会抛出一个异常html_content = response.textsoup = BeautifulSoup(html_content, 'lxml')trs = soup.find('div', attrs={'data-uuid': "go12lpqgpn"}).find_all(name='tr')listUser = []for tr in trs[1:]:tds = tr.find_all('td')name = tds[0].find('a').get_text()head_href = tds[0].find('a').attrs['href']head_id = head_href.split('/')[3].split('?')[0]provice = tds[1].find('span').get_text()height = tds[2].find('span').get_text()weight = tds[3].find('span').get_text()company = tds[4].find('span').get_text()user = {'name': name, 'head_id': head_id, 'provice': provice, 'height': height, 'weight': weight,'company': company}listUser.append(user)print(listUser)return listUserif __name__ == '__main__':listUser = getAllUsers()with open('user.json', 'w', encoding='utf-8') as f:json.dump(listUser, f, ensure_ascii=False, indent=4)大致结果数据如下:
[{"name": "爱尔法·金","head_id": "55898952","provice": "中国新疆","height": "184cm","weight": "65kg","company": "快享星合"},{"name": "艾克里里","head_id": "19441668","provice": "中国广东","height": "174cm","weight": "55kg","company": "领优经纪"},{"name": "艾力扎提","head_id": "55898954","provice": "中国新疆","height": "178cm","weight": "56kg","company": "简单快乐"},// ...
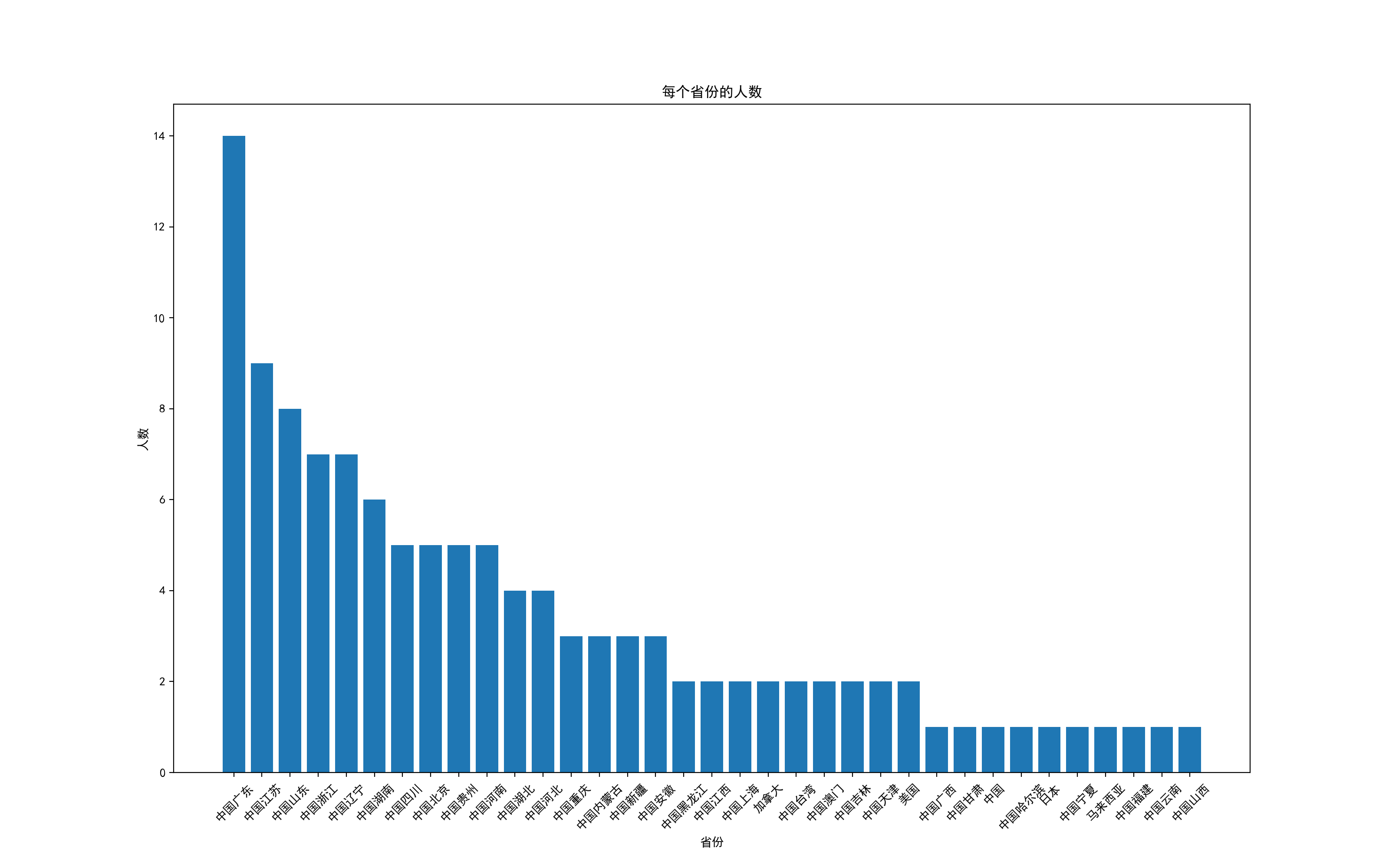
]2)图表展示抓取到的数据
import pandas as pd
import matplotlib.pyplot as pltdf = pd.read_json('user.json')province_counts = df['provice'].value_counts().reset_index()
province_counts.columns = ['provice', 'count']
print(province_counts)# 设置字体为支持中文的字体,比如'SimHei'(黑体),确保你的系统中安装了该字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用于正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号# # 创建一个尺寸为 16x10 英寸、分辨率为 200dpi 的图形窗口
plt.figure(figsize=(16, 10), dpi=200)
plt.bar(province_counts['provice'], province_counts['count'])
plt.title('每个省份的人数')
plt.xlabel('省份')
plt.ylabel('人数')
plt.xticks(rotation=45) # 如果省份名称过长,可以旋转x轴标签以便更好地显示
plt.show()
打印如下数据
provice count
0 中国广东 14
1 中国江苏 9
2 中国山东 8
3 中国浙江 7
4 中国辽宁 7
5 中国湖南 6
6 中国四川 5
7 中国北京 5
8 中国贵州 5
9 中国河南 5
10 中国湖北 4
11 中国河北 4
12 中国重庆 3
13 中国内蒙古 3
14 中国新疆 3
15 中国安徽 3
16 中国黑龙江 2
17 中国江西 2
18 中国上海 2
19 加拿大 2
20 中国台湾 2
21 中国澳门 2
22 中国吉林 2
23 中国天津 2
24 美国 2
25 中国广西 1
26 中国甘肃 1
27 中国 1
28 中国哈尔滨 1
29 日本 1
30 中国宁夏 1
31 马来西亚 1
32 中国福建 1
33 中国云南 1
34 中国山西 1
输出图表:
参考
- https://beautifulsoup.readthedocs.io/zh-cn/v4.4.0/
- https://requests.readthedocs.io/projects/cn/zh-cn/latest/
相关文章:
【爬虫】requests 结合 BeautifulSoup抓取网页数据
一、BeautifulSoup使用步骤 BeautifulSoup 是一个用于从 HTML 或 XML 文件中提取数据的 Python 库。以下是如何使用 BeautifulSoup 来解析 HTML 并提取信息的基本步骤: 1、安装: 如果你还没有安装 BeautifulSoup,你可以使用 pip 来安装它。…...

安全测试框架 二
使用安全测试框架进行测试,可以遵循以下步骤进行,以确保测试的全面性和系统性: 一、明确测试目标和需求 确定测试的范围和重点,明确要测试的系统或应用的安全性方面的关键点和重要性。根据业务需求和安全标准,制定详…...

安徽京准-NTP网络授时服务器助力助力甘南州公共资源交易
安徽京准-NTP网络授时服务器助力助力甘南州公共资源交易 安徽京准-NTP网络授时服务器助力助力甘南州公共资源交易 2024年5月中旬,我安徽京准科技生产研发的NTP时钟服务器成功投运甘南州公共资源交易中心,为该中心的计算机网络系统及其他各业务子系统提供…...

大数据—什么是大数据?
大数据是指所涉及的资料量规模巨大到无法透过主流软件工具,在合理时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。想要更加全面地了解大数据的概念,可以从以下几个维度进行介绍: 大数据的定义: 基本…...
 - 自然语言处理扩展研究)
德克萨斯大学奥斯汀分校自然语言处理硕士课程汉化版(第十一周) - 自然语言处理扩展研究
自然语言处理扩展研究 1. 多语言研究2. 语言锚定3. 伦理问题 1. 多语言研究 多语言(Multilinguality)是NLP的一个重要研究方向,旨在开发能够处理多种语言的模型和算法。由于不同语言在语法、词汇和语义结构上存在差异,这成为一个复杂且具有挑战性的研究…...
中核函数的本质意义)
支持向量机(SVM)中核函数的本质意义
本质上在做什么? 内积是距离度量,核函数相当于将低维空间的距离映射到高维空间的距离,并非对特征直接映射。 为什么要求核函数是对称且Gram矩阵是半正定? 核函数对应某一特征空间的内积,要求①核函数对称;②…...
SpringBoot使用jasypt实现数据库信息的脱敏,以此来保护数据库的用户名username和密码password(容易上手,详细)
1.为什么要有这个需求? 一般当我们自己练习的时候,username和password直接是爆露出来的 假如别人路过你旁边时看到了你的数据库账号密码,他跑到他的电脑打开navicat直接就是一顿连接,直接疯狂删除你的数据库,那可就废…...

Python日志配置策略
1 三种情况下都能实现日志打印: 被库 A 调用,使用库 A 的日志配置。被库 B 调用,使用库 B 的日志配置。独立运行,使用自己的日志配置。 需要实现一个灵活的日志配置策略,使得日志记录器可以根据调用者或运行环境自动…...
想学编程,什么语言最好上手?
Python是许多初学者的首选,因为它的语法简洁易懂,而且有丰富的资源和社区支持。我这里有一套编程入门教程,不仅包含了详细的视频 讲解,项目实战。如果你渴望学习编程,不妨点个关注,给个评论222,…...

binlog和redolog有什么区别
在数据库管理系统中,binlog(binary log)和 redolog(redo log)是两种重要的日志机制,它们在数据持久性和故障恢复方面扮演着关键角色。虽然它们都用于记录数据库的变化,但它们的目的和使用方式有…...
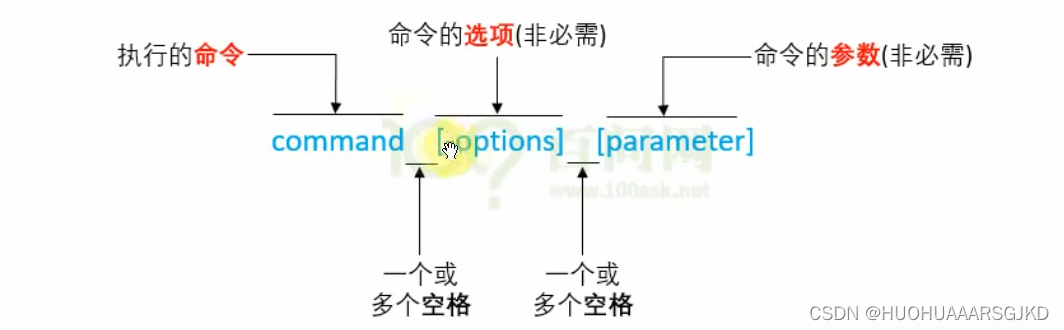
Linux笔记--ubuntu文件目录+命令行介绍
文件目录 命令行介绍 当我们在ubuntu中命令行处理位置输入ls后会显示出其所有目录,那么处理这些命令的程序就是shell,它负责接收用户的输入,并根据输入找到其他程序并运行 命令行格式 linux的命令一般由三部分组成:command命令、…...

71、最长上升子序列II
最长上升子序列II 题目描述 给定一个长度为N的数列,求数值严格单调递增的子序列的长度最长是多少。 输入格式 第一行包含整数N。 第二行包含N个整数,表示完整序列。 输出格式 输出一个整数,表示最大长度。 数据范围 1 ≤ N ≤ 100000…...
解决必剪电脑版导出视频缺斤少两的办法
背景 前几天将电脑重置了,今天想要剪辑一下视频,于是下载了必剪,将视频、音频都调整好,导出,结果15分钟的视频只能导出很短的时长,调整参数最多也只能导出10分钟,My God! 解决 首…...
)
新人学习笔记之(常量)
一、什么是常量 1.常量:在程序的执行过程中,其值不能发生改变的数据 二、常量的分类 常量类型说明举例整型常量整数、负数、0123 456实型常量所有带小数点的数字1.93 18.2字符常量单引号引起来的字母、数字、英文符号S B字符串常量双引号引起来的&…...

Lua解释器裁剪
本文目录 1、引言2、文件功能3、选择需要初始化的库4、结论 文章对应视频教程: 已更新。见下方 点击图片或链接访问我的B站主页~~~ Lua解释器裁剪,很简单~ 1、引言 在嵌入式中使用lua解释器,很多时候会面临资源紧张的情况。 同时,…...

web前端设计nav:深入探索导航栏设计的艺术与技术
web前端设计nav:深入探索导航栏设计的艺术与技术 在web前端设计中,导航栏(nav)扮演着至关重要的角色,它不仅是用户浏览网站的指引,更是网站整体设计的点睛之笔。本文将从四个方面、五个方面、六个方面和七…...

分析解读NCCL_SHM_Disable与NCCL_P2P_Disable
在NVIDIA的NCCL(NVIDIA Collective Communications Library)库中,NCCL_SHM_Disable 和 NCCL_P2P_Disable 是两个重要的环境变量,它们控制着NCCL在多GPU通信中的行为和使用的通信机制。下面是对这两个环境变量的详细解读࿱…...

使用 Python 进行测试(6)Fake it...
总结 如果我有: # my_life_work.py def transform(param):return param * 2def check(param):return "bad" not in paramdef calculate(param):return len(param)def main(param, option):if option:param transform(param)if not check(param):raise ValueError(…...

Flink Watermark详解
Flink Watermark详解 一、概述 Flink Watermark是Apache Flink框架中为了处理乱序和延迟事件时间数据而引入的一种机制。在流处理中,由于数据可能不是按照事件产生的时间顺序到达的,Watermark被用来告知系统在该时间戳之前的数据已经全部到达ÿ…...

LeetCode538.把二叉搜索树转换为累加树
class Solution { public:int sum 0; TreeNode* convertBST(TreeNode* root) { if (root){convertBST(root->right);sum root->val;root->val sum;convertBST(root->left);}return root;}};...

DOM Node:深入解析与高效使用
DOM Node:深入解析与高效使用 引言 DOM(Document Object Model)是现代网页开发的核心技术之一,它允许开发者以程序化的方式操作HTML文档。DOM Node是DOM的核心概念之一,理解并熟练使用DOM Node对于提高网页开发效率至关重要。本文将深入解析DOM Node的概念、类型、属性和…...

杂交瘤技术:单克隆抗体制备的经典核心技术
杂交瘤技术(Hybridoma Technology)是通过人工细胞融合技术,将经抗原免疫的 B 淋巴细胞与骨髓瘤细胞融合,构建可无限增殖且分泌高纯度、高特异性单克隆抗体的杂交瘤细胞系的核心技术。该技术由 Georges Kohler 与 Cesar Milstein 于…...

基于LLM的智能体驱动文字冒险游戏引擎设计与实现
1. 项目概述:一个AI驱动的文字冒险游戏引擎最近在GitHub上闲逛,发现了一个挺有意思的项目,叫droxey/agentadventure。光看名字,大概能猜到它和“智能体”(Agent)以及“冒险”(Adventure…...

如何在Windows电脑上直接安装Android应用:3个简单步骤告别模拟器
如何在Windows电脑上直接安装Android应用:3个简单步骤告别模拟器 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经希望在Windows电脑上直接运行An…...

为什么我们的浏览器操作效率低下?如何用Shortkeys扩展实现3倍效率提升
为什么我们的浏览器操作效率低下?如何用Shortkeys扩展实现3倍效率提升 【免费下载链接】shortkeys A browser extension for custom keyboard shortcuts 项目地址: https://gitcode.com/gh_mirrors/sh/shortkeys 每天在浏览器上,我们花费大量时间…...
)
从手动导入到自动溯源:Perplexity提问→Mendeley定位原文→高亮引用段落→一键生成BibTeX(全流程图解)
更多请点击: https://intelliparadigm.com 第一章:从手动导入到自动溯源:Perplexity提问→Mendeley定位原文→高亮引用段落→一键生成BibTeX(全流程图解) 科研写作中,文献溯源与引用管理长期面临“知其然不…...

抖音批量下载终极解决方案:douyin-downloader免费开源工具完整指南
抖音批量下载终极解决方案:douyin-downloader免费开源工具完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fa…...

MSP 盈利、留客、提口碑,核心就盯这12个 KPI
很多 MSP(托管服务提供商)都会陷入一个误区,手里握着一堆散落在各个看板的运营数据,却始终搞不清哪些指标能真正帮自己提升服务质量、拉高利润、留住客户。忙忙碌碌做了一堆报表,最终还是凭感觉做决策,业务…...

Python爬虫实战:构建智能职位信息聚合工具JobClaw
1. 项目概述:一个面向开发者的智能职位信息聚合与解析工具最近在帮团队招聘和看机会的朋友聊天,发现一个挺普遍的问题:大家找技术岗位,要么在几个主流招聘App上反复刷,信息分散且格式不一;要么就是盯着几个…...
)
告别时序烦恼:用Xilinx MIG IP核搞定FPGA DDR3内存接口(附MT41J256M16配置要点)
告别时序烦恼:用Xilinx MIG IP核搞定FPGA DDR3内存接口(附MT41J256M16配置要点) 在FPGA开发中,DDR3内存接口设计往往是让工程师头疼的难题之一。时序控制、信号完整性、配置参数选择,每一个环节都可能成为项目推进的拦…...